一种财务凭证信息自动识别方法
文献发布时间:2023-06-19 11:45:49
技术领域
本发明涉及图像识别存储技术领域,尤其是指一种财务凭证信息自动识别方法。
背景技术
在企业的标准成本核算中,需要涉及到企业的财务结算内容,企业的财务结算通常有内部单位间的结算、与供应商的结算以及与银行间的结算等,而这些结算的过程中往往需要用到财务凭证。现有的纸质财务凭证包括的内容一般有摘要、科目、金额、制证日期、借贷方向等。但是纸质财务凭证保存较为困难,同时在进行查证、审计时较为麻烦,需要将纸质财务凭证进行电子化存储,现有的将纸质财务凭证进行电子化存储的过程只是简单的将纸质财务凭证进行图像提取记录,并不能自动获取纸质财务凭证种类信息、金额信息以及防伪信息,这些信息需要人工识别获取,效率较低且容易出错。
中国专利公开号CN112598062A,公开日2021年4月2日,名称为《一种图像识别方法和装置》的发明专利中公开了一种图像识别方法和装置,该方法包括:获取待识别图像;从待识别图像中随机裁剪出具有预设图像大小的图像块;将图像块输入训练好的神经网络分类模型获取图像块的分类结果;根据分类结果确定分类置信度;根据分类置信度确定是否将当前分类结果作为最终图像识别结果;当不能将当前分类结果作为最终图像识别结果时,以迭代计算的形式根据特征图和定位策略网络重新获得下一个图像块,并根据下一个图像块获取下一个分类置信度,直至根据获得的分类置信度确定出将当前分类结果作为最终图像识别结果。不足之处在于,该发明只是公开了对图像的一种识别方法,并不能将该识别方法运用到纸质财务凭证的图像识别中,对于纸质产物凭证的金额信息等也无法做到较好的识别。
发明内容
本发明的目的是克服现有技术中的缺点,提供一种财务凭证信息自动识别方法。
本发明的目的是通过下述技术方案予以实现:
一种财务凭证信息自动识别方法,图像分析模块对纸质财务凭证的图像信息进行图像特征信息提取,然后图像分析模块根据图像特征信息进行分析得到数据信息,数据信息进行电子化存储;
所述的图像特征信息包括:纸质财务凭证的类别信息、纸质财务凭证的金额信息和纸质财务凭证的验证信息,
在纸质财务凭证的类别信息识别中,图像分析模块根据不同种类的纸质财务凭证对应的不同的类别信息确定纸质财务凭证的类别;
在对于纸质财务凭证的金额信息识别中,图像分析模块通过以下步骤完成图像特征信息提取:
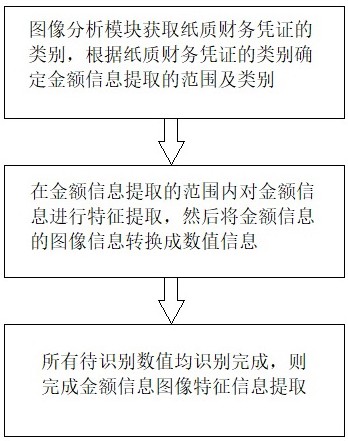
如图1所示,图像分析模块获取纸质财务凭证的类别,根据纸质财务凭证的类别确定金额信息提取的范围及类别,金额信息提取的类别为阿拉伯数字信息;
步骤2,在金额信息提取的范围内对金额信息进行特征提取,然后将金额信息的图像信息转换成数值信息,具体方式为:确定金额信息内每一个数值的图像区域,图像区域内的数值为待识别数值,对于任意一个图像区域,通过卷积神经网络进行识别,将图像区域的待识别数值与卷积神经网络预训练的数值信息进行比对确定置信度,若待识别数值与某一个数值信息的置信度大于等于设定的阈值,且该待识别数值与其他数值信息的置信度小于设定的阈值,则该待识别数值确定为置信度大于等于设定阈值对应的数值信息,若待识别数值与所有数值信息的置信度均小于设定的阈值,则执行纠错分析步骤,使待识别数值确定具体数值信息;
步骤3,所有待识别数值均识别完成,则完成金额信息图像特征信息提取;
在纸质财务凭证的验证信息识别中,图像分析模块根据预设的映射规则将验证信息进行还原验证真伪。
所述的纠错分析步骤具体包括:
将待识别数值的图像区域分解成若干块子图像区域,同时卷积神经网络预训练的数值信息也对应分解成若干块子数值信息,对于任意一个子图像区域,通过卷积神经网络进行识别,将该子图像区域内待识别子数值与卷积神经网络预训练的子数值信息进行比对确定子置信度,若该子图像区域内待识别子数值与某一个子数值信息的置信度大于等于设定的子置信度阈值,同时该子图像区域内待识别子数值与其他的子数值信息的置信度小于设定的子置信度设定阈值,则将子数值信息对应的数值信息确定为待识别数值的数值信息。
本方案将纸质财务凭证分为三类待识别区域,在图像特征信息提取过程中,首先提取的是纸质财务凭证的类别信息,类别信息一般为较易识别的信息,可以是二维码或条形码,更多地可以和颜色相结合,确保纸质财务凭证的类别信息识别读取准确率较高,不会出错。在确定纸质财务凭证的类别信息后,根据纸质财务凭证的类别,调取预设的每一个类别对应的金额信息提取的范围,就可以快速对金额信息进行图像特征信息提取,金额信息在本方案中提供卷积神经网络进行识别,将图像信息转换为具体的金额数据进行存储。更多地,本方案还设计了验证信息,验证信息一般用于对纸质财务凭证的防伪识别,验证信息可以是防伪码或者防伪水印,在确保纸质财务凭证真伪的同时还可以对纸质财务凭证的类别信息的识别进行验证是否识别正确。综上所述,本方案对于财务凭证存储记录不仅仅是做到了图像的存储,而且对于财务凭证的数据进行了数据化的存储,节约了人工成本,且减少了人工记录的误差,同时对于验证信息的识别进一步提高了识别的准确率。
由于纸质财务凭证的金额信息可能是人工填写或者是打印的数据,人工填写会由于每个人的字迹不一造成数值的大小形状不统一,而打印的数据则会产生打印深浅不一的问题,这些都会导致卷积神经网路对金额信息的图像特征信息提取发生错误的情况。因此,本方案中,对于金额信息的图像特征信息提取设置了纠错分析步骤,将待识别数值的图像区域分解成若干块子图像区域,对于任意一块子图像区域如果与对应的子数值信息相匹配,那么可以认为子数值信息对应的数值信息确定为待识别数值的数值信息,此设计优化了对于金额信息的图像特征信息提取的能力。
作为优选,所述的纠错分析步骤还包括:
若该子图像区域内待识别子数值与其中至少两个子数值信息的置信度大于等于设定的子置信度阈值,则将这些子数值信息对应的数值信息作为候选数值信息,且对待识别数值的其他子图像区域进行置信度分析,若其他任意一个子图像区域内待识别子数值与某一个子数值信息的置信度大于等于设定的子置信度阈值,同时该子图像区域内待识别子数值与其他的子数值信息的置信度小于设定的子置信度设定阈值,且该子数值信息对应的数值信息与候选数值信息中某一个数值信息相同,则该子数值信息对应的数值信息即为待识别数值的数值信息。
若分解成若干块子图像区域,对于某一个子图像区域,与至少两个子数值信息的置信度大于等于设定的子置信度阈值,例如阿拉伯数字6或8的下半部分作为子图像区域时,6或8作为子数值信息的置信度均大于设定的子置信度阈值,此时,分析待识别数值的其他子图像区域的置信度,此时6或8其他子图像区域的置信度会相差较大,因此,本方案的设计进一步提升了对于金额信息的图像特征信息提取的能力。
作为优选,所述的若干块子图像区域的大小均相等,若干块子图像区域将图像区域进行横向等分或纵向等分;所述的纠错分析子步骤具体为:
子步骤a,对于单个子图像区域,寻找每一个数值信息中与单个子图像区域大小相等的且置信度最高的第一区域,记录该第一区域及其置信度,所有数值信息对应的置信度中,确定最高的置信度,最高的置信度对应的数值信息为候选数值信息;
子步骤b,选取单个子图像区域相邻的子图像区域,寻找候选数值信息中与相邻的子图像区域大小相等且置信度最高的第二区域,记录该第二区域;
