基于深度感知增强的多曝光图像融合方法
文献发布时间:2023-06-19 13:46:35
技术领域
本发明涉及一种计算机图像处理方法,尤其涉及一种图像融合、HDR图像生成方法。
背景技术
在用手机或相机拍摄图像时,常常会遇到一个状况:无论怎样调节曝光时间和光圈大 小等参数都很难拍摄出一张最优曝光图像。即便图像整体处于较好的曝光度,也总会有一 部分区域处于过曝或欠曝的状态。这是由于自然场景下的动态范围往往远远大于消费级相 机所能记录的动态范围,因而单张拍摄的低动态范围(LDR)图像只能记录有限动态范围 的信息,无法全面地还原场景的全部信息。为了全面记录场景、获取高质量图像,高动态 范围(HDR)成像技术应运而生。高动态范围成像技术的实现一般分为两类:一类是通过专业的HDR成像设备来直接获取,而这种方法对硬件要求极高,应用范围较窄;另一类即 通过软件算法实现,多曝光图像融合即为其中十分有效的一种方案。而且,图像融合的过 程无需专业设备的支持和如相机响应函数估计等额外的专业知识,可应用于手机等普通成像设备,算法操作简单直接,易于使用。
现有的多曝光图像融合方法往往需要比较长的不同曝光图像序列来完整覆盖被摄场景 的动态范围,且只在各图像间曝光差异较小时才能生成效果较好的融合图像。这在很大程 度上限制了算法的适用范围,因为实际应用时,可能是对已有的图像进行融合,而已有源 图像序列可能张数很少,甚至只有不同曝光的两张图像;即使是在实时拍摄图像时,拍摄 绵密而冗长的曝光序列也是一种效率很低的实现方式,它会显著增加存储空间的占用、使 拍摄和处理的时间明显变长,更重要的是,较长的拍摄时间下,被摄场景内的物体可能产 生明显的移动,从而导致融合图像内出现伪影,严重影响图像质量。此外,由于现有方法 往往仅考虑融合图像的结构和细节信息,缺乏针对提升视觉观感的考虑,容易使得融合图 像出现颜色苍白等问题。
多曝光图像融合领域已经在过去的几十年里得到了广泛的关注和发展。领域内的很多 工作,尤其是较早期的工作,主要基于传统机器方法实现。传统方法主要可以细分为空间 域方法[1][2]和变换域方法[3][4]等。传统方法由于依靠手工设计特征和融合策略,其特征提 取和整合能力往往相对有限,因而对不同场景的鲁棒性相对较差,并且一般需要较长且间 隔较小的多曝光序列才能产生较好的融合效果。当源图像曝光差异较大、数量较少时,其 融合结果的质量会显著下降,并且容易出现明显的视觉伪影。
近些年来,随着深度神经网络的发展和广泛应用,基于深度学习的方法逐渐成为多曝 光融合领域的主流,有非常多新的优秀工作涌现出来。基于深度学习的方法主要可分为无 监督方法和有监督方法两类。无监督的多曝光融合方法主要依靠设计或选取无监督的图像 质量评价指标[5][6]作为损失函数,或利用亮度、梯度等图像固有属性来衡量图像的信息丰 富程度[7][8],以进行网络的训练优化。现有工作的问题在于,选取的图像评价指标不能以 完整反映图像质量,因而约束能力有限,不足以约束网络实现高质量融合;另外现有方法 往往在源图像自身的尺度下进行特征的提取和度量,并未充分利用源图像的全部信息。有 监督方法一般通过选取已有多曝光融合方法中最优的融合结果作为参考图像的方式,将多 曝光融合问题转换为一个有监督问题,以便进行网络的学习与优化[9]。但这样的操作会导 致方法的性能受到已有方法的约束,即上界也仅为现有方法的最优结果。另外,这种方式 将图像融合从图像增强问题转化成了图像恢复问题,事实上偏离了图像融合的本质。
此外,现有多曝光融合的方案往往首先将图像转到亮度与色度分离的色彩空间,且只 在亮度通道设计融合策略。这在很多的情形下会导致融合图像的颜色信息丢失或失真,如 何提升融合图像的颜色质量也是一个值得研究、亟待解决的问题。
[参考文献]
[1]Yu,L.,Wang,Z.Dense sift for ghost-free multi-exposure fusion[J].Journal of Visual Communication and Image Representation,2015,31,208–224.
