基于FPGA的YOLOv4卷积神经网络轻量化方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及YOLOv4卷积神经网络的技术领域,尤其是基于FPGA的YOLOv4卷积神经网络轻量化方法。
背景技术
边缘计算是一种全新的计算模式,其概念是在靠近数据中心的边缘地带直接对数据进行处理,而不用传回服务器处理。在目标检测中使用边缘计算能够带来一系列好处:直接在采集端的硬件设备上处理图像,不需要传回上位机,节省数据传输的时间、减少数据传输的开销。因此,通过优化加速卷积神经网络,实现在硬件设备上的高效处理具有重要的实际意义。
选取合适的算法载体即硬件设备,是实现系统的高效运行的基石。在硬件设备上,高功耗和高功耗引发的散热问题是一大缺陷。FPGA(现场可编程门阵列)具有低功耗、低延迟和更高的硬件加速性能,因此选用FPGA作为算法载体即硬件设备。
YOLOv4算法是一种基于端到端的目标检测算法,将目标检测问题转换成回归问题,利用整个卷积神经网络同时完成目标分类和目标定位。从实验效果来看,YOLOv4卷积神经网络不仅检测速度远远快于其它目标检测网络,而且在检测精度方面也表现良好。但是,现有的YOLOv4卷积神经网络在FPGA上运行具有如下缺点:
(1)YOLOv4卷积神经网络各层的输入输出和网络权重均是浮点数据,在进行卷积计算、数据缓存和数据传输的时候,浮点数据会占用硬件平台大量的存储资源。
(2)YOLOv4卷积神经网络中,主干网络的巨大参数量对硬件设备即FPGA的计算性能有着较高的要求,然而,FPGA的计算性能和资源有限,使其对YOLOv4算法的移植有较高难度。
(3)YOLOv4卷积神经网络中,主干网络中使用Mish函数作为激活函数。Mish函数虽然精度虽高,但计算需要消耗的硬件资源太多,不适合在FPGA上直接进行计算。
(4)在YOLOv4卷积神经网络中,SPP结构分别利用四个不同尺度的最大池化进行处理,最大池化的池化核大小分别为13x13、9x9、5x5、1x1(1x1即无处理),处理速度较慢。
因此,为了让YOLOv4算法能更好的工作于嵌入式硬件设备FPGA上,还需要结合FPGA的硬件特点对YOLOv4卷积神经网络进行进一步的优化。
发明内容
为了克服上述现有技术中的缺陷,本发明提供基于FPGA的YOLOv4卷积神经网络轻量化方法,用于解决当前YOLOv4卷积神经网络结构复杂、参数多、训练所需的配置高以及实时检测每秒传输帧数低的问题,提出一种轻量化的YOLOv4卷积神经网络。
为实现上述目的,本发明采用以下技术方案,包括:
基于FPGA的YOLOv4卷积神经网络轻量化方法,对YOLOv4卷积神经网络的主干网络即CSPdarknet53网络中残差块的个数以及堆叠次数进行削减,并保留主干网络中的CSPNet结构以及残差结构。
优选的,削减后的CSPdarknet53网络中,残差块的个数为5,每个残差块的堆叠次数均为1。
优选的,在YOLOv4卷积神经网络的主干网络中,选择H-swish函数作为激活函数。
优选的,H-swish函数的计算方法如下所示:
其中,x表示输入,H-swish(x)表示输出,ReLU6函数的计算方式如下所示:
ReLU6(x)=min(max(0,x),6)
其中,min(·)、max(·)分别表示取最小值和取最大值。
优选的,在YOLOv4卷积神经网络的空间金字塔池化层中使用SPPF结构;SPPF结构包括串联的多个池化层即MaxPool层,将输入串行通过多个池化层即MaxPool层,然后通过一个连接层即Concat层将输入以及各个MaxPool层的输出进行连接。
