基于最大熵soft强化学习的最优渗透路径生成方法
文献发布时间:2023-06-19 19:27:02
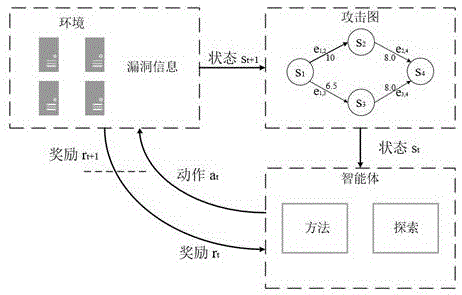
技术领域
本发明涉及网络安全领域,特别涉及一种基于最大熵soft强化学习的渗透路径生成方法。
背景技术
随着互联网应用的共享开放以及新技术的爆发式发展,网络体系架构日益复杂,各种网络安全问题也层出不穷,给用户和企业带来了严重的安全威胁和经济损失。结合威胁情报分析、安全态势评估、入侵检测等技术构建网络安全体系可以应对诸多安全风险。近年来,攻击者利用网络安全漏洞实施恶意攻击的手段和形式日益复杂。为了分析攻击者的行为,网络渗透一直以来是广受关注的网络安全问题。渗透过程可以分为直接渗透和间接渗透,其中直接渗透是从一个主机直接发起攻击并成功渗透到另一个主机的过程;间接渗透是通过渗透成功两个主机之间的跳板主机,才能从一个主机渗透到另一个主机的过程。
在了解渗透原理的基础上,网络管理者可以模拟真实的网络攻防场景,分析可能被攻击者利用的渗透路径,从而设计有效的网络安全防御手段。然而,由于攻击者选择渗透行为的不确定性,加之网络态势的不断改变以及主机漏洞利用难度的客观评价等,这些因素加大了渗透路径的构建难度。与此同时,网络安全防御系统的建立和完善也直接影响评判渗透行为是否客观高效。因此,合理科学地设计渗透路径生成系统面临严峻挑战。
渗透路径生成主要依赖攻击图与Markov链结合的模型来分析可能被攻击者渗透的路径。攻击图的生成是一个收集网络拓扑和应用信息、确定网络主机之间可达条件和设计核心图构建算法的过程。一种基于攻击图和Markov链的网络安全风险评估模型,通过分析计算原子节点的攻击转移概率来获取最大可能被攻击的渗透路径。考虑到内部攻击和未知攻击,一种基于知识图谱的双层威胁渗透图模型,基于知识图谱构建主机资源知识图谱,在此基础上生成主机威胁渗透图和网络渗透威胁图。实验表明该方法能够描述未知攻击和内部攻击。但上述常见渗透路径生成方法未能考虑渗透成功所导致的后续攻击路径的变化;为此,通过将告警集映射到因果知识网络来检测当前的攻击行为,根据能力等级动态调整知识分布,利用改进的Dijkstra算法计算出真实网络对抗环境下的最优攻击路径。为了解决攻击图的伸缩性限制,使用A*Prune算法去除无用边来降低攻击图的复杂度,并采用随机森林算法预测网络拓扑中的攻击位置,从而生成概率最大的渗透路径。
传统的渗透路径生成仍然存在如下问题:(1)人工建模渗透测试环境的成本高,无法应对大规模复杂体系网络场景。(2)人工渗透测试结果往往取决于测试人员个人经验与能力,无法真实的反映出攻击者对目标网络和攻击路径选择的可能性。机器学习的方法成为解决路径规划问题的重要手段。
一种全局引导强化学习方法在移动机器人遇到障碍时,利用环境的时空信息引导机器人做出局部路径调整,而无需重新调用规划算法寻找替代路径,提高了模型的泛化性。将AI路径规划引入渗透路径生成中会显著提升生成效率。在漏洞数据库创建的攻击图上,利用机器学习和深度学习生成渗透路径。一种发现渗透路径的RL方法,其利用智能体通过与环境交互学习而在攻击图中发现最优的多条攻击路径。这为子网间路由器防火墙、认证日志跟踪和基于主机的防病毒等防御措施提供了参考依据。引入智能体多域动作选择模块的方法来发现更多隐藏的多域渗透路径,提出改进的DDPG算法,使得智能体能在不同的状态下选择不同的动作,提高了网络多域安全防御能力。目前渗透测试的智能化方法侧重点为如何高效的提高渗透路径的生成效率,没有考虑面对网络态势环境动态改变的情况下,智能体如何选择最优的动作行为设计。
因此,急需提供一种基于最大熵强化学习模型的渗透路径生成方法已解决上述问题。
发明内容
为实现上述目的,发明人提供了一种基于最大熵soft强化学习的最优渗透路径生成方法,包括以下步骤:
S1,将最优渗透路径抽象为马尔可夫决策过程,在此基础上,将强化学习应用于最优渗透路径生成时,智能体根据当前网络部署的状态信息和节点漏洞给出的环境反馈进行策略学习,用于完成最优渗透路径规划;
S2,在连续动作空间中用近似推理进行最大熵策略学习;
