计算机视觉系统
文献发布时间:2023-06-19 12:07:15
本申请要求2018年8月29日提交的美国临时专利申请第62/724,446号的权益并且该申请通过引用整体结合于此。
技术领域
本公开总的来说涉及计算机系统领域,并且更具体地涉及用于在计算机视觉应用中使用的散列表。
背景技术
计算机视觉和图形的世界正随着增强现实(AR)、虚拟现实(VR)和混合现实(MR)产品的出现而快速收敛,所述产品诸如来自MagicLeap
附图说明
当结合以下附图考虑时,参考本公开主题的以下详细描述,可以更全面地理解所公开的主题的各种目标、特征和优点,其中相同的参考号标识相同的要素。附图是示意性地并且不旨在按比例绘制。为了清楚起见,并非每一个部件在每一个图中都被标记。在不需要图示来允许本领域普通技术人员理解所公开的主题的情况下,也不是所公开的主题的每一个实施例的每一个部件都被示出。
图1示出了常规的增强现实或混合现实渲染系统;
图2示出了根据一些实施例的基于体素(voxel)的增强现实或混合现实渲染系统;
图3示出了根据一些实施例的密集和稀疏体积表示之间的差异;
图4示出了根据一些实施例的场景的复合视图;
图5示出了根据一些实施例的示例元素树结构中的细节级别;
图6示出了根据一些实施例的可以利用本申请的数据结构和体素数据的应用;
图7示出了根据一些实施例的用于识别3D数字的示例网络;
图8示出了根据一些实施例的使用隐式细节级别在相同的数据结构上执行的多个分类;
图9示出了根据一些实施例的由2D卷积神经网络进行的操作消除;
图10示出了根据一些实施例的来自示例测试图像的分析的实验结果;
图11示出了根据一些实施例的用于剔除操作的硬件;
图12示出了根据一些实施例的对用于剔除操作的硬件的改进;
图13示出了根据一些实施例的硬件;
图14示出了根据一些实施例的采用计算机视觉子系统的示例系统;
图15示出了根据一些实施例的使用分层体积数据结构的光线投射;
图16A-图16C示出了示例光线投射算法期间的光线遍历的示例;
图17A-图17B示出了使用不同的光线投射技术渲染的示例比较图像;
图18是示出示例视觉处理单元(VPU)的架构的简化框图;
图19是示出了光线投射技术的示例结果的比较的示例图;
图20A-图20B是示出了不同的光线投射技术的示例性能特性的比较的示例图;
图21A-图21C是示出示例神经网络模型的简化框图;
图22是示出视觉惯性测程技术的示例性能的曲线图;
图23A是传统的相对姿势估计技术的简化框图;
图23B是利用神经网络模型的改进的相对姿势估计技术的简化框图;
图24是示出示例神经网络模型的简化框图;
图25示出了示例点云的体素化;
图26A-图26C是示出用于增强计算机视觉处理的示例技术的流程图;
图27描绘了根据一些实施例的示例多时隙向量处理器;
图28示出了根据一些实施例的示例体积加速硬件;
图29示出了根据一些实施例的体素立方体的组织;
图30示出了根据一些实施例的两级稀疏体素树;
图31示出了根据一些实施例的两级稀疏体素树;
图32示出了根据一些实施例的示例体素数据的存储;
图33示出了根据一些实施例的体素向示例体积数据结构中的插入;
图34示出了根据一些实施例的示例3D体积对象的投影;
图35示出了涉及示例体积数据结构的示例操作;
图36示出了根据一些实施例的使用投影来生成简化地图;
图37示出了根据一些实施例的来自嵌入式设备的示例体积3D测量结果和/或简单2D测量结果的示例聚合;
图38示出了根据一些实施例的在2D 2×2位图上的2D路径找寻的示例加速;
图39示出了根据一些实施例的使用示例体积数据结构的碰撞检测的示例加速;
图40是根据至少一些实施例的具有设备的示例性网络的简化框图;
图41是根据至少一些实施例的示例性雾或云计算网络的简化框图;
图42是根据至少一些实施例的包括示例设备的系统的简化框图;
图43是根据至少一些实施例的示例处理设备的简化框图;
图44是根据至少一些实施例的示例性处理器的框图;以及
图45是根据至少一些实施例的示例性计算系统的框图。
具体实施方式
在以下描述中,阐述了与所公开的主题的系统和方法以及此类系统和方法可以操作的环境等相关的许多具体细节等等,以便提供对所公开的主题的透彻理解。然而,对于本领域技术人员将是显而易见的是,可以在没有这些具体细节的情况下实践所公开的主题,并且不详细描述在本领域中是众所周知的某些特征,以便避免复杂化所公开的主题。此外,应当理解,下文所提供的实施例是示例性的,并且构想了在所公开的主题的范围内存在其他的系统和方法。
各种技术基于增强现实、虚拟现实、混合现实、自主设备和机器人出现并包含它们,这可利用表示三维空间和几何形状的体积的数据模型。使用此类3D或体积数据的各种真实环境和虚拟环境的描述在传统上具有大数据集,某些计算系统一直难以以期望的方式处理所述大数据集。此外,当诸如无人机、可穿戴设备、虚拟现实系统等的设备变得更小时,此类设备的存储器和处理资源也可能受到限制。作为示例,AR/VR/MR应用可能对使用支持硬件生成的图形表示要求高帧率。然而,在一些应用中,此类硬件的GPU和计算机视觉子系统可能需要以高速率(诸如高达130fps(7毫秒))处理数据(例如,3D数据),以便产生期望的结果(例如,生成具有产生可信的结果的帧率的可信的图形场景、防止由于过长等待时间引起的用户的晕动病(motion sickness)、以及其他示例目标)。可以类似地挑战额外的应用以令人满意地处理描述大体积的数据,同时满足相对应的系统的处理、存储器、功率、应用要求中的限制,以及其他示例问题。
在一些实现方式中,可以为计算系统提供逻辑以生成和/或使用根据格式定义的稀疏体积数据。例如,可以提供定义的体积数据结构以在各种系统和应用中统一计算机视觉和3D渲染。可以使用光学传感器捕获对象的体积表示,光学传感器诸如例如立体相机或深度相机。对象的体积表示可以包括多个体素。可以定义改进的体积数据结构,该改进的体积数据结构使得相对应的体积表示能够被递归地细分以获取对象的目标分辨率。在细分期间,可以从体积表示(和支持操作)中剔除体积表示中的空白空间,该空白空间可以被包括在体素中的一个或多个体素中。空白空间可以是体积表示的不包括对象的几何属性的区域。
因此,在改进的体积数据结构中,相对应的体积内的各个体素可以被标记为(由存在于相对应的体积空间内的某种几何形状)“占用的”或“空白的”(表示相对应的体积由空白空间构成)。此类标签可以附加地被解释为指定其相对应的子体积中的一个或多个子体积也是占用的(例如,如果父体素或更高级别的体素被标记为占用的),或者其子体积中的全部都是空白空间(即,在父体素或更高级别的体素被标记为空白的情况下)。在一些实现方式中,将体素标记为空白可以允许该体素和/或其相对应的子体积体素从用于生成相对应的体积表示的操作中被有效地移除。体积数据结构可以按照稀疏树结构,诸如按照稀疏六十四进制(sexaquaternary)树(SST)格式。进一步,此类稀疏体积数据结构的方法可以比传统地用于存储对象的体积表示的方法利用相对较少的存储空间。附加地,体积数据的压缩可以增加此类表示的传输可及性(viability)并且能够更快地处理此类表示,以及其他示例益处。
体积数据结构可以是硬件加速的以快速地允许对3D渲染器的更新,消除可能在分离的计算机视觉和图形系统中发生的延迟。此类延迟可导致等待时间,当在AR、VR、MR和其他应用中使用时,该等待时间可导致用户晕动病以及其他额外的缺点。快速测试体素在加速的数据结构中的几何属性的占用的能力允许了可以被实时更新的低等待时间AR、VR、MR或其他系统的构造。
在一些实施例中,体积数据结构的能力还可以提供帧内(intra-frame)警告。例如,在AR、VR、MR和其他应用中,当用户可能与成像的场景中的真实对象或合成对象碰撞时,或者在用于无人机或机器人的计算机视觉应用中,当此类设备可能与成像的场景中的真实对象或合成对象碰撞时,由体积数据结构提供的处理速度允许警告即将发生的碰撞。
本公开的实施例可以与在应用中(诸如机器人、用于增强现实和混合现实头戴设备的头戴式显示器以及电话和平板电脑)的体积数据的存储和处理相关。本公开的实施例将在一组体素内的每一个体积元素(例如,体素)以及可选地与该体素的几何形状相关的物理量表示为单个位。与一组64个体素相关的附加参数可以与体素相关联,诸如相对应的红绿蓝(RGB)或其他着色编码、透明度、截断符号距离函数(truncated signed distancefunction,TSDF)信息等,并且被存储在相关联的且可选的64位数据结构中(例如,使得两个或更多位被用于表示每一个体素)。此类表示方案可以实现最小存储器要求。此外,通过单个位表示体素允许了许多简化计算的执行以在逻辑上或数学上组合来自体积表示的元素。组合来自体积表示的元素可以包括,例如对体积中的平面进行或运算(OR-ing)以创建3D体积数据的2D投影,并且通过对在2.5D歧管中占用的体素的数量进行计数来计算表面积等。为了比较,可以使用异或(XOR)逻辑以比较64位子体积(例如,4^3子体积),并且体积可以被反转,其中可以通过将对象一起进行或运算来将对象合并以创建混合对象,以及其他示例。
图1示出了常规的增强现实或混合现实系统,其由并行的图形渲染和计算机视觉子系统构成,其具有渲染后连接装置以计及由于快速头部运动引起的变化和环境中可能在所渲染的图形中产生遮挡和阴影的变化。在一个示例实现中,系统可以包括由主机存储器124支持的主机处理器100,以通过经由总线101的互连、芯片上片上网络(on-chip networkon-chip)或其他互连来控制图形流水线、计算机视觉流水线和渲染后校正装置的执行。该互连允许主机处理器100运行适当的软件以控制图形处理单元(GPU)106、相关联的图形存储器111、计算机视觉流水线116、以及相关联的计算机视觉存储器124的执行。在一个示例中,使用GPU 106经由OpenGL图形着色器107(例如,对三角形列表105操作)进行的图形的渲染可以以与计算机视觉流水线相比更慢的速率发生。结果,可以执行经由弯曲引擎108和显示/遮挡处理器109的渲染后校正,以计及自图形由GPU 106渲染以来、头部姿势和遮挡的场景几何形状中可能已经发生的变化。GPU 106的输出是带时间戳的,使得它可以结合分别来自头部姿势流水线120的校正控制信号121和来自遮挡流水线123的校正控制信号123来产生正确的图形输出,以计及在头部姿势119和遮挡几何形状113中的任何变化,以及其他示例中的任何变化。
与GPU 106并行的多个传感器和相机(例如,包括用于深度和视觉处理117的主动立体相机和被动立体相机)可以被连接到计算机视觉流水线116。计算机视觉流水线116可以包括至少三个阶段中的一个或多个阶段,所述阶段中的每一个阶段可以包含多个阶段的较低级别处理。在一个示例中,在计算机视觉流水线116中的阶段可以是图像信号处理(ISP)流水线118、头部姿势流水线120和遮挡流水线122。ISP流水线118可以采用输入相机传感器117的输出并对它们进行调节,使得它们可用于后续的头部姿势和遮挡处理。头部姿势流水线120可以采用ISP流水线118的输出并将它与头戴设备110中的惯性测量单元(IMU)的输出119一起使用,以计算自由GPU 106渲染的相对应的输出图形帧以来头部姿势的变化。头部姿势流水线(HPP)120的输出121可以与用户指定的网格一起应用到弯曲引擎108,以扭曲GPU输出102,使得它与更新的头部姿势位置119相匹配。遮挡流水线122可以采取头部姿势流水线121的输出并且在视野中寻找新的对象,诸如进入视野的手部113(或其他示例对象),该手部113(或其他示例对象)应当在场景几何形状上产生相对应的阴影114。遮挡流水线122的输出123可以由显示和遮挡处理器109用于将视野正确地覆盖在弯曲引擎108的输出103的顶部上。显示和遮挡处理器109使用计算的头部姿势119产生用于合成阴影114的阴影掩模,并且显示和遮挡处理器109可以在阴影掩模的顶部上合成手部113的遮挡几何形状,以在弯曲引擎108的输出103的顶部上产生图形阴影114,并且产生用于在增强/混合现实头戴设备110上显示的(多个)最终输出帧104,以及其他示例用例和特征。
图2示出了根据本公开的一些实施例的基于体素的增强现实或混合现实渲染系统。在图2中描绘的装置可以包括主机系统,该主机系统组成在主机CPU 200和相关联的主机存储器201上。此类系统可以经由总线204、片上网络或其他通信机制来与统一的计算机视觉和图形流水线223和相关联的统一的计算机视觉和图形存储器213进行通信,并且相关联的统一的计算机视觉和图形存储器213包含要在最终场景中渲染的、用于在头戴式增强现实或混合现实显示器211上显示的真实体素和合成体素。AR/MR显示器211还可以包含多个主动和被动图像传感器214,以及惯性测量单元(IMU)212,该惯性测量单元(IMU)212用于测量头部姿势222定向的变化。
在组合的渲染流水线中,可以从三角形列表204开始生成合成几何形状,该三角形列表204由OpenGL JiT(即时,Just-in-Time)翻译器205处理以产生合成体素几何形状202。例如,可以通过选择来自三角形列表的三角形的主平面来生成合成体素几何形状。随后可以对在所选择的平面中的每一个三角形执行2D光栅化(例如,在X和Z方向上)。可以创建第三坐标(例如,Y)作为要跨三角形插值的属性。光栅化的三角形的每一个像素可以导致相对应的体素的定义。该处理可以由CPU或GPU执行。当由GPU执行时,每一个光栅化的三角形可以从GPU读回以在GPU绘制像素的地方创建体素,以及其他示例实现方式。例如,可以使用列表的2D缓冲器来生成合成体素,其中列表中的每一个条目都存储在该像素处渲染的多边形的深度信息。例如,可以使用正交视点(例如,自上而下)来渲染模型。例如,在示例缓冲器中提供的每一个(x,y)都可以表示在相对应的体素体积中的(x,y)处的列(例如,从(x,y,0)到(x,y,4095))。随后可以使用每一个列表中的信息来将每一个列从信息渲染为3D扫描线。
继续图2的示例,在一些实现方式中,合成体素几何形状202可以与使用同步定位和地图构建(SLAM)流水线217构造的测量的几何形状体素227相结合。SLAM流水线可以使用主动传感器和/或被动图像传感器214(例如,214.1和214.2),该主动传感器和/或被动图像传感器214首先使用图像信号处理(ISP)流水线215进行处理以产生输出225,该输出225可以由深度流水线216转换为深度图像226。主动或被动图像传感器214(214.1和214.2)可以包括主动或被动立体传感器、结构光传感器、飞行时间传感器、以及其他示例。例如,深度流水线216可以处理来自结构光或飞行时间传感器214.1或替代地来自被动立体传感器214.2的深度数据。在一个示例实现方式中,立体传感器214.2可以包括一对被动的立体传感器,以及其他示例实现方式。
由深度流水线215生成的深度图像可以由密集SLAM流水线217使用SLAM算法(例如,体感融合(Kinect Fusion))处理,以产生测量的几何形状体素227的体素化模型。可以提供光线追踪加速器206,其可以将测量的几何形状体素227(例如,真实体素几何形状)与合成体素几何形状202相结合以产生场景的2D渲染,用于经由显示处理器210输出到显示设备(例如,VR或AR应用中的头戴式显示器211)。在此类实现方式中,可以从测量的几何形状体素227的真实体素和合成几何形状202构造完整的场景模型。因此,不要求对2D渲染的几何形状进行弯曲(例如,如在图1中)。此类实现方式可以与头部姿势跟踪传感器和相对应的逻辑相结合以正确地对准真实几何形状和测量的几何形状。例如,示例头部姿势流水线221可以处理来自安装在头戴式显示器212中的IMU 212的头部姿势测量结果232,并且在经由显示处理器210渲染期间,可以考虑头部姿势测量结果流水线的输出231。
在一些示例中,统一的渲染流水线还可以使用测量的几何形状体素227(例如,真实体素模型)和合成几何形状202(例如,合成体素模型),以便对音频混响模型进行渲染和对真实世界场景、虚拟现实场景或混合现实场景的物理进行建模。作为示例,物理流水线218可以采用测量的几何形状体素227和合成几何形状202体素几何形状,并且使用光线投射加速器206来计算用于头戴式显示器(HMD)211中的左耳机和右耳机的输出音频样本,以使用内置于体素数据结构中的声反射系数计算输出样本230。类似地,由202和227构成的统一的体素模型还可以用于确定用于在复合AR/MR场景中的合成对象的物理更新。物理流水线218采取复合场景几何形状作为输入,并且在对合成几何形状202计算更新228以用于渲染并且作为物理模型的未来迭代的基础之前,使用光线投射加速器206来计算碰撞。
在一些实现方式中,系统(诸如图2中所示的系统)可以附加地被设有一个或多个硬件加速器,以实现和/或利用卷积神经网络(CNN),该卷积神经网络(CNN)可以处理来自ISP流水线215的输出的RGB视频/图像输入、来自SLAM流水线217的输出的体积场景数据、以及其他示例。神经网络分类器可以排他地使用硬件(HW)卷积神经网络(CNN)加速器207运行或在处理器和HW CNN加速器207的组合中运行以产生输出分类237。HW CNN加速器207进行体积表示上的推理的可用性可以允许将测量的几何形状体素227中的体素组标记为属于特定对象类别,以及其他示例使用。
标记体素(例如,使用CNN并支持硬件加速)可以允许那些体素所属的那些对象可以被系统识别为与已知对象相对应,并且可以将源体素从测量的几何形状体素227中移除并由与对象相对应的边界框替代和/或由与对象的来源、对象的姿势、对象描述符相关的信息以及其他示例信息替代。这可以导致场景的语义上远远更有意义的描述,该描述例如可以被用作输入,由机器人、无人机或其他计算系统用来与场景中的对象互动,或由音频系统用来查找场景中的对象的吸声系数并将它们反映在场景的声学模型中,以及其他示例使用。
一个或多个处理器设备和硬件加速器可以被提供用于实现在图2中示出并描述的示例系统的流水线。在一些实现方式中,组合的渲染流水线的硬件元素和软件元素中的全部可以共享对DRAM控制器209的访问,该DRAM控制器209进而允许数据被存储在共享的DDR存储器设备208中,以及其他示例实现方式。
呈现图3以说明根据一些实施例的、密集体积表示与稀疏体积表示之间的差异。如图3的示例所示的,可以以如302中所示的密集方式或以如304中所示的稀疏方式的体素的形式来描述真实世界对象或合成对象300(例如,兔子的雕像)。诸如302的密集表示的优点是对体积中的所有体素的均匀速度的访问,但缺点是可能需要的存储量。例如,对于诸如512^3元素体积(例如,与使用体感(Kinect)传感器以1cm分辨率扫描的体积中的5m相对应)的密集表示,对每一个体素利用4字节截断符号距离函数(TSDF)以存储相对小的体积需要512兆字节。八叉树表示304体现了稀疏表示,在另一方面,八叉树表示304可以仅存储在现实世界场景中具有实际几何形状的那些体素,由此减少存储相同体积所需的数据量。