优选的,此多个MaxPool层的大小均为5×5。
优选的,利用加法二次幂量化即APoT量化,对YOLOv4卷积神经网络进行量化。
本发明的优点在于:
(1)本发明对YOLOv4卷积神经网络的主干网络进行尺度缩放,对主干网络即CSPdarknet53网络中的残差块个数以及堆叠次数进行了削减,保留了主干网络中的CSPNet结构以及残差结构,降低了模型的资源占用,同时保证轻量化过后的模型的检测精度。
(2)本发明将主干网络中的Mish结构改为H-swish结构,使用H-swish函数作为激活函数,H-swish函数的精度与Mish函数接近,消耗的计算资源远少于Mish函数。因此综合考虑精度与消耗资源数量,选择H-swish函数作为激活函数。
(3)本发明将YOLOv4卷积神经网络中的SPP结构改为SPPF结构,两者的计算结果是一模一样的,但SPPF结构比SPP结构的计算速度快不止两倍。
(4)在本发明的轻量化即优化方法中,以加法二次幂量化(APoT量化)为基础,对神经网络模型进行量化。加法二次幂量化是一种针对钟形和长尾分布的神经网络权重,能够有效的非均匀性量化方案。通过将所有量化数值限制为几个二次幂相加,有利于提高计算效率,并与权重分布良好匹配。该量化方案效果很好,甚至可以与全精度模型竞争。
附图说明
图1为传统YOLOv4卷积神经网络的结构示意图。
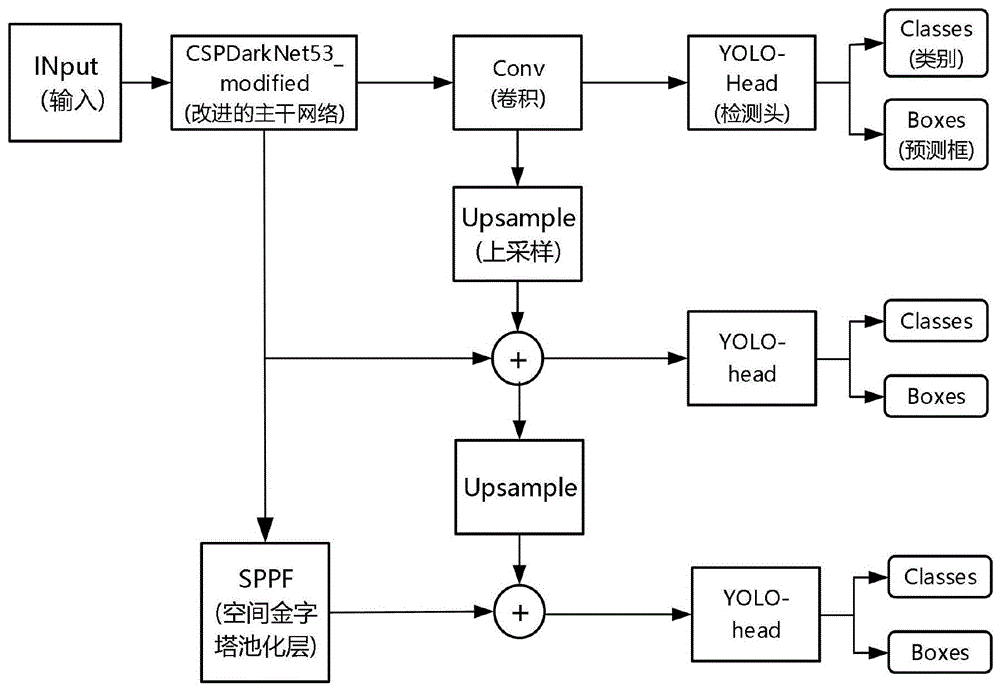
图2为本发明改进的YOLOv4卷积神经网络的结构示意图。
图3为本发明改进的主干网络的结构示意图。
图4为SPP结构的示意图。
图5为SPPF结构的示意图。
图6为ResNet-18的权值分布示意图。
图7为APoT进行4bit量化后数据分布示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
YOLOv4算法(目标检测算法)将输入图像分成若干个格子单元,每个单元对应最后输出的特征图中的一组通道。预测时这一组通道会得到该格子中的物体的检测结果。同时如果某个物体的中心位置的坐标处于该单元中,那么这个单元对应的一组输出通道就负责计算出这个物体的预测结果信息。在最后的结果中每个单元对应通道输出的结果对应于3个预测框信息,每个预测框的预测结果包括预测框4边相对于预设锚点(Anchor)的位置,框中存在这一目标的置信度,以及框中目标的分类结果。
现有技术中,YOLOv4算法使用CSPdarknet53网络(特征提取网络)提取特征,CSPdarknet53网络使用了残差块Resblock,它设置了残差连接,使网络可以容纳的层数更深,具备更强特征提取能力,同时借鉴了CSPNet设计思想,使用CSP残差结构,在减少了一些网络参数的同时保持网络检测能力,CSPdarknet53网络中使用Mish作为激活函数。CSPdarknet53网络在提取特征的同时将图像压缩到原图的1/32,之后检测器分别在原图的1/8,1/16,1/32倍的三个采样特征图上进行预测。在训练过程中YOLOv4算法使用了Mosaic法进行图像增强,同时使用CIoU作为Loss函数。
现有技术中,YOLOv4卷积神经网络的结构如图1所示,包括如下几个部分:
1.特征提取网络(主干网络)
通常来说,增加神经网络的深度能提高网络的信息含量,增强信息提取能力,但单纯地的增加网络深度可能导致网络退化问题,当网络达到一定深度时可能降低网络的性能,这是由于依靠单纯堆叠的传统多层网络结构不能很好地用非线性表达表示恒等映射,残差块便是为解决这一问题提出的。
