一种基于智能对话的主动式网络信息挖掘方法
文献发布时间:2023-06-19 18:34:06
技术领域
本发明属于信息安全技术领域,特别是涉及一种基于智能对话的主动式网络信息挖掘方法。
背景技术
Chen等人针对整体网络违法现象,提出一类对违法行为研究的数据分析方法;Radianti 等人,针对在线非法交易市场,对用户互动特征的分类进行研究,以此分类用户类型;Kim 等人,针对网络攻击行为,通过案例分析方法,研究网络违法行为的类型分类和损害影响的衡量;Sood等人,针对网络违法行为商业化,对网络违法行为类型进行分类和描述;Hutchings 等人,针对在线非法交易市场,通过数据分析方法,对目标人员行为特征分类与研究;Wergberg 等人,针对在线非法交易市场,研究了非法市场供应链;Minsu等人,针对在线非法交易市场,通过数据分析、文本分析等方法,挖掘地下产业社交网络。
当前,针对网络违法行为研究大多通过事后获取相关数据,进行内容分析和数据分析,现有研究方法获取信息基于被动收集,方式单一,仅依托公开应用场景,很难通过在公开的社交平台上收集获取潜在的敏感网络信息,难以挖掘更深层次隐含信息,如售价、产品源、发货地、目标人员联系方式等;不具有主动探测和挖掘组织的能力,对组织很难有一个更加清晰全面的认知和画像分析。
发明内容
本发明的目的在于克服现有技术的不足,提供一种基于智能对话的主动式网络信息挖掘方法。
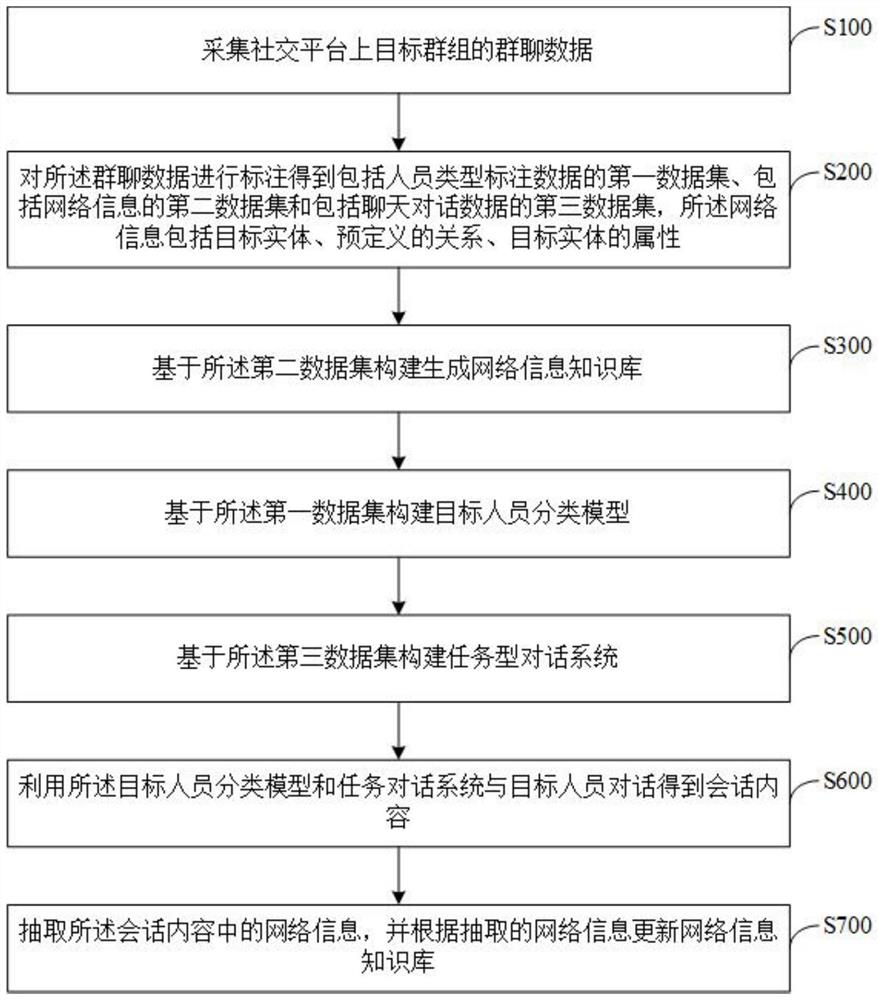
本发明的目的是通过以下技术方案来实现的:一种基于智能对话的主动式网络信息挖掘方法,包括:
采集社交平台上目标群组的群聊数据;
对所述群聊数据进行标注得到包括人员类型标注数据的第一数据集、包括网络信息的第二数据集和包括聊天对话数据的第三数据集,所述网络信息包括目标实体、预定义的关系、目标实体的属性;
基于所述第二数据集构建生成网络信息知识库;
基于所述第一数据集构建目标人员分类模型;
基于所述第三数据集构建任务型对话系统;
利用所述目标人员分类模型和任务对话系统与目标人员对话得到会话内容;
抽取所述会话内容中的网络信息,并根据抽取的网络信息更新网络信息知识库。
进一步地,对所述群聊数据进行标注得到包括人员类型标注数据的第一数据集、包括网络信息的第二数据集和包括聊天对话数据的第三数据集,包括:
基于所述群聊数据,标注发言人类型得到人员类型标注数据,根据所述人员类型标注数据生成第一数据集;
基于所述群聊数据,标注网络信息得到第二数据集,所述网络信息包括目标实体、预定义的关系、目标实体的属性;
基于所述群聊数据生成多轮聊天对话数据,根据所述聊天对话数据生成第三数据集。
进一步地,基于所述第二数据集构建生成网络信息知识库,包括:
根据所述第二数据集中的目标实体、预定义的关系、目标实体的属性组成第一三元组信息;
将所述第一三元组信息存入图数据库中形成网络信息知识库。
进一步地,基于所述第一数据集构建目标人员分类模型,包括:
.对所述第一数据集的文本进行预处理,所述预处理包括去除停用词、非ASCII字符和标点符号;
构建专业术语字典;
利用分词工具和所述专业术语字典对预处理后第一数据集的文本进行分词,得到语料和目标人员类型标签;
将所述语料和目标人员类型标签输入预设的中文词向量预训练模型,得到词向量;
将所述词向量输入预设的TextCNN模型进行训练,得到目标人员分类模型。
