一种文本匹配方法、装置、系统以及存储介质
文献发布时间:2023-06-19 18:37:28
技术领域
本发明主要涉及语言处理技术领域,具体涉及一种文本匹配方法、装置、系统以及存储介质。
背景技术
文本匹配是自然语言处理中的一项重要且富有挑战的任务,用于判断两段文本的相似性,广泛应用于搜索引擎、推荐系统、问答系统等场景。在现有的先进文本匹配模型中,大多数方法是对每个单词进行统一处理,直接进行文本比较。但是,这样忽略了文本的匹配粒度,从而降低了匹配的准确率。
发明内容
本发明所要解决的技术问题是针对现有技术的不足,提供一种文本匹配方法、装置、系统以及存储介质。
本发明解决上述技术问题的技术方案如下:一种文本匹配方法,包括如下步骤:
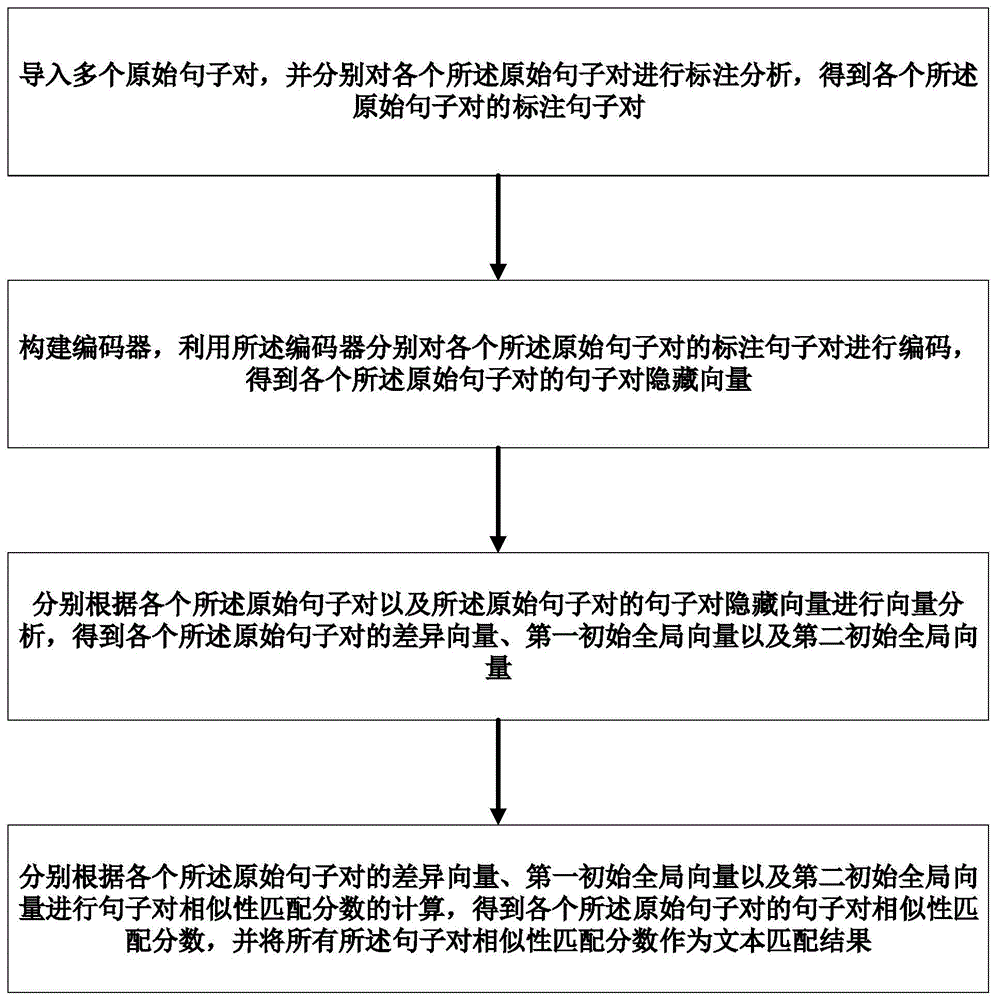
导入多个原始句子对,并分别对各个所述原始句子对进行标注分析,得到各个所述原始句子对的标注句子对;
构建编码器,利用所述编码器分别对各个所述原始句子对的标注句子对进行编码,得到各个所述原始句子对的句子对隐藏向量;
分别根据各个所述原始句子对以及所述原始句子对的句子对隐藏向量进行向量分析,得到各个所述原始句子对的差异向量、第一初始全局向量以及第二初始全局向量;
分别根据各个所述原始句子对的差异向量、第一初始全局向量以及第二初始全局向量进行句子对相似性匹配分数的计算,得到各个所述原始句子对的句子对相似性匹配分数,并将所有所述句子对相似性匹配分数作为文本匹配结果。
本发明解决上述技术问题的另一技术方案如下:一种文本匹配装置,包括:
标注分析模块,用于导入多个原始句子对,并分别对各个所述原始句子对进行标注分析,得到各个所述原始句子对的标注句子对;
编码分析模块,用于构建编码器,利用所述编码器分别对各个所述原始句子对的标注句子对进行编码,得到各个所述原始句子对的句子对隐藏向量;
向量分析模块,用于分别根据各个所述原始句子对以及所述原始句子对的句子对隐藏向量进行向量分析,得到各个所述原始句子对的差异向量、第一初始全局向量以及第二初始全局向量;
匹配结果获得模块,用于分别根据各个所述原始句子对的差异向量、第一初始全局向量以及第二初始全局向量进行句子对相似性匹配分数的计算,得到各个所述原始句子对的句子对相似性匹配分数,并将所有所述句子对相似性匹配分数作为文本匹配结果。
基于上述一种文本匹配方法,本发明还提供一种文本匹配系统。
本发明解决上述技术问题的另一技术方案如下:一种文本匹配系统,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,当所述处理器执行所述计算机程序时,实现如上所述的文本匹配方法。
基于上述一种文本匹配方法,本发明还提供一种计算机可读存储介质。
本发明解决上述技术问题的另一技术方案如下:一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,当所述计算机程序被处理器执行时,实现如上所述的文本匹配方法。
本发明的有益效果是:通过对原始句子对的标注分析得到标注句子对,利用编码器对标注句子对的编码得到句子对隐藏向量,根据原始句子对以及句子对隐藏向量的向量分析得到差异向量、第一初始全局向量以及第二初始全局向量,根据差异向量、第一初始全局向量以及第二初始全局向量的句子对相似性匹配分数计算得到文本匹配结果,突出了关键字这一重要匹配粒度在句子匹配中的重要性,实现了更精确的文本匹配,相对现有技术,能够更精确地判断文本的相似性且提升了文本匹配的准确率。
