一种基于序列到序列模型的制冷系统负荷预测方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及制冷机房能效的技术领域,尤其涉及一种基于序列到序列模型的制冷系统负荷预测方法。
背景技术
鉴于许多高能耗企业的动力站房的能耗占企业总能耗的近50%,因此,高效动力系统的能效优化越发重要,然而,高效的能效优化策略依赖于对高效动力系统负荷的准确预测。
现有的负荷预测算法多采用回归算法和短时序预测方法,如LSTM和GRU等循环神经网络,这些方法在预测中长时序预测问题时,因为存在误差急剧累积导致效果不好。目前,随着自编码器、Transformer等序列到序列算法在自然语言处理等领域的成功,为我们开展高效动力系统负荷的中长时序预测带来了新的思路,然而这类模型存在以下问题:
1.由于注意力机制的使用导致网络计算量和时间复杂度的开销相较于传统的CNN和RNN深度学习方法变得巨大;
2.对于时间序列的嵌入编码没有充分考虑其长序依赖,位置依赖,特殊时间点以及相互权重影响;
3.为了获取更多的特征,很多模型都采用多个编码器堆叠的方式,这不仅增加了大量的网络参数,同时也会造成参数过量而导致难以训练和收敛。
发明内容
为了解决上述问题,本发明提出一种基于序列到序列模型的制冷系统负荷预测方法,解决高效动力系统负荷的中长时序预测存在误差累积、准确率不高的问题,实现动力站房系统中长期负荷的更准确预测,满足工程级动力系统能效优化应用的准确性要求。
本发明可通过以下技术方案实现:
一种基于序列到序列模型的制冷系统负荷预测方法,将大量的历史数据整理为带有时间戳属性的多维时间序列MTS,以此训练序列到序列的预测模型,然后以给定窗口的时序数据作为输入,利用训练好的预测模型预测出接下来一段时间内的负荷走势,
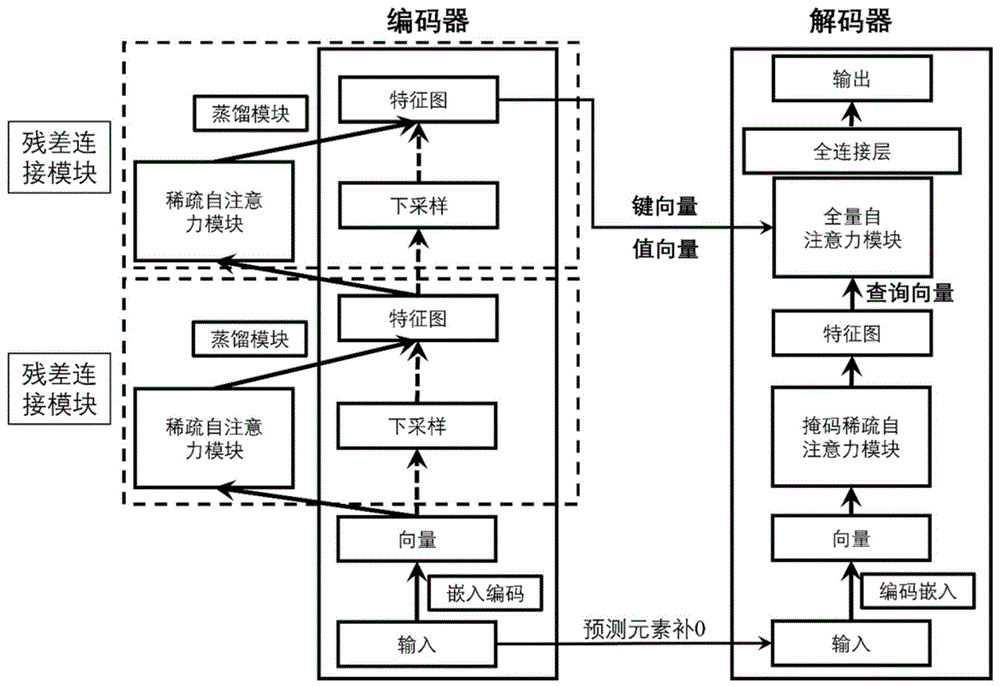
其中,所述预测模型包括编码器和解码器,所述编码器采用多层结构,稀疏自注意力模块和蒸馏模块构成的多层结构,其以时序数据嵌入编码形成的向量作为初始层结构的输入,然后前一层结构的输出作为后一层结构的输入,直至输出最终特征图,每层结构的输入均分为两路,第一路依次经过稀疏自注意力模块、蒸馏模块输出特征图Ⅰ,第二路经过下采样输出特征图Ⅱ,然后所述特征图Ⅰ和特征图Ⅱ经过残差连接模块进行特征融合,输出当前层特征图;
所述解码器将要预测的目标元素先填充为零,再进行嵌入编码生成的向量输入掩码稀疏自注意力模块,之后生成的特征图作为查询向量与编码器输出的最终特征图依次输入全量自注意力模块、全连接层,最后以生成式方式实时输出预测的目标元素。
进一步,所述稀疏自注意力模块使用全连接层将查询矩阵Q和键矩阵K融合后的特征投射到一个新的概率空间,再利用公式I(Q)=FC(Q+K)计算查询的重要性得分,通过设置n=clnL
进一步,所述特征图Ⅰ从第j个稀疏自注意力模块到j+1个稀疏自注意力模块的"提炼"过程定义为:
其中,t表示当前时间段,[·]
进一步,以矩阵形式表示所述多维时间序列MTS,先进行z-score标准化处理,然后按行进行批次划分,再利用如下公式进行嵌入编码形成向量作为预测模型的输入,
其中,
表示输入的特征维度为d
表示位置编码:
其中
表示用来调节位置编码和时间编码权重的参数,计算方式表示为:
其中,Relu()为激活函数,Conv1()为一维卷积,其输入通道数为D
进一步,利用如下方程式进行z-score标准化处理,
其中,d
本发明有益的技术效果在于:
1.提出了一种基于神经网络的稀疏自注意力机制,通过可学习的神经网络获取突出贡献注意力点积对,进一步优化Transformer自注意力机制在时间复杂度和内存使用方面的能力;