进一步地,基于所述第三数据集构建任务型对话系统,包括:
基于所述第三数据集,标注每句对话的意图标签形成第四数据集;
基于所述第四数据集和词向量,利用BiLSTM模型进行训练得到意图识别模块;
基于所述第三数据集,标注对话任务中的执行动作形成第五数据集;
基于第四数据集和第五数据集设置回答话术模板;
基于所述回答话术模板构建回复模块;
构建同义词替换表和基于规则的第一对话策略;
基于所述第四数据集和第五数据集,将所述意图标签、目标实体、执行动作嵌入到输入向量中,利用自注意力机制构建基于深度学习的第二对话策略,所述输入向量为将所述意图标签、目标实体、执行动作文本embedding获得的向量;
基于所述同义词替换表、第一对话策略和第二对话策略构建对话策略模块;
基于所述意图识别模块、回复模块和对话策略模块生成任务型对话系统。
进一步地,所述主动式网络信息挖掘方法还包括:
基于所述词向量,利用BiLSTM-CRF构建命名实体识别模型。
进一步地,利用所述目标人员分类模型和任务对话系统与目标人员对话得到会话内容,包括:
基于开源工具搭建聊天机器人,利用HTTP插件与社交聊天软件建立HTTP API,并将聊天机器人接入目标群组,监听所述目标群组中的聊天消息;
利用所述目标人员分类模型识别所述聊天消息的发言人员类型,当识别到预设类型的发言人员时,利用任务型对话系统与该发言人员进行对话,所述任务型对话系统通过HTTP请求实现社交聊天软件消息的获取和发送;
采集会话内容。
进一步地,抽取所述会话内容中的网络信息,并根据抽取的网络信息更新网络信息知识库,包括:
基于所述命名实体识别模型和正则表达式,提取所述会话内容中的目标实体、预定义的关系、目标实体的属性;
将从会话内容中提取的目标实体、预定义的关系、目标实体的属性组成第二三元组信息;
将所述第二三元组信息更新到网络信息知识库。
本发明的有益效果是:
(1)本发明采用机器人接入社交平台交流群组,自动收集聊天内容,定期通过关键字自动化搜寻目标目标群组,实现了网络信息数据收集自动化、自更新、智能化,有效减少手动搜集信息的人工成本与时间成本,确保信息收集的时效性;
(2)本发明通过大量真实有效的交易会话数据,训练出智能且高效的对话系统,主动潜入目标目标群组,采用分类技术自动识别目标人员类型,搜寻目标进行对话,在问题驱动式对话的引导下,与目标易人员进行一对一交流,一方面削弱其防备意识,另一方面引导对方主动交流,并且留下个人隐私等深层次信息,实现了深层次网络信息信息挖掘;
(3)本发明使用对话系统一对一聊天模式,提升了挖掘网络信息的价值和效率,实现了智能化的网络信息信息挖掘;
(4)本发明中智能对话的交流对象为单个目标人员,在大量的交流后,能得知其从事的交易产品信息及其个人基本信息,通过主动套取该目标人员的上下游商家,有机会得知其产品来源与产品去处;即使套取失败,也能通过已掌握的该卖家信息,通过组织关联和关键人物识别技术,将相似度高的其他卖家与之划分为同一组织;在对得到的目标人员信息包括银行卡卡号,手机号等附带个人实名认证的隐私内容,或者进行语音对话,保存语音内容后,结合识别技术进行溯源,实现了目标人员上下游人物进行画像与溯源。
附图说明
图1为本发明中基于智能对话的主动式网络信息挖掘方法的一种实施例的流程图;
图2为本发明中构建网络信息知识库的一种实施例的流程图;
图3为本发明中构建目标人员分类模型的一种实施例的流程图;
图4为本发明中构建任务型对话系统的一种实施例的流程图;