转到图4,示出了根据一些实施例的示例场景的复合视图。具体地,图4示出了场景404的复合视图可以如何使用并行数据结构被保持、显示或使用并行数据结构经受进一步处理以分别表示在用于合成体素数据的等效边界框400内的合成体素401和用于现实世界体素数据的等效边界框402内的现实世界测量的体素403。图5示出了根据一些实施例的均匀4^3元素树结构中的细节级别。在一些实现方式中,可以利用少至1个位来描述使用八叉树表示的体积中的每一个体素,诸如在图5的示例中所表示的。然而,基于八叉树的技术的缺点可以是访问八叉树中的特定体素所利用的间接存储器访问的数量。在稀疏体素八叉树的情况下,相同的几何形状可以以多个细节级别隐式地表示,有利地允许了诸如光线投射、游戏物理、CNN和其他技术的操作,以允许从进一步计算中剔除场景的空白部分,这导致不仅所需的存储整体降低,而且在功耗和计算负荷方面整体降低,以及其他示例优点。
在一个实现方式中,改进的体素描述符(在本文中也被称作“体积数据结构”)可以被提供用于将体积信息组织成4^3(或64位)无符号整数,诸如在具有每体素1个位的存储器要求的501中所示的。在该示例中,(与利用64位的SLAMbench/KFusion中的TSDF相比)每体素1个位不足以存储截断符号距离函数值。在本示例中,附加(例如,64位)字段500可以被包括在体素描述符中。该示例可以被进一步增强,使得当在64位字段500中的TSDF是16位时,可以在体素描述符501中隐式地提供x、y和z中附加的2位小数分辨率,以使64位字段500中的体素TSDF和体素位置501的组合等效于分辨率高得多的TSDF,诸如在SLAMbench/KFusion或其他示例中所使用的。例如,64位字段500(体素描述符)中的附加数据可以被用于存储每项1字节的二次采样的RGB颜色信息(例如,来自经由被动RGB传感器的场景)和8位透明度值阿尔法、以及可以是特定应用的并且可以用于存储例如用于音频应用的声学反射率、用于物理应用的刚度、对象材料类型、以及其他示例的两个1字节保留字段R1和R2。
如图5所示,体素描述符501可以被逻辑地分组为四个2D平面,所述2D平面中的每一个包括16个体素502。如图5所表示的,这些2D平面(或体素平面)可以基于4的升幂的连续分解来描述八叉树类型结构的每一个级别。在该示例实现方式中,选择64位体素描述符是因为它与相对应的系统实现方式中使用的64位总线基础设施有很好的匹配(尽管可以在其他系统实现方式中提供其他体素描述符大小和格式,并根据总线或系统的其他基础设施来设计大小)。在一些实现方式中,可以设计体素描述符的大小以降低用于获取体素的存储器访问的数量。例如,与对2^3元素操作的传统八叉树相比,64位体素描述符可以用于将访问八叉树中任意级别处的体素所必需的存储器访问的数量减少1/2,以及其他示例考虑和实现方式。
在一个示例中,可从4^3根体积503开始描述八叉树,并且在示例256^3体积中描绘了其中用于呈现在下面的层504、505和506中的几何形状的编码的每一个非零条目。在该特定示例中,可以使用四个存储器访问以便访问八叉树中的最低层。在此类开销过高的情况下,可采用替代方式来将八叉树的最高级别编码为更大的体积,诸如64^3,如507中所示。在该情况下,507中的每一个非零条目可以指示在下面的256^3体积508中的下面的4^3八叉树的存在。与503、504和505中所示的替代等式相比,该替代组织的结果是仅需要两次存储器访问以访问256^3体积508中的任何体素。在主控该八叉树的设备具有较大量的嵌入式存储器、从而允许体素八叉树508的仅较低和较少频率访问的部分在外部存储器中的情况下,后一种方法是有利的。该方法在存储方面成本更高,例如,在充满的、较大的(例如,64^3)体积被存储在片上存储器中的情况下,但是该折衷可以允许较快的存储器访问(例如,2倍速度)和低得多的功耗,以及其他示例优点。
转到图6,示出了根据一些实施例的示出可以利用本应用的数据结构和体素数据的示例应用的框图。在一个示例中,诸如图5中所示的,可以通过示例体素描述符500提供附加的信息。在体素描述符可以将利用的整体存储器增加到每体素2个位时,体素描述符可以实现大范围的应用,这些应用可以利用体素数据,诸如图6中所表示的体素数据。例如,(诸如使用密集SLAM系统601(例如,SLAMbench)生成的)共享体积表示602可以被用于使用图形光线投射或光线追踪603渲染场景、可以被用于音频光线投射604、以及其他实现方式。在又其他示例中,体积表示602还可以在卷积神经网络(CNN)推理605中使用,并且可以通过云基础设施607备份。在一些实例中,云基础设施607可以包含可以经由推理访问的对象(诸如树、一件家具或其他对象(例如,606))的详细体积描述符。基于推理或以其他方式标识对象,相对应的详细描述符可以被返回到设备,允许由具有姿势信息和包含对象属性的描述符以及其他示例特征的边界框表示来替换体积表示602的体素。
在又其他实施例中,在一些系统中可以附加地或替代地利用上文所讨论的体素模型,使用3D到2D投影从体积表示602来构造示例环境的2D地图608。这些2D地图可以经由通信机器经由云基础设施和/或其他基于网络的资源607被再次分享并(例如,使用相同的云基础设施)聚合以使用众包(crowd-sourced)技术构建更高质量的地图。这些地图可以由云基础设施607分享到连接的机器和设备。在又进一步示例中,可以使用投影随后通过逐段简化609(例如,假设交通工具或机器人的宽度和高度固定)来针对超低带宽应用优化2D地图。简化路径随后可以在路径的每逐段线性段仅具有单个X、Y坐标对,从而降低了将交通工具609的路径传送到云基础设施607并且聚合在该相同的云基础设施607中以使用众包技术构建更高质量的地图所需的带宽量。这些地图可以由云基础设施607分享到连接的机器和设备。
为了实现这些不同的应用,在一些实现方式中,可以提供共用功能,诸如通过共享软件库,在一些实施例中可以使用硬件加速器或处理器指令集架构(ISA)扩展来加速该共享软件库,以及其他示例。例如,此类功能可以包括将体素插入到描述符中、删除体素或查找体素610。在一些实现方式中,还可以支持碰撞检测功能620,以及从体积630删除点/体素,以及其他示例。如上文所介绍的,可以向系统提供从相对应的体积表示602(3D体积)(例如,其可用作路径或碰撞确定的基础)快速生成X方向、Y方向和Z方向上的2D投影640的功能。在一些情况下,能够使用直方图金字塔650从体积表示602生成三角形列表也可以是有利的。进一步,可以向系统提供用于快速确定体积空间602的2D和3D表示中的自由路径660的功能。此类功能在一系列应用中可能是有用的。可以提供进一步功能,诸如阐述体积中的体素数量、使用群体计数器以对体积表示602的掩模区域中的值为1的位的数量进行计数来确定对象的表面、以及其他示例。
转到图7的简化框图,示出了根据至少一些实施例的示例网络,其包括配备有识别3D数字的功能的系统。例如,图6中所示的应用中的一个是体积CNN应用605,其在图7中被更详细地描述,其中示例网络被用于识别从数据集(诸如混合的国家标准与技术研究院(MNIST)数据集)生成的3D数字700。通过在训练基于CNN的卷积网络分类器710之前对此类数据集中的数字在X、Y和Z上施加适当的旋转和平移,可以将该数字用于该训练。当用于在嵌入式设备中的推理时,即使在数字经受在X、Y和Z上的旋转和平移的情况下,经训练的网络710也可以用于以高准确度对场景中的3D数字进行分类720,以及其他示例。在一些实现方式中,可以由图2所示的HW CNN加速器207加速CNN分类器的操作。随着神经网络的第一层使用体积表示602中的体素执行乘法运算,由于乘以零始终等于零并且数据值A乘以1(体素)等于A,因此可以跳过这些算术运算。
图8示出了使用隐式细节级别在相同的数据结构上执行的多个分类。使用体积表示602的CNN分类的进一步改进可以是,因为八叉树表示在如图5中所示的八叉树结构中隐式地包含多个细节级别,所以诸如图8中所示的,可以使用单个分类器830或并行的多个分类器以并行使用隐式细节级别800、810和820来在相同数据结构上执行多个分类。在传统的系统中,由于分类通过之间所需的图像缩放,可比较的并行分类可能是缓慢的。因为相同的八叉树可以在多个细节级别包含相同的信息,所以在应用本文所讨论的体素结构的实现方式中,此类缩放可以被放弃。实际上,基于体积模型的单个训练数据集可以覆盖所有的细节级别,而不是诸如在常规CNN网络中所需的缩放的训练数据集。
转到图9的示例,根据一些实施例,示例操作消除由2D CNN示出。诸如图9中所示的,操作消除可以用于3D体积CNN以及2D CNN。例如,在图9中,在第一层中,位图掩模900可以被用于描述输入910的预期“形状”,并且可以被应用于传入的视频流920。在一个示例中,操作消除不仅可以用于3D体积CNN,而且可以用于2D体积CNN。例如,在图9的示例的2D CNN中,位图掩模900可以被应用于CNN的第一层以描述输入910的预期“形状”,并且可以应用于CNN的输入数据,诸如传入的视频流820。作为示例,图9中示出了将位图掩模应用于行人的图像用于在CNN网络中的训练或推理的效果,其中901表示行人901的原始图像,而903表示应用了位图掩模的相对应的版本。类似地,902中示出了不包含行人的图像以及904中示出了相对应的位图掩模版本。可以将相同的方法应用于任何类型的2D或3D对象,以便通过由检测器所预期的预期的2D或3D几何形状的知识来减少CNN训练或推理所需的操作数量。911中示出了3D体积位图的示例。920中示出了用于在真实场景中推理的2D位图的使用。
在图9的示例实现方式中,(在900处)示出了概念位图,而真实位图通过对针对特定类别的对象910的一系列的训练图像求平均而生成。所示的示例是二维的,然而类似的位图掩模还可以被生成用于所提出的具有每体素1个位的体积数据格式中的3D对象。实际上,该方法还可以潜在地被扩展以使用每一个体素/像素附加的位来指定预期的颜色范围或者2D或3D对象的其他特性,以及其他示例实现方式。
图10是示出根据一些实施例的、涉及10,000CIFAR-10测试图像的分析的示例实验的结果的表。在一些实现方式中,操作消除可以用于消除由于在CNN网络(诸如图10中所示的LeNet 1000)中频繁的整流线性单元(ReLU)操作而引起的在1D、2D和3D CNN中的中间计算。如图10中所示的,在使用10,000CIFAR-10测试图像的实验中,由ReLU单元生成的依赖数据的零值的百分比可以高达85%,这意味着在零值的情况下,可以提供一种系统,该系统识别零值并且作为响应,不获取相对应的数据并执行相对应的乘法运算。在该示例中,该85%表示从修改的国家标准与技术研究院数据库(MNIST)测试数据集生成的ReLU动态零值的百分比。与这些零值相对应的相对应操作消除可以用于减少功耗和存储器带宽要求,以及其他示例益处。
可以基于位图剔除不重要的操作。例如,此类位图的使用可以根据在题为“Circuit for compressing data and a processor employing the same(用于压缩数据的电路和采用该电路的处理器)”的美国专利第8,713,080号中所讨论和示出的原理和实施例,其内容通过引用整体结合于此。一些实现方式可以提供能够使用此类位图的硬件,诸如在题为“Hardware for performing arithmetic operations(用于执行算术操作的硬件)”的美国专利第9,104,633号中所讨论和示出的系统、电路系统和其他实现方式,其内容也通过引用整体结合于此。
图11示出了根据一些实施例的可以被合并到系统中以提供用于基于位图剔除不重要的操作的功能的硬件。在该示例中,提供了多层神经网络,其包括重复的卷积层。该硬件可以包括一个或多个处理器、一个或多个微处理器、一个或多个电路、一个或多个计算机等。在该特定示例中,神经网络包括初始卷积处理层1100,之后是池化处理1110,以及最后是激活函数处理(诸如整流线性单元(ReLU)函数)1120。提供ReLU输出向量1131的ReLU单元1120的输出可以被连接到随后的卷积处理层1180(例如,可能经由延迟1132),该卷积处理层1180接收ReLU输出向量1131。在一个示例实现方式中,还可以与ReLU单元1120到随后的卷积单元1180的连接并行地生成ReLU位图1130,该ReLU位图1130表示在ReLU输出向量1131中的哪些元素是零值以及哪些元素是非零。
在一个实现方式中,可以生成或以其他方式提供位图(例如,1130)以通知启用的硬件消除涉及神经网络的计算的操作的机会。例如,ReLU位图1130中的位可以由位图调度器1160解释,在ReLU位图1130中存在相对应的二进制零的情况下,给定乘以零将总是产生零作为输出,该位图调度器1160指示随后的卷积单元1180中的乘法器跳过ReLU输出向量1131中的零值条目。并行地,还可以跳过从地址生成器1140对与ReLU位图1130中的零值相对应的数据/权重的存储器获取,这是由于在将被随后的卷积单元1180跳过的获取的权重中几乎没有值。如果经由DDR控制器1150从附接的DDR DRAM存储设备1170获取权重,则等待时间可能太高以至于仅可能节省一些片上带宽和相关功耗。另一方面,如果从片上RAM1180存储获取权重,则或许可能绕过/跳过整个权重获取操作,尤其是如果在对随后的卷积单元1180的输入处添加与RAM/DDR获取延迟1132相对应的延迟。
转到图12,呈现了根据一些实施例的简化框图以说明对配备有用于剔除不重要的操作(或执行操作消除)的电路系统和其他逻辑的示例硬件的改进。如图12的示例中所示的,可以提供附加的硬件逻辑以从前导最大池化(Max-Pooling)单元1210或卷积单元1200提前预测ReLU单元1220输入的符号。将符号预测和ReLU位图生成添加到最大池化单元1210可以允许从时序的视角较早地预测ReLU位图信息,以覆盖通过地址生成器1240、通过外部DDR控制器1250和DDR存储1270或内部RAM存储1271可能发生的延迟。如果延迟足够低,则可以在地址生成器1240中解释ReLU位图并且与ReLU位图零值相关联的存储器获取可以被完全跳过,因为可以确定永不使用从存储器获取的该结果。对图11的方案的该修改可以节省附加的功率,并且如果通过DDR访问路径(例如,1240到1250到1270)或RAM访问路径(例如,1240到1271)的延迟足够低,以便不保证延迟阶段1232,则还可以允许移除在到随后的卷积单元1280的输入处的延迟阶段(例如,1132、1232),以及其他示例特征和功能。
图13是说明根据一些实施例的示例硬件的另一个简化框图。例如,CNN ReLU层可以产生与负输入相对应的高数量的输出零值。实际上,负ReLU输入可以通过查看对先前层(例如,图13的示例中的池化层)的(多个)符号输入来预测性地确定。浮点和整数算术可以以最高有效位(MSB)的方式明确地标符号,使得跨卷积层中将要相乘的输入向量的简单的逐位异或(XOR)操作可以预测哪些乘法将产生输出零值,诸如图13中所示。得到的经预测符号的ReLU位图向量可以被用作用于确定要消除的乘法的子集和来自存储器相关联的系数读数的基础,诸如以上文的其他示例中所描述的方式。
提供用于将ReLU位图的生成返回到先前的池化或卷积阶段(即,相对应的ReLU阶段之前的阶段)可以导致附加的功率。例如,当乘法器将产生将最终被ReLU激活逻辑设置为零值的负输出时,符号预测逻辑可以被提供用于禁用乘法器。例如,在乘法器1314输入1301和1302的两个符号位1310和1315通过异或门逻辑地组合以形成前ReLU(PreReLU)位图位1303的情况下,示出了这一点。该相同的信号可以用于禁用乘法器1314的操作,否则其将不必要地消耗能量生成负输出,该负输出将在被输入用于下一卷积阶段1390中的乘法之前被ReLU逻辑设置为零值,以及其他示例。
注意,1300、1301、1302和1303(符号A)的表示示出了在图13中的用B标记的表示中所示的视图的更高级别视图。在该示例中,对块1302的输入可以包括两个浮点操作数。输入1301可以包括显式符号位1310、包括多个位的尾数(Mantissa)1311、以及同样包括多个位的指数1312。类似地,输入1302可以同样地包括符号1315、尾数1317和指数1316。在一些实现方式中,尾数和指数可以具有不同的精度,因为结果1303的符号分别仅取决于1301和1302、或1310和1315的符号。实际上,1301和1302都不需要是浮点数,但是只要它们是有符号数并且最高有效位(MSB)显式地或隐式地(例如,如果数字是反码或补码等)有效地是符号位,就可以是任何整数或固定点格式。
继续图13的示例,可以使用异或(XOR,有时在本文中替代地表示为ExOR或EXOR)门将两个符号输入1310和1315相结合以生成位图位1303,随后可以使用硬件处理该位图位1303以标识可以在下个卷积块(例如,1390)中省略的下游乘法。在两个输入数字1313(例如,与1301相对应)和1318(例如,与1302相对应)具有相反的符号并且将产生负输出1304(该负输出1304将被ReLU块1319设置为零值)、从而得到在RELU输出向量13191中要被输入到随后的卷积阶段1390的零值的情况下,相同的异或输出1303还可以用于禁用乘法器1314。因此,在一些实现方式中,PreReLU位图1320可以并行地被传输到位图调度器1360,该位图调度器1360可以调度乘法以在卷积单元1390上运行(和/或省略)。例如,对于在位图1320中的每一个零值,可以在卷积单元1390中跳过相对应的卷积操作。并行地,位图1320可以由示例地址生成器1330使用,该地址生成器1330控制用于在卷积单元1390中使用的权重的获取。与位图1320中的1值对应的地址列表可以在地址生成器1330中被编译,并且经由DDR控制器1350控制到DDR存储1370的路径,或控制到片上RAM 1380的路径。在任何一种情况下,可以获取并呈现与PreReLU位图1320中的1值相对应的权重(例如,在到权重输入1371的以时钟周期计的一些等待时间之后)到卷积块1390,同时与零值相对应的权重的获取可以被省略,以及其他示例。
如上所述,在一些实现方式中,延迟(例如,1361)可以介于位图调度器1360与卷积单元1390之间以平衡通过地址生成器1330、DDR控制器1350和DDR 1350的延迟、或通过地址生成器1330和内部RAM 1380的路径的延迟。该延迟可以使得由位图调度器驱动的卷积能够与相对应的权重在时间上正确地对齐以用于卷积单元1390中的卷积计算。实际上,从时序的视角看,比ReLU块1319的输出处更早地生成ReLU位图可以允许获得附加的时间,该附加的时间可以用于在地址生成器1330生成对存储器(例如,RAM 1380或DDR1370)的读取之前拦截它们,使得(例如,与零值相对应的)一些读数可以被放弃。因为存储器读取可以比芯片上的逻辑操作高得多,所以排除此类存储器获取可以导致非常显著的能量节省,以及其他示例优点。
在一些实现方式中,如果在时钟周期方面的节省仍不足以覆盖DRAM访问时间,则可以使用面向块的技术来提前从DDR中读取符号位(例如,1301)的组。这些符号位的组可以与来自输入图像或中间卷积层1302的符号块一起使用,以便使用一组(多个)异或门1300来生成PreReLU位图块(例如,以计算在2D或3D阵列/矩阵之间的2D或3D卷积中的符号位之间的差异,以及其他示例)。在此类实现方式中,可以在DDR或片上RAM中提供附加的1位存储用于存储每一个权重的符号,但是这可以允许以避免从DDR或RAM读取将被乘以来自ReLU阶段的零值的权重的方式覆盖许多周期的等待时间。在一些实现方式中,可以避免在DDR或片上RAM中的每权重附加的1位存储,因为符号以它们可以独立于指数和尾数可寻址的方式存储,以及其他示例考虑和实现方式。
