融合蛋白合成的方法和产品
文献发布时间:2024-04-18 19:52:40
本申请是申请日2016年6月3日、申请号201680037511.8、发明名称为“融合蛋白合成的方法和产品”的发明专利申请的分案申请。
技术领域
本发明涉及融合蛋白(即包括两种或更多种共价连接的蛋白质的聚合物,如下面所定义的)的合成(即生产、生成或装配),并且具体地涉及使用反应以形成异肽键的正交的肽连接体对模块式(例如逐步)合成融合蛋白。本发明涉及提供用于合成融合蛋白——具体而言固相合成——的新方法。该方法可以有利地用于生产多种产品,包括融合蛋白,例如融合蛋白阵列。本发明也提供了肽连接体和正交的所述连接体对在合成融合蛋白中的用途。也提供了包括所述连接体的重组蛋白、编码所述蛋白和连接体的核酸分子、包括所述核酸分子的载体和包括所述载体和核酸分子的宿主细胞。也提供了包括所述重组多肽和/或核酸分子/载体的试剂盒。也考虑由本发明的方法获得的融合蛋白和包括所述融合蛋白的产品,例如阵列和文库。
背景技术
生物学事件通常取决于多种蛋白质的协同活性并且复合体中蛋白质的精确排列影响和决定它们的功能。因而,以受控方式排列复合体中单独蛋白质的能力代表表征蛋白质功能中的有用工具。而且,缀合多种蛋白质以形成所谓的“融合蛋白”可以导致具有有用特征的分子。例如,簇集单一种类的蛋白质通常大大地增强了生物学信号,例如疫苗上的重复抗原结构。具有不同活性的簇集蛋白也可以导致具有改善活性的复合体,例如通过酶的底物引导(substrate channelling)。
但是,簇集不同种类的蛋白质成为精确的人造“融合蛋白”已经遇到了许多问题。例如,单独蛋白质或蛋白结构域可以基因地接合为一个长的开放阅读框,但是蛋白质合成中的错误和错折叠很快成为限制。可选方法已经集中于单独地表达蛋白质或蛋白结构域并且然后将这些“模块”或“单元”连接在一起。例如,方法已经集中于修饰蛋白质以包含良好表征的相互作用配偶体,比如生物素/抗生物素蛋白,从而使得蛋白质能够通过非共价相互作用形成复合体。其它方法依赖于蛋白质内的反应基团——具体而言半胱氨酸残基——以通过共价键即二硫键连接蛋白质。但是,即使最佳的非共价键或可逆共价键允许融合蛋白的重排。因此,现有方法是受限的,因为它们通常导致难以分离的融合蛋白的不明确的混合物和/或在多种环境下例如在还原条件下不稳定的融合蛋白。
用于合成融合蛋白的系统的重要特征包括独立于任何模板的所述融合蛋白内的单独蛋白(即模块、结构域或单元)与每种蛋白(即模块、结构域或单元)的简单表达之间的分子上限定的连接。对于每种反应具有近乎定量的产率从而最小化几个步骤之后的非均质(heterogeneous)产品的无意合成——其是混合物内不完整链的常见结果——也是高度期望的。对于单独模块也优选地是利用相对小的肽标记物而不是大的蛋白融合结构域进行修饰,以便于最小化对融合蛋白内的每种模块功能的破坏。但是,现有融合蛋白合成方法尚不能够满足这些标准。
因而,对于用于合成融合蛋白的改善方法存在需要和期望,并且现在已经发现了形成异肽键以生成不可逆共价键的肽连接体可以被用在用于合成融合蛋白的模块式(例如逐步)和高产率方法中。
异肽键是在羧基/甲酰胺和氨基之间形成的酰胺键,其中羧基或氨基中的至少一种在蛋白主链(蛋白质的骨架)的外部。这些键在生物学条件下是化学不可逆的并且它们对大多数蛋白酶具有抗性。事实上,蛋白质之间的异肽键已经被确定为测量的最强蛋白相互作用。
异肽键形成可以是酶催化的,例如通过转谷氨酰胺酶。通常在自然环境中发现异肽键改善蛋白质复合物的强度和/或稳定性,例如细胞外基质结构的稳定或血凝块的增强。
异肽键也可以自发形成,如在HK97噬菌体衣壳形成和革兰氏阳性细菌菌毛中已经鉴定的。已经提出了自发的异肽键形成在蛋白质折叠之后发生,这通过来自赖氨酸的ε-氨基亲核攻击来自天冬酰胺或天冬氨酸的Cγ基团进行——其由附近的谷氨酸或天冬氨酸促进。
能够自发异肽键形成的蛋白质已经有利地用于研发肽标记物/结合配偶体对,其已经共价地彼此结合并且其因此提供了不可逆的相互作用(参见例如WO2011/098772,其通过引用被并入本文)。在这方面,能够自发异肽键形成的蛋白质可以表达为分开的片段,以产生肽标记物和肽标记物的结合配偶体,其中两个片段能够通过异肽键形成而共价重构。通过肽标记物和结合配偶体对形成的异肽键在下列条件下是稳定的:其中非共价相互作用将快速解离,例如在长时间段内(例如数周)、在高温下(到至少95℃)、在高的力(highforce)下或者利用严苛的化学处理(例如,pH 2-11、有机溶剂、洗涤剂或变性剂)。
简言之,肽标记物/结合配偶体对可以衍生自能够自发形成异肽键的任何蛋白质(异肽蛋白),其中蛋白质的结构域分开地表达以产生肽标记物和肽结合配偶体,该肽标记物包括参与异肽键的残基中的一种(例如赖氨酸),该肽结合配偶体包括参与异肽键的另一种残基(例如天冬酰胺或天冬氨酸)。在一些情况下,肽标记物或结合配偶体中的一种包括形成异肽键需要的一种或多种其它残基(例如谷氨酸)。但是,已经发现,分开表达包括参与异肽键形成的残基的结构域,即作为三种分开的肽(结构域、模块或单元)是可能的。在这方面,肽标记物包括参与异肽键的残基中的一种(例如赖氨酸),肽结合配偶体包括参与异肽键的另一种残基(例如天冬酰胺或天冬氨酸)并且第三肽包括参与异肽键形成的一种或多种其它残基(例如谷氨酸)。将所有三种肽混合导致在包括反应以形成异肽键的残基的两种肽,即肽标记物和结合配偶体之间形成异肽键。因此,第三肽介导肽标记物和结合配偶体的缀合但是不形成部分得到的结构,即第三肽不共价连接至肽标记物或结合配偶体。因此,第三肽可以被视为蛋白连接酶或肽连接酶。这是特别有用的,因为它使需要被融合至感兴趣蛋白质的肽标记物和结合配偶体的大小最小化,从而降低由肽标记物或结合配偶体的添加引起的不需要的相互作用的可能性,例如错折叠。
如在下面更详细讨论的,能够自发形成一个或多个异肽键的各种蛋白质(所谓的“异肽蛋白”)已经被鉴定并且可以被修饰以产生肽标记物/结合配偶体对和任选地肽连接酶,如上面所讨论的。能够自发形成一个或多个异肽键的进一步蛋白质可以通过将它们的结构与已知自发形成一个或多个异肽键的蛋白质的结构进行比较来鉴定。具体地,可以自发形成异肽键的其它蛋白质可以通过将它们的晶体结构与来自已知异肽蛋白例如主要菌毛蛋白Spy0128的晶体结构进行比较,并且具体而言将通常比较参与异肽蛋白形成的Lys-Asn/Asp-Glu/Asp残基来鉴定。另外地,其它异肽蛋白可以通过使用蛋白质数据库利用标准数据库检索工具筛选已知异肽蛋白的结构同源性来鉴定。SPASM服务器(
显著地,形成异肽键的蛋白质可以从头设计,如在WO2011/098772(其通过引用被并入本文)中描述的。Rosetta可以被用于从头设计异肽蛋白并且该软件可以在
发明内容
本发明人已经有利地确定了这些肽标记物/结合配偶体对可以被用作肽连接体以共价地接合多种蛋白质,即以产生融合蛋白。具体而言,本发明人已经证明了正交(即互相不反应的或非关联的)的肽标记物/结合配偶体肽对在两种或更多种蛋白质的融合(例如缀合、连接),即融合蛋白的产生(合成、构建、装配)中发现实用性。如在下面的实施例中详细证明的,本发明的方法和用途基于连续的异肽键形成提供了模块式(例如逐步)和高产率的将蛋白质连接入链的途径。具体而言,本文描述的方法和用途能够使得蛋白质链的受控(即特异性的、靶向的)延伸而不生成统计学上的混合物。相对于先前方法其是特别有利的,这是因为其产生如此融合蛋白,在该融合蛋白中每个蛋白质单元(模块、结构域)通过不可逆连接即异肽键接合。因而,当连接不依赖半胱氨酸残基的反应时,其适用于包含游离半胱氨酸残基和/或二硫键的蛋白质。而且,添加至链的每个蛋白质单元需要仅利用两种小的肽标记物来修饰,这两种小的肽标记物可以在蛋白质内的各个位置处即在蛋白质上的N末端、C末端或内部位点处被并入。因而,融合蛋白的每个蛋白质单元可以被完全地基因编码,即方法不依赖于使用非天然的(即非标准的)氨基酸或翻译后修饰氨基酸残基。因而,本发明提供了用于合成融合蛋白的简单的和可扩展的方法,其是高度特异性的并且不需要纯化中间体。