图5为本发明中更新目标人员分类模型的一种实施例的流程图。
具体实施方式
下面将结合实施例,对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有付出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
参阅图1-图5,本实施例提供了一种基于智能对话的主动式网络信息挖掘方法:
如图1所示,一种基于智能对话的主动式网络信息挖掘方法,包括:
S100.采集社交平台上目标群组的群聊数据。
所述群聊数据包括群聊人员ID、昵称、发言内容、发言时间和所在群组等。
在一个实施例中,所述群聊数据的采集方法为:利用开源工具构建聊天机器人,将聊天机器人接入目标群组,利用社交软件API接口采集群聊数据。
S200.对所述群聊数据进行标注得到包括人员类型标注数据的第一数据集、包括网络信息的第二数据集和包括聊天对话数据的第三数据集,所述网络信息包括目标实体、预定义的关系、目标实体的属性。
在一个实施例中,对所述群聊数据进行标注得到包括人员类型标注数据的第一数据集、包括网络信息的第二数据集和包括聊天对话数据的第三数据集,包括:
S210.基于所述群聊数据,标注发言人类型得到人员类型标注数据,根据所述人员类型标注数据生成第一数据集。
一般的,标注发言人类型既可以采用标注工具进行标注,也可以手动标注,还可以采用标注工具和手动标注结合的方式。
所述第一数据集包括发言内容文本和文本标签等。所述文本标签是通过标注发言人类型得到的,所述文本标签包括卡商、号商、接码平台、打码平台、料商、工具开发者、账号售卖平台、工具售卖平台和买家等。
在一个实施例中,第一数据集的生成方法为:对群聊数据进行预处理(例如,去除重复的文本,筛选掉小于2个字符的文本和无中文字符的文本),提取群成员ID及其发言内容,根据发言内容,通过人工判定、编写规则等方式进行类别标注,获得第一数据集。
进行数据标注时,人工判定是使用开源标注系统进行手动标注;编写规则是通过建立人员类别关键词字典,编写程序判定发言内容是否包含某个关键词,若是则标注该类型。人员关键词字典建立时满足以下条件:关键词的数量应该足够少(小于第一预设值);不同类别之间的种子关键词相似性很低(低于第二预设值);对于各类别,种子关键词非常具有代表性;考虑到分词的不确定,种子关键词不一定是一个词语,也可以是短语形式。
S220.基于所述群聊数据,标注网络信息得到第二数据集,所述网络信息包括目标实体、预定义的关系、目标实体的属性。
所述目标实体包括卡商、号商、接码平台、打码平台、料商、工具开发者、账号售卖平台、工具售卖平台、买家、卡、支付平台等。
卡商的属性包括社交账号、手机号、地理位置、真实姓名、公司名称等。
号商的属性包括社交账号、手机号、地理位置、真实姓名、公司名称等。
料商的属性包括社交账号、手机号、地理位置、真实姓名、公司名称等。
接码平台的属性包括平台URL、平台名称、所属公司等。
打码平台的属性包括平台URL、平台名称、所属公司等。
工具开发者的属性包括社交账号、手机号、真实姓名、开发工具类型等。
账号售卖平台属性包括平台URL、平台名称、所属公司等。
工具售卖平台属性包括平台URL、平台名称、所属公司等。
买家属性包括社交账号、手机号、地理位置、真实姓名等。
卡的属性包括余额、类型、归属地、库存量、运营商、卡号、发货时间、发货地点、价格等。
