一种基于表格驱动的序列化字节流自动生成方法及系统
文献发布时间:2024-01-17 01:26:37
技术领域
本发明涉及计算机软件和通信技术领域,具体而言,涉及一种基于表格驱动的序列化字节流自动生成方法及系统。
背景技术
在当前主流的计算机系统和通信系统中,要想实现数据在物理介质中的存储或通信传输,无论源数据在逻辑上具有何样的结构,都必须将其转化为一个单维的有序字节(Byte)串,这种转化操作称为“序列化”,所形成的Byte串简为称“字节流”或“数据块”。
将具有多样结构的数据转化为字节流,是计算机、软件、通信等众多工程技术领域中频繁涉及的一项工作,实现其自动化对提高生产效率具有重要意义。为此,人们发展了多项相关的技术方法,在云计算等领域,发展了基于XML、JSON、gRPC等标准的序列化方法,但这些方法往往需要在字节流中加入大量的标记符,并且仅允许使用若干指定数据编码格式,因此,数据输入不便、灵活性受限,并且信息存储传输效率也受到影响。
专利CN1783881B(绑定结构化数据协议至提供字节流协议的机制)、专利CN104077335B(一种结构化数据的序列化、反序列化方法、装置和系统)和专利CN110597814B(结构化数据的序列化、反序列化方法以及装置)都是对特定业务的若干个已知结构的结构化数据,按照不同数据类型或结构类型,运行提前设计好的对应程序模块对其序列化,不涉及程序模块的自动生成。专利CN103019689B(通用的对象序列化的实现方法)是把某对象序列化成XML。专利CN105868364A(一种基于字节流的结构化数据表示方法)将不同结构化数据转化为某一特定格式的字节流。定义通用格式的字节流,以表示特定场景的不同结构化数据,仅适用于特定业务,不能满足不同结构化数据需要转换成不同格式字节流的更广泛业务需求。专利CN108446319A(将数据进行二进制序列化的方法和系统)针对业务已有的某特定结构的数据的序列化,通过对已有序列化结果的部分替换,实现特定数据发生变化后的快速序列化。专利CN112214516A(数据序列化和反序列化的方法及装置)先将数据结构化,再将结构化数据转为字节流,实现数据的序列化。其结构化数据仅是一个中间过程,且对结构化数据的结构、长度等有约束,不通用。
发明内容
本发明解决的技术问题是:提供了一种基于表格驱动的序列化字节流自动生成方法及系统,操作人员只需要通过填写Excel或CSV表格,即可完成字节流的定义,以及批量数据的自动化转换,友好易用、灵活高效,尤其适用于数据结构需频繁更改的场景,并且可与文档编制工作无缝衔接、进一步节约人力。
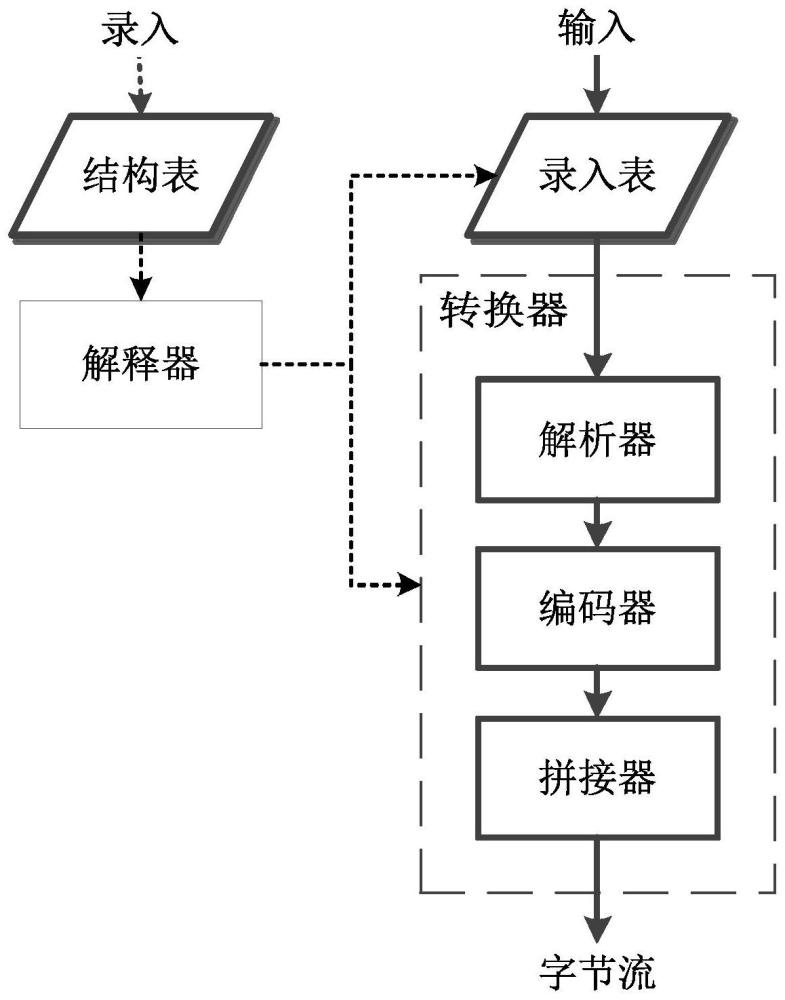
本发明的技术方案是:一种基于表格驱动的序列化字节流自动生成系统,包括结构表和解释器;所述结构表用于提供用户业务中涉及的数据组及其对应的字节流格式的定义;数据组即业务相关的所有结构性数据;所述解释器通过读取上述结构表,对其中的索引单、定义单进行语意分析,生成录入表和转换器;运行生成的转换器,读取生成的输入了业务结构性数据的所有录入表,生成对应的若干个字节流,供业务使用。
所述结构表由多个表单组成,包括:
若干个定义单,每个定义单用于描述一个字节流,以及该字节流承载的一组结构性数据,每组结构性数据可包含若干条元数据;
一个索引单,用来对所有的定义单及其对应的字节流进行统一编目,即为每种字节流赋予一个全局唯一的块标识。
所述定义单采用二维表格;其每一行或每一列用于描述一条元数据,相应的每一列或每一行用于描述元数据的一项属性;定义单的表头为元数据的属性。