在一个示例中,可以进一步增强系统以利用DDR访问,该DDR访问可以具有用于最大数据传输速率的自然突发访问。通过跳过各个DDR权重访问以节省能量在该内容中可能是不可行的,因为它们可能比突发更短。因此,在一些实例中,在与特定突发事务对应的所有位图位都是0的情况下,可以跳过突发。然而,这可能不频繁地发生并且因此,得到的功率和带宽节省可能是有限的。在又其他实现方式中,可以针对在突发中的位图位的数量设置寄存器可编程阈值,使得如果位图突发中超过N位是零值,则将完全跳过该突发。这可能具有稍微降级整体CNN分类准确率的效果,但是出于节省能量的考虑可能是可接受的。
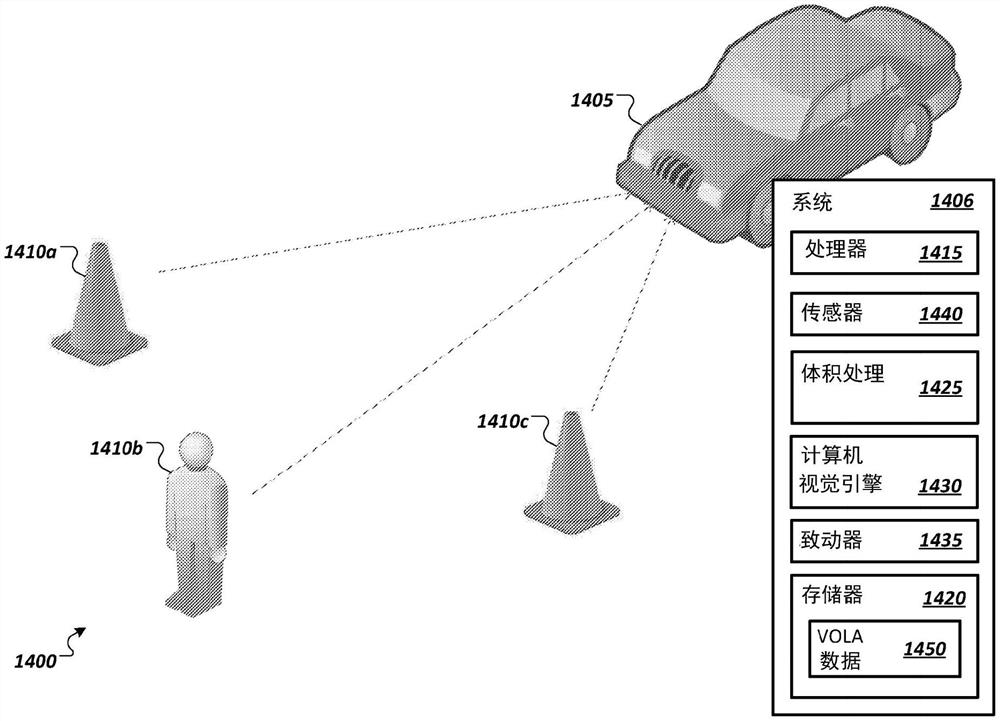
转向图14,示出了图示涉及对3D空间进行分析的机器1405的示例环境的简化框图1400。在一些实现方式中,该机器可以配备有实现在硬件和/或电路中的机器可执行逻辑,以利用体积数据在一个或各种应用或行动(诸如如本文所讨论的,SLAM程序、光线投射、测程、碰撞检测、2D或3D路径规划、以及其他示例)中描述3D空间。如本文所讨论的,体积数据可以被体现为稀疏树表示。在一些实例中,还可以或替代地通过权衡增加的存储器占用(例如,在散列表比密集阵列使用更少的存储器时)来将散列表用于执行体积数据的更快处理。
机器1405可包括本文所讨论的配置用于应对和处理表现在稀疏树体积数据结构中的体积数据的硬件和逻辑。在图14中所示的特定示例中,机器1405可被实现为自主或半自主机器,其能够处理描述3D场景的体积数据并利用该信息以基于该场景中存在的地形在场景中自主移动(例如,改变其在场景中的位置和/或改变一个或多个机器元件(例如,传感器、相机、指针、致动器、工具等)的定向(例如,瞄准))。通过这样做,该机器可以检测对象(例如,1410a-c)并基于所检测到的对象自主地在场景内导航或与场景互动。在一些实现方式中,机器1305可被体现为自主运载工具(用于运载乘客或货物)、空中无人机、陆基无人机或水基无人机、机器人、以及其他示例。
在一个示例实现方式中,机器1405可包括计算系统1406,该计算系统1406使用数据处理器1415(诸如一个或多个中央处理单元(CPU)、图形处理单元(GPU)、张量处理单元或其他矩阵算术处理器、硬件加速器(例如,体积处理加速器、机器学习加速器)、以及其他示例通用或专用处理硬件)来实现,并使用一个或多个存储器元件(例如,1420)来进一步实现。可以提供附加的逻辑块,其被实现在硬件电路系统、固件或软件中,诸如体积处理逻辑1425、计算机视觉引擎1430和致动器1435。在一些实现方式中,机器1405可以附加地包括一个或多个传感器(例如,1440)以测量3D空间(例如,激光雷达、飞行时间传感器、实感技术(realsense)传感器等)。此类传感器1440可用于生成描述3D环境的体积数据以开发体积的地图以及用于将使用传感器1440检测到的本地观察到的几何形状与描述预期或先前观察到的版本的体积的占用几何形状的参考数据进行比较。传感器数据可由计算机视觉引擎1430结合光线投射、测程、姿势估计或(例如,可实现为计算机视觉引擎1430的子模块的)其他功能来处理。在一些实例中,体积处理逻辑1425可具有用于执行一个或多个不同体积处理操作或任务(诸如与计算机视觉引擎1430的功能有关的任务)的逻辑。在一个示例中,可以利用体积加速单元(诸如本文所描述的体积加速单元(VXU))来实现体积处理逻辑1425和/或计算机视觉引擎1430的至少一部分。在一些实现方式中,可以将体积处理逻辑1425和计算机视觉引擎1430的全部或部分逻辑进行组合。体积处理逻辑可以将VOLA数据1450中实现的体积数据作为输入,并解析数据1450,以确定放弃对在数据1450中被识别为不被结构或几何形状占用的相关体积的某些部分的分析的机会。在一些实例中,通过体积处理逻辑1425和/或计算机视觉引擎生成的结果可以使机器1405的一个或多个致动器被触发,使得一个或多个马达、引擎或其他驱动器和/或一个或多个转向机制被激活,并且使机器本身或机器的特定工具根据其设计在体积内移动。例如,体积处理逻辑可为一个或多个致动器提供输入以使无人机或自主运载工具在机器通过对体积数据的处理所理解的体积进行自主导航。
在其应用中,例如,在机器人技术领域中,可利用同步的定位和地图构建(SLAM)应用来促进机器人和无人机在环境中的自主移动,以及其他示例。在一些情况下,SLAM可以利用离线生成的地图。但是,自主机器人通常需要实时构建地图并与之交互,并且使用有限的可用资源来做到这一点。计算密集型SLAM的大多数方法是为高性能台式机系统设计的,并且所需的FLOP、存储器和功率远远超过通常建议或可能集成在现代机器人和无人机中使用的低成本嵌入式设备上,特别是在考虑传统SLAM流水线中的计算密集型光线投射步骤时。为了解决该问题,可以在硬件和/或软件中实现光线投射算法的优化的低功率、低存储器实现,以集成在SLAM流水线中。例如,本文介绍的体积加速度数据结构(VOLA)可以用于3D体积表示,并且附加技术和特征可以利用VOLA的结构和用于实现改进的SLAM应用的架构来实现特定的性能/存储器效率。
尽管计算机视觉和图形的世界是分开的,但它们在机器人技术领域融合在一起。对于两种领域来说,以节省嵌入式系统中可用有限资源的方式在3D空间中表示体积数据是一个重大挑战。例如,用于计算机视觉的输入系统(诸如光检测和测距(LiDAR))可以生成环境的点云深度地图,该点云深度地图可能很快变得太大,以至于嵌入式系统存储器无法处理。构成问题的一个常见应用是SLAM应用,其目的是创建机器人周围环境的地图并且同时在其中定位机器人。在自主应用中,如果自主代理无法实时有效地与地图交互,则构建高度详细的地图将无用处。最重要的交互之一可能是碰撞检测,这在无人机应用中尤其重要(例如,出于显而易见的安全原因)。用于光线/几何形状相交的常用方法是光线投射,通常每秒需要进行大量操作。光线投射代表典型SLAM SW流水线中最昂贵的组件之一,并且因此尽管嵌入式平台有局限性,但仍需要提高其性能和效率,以使实时嵌入式SLAM成为可能。
在一些实现方式中,可以利用基于VOLA数据结构的使用、用于嵌入式平台的光线投射算法的改进的、轻量级的实现方式,该VOLA数据结构是专门为减少3D模型的存储器需求而设计的。例如,可以提供光线投射算法的嵌入式实现,特别是针对SLAM应用。实现此类算法可以改善对诸如高速缓存和SIMD指令之类的计算资源的利用以利用图像和对象空间的一致性,以及其他示例优点。可以利用密集或稀疏的分层网格数据结构(例如,基于VOLA的结构)来产生3D场景的体积压缩。此类解决方案还可以在保持足够的质量和准确性的同时提高功率效率。
如上所述,VOLA类型的数据结构可以被实现为紧凑的数据结构,该紧凑的数据结构被组织为分层的位阵列,该分层的位阵列允许有效地压缩体积数据以用于嵌入式设备,在该情况下,由于存储器限制,在此类设备中使用全点云是不现实甚至是不可能的。空间划分VOLA结构可以使用模块算法和应用于位阵列的位计数,将八叉树的分层结构与体积方法组合。与八叉树、kd树和其他3D表示相反,VOLA可能不使用基于指针的树结构,而是使用分层网格结构。由于压缩是主要考虑因素,因此VOLA仅对占用数据进行编码,从而实现每个体素1位的最大压缩,从而使其极为紧凑。因此,VOLA可能无法很好地适合于通过光线投射进行精确的体积渲染,但是在诸如SLAM之类的应用中却非常有效,在应用中,必须构建并光线投射周围的简单地图,并且在其中表现真实感不是必须或优先事项。在一些实现方式中,VOLA中的每个元素是64位整数,该64位整数将表示的体积划分为4x4x4个子单元,并使用模块算法将每个元素从一维位阵列映射到三个维度。如果一些点在单元内被占用,则将相对应的子单元位设置为1,否则设置为零。在下一级别中,仅表示占用的子单元,以便仅对占用的空间进行编码。这样,在VOLA结构中从较高级别传递到较低级别意味着分辨率提高了四倍,以及其他示例。
VOLA格式的使用已在若干应用中得到证明,对主要城市的空中扫描进行编码时效率特别高,例如,对于LiDAR数据集,最大尺寸可以减少1/70。可以受益于VOLA格式的其他常见应用是CNN推理、路径规划和避障。最后,可以通过使用散列表来进一步减少存储器占用,以及其他示例应用。
示例光线投射算法可以被实现为仅投射初级光线的非递归光线跟踪算法,并且其特别流行为直接体积渲染技术。体积渲染技术的一些主要优点是其出色的图像质量以及无需显式定义表面几何形状即可渲染图像的可能性。相反,主要缺点是它们的高计算成本。关于用于表示3D体积的数据结构和用于体素遍历的算法,存在若干方法。此外,多年来,还开发了许多附加技术来处理特定的子问题并提高算法的性能(诸如空间跳跃、相干分组遍历、视锥体剔除等)。
光线投射中使用的优化类型通常与所选的体积表示相关。体积的最基本表示是均匀网格和分层网格。分层网格可以被组织为松散嵌套的网格、递归或多分辨率网格以及宏单元或多网格。作为另一示例,可以利用二进制空间划分(BSP)来使用任意划分平面来递归地细分空间。在BSP中,kd树是一种特殊情况,它仅使用轴对齐的拆分平面。kd树允许对体积进行自适应划分,但比八叉树更难更新,尤其是对于大的体积。尽管分组kd树遍历的性能胜过静态场景的网格,但重建树的成本使它们不太适合于真正的动态场景。相反,可以以更高的速率创建和修改网格,即使它们具有更高的遍历成本,也使它们对动画场景具有吸引力。渲染体素化几何形状的另一有效表示是稀疏体素八叉树、边界体积层次结构(BVH),以及其他示例。
在一些实现方式中,可以利用空间跳跃来利用VOLA结构以用于有效地跳过空单元。用于跳过空白空间的策略可能与下面的体积表示有关。在一个示例中,通过距离编码的光线加速(RACD)可用于空间跳跃,以便为每个体素存储到下一个可能的不透明体素的跳跃距离,这可作为预处理步骤来执行。在一些实现方式中,可以通过仅针对类似于VOLA的多级网格结构的第一级计算经渲染体积的占用地图,来实现用于空间跳跃的硬件架构。也可以实现基于GPU八叉树的、用于跳过空节点的方法。在一些实现方式中,可使用邻近性云在常规3D网格中跳过空白空间,其中,空体素填充有指示与周围对象的邻近性的场景相关信息。例如,可以在系统中实施基于邻近性云的算法,该系统特别专用于进行大体积渲染的GPU光线投射,其中将最佳的图像顺序和对象顺序空白空间跳过策略组合。
体积遍历实现方式可以至少部分地取决于所选择的体积表示。大多数方法已从基于平面网格的算法发展而来,该基于平面网格的算法根据下一个与轴对齐的平面的距离来确定每次迭代中要访问的最接近的相邻体素。其他实现方式可以遍历仅在整个遍历中采用整数运算的八叉树。在另一示例中,结合有效的稀疏体素八叉树,可以利用数据的有效八叉树表示,以及其他示例。
在传统的光线投射器中,颜色可能在遍历被占用的体素期间积累,直到达到不透明度阈值(例如,不透明度积累),从而允许早终止光线遍历。以该方式,可以计及透明材料来渲染真实的体积数据。在使用VOLA的前后实现中,可以放弃这些类型的特征,因为所需的信息是有关3D空间中的占用的信息,因为VOLA可能自然省略颜色信息的编码(尽管VOLA可以通过附加的体素颜色的位阵列进行扩展,但代价是增加存储器占用)。在此类实现方式中,算法流程可以在遇到体素时立即停止,而无需详细说明任何颜色信息、不透明度、纹理等。
在一种实现方式中,可以实现在光线投射期间使用的光线遍历算法,以专门利用基于VOLA的表示的结构。转到图15,可以使用两个不同的3D体积表示并针对特定的示例光线投射器进行比较:密集的分层网格(1505)和VOLA格式(1510),或者稀疏的分层网格。该示例中的两个数据结构均具有4
在一个示例中,计算系统可以结合(例如,在SLAM应用中)进行光线投射操作的性能,基于分层的稀疏网格结构(例如,VOLA)来实现光线遍历算法。在一些实现方式中,在光线投射应用中利用VOLA结构表示3D空间可以实现更有效的近似分层光线遍历算法。在一些实现方式中,在光线投射应用中使用的光线投射遍历算法可以实现传统遍历算法(诸如John Amanatides和Andrew Wo的用于光线跟踪的快速体素遍历算法)的分层版本。例如,在遍历算法的一个示例实现方式中,当边界体积与参考系统的轴对齐时,对边界体积执行光线相交测试操作(例如,轴对齐边界盒(AABB)测试)。如果体积的某些外部定位部分是空的,则可能检查L0 VOLA元素以轻松修剪要进行光线投射的体积,从而将其缩小为要相交的子-AABB(例如,如1515所示)。此类应用可包括空中扫描,其z维度上的体积几乎为空白。使用透视投影扫描虚拟图像。由于每条光线是独立的,因此可能采用多线程来同时处理不同的光线。在一些实现方式中,线程池被初始化,然后根据可用的运行时资源进行调度。实际上,在一些实现方式中,由于考虑到高速缓存数据的局部性和上下文切换开销,将虚拟图像的矩形子片而不是单个像素或整行分配给线程可能更方便。
在一个示例中,可以使用计算系统(并且在某些情况下完全在硬件中)实现算法,其中p是光线-AABB相交点(或可选地,在体积内的点),并且d是光线方向;光线方程表示为r(t)=p+td。求解方程以找到与x分量正交的轴对齐平面的t,得出t
如图16中所示,示出了传统的遍历算法,由此将光线1605(例如,许多要投射通过体积(例如,1610)的光线之一)投射通过体积1610。在图16A中,黑色正方形(例如,1615、1620)表示体积1610中的被占用的体素,其未被光线1605撞击,而灰色正方形(例如,1625)表示被光线1605命中的第一被占用的体素。在传统的遍历中,如图16A中所示,被光线1605遍历的每个体素由系统逻辑检查(例如,每个检查由相应点(例如,1630)代表)以确定该体素是否被占用。遍历可以扩展为分层结构(诸如VOLA),可以有效地利用其来跳跃空白空间。在一个示例中,分层密集网格和VOLA格式共享相同的数据组织,因此该算法可以不加选择地应用于两者。至于基本算法,可以使用3D坐标在空间中移动,同时根据遇到的体素改变分辨率级别:两者之间的主要区别是如何测试体素的内容。例如,转到图16B,当遇到某一级别的占用体素(例如,1635)时,根据特定的体素砖的级别和边界,访问层次结构中的下一个级别(例如,对t
在一个示例中,可以修改遍历算法的分层实现以在准确度不是主要问题并且可以牺牲准确度有利于速度的情况下加快执行速度。例如,如图16C中所示,在一些实现方式中,光线遍历算法首先确定光线占用并且首先遍历哪个较粗粒度的体素。光线遍历算法然后可以仅集中于评估在占用的较低分辨率(较高级别)的体素中的高分辨率(较低级别)的体素表示。然而,与检查占用的体素中的每个子体素相反,可以采用近似方法,其中以覆盖一个以上体素的间隔(例如,x)检查子体素(例如,检查光线遍历的每第二个或每第三个体素是否占用体积,而不是检查每个遍历的体素)。例如,定点实现方式可用于数据。在识别光线方向的主要分量之后,将某一级别的光线提前,以使其在确定的方向的主要分量上(例如,x,y或z分量)覆盖等于子体素大小的距离。这样做,使用于要遍历的新体素的占用/未占用决定很快。然而,要权衡的是,近似的分层遍历算法不严格访问光线遍历的所有体素,这可能导致光线对占用体素的命中丢失,从而可能在特定条件(例如,当体素的密度较低或渲染具有薄表面的空对象时)下产生伪像,以及其他副作用。如图16C中所示,可以将用于扫描占用的较高级体素内的体素的间隔1655定义为在x方向上的体素。因此,当对占用的较高级体素(例如,1660、1665、1670)进行光线投射检查时,仅检查遍历的体素的一部分(例如,1675、1680、1685)。示例伪代码进一步说明了此类实施例:
级别_增加_值[最大负载+1]←距离初始化(r
而图16C的示例示出了沿着定义的子体素间隔检查体素的近似分层遍历算法,可以基于应用和应用(例如,渲染或SLAM应用)的分辨率敏感性在算法中选择和利用其他间隔。转到图17,例如,对标准分层遍历算法(例如,如结合图16B所示,其中检查被光线遍历的占用体素中的每个子体素)的示例结果与近似分层遍历算法(例如,如结合图16C所示,其中仅检查占用的较高级别的体素中的一部分遍历的子体素)的示例结果之间的可视化比较,示出了示例亚洲龙模型的比较渲染。在该示例中,简单地将图像1705、1710渲染为来自3D亚洲龙模型的原始光线投射数据的深度地图。图像1705代表标准分层遍历算法的结果,而图像1710代表近似分层遍历算法的结果。虽然从近似算法生成的图像1710遗漏了表面上的一些体素(表现为图形伪像),但两个图像1705、1710之间的相似性表明,在一些应用中通过近似分层遍历算法实现的计算效率可能是非常值得的权衡。
图17的图示只是一个示例,但是与在渲染图像方面对准确性进行溢价的传统算法相比,近似分层遍历的实现结果可以更一般地与传统算法进行比较。针对此类比较,对于每个相机姿势,可以使用两种分层遍历算法来产生灰度图像。图像中每个像素的强度是整数,该整数和虚拟相机与命中体素之间的距离有关。因此,可以基于强度值之间的差异来比较两个图像,同时考虑将准确、统一的算法用作基础事实。由于背景(漏光)不提供有价值的信息,因此,为了进行比较,可以仅考虑在精确的光线投射器中击中体素的光线(这可仅导致漏检,而不导致误报)。可以对空间中数百个相机姿势和不同场景的帧进行平均来计算不同结果的百分比。在该示例中,可将VOLA模型用于测试,诸如从丽菲河(位于爱尔兰都柏林)的空中扫描生成的模型以及来自斯坦福3D扫描存储库的三种模型:亚洲龙、露西天使和泰国小雕像。由于使用浮点运算和转换可能导致非常小的像素强度差异(小至一个单位),从而不切实际地增加差异计数,因此可以实施阈值,其中仅考虑像素强度差异大于1的情况。示例结果显示在表1中。注意,表中显示的不同像素的百分比表示为仅精确光线投射器实际击中的像素的分数。对于在两个图像之间强度不同的那些像素,平均值的高值证实了所考虑的情况是正确的漏检。百分比差异取决于所用模型中体素的密度:通常,像素密度越高,近似值越低。
表1:精确渲染的图像与近似渲染的图像之间不同像素的百分比,作为精确图像中命中像素的分数。还报告了遗漏的平均强度差。
在一些实现方式中,可以以诸如视觉处理单元(VPU)的硬件来实现光线投射器。此类硬件设备可以被具体实现以在功率严重受限的环境中提供高性能的机器视觉和人工智能(AI)计算。图18是可以被实现为多核始终在线片上系统(SoC)1805的简化框图,其为具有低等待时间和低功率要求的一系列机器学习和视觉应用提供了高度可持续的性能效率。示例处理设备1805的架构可以使用具有用于图像处理和计算机视觉内核的(例如,通过一个或多个加速器设备(例如,1815)提供的)硬件加速的支持向量和SIMD操作的低功率超长指令字(VLWI)处理器(例如,1810)的组合、由非常高带宽的存储器子系统(例如,1820)以及一个或多个RISC处理器1825、1830(例如,根据SPARC架构的Leon 32位RISC处理器)支持。系统分为三个主要架构单元:媒体子系统(MSS)、CPU子系统(CSS)和微处理器阵列(UPA)。在该示例中,UPA包含VLWI处理器(例如,十二个自定义向量处理器(例如,1840a-l)),在一些情况下被实现为SHAVE(流混合架构向量引擎)处理器。
为了从PC轻松访问SoC,可以使用机器学习加速器(例如,Movidius