附图说明
图1为本发明实施例提供的一种文本匹配方法的流程示意图;
图2为本发明实施例提供的一种文本匹配装置的模块框图。
具体实施方式
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
图1为本发明实施例提供的一种文本匹配方法的流程示意图。
如图1所示,一种文本匹配方法,包括如下步骤:
导入多个原始句子对,并分别对各个所述原始句子对进行标注分析,得到各个所述原始句子对的标注句子对;
构建编码器,利用所述编码器分别对各个所述原始句子对的标注句子对进行编码,得到各个所述原始句子对的句子对隐藏向量;
分别根据各个所述原始句子对以及所述原始句子对的句子对隐藏向量进行向量分析,得到各个所述原始句子对的差异向量、第一初始全局向量以及第二初始全局向量;
分别根据各个所述原始句子对的差异向量、第一初始全局向量以及第二初始全局向量进行句子对相似性匹配分数的计算,得到各个所述原始句子对的句子对相似性匹配分数,并将所有所述句子对相似性匹配分数作为文本匹配结果。
应理解地,将数据集中句子对(即所述原始句子对)的关键字进行标记。
应理解地,还可以利用NLTK文本处理库分别对各个所述原始句子对进行标注分析。
应理解地,NLTK数据集(即NLTK文本处理库)是NLP研究领域常用的一个Python库。
上述实施例中,通过对原始句子对的标注分析得到标注句子对,利用编码器对标注句子对的编码得到句子对隐藏向量,根据原始句子对以及句子对隐藏向量的向量分析得到差异向量、第一初始全局向量以及第二初始全局向量,根据差异向量、第一初始全局向量以及第二初始全局向量的句子对相似性匹配分数计算得到文本匹配结果,突出了关键字这一重要匹配粒度在句子匹配中的重要性,实现了更精确的文本匹配,相对现有技术,能够更精确地判断文本的相似性且提升了文本匹配的准确率。
可选地,作为本发明的一个实施例,所述分别对各个所述原始句子对进行标注分析,得到各个所述原始句子对的标注句子对的过程包括:
分别对各个所述原始句子对进行潜在关键词的提取,得到各个所述原始句子对的多个潜在关键词;
根据预设知识库分别对各个所述原始句子对的各个潜在关键词进行匹配,得到各个所述原始句子对的多个匹配后关键词;
基于命名实体识别方法,根据各个所述原始句子对的多个匹配后关键词分别对对应的所述原始句子对进行标注,得到各个所述原始句子对的标注句子对。
应理解地,设计一个关键字鉴别器,将数据集中句子对(即所述原始句子对)的关键字进行标记。
应理解地,所述预设知识库可以为维基百科实体图或搜狗知识图,维基百科实体图用于英文语料库,搜狗知识图用于中文医学SM。
具体地,首先从NLTK(即所述NLTK数据集)中提取潜在的关键词(即所述潜在关键词),包括名词、动词和形容词的词性标签。然后通过使用外部知识库(即所述预设知识库)来匹配这些潜在的关键词(即所述潜在关键词),其中外部知识库(即所述预设知识库)包括:维基百科实体图用于英文语料库,搜狗知识图用于中文医学SM。最后,使用命名实体识别(NER)的方法(即所述命名实体识别方法),将文本(即所述原始句子对)中具有特定意义的词(实体),主要包括人名、地名、机构名、专有名词等,在文本序列(即所述原始句子对)中标注出来并作为关键字。