每条元数据的定义包括以下属性:段标、格式、字长、路序、名签、说明、填充;其中:
段标,用于定义结构性数据中的重复结构,以及各重复结构的层级和从属关系;
格式,用于定义元数据的二进制编码方式;
字长,用于定义元数据对应的字节片段占据多少个字节和数位;
路序,用于定义元数据对应的字节片段在字节流中的位置;
名签,用于为每个元数据提供全局唯一的标识;
说明,用于定义元数据参数量纲、含义描述、取值范围、显示格式、特殊处理函数;
填充,用于定义当元数据的默认填充值。
所述索引单采用二维表格;其每一行用于描述一条字节流,每一列用于描述字节流的一项属性;索引单的表头为字节流的属性。
所述字节流的属性包括:块标识、定义单名称、字节流长度、字节流大小端、定义单使能标志;
块标识、用于给定相应定义单对应的块标识;
定义单名称、用来作为索引单到所有定义单的索引;
字节流长度、用来描述对应字节流的长度;
字节流大小端、用来指明整个字节流的数据按照大端或小端组织;
定义单使能标志,用来指明相应定义单是否需要更新。
所述解释器中的录入表作为提供数据录入网格的空白表格模板,供业务使用时录入承载着业务内容的结构性数据;根据录入表中的每一个有效单元格的行列索引,能够唯一确定其对应的元数据。
所述解释器中的转换器与录入表配套使用,读取已录入业务数据的录入表,生成业务需求的字节流。
所述转换器包括解析器、编码器和拼接器,完成对所有录入表的处理;其中,
解析器,通过读入录入表,依次提取录入表中全部单元格内的字符串,并对字符串进行语意解析,获得每个元数据的原始输入值、对应编码要求以及对应的字节流拼接要求;
编码器,按照元数据的编码要求,将所有元数据原始输入值逐一编码转换为对应的Byte组;
拼接器,按照元数据的字节流拼接要求,将编码器产生的所有Byte组拼接成结构性数据对应的字节流,并输出。
一种基于所述系统的序列化字节流自动生成方法,包括:
建立语法约定及对应转换函数基础库:确定结构表的索引单、定义单分别包含的属性集;对于结构表中的每个属性,约定其关键词、标记符和语序;
建立结构表模板:对于每个表单,以其属性的名称,建立表头;
开发解释器:按照建立的结构表的语法约定,及对应的转换函数基础库,开发解释器;所述解释器通过读取上述结构表,对其中的索引单、定义单进行语意分析,生成录入表和转换器;所述语意分析即分析结构表中各属性的内容,获取所有结构性数据对应的所有元数据的编码规则和数据录入要求;
建立结构表实例:按照建立的语法约定,将用户业务中涉及的数据组及其对应的字节流格式的定义,录入结构表模板中,形成结构表实例;
生成转换器和录入表:解释器读取提供的、已录入业务数据定义的结构表实例,依据建立的语法约定,对其中的索引单和所有定义单进行语意分析,获取所有结构性数据及其对应的所有元数据的编码规则和数据录入要求,生成对应有效定义单数目的若干个录入表模板和配套的转换器;
录入结构性数据:在生成的成套录入表中,输入结构性数据;
运行转换器生成字节流:运行生成的转换器,读取生成的输入了业务结构性数据的所有录入表,生成对应的若干个字节流,供业务使用。
本发明与现有技术相比的有益效果是:
(1)本发明基于表格,操作友好,不依赖复杂的建模工具。
(2)本发明利用率高效。特别是业务需求频繁变更情况下,修改方便。
(3)本发明修改灵活。本发明通过建立语法约定,实现不同业务用途字节流的协议等定义的录入,不对业务具体设计做约束,具有极大的灵活性。
(4)本发明实现了不同业务所需字节流编码工具的通用化实现,避免了重复开发过程,提高研发与生产效率。