子步骤c,比较第一区域和第二区域,若第一区域和第二区域相邻或第一区域和第二区域之间的距离小于设定的误差值或第一区域和第二区域之间重叠的区域的面积小于设定的面积值,则判断候选数值信息为最终数值信息,待识别数值的数值信息确定为最终数值信息对应的识别数值;其他情况下,跳转至子步骤d,
子步骤d,删除最高的置信度对应的数值信息,重复执行子步骤a至子步骤c,直到确定待识别数值对应的识别数值为止。
手写的金额信息会由于不同人手写差别较大,所以在对金额信息的图像特征信息提取的过程中,若用将待识别数值的图像区域分解成若干块子图像区域,同时卷积神经网络预训练的数值信息也对应分解成若干块子数值信息,子图像区域和子数值信息确定置信度的方法,有可能会无法识别出手写信息,因此,本方案中卷积神经网络预训练的数值信息不再是简单的分解成若干块子数值信息,而是将子图像区域在卷积神经网络预训练的数值信息中遍历匹配,得出最优匹配结果,这样首先确保了手写的金额信息能进行尽可能的最优匹配,然后将该子图像区域相邻的子图像区域与卷积神经网络预训练的数值信息进行匹配,第一区域和第二区域之间可能会不相邻或者可能会有重叠区域,但是只要第一区域和第二区域相邻或第一区域和第二区域之间的距离小于设定的误差值或第一区域和第二区域之间重叠的区域的面积小于设定的面积值,就认为是匹配成功。
作为优选,所述的子步骤d最多执行两次,若在执行两次子步骤d后未确定最终数值信息,则判断待识别数值识别失败。
作为优选,所述的金额信息还包括中文大写数字信息,中文大写数字信息通过OCR进行识别,识别完成后将中文大写数字信息对应的数值和阿拉伯数字信息对应的数值相比较,若两者数值相等,则判断阿拉伯数字信息和中文大写数字信息识别成功,若两者数值不相等,则执行修正步骤,确保金额信息识别成功。
纸质财务凭证上的金额信息有时通过人工手写完成,此时会出现中文大写数字和阿拉伯数字信息识别不一致的情况,因此,本方案中巧妙的利用了财务凭证上包含的阿拉伯数字信息和中文大写数字信息判断卷积神经网络特征识别是否出现错误,对阿拉伯数字信息和中文大写数字信息进行匹配,可以将不一致的数值修正成一致的数值。
作为优选,所述的修正步骤具体为:在中文大写数字信息中寻找置信度大于设定的中文大写数字阈值的可能匹配结果,在阿拉伯数字信息中寻找置信度大于设定的阿拉伯数字阈值的可能匹配结果,若在可能匹配结果中对应的数值相等,则将不相等的数值修正成相等的数值。
作为优选,财务凭证信息自动识别方法还包括对卷积神经网络进行优化的方法,在初始的卷积神经网络中,每一个数值对应一个初始图像数量,在进行若干次的卷积神经网络训练后,每一个数值对应的图像数量也会存在若干个,将任意一个数值的所有图像与预初始图像进行相似度比较,选取相似度小于等于设定的阈值的图像,将这些图像作为候选图像保留,然后将所有候选图像两两比较相似度,若任意两个候选图像之间的相似度小于设定值,则将这两个候选图像之间与初始图像之间相似度较低的进行保留、相似度较高的舍弃,若任意两个候选图像之间的相似度大于等于设定值,则两个候选图像均保留;所有保留的候选图像和初始图像均保留作为该数值对应的图像。
本设计对卷积神经网络进行优化训练,尽可能的保留了对于同一个数值可能出现的图像,这些图像之间互相有差异但是都可以认为是该数值对应的图像,此设计能提高卷积神经网络的识别效率,也进一步确保了对于纸质财务凭证的金额信息的识别正确率。
本发明的有益效果是:
1. 本方案对于财务凭证存储记录不仅仅是做到了图像的存储,而且对于财务凭证的数据进行了数据化的存储,节约了人工成本,且减少了人工记录的误差,同时对于验证信息的识别进一步提高了识别的准确率;