上述实施例中,分别对各个原始句子对进行标注分析得到标注句子对,能够标注出具有特定意义的词,实现了更精确的文本匹配,相对现有技术,能够更精确地判断文本的相似性且提升了文本匹配的准确率。
可选地,作为本发明的一个实施例,所述标注句子对包括第一标注句子和第二标注句子,所述编码器包括BERT模型和最大池化层;
所述利用所述编码器分别对各个所述原始句子对的标注句子对进行编码,得到各个所述原始句子对的句子对隐藏向量的过程包括:
利用所述BERT模型分别对各个所述原始句子对的第一标注句子进行编码,得到各个所述原始句子对的第一隐藏分量;
利用所述BERT模型分别对各个所述原始句子对的第二标注句子进行编码,得到各个所述原始句子对的第二隐藏分量;
利用所述最大池化层分别对各个所述原始句子对的第一隐藏分量进行最大池化处理,得到各个所述原始句子对的第一句子隐藏向量;
利用所述最大池化层分别对各个所述原始句子对的第二隐藏分量进行最大池化处理,得到各个所述原始句子对的第二句子隐藏向量;
其中,所述原始句子对的句子对隐藏向量包括所述原始句子对的第一句子隐藏向量和所述原始句子对的第二句子隐藏向量。
应理解地,在所述BERT模型的最后一层平行构建一个“关键字-注意力”层,使模型更加关注关键字。
具体地,通过对句子对的关键字进行标记之后,将关键字-注意力层与BERT(即所述BERT模型)的最后一层进行平行堆叠以用来注入关键字。该关键字-注意力层强迫模型去关注句子对的关键词的差异,从而来学习到句子对的本质差异。实现方法是通过在BERT的最后一层transformer层中平行添加一个关键字自注意力掩码层,紧跟着最后加一层所述最大池化层,用来生成句子对的隐藏向量。
应理解地,所述关键字自注意力掩码层使用了所述BERT模型中transformer层的功能。
具体地,假设句子对用A(即所述第一标注句子),B(即所述第二标注句子)表示,关键字-注意力层的输入为
其中Maxpooling(·)代表最大池化操作。
上述实施例中,利用编码器对标注句子对的编码得到句子对隐藏向量,能够使模型更加关注关键字,同时,强迫模型去关注句子对的关键词的差异,从而学习到句子对的本质差异,实现了更精确的文本匹配,相对现有技术,能够更精确地判断文本的相似性且提升了文本匹配的准确率。
可选地,作为本发明的一个实施例,所述分别根据各个所述原始句子对以及所述原始句子对的句子对隐藏向量进行向量分析,得到各个所述原始句子对的差异向量、第一初始全局向量以及第二初始全局向量的过程包括:
利用所述BERT模型分别对各个所述原始句子对进行编码,得到各个所述原始句子对的第一初始全局向量以及第二初始全局向量;
分别根据各个所述原始句子对的第一句子隐藏向量、第二句子隐藏向量、第一初始全局向量以及第二初始全局向量进行差异向量的计算,得到各个所述原始句子对的差异向量。
应理解地,计算句子对关键字匹配(即所述第一句子隐藏向量或所述第二句子隐藏向量)与标准样本句子对匹配(即所述第一初始全局向量或所述第二初始全局向量)的差异向量,促使模型学习它们的差异。