S3,智能体在探索策略学习的过程中,在环境因素变化的干扰下选取未来收益高的动作。
作为本发明的一种优选方式,所述步骤S1中,马尔可夫决策过程包括四元组,分别为:
状态空间
动作空间
状态转移概率
回报值
作为本发明的一种优选方式,所述步骤S1中,智能体根据当前网络部署的状态信息和节点漏洞给出的环境反馈进行策略学习包括以下步骤:智能体在时刻
作为本发明的一种优选方式,所述步骤S2中,在连续动作空间中用近似推理进行最大熵策略学习还包括以下步骤:
标准的强化学习目标是学习到一个最大化期望收益的最优策略,表达式为:
其中,
其中,
定义Soft Q-learning的学习算法为:
通过以上公式,
基于上述公式,得到更新后的最大熵策略:
最大熵策略分布在连续的动作空间中,在最大熵的框架下更具有随机性,用于增加智能体的探索率。
作为本发明的一种优选方式,所述步骤S3中,智能体在探索策略学习的过程中,在环境因素变化的干扰下选取未来收益高的动作,所述环境因素变化包括漏洞评分改变和状态节点有向边改变;
所述漏洞评分改变包括:一些节点的前驱节点已被渗透,自身组件脆弱性增加,导致CVSS分值升高和一些节点部署了入侵检测系统,预警网络攻击,及时修复自身的脆弱性组件,导致CVSS分值降低;
所述状态节点有向边改变为:实际网络场景下主机之间设置了信息交互机制,即它们按照约定时间进行基于密钥协议的信息交互,当其中一个主机被渗透成功时,导致无法与相邻主机进行信息交互,相邻主机立刻预警且暂时关闭与被渗透主机之间的通信服务。
区别于现有技术,上述技术方案所达到的有益效果有:
(1)本方法通过将漏洞评分和渗透路径长度相结合,量化攻击者发起渗透攻击的获益,在此基础上可以有效的评判每一条渗透路径的优劣程度。
(2)本方法基于最大熵模型的Soft Q-learning方法,鼓励智能体受到干扰时探索和开发大部分的状态空间,并设置密集的奖励机制和经验学习机制促使智能体快速地学习到最优策略,从而获得最优渗透路径。
(3)本方法构建了一种具备网络安全防御功能的模拟环境,测试所提方法在网络环境动态变化下的性能,仿真结果表明,本方法在适应性和路径质量上优于基准方法。
附图说明
图1为具体实施方式所述攻击示例图。
图2为具体实施方式所述强化学习交互过程图。
图3为具体实施方式所述初始阶段攻击图中的部分渗透路径图。
图4为具体实施方式所述漏洞评分变化图。
图5为具体实施方式所述主机信息交互变化图。
图6为具体实施方式所述实验网络拓扑图。
图7为具体实施方式的根据实验场景抽象出的攻击图。
图8为具体实施方式的不同方法的奖励值变化图。
图9为具体实施方式所述训练轮次和网络节点数量对失败率的影响趋势图。
图10为具体实施方式所述方法的熵值变化图。
图11为具体实施方式所述方法的攻击获益图。
具体实施方式
为详细说明技术方案的技术内容、构造特征、所实现目的及效果,以下结合具体实施例并配合附图详予说明。
最优渗透路径问题介绍:攻击者从一个主机发动攻击渗透到另一个主机最大可能的渗透路径称为最优渗透路径。可以利用攻击图Attack Graph和漏洞评分系统CommonVulnerability Scoring System,CVSS进行漏洞分析,从而对渗透路径进行问题建模。
攻击图Attack Graph, AG是一种基于模型的网络安全评估技术。该技术可以建模真实网络场景,以评估目标网络中攻击者的攻击行为以及攻击状态的转移过程。
攻击图可以用四元组
(1)
(2)
(3)
(4)
根据上述定义,给出图1所示的攻击图示例,其中
攻击路径:攻击路径Attack Path, AP指攻击者从初始状态节点到达目的状态节点的状态转移序列。例如,图1(a)中
攻击路径长度:攻击路径长度Attack Path Length, APL是一条攻击路径包含的有向边数量。例如,攻击路径
攻击成功概率:攻击成功概率Probability of successful Attack,PA是攻击路径中所有状态转移都成功的概率。例如,图1(b)中P(AP
利用脆弱性扫描工具Nessus等对网络进行脆弱性扫描,再依据网络拓扑结构和所得的脆弱性结果,结合攻击图自动生成工具MulVAL即可构建出攻击图。