在一个示例测试中,测试了精确(标准)和近似版本的统一网格和分层网格算法,并在性能方面进行了比较。为了利用在用于执行光线投射应用的特定架构(例如,使用SHAVE指令集架构(ISA)的架构)中可用的向量操作,可以利用系统编译器中可用的内置函数(内部函数)重构分层实现方式,并单独进行测试。在一个示例中,使用了对都柏林O'Connell桥楼(OCBH)建筑物的空中扫描和斯坦福3D扫描储存库中的两个模型进行的测试。此类示例测试获得的结果在图19中示出,在图19中显示了平均、最小和最大帧速率测量值。所显示的测量值是在所有测试的相同条件下进行的,在查看体积中心的固定点的同时执行虚拟相机的圆周运动。如在图19的曲线图1900中所示,近似实现的性能始终比精确实现好,其中帧速率提高了30%至75%。通过使用内部函数,精确和近似SIMD光线投射器版本的最大加速因子分别达到12.78和17.74。
在光线投射应用中使用稀疏的分层网格结构(例如,VOLA)可以实现额外的益处,例如,就数据结构的性能和存储器占用而言。例如,从拓扑的角度来看,密集的和稀疏的分层网格可以有效共享空间中的同一组织,但是在稀疏网格的情况下,实际上仅存储占用的数据。这导致非常小的存储器占用(表),但同时又增加了在分层网格中定位特定体素所需的时间,因为必须检查所有先前的级别,以便识别稀疏网格表中的设置位并对其进行计数。例如,表2报告了相同模型的不同格式的存储器占用之间的比较。表中显示的密集网格和VOLA格式直接从示例多边形文件格式(PLY)对象获得。可以看出,VOLA结构确保大幅尺寸减小,相对于PLY格式,这里的最大尺寸减小约1/11140。从仅取决于分层网格的深度的意义上讲,密集的网格占用可以被认为是完全确定的;相反,VOLA结构占用取决于空间中实际占用的体素。如图20A的曲线图2000a中所示,示出了三种不同的VOLA模型的平均帧速率以及用于密集网格的相同算法和优化。可能注意到使用近似实现方式不再有任何实际收益;同样,引入SHAVE内部函数优化的好处非常低。这可以从以下事实来解释,即所采用的技术旨在优化算法的网格遍历性能,但是现在的瓶颈主要在于测试VOLA结构中体素占用所需的高时间。结果,在实际遍历中花费的时间比例在这里比密集网格低得多。VOLA实现方式的性能比密集网格的性能低约1/11到1/30。但是,将获得的性能与存储器占用(平均-FPS/MB)相关联,可以得出结论,VOLA实现方式效率更高得多,并且因此它可以如图所示(例如,在图20B的示例表2000b中)在高度存储器受限的环境中构成有效的选择。
表2:相同3D模型的不同数据格式占用的存储器占用比较。
在一些实现方式中,可以利用用于实现光线投射的稀疏分层数据结构来实现光线投射算法的嵌入式实现方式。此外,可以采用近似光线遍历算法来实现处理性能的益处。此外,可以在密集(VOLA)方法与稀疏(VOLA)方法之间权衡性能和存储器使用情况,显示出以降低性能为代价的、VOLA结构在FPS/MB效率上的一致优点。因此,在光线投射应用中利用稀疏分层网格结构表示3D体积的系统可能被认为是优选的,特别是在存储器高度受限的环境中。实际上,本文讨论的改进的系统实现方式显示出非常高的功率效率,比传统的光线投射实现方式高多达两个数量级,还有其他示例优势。
计算机视觉系统可以结合自主地确定自主设备(诸如机器人、自主无人机或交通工具)的位置和定向来利用光线投射和渲染结果,以及其他示例。实际上,准确的位置和定向估计对于自主机器人的导航至关重要。尽管这是一个经过充分研究的问题,但是现有的解决方案依赖于统计过滤器,这些过滤器通常需要良好的参数初始化或校准,并且计算量大。如本文所讨论的,改进的系统可以实现改进的端对端机器学习方法,包括并入多个数据源(例如,单目RGB图像和惯性数据)以独立地克服每个源的弱点。在一些实现方式中,利用此类功能的改进的系统可以实现测程结果,该测程结果在计算上更便宜,并且精确度处于或仅略低于最新技术水平,从而允许此类系统为资源受限的设备实现有价值的潜在解决方案,以及其他示例用途和优势。
运动估计是移动机器人技术的主要支柱之一。它为机器人提供了在未知环境中知道其位置和定向的能力,并且可以与地图构建方法组合以开发同步定位和地图构建(SLAM)。实际上,在此类实现方式内,所利用的SLAM流水线可以采用本文讨论的改进的光线投射技术。机器人可以根据传感器的类型使用不同的数据源来执行此类运动估计:本体感知时,它提供诸如惯性测量单元(IMU)之类的机器人内部信息;或者外部感知时,它提供机器人周围环境(诸如相机或LiDAR传感器)的信息。由于机器人的自主性质,它应该能够机载实时执行此类运动估计,这在设备资源有限的情况下是一个特别的挑战。因此,期望找到在此类限制下可以在嵌入式设备中运行的解决方案。
深度学习可用于解决测程应用中的姿势估计问题。例如,相机捕获机器人或其他自主设备的周围环境,并可用于通过视觉测程(VO)跟踪机器人的运动。经典的VO方法根据几何形状约束来估计运动,并且可被分为两组:基于稀疏特征的方法和直接方法。一方面,基于稀疏特征的方法提取并匹配特征点以估计帧之间的运动。此外,一些VO方法添加和维护特征图,以便校正由于存在异常值和嘈杂图像而造成的漂移。另一方面,直接和半直接方法通过最小化连续图像之间的光度误差,使用所有图像像素来估计姿势。
但是,经典的VO方法通常需要外部信息(诸如相机高度或模板)来感知比例并以实际单位恢复距离。此外,传统的VO系统被证明为在存在快速运动时或在照明突然变化时是不可靠的。为了解决这种可靠性的不足,可以将相机信息与惯性传感器组合使用,该惯性传感器可以提供加速度和角速率信息。这些传感器通常以比相机高得多的频率(例如,快约10倍)提供数据。因此,惯性信息可用于克服快速相机运动情况下VO系统的弱点,以及其他示例改进和问题。
视觉惯性测程(VIO)系统利用视觉和惯性信息来提供位置和定向估计。在一些实现方式中,视觉惯性数据融合通过使用概率滤波器方法(诸如扩展卡尔曼滤波器(EKF)或无迹卡尔曼滤波器(UKF))来完成。视觉惯性数据融合是通过基于EKF的系统执行的,他们使用该基于EKF的系统来比较仅使用陀螺仪数据或使用陀螺仪和加速度计数据的不同融合模型。EKF的其他变体可以被实现,诸如多状态约束卡尔曼滤波器(MSCKF),诸如其中使用若干过去的相机姿势来检测静态特征并向状态向量添加约束的系统,以及其他示例。
在一些实现方式中,配备有深度学习功能的系统可以用于克服经典VO方法的弱点,诸如对于模糊或嘈杂的图像缺乏鲁棒性,或者当发生照明或遮挡的变化时。例如,卷积神经网络(CNN)甚至可以对于模糊和噪声图像表现良好,为提取图像特征提供了一种稳健的方法。CNN也可以用于计算两个连续图像之间的光学流。光学流表示相机视图上对象位置的变化,因此它与相机在两个连续帧之间经历的运动有关。在一个示例中,由光学流网络提取的图像特征可以与两个长短期记忆(LSTM)层一起用于深度学习系统中,从而以端到端的深度学习方式实现单目VO系统,其可以优于经典的单目VO方法(例如,基于LIBVISO2的VO),以及其他示例。
基于用于传感器融合的概率滤波器的VIO方法可能需要艰苦而复杂的校准过程,以便将相机和惯性测量单元(IMU)测量结果带到相同的参考坐标系统中。例如,校准过程可以在跟踪系统运行时实时执行,这增加了滤波过程的复杂性。此外,某些IMU的参数难以建模,诸如在大多数商用IMU中所发现的测量内的噪声缩放。深度学习技术可以进一步用于解决传感器融合过程中的问题。例如,LSTM可用于跟踪过去的IMU原始测量值(加速度计和陀螺仪)以估计机器人的姿势,然后可以将其与VO系统融合。在VINet中可以使用LSTM以从IMU的原始测量值中提取编码的特征。这些编码的特征可以与从CNN提取的特征组合在特征向量中,该特征向量是由第二LSTM随时间跟踪的,第二LSTM可以提供机器人的姿势估计。在一些实现方式中,VINet方法可能优于传统方法,诸如传统的基于优化的传感器融合方法,以及其他示例益处。
在一个示例中,改进的系统可以实现端到端的可训练神经网络架构,其结合了视觉和惯性深度学习子模型。例如,在基于视觉的CNN子模型中,可以提供RGB图像作为输入。在第二基于惯性的深度学习子模型中,提供IMU原始测量值作为输入。在一个示例中,端到端神经网络架构可以利用神经网络子模型的组合,该组合网络(及其子组件)可以以端对端的方式进行训练,从而消除对校准或预处理的任何需要。
在一些实现方式中,可以训练端到端机器学习测程系统的神经网络以在每个帧处产生相对于先前帧的姿势估计。每个姿势估计代表变换,通常表示为变换的特殊欧几里得组SE(3)的元素。SE(3)(等式1)中表示的所有变换都可以由旋转矩阵和平移向量组成,这是特殊正交组SO(3)的旋转矩阵部分。
等式1:
在SE(3)中找到变换对于网络而言并不简单,因为R必须正交约束。因此,为了简化学习过程,在SE(3)的李代数se(3)(等式2)中表示估计的变换。
等式2:
se(3)中的姿势估计可以是6维向量,并且可能不受正交约束。一旦估计,就可以通过执行指数映射se(3)->SE(3)来将se(3)中的姿势转换为SE(3)的变换(等式10):
等式3:
等式4:
等式5:
等式6:
等式7:
等式8:
等式9:
等式10:
se(3)→SE(3):exp(ω|t)=(R|Vt)
其中矩阵R和V可以分别使用等式8和9进行计算。A、B、C和θ可以通过等式4、5、6和3得出。ωx矩阵由ω值组成(等式7)。
在一个示例中,可以利用基于视觉的神经网络模型2105,诸如在图21A的简化框图中表示的。它以两个连续的RGB图像作为输入2110,这些RGB图像堆叠在一起组成具有6个通道的大小为512x384的输入张量。该图像大小可包含足够的特征,同时得到浅的CNN。在一个示例中,计算机视觉神经网络(诸如FlowNetS)的层2115可用于提取图像的特征,这些特征可有利地用于运动估计,以及其他示例使用。作为神经网络模型2105的一部分采用的此类网络(例如,2115)可在合成数据集上训练以学习如何估计帧之间的光学流,该光学流表示机器人随时间的运动,以及其他示例。
在图21A的示例中,FlowNetS层2115可以占用网络2105的第九个卷积层,然后是附加的卷积层2120,以将CNN的输出大小减小到2x3x256的张量。在CNN层2125之后,可以使用一系列的完全连接层2130组合提取的特征,以生成输出6维向量姿势2135,该姿势2135表示当前帧(t)相对于前一帧(t-1)的变换,以SE(3)的李代数表示。
在图21B中所示的另一示例网络2140中,仅惯性数据用作网络2140的输入2142。在一个示例中,输入2145可以是IMU数据,具体化为由十个6维向量与来自设备的加速度计和陀螺仪组件的x-y-z原始数据分量组成的子序列。在该示例中,可以按时间顺序对(十个)测量的输入子序列进行排序(最后一个是最新的),从而对传感器随时间经历的运动进行编码。
继续图21B的示例,长短期记忆(LSTM)人工循环神经网络部分2150可以用作模型2140中的回归层,以跟踪子序列上的测量值并提取运动信息,因为它能够在其隐藏状态中存储过去输入产生的短期和长期依赖关系。每个输入通过LSTM 2150时与隐藏状态组合,以查找当前测量值与过去测量值之间的时间对应关系。在一个示例中,LSTM 2150可以具有1层,1024个单位,并且可以跟随有四个完全连接层2155,这些完全连接层2155输出表示从子序列的最后一个元素到第一个元素所经历的(例如,由机器人所经历的)变换的6维向量。这些架构和参数可以由于它们在蒙特卡洛分析中的性能而被选择,该架构和参数可以被用于探索和优化层的不同组合的选择,以及其他示例实现方式。
如上所述,改进的机器学习系统可以利用神经网络模型2160来执行测程计算,该改进的神经网络模型组合图21A-图21B中所示的示例网络部分2105、2140,以利用可以存在于机器人或其他自主设备上的视觉传感器和惯性传感器两者。因此,模型2160的输入可包括视觉数据和惯性数据,诸如一对连续的RGB图像和十个惯性测量值的子序列。在该示例中,虚拟神经网络部分2105与图21A的示例中呈现的虚拟神经网络部分相同,直到其第三完全连接层。类似地,使用惯性测程(IO)网络部分2140直到其第二完全连接层。以该方式,神经网络模型2160维持VO和IO网络两者,直到提供有用特征的最后一层。然后,视觉特征向量和惯性特征向量被合并为128维向量,并通过三个完全连接层2165以输出姿势估计2170。像以前一样,每个姿势估计代表机器人在当前帧处相对于前一帧所经历的变换。
在一个示例实现方式中,用于训练示例神经网络模型2160的数据可以是已编译数据集的一部分(例如,KITTI Vision Benchmark Suite(KITTI视觉基准套件)的原始数据部分)。在一个示例中,测程数据集由22个序列组成,其中的前11序列具有基础事实变换。在该示例中,序列11-22旨在用作评估,因此不提供基础事实。包含最多帧数的序列00、02、08和09用于训练,而序列05、07和10用于评估。在一些实现方式中,可以通过向图像随机施加高斯噪声、高斯模糊和强度变化来增强训练数据,诸如通过对2/3的数据施加高斯噪声(例如,均值=0,标准偏差=[0,32])和像素强度变化(例如,[-25%,25%]),以及对剩余的三分之一的数据施加高斯模糊和内核3、5和7。在增强数据之后,可以对训练数据集(例如,总共22912个图像帧)以及基础事实(例如,以10Hz)进行采样。IMU数据可能以较高的频率(例如,100Hz)到达,意味着每个图像帧可能有多个IMU测量值。但是,也可能存在某些IMU数据丢失的帧。在这种情况下,帧的第一IMU测量值用于填充丢失的测量值,以填充子序列。
在一个示例中,使用的损失函数(等式11)表示每个估计的相对姿势与其各自的基础事实之间的欧几里得距离,用se(3)表示:
等式11
ω、
等式12
等式13
w
其中β用作摩擦因子,防止动量变得过大,而λ是学习率。然后根据m更新权重w
等式14
入(t)=入
在一个示例中,使用的初始学习率(λ
本文讨论的网络可以被评估并比较它们的性能。在该示例中,将VO和VIO与使用相同类型数据的现有方法分别进行比较。例如,可以评估改进的VO网络(例如,如本文结合图21A的示例所讨论的),并将其与传统解决方案进行比较。在一个示例中,可以使用KITTI测程开发套件中提出的度量以及在序列05、07和10上执行的网络来执行比较,从而获得每个帧相对于第一帧的绝对姿势。然后,可以针对序列上的不同轨迹长度(100m、200m、300m、……、800m)计算均方根误差(RMSE)。表3中显示了这些结果,以及传统的VISO2 M和DeepVO网络。如表3的示例所示,在序列05和10的平移和旋转误差方面,诸如本文所讨论的改进的VO网络可以优于传统网络(例如,VISO2M),并且在序列07的平移中执行比较。
表3。所有误差代表所有可能序列长度的平均RMSE。t
转向图22,示出了本文中(例如,结合图21C)讨论的改进的VIO网络的实施例的示例结果,并将其与传统解决方案的结果进行比较。例如,图22示出了使用改进的VIO网络针对基础事实实现的估计轨迹(表4中示出了相对应的示例终点平移和旋转误差)。
表4。与传统解决方案相比,改进的VIO网络模型的终点位置和定向误差。平移误差以终点的绝对误差和该误差相对于第0-800帧中涵盖的总距离的百分比表示。
尽管纯惯性测程(IO)网络的实现方式可能随时间显示大的漂移误差,但当将其与视觉测程网络组合(以形成可视惯性测程网络,诸如上述示例中所述)时,漂移可能大大减少。此外,当机器人转动时,视觉惯性测程(VIO)网络可能表现出更好的性能,其性能优于视觉测程网络。这说明了IMU如何补偿相机中对象的大位移。改进的视觉惯性测程网络可能优于传统解决方案。此类网络可以用于从机器人到自主无人机的各种应用中,以及其他示例。
除了上述示例特征之外,改进的计算机视觉系统可以附加地使用稀疏的分层体素网格表示(例如,VOLA)来利用卷积神经网络(CNN)估计一对点云之间的相对姿势。如本文所讨论的,体素网格与点云相比是更有效的存储器解决方案,因此它可以在可能限制存储器和计算资源的嵌入式系统(例如,自主设备)上使用。可以将使用变换误差的新损失函数与3D体素网格上的2D卷积一起使用。实际上,此类解决方案可以提供此类效率,同时保持与迭代最近点(ICP)的传统、最先进的实现方式相当的精度。实际上,改进的、基于体素网格的解决方案可以实现对ICP的改进,因为体素网格的使用限制了高密度区域对对齐误差的影响,以及其他示例使用和优点。
近年来,由于各种各样的传感器能够以更高的数量和质量来扫描3D数据,因此3D扫描技术已变得对每个人更加容易使用。这些3D传感器产生点云,该点云是在统一坐标系中的一组未组织的三维点,其描述了用于表示3D数据的空间信息。但是,可用的3D传感器(如LiDAR、声纳和RGB-D)的扫描范围有限。为了克服该有限范围,需要采集多个扫描并将其合并以创建3D地图。多次扫描的融合要求每次扫描都在同一坐标系中表示,因此它们的信息以有组织的方式显示。因此,为了在同一坐标系中表示所有扫描,知道执行扫描的位置是至关重要的。该位置可以表示为参考帧与当前扫描之间的位移。已知为相机姿势的位移,可以表示为由平移t和旋转R形成的变换ΔT,因此ΔT=(R|t)。可以通过使用扫描中可用的3D信息或在其他类型的传感器(诸如GPS、IMU、或地面车辆上的车轮测程)的支持下提取传感器的位移。在一些情况下,可以应用诸如本文所讨论的测程解决方案以帮助确定此类放置。一旦知道相机的位置,就可以在同一坐标系上表示扫描,从而创建包含来自所有扫描的信息的3D地图。查找相机位置的问题被称为相对姿势估计,这在历史上很难在资源受限的设备上实现。
在一个示例中,计算系统可被配置成用于通过实施和使用深度神经网络(DNN)来解决相对姿势估计问题。由于噪声和传感器的限制,点云的大小在两次扫描之间可能不同。但是,从设计阶段开始,点云的体素网格表示已固定。由于3D卷积的计算量很大,因此改进的解决方案可以替代地使用3D体素网格的替代2D表示,从而允许使用计算效率高的2D卷积神经网络(CNN)。在一些实现方式中,可以使用2D卷积神经网络来寻找体素网格对之间的变换。可以基于使用基础事实和网络预测对点云进行变换而获得的误差来确定损失函数。此类实现方式的性能可以是使用RGB-D SLAM数据集将其结果与最新技术的迭代最近点(ICP)方法进行比较。此外,可以利用产生两个点云的传感器的扫描之间的相对姿势估计来寻找在产生的点云之间产生最佳对齐的变换。因此,本文中讨论的此类相对姿势估计解决方案可以可替代地被称为“点云对齐”解决方案。
转向图23A-图23B,目前,最频繁的3D点云对齐方法基于迭代最近点(ICP)2315的变体,其以迭代的方式估计使两个不同点云2305、2310中的相对应点之间的距离最小的变换,如图23A中所示。该迭代过程可能计算量大,并且另外,它对处理点云2305、2310之间的初始对齐和重叠及其大小敏感。根据计算和最小化两个点云之间的对齐差异的方法,可以找到多种基于ICP的方法,其中,可以在平面或曲线之间完成此距离,而不是在点之间。为了使3D对齐更加有效,可以将ICP解决方案扩展到使用特征从3D点云的描述符中提取关键点。旋转和平移不变性或噪声鲁棒性等因素对这些关键点很重要,其中使用基于直方图的描述符、3DSIFT、SHOT和NARF进行的工作就是示例。