2. 对于金额信息的图像特征信息提取设置了纠错分析子步骤,优化了对于金额信息的图像特征信息提取的能力;
3. 对卷积神经网络进行优化训练,进一步确保了对于纸质财务凭证的金额信息的识别正确率。
附图说明
图1是本发明纸质财务凭证的金额信息识别的流程图;
图2是本发明纸质财务凭证的一种示意图。
具体实施方式
下面结合附图和实施例对本发明进一步描述。
实施例1:
一种财务凭证信息自动识别方法,图像分析模块对纸质财务凭证的图像信息进行图像特征信息提取,然后图像分析模块根据图像特征信息进行分析得到数据信息,数据信息进行电子化存储;
所述的图像特征信息包括:纸质财务凭证的类别信息、纸质财务凭证的金额信息和纸质财务凭证的验证信息,
在纸质财务凭证的类别信息识别中,图像分析模块根据不同种类的纸质财务凭证对应的不同的类别信息确定纸质财务凭证的类别;
在对于纸质财务凭证的金额信息识别中,图像分析模块通过以下步骤完成图像特征信息提取,如图1所示:
步骤1,图像分析模块获取纸质财务凭证的类别,根据纸质财务凭证的类别确定金额信息提取的范围及类别,金额信息提取的类别为阿拉伯数字信息;
步骤2,在金额信息提取的范围内对金额信息进行特征提取,然后将金额信息的图像信息转换成数值信息,具体方式为:确定金额信息内每一个数值的图像区域,图像区域内的数值为待识别数值,对于任意一个图像区域,通过卷积神经网络进行识别,将图像区域的待识别数值与卷积神经网络预训练的数值信息进行比对确定置信度,若待识别数值与某一个数值信息的置信度大于等于设定的阈值,且该待识别数值与其他数值信息的置信度小于设定的阈值,则该待识别数值确定为置信度大于等于设定阈值对应的数值信息,若待识别数值与所有数值信息的置信度均小于设定的阈值,则执行纠错分析步骤,使待识别数值确定具体数值信息;
步骤3,所有待识别数值均识别完成,则完成金额信息图像特征信息提取;
在纸质财务凭证的验证信息识别中,图像分析模块根据预设的映射规则将验证信息进行还原验证真伪。
所述的纠错分析步骤具体包括:
将待识别数值的图像区域分解成若干块子图像区域,同时卷积神经网络预训练的数值信息也对应分解成若干块子数值信息,对于任意一个子图像区域,通过卷积神经网络进行识别,将该子图像区域内待识别子数值与卷积神经网络预训练的子数值信息进行比对确定子置信度,若该子图像区域内待识别子数值与某一个子数值信息的置信度大于等于设定的子置信度阈值,同时该子图像区域内待识别子数值与其他的子数值信息的置信度小于设定的子置信度设定阈值,则将子数值信息对应的数值信息确定为待识别数值的数值信息。
本方案将纸质财务凭证分为三类待识别区域,在图像特征信息提取过程中,首先提取的是纸质财务凭证的类别信息,类别信息一般为较易识别的信息,可以是二维码或条形码,更多地可以和颜色相结合,确保纸质财务凭证的类别信息识别读取准确率较高,不会出错。在确定纸质财务凭证的类别信息后,根据纸质财务凭证的类别,调取预设的每一个类别对应的金额信息提取的范围,就可以快速对金额信息进行图像特征信息提取,金额信息在本方案中提供卷积神经网络进行识别,将图像信息转换为具体的金额数据进行存储。更多地,本方案还设计了验证信息,验证信息一般用于对纸质财务凭证的防伪识别,验证信息可以是防伪码或者防伪水印,在确保纸质财务凭证真伪的同时还可以对纸质财务凭证的类别信息的识别进行验证是否识别正确。综上所述,本方案对于财务凭证存储记录不仅仅是做到了图像的存储,而且对于财务凭证的数据进行了数据化的存储,节约了人工成本,且减少了人工记录的误差,同时对于验证信息的识别进一步提高了识别的准确率。