[2]Goshtasby,A.A..Fusion of multi-exposure images[J].ImageVis.Comput,2005,23, 611–618.
[3]Burt P J,Hanna K,Kolczynski R J.Enhanced image capture throughfusion[C]//1993 (4th)International Conference on Computer Vision.IEEE,1993.
[4]Li S,Kang X,Hu J.Image Fusion With Guided Filtering[J].IEEETransactions on Image Processing,2013,22(7):2864-2875.
[5]Prabhakar K R,Srikar V S,Babu R V.DeepFuse:A Deep UnsupervisedApproach for Exposure Fusion with Extreme Exposure Image Pairs[C]//2017IEEEInternational Conference on Computer Vision(ICCV).IEEE Computer Society,2017.
[6]Ma K,Duanmu Z,H Zhu,et al.Deep Guided Learning for Fast Multi-Exposure Image Fusion[J].IEEE Transactions on Image Processing,2019,PP(99):1-1.
[7]Xu H,Ma J,Jiang J,et al.U2Fusion:A Unified Unsupervised ImageFusion Network[J]. IEEE Transactions on Pattern Analysis and MachineIntelligence,2020.
[8]Zhang H,Xu H,Xiao Y,et al.Rethinking the Image Fusion:AFastUnified Image Fusion Network based on Proportional Maintenance of Gradientand Intensity[J].Proceedings of the AAAI Conference on ArtificialIntelligence,2020,34(7):12797-12804.
[9]Xu H,Ma J,Zhang X P.MEF-GAN:Multi-exposure Image Fusion viaGenerative Adversarial Networks[J].IEEE Transactions on Image Processing,2020,PP(99):1-1.
[10]Mertens T,Kautz J,REe Th F V.Exposure Fusion:A Simple andPractical Alternative to High Dynamic Range Photography[J].Computer GraphicsForum,2010, 28(1):161-171.
[11]Li H,Ma K,Yong H,et al.Fast Multi-Scale Structural PatchDecomposition for Multi-Exposure Image Fusion[J].IEEE Transactions on ImageProcessing,2020,PP(99):1-1.
[12]Hao C,Varshney P K.A human perception inspired quality metric forimage fusion based on regional information[J].Information Fusion,2007,8(2):193-207.