在可获得RGB-D图像的情况下,可以使用RGB图像来改进相机位移的估计。这可以被用来实现用于单目或双目或多相机姿势估计的方法。在改进的系统的一些实现方式中,RGB图像用作卷积神经网络(CNN)的输入,该卷积神经网络使用一组卷积层提取图像数据中的复杂特征,然后通过一组完全连接层来回归姿势。此外,在一些实现方式中,可以在该拓扑上添加长短期记忆(LSTM)层,以形成循环神经网络(RNN),从而处理在长轨迹中拍摄的图像之间的时间依赖关系。
其他实现方式可以利用不同类型的输入以及RGB图像。例如,图像对之间的光学流可用于估计相对姿势。此外,从2.5D角度考虑这种情况,在神经网络将RGB-D图像用作输入的情况下,也可以使用深度尺寸的信息,以及其他示例。一些实现方式可以利用3D数据上的CNN来对此3D数据执行深度学习。例如,可以通过首先从点云中提取特征点,然后将获得的特征馈送到深度学习方法,来评估点云对齐问题。例如,“超点”描述符可以用作匹配点云的基本单元,并且该描述符可以用作深度神经网络自动编码器的输入,该编码器保留用于寻找点云之间的变换的几何形状信息。在其他实现方式中,可以使用兴趣点,这些兴趣点表示存在大量点的点云的群集。此外,可以使用不同的问题(如使用此策略的分类或分割),其中最近的邻居地图和KD树分别用作点云的描述符。
在一些实现方式中,点云可表示为点子集,该点子集表示为(x;y;z)坐标的列表,然后将其馈送到完全连接层,这些层查找点之间的交互,以便对三维对象进行分类。在一些实现方式中,诸如由图23B中的简化框图所表示的,可以通过体素化过程2330将点云2305、2310转换为相应的体素网格(VG)2320、2325,该体素化过程2330在每个单元具有固定大小的3D网格上转换每个点云2305、2310。这固定所需的存储器量,并在体素之间生成相邻关系。然后可以使用基于体素网格的输入2320、2325向卷积神经网络2350提供输入以生成相对姿势结果2355。将该类型的数据与深度学习一起使用的策略可被应用于对象分类和定向问题,以及其他应用。传统解决方案和系统不使用体素网格(VG)和深度学习来解决相对姿势估计问题。使用3D空间的VG表示具有在设计阶段具有固定大小和较小的存储器占用的属性。此外,通过将低功率硬件加速器用于CNN执行和其他机器学习操作(例如,Movidius
转到图24中所示的简化框图,表示了示例神经网络拓扑,用于基于所分析的3D空间的体素网格表示(例如,2320、2325)来确定相对姿势估计。在一个示例实现方式中,可以实现2D卷积神经网络以将一对体素网格结构2320、2325作为输入,以通过训练CNN 2350对齐其相对应点云(点云从扫描生成并且体素网格结构以其为基础)来找到扫描之间的相对姿势。实际上,可以通过由系统执行的体素化过程从点云中的相对应一个生成或提取每个体素网格结构2320、2325。然后,可以由系统执行3D到2D投影2405,以便适应网络2350内2D卷积层中使用的输入。一旦在网络中引入了一对2D投影,它们之间的相对姿势ΔT 2355被预测。
如在图24的示例中所示,在体素网格输入2320、2325在2D投影中被切片并转换为2D投影输入(分别为2410、2415)的情况下,2D投影输入2410、2415可以被提供为CNN 2350的表示部分2420的输入。网络2350的表示部分2420可以被实现为具有多组(例如,成对的)相对应的卷积层(例如,2425a、b)的暹罗网络。在图24中使用的符号内,对于表示部分2420中的每个层,Conv(i;j;k)表示具有i个输出的卷积层、具有步长为k的j×j的内核大小和“相同”的零填充。来自表示部分2420的输出可以被级联以形成特征向量2430,其被引入作为网络2350的回归部分2435的输入。例如,回归部分2435可以被实现为包括一组完全连接层2440,其中最终完全连接的层分别生成用于生成相对姿势结果2355的旋转(ΔR)分量和平移(Δt)分量中的每一个。在图24的表示中使用的符号中,FC(i)表示具有i个神经元的完全连接层。
如上所述,点云是由一组无组织点形成的一种数据,因此首先在称为体素化的过程中将其表示为3D网格。体素化将点云转换为体素网格,在其中数据以体素结构化,因为2D图像相应地以像素结构化。本质上,它是具有[高度、宽度、深度]形状的立方3D网格,其中每个称为体素的立方体包含来自点云的小型信息区域。如果点落在该区域中,则体素占用设置为1,否则为0。这意味着VG每个体素仅包含1位,即占用VG。图25中示出了3D空间的点云表示2505的示例,以及从点云表示2505通过体素化生成的相对应体素网格表示2510的示例。VOLA结构可以被视为体素网格数据结构的一种特殊形式,其中仅存储代表某些几何形状所占用的3D空间的那些体素的数据。因此,诸如本文的示例中所描述的,VOLA体素网格结构减少了对数据传输和存储器受限环境有用的存储数据量。
如上所述,在一些实现方式中,在引入基于体素网格的输入(例如,2320、2325)之前,可以执行3D到2D投影步骤以使3D表示适合与具有2D内核的卷积层一起使用。这降低了网络(例如,2350)的计算成本,并且使其更简单,从而允许容易地将其部署到存在存储器限制的嵌入式设备中,以及其他示例应用。可以在3D数据上使用2D投影,诸如在多视图CNN中,其中从3D模型的不同角度提取2D图像投影,以将其与完善的2D CNN一起使用。但是,该方法通常不保留3D体积的空间结构,因为它着重于可能不需要该信息的分类问题。其他实现方式可能使用各向异性探测内核将3D对象投影到2D中,类似于将3D VG卷积到2D平面中的“X光线扫描”过程。该投影可能有助于捕获3D体积的3D全局结构,用于我们工作的姿势估计问题。由于体素网格被表示为代表现实世界中(X;Y;Z)尺寸的(h
如以上在图24的示例中所阐述的,计算系统可以在硬件和/或软件中实现卷积神经网络(CNN),并使用CNN来估计一对体素网格之间的相对姿势。CNN 2350将相对应体素网格的2D投影作为输入,并输出代表相对姿势的旋转(ΔR)和平移(Δt)的向量。CNN 2350的表示部分2420可以从每对输入中提取特征向量2430。该特征向量2430可以包含实用信息,该实用信息稍后用于预测相对姿势。特征向量2430由具有两个相同卷积层分支的暹罗网络形成,其中权重在彼此之间共享。在一些实现方式中,在表示部分2430中的每一个卷积层之后,存在整流线性单元(ReLU)作为激活函数。在一些实例中,不使用池化层来确保数据的空间信息被保留。对于CNN 2350的回归部分2435,将暹罗网络的两个分支的输出展平并级联,从而形成向量,该向量被引入到回归部分中,该回归部分是负责估计网络预测的部分。该回归部分由一组完全连接层2440形成,每个完全连接层跟随有ReLU激活函数。网络的输出具有两个分量(预测的旋转部分和平移部分),因此在网络2350的最后分段2450中,在两个完全连接层上存在分隔,每个完全连接层用于每个预测部分。
继续以上示例,CNN 2350的输出2355可以由代表体素网格对之间的相对姿势的向量组成。该向量通常被定义为变换的特殊欧几里得组SE(3)的变换矩阵ΔT:一组元素,由特殊正交组SO(3)的旋转元素和平移向量组成。在SE(3)组中进行预测时,由于SO(3)旋转分量必须是正交矩阵,因此可能存在一些问题。在一些实现方式中,使用SE(3)组的李代数se(3)作为避免正交性要求的解决方案,因为它表示瞬时变换而没有正交性约束。为了在se(3)与SE(3)之间进行转换,可以使用指数映射:
等式15:
se(3)→SE(3)∶exp(ω│u)=(R│t)=ΔT
由于使用李代数组,因此网络的姿势预测(w|u)由两个向量表示:w=(w1;w2;w3)表示旋转而u=(u1;u2;u3)表示平移,这两个向量被转换成ΔT。进行该转换的计算步骤利用了上面的等式3-9。
在一些实现方式中,可以利用由损失函数控制的学习阶段来训练网络2350,该学习阶段指导网络实现正确的解决方案。损失函数可以衡量网络的预测质量,对学习抛出的反向传播进行惩罚或奖励。在一个示例中,所提出的损失函数在应用两个不同的变换T
等式16:
其中
存在着重于相对姿势估计问题的许多数据集,这些数据集可用于测试姿势估计解决方案中使用的CNN的有效性。此类数据集可用于表示基础事实,该基础事实提供有关数据定位的信息,这对于了解相对姿势是必需的。在一个示例中,需要点云来评估网络。这种类型的数据可以通过两种方式找到:从直接提供由3D激光传感器产生的点云的3D数据集(例如,LiDAR;或RGB-D数据集),其中点云可以通过直接的过程从深度图中提取,将每个具有深度信息的像素转换为点。
对于诸如本文所讨论的利用深度学习的实现方式,在学习阶段可能需要大量数据以训练网络。满足此要求,可以找到不同的数据集,并根据其应用区分它们。例如,KITTI数据集、Oxford机器人汽车数据集、Malaga Urban数据集和其他数据集可能集中在自主驾驶应用中,其中汽车用于移动相机/传感器。再举另一个示例:7场景数据集、ICL-NUIM数据集和其他数据集可能集中在室内环境中的手持设备上,在该室内环境中他们用手拿着和移动相机。在另一个示例中,可以利用TUM数据集,除了手持序列之外,TUM数据集还可以包含从在地面上移动的轮式机器人获得的数据,以及可以在网络的训练期间使用的其他示例数据集。
作为示例,在使用深度学习应用地面机器人进行室内定位时,可以利用TUM数据集,因为它提供了足够数量的此类数据来训练深度神经网络(DNN)。该数据集可包括多个序列,这些序列根据其应用按类别进行组织。在一个示例中,仅使用“机器人SLAM”序列。为了从深度地图获得点云,数据集中提供的工具用于评估我们方法的性能。
如本文所述,可以对来自TUM数据集的点云进行体素化(例如,仅将在x、y和z方向上距离相机[4、4、8]米范围内的点放到大小为[64,64,128]的VG中)。为了从头开始训练网络,在一个示例中,可以使用“机器人SLAM”类别的前三个序列(例如,fr2/pioneer(先锋)360,fr2/pioneer(先锋)slam和fr2/pioneer(先锋)slam2),剩下第四组(例如,fr2/pioneer(先锋)slam3)不进行训练,以便评估具有未知数据的网络。
此外,为了增加用于训练的数据量并且为了使网络对传感器的大位移具有鲁棒性,可以通过在数据序列中采用不同的步长来创建训练对,形式为(F
在一个示例中,网络模型可以用TensorFlow框架实现,并用图形处理单元(GPU)、向量处理单元或其他计算机处理器训练。在一个示例中,通过使用TUM数据集中提供的工具来分析被训练网络的性能,其中提供了两种不同类型的误差:(i)相对姿势误差(RPE),它测量轨迹在固定间隔Δ内的的局部精度,这是与轨迹漂移相对应的误差;以及(ii)绝对轨迹误差(ATE),它通过比较所估计的轨迹与基础事实轨迹之间的绝对距离来测量所估计的轨迹的全局一致性。
为了将网络的性能与现有方法进行比较,可以使用迭代最近点(ICP)的传统实现方式。表5中列出了本文讨论的基于CNN的相对姿势估计方法的示例评估中确定的误差,以及传统ICP实现方式和组合CNN-ICP方法的结果(将改进的基于CNN的解决方案与ICP部分组合)也用于比较。可以看出,就相对姿势估计而言,与使用ICP的方法相比,CNN的旋转误差更高,但是CNN的平移误差最低。这意味着尽管旋转误差很大,但对姿势的影响很小,使得平移误差影响最大。在某些实例中,平移相对姿势估计误差可被认为足以进行比较,因为当相机移动时、旋转相对姿势估计误差表现为平移误差。最后,尽管CNN的ATE误差较大,但网络获得的轨迹是平滑的,并且遵循与基础事实相同的“形状”,而ICP轨迹通常更不稳定。可以将CNN的较高ATE视为在不存在评估旋转比例的一小组数据上训练CNN的结果。
表5:每个相对姿势估计技术的相对姿势误差(RPE)和绝对轨迹误差(ATE)(表示为均方根误差(RMSE)、平均值和标准差(STD))。在该示例中,RPE以5帧的固定Δ间隔计算。
如上所述,改进的计算系统可以(在硬件和/或软件中)实现端到端方法,以基于点云之间的变换误差来使用损失函数找到体素网格之间的相对姿势。与ICP(甚至是CNN+ICP的组合)相比,此类系统的CNN估算的轨迹可能更平滑。尽管此类系统可以利用相对大量的数据来训练相对应的深度学习模型,但是在其他实现方式中,可以增加训练数据集的大小。应当理解,该方法可以用在其他应用中,包括手持相机、无人机和汽车。此外,实现方式可以利用由LiDAR获得的点云。在一些实现方式中,还可以减小或以其他方式简化网络的参数的大小,以及其他示例修改。
图26A-图26C是示出用于通过系统增强计算机视觉处理的示例技术的流程图2600a-c。在图26A的示例中,示出了用于执行光线投射的改进技术。例如,可以访问2602稀疏的分层体积(基于网格的)数据结构(例如,基于VOLA的结构),并且可以使用体积数据结构执行2604光线投射算法。可以将多个光线投射2606到由体积数据结构表示的体积中,以执行光线投射算法。光线投射可包括光线遍历步骤——在该情况下,根据导致光线近似遍历的间隔,检查少于所有与光线相交的体素,以查看它们是否包含几何形状(或被“占用”)。根据遍历,近似确定光线是否与被占用的体素相交,如果是,则光线首先与哪个被占用的体素相交。例如,作为SLAM流水线、渲染应用或其他示例使用的一部分,对每个光线重复该光线投射过程。
转到图26B,示出了用于确定设备(例如,设备的一个或多个传感器)的姿势的改进技术。该设备可以是能够在环境中自主导航和移动的自主设备。在一个示例中,视觉数据(例如,由设备的相机生成的视觉数据)可以输入2620到神经网络模型的第一部分,该第一部分被实现为视觉测程神经网络。此外,惯性数据(例如,由设备的IMU生成的惯性数据)也可以在神经网络模型的第二部分处被输入2622到该模型,该模型的第二部分被实现为惯性测程神经网络部分。视觉测程网络部分和惯性测程网络部分的各个输出可以被级联起来,并作为输入提供给神经网络模型内一组完全连接层中的第一完全连接层。可以通过神经网络模型基于视觉数据和惯性数据的组合输入来生成2626代表设备的姿势的输出。
转到图26C,示出了用于确定相对姿势估计的改进技术。例如,捕获的用于描述环境视图(并描述两个体积(例如,整个环境的子体积))的点云数据可(在2630、2632)被转换成各自体素化的体积数据结构(例如,基于VOLA的结构),每个体积数据结构代表相对应的体积。然后可以将这些体积数据结构(在2634、2636处)切片或以其他方式转换成2D数据结构(例如,各个2D切片集),并且可以将2D切片(在2638处)作为输入提供,以训练卷积神经网络模型以确定相对姿势估计。实际上,卷积神经网络模型可以基于两个体素化的体积数据结构中描述的体积来生成2640表示相对姿势估计的结果。
图27是根据一些实施例的表示示例多时隙向量处理器(例如,超长指令字(VLIW)向量处理器)的简化框图。在该示例中,向量处理器可以包括多个(例如,9个)功能单元(例如,2703-2711),其可以由多端口存储器系统2700馈送,由向量寄存器堆(VRF)2701和通用寄存器堆(GRF)2702备份。处理器包含指令解码器(IDEC)2712,其解码指令并生成控制功能单元2703-2711的控制信号。功能单元2703-2711是判定式(predicated)执行单元(PEU)2703、分支和重复单元(BRU)2704、负载存储端口单元(例如,LSU0 2705和LSU1 2706)、向量运算单元(VAU)2707、标量运算单元(SAU)2710、比较和移动单元(CMU)2708、整数运算单元(IAU)2711以及体积加速单元(VXU)2800。在该特定实现方式中,VXU 2800可以加速对体积数据的操作,包括存储/检取操作两者、逻辑操作和算术操作。虽然在图27的示例中将VXU电路系统2800示出为单一组件,但应当理解,VXU(以及其他功能单元2703-2711中的任一个)的功能可以被分布在多个电路系统之间。进一步,在一些实现方式中,VXU 2800的功能可以在一些实现方式中被分布在处理器的其他功能单元(例如,2703-2708、2710、2711)中的一个或多个功能单元内,以及其他示例实现方式。
图28是示出了根据一些实施例的VXU 2800的示例实现方式的简化框图。例如,VXU2800可以提供至少一个64位输入端口2801以接受来自向量寄存器堆2801或通用寄存器堆2802的输入。该输入可以与多个功能单元相连接以对64位无符号整数体积位图操作,该多个功能单元包括寄存器堆2803、地址生成器2804、点寻址逻辑2805、点插入逻辑2806、点删除逻辑2807、在X维度中3D到2D投影逻辑2808、在Y维度中3D到2D投影逻辑2809、在Z维度中3D到2D投影逻辑2810、2D直方图金字塔生成器2811、3D直方图金字塔生成器2812、群体计数器2813、2D路径找寻逻辑2814、3D路径找寻逻辑2815和可能的附加功能单元。来自块2802的输出可以被写回到向量寄存器堆VRF 2801或通用寄存器堆GRF 2802寄存器堆。
转到图29的示例,呈现了4^3体素立方体2900的组织的表示。还呈现了第二体素立方体2901。在该示例中,体素立方体可以定义在如64位整数2902的数据中,其中立方体内的每一个单个体素由64位整数中的单个相对应位来表示。例如,在地址{x,y,z}={3,0,3}处的体素2912可以被设置为“1”以指示在由体素立方体2901所表示的体积空间内、该坐标处的几何形状的存在。进一步,在该示例中,所有其他体素(除体素2902外)可以与“空白”空间相对应,并且可以被设置为“0”以指示在那些坐标处不存在物理几何形状,以及其他示例。转到图30,示出了根据一些实施例的示例两级稀疏体素树3000。在该示例中,仅单个“占用的”体素被包括在体积内(例如,在位置{15,0,15})。在该情况下,树3001的上级-0包含单个体素条目{3,0,3}。该体素进而指向树3002的、在元素{3,0,3}中包含单个体素的下一级。在与稀疏体素树的级0相对应的数据结构中的条目是具有一个被设置为占用的体素的64位整数3003。该被设置的体素意味着64位整数的阵列随后被分配到与3003中设置的体素体积相对应的树的级1中。在级1子阵列3004中,仅体素中的一个体素被设置为占用,而所有其他体素被设置为未占用。在该示例中,由于树是两级树,因此级1表示树的底部,使得层级结构终止于此。
图31示出了根据一些实施例的两级稀疏体素树3100,其在特定体积的位置{15,0,3}和{15,0,15}中包含占用的体素。在该情况下(将特定体积细分为64个上级0体素),树3101的上级0包含具有相对应的数据3104的两个体素条目{3,0,0}和{3,0,3},这两个体素条目示出了两个体素被设置(即占用)。稀疏体素树(SVT)的下一级被提供为64位整数的阵列,其包含两个子立方体3102和3103,一个子立方体用于级0中设置的每个体素。在级1子阵列3105中,两个体素被设置为占用:v15和v63,并且所有其他体素被设置为未占用和树。该格式是灵活的,因为在树的下一级中的64个条目总是与在树的上层中的每一个被设置的体素相对应地分配。只要已经设置了上层中的相对应的体素,该灵活性就可以允许以灵活的方式(即,诸如随机地,而不是以固定顺序)将动态变化的场景几何形状插入到现有的体积数据结构中。如果没有设置上层中的相对应的体素,则或者将保持指针的表,这导致更高的存储器要求,或者将需要至少部分地重建树以便插入未预见的几何形状。