由于纸质财务凭证的金额信息可能是人工填写或者是打印的数据,人工填写会由于每个人的字迹不一造成数值的大小形状不统一,而打印的数据则会产生打印深浅不一的问题,这些都会导致卷积神经网路对金额信息的图像特征信息提取发生错误的情况。因此,本方案中,对于金额信息的图像特征信息提取设置了纠错分析步骤,将待识别数值的图像区域分解成若干块子图像区域,对于任意一块子图像区域如果与对应的子数值信息相匹配,那么可以认为子数值信息对应的数值信息确定为待识别数值的数值信息,此设计优化了对于金额信息的图像特征信息提取的能力。
纠错分析步骤还包括:
若该子图像区域内待识别子数值与其中至少两个子数值信息的置信度大于等于设定的子置信度阈值,则将这些子数值信息对应的数值信息作为候选数值信息,且对待识别数值的其他子图像区域进行置信度分析,若其他任意一个子图像区域内待识别子数值与某一个子数值信息的置信度大于等于设定的子置信度阈值,同时该子图像区域内待识别子数值与其他的子数值信息的置信度小于设定的子置信度设定阈值,且该子数值信息对应的数值信息与候选数值信息中某一个数值信息相同,则该子数值信息对应的数值信息即为待识别数值的数值信息。
若分解成若干块子图像区域,对于某一个子图像区域,与至少两个子数值信息的置信度大于等于设定的子置信度阈值,例如阿拉伯数字6或8的下半部分作为子图像区域时,6或8作为子数值信息的置信度均大于设定的子置信度阈值,此时,分析待识别数值的其他子图像区域的置信度,此时6或8其他子图像区域的置信度会相差较大,因此,本方案的设计进一步提升了对于金额信息的图像特征信息提取的能力。
所述的金额信息还包括中文大写数字信息,中文大写数字信息通过OCR进行识别,识别完成后将中文大写数字信息对应的数值和阿拉伯数字信息对应的数值相比较,若两者数值相等,则判断阿拉伯数字信息和中文大写数字信息识别成功,若两者数值不相等,则执行修正步骤,确保金额信息识别成功。
纸质财务凭证上的金额信息有时通过人工手写完成,此时会出现中文大写数字和阿拉伯数字信息识别不一致的情况,因此,本方案中巧妙的利用了财务凭证上包含的阿拉伯数字信息和中文大写数字信息判断卷积神经网络特征识别是否出现错误,对阿拉伯数字信息和中文大写数字信息进行匹配,可以将不一致的数值修正成一致的数值。
所述的修正步骤具体为:在中文大写数字信息中寻找置信度大于设定的中文大写数字阈值的可能匹配结果,在阿拉伯数字信息中寻找置信度大于设定的阿拉伯数字阈值的可能匹配结果,若在可能匹配结果中对应的数值相等,则将不相等的数值修正成相等的数值。
财务凭证信息自动识别方法还包括对卷积神经网络进行优化的方法,在初始的卷积神经网络中,每一个数值对应一个初始图像数量,在进行若干次的卷积神经网络训练后,每一个数值对应的图像数量也会存在若干个,将任意一个数值的所有图像与预初始图像进行相似度比较,选取相似度小于等于设定的阈值的图像,将这些图像作为候选图像保留,然后将所有候选图像两两比较相似度,若任意两个候选图像之间的相似度小于设定值,则将这两个候选图像之间与初始图像之间相似度较低的进行保留、相似度较高的舍弃,若任意两个候选图像之间的相似度大于等于设定值,则两个候选图像均保留;所有保留的候选图像和初始图像均保留作为该数值对应的图像。
本设计对卷积神经网络进行优化训练,尽可能的保留了对于同一个数值可能出现的图像,这些图像之间互相有差异但是都可以认为是该数值对应的图像,此设计能提高卷积神经网络的识别效率,也进一步确保了对于纸质财务凭证的金额信息的识别正确率。