2.改进了传统深度模型编码器堆叠的方式,并采用多类别池化和残差的蒸馏机制,在不用叠加多个编码器的条件下尽可能多的获取特征;
3.提出了一种新的时间序列嵌入编码方式,使局部位置编码和全局时间编码具有更强的鲁棒性能。
附图说明
图1是本发明的数据演示示意图;
图2是本发明的预测模型的整体结构示意图;
图3是本发明的编码器结构的部分细节图。
具体实施方式
下面结合附图及较佳实施例详细说明本发明的具体实施方式。
如图1所示,本发明提供了一种基于序列到序列模型的制冷系统负荷预测方法,将大量的历史数据整理为带有时间戳属性的多维时间序列MTS,以此训练序列到序列的预测模型,然后以给定窗口的时序数据作为输入,利用训练好的预测模型预测出接下来一段时间内的负荷走势,
其中,预测模型包括编码器和解码器,该编码器采用多层结构,稀疏自注意力模块和蒸馏模块构成的多层结构,其以时序数据嵌入编码形成的向量作为初始层结构的输入,然后前一层结构的输出作为后一层结构的输入,直至输出最终特征图,每层结构的输入均分为两路,第一路依次经过稀疏自注意力模块、蒸馏模块输出特征图Ⅰ,第二路经过下采样输出特征图Ⅱ,然后所述特征图Ⅰ和特征图Ⅱ经过残差连接模块进行特征融合,输出当前层特征图;
该解码器将要预测的目标元素先填充为零,再进行嵌入编码生成的向量输入掩码稀疏自注意力模块,之后生成的特征图作为查询向量与编码器输出的最终特征图依次输入全量自注意力模块、全连接层,最后以生成式方式实时输出预测的目标元素。
具体如下:
步骤1:时序数据准备和预处理
在高效动力系统内的历史数据是模型训练和建立的关键因素,因此本发明需要对数据进一步处理,本发明将大量的历史数据整理为多维度的带有时间戳属性的多维时间序列MTS,并以此为基础训练本发明提出的预测模型即深度网络,然后给定一定窗口的时序数据,利用训练好的深度网络就可以预测出接下来一段时间内的负荷走势,如图1所示。
当MTS中某一属性的最大值和最小值未知时,或者存在异常值时,数据的最小-最大归一化是不适用的,因此我们对数据的z-score标准化方法定义如下:
其中d
D
一般来说,我们将训练数据D′按行转化为几个小批次,例如我们的训练数据一共有100行,可设置最小批次数是10行,那么B=100/10,就是一共10个批次,每批次中的行序号即为k。深度网络的输入可以定义为:
其中,b指的是最小批的索引(b∈1,…,B),k是最小批中的行索引(k∈1,…,L
输出的预测值为:
其中H是当前时间戳之后间隔的时间步数,k是输出中的行索引(k∈1,…,L
步骤2:构建序列到序列模型;
本发明的整体结构如图2所示,并遵循编码器-解码器架构。在编码过程中,输入被嵌入形成向量,然后进入本发明提出的稀疏自注意力模块,该稀疏自注意力模块的输出需要经过蒸馏模块然后输出特征图,为了保证特征前向传播过程中减少损失,本发明将嵌入后的向量进行下采样后与蒸馏模块的输出进行融合得到特征图,这一过程称为残差连接模块。
解码器接收长序列输入,将要预测的目标元素先填充为零,并进行与编码器同样的嵌入编码,生成的向量输入掩码稀疏自注意力模块,之后生成的特征图作为查询向量与编码器输出的键向量和值向量被送入全量自注意力模块。全连接层以生成式的方式即时预测输出元素。
2.1嵌入编码
多维时间序列是按时间顺序排列的数据序列,其数值在连续空间中。在大多数情况下,原始数据在嵌入后被用作模型输入,因此,嵌入编码决定了数据的表现程度。以前的工作通过手动加入不同的时间窗口、滞后运算符和其他手动特征推导来设计数据嵌入,然而,这种方法过于繁琐,需要特定领域的知识。在深度学习模型中,基于神经网络的嵌入方法已被广泛使用,特别是,考虑到位置语义和时间戳信息会对数据的嵌入产生影响,本发明提出了如下的嵌入编码方式:
其中,
表示输入的多维时间序列/>
为位置编码:
其中
每个全局时间戳都被一个可学习的嵌入
那么年:[0,0,…0]为23维的向量,2022年就将第1个0置1,再用全连接投射到512维
月:[0,0,…0]为12维的向量,11月就将第11个0置1,再用全连接投射到512维
日:[0,0,…0]为31维的向量,11日就将第11个0置1,再用全连接投射到512维
时:[0,0,…0]为24维的向量,11时就将第11个0置1,再用全连接投射到512维
分:[0,0,…0]为60维的向量,11分就将第11个0置1,再用全连接投射到512维
秒:[0,0,…0]为60维的向量,11秒就将第11个0置1,再用全连接投射到512维
另外,本发明使用
其中Relu()为激活函数,Conv1d()为一维卷积,其输入通道数为D
2.2稀疏自注意力模块
传统的全量自注意力模块是基于元组输入,即查询、键和值,可以描述为:
其中Q,K,V分别是查询、键和值的矩阵,d
其中k(q
众多研究表明,稀疏的自注意力分数形成了一个长尾分布,即少数点积对贡献了主要的注意力,其他点积对可以被忽略。在这种情况下,如果我们能通过Q和K之间的关系计算出最重要的n个查询向量,那么O(L
I(Q)=FC(Q+K)
其中I(Q)表示查询的重要性得分,其形状为L
通过上述方式,我们抛弃了传统Transformer中计算注意力分数的方法,相反,我们通过使用全连接层将Q和K融合后的特征投射到一个新的概率空间。此外,我们获得了查询的分数,并通过设置n=clnL
总而言之,我们的方法有以下优点:
1.减少了过滤查询向量过程中的计算工作量;
2.获得更快的训练速度和更低的GPU使用率;
3.实现了特征域的良好连续性。
2.3编码器
为了提取长序列输入的稳健的长距离依赖性,我们提出了一种单编码器的特征提取方法,并改进了蒸馏操作,这在图3中表示。在输入嵌入编码后的向量被我们的稀疏自注意力模块计算后,我们得到了图中注意力模块的N头权重矩阵,而我们从第j个注意力块到(j+1)个注意力块的"提炼"过程可以定义为:
其中[·]
其中Conv1d(·)用ELU(·)激活函数在时间维度上进行一维卷积滤波(卷积核大小为3)。虽然下采样可以降低特征的维度,但一些语义信息将被丢失。为了减轻这种影响,我们通过平行添加一个最大池化层(Maxpool)和一个均值池化层(AvePool)来获得尽可能多的语义信息(步长均为2),我们还添加了一个可学习的γ来调整这两个集合操作的重要性。此外,为了防止梯度和特征的消失,我们添加了一个残差连接。编码后,特征图的长度变成了原来的四分之一。与那些通过堆叠编码器的方法相比,我们的参数数量更少,计算速度更快,也能得到尽可能多的特征。
2.4解码器
解码器的输入包含两部分,一部分是编码器的输出(键和值),另一部分是将目标元素填充为0后的嵌入向量再经过掩码稀疏自注意力模块计算的查询向量。与稀疏自注意力模块相比,掩码稀疏自注意力模块在计算Softmax(·)之前对未来部分进行了屏蔽,并用每次查询前所有时间点的V向量的累加和填充。这种填充方法可以防止模型对未来信息的关注。最后,查询、键和值被传递到传统的全量自注意力模块,通过全连接层以获得预测结果。
步骤3:实验设置
3.1数据集
本发明所使用的数据集为冷机房制冷系统数据,时间跨度为2022.05.01至2022.08.31,数据间隔为1分钟,共177120条数据,数据维度分别为:时间,冷机负荷(kw),冷机一次侧负荷(kw),冷却塔负荷(kw),冷却泵负荷(kw),共5个维度。我们按照6:2:2的比例来划分训练集,验证集和测试集,我们采用滑动窗口来处理数据集,输入的序列长度为N,其后M步作为真值(与模型的预测值进行MSE训练)。