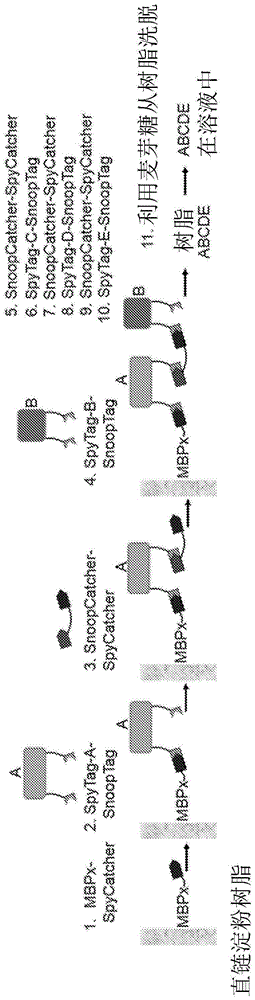
本发明的方法的代表性的实例在图1中列出,其示出了本发明的固相实施方式。但是,这绝不意欲限制本发明的范围并且各种其它排列根据下面的描述对于技术人员将是显而易见的并且意欲由本发明包括,如所附权利要求书中所限定的。
图1示出了两对肽连接体,其被称为SpyTag/SpyCatcher和SnoopTag/SnoopCatcher,其中每对即每个“Tag”和“Catcher”特异性地和自发地反应以形成异肽键,从而将“Tag”肽连接至“Catcher”肽。在这方面,这些对是正交的,这意味着它们是互相不反应的,即SpyTag和SpyCatcher不能与SnoopCatcher或SnoopTag的任一种反应以形成异肽键。如下面更详细讨论的,在一些实施方式中,“Tag”可以被视为肽标记物并且“Catcher”肽可以被视为结合配偶体蛋白。
因而,在步骤1中,提供了第一蛋白MBPx(下面讨论的麦芽糖结合蛋白的修饰版本),其中该蛋白已经被修饰以并入肽连接体SpyCatcher(即第一对肽连接体的第一部分),例如经由编码单一开放阅读框中MBPx多肽和SpyCatcher肽连接体的核酸分子的重组表达。在该代表性的实例中,MBPx蛋白被用作纯化或固定标记物,其允许延伸的融合蛋白在固相(直链淀粉树脂)上固定。但是,从下面的讨论将显而易见的是这不是本发明的必要特征。例如,方法可以是非均质的(即固相)或均质的(homogeneous)(即在溶液中)并且如果是非均质的,可以使用任何适合的纯化/固定标记物,即标记物是蛋白质或肽标记物不是必要的。
在步骤2中,第一蛋白(MBPx-SpyCatcher)与已经被修饰来并入两种肽连接体的第二蛋白(A)接触。一种肽连接体是第一对连接体(SpyTag)的第二部分,第一部分形成第一蛋白(SpyCatcher)的结构域。另一肽连接体是第二对肽连接体(SnoopTag)的第一部分;如上面所讨论的,第二对连接体不与第一对连接体反应。因而,在将第一和第二蛋白接触在一起时,第一对连接体反应(例如自发地)以在SpyCatcher和SpyTag肽连接体之间形成特异性异肽键,从而将第一蛋白(MBPx-SpyCatcher)和第二蛋白(SpyTag-A-SnoopTag)连接在一起以形成融合蛋白。
在步骤3中,融合蛋白(MBPx-SpyCatcher-SpyTag-A-SnoopTag)与包括两种肽连接体SnoopCatcher和SpyCatcher的进一步蛋白接触。因而,一种肽连接体(SnoopCatcher)是第二对肽连接体的第二部分并且另一肽连接体(SpyCatcher)来自第一对肽连接体。这些肽连接体可以经由间隔区例如肽间隔区或者被并入最终融合蛋白中的蛋白质连接。在将融合蛋白(MBPx-SpyCatcher-SpyTag-A-SnoopTag)与进一步蛋白(SnoopCatcher-SpyCatcher)接触时,第二对连接体反应(例如自发地)以形成异肽键,从而延伸融合蛋白。可选地来看,SnoopCatcher-SpyCatcher蛋白的添加可以被视为功能化或激活融合蛋白进行进一步延伸,即通过将反应性基团(反应性肽连接体)添加至融合蛋白。
在步骤4中,来自步骤3的延伸的融合蛋白(MBPx-SpyCatcher-SpyTag-A-SnoopTag-SnoopCatcher-SpyCatcher)与进一步蛋白(B)接触,类似于A蛋白质(SpyTag-B-SnoopTag),该蛋白(B)包含两种肽连接体。再者,异肽键在能够反应在一起的肽连接体——即第一对,SpyCatcher和SpyTag——之间形成以进一步延伸融合蛋白。
将显而易见的是该过程可以重复直到期望融合蛋白的所有蛋白质单元已经连接在一起。融合蛋白可以简单地从固相例如利用麦芽糖洗脱,并且在不经过进一步纯化的情况下使用。应当注意,融合蛋白的末端蛋白需要被修饰为仅并入单一肽连接体,其可以与融合蛋白的蛋白质例如倒数第二个蛋白质单元中的游离肽连接体反应。如在实施例中讨论的,本发明人已经证明了包含10个蛋白质单元的融合蛋白的合成,其已经通过凝胶电泳和质谱法验证。
虽然不希望受理论束缚,但是据认为肽连接体对例如SnoopTag/SnoopCatcher、SpyTag/SpyCatcher等中的氨基酸残基的精确定向促进肽连接体之间的亲核攻击和不可逆异肽键的形成。如上面所提及的,赖氨酸与这些对的每个中的天冬氨酸或天冬酰胺反应。SpyTag肽具有反应性天冬氨酸并且因此其不能与SnoopCatcher的反应性天冬酰胺反应。SnoopTag肽具有反应性赖氨酸并且因此其不能与SpyCatcher的反应性赖氨酸反应。因此,这两种肽连接体对是正交的,并且将显而易见的是任何正交的肽连接体对可以被用在本发明的方法中来形成融合蛋白。在这方面,其是正交的、互相不反应性质的肽连接体对——其能够生成强健的和可编程的融合蛋白。具体而言,如果生长的融合蛋白链被附接至固相,则反应模块(即待连接至融合蛋白的下一个蛋白质)可以以大大的过量添加,从而驱动反应完成。这意味着未反应的构造块可以被简单地洗掉,因此分离(即将生长的融合蛋白与未反应的组分分离)在每个步骤中是不必要的。因而,使用少量的正交连接一次一步的延长使得链生长。因此,由本发明人研发的方法优于先前描述的蛋白偶联方法,特别是在融合蛋白产品的稳定性和单个反应步骤的简单性方面优于先前描述的蛋白偶联方法。
因此,最宽泛地来说,本发明可以被视为至少两种正交的肽连接体对用于生产融合蛋白的用途,其中每个肽连接体对反应以形成异肽键。
具体而言,每个肽连接体对的肽连接体彼此反应以形成异肽键。如上面所提及的,每个肽连接体形成蛋白质的一部分(例如结构域),其将形成融合蛋白的单元(例如结构域或模块)。换句话说,待连接在一起的蛋白质可以被修饰以并入至少一种肽连接体(例如两种、三种、四种肽连接体等),其中在生产融合蛋白中使用的每个肽连接体对正交于在生产所述融合蛋白中使用的至少一个其它肽连接体对。
因而,在一些实施方式中,正交的肽连接体对被用在生产包含至少两种蛋白质单元(例如结构域或模块)的融合蛋白中。例如,在图1中示出的代表性实施方式中,用于将蛋白质A与蛋白质B缀合的蛋白质可以被视为连接体单元,即该连接体单元(连接体蛋白)仅起将蛋白质A与蛋白质B缀合的功能。因而,融合蛋白可以被视为包含或包括至少两种功能性蛋白质,即具有非作为连接体的功能的蛋白质。在其它实施方式中,融合蛋白可以被视为包含或包括至少三种蛋白质(即不考虑它们的功能)。
在进一步实施方式中,融合蛋白可以被视为包含或包括至少三种功能性蛋白质。例如,参照在图1中示出的代表性实施方式,如果用于缀合蛋白质A与蛋白质B的连接体蛋白除了肽连接体之外还包含蛋白质(例如功能性蛋白质),则其可以被视为融合蛋白的蛋白质单元(结构域或模块)。因而,融合蛋白可以被视为包含或包括至少三种功能性蛋白质,即具有非连接体的功能或除了连接体之外的功能的蛋白质。
可选地来看,本发明提供了生产(例如生成、合成、装配等)融合蛋白的方法,所述方法包括:
a)将第一蛋白质与第二蛋白质在能够在所述蛋白质之间形成异肽键的条件下接触,其中所述第一蛋白质和所述第二蛋白质每种包括肽连接体,其中所述肽连接体是肽连接体对,其(彼此)反应以形成连接所述第一蛋白质至所述第二蛋白质以形成连接的蛋白质的异肽键;和
b)将来自(a)的连接的蛋白质与第三蛋白质在能够在所述第三蛋白质和所述连接的蛋白质之间形成异肽键的条件下接触,其中所述第三蛋白质包括与来自(a)的连接的蛋白质中的进一步肽连接体反应的肽连接体,并且其中所述肽连接体是肽连接体对,其(彼此)反应以形成连接所述第三蛋白质至所述连接的蛋白质以形成融合蛋白的异肽键,