[13]Ma K,Zeng K,Wang Z.Perceptual Quality Assessment for Multi-Exposure Image Fusion[J].IEEE Transactions on Image Processing A Publicationof the IEEE Signal Processing Society,2015,24(11):3345.
[14]Simonyan K,Zisserman A.Very Deep Convolutional Networks forLarge-Scale Image Recognition[J].Computer Science,2014.
发明内容
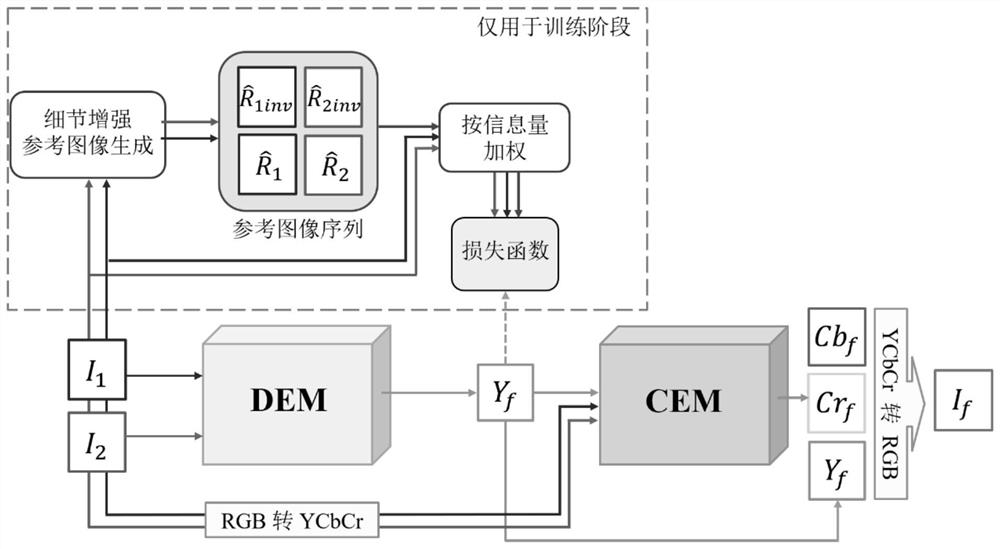
针对上述现有技术,本发明提出一种基于深度感知增强的多曝光图像融合方法,该方 法依据影响视觉感知的特性,将多曝光融合问题解耦为结构与细节融合与颜色融合两个子 问题,相对应地将网络设计划分为了两个子网络:一个细节增强子网络,一个颜色增强子 网络。在细节增强网络中,创新性地提出了一种局部双向曝光优化的策略,用以更为充分 地提取源图像的信息,引导网络模型的优化;在颜色增强网络中,通过令网络学习到同一 场景下颜色对应亮度变化的映射关系的方式,使其可以根据源图像为细节增强网络得到的 结构(亮度)分量拟合出更为真实的颜色分量。两个网络相辅相成,保证了所提方法能够 生成信息丰富且视觉观感良好的融合图像。
为了解决上述技术问题,本发明提出的一种基于深度感知增强的多曝光图像融合方法, 包括以下步骤:
步骤1、对两张源图像I
步骤2:构建细节增强网络(DEM),并设计细节增强网络的损失函数对该网络进行优 化,得到优化后的细节增强网络;
步骤3:构建颜色增强网络(CEM),并设计颜色增强网络的损失函数对该网络进行优 化,得到优化后的颜色增强网络;
步骤4、利用优化后的细节增强网络和优化后的颜色增强网络,得到针对两张不同曝光 度图像的高质量的融合图像。
进一步讲,本发明所述的基于深度感知增强的多曝光图像融合方法各步骤的具体内容 如下:
步骤1的具体内容如下:
1-1)正向增强:
对每张源图像I∈{I
对于每个像素位置(i,j),利用局部图像窗口的数学统计量,标准差来计算最优曝光调节 矩阵
令
1-2)反向增强:
对源图像I的像素数值取反,得到反转图像I
上述的正向增强和反向增强得到的所有的细节增强的参考图像共同构成细节增强参考 图像序列
步骤2的具体内容如下:
2-1)设计所述细节增强网络的结构:
将细节增强网络设置为类U-Net的多尺度编码器-解码器结构;其中,编码器部分由两 个子编码器组成,两个子编码器包括联合编码器和判别编码器,所述联合编码器用以探索 两输入图像间的相关特征,所述判别编码器用以探索每个输入图像自身的代表性特征;所 述联合解码器接收所述两个子编码器的输出作为输入,并在每个图像尺度接收来自所述两 个子编码器的跳跃连接特征,生成最终的融合图像亮度,融合图像的亮度分量Yf的表达式如 下:
式(2)中,
2-2)设计细节增强网络的损失函数:
将两张源图像I
式(3)中,
式(4)中,H和W分别为Y
式(5)中,φ
2-3)设计自动确定超参数γ
待训练完成后,得到优化后的细节增强网络。
步骤3的具体内容如下:
3-1)设计颜色增强网络的神经网络结构:
将颜色增强网络设置为联合编码器-解码器的卷积神经网络结构,用以探索输入图像之 间的映射关系;所述颜色增强网络用于实现输入源图像和由细节增强网络得到的融合图像 的亮度分量Y
是(6)中,
3-2)设计颜色增强网络的损失函数:
在训练时,从每一个多曝光序列中随机选择三张图像,将两张图像和第三张图像的亮 度分量作为颜色增强网络输入,让颜色增强网络推断这一场景在第三张图像的亮度情况下 应有的颜色信息;在这种条件下,第三张图像的原始颜色信息Cb
待训练完成后,得到优化后的颜色增强网络。
步骤4的具体内容如下:
4-1)将两张不同曝光度的源图像输入步骤2获得的优化后的细节增强网络,该细节增 强网络的输出为融合图像的亮度分量;