附图说明
图1为本发明实施例系统组成示意图;
图2为本发明实施例实施方法示意图;
具体实施方式
下面结合附图和具体实施方式对本发明作进一步阐述。
本发明涉及一种基于表格驱动的序列化字节流自动生成系统,该系统包括1套结构表和1个解释器,其中:
结构表用于提供用户业务中涉及的数据组及其对应的字节流格式的定义。数据组即业务相关的所有结构性数据。
所述结构表是一个套表,由多个表单组成,包括:
1)若干个定义单,每个定义单用于描述1个字节流,以及该字节流承载的1组结构性数据,每组结构性数据可包含若干条元数据;
2)1个索引单,用来对所有的定义单及其对应的字节流进行统一编目,即为每种字节流赋予1个全局唯一的块标识。
所述定义单是一个2维表格:
1)其每一行(或每一列)用于描述1条元数据,每一列(或每一行)用于描述元数据的1项属性;
2)在定义单的表头,列出元数据的属性。每条元数据的定义包括但不限于以下属性:段标、格式、字长、路序、名签、说明、填充。其中:
·段标,用于定义结构性数据中的重复结构,以及各重复结构的层级和从属关系;
·格式,用于定义元数据的二进制编码方式;
·字长,用于定义元数据对应的字节片段占据多少个字节(Byte)和数位(bit);
·路序,用于定义元数据对应的字节片段在字节流中的位置;
·名签,用于为每个元数据提供全局唯一的标识。
·说明,用于定义元数据参数量纲、含义描述、取值范围、显示格式、特殊处理函数等。
·填充,用于定义当元数据的默认填充值。
定义单形式如下表所示:
所述索引单是一个2维表格:
1)其每一行用于描述1条字节流,每一列用于描述字节流的1项属性;
2)在索引单的表头,列出字节流的属性,所述字节流的属性包括但不限于:块标识、定义单名称、字节流长度、字节流大小端、定义单使能标志。
·块标识、用于给定相应定义单对应的块标识;
·定义单名称、用来作为索引单到所有定义单的索引;
·字节流长度、用来描述对应字节流的长度;
·字节流大小端、用来指明整个字节流的数据按照大端或小端组织;
·定义单使能标志。用来指明相应定义单是否需要更新。
索引单形式如下表所示:
所述定义单、索引单强调的是其功能划分。除可以独立表单的形态呈现外,亦可以复合表格的形态呈现。该实施例按照独立表单形式呈现。
解释器提供一套可执行的计算机程序,能够通过读取上述结构表,对其中的索引单、定义单进行语意分析,生成录入表和转换器。
(1)所述录入表是一套提供了数据录入网格的空白表格模板,供业务使用时录入承载着业务内容的结构性数据。其技术特征包括:根据录入表中的每一个有效单元格的行列索引,能够唯一确定其对应的元数据。
(2)转换器与录入表配套使用,读取已录入业务数据的录入表,生成业务需求的字节流。所述转换器包括解析器、编码器和拼接器,完成对所有录入表的处理。
1)解析器,通过读入录入表,依次提取录入表中全部单元格内的字符串,并对字符串进行语意解析,获得每个元数据的原始输入值、对应编码要求以及对应的字节流拼接要求。
2)编码器,按照元数据的编码要求,将所有元数据原始输入值逐一编码转换为对应的Byte组。
3)拼接器,按照元数据的字节流拼接要求,将编码器产生的所有Byte组拼接成结构性数据对应的字节流,并输出。
本发明还涉及一种基于表格驱动的序列化字节流自动生成方法。为进一步说明该方法的各个步骤,该实施例以某业务字节流自动转换需求做阐述,该业务需要生成下述两种结构性数据的自动转换工具,并生成业务数据对应的字节流,一种基于表格驱动的序列化字节流自动生成方法,包括如下步骤:
步骤1,建立语法约定及对应转换函数基础库:
确定结构表的索引单、定义单分别包含的属性集。对于结构表中的每个属性,约定其关键词、标记符和语序等。
定义单的属性包括段标、格式、字长、路序、名签、说明、填充。
定义单各属性语法约定如下:
段标约定用来实现对不同参数或数据的分层、折叠。实现对单个表单中重复形式的多个或多组参数的批量管理。
约定:“G#”,如G0指示父层,G1/G2/G3...指示折叠层(子层)。
格式约定实现通用数据格式与该系统数据格式的一一映射关系。
约定:“填充”,指明某个参数或某些字段需要按照给定的内容填充,如填充0xAA;
约定:“原码(或U)”,参数按原码处理;
约定:“补码(或I)”,参数按补码处理(量纲、范围等由其他约定指明);
约定:“浮点(或F)”,参数按浮点数处理(具体是单精度浮点值或双精度浮点值由其他约定指明);
约定:“枚举(或E)”,参数按枚举类型处理(枚举内容由其他约定指明);约定:“G#×N”,参数为折叠结构,表示N个G#组成该G#的父层;
约定:“固定”,链接到遥控协议总目录表单的块标识;
约定:“Func#”,定制数据处理方法,如可用Func1指明某参数的处理需要采用定制的Func1方法(如CRC校验计算等),再如可用于定义多模态数据块中的分支结构,以及各分支结构的层级和从属关系;
字长约定约定:“整数值”(如1、2、4、8...),表示某参数对应表示的字节长度;
约定:“分数值”(如1/8、2/8、4/8...),表示某参数对应表示的比特长度;路序约定对路序描述格式进行约定,实现字节流路序的统一描述。
约定:“Wx~Wy”,其中x和y可以改变,中间用“~”连接,表示该参数内容需要表示到第x到第y个字节当中;
约定:“比特组枚举[y:x]”,其中y≥x,表示参数内容需要表示到指定长度数据的第y到第x比特位上;
约定:“数据组”,表示该关键字以下为一个子层G#(#>0);
名签约定不同父层G0或子层G#(#>0)的名签不能重复,保证遥控协议录入表中各参数的唯一性。
说明约定实现参数量纲、参数含义、参数范围的统一描述方法。
约定:“[x,y]”,其中y≥x,表示该参数工程值的范围约束;
约定:“量纲:x(T)”,其中x表示当量,T表示参数量纲;
约定:“
约定:“@para”,表示要求统计表中名签为para的有效个数;
约定:“EpSecUTC”,表示业务实际使用时,给出的时间格式是yyyy-mm-ddThh:mm:ss。同时约定计算时间间隔时的时间基准为2009-01-01T 00:00:00。
填充约定规定不同参数及空白参数默认填充的统一描述方法。包括“0x”十六进制描述、“0b”二进制描述及“0d”十进制描述。
索引单的属性包括块标识、定义单名称、字节流长度、字节流大小端、定义单使能标志。
索引单各属性语法约定如下:
块标识约定约定:按照三种形式描述,“0x”十六进制描述、“0b”二进制描述及“0d”十进制描述。
定义单名称约定和定义单的名称需要一致,用来作为索引单到所有定义单的索引。
字节流长度约定整数。
字节流大小端约定约定:“HToL”,指明整个字节流的数据按照大端组织;
约定:“HLoT”,指明整个字节流的数据按照小端组织;
定义单使能标志约定约定:“Enable”,指明该定义单需要更新;
约定:“Disable”,指明该定义单不需要更新;
建立好上述各属性对应语法约定后,建立转换函数基础库。即依据本发明建立的前述语法约定,实现每种约定对应的转换函数,所有转换函数组成转换函数基础库。
步骤2,建立结构表模板:
对于每个表单,以其属性的名称,建立表头。其中:
定义单模板的表头采用元数据的所有属性的名称建立;
索引单模板的表头采用字节流的所有属性的名称建立。
步骤3,开发解释器:
按照步骤1建立的结构表的语法约定,及对应的转换函数基础库,开发解释器。解释器是一套可执行代码或软件,通过读取上述结构表,对其中的索引单、定义单进行语意分析,生成录入表和转换器。所述语意分析即分析结构表中各属性的内容,获取所有结构性数据对应的所有元数据的编码规则和数据录入要求。
解释器运行的具体步骤为:
1、读取索引单和所有定义单;
2、对某一定义单,将定义单的折叠结构展开,列出所有定义单中定义的参数及其相关约定,包括对应的索引单内对定义单的描述,组成形如{序号、段标、格式、字长、路序、名签、说明、填充、数值、编码}n行9列的定义单字符串矩阵DefMatrix,其中“序号”从1开始逐一增加,“数值”列和“编码”列留空,其余列从定义单的对应行读出;并组成形如{序号、块标识、定义单名称、字节流长度、字节流大小端、定义单使能标志}的1行6列索引单字符串矩阵IndxMatrix。
3、对索引单中属性“定义单使能标志”为“Enable”的所有行,新建对应的录入表空表,录入表空表的名称由索引单属性“定义单名称”对应的字符串处理后得到,处理方法是将所述字符串中“定义单”替换为“录入表”。
4、录入表的列数为1+n。第一列为字节流名称。定义单中“说明”属性和“格式”属性共同指出的需要录入数据的对应参数均放到列中,列的名称为对应的“名签”属性内容。
其中不需要录入的数据包括:
①“格式”属性内容为:“填充”、“固定”;
②“说明”属性内容为:“@para”;
另外,对于某“段标”属性为“Gk”(k>0),且“格式”属性为“Gk+1×N”的折叠结构,将“段标”为Gk+1的所有参数展开N组到列中,列的名称即为前述“段标”为Gk+1的参数的“名签”属性内容后缀加1、2、3...N。
5、录入表的行数为2+m。第一行表头,第二行为说明,说明内容为定义单中对应参数的“说明”属性内容。
行数m由折叠结构确定,具体的,对于某“段标”属性为“G0”,且“格式”属性为“G#×N”的折叠结构,其展开后应有Ns行,对所有Ns求和,即录入表行数m=Sum(Ns),行的名称为“格式”属性为“G#×N”所在行对应的“名签”属性内容后缀加1、2、3...N。
以上新建录入表的步骤中,对录入表空白模板中预留填数的单元格进行记录,形成形如{录入表名称、定义单字符串矩阵DefMatrix序号、录入表行号、录入表列号}的n行4列录入表单元格查找矩阵SeekMatrix。
解释器的上述步骤执行完成后,即完成了所有录入表的建立。
以下步骤描述解释器生成转换器的过程:解释器生成转换器的过程,即是将上述定义单字符串矩阵DefMatrix、索引单字符串矩阵IndxMatrix、录入表单元格查找矩阵SeekMatrix三个字符串矩阵中的数值、约定等,通过查找转换成转换函数基础库中的转换函数,最终生成可执行代码的过程。
6、生成解析器步骤
按录入表表名称读取录入表。录入表表名称取自录入表单元格查找矩阵SeekMatrix中的“录入表名称”属性内容。
按照{录入表名称、录入表行号、录入表列号、行列对应单元格的字符串}形式提取录入表中的内容。形成录入表内容矩阵DataMatrix。
将录入表单元格查找矩阵SeekMatrix和录入表内容矩阵DataMatrix的录入表单元格的具体字符串按照索引填入定义单字符串矩阵DefMatrix的“数值”列的对应行中,完成对定义单字符串矩阵DefMatrix更新。