其中来自(a)的/在(a)中使用的所述肽连接体对正交于来自(b)的/在(b)中使用的肽连接体对。
从又另一方面看,本发明提供了生产(例如生成、合成、装配等)融合蛋白的方法,所述方法包括:
a)提供包括第一肽连接体的第一蛋白质;
b)在能够使得所述第一肽连接体和第二肽连接体形成异肽键的条件下将所述第一蛋白质与第二蛋白质接触,从而连接所述第一和第二蛋白质,其中所述第二蛋白质包括所述第二肽连接体和第三肽连接体;和
c)在能够使得所述第三肽连接体和第四肽连接体形成异肽键的条件下将所述连接的第一和第二蛋白质与第三蛋白质接触,从而连接所述第二和第三蛋白质以形成融合蛋白,其中所述第三蛋白质包括所述第四肽连接体,
其中所述第一和第二肽连接体是肽连接体对,其正交于由所述第三和第四肽连接体组成的肽连接体对。
如上面所指出的,在一些实施方式中,第二蛋白质可以起第一和第三蛋白质之间的连接体的功能。因此,融合蛋白可以被视为包括两种“功能性”蛋白质,即具有非将两种蛋白质单元(模块、结构域等)连接在一起的功能的蛋白质。因而,在一些实施方式中,第二蛋白质可以被视为连接体蛋白,即如此蛋白质:其包含至少两种肽连接体——每种来自不同的正交的肽连接体对——和任选地间隔区结构域,例如肽间隔区。
因而,在一些实施方式中,第二蛋白质可以被视为连接体蛋白,其功能化或激活第一蛋白质以能够使所述第一蛋白质与所述第三蛋白质连接(缀合至所述第三蛋白质)。类似地,在进一步蛋白质被加入至融合蛋白时(即融合蛋白延伸时),连接体蛋白可以被用于功能化或者激活融合蛋白中的一种或多种蛋白质以使得所述一种或多种蛋白质与所述进一步蛋白质连接。
如上面所讨论的,使用正交的肽连接体对促进产生包含大量蛋白质单元的融合蛋白。因此,通过使融合蛋白与进一步蛋白质接触可以将额外蛋白质加入至融合蛋白(即融合蛋白可以被延伸(例如延长、加长)),该进一步蛋白质包括至少一种能够与融合蛋白的蛋白质中的肽连接体形成异肽键的肽连接体。在这方面,新蛋白质中的肽连接体形成肽连接体对的一部分,该肽连接体对正交于用于形成融合蛋白中的先前异肽键的肽连接体对。
因而,在一些实施方式中,方法进一步包括延伸融合蛋白的步骤,其中待与融合蛋白连接的新蛋白质(即额外或进一步蛋白质)包括形成肽连接体对的一部分的肽连接体,该肽连接体对正交于用于形成融合蛋白中的先前异肽键的肽连接体对,其中新蛋白质中的肽连接体能够与融合蛋白的蛋白质中的肽连接体形成异肽键,所述方法包括在能够使所述新蛋白质(具体地所述新蛋白质中的肽连接体)与融合蛋白中的肽连接体形成异肽键的条件下使所述新蛋白质与所述融合蛋白接触。
因此,在一些实施方式中,第三蛋白质可以被视为待加入融合蛋白的“进一步”蛋白质,例如额外或新蛋白质。因此,延伸融合蛋白可以被视为重复上述方法中的步骤(c),其中进一步蛋白质中的肽连接体是肽连接体对,其正交于被用于接合加入至融合蛋白的先前蛋白质的肽连接体对。
在一些实施方式中,待加入至融合蛋白的新蛋白质(即进一步或额外蛋白质)包括至少第二肽连接体(例如以允许融合蛋白链的进一步延伸)。因此,第二肽连接体(和新蛋白质中的任何进一步肽连接体)正交于用于连接(缀合)融合蛋白和新蛋白质的肽连接体对。
因而,在仍进一步实施方式中,生产所述融合蛋白的方法可以包括延伸所述融合蛋白的步骤,其中所述第三蛋白质包括第五肽连接体和所述方法包括在能够使得所述第五肽连接体和第六肽连接体形成异肽键的条件下将所述融合蛋白与第四蛋白质接触,从而连接所述第三和第四蛋白质以延伸所述融合蛋白的步骤,其中所述第四蛋白质包括所述第六肽连接体,其中所述第五和第六肽连接体形成肽连接体对,其正交于由所述第三和第四肽连接体组成的肽连接体对。
如图1中所示出的,使用两个正交的肽连接体对生成包括多个蛋白质单元(例如多于3个蛋白质单元,例如4、5、6、7、8、9、10或更多个蛋白质单元,比如12、15、20或更多个蛋白质单元)的融合蛋白是可能的。因而,在一些实施方式中,由第五和第六肽连接体组成的肽连接体对与由第一和第二肽连接体组成的肽连接体对相同。
因而,在仍进一步实施方式中,融合蛋白可以被进一步延伸,其中所述第四蛋白质包括第七肽连接体和所述方法包括在使得所述第七肽连接体和第八肽连接体形成异肽键的条件下将所述融合蛋白与第五蛋白质接触,从而连接所述第四和第五蛋白质以延伸所述融合蛋白的步骤,其中所述第五蛋白质包括所述第八肽连接体,其中所述第七和第八肽连接体形成肽连接体对,其正交于由所述第五和第六肽连接体组成的肽连接体对。
在一些实施方式中,由第七和第八肽连接体组成的肽连接体对与由第三和第四肽连接体组成的肽连接体对相同。
将显而易见的是融合蛋白链可以通过重复上述步骤延伸,例如其中第五蛋白质包括第九肽连接体和第六蛋白质包括第十肽连接体,并且其中所述第九和第十肽连接体形成肽连接体对,其正交于由所述第七和第八肽连接体组成的肽连接体对。在一些实施方式中,由第九和第十肽连接体组成的肽连接体对与由第一和第三肽连接体和/或所述第五和第六肽连接体组成的肽连接体对相同。
因而,在一些实施方式中,至少两个正交的肽连接体对可以被交替地用于连接(缀合)蛋白质以形成融合蛋白。可选地来看,待添加至融合蛋白的新蛋白质或进一步蛋白质包括形成肽连接体对的一部分的至少一种肽连接体,该肽连接体对正交于用于连接融合蛋白中先前加入的蛋白质的肽连接体对。
虽然本发明可以使用两个正交的肽连接体对成功地进行,但是将显而易见的是多于两个正交的肽连接体对可以被用在本发明的方法和用途中。因而,在上面给出的代表性实例的背景下,在一些实施方式中,由第五和第六肽连接体组成的肽连接体对与由第一和第二肽连接体组成的肽连接体对是不同的,优选正交的。如下面所讨论的,使用多于两个正交的肽连接体对将能够产生复杂的融合蛋白结构,例如分支结构。因此,如下面详细讨论的,本发明人已经研发了数个正交的肽连接体对,其形成本发明的进一步实施方式。
例如,包括三种蛋白质1、2和3的融合蛋白可以根据上面描述的方法生产,其中蛋白质1包括肽连接体A,蛋白质2包括肽连接体A’和B并且蛋白质3包括肽连接体B’。在这方面,肽连接体A和A’(肽连接体对)反应以形成异肽键并且肽连接体B和B’(肽连接体对)反应以形成异肽键,其中肽连接体对A/A’和B/B’是正交的(即不与另一对反应形成异肽键)。使用第三正交的肽连接体对将能够产生支化结构。例如,蛋白质2可以包括第三肽连接体C和第四蛋白质4可以包括肽连接体C’,其中C和C’(肽连接体对)反应以形成异肽键并且其中肽连接体A/A’、B/B’和C/C’是正交的。当融合蛋白1-2-3与蛋白质4在能够使得C和C’形成异肽键的条件下接触时,所得到的融合蛋白将是支化的,即1-2(-4)-3(参见图13A)。可选地,融合蛋白1-2-4可以与蛋白质3在使得B和B’形成异肽键的条件下接触以产生支化的融合蛋白1-2(-4)-3。技术人员将理解,复杂的支化结构可以使用三个正交的肽连接体对生成并且支化结构的复杂性可以通过使用额外正交的肽连接体对进一步增加。具体而言,使用多于两个正交的肽连接体对可以有利地被用于生成不对称的支化结构。
因而,在一些实施方式中,本发明的方法和用途利用多于两个正交的肽连接体对,例如3、4、5、6、7、8、9或10或更多正交的肽连接体对。
支化也可以使用两个正交的肽连接体对实现。例如,包括五种蛋白质1-5的支化的融合蛋白可以通过在这些蛋白质的一种中包括额外肽连接体产生,例如蛋白质2可以包括来自两个正交的肽连接体对的4个肽连接体。在该代表性实施方式中,蛋白质1包括肽连接体A,蛋白质2包括肽连接体A’和三个肽连接体B。蛋白质3、4和5每种包括肽连接体B’,其中肽连接体A和A’(肽连接体对)反应以形成异肽键和肽连接体B和B’(肽连接体对)反应以形成异肽键,其中肽连接体对A/A’和B/B’是正交的。因而,将融合蛋白1-2与蛋白质3-5接触将产生支化的融合蛋白,其中蛋白质3-5彼此独立地都接合至蛋白质2(参见图13)。将显而易见的是蛋白质3-5可以是相同或不同的蛋白质。而且,蛋白质3-5中的一种或多种可以包括来自正交的肽连接体对的额外肽连接体以促进融合蛋白的每个分支的延伸(例如分开的、独立的延伸)。