4-2)将上述两张不同曝光度的源图像由步骤4-1)生成的融合图像的亮度分量输入步骤 3获得的优化后的颜色增强网络,该颜色增强网络的输出为融合图像的颜色分量;
4-3)将步骤4-1)得到的融合图像的亮度分量与步骤4-2)得到的融合图像的颜色分量 进行拼接,并从YCbCr颜色空间转回RGB颜色空间,最终得到该两张不同曝光度图像的高 质量的融合图像。
与现有技术相比,本发明的有益效果是:
在本发明中,设计了细节增强网络和颜色增强网络,分别融合图像的亮度和颜色信息。 在细节增强部分,设计了一种细节增强策略,通过最大化各源图像及反转源图像局部方差 的方式,获得一系列细节增强的参考图像,并将各参考图像依据信息丰富度加权作为优化 目标,对细节增强神经网络进行训练,从而得到包含丰富细节的融合亮度;在颜色增强部 分,设计细节增强神经网络,使其学习到不同场景下颜色关于亮度的映射关系,从而实现 为融合亮度渲染颜色,完成融合图像的生成。利用本发明得到的多曝光融合图像不仅具有 丰富的细节信息和良好的全局结构一致性,还具有相较已有方法更加真实、生动的颜色信 息,显著提高图像视觉质量。此外,本方法具有良好的运算效率和可拓展性,可进行实时 图像融合,亦可拓展用于单张图像的曝光优化。
附图说明
图1是本发明方法的整体流程图;
图2是双向细节增强参考图像生成流程图;
图3是发明中DEM网络的卷积神经网络结构图;
图4是发明中CEM网络的卷积神经网络结构图;
图5是本发明方法结果与其他现有方法的融合结果对比图一;
图6是本发明方法结果与其他现有方法的融合结果对比图二;
图7是本发明方法结果与其他现有方法的融合结果对比图三;
具体实施方式
下面结合附图及具体实施例对本发明做进一步的说明,但下述实施例绝非对本发明有 任何限制。
本发明提出的一种基于深度感知增强的多曝光图像融合方法,如图1所示,包括以下 步骤:
步骤1、对两张源图像I
1.1正向增强:对源图像I进行分解:
对于每个像素位置(i,j),利用局部图像窗口的数学统计量:标准差来计算
令
1.2反向增强:对源图像的数值取反,得到反转图像I
正向、反向增强得到的所有参考图像共同构成细节增强参考图像序列。
步骤2:构建细节增强网络(DEM),并设计细节增强网络的损失函数对该网络进行优 化,得到优化后的细节增强网络;过程如下:
2.1设计细节增强网络结构;将DEM的网络设置为一种类似U-Net的编码器-解码器结 构;其中,编码器部分由两个子编码器组成,一个称为联合编码器,用以探索两输入图像间的相关特征,另一个称为判别编码器,用以探索每个输入图像自身的代表性特征;一个联合解码器模块接收两个部分编码器的输出作为输入,并在每个尺度接收来自各编码器的跳跃连接特征,从而生成最终的融合图像亮度;细节增强网络(DEM)能够为融合图像生 成包含尽可能丰富细节信息的亮度分量Y
其中
2.2DEM网络损失函数设计;将两张源图像的亮度(Y
其中,
H和W为输入输出图像的高和宽;
其中φ
为了免于超参数的调节,设计了一种自动确定超参数γ
待训练完成后,在实际应用时,向DEM网络输入两张不同曝光度图像,即可输出的融 合图像亮度。
步骤3:构建颜色增强网络(CEM),并设计颜色增强网络的损失函数对该网络进行优 化,得到优化后的颜色增强网络;过程如下:
3.1设计CEM网络的神经网络结构;将CEM网络设置为联合编码器-解码器的卷积神经网络结构,用以探索输入图像之间的映射关系,网络的结构细节如图4所示:
CEM网络的目标为实现输入源图像和由DEM网络得到的融合亮度,推断出该场景在融合亮度下最恰当的颜色信息,即如下式所示:
其中
3.2CEM网络损失函数设计;
在训练时,从每一个多曝光序列中随机选择三张图像,将两张图像和第三张图像的亮 度分量作为网络输入,让网络推断这一场景在第三张图像的亮度情况下应有的颜色信息; 在这种条件下,第三张图像的原始颜色信息(Cb
待训练完成后,在实际应用时,向CEM网络输入两张不同曝光图像和DEM网络生成的融合图像亮度,即可输出融合图像颜色。