上述实施例中,利用BERT模型分别对各个原始句子对进行编码得到第一初始全局向量以及第二初始全局向量,分别根据各个第一句子隐藏向量、第二句子隐藏向量、第一初始全局向量以及第二初始全局向量进行差异向量的计算得到差异向量,能够促使模型学习句子对关键字匹配与标准样本句子对匹配的差异。
可选地,作为本发明的一个实施例,所述分别根据各个所述原始句子对的第一句子隐藏向量、第二句子隐藏向量、第一初始全局向量以及第二初始全局向量进行差异向量的计算,得到各个所述原始句子对的差异向量的过程包括:
基于第一式,分别根据各个所述原始句子对的第一句子隐藏向量、第二句子隐藏向量、第一初始全局向量以及第二初始全局向量进行差异向量的计算,得到各个所述原始句子对的差异向量,所述第一式为:
K
其中,K
应理解地,将句子隐藏向量H
K
其中·表示点乘运算符,用于计算句子A(即所述第一标注句子)和B(即所述第二标注句子)的全局向量H
上述实施例中,基于第一式分别根据各个第一句子隐藏向量、第二句子隐藏向量、第一初始全局向量以及第二初始全局向量进行差异向量的计算得到差异向量,能够促使模型学习句子对关键字匹配与标准样本句子对匹配的差异。
可选地,作为本发明的一个实施例,所述分别根据各个所述原始句子对的差异向量、第一初始全局向量以及第二初始全局向量进行句子对相似性匹配分数的计算,得到各个所述原始句子对的句子对相似性匹配分数的过程包括:
基于第二式,分别根据各个所述原始句子对的差异向量、第一初始全局向量以及第二初始全局向量进行句子对相似性匹配分数的计算,得到各个所述原始句子对的句子对相似性匹配分数,所述第二式为:
sim_scores=softmax[W·H(CLS)+b],
其中,
其中,sim_scores为句子对相似性匹配分数,softmax[·]为激活函数,W为权重矩阵,H(CLS)为目标全局向量,b为偏置向量,·为点乘运算符,H
应理解地,通过将标准样本句子对匹配向量(即所述第一初始全局向量以及所述第二初始全局向量)与所述差异向量进行连接,以便于分类层计算得到句子对相似性匹配分数。
具体地,通过将标准样本句子对匹配(即所述第一初始全局向量以及所述第二初始全局向量)与所述差异向量进行连接,以便于分类层计算得到句子对相似性匹配分数sim_scores,具体为:
sim_scores=softmax(W·H(CLS)+b)
其中
上述实施例中,基于第二式分别根据各个差异向量、第一初始全局向量以及第二初始全局向量进行句子对相似性匹配分数的计算得到句子对相似性匹配分数,以便于通过分类层计算得到句子对相似性匹配分数,突出了关键字这一重要匹配粒度在句子匹配中的重要性,实现了更精确的文本匹配,相对现有技术,能够更精确地判断文本的相似性且提升了文本匹配的准确率。
可选地,作为本发明的另一个实施例,本发明设计一个关键字鉴别器,将数据集中句子对的关键字进行标记;在BERT模型的最后一层平行构建一个“关键字-注意力”层,使模型更加关注关键字;计算句子对关键字匹配与标准样本句子对匹配的差异向量,促使模型学习它们的差异;通过将标准样本句子对匹配向量与差异向量进行连接,以便于分类层计算得到句子对相似性匹配分数。本发明能准确对句子对的关键字信息进行标注,并通过添加关键字-注意力层,突出了关键字这一重要匹配粒度在句子匹配中的重要性,实现了更精确的文本匹配,相对现有技术,能够更精确地判断文本的相似性且提升了文本匹配的准确率。