因而,在一些实施方式中,融合蛋白可以是支化的。在其它实施方式中,融合蛋白可以是线性的。在一些实施方式中,例如在多于两个正交的肽连接体对被使用时,融合蛋白可以由不对称分支组成,即融合蛋白可以具有不对称结构。因而,在一些实施方式中,本发明提供了生产支化的融合蛋白的方法。在一些实施方式中,本发明提供了生产线性融合蛋白的方法。
术语“支化的”指的是如此融合蛋白:在其中两个或更多个蛋白质单元彼此独立地,即经由独立(分开)形成的异肽键连接(接合、缀合)至融合蛋白的相同内部蛋白质单元(非末端蛋白质单元)。内部蛋白质单元或非末端蛋白质单元可以被限定为通过异肽键连接(接合、缀合)至融合蛋白中至少两个其它蛋白质单元的蛋白质。末端蛋白质单元可以被限定为经由异肽键仅连接(接合、缀合)至融合蛋白中一个其它蛋白质单元的蛋白质。因而,在上面讨论的和图13中示出的代表性实例中,蛋白质2是内部蛋白质单元或非末端蛋白质单元,因为其经由异肽键接合至蛋白质1和3,其中蛋白质4和5可以被视为融合蛋白的“分支”。蛋白质1、3、4和5可以被视为末端蛋白质单元。因而,支化的融合蛋白包括多于两个末端蛋白质单元。
术语“线性”指的是如此融合蛋白:在其中所有内部蛋白质单元仅连接至融合蛋白中的两个其它蛋白质单元,从而生成蛋白质单元的线性链。因而,线性融合蛋白仅包括两个末端蛋白质单元。
在又其它实施方式中,融合蛋白可以是环状的。例如,采用上面的融合蛋白1-2-3,如果蛋白质1还包含肽连接体C并且蛋白质3还包含肽连接体C’,则蛋白质1和3可以通过异肽键连接,从而形成环状蛋白质。因而,在一些实施方式中,线性蛋白质可以被视为可环化的(circularisable),即能够形成环状融合蛋白。在这方面,如下面所讨论的,肽连接体中的一个或多个可以被封闭或保护以阻止或延迟其反应。因而,使用上面的实例,如果肽连接体C和/或C’被封闭,则融合蛋白将是可环化的线性融合蛋白并且可以通过解闭(unblock)C和/或C’以使得肽连接体反应形成异肽键而环化。
因而,在一些实施方式中,本发明提供了生产环状或可环化融合蛋白的方法。
因而,术语“环状”通常指的是不包含任何末端蛋白质单元的融合蛋白。但是,将显而易见的是生产“支化的环状”融合蛋白是可能的,其包括如此环状融合蛋白:其中内部蛋白质单元的一个或多个通过异肽键连接至融合蛋白中的至少三个其它蛋白质单元。
如本文所使用的术语“正交”指的是相互不反应的分子,例如不能够彼此反应或者以与能够彼此反应的相应分子相比降低的效率反应的分子。在本发明的肽连接体的背景下,具体而言肽连接体对,术语正交指的是不能与其它的肽连接体对反应以形成异肽键或者以与相应分子——例如能够自发形成异肽键的内源蛋白质——或者肽连接体对——能够彼此有效地反应以形成异肽键——相比降低的效率反应的肽连接体对。无能力反应可以被视为样品中5%或更少的肽连接体反应以形成异肽键,例如4%、3%、2%或1%或更少。降低的效率可以被视为与每个肽连接体对形成异肽键的能力相比低于5%效率,例如低于4%、3%、2%或1%效率的正交的肽连接体对反应以形成异肽键。相反地,有效地反应以形成异肽键的肽连接体对可以以至少95%效率,例如至少96%、97%、98%、99%或100%效率反应,即样品中肽连接体对的至少95%的肽连接体在能够形成异肽键的条件下反应以形成异肽键。例如,当A和A’不能与B和/或B’反应以形成异肽键时或者当A和A’以与在A和A’和/或B和B’之间的异肽键形成相比低于5%的效率与B和/或B’反应以形成异肽键时,两个肽连接体对A/A’和B/B’可以被视为正交的。
可选地来看,在能够或促进异肽键形成的条件下有效地在一起反应以形成异肽键的两个肽连接体可以被限定为关联的肽连接体对,其中术语“关联”指的是在一起起作用,即在一起反应以形成异肽键的组分。因而,在能够或促进异肽键形成的条件下有效地在一起反应以形成异肽键的两个肽连接体也可以被称为“互补”的肽连接体对。因此,正交的肽连接体对可以被视为非关联对或非互补对。例如,基于上面描述的代表性实例,肽连接体对A/A’可以被视为关联或互补肽连接体对,而A/A’和B/B’是非关联或非互补对,因为A和A’在能够或促进异肽键形成的条件下不能与B和/或B’有效地反应以形成异肽键。
在本发明的方法和用途中使用的肽连接体可以衍生自能够自发形成异肽键的蛋白质。具体而言,“能够自发形成异肽键的蛋白质”(在本文中也被称为“异肽蛋白”)是在不存在酶或其它物质的情况下和/或没有化学修饰在其蛋白质链内,即分子内地可以形成异肽键的蛋白质。用于形成异肽键的两种反应性残基因此包括在单一蛋白质链内。因而,仅分子间地,即与其它肽或蛋白质链或单元形成异肽键的蛋白质不被视为在本发明中使用的异肽蛋白。具体地,具有分子间异肽键的HK97衣壳亚单元被排除。
如本文所使用的术语“异肽键”指的是羧基或甲酰胺基与氨基——其至少一种不衍生自蛋白质主链或者可选地来看不是蛋白质骨架的一部分——之间的酰胺键。异肽键可以在单一蛋白质内形成或者可以在两个肽或肽和蛋白质之间发生。因而,异肽键可以在单一蛋白质内分子内地形成或者分子间地,即在两个肽/蛋白质分子,例如两个肽连接体之间形成。通常地,异肽键可以在赖氨酸残基与天冬酰胺、天冬氨酸、谷氨酰胺或谷氨酸残基或蛋白质或肽链的末端羧基之间发生,或者可以在蛋白质或肽链的α-氨基末端与天冬酰胺、天冬氨酸、谷氨酰胺或谷氨酸之间发生。参与异肽键的对的每个残基在本文中被称为反应性残基。在本发明的优选实施方式中,异肽键可以在赖氨酸残基和天冬酰胺残基之间或者在赖氨酸残基和天冬氨酸残基之间形成。具体地,异肽键可以在赖氨酸的侧链胺与天冬酰胺的甲酰胺基或天冬氨酸的羧基之间发生。
参与异肽键的残基之间的距离从残基内特定C原子测量。因此,当赖氨酸参与异肽键时,距离从赖氨酸的C-ε原子测量;当天冬氨酸参与异肽键时,距离从天冬氨酸的C-γ原子测量;当天冬酰胺参与异肽键时,距离从天冬酰胺的C-γ原子测量;并且当谷氨酸参与异肽键时,距离从谷氨酸的C-δ原子测量。参与异肽键的反应性残基的这些原子(从其计算距离)在本文中被称为“相关原子”。
通常,为了异肽键形成,反应性残基例如反应性赖氨酸和天冬酰胺/天冬氨酸残基(和具体地其相关原子;对于赖氨酸,C-ε原子,并且对于天冬酰胺/天冬氨酸,C-γ原子)应当在空间上靠近彼此放置——例如在它们衍生自的异肽蛋白中。因而,具体地,反应性残基例如赖氨酸和天冬酰胺/天冬氨酸(和具体地其相关原子)在折叠蛋白(它们衍生自其)中在彼此的4埃内并且可以在彼此的3.8、3.6、3.4、3.2、3.0、2.8、2.6、2.4、2.2、2.0、1.8或1.6埃内。具体地,反应性残基(和具体地它们的相关原子)在它们衍生自的异肽蛋白中可以在彼此的1.81、2.63或2.60埃内。
通常,本发明的肽连接体可以衍生自的异肽蛋白可以包括谷氨酸或天冬氨酸残基,其靠近参与异肽键的形成的两个其它反应性氨基酸残基,例如靠近赖氨酸和天冬酰胺/天冬氨酸。具体地,谷氨酸的C-δ原子或天冬氨酸残基的C-γ原子可以在距离折叠蛋白质结构中参与异肽键的反应性天冬酰胺/天冬氨酸残基——例如距离反应性天冬酰胺/天冬氨酸残基的C-γ原子——5.5埃内。例如,谷氨酸(例如其C-δ原子)可以在距离异肽键中的反应性天冬酰胺/天冬酰胺残基——例如其C-γ原子——5.4、5.2、5.0、4.8、4.6、4.4、4.2、4.0、3.8、3.6、3.4、3.2或3.0埃内。具体地,谷氨酸残基例如其C-δ原子可以距离天冬酰胺/天冬氨酸残基——例如其C-γ原子——4.99、3.84或3.73埃。