交易平台的属性包括类型、名称等。
预定义的关系包括:卡商与接码平台之间的“提供手机卡”、卡商与买家之间的“提供手机卡”、卡商与号商之间的“提供手机卡”、接码平台与号商之间“提供手机号、验证码”、接码平台与买家之间“提供手机号、验证码”、号商与账号售卖平台之间“提供账号”、号商与工具售卖平台之间“提供账号”、号商与买家之间“提供账号”、打码平台与号商之间“提供验证服务”、料商与号商之间“提供身份信息”、工具开发者与号商之间“提供工具”等。
具体的,对群聊数据进行预处理(如,去除重复的文本,筛选掉小于2个字符的文本、无中文字符的文本),提取发言内容,根据目标领域知识(如目标人员常用行话、简写名词),使用开源标注系统标注目标实体、预定义的关系、目标实体的属性,得到第二数据集。
S230.基于所述群聊数据生成多轮聊天对话数据,根据所述聊天对话数据生成第三数据集。
具体的,对群组信息和群聊数据进行预处理(如,去除重复的文本,筛选掉小于2个字符的文本、无中文字符的文本),提取群聊人员ID和发言内容,以及爬取开源数据,进行数据预处理后,收集整理形成多轮聊天对话数据(例如,将原始文本数据整理为问答对,如“问: 你们的卡主要有哪些用途啊?答:可以用于微信注册,微信辅助,微信解封QQ绑定,QQ解封等;问:你们的注册卡都有哪些用户啊?答:基本上都是一些工作室在使用的;问:都有哪些号段可以选择呢?答:包含162、165、170几个号段的”),获得第三数据集。
S300.基于所述第二数据集构建生成网络信息知识库。
在一个实施例中,如图2所示,基于所述第二数据集构建生成网络信息知识库,包括:
S310.根据所述第二数据集中的目标实体、预定义的关系、目标实体的属性组成第一三元组信息。
S320.将所述第一三元组信息存入图数据库中形成网络信息知识库。
例如,将第一三元组信息存入Neo4j数据库中,通过前端页面展示形成网络信息知识库。
S400.基于所述第一数据集构建目标人员分类模型。
在一个实施例中,如图3所示,基于所述第一数据集构建目标人员分类模型,包括:
S410.对所述第一数据集的文本进行预处理,所述预处理包括去除停用词、非ASCII字符和标点符号。
S420.构建专业术语字典。
例如,根据目标领域知识构建专业术语字典。专业术语字典是指行话、简写词语组成的字典。
S430.利用分词工具和所述专业术语字典对预处理后第一数据集的文本进行分词,得到语料和目标人员类型标签。
例如,利用结巴分词工具,导入专业术语字典,对第一数据集的文本进行分词。
目标人员类型标签包括卡商、号商、接码平台、打码平台、料商、工具开发者、账号售卖平台、工具售卖平台和买家等。
S440.将所述语料和目标人员类型标签输入预设的中文词向量预训练模型RoBERTa-wwm-ext,得到词向量。
S450.将所述词向量输入预设的TextCNN模型进行训练,得到目标人员分类模型。
例如,词向量维度设置为768,卷积核尺寸设置为(2,3,4),卷积核数量设置为256,参数Droptout的值设置为0.5,将数据集以8:2的比例分为训练集和测试集进行训练。
S500.基于所述第三数据集构建任务型对话系统。
在一个实施例中,如图4所示,基于所述第三数据集构建任务型对话系统,包括:
S510.基于所述第三数据集,标注每句对话的意图标签形成第四数据集。
