一种主题热点提取方法及系统
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及互联网大数据领域,更具体地说,涉及一种主题热点提取方法及系统。
背景技术
互联网产生的文本数据越来越多,文本信息过载问题也日益严重,自动化提取主题热点便是让用户在当今世界海量的互联网数据中找到有效的信息的一个重要手段。但当前的自动化提取效率较低、投入较高且不易于人工阅读。
发明内容
本发明要解决的技术问题是提供一种主题热点提取方法及系统,以解决背景技术中提到的问题。
为了达到上述目的,本发明采取以下技术方案:
一种主题热点提取方法,包括步骤:
S1:输入多个资讯,根据每个资讯的标题匹配每个资讯所对应的主题,并将表示该资讯的json文件放置于表示相应主题的csv文件下;所述json文件包含资讯的id、标题以及内容;
S2:在每一主题下抽取n条对应的若干资讯,并利用Textrank法抽取每条资讯的前k个关键句组合每条资讯的关键句,将n条资讯所得到的所有关键句组成该主题下的关键句列表;
S3:利用Textrank法对每个主题下的关键句列表进行关键句排序,再将排序后的关键句列表输入MMR模型中进行兼顾重要性和多样性的重排,并从中抽取前p个句子作为该主题的摘要句。
可选的一种方案下,所述方法还包括:
S4:将每个主题的关键信息提炼并整理到json文件输出;所述关键信息包括:每个主题的时间、关键词、主题标题、摘要列表;其中摘要列表包括每篇资讯的id、来源、时间、资讯标题、S3所提取的摘要句、url。
可选的另一种方案下,所述方法还包括:
S4:利用Bert算法对资讯标题进行压缩形成短语级标题;
S5:将每个主题的关键信息提炼并整理到json文件输出;所述关键信息包括:每个主题的时间、关键词、主题标题、摘要列表;其中摘要列表包括每篇资讯的id、来源、时间、资讯的短语级标题、S3所提取的摘要句、url。
优选的,S4中,利用Bert算法进行序列标注,标注标题中的每个字是否需要放入压缩标题形成短语级标题;标注规范为BIO。
优选的,S1中的匹配方式为将资讯与主题进行相似度进行计算,并将相似度最高的资讯与主题进行匹配。
一种用于实现上述方法的系统,包括:
读取模块:用于读取资讯;
匹配模块:用于将资讯匹配至对应的主题;
关键句提取模块:用于在每个主题内对资讯进行关键句提取;
排序模块:用于对关键句进行排序;
提取模块:用于提取前p个关键句作为摘要句;
观点输出模块:用于输出每个主题对应的包含摘要句的json文件。
优选的,所述json文件包括每个主题的时间、关键词、主题标题、摘要列表;其中摘要列表包括每篇资讯的id、来源、时间、资讯标题、提取模块所提取的摘要句、url。
优选的,所述系统还包括标题压缩模块,所述标题压缩模块用于对每个资讯的标题进行压缩形成短语级标题。
优选的,所述json文件包括每个主题的时间、关键词、主题标题、摘要列表;其中摘要列表包括每篇资讯的id、来源、时间、资讯的短语级标题、提取模块所提取的摘要句、url。
本发明方法和系统相对于现有技术的优点在于,能够从海量数据中提炼出与感兴趣的主题相关的关键信息,并聚集形成易于人工阅读、排查的主题及摘要信息,能够为各类机构及时获取与自身相关的热点主题需求提供支撑,极大地提高了实际应用中的推理合理性和效率,且能够显著降低信息监测人力投入,具有较强的应用价值。
附图说明
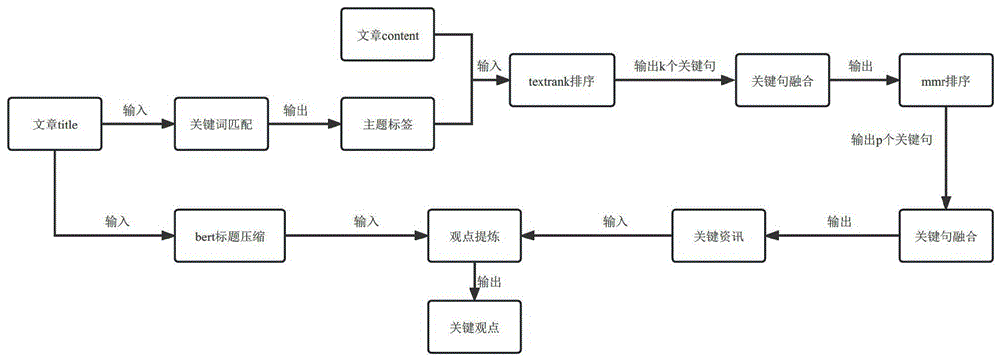
图1是本发明方法示意图。
具体实施方式
下面结合附图对本发明的具体实施方式作描述。
如图1所示为本发明方法示意图,包括步骤:
S1:输入多个资讯,根据每个资讯的标题匹配每个资讯所对应的主题,并将表示该资讯的json文件放置于表示相应主题的csv文件下;json文件包含资讯的id、标题以及内容;
S2:在每一主题下抽取n条对应的若干资讯,并利用Textrank法抽取每条资讯的前k个关键句组合每条资讯的关键句,将n条资讯所得到的所有关键句组成该主题下的关键句列表;