漏洞被利用的难易程度可以从可利用度、影响度和影响范围进行量化。一般采用美国国家漏洞数据库National Vulnerability Database, NVD发布的通用CVSS进行评估。如表1,CVSS的量化细则包括:
表1 CVSS评分组件权重
/>
可利用度评价Exploitability Metric,包括攻击途径Attack Vector, AV、攻击复杂度Attack Complexity, AC、权限要求Privilege Required, PR和用户验证UserInteraction, UI,用以反映漏洞不跟随时间和环境变化而变化的固有特征;
影响度评价Impact Metrics,包括机密性Confidentiality Impact, C、完整性Integrity Impact, I,可用性Availability Impact, A,用以反应漏洞被成功利用后造成的威胁程度;
影响范围Scope,包括范围固定Unchanged和范围变化Changed,用以反应漏洞是否会影响组件外的资源或获取其它权限。为了量化漏洞被利用的难易程度,下面给出原子攻击
其中:
在实际应用中,
最优渗透路径旨在攻击图模型中的起始节点和目标节点之间寻找一条攻击获益最大的路径。攻击获益的衡量指标主要体现在:(a)漏洞得分
被定义为攻击图(AG)中初始节点/>
定义0-1变量
则给定一个路径
。
攻击图中边上的漏洞分值计算为
给定首次获得的渗透路径
综上所述,最优渗透路径的实质是给定
subject to:
约束条件中,0-1变量
状态空间
动作空间
状态转移概率
回报值
如图2所示,强化学习是智能体以试错的方式进行学习,通过与环境进行交互获得奖赏来不断指导自身行为。不同于监督学习和无监督学习,环境产生的强化信号可以对动作好坏进行评价。图2所示:智能体在某一时刻观测到环境反馈的状态,依据策略选取动作,完成动作后获得实时奖励值。动作同时会改变环境,使得状态从转移到。智能体根据时刻的状态选择下一个动作,进入下一时间节点的迭代。
在本实施例中,基于最大熵的Soft Q-learning 方法,具体的:传统强化学习中智能体的目标是最大化累计折扣回报值,智能体在单个场景督促下只能学到单一的策略,对于多任务最优或次优行为的场景,例如渗透路径场景而言,智能体倾向于学习到一个较为随机的策略,并且可以探索到更多评价良好的行为。因此,在连续动作空间中用近似推理进行最大熵策略学习可以解决此类问题。
标准的强化学习目标是学习到一个最大化期望收益的最优策略,表达式为:
其中,
其中,
定义Soft Q-learning的学习算法为:
通过以上公式,
基于上述公式,得到更新后的最大熵策略,表达式为:
最大熵策略分布在连续的动作空间中,在最大熵的框架下更具有随机性,用于增加智能体的探索率。
本实施例采用的Soft Q-learning方法提供了一种隐式的探索策略,它鼓励智能体受到干扰时探索和开发大部分的状态空间,以充分的探索来捕获多种模式的近似最优行为,降低算法对模型与估计误差的敏感性。因此,面对复杂多变的网络环境,该方法控制熵值和奖励的重要程度可以保证求解最优渗透路径的过程具有稳定性。
传统基于攻击图的最优渗透路径生成方法主要存在两个问题。一方面,基于当前网络拓扑环境构建的生成的攻击路径无法适应网络环境参数的改变,需要重新构建攻击图来应对,灵活性差。另一方面,通过计算转移概率,分析不同攻击路径的概率分布和期望的方法响应速度较慢,无法适应大规模网络场景。
考虑到上述问题,智能体在探索学习的过程中,应该在环境因素变化的干扰下选取未来收益尽可能高的动作。如图3所示,
漏洞评分改变:一些节点的前驱节点已被渗透,自身组件脆弱性增加导致CVSS分值升高;另外,一些节点部署了入侵检测系统,可以预警网络攻击,及时修复自身的脆弱性组件,因此CVSS分值降低。如图4,当
状态节点有向边改变:实际网络场景下主机之间设置了信息交互机制,即它们按照约定时间进行基于密钥协议的信息交互。当某个主机被渗透成功时,它可能无法与相邻主机进行信息交互,相邻主机会立刻预警且暂时关闭与此主机之间的通信服务。如图5,当