例如,标注每句对话的意图标签是指判断每句对话内容表达的真实意图,如回答语句“包含162、165、170几个号段的”的意图标签为:“回答卡号”,回答“你好”的意图标签是:“打招呼”。
所述意图标签包括打招呼、回答卡余额、回答卡价格、回答卡类型、回答卡归属地、回答卡库存量、回答卡运营商、回答卡号、回答发货时间、回答发货地点、回答平台类型、回答平台名称、回答平台URL、回答社交账号、回答手机号、回答地理位置、回答公司名称,否定回答和挑战回答等。
所述“否定回答”是指目标人员对所述智能对话系统提出的问题没有正面回答或给出否定回答。
所述“挑战回答”是指目标人员对所述智能对话系统提出质疑或不友好语句,如回答[“你是机器人吗?”]。
S520.基于所述第四数据集和词向量,利用BiLSTM模型进行训练得到意图识别模块。
在一个实施例中,利用目标领域词向量模型对Token进行编码,得到每个Token对应的词向量,然后将其输入到BiLSTM层中获取特征编码,然后再输入到softmax层进行计算,输出概率最大的意图分类,以8:2比例划分训练集和测试集,batch_size为256,训练学习率为0.001,使用dropout技术来防止过拟合,值设为0.2。
S530.基于所述第三数据集,标注对话任务中的执行动作形成第五数据集。
执行动作是指所述智能对话系统回答目标人员时执行的话术动作,所述执行动作包括打招呼、询问卡余额、询问卡价格、询问卡类型、询问卡归属地、询问卡库存量、询问卡运营商、询问卡号、询问发货时间、询问发货地点、询问平台类型、询问平台名称、询问平台URL、询问社交账号、询问手机号、询问地理位置、询问公司名称,执行否定回答和执行挑战回答等。
S540.基于第四数据集和第五数据集设置回答话术模板。
回答话术模板是指所述执行动作对应的回答语句,如执行动作“打招呼”对应的回答语句为[“你好”、“你好啊”、“您好”、“你好,需要什么?”],执行动作“询问卡价格”对应的回答语句为[“卡多少钱一张?”、“卡怎么卖的啊?”、“卡价格怎么样啊?”]。
在一个实施例中,意图类型、执行动作、回答话术模板等数据采用yml文件。
S550.基于所述回答话术模板构建回复模块。
S560.构建同义词替换表和基于规则的第一对话策略。
具体的,根据目标领域知识,构建同义词替换表,用于替换识别到的缩写词、行话。
目标人员在聊天时会采取简写,同音字、错别字等故意逃避监管,为更加准确识别目标人员聊天内容,基于开源信息,建立同义词替换表。
对话策略(第一对话策略和第二对话策略)是负责所述智能会话系统根据目标人员的回答,预测下一步需要采取的执行动作,以及如何更新对话状态信息。基于规则的第一对话策略是指编写基于规则的对话流程控制,只要满足规则,每次执行的动作都是确定性分支,如,当所述智能对话系统识别目标人员回答语句的意图是“回答卡价格”,下一步执行的动作是“询问卡余额”。
S570.基于所述第四数据集和第五数据集,将所述意图标签、目标实体、执行动作嵌入到输入向量中,利用自注意力机制构建基于深度学习的第二对话策略,所述输入向量为将所述意图标签、目标实体、执行动作文本embedding获得的向量。
具体的,将所述意图标签、目标实体、执行动作嵌入到输入向量中,然后通过自注意力层编码,接着接入池化层,并通过dropoutt层防止过拟合,最后通过softmax层获取每个行为的概率,最终返回概率最大的动作作为下一个对话动作。
具体的,设置阈值,当所述模型输出概率最大的下一执行动作的概率小于阈值时,执行默认动作。