7、生成编码器步骤
对定义单字符串矩阵DefMatrix的每一行,及对应的索引单字符串矩阵IndxMatrix,依据前述已经建立好的语法约定,依次对其“说明”属性内容、“格式”属性内容、“说明”属性内容、“字长”属性内容、及“字节流大小端”属性内容查找其在转换函数基础库中的对应函数,查找出的函数按照前述属性描述的顺序依次排列,前一函数的输出即为后一函数的输入。每一行的编码完成后,编码结果Byte组存入定义单字符串矩阵DefMatrix的“编码”列。
特别的,
对“格式”属性内容为“填充”的行,将“填充”属性内容填入“编码”列;对“格式”属性内容为“固定”的行,将对应索引单字符串矩阵IndxMatrix中“块标识”属性内容填入“编码”列;
对“说明”属性内容中包括“@para”的,对定义单字符串矩阵DefMatrix中所有行中“名签”属性内容为“para”的有效个数进行统计,并按照“格式”属性内容和“字长”属性内容进行编码,结果填入“编码”列;
对定义单字符串矩阵DefMatrix的所有行都完成前述转换函数查找、排列及特别处理方式的编程实现。
8、生成拼接器步骤
按照“字节流长度”属性内容生成对应长度的“全零”字节流。
对定义单字符串矩阵DefMatrix的每一行,按照“路序”属性内容、将其“编码”属性内容Byte组填入前述“全零”字节流的对应位置中,即完成所有码字拼接,产生最终字节流。
解释器的上述步骤执行完成后,即完成了转换器(包括解析器、编码器和拼接器)的生成。
步骤4,建立结构表实例:
按照步骤1建立的语法约定,将用户业务中涉及的数据组及其对应的字节流格式的定义,录入结构表模板中,形成结构表实例。
所形成的结构表中,定义单的数量与该业务使用的字节流类别的数量一致。
定义单1,业务地点信息数据定义单
定义单2,工作时间窗口数据定义单
索引单
步骤5,生成转换器和录入表:
解释器读取步骤4提供的、已录入业务数据定义的结构表实例,依据步骤1建立的语法约定,对其中的索引单和所有定义单进行语意分析,获取所有结构性数据及其对应的所有元数据的编码规则和数据录入要求,生成对应有效定义单数目的若干个录入表模板和配套的转换器。
录入表模板1,业务地点信息数据录入表
录入表模板2,工作时间窗口数据录入表
生成的转换器是一套可执行代码。
步骤6,录入结构性数据
在步骤5生成的成套录入表中,输入结构性数据。
业务地点信息数据录入表
工作时间窗口数据录入表
步骤7,运行转换器生成字节流
运行步骤5生成的转换器,读取步骤6生成的输入了业务结构性数据的所有录入表,生成对应的若干个字节流,供业务使用。
业务地点信息数据对应的字节流如下
工作时间窗口数据对应的字节流如下
对于指定业务,步骤1~5仅需执行1次,即已产生包括录入表和转换器的字节流生成工具。业务使用需要批量转换数据时,只需重复步骤6-步骤7即可。
本发明虽然已以较佳实施例公开如上,但其并不是用来限定本发明,任何本领域技术人员在不脱离本发明的精神和范围内,都可以利用上述揭示的方法和技术内容对本发明技术方案做出可能的变动和修改,因此,凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化及修饰,均属于本发明技术方案的保护范围。
- 一种基于字节流格式的kudu数据导入系统及方法
- 一种基于时间序列化差异检测恶意代码的方法及系统
- 一种基于视觉众包数据自动生成车道级拓扑关系的方法、系统及存储器
- 一种基于表格模板集的表格自动生成方法及系统
- 一种基于表格模板集的表格自动生成方法及系统