S3:利用Textrank法对每个主题下的关键句列表进行关键句排序,再将排序后的关键句列表输入MMR模型中进行兼顾重要性和多样性的重排,并从中抽取前p个句子作为该主题的摘要句。
其中,Textrank法原理如下:
Textrank是一种基于图的算法,其利用一篇文档内部的词语间的共现信息抽取关键词/句,其中节点为词,边为词与词之间的相似程度,可以是余弦相似度,在不断地迭代之后,这个马尔科夫链会形成一个平稳分布,而每个单词/句子的Textrank值就是平稳概率。
其中d为阻尼系数,w
其中,MMR模型原理如下:
MMR模型同时将相关性和多样性进行衡量。其可以方便的调节相关性和多样性的权重来满足偏向“需要相似的内容”或者偏向“需要不同方面的内容”的要求。
该公式的两项通过减号相连,在最大化该句子与剩余句子的相似程度的同时,减少该句子的冗余度(即该句子与已选句子的相似度),使被选句子的丰富程度更高。D
可选的一种实施例中,方法还包括:
S4:将每个主题的关键信息提炼并整理到json文件输出;关键信息包括:每个主题的时间、关键词、主题标题、摘要列表;其中摘要列表包括每篇资讯的id、来源、时间、资讯标题、S3所提取的摘要句、url。
可选的另一种实施例中,方法还包括:
S4:利用Bert算法对资讯标题进行压缩形成短语级标题;
S5:将每个主题的关键信息提炼并整理到json文件输出;关键信息包括:每个主题的时间、关键词、主题标题、摘要列表;其中摘要列表包括每篇资讯的id、来源、时间、资讯的短语级标题、S3所提取的摘要句、url。
S4中,利用Bert算法进行序列标注,标注标题中的每个字是否需要放入压缩标题形成短语级标题。标注规范为BIO。
其中,Bert算法为已知算法。Bert将transformer模型的encoder堆叠成12个block,拥有强大的语言表征能力和特征提取能力。其输入为每个句子的positionembedding、word embedding、segment embedding相加。
其中Muti-head Self-Attention部分为以下运算:
MutiHead(Q,K,V)=concat(head
Q、K、V为输入向量表示经不同的矩阵变换后的得到的矩阵。
在预训练阶段,通过MLM和NSP任务,我们获得文本的包含上下文语义信息的表示,本任务使用Bert_base_chinese作为预训练模型;在微调阶段,对于词性标注问题,最后fc层的输出与对应的真实词性标签计算损失,并进行反向传播更新模型的参数。在本次任务中,每个词语的标签为“是否作为压缩短语级标题的一词”。
S1中的匹配方式为将资讯与主题进行相似度进行计算,并将相似度最高的资讯与主题进行匹配。
本发明还包括一种用于实现上述方法的系统,包括:
读取模块:用于读取资讯;
匹配模块:用于将资讯匹配至对应的主题;
关键句提取模块:用于在每个主题内对资讯进行关键句提取;
排序模块:用于对关键句进行排序;
提取模块:用于提取前p个关键句作为摘要句;
观点输出模块:用于输出每个主题对应的包含摘要句的json文件。
一种实施例下,json文件包括每个主题的时间、关键词、主题标题、摘要列表;其中摘要列表包括每篇资讯的id、来源、时间、资讯标题、提取模块所提取的摘要句、url。
另一种实施例下,系统还包括标题压缩模块,标题压缩模块用于对每个资讯的标题进行压缩形成短语级标题。json文件包括每个主题的时间、关键词、主题标题、摘要列表;其中摘要列表包括每篇资讯的id、来源、时间、资讯的短语级标题、提取模块所提取的摘要句、url。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 一种基于机动车电子标识数据的城市出行热点提取方法
- 一种社交媒体热点主题提取方法与系统
- 基于TF‑IDF特征的短文本聚类以及热点主题提取方法