残差网络通过引入残差学习来解决网络退化问题。对于由多个层堆积而成的堆积层结构,通过残差网络F(x)=H(x)-x学习后,输入为x对应的特征为H(x),残差为F(x)=H(x)-x,因此对应原始特征为F(x)+x。在极端情况下,当残差为0时,堆积层相当于恒等映射(identitymapping),至少保证模型性能不会下降;通常残差不会为0,堆积层会以输入特征为基础学习到新特征,使得性能更好。
在YOLOv3算法中,特征提取网络使用的是Darknet53。残差网络是Darknet53最主要的特征,Darknet53中的残差卷积是首先进行一次卷积核大小为3x3、步长为2的卷积,该卷积会压缩输入特征层的宽和高,此时可以获得一个新的特征层,我们将该特征层命名为layer。之后再对该特征层进行一次1x1的卷积和一次3x3的卷积,并把这个结果加上layer,此时便构成了残差结构。通过不断的1x1卷积和3x3卷积以及残差边的叠加,便可以大幅度的加深网络。
而在YOLOv4算法中,对Darknet53做了一点改进,借鉴了CSPNet,也就是跨阶段局部网络。CSPNet实际上是基于Densnet的思想,复制基础层的特征映射图,通过dense block发送副本到下一个阶段,将梯度的变化从头到尾地集成到特征图中,因此减少了模型的参数量和FLOPS数值。这样可以有效缓解梯度消失问题(通过非常深的网络很难去反推丢失信号),支持特征传播,鼓励网络重用特征,从而减少网络参数数量。
2.空间金字塔池化层
在空间金字塔池化层部分,YOLOV4卷积神经网络使用了SPP结构。
SPP结构在对CSPdarknet53网络的最后一个特征层进行三次DarknetConv2D_BN_Leaky卷积后,分别利用四个不同尺度的最大池化进行处理,最大池化的池化核大小分别为13x13、9x9、5x5、1x1(1x1即无处理)。它能够极大地增加感受野,分离出最显著的上下文特征。
3.获得预测结果
利用空间金字塔池化层,可以获得三个加强特征,这三个加强特征的shape分别为(76,76,256)、(38,38,512)、(19,19,1024),然后利用这三个shape的特征层传入检测头YoLo Head获得预测结果。检测头YoLo Head本质上是一次3x3卷积加上一次1x1卷积,3x3卷积的作用是特征整合,1x1卷积的作用是调整通道数。对三个特征层分别进行处理,假设预测是的VOC数据集,输出层的shape分别为(76,76,75)、(38,38,75)、(19,19,75),最后一个维度为75是因为该图是基于VOC数据集的,它的类为20种,YOLOv4针对每一个特征层的每一个特征点存在3个先验框,所以预测结果的通道数为3x25。其中的25可以拆分为4+1+20,其中的4代表先验框的调整参数(x_offset、y_offset、h和w),1代表先验框内是否包含物体,20代表的是这个先验框的种类,由于VOC分了20类,所以这里是20。
本发明的基于FPGA的YOLOv4卷积神经网络轻量化方法,是针对当前YOLOv4卷积神经网络结构复杂、参数多、训练所需的配置高以及实时检测每秒传输帧数低的问题,提出的一种轻量化YOLOv4卷积神经网络。
本发明的轻量化YOLOv4卷积神经网络的结构如图2所示,包括如下几个部分的改进设计:
1.主干网络的改进设计