进一步,谷氨酸残基例如其C-δ原子可以在距离参与异肽键的反应性赖氨酸残基——例如其C-ε原子——6.5埃内,例如在6.3、6.1、5.9、5.7、5.5、5.3、5.1、4.9、4.7、4.5、4.3或4.1埃内。具体地,谷氨酸残基例如其C-δ原子可以距离反应性赖氨酸——例如其C-ε原子——6.07、4.80或4.42埃。
谷氨酸残基(或天冬氨酸残基)可以帮助诱导异肽键的形成,如前面所讨论的。
如上面所讨论的,在本发明的方法和用途中使用的肽连接体可以通过将异肽蛋白的反应性结构域分裂为两个或三个结构域来获得。因而,每个肽连接体对由包括赖氨酸残基的肽和包括天冬氨酸或天冬酰胺残基的肽组成,其中所述残基(即赖氨酸和天冬氨酸或赖氨酸和天冬酰胺)参与异肽键的形成(即反应以形成异肽键),从而接合(缀合)所述肽连接体。
在一些优选的实施方式中,所述肽连接体之间的异肽键的形成是自发的。因此,肽连接体中的一个包括谷氨酸或天冬氨酸残基,其促进例如诱导或催化肽连接体中赖氨酸与天冬酰胺或天冬氨酸残基之间的异肽键的形成。在一些实施方式中,谷氨酸或天冬氨酸残基满足上面列出的靠近标准中的一个或多个。
因而,在其中所述肽连接体之间的异肽键的形成是自发的实施方式中,肽连接体的一个可以被视为肽标记物并且另一个肽连接体(即包括谷氨酸或天冬氨酸残基的连接体,其促进例如诱导或催化异肽键的形成)可以被视为肽结合配偶体,即如下面进一步限定的肽标记物的结合配偶体。
如本文所使用的术语“自发的”指的是键,例如异肽或共价键,其可以在蛋白质中或在肽或蛋白质之间(例如在2个肽或肽和蛋白质之间,即本发明的肽连接体)在不存在任何其它试剂(例如酶催化剂)的情况下和/或在不对蛋白质或肽进行化学修饰的情况下,例如在不使用1-乙基-3-(3-二甲基氨基丙基)碳二亚胺(EDC)进行天然化学连接或化学偶联的情况下形成。因而,不进行天然化学连接来修饰肽或蛋白质具有C-末端硫酯。
因而,当蛋白质独自(on its own)分离时,自发的异肽键可以形成,或者当在不化学修饰的情况下分离时,共价或异肽键可以在两个肽或者肽和蛋白质(即本发明的肽连接体)之间形成。自发的异肽键或共价键因此可以在不存在酶或其它外源物质或者在不化学修饰的情况下自动地形成。但是,具体地,自发的异肽键或共价键可能需要在参与键的蛋白质中或在肽/蛋白质的一个中(即肽连接体的一个中)存在谷氨酸或天冬氨酸残基以允许以靠近诱导的方式形成键。
自发的异肽键或共价键可以几乎就在蛋白质的产生之后或者在包括本发明的肽连接体的两个或更多个蛋白质——例如肽标记物和结合配偶体——之间的接触之后,例如在1、2、3、4、5、10、15、20、25或30分钟内,或者在1、2、4、8、12、16、20或24小时内形成。键可以在一系列条件下形成,比如在磷酸盐缓冲盐水(PBS)或者Tris缓冲盐水(TBS)中在pH 4.0-9.0,例如5.0、5.5、6.5、7.0、7.5、8.0或8.5下和在0-40℃,例如1、2、3、4、5、10、12、15、18、20、22或25℃下。技术人员将容易地能够确定其它适合的条件。
因而,在一些实施方式中,“在能够形成异肽键的条件下”使包括如本文限定的肽连接体的蛋白质接触包括在缓冲条件下比如在缓冲溶液中或者在已经利用缓冲液比如PBS或TBS平衡的固相(例如柱)上使所述蛋白质接触。接触步骤可以在任何适合pH下,比如pH4.0-9.0,例如4.5-8.5、5.0-8.0、5.5-7.5,比如大约pH 6.2、6.4、6.6、6.8、7.0、7.2、7.4、7.6、7.8或8.0。另外地或可选地,接触步骤可以在任何适合的温度下,比如大约0-40℃,例如大约1-39、2-38、3-37、4-36、5-35、6-34、7-33、8-32、9-31或10-30℃,例如大约10、12、15、18、20、22或25℃。技术人员将理解条件,条件可能需要改变,这取决于在本发明的方法中使用的肽连接体的特征,并且将能够容易地确定那些条件是适合的。
在一些实施方式中,“在能够形成异肽键的条件下”使包括如本文限定的肽连接体的蛋白质接触包括在化学分子伴侣——例如增强或改善肽连接体的反应性的分子——的存在下使所述蛋白质接触。在一些实施方式中,化学分子伴侣是TMAO(三甲胺N-氧化物)。在一些实施方式中,化学分子伴侣例如TMAO以至少大约0.2M,例如至少0.3、0.4、0.5、1.0、1.5、2.0或2.5M,例如大约0.2-3.0M、0.5-2.0M、1.0-1.5M的浓度存在于反应中。
在一些实施方式中,在所述肽连接体之间形成异肽键不是自发的,即异肽键的形成通过添加至反应的组分诱导或催化。诱导或催化异肽键形成的组分可以是肽,例如多肽比如酶,比如转谷氨酰胺酶。在优选实施方式中,诱导或催化异肽键形成的组分可以是衍生自异肽蛋白的肽,即包括谷氨酸或天冬氨酸残基的异肽蛋白的结构域或片段,所述谷氨酸或天冬氨酸残基促进例如诱导或催化肽连接体中赖氨酸和天冬酰胺或天冬氨酸残基之间的异肽键的形成。促进例如诱导或催化肽连接体中赖氨酸和天冬酰胺或天冬氨酸残基之间的异肽键形成的肽可以被视为蛋白质连接酶或肽连接酶,因为其能够特异性地诱导两个肽连接体之间的异肽键的形成。
因而,在其中所述肽连接体之间的异肽键的形成不是自发的实施方式中,即其中诱导肽连接体之间的异肽键形成的组分(例如肽,例如肽连接酶)被分开地提供,这两个肽连接体可以被视为如下面所限定的肽标记物。因此,诱导肽连接体(肽标记物)之间的异肽键形成的肽可以被视为肽连接酶或者肽连接体对结合配偶体。
因而,在一些事实方式中,本发明进一步包括在能够在所述蛋白质之间形成异肽键的条件下使待连接的蛋白质与能够诱导所述肽连接体之间的异肽键形成的组分(例如肽)接触的步骤。在一些实施方式中,能够诱导所述肽连接体之间的异肽键形成的组分是包括谷氨酸或天冬氨酸残基的肽,所述谷氨酸或天冬氨酸残基诱导所述蛋白质的肽连接体中的赖氨酸和天冬酰胺或天冬氨酸残基之间的异肽键的形成。
能够诱导所述肽连接体之间的异肽键形成的组分(例如肽)可以在将待接合在一起的蛋白质彼此接触之前、之后或同时添加至反应。在一些实施方式中,能够诱导所述肽连接体之间的异肽键形成的组分(例如肽)可以在将待接合在一起的蛋白质彼此接触之后添加至反应。
能够诱导所述肽连接体之间的异肽键形成的组分(例如肽)的使用是特别有利的,这是因为其允许在不存在大的间插(intervening)肽结构域的情况下接合(缀合)融合蛋白的蛋白质单元。可选地来看,能够诱导所述肽连接体之间的异肽键形成的组分(例如肽)的使用促进使用小肽连接体(例如肽标记物),即能够在所述肽连接体之间形成异肽键的关联肽连接体对中每个肽连接体的最小肽序列。
在一些实施方式中,关联肽连接体对和能够诱导所述肽连接体之间的异肽键形成的肽衍生自相同的异肽蛋白。
能够自发地形成异肽键的蛋白质可以能够形成至少一种这样的键并且可以包括多于一个异肽键,例如2、3、4、5、6、7、8、9、10或更多。从异肽蛋白研发数种不同的肽连接体对可以是可能的,特别是如果多于一个自发形成的异肽键存在于蛋白质内。在一些实施方式中,衍生自相同异肽蛋白的不同肽连接体对可以是正交的。从包括单一或仅两个异肽键的异肽蛋白研发每个肽连接体对在本发明中是优选的。