本发明的纸质财务凭证图如图2所示,该财务凭证为某电力公司模拟电费发票,在本实施例中,发票代码即为纸质财务凭证的类别信息,可以根据发票代码确定纸质财务凭证的类别,对于纸质财务凭证的金额信息,由于预先设定了该电费发票的模板,因此可以获取金额信息提取的范围,提取的范围包括阿拉伯数字的金额和中文大写数字金额,阿拉伯数字金额包括用户的户号、起止的电表读数、实际的电量、电价和电费等,中文大写数字金额包括合计人民币(大写)的表格中的信息,电费既可以简单获取总的金额数,又可以获取每一个分类的电费和总的电费,若获取每一个分类的金额数,则可以对分类的金额数进行相加等计算和总的金额数进行验算匹配,进一步提高识别的可靠性。
本实施例中所展示的模拟电费发票的为打印出的数据,虽然较为规整但是仍然会出现字迹不清的情况,例如,在打印过程中会出现某些部分较淡无法识别,或者在长时间存放后打印的字迹也会出现部分变浅的现象。因此,本方案考虑了对金额信息进行优化识别读取,大大提升了了金额信息读取的准确性和有效性。另外,除本实施例暂时的模拟电费发票外,还存在着手写的电费发票,由于手写的笔迹每个人均不相同,而传统的对手写的笔迹的识别方法需要对卷积神经网络进行大量的训练,效率较低,而通过本发明的方法可以较快的对手写的数字信息进行识别,识别的正确率也较高。
实施例2:一种财务凭证信息自动识别方法,其原理和实施方法和实施例1基本相同,不同之处在于:所述的若干块子图像区域的大小均相等,若干块子图像区域将图像区域进行横向等分或纵向等分;所述的纠错分析子步骤具体为:
子步骤a,对于单个子图像区域,寻找每一个数值信息中与单个子图像区域大小相等的且置信度最高的第一区域,记录该第一区域及其置信度,所有数值信息对应的置信度中,确定最高的置信度,最高的置信度对应的数值信息为候选数值信息;
子步骤b,选取单个子图像区域相邻的子图像区域,寻找候选数值信息中与相邻的子图像区域大小相等且置信度最高的第二区域,记录该第二区域;
子步骤c,比较第一区域和第二区域,若第一区域和第二区域相邻或第一区域和第二区域之间的距离小于设定的误差值或第一区域和第二区域之间重叠的区域的面积小于设定的面积值,则判断候选数值信息为最终数值信息,待识别数值的数值信息确定为最终数值信息对应的识别数值;其他情况下,跳转至子步骤d,
子步骤d,删除最高的置信度对应的数值信息,重复执行子步骤a至子步骤c,直到确定待识别数值对应的识别数值为止。所述的子步骤d最多执行两次,若在执行两次子步骤d后未确定最终数值信息,则判断待识别数值识别失败。
手写的金额信息会由于不同人手写差别较大,所以在对金额信息的图像特征信息提取的过程中,若用将待识别数值的图像区域分解成若干块子图像区域,同时卷积神经网络预训练的数值信息也对应分解成若干块子数值信息,子图像区域和子数值信息确定置信度的方法,有可能会无法识别出手写信息,因此,本方案中卷积神经网络预训练的数值信息不再是简单的分解成若干块子数值信息,而是将子图像区域在卷积神经网络预训练的数值信息中遍历匹配,得出最优匹配结果,这样首先确保了手写的金额信息能进行尽可能的最优匹配,然后将该子图像区域相邻的子图像区域与卷积神经网络预训练的数值信息进行匹配,第一区域和第二区域之间可能会不相邻或者可能会有重叠区域,但是只要第一区域和第二区域相邻或第一区域和第二区域之间的距离小于设定的误差值或第一区域和第二区域之间重叠的区域的面积小于设定的面积值,就认为是匹配成功。
以上所述的实施例只是本发明的一种较佳的方案,并非对本发明作任何形式上的限制,在不超出权利要求所记载的技术方案的前提下还有其它的变体及改型。
- 一种财务凭证信息自动识别方法
- 一种财务凭证归档及处理信息提示系统