图2为本发明实施例提供的一种文本匹配装置的模块框图。
可选地,作为本发明的另一个实施例,如图2所示,一种文本匹配装置,包括:
标注分析模块,用于导入多个原始句子对,并分别对各个所述原始句子对进行标注分析,得到各个所述原始句子对的标注句子对;
编码分析模块,用于构建编码器,利用所述编码器分别对各个所述原始句子对的标注句子对进行编码,得到各个所述原始句子对的句子对隐藏向量;
向量分析模块,用于分别根据各个所述原始句子对以及所述原始句子对的句子对隐藏向量进行向量分析,得到各个所述原始句子对的差异向量、第一初始全局向量以及第二初始全局向量;
匹配结果获得模块,用于分别根据各个所述原始句子对的差异向量、第一初始全局向量以及第二初始全局向量进行句子对相似性匹配分数的计算,得到各个所述原始句子对的句子对相似性匹配分数,并将所有所述句子对相似性匹配分数作为文本匹配结果。
可选地,作为本发明的一个实施例,所述标注分析模块具体用于:
分别对各个所述原始句子对进行潜在关键词的提取,得到各个所述原始句子对的多个潜在关键词;
根据预设知识库分别对各个所述原始句子对的各个潜在关键词进行匹配,得到各个所述原始句子对的多个匹配后关键词;
基于命名实体识别方法,根据各个所述原始句子对的多个匹配后关键词分别对对应的所述原始句子对进行标注,得到各个所述原始句子对的标注句子对。
可选地,本发明的另一个实施例提供一种文本匹配系统,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,当所述处理器执行所述计算机程序时,实现如上所述的文本匹配方法。该系统可为计算机等系统。
可选地,本发明的另一个实施例提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,当所述计算机程序被处理器执行时,实现如上所述的文本匹配方法。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
所属领域的技术人员可以清楚地了解到,为了描述的方便和简洁,上述描述的装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
在本申请所提供的几个实施例中,应该理解到,所揭露的装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。
作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本发明实施例方案的目的。
另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以是两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分,或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(ROM,Read-On ly Memory)、随机存取存储器(RAM,Random Access Memory)、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。