图32示出了根据一些实施例的用于存储来自图31的体素的替代技术。在该示例中,整体体积3200包含如图31中的存储在全局坐标{15,0,3}和{15,0,15}处的两个体素。在该方法中,不是分配64个条目的阵列以表示在级0以下的级1中的所有子立方体,而是仅将那些在级1中的实际包含几何形状(例如,如由相对应级0体素是占用者还是非占用者所指示的)的元素分配为相对应的64位级1记录,在该示例中,使得级1仅具有两个64位条目而非64个条目(即,针对64个级1体素中的每一个体素,无论是占用的还是空白的)。因此,在该示例中,第一级0 3204等同于图31中的3104,而下一级3205在存储器要求方面是图23中的相对应的3105的1/62。在一些实现方式中,如果没有已经在级1中为将要插入到级0中的新几何形状分配空间,则树必须被复制和重新排列。
在图32的示例中,可以通过对在当前层以上的层中的占用体素计数来导出子体积。以此方式,系统可以确定在体素数据中一个较高层级在哪里终止以及下一个较低层级在哪里开始。例如,如果三个层级0体素被占用,则系统可以预期三个相对应的层级1条目将跟随在体素数据中,并且(在这三个之后的)下一个条目与层级2中的第一条目相对应,以此类推。在场景的某些部分不随时间变化的情况下,或在应用中需要远程传输体积数据(例如从扫描冥王星表面的宇宙探测器进行远程传输,其中每一位的传输都是昂贵且耗时)的情况下,此类最优压紧可以是非常有用的。
图33示出了根据一些实施例的可以将体素插入到表示为64位整数体积数据结构条目的4^3立方体中的方式,以反映在相对应体积内的几何形状的变化。在一个示例中,如3300中所示的,每一个体素立方体可以被组织为64位整数内的四个逻辑16位平面。每一个平面与Z值0到3相对应,并且在每一个平面内的每一个y值代码用于4个逻辑4位位移0到3,以及最后在每一个4位y平面内的每一个位代码用于x的4个可能值(0到3),以及其他示例组织。因此,在该示例中,为了将体素插入到4^3体积中,首先可以将x值0到3偏移一位,随后可以将该值偏移0/4/8/12位以编码y值,并且最后可以通过偏移0/16/32/48位来表示z值,如3301中的C代码表达式中所示的。最后,由于每一个64位整数可以是多达64个体素的组合,每一个体素被分别编写,因此如3302中所示,通过将旧位图值和新位图值进行或运算,新的位图必须与从稀疏体素树中读取的旧64位值进行逻辑组合。
转到图34,示出了根据一些实施例的表示,以图示如何能够将存储在64位整数3400中的3D体积对象通过在X方向上的逻辑或运算来投影以产生2D图案3401、通过Y方向上的逻辑或运算来投影以产生2D输出3402并且最后通过Z方向上的逻辑或运算来投影以产生3403中所示的图案。图35示出了根据一些实施例的、来自输入64位整数的位如何逻辑地或运算以产生在X、Y和Z方向上的输出投影。在该示例中,表3501逐列示出了对来自输入向量3500的哪些元素索引进行或运算以产生x投影输出向量3502。表3503逐列示出了对来自输入向量3500的哪些元素索引进行或运算以产生y投影输出向量3504。最后表3505逐列示出了对来自输入向量3500的哪些元素索引进行或运算以产生z投影输出向量3506。
X投影对来自输入数据3500的位0、1、2、3进行逻辑或运算以产生X投影3501的位0。例如,可以通过对来自3500的位4、5、6和7进行异或来产生3501中的位1,以此类推。类似地,可以通过对3500的位0、4、8和12一起进行或运算来产生Y投影3504中的位0。并且通过对3500的位1、5、9和13一起进行或运算来产生3504的位1,等等。最后,可以通过对3500的位0、16、32和48一起进行或运算来产生Z投影3506中的位0。并且可以通过对3500的位1、17、33和49一起进行或运算来产生3506的位1,以此类推。
图36示出了根据一些实施例的、如何可以将投影用于生成简化地图的示例。在该场景中,目标可以是从体素体积3600产生路径的紧凑2D地图,高度为h 3610且宽度为w3601的交通工具3602沿该路径行进。此处,Y投影逻辑可以用于从体素体积3602生成初始粗略2D地图3603。在一些实现方式中,可以处理该地图以检查特定维度的特定交通工具(例如,汽车(或自主汽车)、无人机等)是否能够穿过路径的宽度约束3601和高度约束3610。这可以通过执行在Z方向上的投影以检查宽度约束3601并且在Y方向上的投影可以被掩蔽以限制对交通工具高度3610的计算来执行,以便确保路径是可通过的。通过(例如,在软件中)附加的后处理可以看出,对于可通过且仅X和Z满足宽度和高度限制的路径,沿路径的点A3604、B 3605、C 3606、D 3607、E 3608和F 3609的坐标可以仅被存储或通过网络被传输,以便完全重构交通工具可沿其行进的合法路径。假设路径可以被解析成此类分段片段,仅用该路径的每分段线性区域一个字节或两个字节来完全描述路径是可能的。这可以有助于此类路径数据(例如,通过自主交通工具)的快速传输和处理,以及其他示例。
图37示出了根据一些实施例的、可以如何通过数学方法聚合来自嵌入式设备的体积3D测量结果或简单2D测量结果,以便生成高质量众包地图作为使用LIDAR或其他昂贵装置进行精密测量的替代。在所提出的系统中,多个嵌入式设备3700、3701等可以配备有能够取得测量结果的各种传感器,该测量结果可以被传输到中央服务器3710。在服务器上运行的软件执行对所有测量结果的聚合3702并且由非线性解算器3703对结果矩阵执行数值解算以产生高度准确的地图,该地图可以随后被重新分配回到嵌入式设备。实际上,数据聚合还可以包括来自卫星3720、空中LIDAR勘测3721和地面LIDAR测量3722的高精度勘测数据,以在这些高保真度数据集可用的情况下增加所得地图的精度。在一些实现方式中,可以以具有诸如本文中所描述的格式的稀疏体素数据结构来生成地图和/或记录的测量结果、将地图和/或记录的测量结果转换为具有诸如本文中所描述的格式的稀疏体素数据结构、或使用具有诸如本文中所描述的格式的稀疏体素数据结构以其他方式表达地图和/或记录的测量结果,以及其他示例实现方式。
图38是示出根据一些实施例的、如何可以加速在2D 2×2位图上的2D路径找寻的示图。操作的原理是,为使在具有相同网格单元的地图上的点之间存在连接性,在x或y或x和y方向上连续排列的单元的值必须全部被设置为1值。所以,可以实例化从那些单元中汲取的位的逻辑与(AND)以测试在网格中的位图是否存在有效路径,并且可对通过N×N网格的每一个有效路径实例化不同的与门。在一些实例中,该方法可以引入组合复杂度,因为即使8×8 2D网格也可以包含34
图39是根据一些实施例的简化框图,其示出了如何可以使用所提出的体积数据结构来加速碰撞检测。几何形状的3D N×N×N图可以被子采样为由最低细节级别(LoD)2×2×2体积3902、下一最高4×4×4体积3901、8×8×8体积3900、以此类推一直到N×N×N体积构成的金字塔。如果经由诸如GPS的定位方法或经由从3D地图重新定位,在3D空间中已知无人机、交通工具或机器人3905的位置,则随后可以通过将无人机/机器人的x位置、y位置和z位置适当地缩放(将其除以2相关次数)、并且询问3902几何形状的存在(例如,检查相应的位图位是否是指示可能的碰撞的1),来将该位置快速地用于测试几何形状存在或不存在于相关2×2×2子体积的象限中。如果存在可能的碰撞(例如,找到了“1”),则随后可以进一步在体积3901、3900等中执行检查以证实无人机/机器人是否可以移动。然而,如果在3902中的体素是空闲的(例如,“0”),则随后机器人/无人机可以将相同体素解释为空闲空间并且操纵方向控制以自由地移动通过地图的大部分。
虽然本文中所描述并示出的系统和解决方案中的一些已经被描述为包含多个元件或与多个元件相关联,但是不是所有被清晰地示出或描述的元件都用于本公开的每一个替代的实现方式中。另外,可以将元件中的一个或多个定位在系统外部,而在其他实例中,可以将某些元件包括在其他所述的元件以及未在所示的实现方式中描述的其他元件中的一个或多个元件内,或者作为其他所述的元件以及未在所展示的实现方式中描述的其他元件中的一个或多个元件的一部分。进一步,可以将某些元件与其他组件以及用于除本文中所描述的那些目的之外的替代的目的或附加的目的的组件相组合。
进一步,应该理解到,上文所呈现的示例是仅为了说明某些原则和特征的目的而提供的非限制性示例,并且不一定限制或约束本文中所描述的概念的可能的实施例。例如,可以利用本文中所描述的特征和组件的各种组合(包括通过本文中所描述的组件的各种实现方式来实现的组合)来实现各种不同的实施例。应该从本说明书的内容中理解其他实现方式、特征和细节。
图40-图45是可根据本文中所公开的实施例来使用的示例性计算机架构的框图。实际上,本文所描述的系统的计算设备、处理器以及其他逻辑和电路系统可以包含功能的全部或一部分以及实现此类功能的支持软件和/或硬件电路系统。进一步,还可以将本领域已知的用于处理器和计算系统的其他计算机架构设计在这里示出的示例之外使用。一般来说,适用于本文中所公开的实施例的计算机架构可以包括但不限于图40-图45中示出的配置。
图40示出了通过链路耦合到相应的网关的相应的物联网(IoT)网络的示例域拓扑。物联网(IoT)是这样一种概念,其中大量的计算设备彼此互连,并且连接到互联网,以提供非常低级别的功能和数据采集。因此,如本文所使用的,IoT设备可以包括半自主设备,该半自主设备执行与其他IoT设备以及更广泛的网络(诸如因特网)通信的功能(诸如感测或控制等等)。此类IoT设备可以配备有逻辑和存储器以实现和使用(诸如上文所介绍的)散列表。
通常,IoT设备在存储器、大小或功能上受到限制,允许以与较小数量的较大设备类似的成本部署较大数量的IoT设备。然而,IoT设备可以是智能电话、膝上型计算机、平板或PC、或其他较大设备。进一步,IoT设备可以是虚拟设备,诸如在智能电话或其他计算设备上的应用。IoT设备可包括IoT网关,用于将IoT设备耦合到其他IoT设备和将IoT设备耦合到云应用,以进行数据存储、过程控制等。
IoT设备的网络可以包括商业和家庭自动化设备,诸如供水系统、配电系统、流水线控制系统、工厂控制系统、灯开关、恒温器、锁、相机、警报器、运动传感器等。IoT设备可以通过远程计算机、服务器或其他系统来访问,例如,以控制系统或访问数据。
因特网和类似网络的未来增长可能涉及极大量的IoT设备。因此,在本文讨论的技术的上下文中,对于这种未来联网的许多创新将解决对所有这些层不受阻碍地增长、发现连接的资源并使其可访问、以及支持隐藏和划分连接的资源的能力的需求。可以使用任何数量的网络协议和通信标准,其中每一个协议和标准被设计用于解决特定目标。此外,协议是支持人类可访问服务的结构的一部分,这些服务无论位置、时间或空间如何都进行操作。所述创新包括服务递送和相关联的基础设施,诸如硬件和软件、安全增强、以及基于在服务水平和服务递送协议中指定的服务质量(QoS)的服务的提供。如将被理解的,IoT设备和网络(诸如图40和图41中所介绍的那些)的使用在包括有线和无线技术的组合的异构连接网络中提出了许多新的挑战。
图40具体提供了域拓扑的简化图,该域拓扑可用于包括IoT设备4004的多个物联网(IoT)网络,其中IoT网络4056、IoT网络4058、IoT网络4060、IoT网络4062通过主干链路4002耦合到相应的网关4054。例如,多个IoT设备4004可以与网关4054通信,并且通过网关4054与彼此通信。为了简化附图,不是每一个IoT设备4004或通信链路(例如,链路4016、4022、4028或4032)都被标记。主干链路4002可以包括任意数量的有线技术或无线技术(包括光网络),并且可以是局域网(LAN)、广域网(WAN)或因特网的一部分。另外,此类通信链路促进IoT设备4004与网关4054两者之间的光信号路径,包括使用促进各种设备的互连的多路复用/多路分解(MUXing/deMUXing)组件。
网络拓扑可以包括任意数量类型的IoT网络,诸如使用蓝牙低功率(BLE)链路4022与网络4056一起提供的网格网络。可能存在的其他类型的IoT网络包括:无线局域网(WLAN)网络4058,用于通过IEEE 802.11
这些IoT网络中的每一个都可以为新技术特征(诸如本文所描述的那些)提供机会。改进的技术和网络可以使设备和网络指数性增长,包括将IoT网络用作雾设备或系统。随着此类改进技术的使用的增长,可以开发IoT网络用于自我管理、功能演进和协作,而无需直接的人为干预。改进技术甚至可以使IoT网络能够在没有中央控制系统的情况下起作用。因此,本文所描述的改进技术可以用于远超当前实现方式的、自动化和增强网络管理和操作功能。
在示例中,IoT设备4004之间的通信,诸如通过主干链路4002的通信,可以由用于认证、授权和计费(AAA)的分散式系统保护。在分散式AAA系统中,可以跨互连的异构网络基础设施实现分布式支付、贷款、审计、授权和认证系统。这允许系统和网络向自主操作移动。在这些类型的自主操作中,机器甚至可以签约人力资源并与其他机器网络协商伙伴关系。这可以允许实现共同的目标,并实现相对于概述的、计划的服务水平协议的平衡的服务交付,以及实现提供计量、测量、可跟踪性和可追踪性的解决方案。创建新的供应链结构和方法可以在没有人员参与的情况下创建大量服务、挖掘大量服务的价值并使大量服务崩溃。
通过将诸如声音、光、电子交通、面部和模式识别、气味、振动等感测技术集成到IoT设备之间的自主组织中,可以进一步增强此类IoT网络。传感系统的集成可以允许服务交付的相对于合同服务目标、基于服务编排和服务质量(QoS)的资源聚集和融合的系统的且自主的通信和协调。基于网络的资源处理的各个示例中的一些包括以下各项。
例如,网格网络4056可以由执行内联数据到信息变换的系统来增强。例如,包括多链路网络的处理资源的自形成链可以以有效的方式分配原始数据到信息的变换,以及具有在资产和资源以及每一个资产和资源的相关联管理之间进行区分的能力。此外,可以插入基础设施的适当组件和基于资源的信任和服务索引,以提高数据完整性、质量、保证并且提供数据置信度度量。
例如,WLAN网络4058可以使用执行标准转换的系统来提供多标准连接,从而使得IoT设备4004能够使用不同的协议进行通信。其他系统可以提供跨多标准基础设施的无缝互连,多标准基础设施包括可见的因特网资源和隐藏的因特网资源。
例如,蜂窝网络4060中的通信可以通过迁移数据、将通信扩展到更多远程设备或迁移数据并将通信扩展到更多远程设备的系统来增强。LPWA网络4062可以包括执行非网际协议(IP)到IP互连、寻址和路由的系统。此外,每一个IoT设备4004可以包括合适的收发机,该收发机用于与该设备进行广域通信。进一步,每一个IoT设备4004可以包括使用附加的协议和频率进行通信的其他收发机。关于图42和图43中描绘的IoT处理设备的通信环境和硬件进一步讨论了这一点。
最后,IoT设备集群可以被配备成与其他IoT设备以及云网络进行通信。这可以允许IoT设备在设备之间形成自组织(ad-hoc)网络,允许它们用作单个设备,单个设备可以被称为雾设备。以下关于图41进一步讨论了该配置。
图41示出了与作为云计算网络边缘处的雾设备操作的IoT设备(设备4102)的网格网络通信的云计算网络。IoT设备的网格网络可以被称为雾4120,在云4100的边缘处操作。为了简化该图,不是每一个IoT设备4102都被标记。
可以将雾4120认为是大规模地互连的网络,其中数个IoT设备4102例如通过无线电链路4122与彼此进行通信。作为示例,可以使用开放连接基金会(Open ConnectivityFoundation
尽管在本示例中展示三种类型的IoT设备4102:网关4104、数据聚合器4126、以及传感器4128,但可以使用IoT设备4102和功能的任何组合。网关4104可以是提供云4100与雾4120之间通信的边缘设备,并且还可以针对从传感器4128获取的数据(诸如运动数据、流量数据、温度数据等)提供后端处理功能。数据聚合器4126可以从任何数量的传感器4128收集数据,并执行后端处理功能用于分析。结果数据、原始数据或两者可以通过网关4104被传递到云4100。传感器4128可以是完全IoT设备4102,例如,既能够收集数据又能够处理数据的IoT设备。在一些情况下,传感器4128可以在功能上更有限,例如,收集数据并允许数据聚合器4126或网关4104处理数据。
来自任何IoT设备4102的通信可以沿着任何IoT设备4102之间的方便路径(例如,最方便的路径)被传递以到达网关4104。在这些网络中,互连的数目提供了大量冗余,这允许即使在损失数个IoT设备4102的情况下也维持通信。进一步,使用网格网络可以允许使用非常低功率或定位在远离基础设施处的IoT设备4102,因为连接到另一个IoT设备4102的距离可以远小于连接到网关4104的距离。
从这些IoT设备4102提供的雾4120可以被呈现给云4100中的设备(诸如服务器4106)作为位于云4100边缘处的单个设备,例如,雾设备。在该示例中,来自雾设备的警报可以在不被标识为来自雾4102内的特定IoT设备4120的情况下被发送。以这种方式,雾4120可以被认为是分布式平台,该分布式平台提供计算和存储资源以执行处理或数据密集型任务,诸如数据分析、数据聚合和机器学习等。
在一些示例中,可以使用命令式编程风格来配置IoT设备4102,例如,每一个IoT设备4102具有特定功能和通信伙伴。然而,可以以声明式编程风格来配置形成雾设备的IoT设备4102,这允许IoT设备4102重新配置它们的操作和通信,诸如响应于条件、查询和设备故障来确定所需的资源。作为示例,来自位于服务器4106的用户的、与由IoT设备4102监测的设备子集的操作相关的查询可能导致雾4120设备选择回答查询所需的IoT设备4102(诸如特定传感器4128)。然后,来自这些传感器4128的数据在由雾4120设备发送到服务器4106以回答查询之前,可以由传感器4128、数据聚合器4126或网关4104的任何组合进行聚合和分析。在该示例中,雾4120中的IoT设备4102可以基于查询(诸如添加来自流量传感器或温度传感器的数据)来选择所使用的传感器4128。此外,如果IoT设备4102中的一些IoT设备不可操作,则雾4120设备中的其他IoT设备4102可以提供类似的数据(如果可用的话)。
在其他示例中,以上所描述的操作和功能可以由示例形式为电子处理系统的IoT设备机器来体现,根据示例实施例,在该电子处理系统中可以执行指令集或指令序列以使得该电子处理系统执行本文讨论的方法中的任何一种。所述机器可以是IoT设备或IoT网关,包括由个人计算机(PC)、平板PC、个人数字助理(PDA)、移动电话或智能手机、或能够(相继或以其他方式)执行指定要由该机器要采取的动作的指令的任何机器的各方面所体现的机器。此外,虽然在以上的示例中只描述和引用单个机器,但是此类机器也应该被视为包括单独地或联合地执行一组(或多组)指令以执行此处所讨论的方法中的任何一个或多个的机器的任何集合。此外,这些示例和与基于处理器的系统类似的示例应被视为包括由处理器(例如,计算机)控制或操作、以单独地或联合地执行指令来执行在此所讨论的方法论中的任何一种或多种的一个或多个机器的任何集合。在一些实现方式中,可以协作地操作一个或多个多个设备以实现功能和执行本文所描述的任务。在一些情况下,一个或多个主机设备可以供应数据、提供指令、聚合结果或其他方式促成由多个设备提供的联合操作和功能。当功能由单个设备实现时,可以被认为是设备本地的功能;在多个设备作为单个机器操作的实现方式中,该功能可以被认为是设备共同地本地的,并且该设备集合可以提供或消耗由其他远程机器(实现为单个设备或设备集合)提供的结果,以及其他示例实现方式。