在上述实施例中,图4和图5所示的两种网络环境的变化都会使得攻击图的参数进行动态调整,更接近于真实网络环境。同时,攻击图动态更新的过程作为连续的状态空间能够不断反馈给智能体,在最大熵策略驱动下,智能体能够及时依据环境的反馈选取动作,直到形成稳定策略。
除此之外,本方法还提供了仿真实验检测方案,具体的:
实验环境:为了验证本方法的有效性,搭建一个实际网络环境测试渗透路径生成。实验网络拓扑如图6,包括外部和内部攻击者、主机、防火墙、入侵检测系统IDS。防火墙1和防火墙2-3之间形成DMZ Zone,并分布着五台主机H
本方法依据公开漏洞数据库NVD为二十五台主机设置漏洞信息,表2给出了部分主机H
表2 主机漏洞信息
根据实验网络拓扑图和采集的主机漏洞信息,利用自动生成工具MulVAL生成攻击图如图7所示。攻击图中包含23种不同的状态节点,状态转移的有向边上标注漏洞评分。攻击图为有向图,可以用邻接矩阵存储攻击图中的信息。攻击图中的状态数作为邻接矩阵的维度,攻击图中边上的分值作为邻接矩阵中的对应元素值并记流向节点自身的状态转移漏洞评分
训练和测试:根据攻击图映射的邻接矩阵,智能体通过不断探索来学习攻击者的行为策略,并设定每一轮探索的中止条件可为以下3种情况:(1)成功渗透到目标主机并获取权限;(2)训练步数达到设定值;(3)状态不停转移到自身导致训练陷入死循环。
为了找到攻击者发起渗透攻击的最大可能路径,智能体需要通过不断试错学习得到最优策略。初始状态时,因未经过预先学习,智能体倾向于使用随机策略来选择所需执行的动作。因此,智能体首先进行第一轮学习,并且找到到达目标状态
,并记初始环境下最优渗透路径长度
第二轮学习开始后,智能体在学习过程中,防御系统对异常或攻击行为的响应使得图7中一些有向边的赋值或连通性发生了变化,如表3所示。智能体需要在更新后的攻击图给出的反馈下继续更新最优渗透路径,模拟攻击者发动网络攻击获取攻击收益最大化的过程。
表3 攻击图的动态变化列表
/>
智能体在第
。
结果分析:以第二轮学习结果为例,智能体顺利到达目标节点
首先,考察整个训练过程中迭代次数对
接着通过改变训练步长和网络节点数量来计算任务失败率,比较三种方法在生成最优渗透路径的效率。图9所示:三种方法的失败率均随着网络节点数量的增加呈现上升趋势,随着训练轮次的增加而呈现下降趋势,但Soft Q-learning方法的失败率整体低于其它两种方法。
最大熵强化学习模型中的熵值反映系统的可靠性和稳定性,且熵值越小,策略越稳定。图10分别展示了两种不同规模网络节点个数下,模型熵值的变化情况。智能体的随着训练回合数增加,Soft Q-learning方法的熵值逐渐下降,这是因为在训练开始时鼓励智能体进行探索,且节点个数较多的情况下,智能体探索性更强,熵值较大,当训练累积一段时间后,智能体学习到的策略趋于稳定,熵值逐渐减小。
攻击获益可以衡量渗透路径被利用的可能性,攻击获益越大,证明该条渗透路径越有可能被攻击者利用。图11反映了在不同渗透路径长度下,三种方法的对应的攻击获益值,在路径长度分别为5和9时,可以看到通过Q-learning方法得出的攻击获益为负值,说明该方法得到的渗透路径质量不高,不是基于当前网络环境下的最优渗透路径。除此之外,Soft Q-learning方法在不同路径长度下得到的攻击获益值明显高于两种对照方法。
渗透攻击给网络安全带来了巨大威胁,最优渗透路径生成能够反映攻击者入侵目标网络的最大可能攻击过程,为分析攻击行及设计防御策略提供了重要依据。本实施例提出一种基于最大熵强化学习的最优渗透路径生成方法,在动态攻击图上智能、高效地探索出攻击路径。实验结果表明,智能体使用最大熵模型训练出的学习策略可以提高渗透路径生成效率。
需要说明的是,尽管在本发明中已经对上述各实施例进行了描述,但并非因此限制本发明的专利保护范围。因此,基于本发明的创新理念,对本发明所述实施例进行的变更和修改,或利用本发明说明书及附图内容所作的等效结构或等效流程变换,直接或间接地将以上技术方案运用在其他相关的技术领域,均包括在本发明的专利保护范围之内。