能够自发地形成一个或多个异肽键的已知蛋白的实例包括来自酿脓链球菌(Streptococcuspyogenes)的Spy0128(Kang et al,Science,2007,318(5856),1625-8)、Spy0125(Pointon et al,J.Biol.Chem.,2010,285(44),33858-66)和FbaB(Oke et al,J.Struct Funct Genomics,2010,11(2),167-80),金黄色酿脓葡萄球菌(Staphylococcusaureus)的Cna(Kang et al,Science,2007,318(5856),1625-8),粪肠球菌(Enterococcusfaecalis)的ACE19蛋白(Kang et al,Science,2007,318(5856),1625-8),来自蜡样芽胞杆菌(Bacillus cereus)的BcpA菌毛蛋白(Budzik et al,PNAS USA,2007,106(47),19992-7),来自无乳链球菌(Streptococcus agalactiae)的次要(minor)菌毛蛋白GBS52(Kang et al,Science,2007,318(5856),1625-8),来自白喉杆菌(Corynebacterium diphtheriae)的SpaA(Kang et al,PNAS USA,2009,106(40),16967-71),来自变异链球菌(Streptococcus mutans)的SpaP(Nylander et al,ActaCrystallogr Sect F Struct Biol Cryst Commum.,2011,67(Pt1),23-6),来自肺炎链球菌(Streptococcus pneumoniae)的RrgA(Izore et al,Structure,2010,18(1),106-15)、RrgB(El Mortaji et al,J.Biol.Chem.,2010,285(16),12405-15)和RrgC(El Mortaji etal,J.Biol.Chem.,2010,285(16),12405-15),来自戈登氏链球菌(Streptococcusgordonii)的SspB。如上面所讨论的,这些蛋白质中的任一种可以被用于生成在本发明的方法和用途中使用的肽连接体(具体地关联肽连接体对)。
待连接以形成融合蛋白的蛋白质中的肽连接体的排列或顺序不是特别重要的。例如,期望融合蛋白的第一蛋白可以包括肽标记物(A)和第二蛋白质可以包括与第一蛋白质(A’)上的肽标记物关联的肽结合配偶体和与第三蛋白质(B’)上的肽标记物关联的肽结合配偶体。可选地,期望融合蛋白的第一蛋白可以包括肽结合配偶体(A’)和第二蛋白质可以包括与第一蛋白质(A)上的肽结合配偶体关联的肽标记物和与第三蛋白(B)上的肽结合合配偶体关联的肽标记物。在这方面,用于连接两种蛋白质(例如第一蛋白质和第二蛋白质,融合蛋白与进一步蛋白质等)的肽连接体对正交于用于延伸融合蛋白的肽连接体对是足够的。如下面所讨论的,正交的肽连接体可以以多种方式实现。
因而,在一些优选的实施方式中,第一肽连接体对(A/A’)包括具有反应性赖氨酸残基的一个肽连接体A(例如肽标记物)和具有反应性天冬氨酸或天冬酰胺残基的一个肽连接体A’(例如肽结合配偶体),并且第二肽连接体对(B/B’)包括具有反应性天冬氨酸或天冬酰胺残基的一个肽连接体B(例如肽标记物)和具有反应性赖氨酸残基的一个肽连接体B’(例如肽结合配偶体)。使用上面提供的实例,不存在A与B’反应的适合途径并且不存在B与A’反应的适合途径。因此,肽连接体对彼此正交。
在进一步实施方式中,第一肽连接体对(A/A’)包括具有反应性赖氨酸残基的一个肽连接体A(例如肽标记物)和具有反应性天冬氨酸或天冬酰胺残基的一个肽连接体A’(例如肽结合配偶体),并且第二肽连接体对(B/B’)包括具有反应性赖氨酸残基的一个肽连接体B(例如肽标记物)和具有反应性天冬氨酸或天冬酰胺残基的一个肽连接体B’(例如肽结合配偶体)。可选地,第一肽连接体对(A/A’)包括具有反应性天冬氨酸或天冬酰胺残基的一个肽连接体A(例如肽标记物)和具有反应性赖氨酸残基的一个肽连接体A’(例如肽结合配偶体),并且第二肽连接体对(B/B’)包括具有反应性天冬氨酸或天冬酰胺残基的一个肽连接体B(例如肽标记物)和具有反应性赖氨酸残基的一个肽连接体B’(例如肽结合配偶体)。在这些实施方式中,肽连接体(肽标记物)A和B可以被选择使得它们在至少一个(例如两个、三个)“锚定”残基的大小方面具有本质差别,以便于A和B’与B和A’的非共价停靠(docking)(即A和B’与B和A’之间的相互作用)是无效的,从而确保具有最小的交叉反应。
术语“锚定残基”指的是关联肽连接体对中肽连接体的一个(例如肽结合配偶体)的β-链中的氨基酸残基,其指向肽连接体的疏水核心并且接受来自关联肽连接体对的另一个肽连接体(例如肽标记物)的反应性残基。β-链在面向溶剂的残基与面向疏水蛋白核心的残基之间交替并且残基定向由形成异肽蛋白——肽连接体衍生自其——中的自发异肽键的结构域的结构限定。这可以通过本领域中已知的任何适合的方法限定,例如X射线晶体学、核磁共振或冷冻电镜术。
小的锚定残基包括丙氨酸和缬氨酸。中等尺寸锚定残基包括亮氨酸、异亮氨酸和甲硫氨酸。大的锚定残基包括苯丙氨酸和色氨酸。因而,在一些实施方式中,至少一个小的锚定残基可以被中等尺寸或者大的锚定残基替换。在一些实施方式中,至少一个中等尺寸锚定残基可以被小的或大的锚定残基替换。在仍进一步实施方式中,至少一个大的锚定残基可以被中等尺寸或小的锚定残基替换。
在一些实施方式中,正交的肽连接体对可以衍生自不同的异肽蛋白或者相同异肽蛋白的不同结构域。在一些实施方式中,正交的肽连接体对从头生产。
从头生产的肽连接体对应当具备用于自发形成异肽键的两个需要的反应性氨基酸残基,优选地连同谷氨酸或天冬氨酸残基。因此,如上面所描述的,一个肽连接体包括反应性赖氨酸残基并且另一个肽连接体包括反应性天冬酰胺或天冬氨酸残基。在优选的实施方式中,肽连接体中的一个还包括诱导或促进所述肽连接体之间的异肽键形成的谷氨酸或天冬氨酸。但是,如上面所指出的,包括诱导或促进所述肽连接体之间的异肽键形成的谷氨酸或天冬氨酸残基的组分(例如肽,例如肽连接酶)可以被分开地提供。
将显而易见的是关联肽连接体对中的肽连接体都不包括参与异肽键形成的两个反应性残基,即关联肽连接体对中的每个肽连接体包括一个反应性残基,即赖氨酸残基或天冬氨酸/天冬酰胺残基。
在其中肽连接体中的一个包括诱导或促进所述肽连接体之间的异肽键形成的谷氨酸或天冬氨酸残基的实施方式中,典型地,所述谷氨酸或天冬氨酸残基在距离参与异肽键的连接体中的残基6.5埃内,例如在6.0、5.5、5.0、4.5、4.0、3.5或3.0埃内。这些距离具体地指每个残基内的相关原子即产于形成异肽键的原子之间的距离。当两个肽连接体彼此靠近时,例如当第一和第二蛋白质接触在一起时,参与键的两个反应性残基(并且具体地,它们的相关原子)应当在空间上彼此距离在4埃内,优选地3.8、3.6、3.4、3.2、3.0、2.8、2.6、2.4、2.2、2.0、1.8或1.6。
技术人员将立即认识到当从头设计异肽蛋白时,参与异肽键形成的残基的pKa也应当被考虑。例如,优选的是反应性赖氨酸残基在反应之前去质子化,其在中性pH下可能需要赖氨酸包埋(bury)在疏水核心中。
虽然正交的肽连接体对可以衍生自不同异肽蛋白或者相同异肽蛋白的不同结构域是优选的,但是从相同异肽蛋白,特别是从异肽蛋白的相同结构域生产正交的肽连接体对是可能的。例如,来自关联肽连接体对的一个肽连接体可以被修饰使得其不与该对中的另一肽连接体反应(或者不有效地反应)。该修饰可以是可逆的,使得逆转或去除阻止肽连接体之间反应的修饰重建肽连接体对有效地反应以形成异肽键的能力。因而,举例而言,关联肽连接体对A/A’的肽连接体中的一个可以被修饰,例如通过添加封闭基团修饰A,以产生肽连接体B,其中B不能有效地与A’或A反应以形成异肽键。从B去除封闭基团导致肽连接体B’,其能够与A’反应以形成异肽键。