具体的,以8:2的比例划分训练集和测试集,batch_size设置为16,训练学习率为0.001, dropout值设为0.2。
S580.基于所述同义词替换表、第一对话策略和第二对话策略构建对话策略模块。
S590.基于所述意图识别模块、回复模块和对话策略模块生成任务型对话系统。
S600.利用所述目标人员分类模型和任务对话系统与目标人员对话得到会话内容。
在一个实施例中,利用所述目标人员分类模型和任务对话系统与目标人员对话得到会话内容,包括:
S610.基于开源工具搭建聊天机器人,利用HTTP插件与社交聊天软件建立HTTPAPI,并将聊天机器人接入目标群组,监听所述目标群组中的聊天消息。
S620.利用所述目标人员分类模型识别所述聊天消息的发言人员类型,当识别到预设类型的发言人员时,利用任务型对话系统与该发言人员进行对话,所述任务型对话系统通过HTTP 请求实现社交聊天软件消息的获取和发送。
由于目标人员警惕性比较高,具有较强的反侦察力,对话策略采用基于规则和基于深度学习的策略配合使用。所述任务型对话系统与目标人员对话流程是:获取目标人员发言内容;调用所述意图识别模块识别对话意图,所述命名实体识别模型识别目标实体;将对话意图和目标实体输入所述对话策略模块,输出下步执行动作;回复模块查找所述执行动作对应的回答话术模板,返回回答语句。
S630.采集会话内容。
S700.抽取所述会话内容中的网络信息,并根据抽取的网络信息更新网络信息知识库。
在一个实施例中,所述主动式网络信息挖掘方法还包括:基于所述词向量,利用BiLSTM-CRF构建命名实体识别模型。
例如,将所述词向量输入BILSTM模型,输出表征向量,使用Sklearn-crfsuite实现CRF 模型,使用L1和L2正则化方法防止过拟合,系数均设置为0,采用Adam作为优化算法。
在一个实施例中,如图5所示,抽取所述会话内容中的网络信息,并根据抽取的网络信息更新网络信息知识库,包括:
S710.基于所述命名实体识别模型和正则表达式,提取所述会话内容中的目标实体、预定义的关系、目标实体的属性。
例如,手机号、URL地址、邮箱账号具备非常明显的特征,可以利用正则表达式进行提取,识别手机号的正则表达式:“/^1[34578]\d{9}$”,识别URL地址的正则表达式:“^((http:\/\/)|(https:\/\/))?([a-zA-Z0-9]([a-zA-Z0-9\-]{0,61}[a-zA-Z0-9])?\.)+[a-zA-Z]{2,6}(\/)”,识别邮箱的正则表达式:“^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$”。
S720.将从会话内容中提取的目标实体、预定义的关系、目标实体的属性组成第二三元组信息。
S730.将所述第二三元组信息更新到网络信息知识库。
以上所述仅是本发明的优选实施方式,应当理解本发明并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文所述构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都应在本发明所附权利要求的保护范围内。
- 一种基于语音智能识别的消息式信息交互系统及方法
- 一种主动交互式对话机器人系统及该系统主动对话的方法
- 一种主动交互式对话机器人系统及该系统主动对话的方法