3.2实验设置
本发明所提出的深度网络模型在Pytorch框架下实现,并使用Adam优化器进行训练,初始学习率为10
3.3评价指标
对于本发明深度模型的评价指标,我们使用CORR、MAE和MSE,其中CORR表示经验相关系数,MAE是平均绝对误差,MSE表示平均平方误差。它们的定义如下:
其中y和
和
步骤4:模型执行
基于上述制冷机房序列到序列负荷预测模型,将待处理的制冷机房的历史负荷数据作为输入,得到对应的负荷预测结果,用于对制冷机房能效进行优化。
由于采用了上述技术方案,本发明的有益效果是:
1)相比传统的预测方法,中长期预测(超过30步)所得到的CORR提升3%,MAE提升25%,MSE提升70%;
2)与传统Transformer的自注意力模块相比,本发明将时间和空间复杂度可以从O(L
3)与传统的Transformer模型相比,本发明使模型的参数量下降50%
以上;
4)与传统Transformer的自注意力模块相比,当预测步长超过100步时,本发明将训练时间缩小5倍以上,显存占用量缩小2倍以上。
另外,我们还进行了更多领域的应用研究实验,具体如下:
实施举例1:冷机房制冷系统负荷预测
本发明应用于制冷系统负荷预测,输入数据步长为60,维度为5,预测步长为30,预测维度为5,分别为时间,冷机负荷(kw),冷机一次侧负荷(kw),冷却塔负荷(kw),冷却泵负荷(kw),总负荷为各个设备负荷相加的总和。模型构建的方式如图2所示,我们得到的预测值与真实值之间的CORR,MAE和MSE的结果为corr:0.954,mae:0.188,mse:0.079,而传统的Transformer的方法得到corr:0.917,mae:0.237,mse:0.136。
实施举例2:基于本发明的深度算法的汇率预测
我们收集了包括澳大利亚、英国、加拿大、瑞士、中国、日本、新西兰和新加坡在内的八个国家1990年至2016年的每日汇率。一共7588条数据,我们按照6:2:2比例进行训练集,验证集和测试集切分。我们将本专利应用于汇率预测,输入数据步长设为120,预测步长设为60,并且按照图2构建本发明的模型。我们得到的预测值与真实值之间的CORR,MAE和MSE的结果为corr:0.911,mae:0.241,mse:0.142,而传统的Transformer的方法得到corr:0.882,mae:0.275,mse:0.204。
实施举例3:
我们使用了一个公开的居民用电量统计的数据集作为测试。该数据集提供了两年的数据,每个数据点每分钟记录一次,该数据集来自我国的一个地区。数据集包含2年365天共1,051,200数据点。每个数据点均包含8维特征,包括数据点的记录日期、预测值“油温”以及6个不同类型的外部负载值。我们按照6:2:2比例进行训练集,验证集和测试集切分。我们将本专利应用于汇率预测,输入数据步长设为720,预测步长设为360,并且按照图2构建本发明的模型。我们得到的预测值与真实值之间的CORR,MAE和MSE的结果为corr:0.772,mae:0.308,mse:0.379,而传统的Transformer的方法得到corr:0.737,mae:0.377,mse:0.458。
技术人员应当理解,这些仅是举例说明,在不背离本发明的原理和实质的前提下,可以对这些实施方式做出多种变更或修改,因此,本发明的保护范围由所附权利要求书限定。
- 一种基于文本、知识库及序列到序列的自然问答方法
- 一种基于序列到序列模型的人群数量预测方法以及装置
- 一种基于Transformer序列到序列模型的径流预测方法