例如,图42示出了与多个物联网(IoT)设备通信的云计算网络或云4200的图示。云4200可以表示因特网,或者可以是局域网(LAN),或广域网(WAN),诸如公司的专有网络。IoT设备可以包括任何数量的不同类型的设备,分组在各种组合中。例如,交通控制组4206可以包括沿城市中街道的IoT设备。这些IoT设备可包括交通信号灯、交通流监测器、相机、天气传感器等。交通控制组4206或其他子组可通过有线或无线链路4208(诸如LPWA链路、光学链路等)与云4200通信。进一步,有线或无线子网络4212可以允许IoT设备诸如通过局域网、无线局域网等与彼此通信。IoT设备可以使用另一设备(诸如网关4210或网关4228)来与远程位置(诸如云4200)通信;IoT设备还可以使用一个或多个服务器4230来促进与云4200或与网关4210的通信。例如,一个或多个服务器4230可以作为中间网络节点来操作以支持本地局域网之间的本地边缘云或雾实现方式。此外,所描绘的网关4228可以以云到网关到多个边缘设备(cloud-to-gateway-to-many edge devices)配置来操作(诸如各种IoT设备4214、4220、4224对于云4200中资源的分配和使用是受限的或动态的)。
IoT设备的其他示例组可以包括远程气象站4214、本地信息终端4216、警报系统4218、自动柜员机4220、警报面板4222、或移动交通工具(诸如应急交通工具4224或其他交通工具4226),等等。这些IoT设备中的每一个可以与其他IoT设备、与服务器4204、与另一个IoT雾设备或系统(未示出,但在图41中描绘)、或其中的组合通信。该组IoT设备可以被部署在各种住宅设置、商业设置和工业设置中(包括在私有环境或公共环境两者中)。
如从图42中可以看出的,大量的IoT设备可以通过云4200进行通信。这可以允许不同的IoT设备自主地向其他设备请求或提供信息。例如,一组IoT设备(例如,交通控制组4206)可请求来自一组远程气象站4214的当前天气预报,该组远程气象站4214可在没有人为干预的情况下提供预报。此外,应急交通工具4224可被自动柜员机4220警告:盗窃正在进行。当应急交通工具4224朝自动柜员机4220前进时,它可以访问交通控制组4206以请求到该位置的通行许可,例如,通过将信号灯转变为红灯以在交叉路口阻挡交叉交通达足够的时间以使应急交通工具4224无阻碍地进入交叉路口。
IoT设备集群(诸如远程气象站4214或交通控制组4206)可以被配备成与其他IoT设备以及云4200通信。这可以允许IoT设备在设备之间形成自组织网络,允许它们用作单个设备,单个设备可以被称为雾设备或系统(例如,如上参考图41所述)。
图43是可以存在于IoT设备4350中用于实现本文描述的技术的组件的示例的框图。IoT设备4350可以包括在示例中示出的组件或在以上公开中引用的组件的任何组合。这些组件可被实现为适用于IoT设备4350中的IC、IC的部分、分立电子设备或其他模块、逻辑、硬件、软件、固件或其组合,或被实现为另外并入较大系统的机箱内的组件。另外,图43的框图旨在描绘IoT设备4350的组件的高级视图。然而,所示出的组件中的一些组件可以被省略,可以存在附加的组件,并且可能在其他实现方式中发生所示组件的不同布置。
IoT设备4350可以包括处理器4352,该处理器4352可以是微处理器、多核处理器、多线程处理器、超低压处理器、嵌入式处理器或其他已知的处理元件。处理器4352可以是片上系统(SoC)的一部分,其中处理器4352和其他组件形成为单个集成电路,或者单个封装(诸如来自英特尔(Intel)的爱迪生(Edison
处理器4352可通过互连4356(例如,总线)来与系统存储器4354通信。可使用任何数量的存储器设备来提供给定量的系统存储器。作为示例,存储器可以是根据联合电子器件工程委员会(JEDEC)设计的随机存取存储器(RAM),诸如DDR或移动DDR标准(例如,LPDDR、LPDDR2、LPDDR3或LPDDR4)。在各种实现方式中,单独的存储器设备可以是任何数量的不同封装类型,诸如单管芯封装(SDP)、双管芯封装(DDP)或四管芯封装(Q17P)。在一些示例中,这些设备可以直接焊接到主板上,以提供较薄型的解决方案,而在其他示例中,设备被配置为一个或多个存储器模块,这些存储器模块进而通过给定的连接器耦合至主板。可使用任何数量的其他存储器实现方式,诸如其他类型的存储器模块,例如,不同种类的双列直插存储器模块(DIMM),包括但不限于microDIMM(微DIMM)或MiniDIMM(迷你DIMM)。
为了提供对信息(诸如数据、应用、操作系统等)的持久性存储,存储4358还可经由互连4356而耦合至处理器4352。在示例中,存储4358可经由固态盘驱动器(SSDD)来实现。可用于存储4358的其他设备包括闪存卡(诸如SD卡、microSD卡、xD图片卡,等等)和USB闪存驱动器。在低功率实现方式中,存储4358可以是与处理器4352相关联的管芯上存储器或寄存器。然而,在一些示例中,存储4358可使用微硬盘驱动器(HDD)来实现。此外,附加于或替代所描述的技术,可将任何数量的新技术用于存储4358,诸如阻变存储器、相变存储器、全息存储器或化学存储器,等等。
组件可通过互连4356进行通信。互连4356可包括任何数量的技术,包括工业标准架构(ISA)、扩展ISA(EISA)、外围组件互连(PCI)、外围组件互连扩展(PCIx)、PCI快速(PCIe)或任何数量的其他技术。互连4356可以是例如在基于SoC的系统中使用的专有总线。其他总线系统可被包括,诸如I2C接口、SPI接口、点对点接口、功率总线,等等。
互连4356可将处理器4352耦合至网格收发机4362,以便例如与其他网格设备4364通信。网格收发机4362可使用任何数量的频率和协议,诸如IEEE 802.15.4标准下的2.4千兆赫兹(GHz)传送,使用如由蓝牙
网格收发机4362可使用多种标准或无线电来进行通信以用于不同范围的通信。例如,IoT设备4350可使用基于BLE的或另一低功率无线电的本地收发机与接近的(例如,在约10米内的)设备通信以节省功率。更远的(例如,在约50米内的)网格设备4364可通过ZigBee或其他中间功率无线电而达到。这两种通信技术能以不同的功率水平通过单个无线电发生,或者可通过分开的收发机而发生,分开的收发机例如使用BLE的本地收发机和分开的使用ZigBee的网格收发机。
无线网络收发机4366可被包括,以经由局域网协议或广域网协议来与云4300中的设备或服务通信。无线网络收发机4366可以是遵循IEEE802.15.4或IEEE 802.15.4g标准等的LPWA收发机。IoT设备4350可使用由Semtech和LoRa联盟开发的LoRaWANTm(长距广域网)在广域上通信。本文中所描述的技术不限于这些技术,而是可与实现长距离、低带宽通信(诸如Sigfox和其他技术)的任何数量的其他云收发机一起使用。进一步地,可使用其他通信技术,诸如在IEEE 802.15.4e规范中描述的时分信道跳。
除了针对如本文中所描述的网格收发机4362和无线网络收发机4366而提及的系统之外,还可使用任何数量的其他无线电通信和协议。例如,无线电收发机4362和4366可包括使用扩展频谱(SPA/SAS)通信以实现高速通信的LTE或其他蜂窝收发机。进一步地,可使用任何数量的其他协议,诸如用于中速通信和供应网络通信的
无线电收发机4362和4366可包括与任何数量的3GPP(第三代合作伙伴计划)规范(尤其是长期演进(LTE)、长期演进-高级(LTE-A)和长期演进-高级加强版(LTE-A Pro))兼容的无线电。可以注意到,可选择与任何数量的其他固定的、移动的或卫星通信技术和标准兼容的无线电。这些可包括例如任何蜂窝广域无线通信技术,其可包括例如第5代(5G)通信系统、全球移动通信(GSM)无线电通信系统、通用分组无线电服务(GPRS)无线电通信技术、或GSM演进(EDGE)增强数据速率无线电通信技术、UMTS(通用移动电信系统)通信技术,除了上面列出的标准外,任何数量的卫星上行链路技术都可以用于无线网络收发机4366,包括例如符合由ITU(国际电信联盟)或ETSI(欧洲电信标准协会)发布标准的无线电等。本文中所提供的示例因此可被理解为适用于各种现有的和尚未制定的各种其他通信技术。
网络接口控制器(NIC)4368可被包括以提供到云4300或到其他设备(诸如网格设备4364)的有线通信。有线通信可提供以太网连接,或可基于其他类型的网络,诸如控制器区域网(CAN)、本地互连网(LIN)、设备网络(DeviceNet)、控制网络(ControlNet)、数据高速路+、现场总线(PROFIBUS)或工业以太网(PROFINET),等等。附加的NIC 4368可被包括以允许到第二网络的连接,例如,NIC 4368通过以太网提供到云的通信,并且第二NIC 4368通过另一类型的网络提供到其他设备的通信。
互连4356可将处理器4352耦合至外部接口4370,该外部接口4370用于连接外部设备或子系统。外部设备可包括传感器4372,诸如加速度计、水平传感器、流量传感器、光学光传感器、相机传感器、温度传感器、全球定位系统(GPS)传感器、压力传感器、气压传感器,等等。外部接口4370可进一步用于将IoT设备4350连接至致动器4374(诸如电源开关、阀致动器、可听见声音发生器、视觉警告设备等)。
在一些任选的示例中,各种输入/输出(I/O)设备可存在于IoT设备4350内,或可连接至IoT设备4350。例如,显示器或其他输出设备4384可被包括以显示信息,诸如传感器读数或致动器位置。输入设备4386(诸如触摸屏或键区)可被包括以接受输入。输出设备4384可包括任何数量的音频或视觉显示形式,包括:简单视觉输出,诸如二进制状态指示器(例如,LED);多字符视觉输出;或更复杂的输出,诸如显示屏(例如,LCD屏),其具有从IoT设备4350的操作生成或产生的字符、图形、多媒体对象等的输出。
电池4376可为IoT设备4350供电,但是在其中IoT设备4350被安装在固定位置的示例中,该IoT设备4350可具有耦合至电网的电源。电池4376可以是锂离子电池、金属-空气电池(诸如锌-空气电池、铝-空气电池、锂-空气电池),等等。
电池监测器/充电器4378可被包括在IoT设备4350中以跟踪电池4376的充电状态(SoCh)。电池监测器/充电器4378可用于监测电池4376的其他参数以提供失效预测,诸如电池4376的健康状态(SoH)和功能状态(SoF)。电池监测器/充电器4378可包括电池监测集成电路,诸如来自线性技术公司(Linear Technologies)的LTC4020或LTC2990、来自亚利桑那州的凤凰城的安森美半导体公司(ON Semiconductor)的ADT7488A、或来自德克萨斯州达拉斯的德州仪器公司的UCD90xxx族的IC。电池监测器/充电器4378可通过互连4356将关于电池4376的信息传递至处理器4352。电池监测器/充电器4378也可包括允许处理器4352直接监测电池4376的电压或来自电池4376的电流的模数(ADC)转换器。电池参数可被用于确定IoT设备4350可执行的动作,诸如传输频率、网格网络操作、感测频率,等等。
功率块4380或耦合至电网的其他电源可与电池监测器/充电器4378耦合以对电池4376充电。在一些示例中,功率块4380可用无线功率接收机代替,以便例如通过IoT设备4350中的环形天线来无线地获得功率。无线电池充电电路(诸如来自加利福尼亚州的苗比达市的线性技术公司的LTC4020芯片,等等)可被包括在电池监测器/充电器4378中。所选择的特定的充电电路取决于电池4376的尺寸,并因此取决于所要求的电流。可使用由无线充电联盟(Airfuel Alliance)颁布的Airfuel标准、由无线电力协会(Wireless PowerConsortium)颁布的Qi无线充电标准、或由无线电力联盟(Alliance for Wireless Power)颁布的Rezence充电标准等等来执行充电。
存储4358可包括用于实现本文中公开的技术的软件、固件或硬件命令形式的指令4382。虽然此类指令4382被示出为被包括在存储器4354和存储4358中的代码块,但是可以理解,可用例如被建立到专用集成电路(ASIC)中的硬连线电路替换代码块中的任一个。
在示例中,经由存储器4354、存储4354或处理器4352提供的指令4382可具体化为非瞬态机器可读介质4360,该非瞬态机器可读介质4360包括用于指示处理器4352执行IoT设备4350中的电子操作的代码。处理器4352可通过互连4356访问非瞬态机器可读介质4360。例如,非瞬态机器可读介质4360可由针对图43的存储4358所描述的设备来具体化,或者可包括特定的存储单元,诸如光盘、闪存驱动器或任何数量的其他硬件设备。非瞬态机器可读介质4360可包括用于指示处理器4352执行例如像参照上文中描绘的操作和功能的(多个)流程图和(多个)框图而描述的特定的动作序列或动作流的指令。
图44是根据实施例的处理器的示例图示。处理器4400是可以与上文的实现方式结合使用的一种类型的硬件设备的示例。处理器4400可以是任何类型的处理器,诸如微处理器、嵌入式处理器、数字信号处理器(DSP)、网络处理器、多核处理器、单核处理器、或用于执行代码的其他设备。虽然在图44中图示出仅一个处理器4400,但处理元件可替代地包括多于一个的图44中所图示的处理器4400。处理器4400可以是单线程核,或者对于至少一个实施例,处理器4400可以是多线程的,因为其每个核可包括多于一个硬件线程上下文(或“逻辑处理器”)。
图44还示出根据实施例的耦合至处理器4400的存储器4402。存储器4402可以是对于本领域技术人员而言已知或以其他方式可用的各种各样的存储器(包括存储器层级结构的各层)中的任何存储器。此类存储器元件可以包括但不限于随机存取存储器(RAM)、只读存储器(ROM)、现场可编程门阵列(FPGA)的逻辑块、可擦除可编程只读存储器(EPROM)、以及电可擦除可编程ROM(EEPROM)。
处理器4400可以执行与本文中详细描述的算法、过程、或操作相关联的任何类型的指令。一般而言,处理器4400可以将元件或制品(例如,数据)从一种状态或事物变换成另一种状态或事物。
代码4404(其可以是用于由处理器4400执行的一条或多条指令)可被存储在存储器4402中,或者可被存储在软件、硬件、固件、或其任何合适的组合中,或者在适当的情况下并且基于特定需要而被存储在任何其他内部或外部组件、设备、元件、或对象中。在一个示例中,处理器4400可以遵循由代码4404指示的指令的程序序列。每条指令进入前端逻辑4406并且由一个或多个解码器4408处理。解码器可生成诸如采用预定义格式的固定宽度的微操作之类的微操作作为其输出,或者可生成反映原始代码指令的其他指令、微指令、或控制信号。前端逻辑4406还包括寄存器重命名逻辑4410和调度逻辑4412,调度逻辑4412一般分配资源并对与供执行的指令对应的操作进行排队。
处理器4400还可以包括具有一组执行单元4416a、4416b、4416n等的执行逻辑4414。一些实施例可以包括专用于指定功能或功能集的大量执行单元。其他实施例可包括仅一个执行单元或可以执行特定功能的一个执行单元。执行逻辑4414执行由代码指令指定的操作。
在对由代码指令指定的操作的执行完成之后,后端逻辑4418可以对代码4404的指令进行引退。在一个实施例中,处理器4400允许乱序执行但要求对指令的有序引退。引退逻辑4420可以采取各种已知的形式(例如,重排序缓冲区等等)。以此方式,至少对于由解码器所生成的输出、硬件寄存器和由寄存器重命名逻辑4410利用的表以及由执行逻辑4414修改的任何寄存器(未示出)而言,处理器4400在代码4404的执行期间被转换。
虽然未在图44中示出,但处理元件可包括与处理器4400一起处于芯片上的其他元件。例如,处理元件可包括与处理器4400一起的存储器控制逻辑。处理元件可包括I/O控制逻辑和/或可包括与存储器控制逻辑一起被集成的I/O控制逻辑。处理元件还可包括一个或多个高速缓存。在一些实施例中,非易失性存储器(诸如闪存或熔丝)也可与处理器4400一起被包括在芯片上。
图45图示出根据实施例的以点对点(PtP)配置布置的计算系统4500。具体而言,图45示出了其中处理器、存储器以及输入/输出设备通过数个点对点接口互连的系统。一般而言,本文中所描述的计算系统中的一个或多个计算系统能以与计算系统4500相同或类似的方式来配置。
处理器4570和4580还可各自包括集成存储器控制器逻辑(MC)4572和4582以与存储器元件4532和4534通信。在替代实施例中,存储器控制器逻辑4572和4582可以是与处理器4570和4580分开的分立逻辑。存储器元件4532和/或4534可以存储要由处理器4570和4580用来获取本文中所概述的操作和功能中的各种数据。
处理器4570和4580可以是任何类型的处理器,诸如结合其他附图所讨论的那些处理器。处理器4570和4580可经由分别使用点对点(PtP)接口电路4578和4588的点对点接口4550来交换数据。处理器4570和4580可各自经由使用点对点接口电路4576、4586、4594和4598的各个点对点接口4552和4554与芯片组4590交换数据。芯片组4590还可以使用接口电路4592(其可以是PtP接口电路)经由高性能图形接口4539来与高性能图形电路4538交换数据。在替代实施例中,图45中所图示的PtP链路中的任一者或全部可被实现为多分支总线而不是PtP链路。
芯片组4590可经由接口电路4596与总线4520通信。总线4520可具有通过该总线通信的一个或多个设备,诸如总线桥4518和I/O设备4516。经由总线4510,总线桥4518可与其他设备通信,这些其他设备诸如用户接口4512(诸如键盘、鼠标、触摸屏、或其他输入设备)、通信设备4526(诸如调制解调器、网络接口设备、或可通过计算机网络4560通信的其他类型的通信设备)、音频I/O设备4514、和/或数据存储设备4528。数据存储设备4528可存储代码4530,该代码4530可由处理器4570和/或4580执行。在替代实施例中,总线架构的任何部分可利用一个或多个PtP链路来实现。
图45中所描绘的计算机系统是可用于实现本文中所讨论的各实施例的计算系统的实施例的示意性图示。将会领会,图45中所描绘的系统的各组件能以芯片上系统(SoC)架构或以能够实现本文中所提供的示例和实现方式的功能和特征的任何其他合适的配置来组合。
在进一步的示例中,机器可读介质也包括任何有形介质,该有形介质能够存储、编码或携带供由机器执行并且使机器执行本公开方法中的任何一种或多种方法的指令,或者该有形介质能够储存、编码或携带由此类指令利用或与此类指令相关联的数据结构。“机器可读介质”因此可包括但不限于固态存储器、光学介质和磁介质。机器可读介质的特定示例包括非易失性存储器,作为示例,包括但不限于:半导体存储器设备(例如,电可编程只读存储器(EPROM)、电可擦除可编程只读存储器(EEPROM)和闪存设备);诸如内部硬盘及可移除盘之类的磁盘;磁光盘;以及CD-ROM和DVD-ROM盘。可使用传输介质,经由网络接口设备,利用多种传输协议中的任何一种协议(例如,HTTP),进一步通过通信网络来传送或接收由机器可读介质具体化的指令。