可逆的或可去除的封闭基团的使用在本领域中是熟知的。因而,添加封闭基团至来自关联肽连接体对的一个肽连接体以产生正交肽连接体对可以被视为添加保护基团至肽连接体或者笼蔽(cage)肽连接体。封闭(例如保护、掩蔽或笼蔽)基团可以通过本领域中已知的任何适合的手段去除,其重建肽连接体与肽连接体对的另一肽连接体有效地反应以形成异肽键的能力。封闭基团的去除(去保护、解掩蔽(unmasking)、解笼蔽(uncaging))可以经由化学、酶促或光反应实现,这取决于封闭基团的性质。适合的封闭基团的实例包括大体积部分(bulky moiety),比如如此蛋白质:其可以空间地阻碍反应并且可以通过使用酶比如烟草蚀纹病毒蛋白酶去除(如在下列文献中综述的:Bioorg Med Chem.2012Jan 15;20(2):571-82.doi:10.1016/j.bmc.2011.07.048.Epub 2011Jul 30.Cleavable linkers inchemical biology.Leriche G,Chisholm L,WagnerA.反式环辛烯笼蔽的赖氨酸,(N-(((E)-环辛-2-烯-1-基)-氧)羰基-L-赖氨酸,其通过与四嗪反应化学地去笼蔽(Nat ChemBiol.2014Dec;10(12):1003-5.doi:10.1038/nchembio.1656.Epub 2014Nov 2.Diels-Alder reaction-triggered bioorthogonal protein decaging in living cells.Li J,Jia S,Chen PR)或利用邻硝基苄基或香豆素基团——其通过适合波长的光去笼蔽——笼蔽的赖氨酸,如本领域中熟知的(参见例如Chem Rev.2013Jan 9;113(1):119-91.doi:10.1021/cr300177k.Epub 2012Dec 21.Photoremovable protecting groups inchemistry and biology:reaction mechanisms and efficacy.Klán,
封闭基团的使用不需要被限制于产生额外正交的肽连接体对。例如,封闭基团可以特别地有用于控制融合蛋白的延伸,例如在多重反应中。举例而言,多种融合蛋白可以在单一固相基底上合成,例如以产生包括许多不同融合蛋白的阵列。在固相上每种融合蛋白的物理分离将促进肽连接体在基底上的选择性解封闭,例如类似于生成核酸阵列使用光反应性封闭基团。肽连接体的选择性解封闭将能够使得单一融合蛋白或融合蛋白组(例如在固相上的具体位置中)在一个延伸反应中延伸,和使得不同融合蛋白或融合蛋白组在后续反应中延伸。
因而,在一些实施方式中,肽连接体中的一个或多个可以包括封闭基团,即可逆的封闭基团。在一些实施方式中,可以通过使融合蛋白与去除封闭基团的光例如UV光、化学试剂或酶接触去除封闭基团。
因而,在一些实施方式中,本发明的方法可以包括从融合蛋白中的肽连接体解封闭或去除封闭基团的步骤。
在代表性实施方式中,本发明提供了生产(例如生成、合成、装配等)融合蛋白的方法,所述方法包括:
a)将第一蛋白质与第二蛋白质在能够在所述蛋白质之间形成异肽键的条件下接触,其中所述第一蛋白质和所述第二蛋白质每种包括肽连接体,其中所述肽连接体是肽连接体对,其(彼此)反应以形成连接所述第一蛋白质至所述第二蛋白质以形成连接的蛋白质的异肽键;和
b)将来自(a)的连接的蛋白质与第三蛋白质在能够在所述第三蛋白质和所述连接的蛋白质之间形成异肽键的条件下接触,其中所述第三蛋白质包括与来自(a)的连接的蛋白质中的进一步肽连接体反应的肽连接体,并且其中所述肽连接体是肽连接体对,其(彼此)反应以形成连接所述第三蛋白质至所述连接的蛋白质以形成融合蛋白的异肽键,
其中来自(a)的所述肽连接体对正交于来自(b)的肽连接体对。
并且其中连接的蛋白质中的进一步肽连接体包括封闭基团和能够在所述第三蛋白质和所述连接的蛋白质之间形成异肽键的条件包括处理连接的蛋白质以去除封闭基团。
在一些实施方式中,封闭基团可以在使连接的蛋白质与所述第三蛋白质接触的步骤之前被去除(肽连接体可以被解封闭)。在一些实施方式中,封闭基团可以在使连接的蛋白质与所述第三蛋白质接触的步骤之后或同时被去除(肽连接体可以被解封闭)。
如本文所使用的术语“肽连接体”通常指的是肽、寡肽或多肽,其可以直接地从异肽蛋白设计或衍生,例如肽连接体可以是异肽蛋白的片段或者其修饰。关于肽、寡肽和多肽所指的之间的大小界限没有标准限定,但是通常地肽可以被视为包括在2-20个氨基酸之间,和寡肽包括在21-39个氨基酸之间并且多肽可以被视为包括至少40个氨基酸。因而,如本文所限定的肽连接体可以被视为包括至少6个氨基酸,例如6-300个氨基酸。
在一些实施方式中,肽连接体可以被称为肽标记物并且其长度可以在6-50个氨基酸之间,例如7-45、8-40、9-35、10-30、11-25个氨基酸的长度,例如其可以包括6、7、8、9、10、11、12、13、14、15、16、17、18、19或20个氨基酸或由其组成。肽连接体或标记物经由异肽键特异性地共价结合至第二肽连接体,其中另一个肽连接体,其可以被视为肽标记物或肽结合配偶体,如下面所限定的。彼此反应(例如特异性地和有效地)以形成异肽键的两个肽连接体(例如肽标记物和肽标记物或肽标记物和肽结合配偶体)可以被限定为肽连接体对,具体地关联肽连接体对。
因而,如上面所提及的,肽连接体必须包括参与异肽键形成的至少一种氨基酸残基,例如赖氨酸或天冬酰胺/天冬酰胺。因此,肽连接体对中的每个肽连接体必须包括参与异肽键形成的不同的即互补的反应性氨基酸残基,即一个肽连接体包括赖氨酸残基并且另一个肽连接体包括天冬酰胺或天冬氨酸残基。
在一些实施方式中,肽连接体对包括两个肽标记物。通常地,两个肽标记物不自发地反应以形成异肽键,即它们需要添加诱导或催化所述肽标记物/连接体之间的异肽键形成的组分(例如肽,例如肽连接酶),如上面所限定的。
在一些实施方式中,肽连接体(即关联肽连接体对中肽连接体的一个)可以被称为肽结合配偶体,其可以被限定为肽(具体地寡肽或多肽)——其从异肽蛋白衍生或设计并且其可以经由异肽键(优选地经由自发反应)共价结合至肽标记物。在一些实施方式中,可以从与肽结合配偶体共价结合的肽标记物——即其相应肽标记物或连接体——相同的异肽蛋白设计或衍生肽结合配偶体。
通常地,肽结合配偶体大于其相应肽标记物并且包括与肽标记物相比更大的异肽蛋白的片段或部分或由其组成。具体而言,除了包括参与异肽键形成的残基(即赖氨酸或天冬酰胺/天冬氨酸)之外,肽结合配偶体还包括促进或诱导在肽连接体例如肽标记物和肽结合配偶体之间的异肽键形成的谷氨酸或天冬氨酸残基。
因而,肽结合配偶体可以包括与被设计为组成肽标记物的片段重叠的异肽蛋白的片段或者可以包括与肽标记物的片段相比不连续的和分开的异肽蛋白的片段。因而,肽结合配偶体的序列可以与设计的肽标记物的序列重叠,或者肽标记物和肽结合配偶体可以包括两个不连续的异肽蛋白的片段或者由其组成。在一些实施方式中,肽标记物可以不基于异肽蛋白的序列,例如肽标记物(肽连接体)可以从头设计。
虽然对于肽结合配偶体的尺寸不存在特别限制,但是最小化用于本发明的方法和用途的肽连接体的尺寸实际上是优选的。
因而,在一些实施方式中,肽连接体(例如肽结合配偶体)的长度可以是50-300个氨基酸之间,例如60-250、70-225、80-200个氨基酸的长度,例如其可以包括60、65、70、75、80、85、90、95、100、110、120、130、140、150、160、170、180、190或200个氨基酸或由其组成。
因此,在一些实施方式中,肽连接体对包括肽标记物和肽结合配偶体,其中所述肽连接体自发地反应以形成异肽键。
当肽连接体之间的异肽键形成不是自发的时(例如当肽连接体是两个肽标记物时),诱导或催化所述肽标记物/连接体之间的异肽键形成的肽可以被视为衍生自如上面所限定的异肽蛋白或肽结合配偶体的肽(例如肽连接酶)。具体而言,肽包括促进或诱导肽连接体之间的异肽键形成的谷氨酸或天冬氨酸残基,但是重要地是连接酶不包含与肽连接体对中的肽连接体中的任一个反应以形成异肽键的氨基酸残基。在一些实施方式中,肽连接酶的长度可以是50-300个氨基酸之间,例如60-250、70-225、80-200个氨基酸的长度,例如其可以包括60、65、70、75、80、85、90、95、100、110、120、130、140、150、160、170、180、190或200个氨基酸或由其组成。