YOLOv4卷积神经网络中主干网络CSPdarknet53的提取能力和检测精度非常强,在各个领域都有非常优秀的表现。但主干网络巨大的参数量对FPGA的性能有着较高的要求,使其对目标实时检测和算法移植有较高的难度。模型尺度缩放常用于深度卷积神经网络的轻量化,以获取推理速度更快、应用场景更广的卷积神经网络模型即CNN模型,但是轻量化的过程很难避免CNN模型学习能力下降。例如,YOLOv4-tiny虽然具有较低的参数量,较快的检测速度,但是特征提取能力较差,在复杂的场景变化中检测能力较差,对物体识别效果不太理想。
依据上述分析结果,本发明为了解决既提高速度又具备较强检测能力的问题,将YOLOv4卷积神经网络中的主干网络进行改进,改进后的主干网络结构如图3所示。本发明在进行主干网络尺度缩放的时候,借鉴CSPdarknet53_tiny的思想对主干网络CSPdarknet53中的残差块个数以及堆叠次数(现有技术中CSPdarknet53的堆叠次数为:1、2、8、8、4)进行了削减,削减后的CSPdarknet53网络中,残差块的个数为5,每个残差块的堆叠次数均为1,保留了主干网络中的CSPNet结构以及差结构,以提升轻量化过后的模型的检测精度。
2.激活函数的改进设计
Swish函数的计算公式如下式1所示:
Swish(x)=x·sigmoid(βx) 式1
其中,β是一个常数系数。
Swish函数没有上界,函数图形平滑,在深层模型上的效果优于FPGA上常用的ReLU函数(Relu函数是一种比较经典的激活函数)。通常来说,使用Swish函数代替ReLU函数可以提高模型的精确度。Swish函数没有上下界,可能导致计算结果越界的问题,同时Swish函数计算量较大,对于低算力设备是个负担。因此选择Swish函数的改进版H-swish函数。H-swish函数用一个近似函数来逼近Swish函数,是Swish函数的低精度版本,它能在大幅减少计算量的同时取得接近Swish函数的精度效果。
H-swish函数的计算公式如下式2所示:
其中,x表示输入,H-swish(x)表示输出,ReLU6函数是在普通ReLU函数的基础上增加限制最大输出为6,可以避免低精度模型中数值越界问题,ReLU6函数的计算公式如下式3所示:
ReLU6(x)=min(max(0,x),6) 式3
YOLOv4卷积神经网络中的主干网络使用Mish函数作为激活函数。
本发明分别对使用H-swish函数,Swish函数,Mish函数和Leaky-ReLu函数作为激活函数进行对比实验,得到的模型精度及在计算激活函数消耗的硬件资源如下表1所示。
表1不同激活函数消耗的硬件资源对比
根据表1可以看出Mish函数虽然精度最高,但计算需要消耗的硬件资源太多,不适合在FPGA设备上直接进行计算,H-swish函数得到的精度与Swish函数接近,比Leaky-ReLu函数更高,消耗的计算资源比Swish函数少,比Leaky-ReLu略多。因此,本发明综合考虑精度与消耗资源数量,选择H-swish函数作为主干网络的激活函数。
3.空间金字塔池化层的改进设计
在YOLOv4卷积神经网络中,SPP结构在对CSPdarknet53的最后一个特征层进行的卷积里,在对CSPdarknet53的最后一个特征层进行三次DarknetConv2D_BN_Leaky卷积后,分别利用四个不同尺度的最大池化进行处理,最大池化的池化核大小分别为13x13、9x9、5x5、1x1(1x1即无处理)。SPP结构能够极大地增加感受野,分离出最显著的上下文特征。SPP结构如图4所示。