步骤4、利用优化后的细节增强网络和优化后的颜色增强网络,得到针对两张不同曝光 度图像的高质量的融合图像。即将DEM网络生成的融合图像亮度与CEM网络生成的融合 图像颜色进行拼接,即可得到最终的高质量融合图像。本发明中,DEM网络和CEM网络 为本方法内部子网络,使用者无需知晓。在实际应用本发明方法时,仅需输入两张不同曝 光度的源图像,即可输出高质量融合图像。
下面将本发明所提出的多曝光融合方法与现有的其他多曝光融合工作进行了定性和定 量的对比实验,以验证所提方法的有效性和优越性。与8个现有的工作进行了对比,分别 为Mertens[10],GFF[4],DSIFT[1],MEF-Net[6],FMMEF[11],DeepFuse[5],U2Fusion[7]和MEF-GAN[9]。其中,Mertens、GFF、DSIFT、FMMEF是传统机器学习方法,DeepFuse、 MEF-Net、U2Fusion是无监督的深度学习方法,MEF-GAN是一种有监督的深度学习方法。
定性实验结果比较。由于多曝光融合任务的特点,视觉效果对比是最直观的性能验证 方式。在图5至图7中给出了几组比较有代表性的融合结果对比图。从这些结果图当中, 可以清楚地看出,尽管源图像对存在着非常大的曝光差异,本发明方法生成的融合结果仍 然可以产生全局结构良好、并且曝光程度合适的融合图像。然而,在许多对比方法(尤其 是传统方法和基于权重图融合的方法)当中,融合图像的全局结构一致性遭到了破坏,并 且出现了明显的伪影。例如,在图6当中,方法(a)、(b)、(e)的结果出现了很明显的亮 度跳变伪影,而深度学习方法如(c)、(f)和(h)的结果中,草地部分的曝光明显不足。 另外,本发明的方法产生的融合结果很好地保持了丰富的细节信息,而一些对比方法,尤 其是如(f)等深度学习方法,产生的结果相对模糊。
定量实验结果比较。事实上,在整个多曝光融合乃至图像融合领域,至今为止还没有 一种公认的最优评价指标可以完美全面地衡量融合图像的质量。因此,为了尽可能全面地 评价本发明的方法相较其他现有方法的优越性,选取了8种从不同角度衡量图像质量的客 观评价指标,分别为平均梯度(Average Gradient,AG)、Chen等人所提的融合评价指标(Q
表1为定量对比结果,其中各指标的数值前三名分别用“※”、“Δ”、“○”符号标注。(↓) 表示该指标数值越小时性能越好。
表1
给出所有对比方法在上述评价指标上的总体表现对比,结果如表1所示。从表1中可 以看出,本发明的方法在所有指标中都位于前三名,这也验证了所提方法在定量指标上的 有效性。本发明的方法在指标EI、SF、AG上位列第一,这表明本发明的方法产生的融合结果具有丰富的细节和边缘信息。所提方法在指标Q
运行时间对比。在测试数据集上对本发明的方法与其他的对比方法进行了运行时间统 计和对比。传统方法在Intel I7-8750H处理器上进行运行与评价,深度学习方法在一张Nvidia 2080Ti GPU上进行运行与评价,对比结果如表2所示。可以看到,本发明的方法运行效率 在所有方法当中位列第二,仅次于方法MEF-Net。值得注意的是,MEF-Net方法对输入图 像进行了下采样,并只对下采样的源图像进行处理,从而提高运行速度,但同时也不可避 免地损失了算法的精度。而本发明的方法在原始图片大小上进行融合操作,在保证了更高 的精细度的同时,也保持了优秀的运行效率。本发明的方法可以在720p的源图像上实现实 时(超过60对/秒)融合,这显著地提升了所提方法的可用性和适用范围。
表2.各算法处理720p源图像对的平均运算时间。位列第一、第二位的结果分别由“※”、 “Δ”符号着重标注。
表2
尽管上面结合附图对本发明进行了描述,但是本发明并不局限于上述的具体实施方式, 上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明 的启示下,在不脱离本发明宗旨的情况下,还可以做出很多变形,这些均属于本发明的保 护之内。
- 基于深度感知增强的多曝光图像融合方法
- 一种基于色觉感知及全局质量因子的多曝光度图像融合方法