应当理解,在本说明书中所描述的功能单元或能力可被称为或标记为组件或模块,从而特别强调其实现方式的独立性。此类组件可由任何数量的软件或硬件形式来具体化。例如,组件或模块可以被实现成硬件电路,该硬件电路包括定制的超大规模集成(VLSI)电路或门阵列、诸如逻辑芯片、晶体管之类的现成的半导体,或其他分立的组件。组件或模块也可被实现在可编程硬件设备中,诸如现场可编程门阵列、可编程阵列逻辑、可编程逻辑器件等。组件或模块也可被实现在由各种类型的处理器所执行的软件中。可执行代码的所标识的组件或模块可以例如包括计算机指令的一个或多个物理或逻辑框,其可被组织成例如对象、过程、或函数。然而,所标识的组件或模块的可执行文件不必在物理上在一起,而是可包括存储在不同位置中的不同指令,当这些指令在逻辑上结合在一起时,包括组件或模块,并且针对该组件或模块实现所声称的目的。
实际上,可执行代码的组件或模块可以是单条指令或许多指令,并且甚至可以分布在若干不同的代码段上,分布在不同的程序之间以及跨若干存储器设备或处理系统分布。具体而言,所描述的过程的一些方面(诸如代码重写和代码分析)可发生在与代码部署在其中的处理系统(例如,在嵌入在传感器或机器人中的计算机中)不同的处理系统(例如,在数据中心中的计算机中)上。类似地,操作数据在此可被标识并图示在组件或模块内,并且能以任何合适的形式被具体化并被组织在任何合适类型的数据结构内。操作数据可以被收集为单个数据集,或者可分布在不同位置上(包括分布在不同的存储设备上),并且可以至少部分地仅作为电子信号而存在于系统或网络上。组件或模块可以是无源或有源的,包括可操作以执行期望功能的代理。
当前所描述的方法、系统和设备实施例的附加示例包括下列非限制性的配置。下列非限制性示例中的每一个示例可以独立存在,或可以与以下所提供的或遍及本公开的其他示例中的一个或更多示例按照任何排列或组合进行结合。
尽管已经在某些实现方式和一般相关联方法的方面描述了本公开,但这些实现方式和方法的更改和置换将对于本领域技术人员来说是显而易见的。例如,本文中描述的动作可以以与所描述的顺序不同的顺序来执行,并仍获得期望的结果。作为一个示例,所附附图中描绘的过程并不一定要求所示的特定顺序、或顺序地来实现所期望的结果。在某些实现方式中,多任务处理和并行处理可能是有利的。另外,也可以支持其他用户界面布局和功能。其他变型落在所附权利要求的范围之内。
虽然本说明书包含许多具体实现细节,但这些具体实现细节不应当被解释为对任何发明或可声称权利的范围的限制,而是被解释为针对特定发明的特定实施例的特征的描述。也可将在本说明书中单独的各实施例的情境中所描述的某些特征以组合的形式,在单个实施例中实现。反之,也可单独地在多个实施例中,或在任何合适的子组合中实现在单个实施例的情境中所描述的各种特征。此外,虽然在上文中可能将多个特征描述为以某些组合的方式起作用且甚至最初是如此要求保护的,但是,在一些情况下,可将来自所要求保护的组合的一个或多个特征从组合中删除,并且所要求保护的组合可以针对子组合或子组合的变型。
类似地,虽然在附图中以特定顺序描绘了多个操作,但不应当将此理解为要求按所示的特定顺序或顺序地执行此类操作,或者要求要执行所有示出的操作才能达成期望的结果。在某些情况下,多任务处理和并行处理可能是有利的。此外,不应当将上文所描述的各实施例中的各种系统组件分开理解为在所有实施例中都要求进行此类分开,并且应当理解,一般可将所描述的程序组件和系统一起集成在单个的软件产品中,或将其封装近多个软件产品中。
以下示例与根据本说明书的实施例有关。示例1是一种设备,包括:数据处理设备;存储器,用于存储表示三维(3D)体积的体积数据结构,其中该体积数据结构包括稀疏的分层体积数据结构,并且该体积数据结构包括较高级别体素集,其中每个较高级别体素以第一分辨率表示3D体积中的各个子体积,每个较高级别体素包括较低级别体素集,较低级别体素集以更高的第二分辨率表示各个较高级别体素的子体积;以及光线投射器,该光线投射器可由数据处理设备执行以执行光线投射算法,其中,该光线投射算法将该体积数据结构作为输入,并且执行光线投射算法包括:将来自参考点的多条光线投射到3D体积中;对于多条光线中的每条光线,遍历该光线以确定该体素集中的体素是否被该光线相交并被占用,其中,根据近似遍历来遍历该光线。
示例2包括示例1的主题,其中,遍历光线包括从体积数据结构确定仅较高级别体素集中的子集包含各个被几何形状占用的较低级别体素。
示例3包括示例2的主题,其中,遍历光线进一步包括:确定与光线相交的较低级别体素的子集,其中基于近似遍历少于与光线相交的所有较低级别体素在子集中。
示例4包括示例2-3中任一项的主题,其中,遍历光线包括跳过对每个较高级别体素中、基于体积数据结构被确定为不包含占用的较低级别体素的较低级别体素的分析。
示例5包括示例4的主题,其中,分析包括在与较高级别体素子集相对应的光线的多个点处检查较高级别体素子集中的一个子集内并且与光线相交的较低级别体素是否被占用,其中较高级别级体素子集内并且与光线相交的较低级别级体素的子集不基于近似遍历来检查。
示例6包含示例5的主题,其中,多个点与基于近似遍历的定义的间隔相对应。
示例7包括示例6的主题,其中,所定义的间隔包括与特定尺寸中的较低级别体素的长度相关联的距离。
示例8包括示例7的主题,其中,光线投射器进一步确定特定方向,其中特定尺寸包括光线的主要方向分量。
示例9包括示例4-8中任一项的主题,其中,对较高级别体素的每个子集中的较低级别体素的分析包括访问存储器以检取体积数据结构的相对应部分,其中不从存储器中检取与确定不包含已占用的较低级体素的较高级体素相对应的体积数据结构的部分。
示例10包括示例1-9中的任一项的主题,其中,光线投射算法是使用电路系统实现的SLAM流水线的一部分。
示例11包括示例1-9中的任一项的主题,其中,结合图形渲染应用来执行光线投射算法。
示例12包括示例1-10中任一项的主题,其中,体积数据结构包括第一条目,用于表示每个较高级别体素中的几何形状的存在,并且进一步包括第二条目组,其中第二条目组中的每个条目代表较高级别体素的子集之一中的各个较低级别体素。
示例13包括示例12的主题,其中,第一条目和第二条目包括在相应条目中描述的每个体素的二进制值,并且相应的二进制值指示相对应的体素是否被占用。
示例14包括示例1-13中任一项的主题,其中,数据处理设备包括视觉处理单元(VPU)。
示例15包括示例1-14中任一项的主题,其中,该设备包括机器人或无人机中的一个。
示例16是一种方法,包括:从计算机存储器访问体积数据结构,其中该体积数据结构表示三维(3D)体积,该体积数据结构包括稀疏的分层体积数据结构,并且该体积数据结构包括较高级别体素集,其中每个较高级别体素以第一分辨率表示3D体积中的各个子体积,每个较高级别体素包括较低级别体素集,以更高的第二分辨率表示各个较高级别体素的子体积;以及执行光线投射算法,其中,该光线投射算法将该体积数据结构作为输入,并且执行光线投射算法包括:将来自参考点的多条光线投射到3D体积中;以及对于多条光线中的每条光线,遍历该光线以确定该体素集中的体素是否被该光线相交并被占用,其中,根据近似遍历来遍历该光线。
示例17包括示例16的主题,其中,遍历光线包括从体积数据结构确定仅较高级别体素集中的子集包含各个被几何形状占用的较低级别体素。
示例18包括示例17的主题,其中遍历光线进一步包括:确定与光线相交的较低级别体素的子集,其中基于近似遍历、少于与光线相交的所有较低级别体素在子集中。
示例19包括示例17-18中任一项的主题,其中遍历光线包括跳过对每个较高级别体素中、基于体积数据结构被确定为不包含占用的较低级别体素的较低级别体素的分析。
示例20包括示例19的主题,其中分析包括在与较高级别体素子集相对应的光线的多个点处检查较高级别体素子集中的一个子集内并且与光线相交的较低级别体素是否被占用,其中较高级别级体素子集内并且与光线相交的较低级别级体素的子集不基于近似遍历来检查。
示例21包含示例20的主题,其中多个点与基于近似遍历的定义的间隔相对应。
示例22包括示例21的主题,其中,所定义的间隔包括与特定尺寸中的较低级别体素的长度相关联的距离。
示例23包括示例22的主题,其中光线投射器进一步用于确定特定方向,其中特定尺寸包括光线的主要方向分量。
示例24包括示例19-23中任一项的主题,其中对较高级别体素的每个子集中的较低级别体素的分析包括访问存储器以检取体积数据结构的相对应部分,其中不从存储器中检取与确定不包含已占用的较低级体素的较高级体素相对应的体积数据结构的部分。
示例25包括示例16-24中的任一项的主题,其中,光线投射算法是使用电路系统实现的SLAM流水线的一部分。
示例26包括示例16-24中的任一项的主题,其中,结合图形渲染应用来执行光线投射算法。
示例27包括示例16-26中任一项的主题,其中,体积数据结构包括第一条目,用于代表每个更高级别体素中的几何形状的存在,并且进一步包括第二条目组,其中第二条目组中的每个条目代表较高级别体素的子集之一中的各个较低级别体素。
示例28包括示例27的主题,其中,第一条目和第二条目包括在相应条目中描述的每个体素的二进制值,并且相应的二进制值指示相对应的体素是否被占用。
示例29是一种系统,包括用于执行如权利要求16-28中任一项所述的方法的装置。
示例30包括示例29的主题,其中该装置包括其上存储有指令的机器可读存储介质,其中该指令可由机器执行以执行示例16-28中任一项的方法的至少一部分。
示例32是一种设备,包括:数据处理设备;存储器;测程引擎,可由数据处理设备执行,以用于:将视觉数据输入到神经网络模型的第一网络部分,其中,第一网络部分基于视觉数据来生成第一值;将惯性数据输入到神经网络模型的第二部分,其中第二网络部分基于惯性数据来生成第二值;将第一值和第二值作为输入提供给神经网络模型的完全连接层组;以及从完全连接层生成神经网络模型的输出,其中输出包括基于视觉数据和惯性数据的姿势值。
示例32包括示例31的主题,其中,第一网络部分包括视觉测程神经网络部分,而第二网络部分包括惯性测程神经网络部分。
示例33包括示例31-32中任一项的主题,其中,第一网络部分包括多个卷积神经网络层和第一完全连接层组。
示例34包括示例33的主题,其中,第一网络部分包括基于FlowNetS的卷积神经网络(CNN)的层。
示例35包括示例31-34中任一项的主题,其中,第二网络部分包括基于长短期记忆(LSTM)的神经网络和第二完全连接层组。
示例36包括示例31-35中任一项的主题,其中,视觉数据包括连续RGB图像的对。
示例37包括示例31-36中任一项的主题,其中,惯性数据包括由惯性测量单元(IMU)设备生成的惯性数据的子序列。
示例38包括示例31-37中的任一项的主题,其中,测程引擎进一步将第一和第二值级联起来,以生成用于完全连接层组的输入。
示例39包括示例31-38中任一项的主题,进一步包括控制器,该控制器用于基于姿势值来确定自主设备的运动方向。
示例40包括示例39的主题,其中,自主设备包括机器人或无人机中的一个。
示例41包括示例39-40中任一项的主题,进一步包括自主设备。
示例42是一种方法,包括:接收描述环境的视觉数据;接收描述设备运动的惯性数据;将视觉数据作为输入提供给神经网络模型的第一网络部分,其中第一网络部分基于视觉数据来生成第一值;将惯性数据作为输入提供给神经网络模型的第二部分,其中第二网络部分基于惯性数据来生成第二值;将第一值和第二值作为输入提供给神经网络模型的完全连接层组;以及从完全连接层生成神经网络模型的输出,其中输出包括基于视觉数据和惯性数据的姿势值。
示例43包括示例42的主题,其中,第一网络部分包括视觉测程神经网络部分,而第二网络部分包括惯性测程神经网络部分。
示例44包括示例42-43中任一项的主题,其中,第一网络部分包括多个卷积神经网络层和第一完全连接层组。
示例45包括示例44的主题,其中,第一网络部分包括基于FlowNetS的卷积神经网络(CNN)的层。
示例46包括示例42-45中任一项的主题,其中,第二网络部分包括基于长短期记忆(LSTM)的神经网络和第二完全连接层组。
示例47包括示例42-46中任一项的主题,其中,视觉数据包括连续RGB图像的对。
示例48包括示例42-47中任一项的主题,其中,惯性数据包括由惯性测量单元(IMU)设备生成的惯性数据的子序列。
示例49包括示例42-48中的任一项的主题,进一步包括将第一和第二值级联起来,以生成用于完全连接层组的输入。
示例50包括示例42-49中任一项的主题,进一步包括基于姿势值来确定设备的运动方向。
示例51包括示例50的主题,进一步包括在该方向上致动设备的运动。
示例52是一种系统,包括用于执行如权利要求42-51中任一项所述的方法的装置。
示例53包括示例22的主题,其中该装置包括其上存储有指令的机器可读存储介质,其中该指令可由机器执行以执行示例42-51中任一项的方法的至少一部分。
示例54是一种系统,包括:自主设备,其包括:处理器;用于生成惯性数据的惯性测量单元(IMU)设备;用于生成视觉数据的相机传感器;测距引擎,用于:将视觉数据作为输入提供给神经网络模型的第一网络部分,其中第一网络部分基于视觉数据来生成第一值;将惯性数据作为输入提供给神经网络模型的第二部分,其中第二网络部分基于惯性数据来生成第二值;提供第一值和第二值作为神经网络模型的完全连接层组的输入;以及从完全连接层生成神经网络模型的输出,其中输出包括基于视觉数据和惯性数据的姿势值。
示例55包括示例54的主题,进一步包括控制器,该控制器用于基于姿势值来确定自主设备的运动方向。
示例56包括示例55的主题,进一步包括致动器,用于致使自主设备至少部分地基于姿势值来在方向上自主移动。
示例57包括示例54-55中任一项的主题,其中,第一网络部分包括视觉测程神经网络部分,而第二网络部分包括惯性测程神经网络部分。
示例58包括示例54-57中任一项的主题,其中,第一网络部分包括多个卷积神经网络层和第一完全连接层组。
示例59包括示例58的主题,其中,第一网络部分包括基于FlowNetS的卷积神经网络(CNN)的层。
示例60包括示例54-59中任一项的主题,其中,第二网络部分包括基于长短期记忆(LSTM)的神经网络和第二完全连接层组。
示例61包括示例54-60中任一项的主题,其中,视觉数据包括连续RGB图像的对。
示例62包括示例54-61中任一项的主题,其中,惯性数据包括由惯性测量单元(IMU)设备生成的惯性数据的子序列。
示例63包括示例54-62中的任一项的主题,其中,测程引擎进一步用于将第一值和第二值级联起来,以生成用于完全连接层组的输入。
示例64包括示例54-63中任一项的主题,进一步包括控制器,该控制器用于基于姿势值来确定自主设备的运动方向。
示例65包括示例64的主题,其中,自主设备包括机器人或无人机中的一个。
示例66是一种设备,包括:数据处理设备;存储器,用于存储表示第一3D体积的第一体积数据结构和表示第二3D体积的第二体积数据结构;以及可由数据处理设备执行的相对姿势估计工具,用于:将第一体积数据结构转换为第一组2D网格;将第二体积数据结构转换为第二组2D网格;提供体素网格对作为卷积神经网络(CNN)的输入,其中该体素网格对包括第一组2D网格之一和第二组2D网格之一;以及使用CNN生成该体素网格对的相对姿势值。
示例67包括示例66的主题,其中,相对姿势估计工具进一步用于确定CNN的损失函数,其中,将损失函数应用于相对姿势值的生成中。
示例68包括示例66-67中任一项的主题,其中,针对来自第一组2D网格和第二组2D网格的一组2D网格对确定相对姿势值,以确定第一3D体积和第二3D体积的相对姿势估计。
示例69包括示例66-68中任一项的主题,其中,第一体积数据结构表示第一3D体积的点云,而第二体积数据结构表示第二3D体积的点云。
示例70包括示例66-69中任一项的主题,其中,CNN包括2D CNN。
示例71包括示例66-70中任一项的主题,其中,CNN包括表示部分和回归部分,将体素网格对作为输入提供给表示部分,该表示部分基于该体素网格对来生成特征向量,该特征向量被提供作为回归部分的输入,并且相对姿势值包括回归部分的输出。
示例72包括示例71的主题,其中,表示部分包括暹罗网络而回归部分包括完全连接层。
示例73包括示例66-72中任一项的主题,进一步包括自主设备。
示例74包括示例73的主题,其中,自主设备包括机器人或无人机中的一个。
示例75是一种方法,包括:从计算机存储器访问用于表示第一3D体积的第一体积数据结构和用于表示第二3D体积的第二体积数据结构;将第一体积数据结构转换为第一组2D网格;将第二体积数据结构转换为第二组2D网格;提供第一组2D网格和第二组2D网格作为卷积神经网络(CNN)的输入;以及使用CNN基于第一3D体积和第二3D体积生成相对姿势值。
示例76包括示例75的主题,进一步包括:确定CNN的损失函数;以及将损失函数应用于相对姿势值的生成。
示例77包括示例75-76中任一项的主题,其中,CNN包括2D卷积层。
示例78包括示例75-77中任一项的主题,其中,CNN包括表示部分和回归部分,将第一组2D网格和第二组2D网格作为输入提供给表示部分,表示部分生成作为输出的特征向量,将特征向量作为输入提供给回归部分,并且相对姿势值包括回归部分的输出。
示例79包括示例78的主题,其中,表示部分包括暹罗网络而回归部分包括完全连接层。
示例80是一种系统,包括用于执行如权利要求75-79中任一项所述的方法的装置。
示例81是一种非瞬态机器可读存储介质,其上存储有指令,当所述指令由机器执行时使所述机器用于:从计算机存储器访问用于表示第一3D体积的第一体积数据结构和用于表示第二3D体积的第二体积数据结构;将第一体积数据结构转换为第一组2D网格;将第二体积数据结构转换为第二组2D网格;提供第一组2D网格和第二组2D网格作为卷积神经网络(CNN)的输入;以及使用CNN基于第一3D体积和第二3D体积生成相对姿势值。
示例82包括示例81的主题,进一步包括:确定CNN的损失函数;以及将损失函数应用于相对姿势值的生成。
示例83包括示例81-82中任一项的主题,其中,CNN包括2D卷积层。
示例84包括示例81-83中任一项的主题,其中CNN包括表示部分和回归部分,将第一组2D网格和第二组2D网格作为输入提供给表示部分,表示部分生成作为输出的特征向量,将特征向量作为输入提供给回归部分,并且相对姿势值包括回归部分的输出。
示例85包括示例84的主题,其中,表示部分包括暹罗网络,而回归部分包括完全连接层。
示例86包括示例81-85中的任一项的主题,其中,第一体积数据结构和第二体积数据结构中的一个或两个是根据相对应点云数据的体素化生成的。
因此,己经描述了主题的具体实施例。其他实施例在以下权利要求的范围内。在一些情况下,权利要求书中所列举的动作可以用不同顺序来执行,并且仍然获得期望结果。此外,在附图中描绘的过程不一定需要所示出的特定顺序或相继顺序来实现期望的结果。
- 计算机视觉训练系统和用于训练计算机视觉系统的方法
- 医用计算机视觉设备的散热装置及医用计算机视觉设备