本发明中,将SPP结构改为SPPF结构,SPPF结构是将输入串行通过多个5x5大小的池化层即MaxPool层,然后通过一个连接层即Concat层将输入以及各个MaxPool层的输出进行连接。这里需要注意的是串行两个5x5大小的MaxPool层是和一个9x9大小的MaxPool层计算结果是相同的,串行三个5x5大小的MaxPool层是和一个13x13大小的MaxPool层计算结果是一样的。也就是说,SPPF结构和SPP结构作用是等价的。SPPF结构如图5所示。
虽然SPP结构和SPPF结构二者作用相同,但由于SPPF结构计算量更小,所以能加快空间金字塔池化层运行速度。经试验验证后,对比SPP结构和SPPF结构的计算结果以及速度,去除SPP结构和SPPF结构中最开始和结尾处的1x1卷积层,对比含有MaxPool层的部分计算结果与运行速度,计算结果如下表2所示。
表2 SPP结构和SPPF结构的计算结果对比
通过表2的对比可以发现,两者的计算结果是一模一样的,但SPPF结构比SPP结构计算速度快了不止两倍。
4.模型定点量化
大部分的深度学习框架如Caffe、TensorFlow、Theano都使用32bit或者64bit的浮点数进行CNN模型的训练和推理。由于CNN模型的冗余性,决定了合理的减少参数几乎不会对网络精度造成影响,因此合理地量化网络可以在保证精度的情况下减少存储量。而且由于FPGA设备内存有限,在FPGA上运行卷积神经网络时通常不能把所有模型权重一次性传入其中,只能将读取的权重存放在ARM端内存中,预测时分为若干部分传入,这样会严重影响FPGA上目标检测算法运行速度。YOLOv4卷积神经网络的模型权重有244MB大小,压缩权重数据能有效减少数据传输消耗的时间,对算法预测过程起到有效的加速作用。
量化可以分为两种主要类型:①均匀化量化②非均匀量化。当前神经网络的量化方法往往采用均匀量化,这是因为均匀量化对于硬件设计更为友好,然而在一些研究中已经发现,深度神经网络DNN中的权重分布往往是遵循钟形和长尾分布而不是均匀分布,如图6为ResNet-18的权值分布图,相当多的权重集中在平均值(峰值区域)附近;而仅有很少权重的大小相对较高,并且超出了量化范围(称为离群值)。对于如此分布的权重,采用线性的均匀量化去描述,必然会导致较大的误差,这也是为什么当采用4bit乃至2bit的均匀量化时准确率会暴跌。
本发明所提出的轻量化方法中,以加法二次幂量化(APoT量化)为基础,加法二次幂是电子科大&哈佛大学&新加坡国立联合发表在ICLR2020上的一篇非均匀量化的工作。加法二次幂是一种针对钟形和长尾分布的神经网络权重,能够有效的非均匀性量化方案。通过将所有量化数值限制为几个二次幂相加,有利于提高计算效率,并与权重分布良好匹配。该量化方案效果很好,甚至可以与全精度模型竞争。在ImageNet上的3bit量化ResNet-34仅下降了0.3%的Top-1和0.2%Top-5的准确性,证明APoT量化的有效性。使用APoT进行4bit量化后数据分布如图7所示。APoT量化的量化规则如下式4所示:
其中,γ是一个缩放系数,以确保Q
例如,当b=4(4bit量化),k=2,n=4/2=2时,
p0∈{0,2
其中,Q
以上仅为本发明创造的较佳实施例而已,并不用以限制本发明创造,凡在本发明创造的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明创造的保护范围之内。
- 基于FPGA实现的卷积神经网络以及基于FPGA实现卷积神经网络的实现方法
- 基于YOLOv4模型和卷积神经网络的水果成熟检测方法和系统