因而,肽连接体(例如肽标记物和/或肽结合配偶体)因此不由异肽蛋白的整个蛋白质序列组成并且在长度上更短。例如,肽连接体可以包括少于5、10、20、30、40或50%的存在于异肽蛋白中的氨基酸残基的数目。
虽然肽连接体或肽连接体对可以基于异肽蛋白(具体地其一个或多个片段)的序列,但是技术人员将容易理解肽连接体的序列可以不同于其衍生自的异肽蛋白的部分的序列。因而,在一些实施方式中,肽连接体或肽连接体对可以包括与其衍生自的异肽蛋白的序列相比的突变或变更。如下面所讨论的,一些突变可以被引入肽连接体序列以改善肽连接体的稳定性和/或功能,例如以改善肽连接体之间的自发异肽键形成的反应速率。
因而,在一些实施方式中,肽连接体可以包括异肽蛋白的片段或者由其组成,其中该片段满足上面陈述的尺寸标准并且与其衍生自的异肽蛋白的可比较区域具有至少70、75、80、85、90、95、96、97、98、99或100%序列同一性。
而且,如上面所指出的,异肽蛋白可以通过检索已知异肽蛋白的结构同系物——即与已知异肽蛋白具有序列相似性或同一性的蛋白质——来鉴定。这些同系物可以被视为功能上等价的蛋白质并且可以在生产本发明的肽连接体中发现实用性。
在一些实施方式中,在本发明的方法和用途中使用的肽连接体对可以衍生自任何适合的异肽蛋白。如上面所提及的,各种异肽蛋白在本领域中是已知的。例如,肽连接体可以衍生自主要菌毛蛋白Spy0128,其具有在SEQ ID NO.23中列出的氨基酸序列并且由在SEQID NO.24列出的核苷酸序列编码。在该蛋白质中形成两个异肽键。一个异肽键在SEQIDNO.23中的位置179处的赖氨酸与SEQ ID NO.23中的位置303处的天冬酰胺(反应性残基)之间形成。诱导自发异肽键的谷氨酸残基在SEQ ID NO.23中的位置258处发现。因而,由在SEQ ID NO.23中陈述的异肽蛋白开发的肽连接体对将优选地包括含有蛋白质片段——其包括在位置303处的反应性天冬酰胺——的肽连接体和含有蛋白质片段——其包括在位置179处的反应性赖氨酸——的肽连接体。在一些实施方式中,肽连接体中的一个将包括也包含在位置258处的谷氨酸残基的片段。在一些实施方式中,包括在位置258处的谷氨酸残基的蛋白质的片段可以被分开地提供,即作为如上面所限定的肽连接酶。
主要菌毛蛋白Spy0128中的另一个异肽键在SEQ ID NO.23的位置36处的赖氨酸残基与SEQ ID NO.23的位置168处的天冬酰胺残基之间发生。诱导异肽形成的谷氨酸残基在SEQ ID NO.23中的位置117处发现。因此,由在SEQ ID NO.23中陈述的异肽蛋白开发的肽连接体对将优选地包括含有蛋白质片段——其包括在位置36处的反应性赖氨酸残基——的肽连接体和含有蛋白质片段——其包括在位置168处的反应性天冬酰胺——的肽连接体。在一些实施方式中,肽连接体中的一个将包括也包含在位置117处的谷氨酸残基的片段。在一些实施方式中,包括在位置117处的谷氨酸残基的蛋白质片段可以被分开地提供,即作为如上面所限定的肽连接酶。
一种来自粪肠球菌的黏附素蛋白的结构域ACE19也自发地形成异肽键。ACE19具有如在SEQ ID NO.27中陈述的氨基酸序列并且由如在SEQ ID NO.28中陈述的核苷酸序列编码。
异肽键在SEQ ID NO.27的位置181处的赖氨酸残基与SEQ ID NO.27的位置294处的天冬酰胺残基之间发生。该键由在SEQ ID NO.27中的位置213处的天冬氨酸残基诱导。因而,由在SEQ ID NO.27中陈述的异肽蛋白开发的肽连接体对将优选地包括含有蛋白质片段——其包括在位置294处的反应性天冬酰胺残基——的肽连接体和含有蛋白质片段——其包括在位置181处的反应性赖氨酸残基——的肽连接体。在一些实施方式中,肽连接体中的一个将包括也包含在位置213处的天冬氨酸残基的片段。在一些实施方式中,包括在位置213处的天冬氨酸残基的蛋白质片段可以被分开地提供,即作为如上面所限定的肽连接酶。
来自金黄色酿脓葡萄球菌的具有在SEQ ID NO.29中列出的氨基酸序列的胶原蛋白结合结构域包括一个自发形成的异肽键。该异肽键在SEQ ID NO.29的位置176处的赖氨酸与SEQ ID NO.29的位置308处的天冬酰胺之间发生。诱导异肽键的天冬氨酸残基在SEQID NO.29的位置209处。因而,由在SEQ ID NO.29中陈述的异肽蛋白开发的肽连接体对将优选地包括含有蛋白质片段——其包括在位置176处的反应性赖氨酸——的肽连接体和含有蛋白质片段——其包括在位置308处的反应性天冬酰胺——的肽连接体。在一些实施方式中,肽连接体中的一个将包括也包含在位置209处的天冬氨酸残基的片段。在一些实施方式中,包括在位置209处的天冬氨酸残基的蛋白质片段可以被分开地提供,即作为如上面所限定的肽连接酶。
来自酿脓链球菌的FbaB包括结构域CnaB2,其具有在SEQ ID NO.25中列出的氨基酸序列,由在SEQ ID NO.26中列出的核苷酸序列编码并且其包括一个自发形成的异肽键。CnaB2结构域中的异肽键在SEQ ID NO.25的位置15处的赖氨酸与SEQ ID NO.25的位置101处的天冬氨酸残基之间形成。诱导异肽键的谷氨酸残基在SEQ ID NO.25的位置61处。因而,由在SEQ ID NO.25中陈述的异肽蛋白开发的肽连接体对将优选地包括含有蛋白质片段——其包括在位置15处的反应性赖氨酸——的肽连接体和含有蛋白质片段——其包括在位置101处的反应性天冬氨酸——的肽连接体。在一些实施方式中,肽连接体中的一个将包括也包含在位置61处的谷氨酸残基的片段。在一些实施方式中,包括在位置61处的谷氨酸残基的蛋白质片段可以被分开地提供,即作为如上面所限定的肽连接酶(例如SEQ IDNO:34)。
RrgA蛋白是来自肺炎链球菌的黏着蛋白,其具有在SEQ ID NO.21中列出的氨基酸序列并且由在SEQ ID NO.22中列出的核苷酸序列编码。异肽键在SEQ ID NO.21中的位置742处的赖氨酸与SEQ ID NO.21中的位置854处的天冬酰胺之间形成。该键由在SEQIDNO.21的位置803处的谷氨酸残基诱导。因而,由在SEQ ID NO.21中陈述的异肽蛋白开发的肽连接体对将优选地包括含有蛋白质片段——其包括在位置854处的反应性天冬酰胺——的肽连接体和含有蛋白质片段——其包括在位置742处的反应性赖氨酸——的肽连接体。在一些实施方式中,肽连接体中的一个将包括也包含在位置803处的谷氨酸残基的片段。在一些实施方式中,包括在位置803处的谷氨酸残基的蛋白质片段可以被分开地提供,即作为如上面所限定的肽连接酶。
PsCs蛋白是来自中链球菌(Streptococcus intermedius)的por分泌系统C-末端分选结构域蛋白的片段,其具有在SEQ ID NO.31中列出的氨基酸序列并且由在SEQ IDNO.32中列出的核苷酸序列编码。异肽键在SEQ ID NO.31中的位置405处的赖氨酸与SEQ IDNO.31中的位置496处的天冬氨酸之间形成。因而,由在SEQ ID NO.31中陈述的异肽蛋白开发的肽连接体对将优选地包括含有蛋白质片段——其包括在位置496处的反应性天冬氨酸——的肽连接体和含有蛋白质片段——其包括在位置405处的反应性赖氨酸——的肽连接体。
因而,在一些实施方式中,在本发明的方法中使用的肽连接体对可以衍生自包括如在SEQ ID NO:21、23、25、27、29或31的任一个中陈述的氨基酸序列的异肽蛋白或与在SEQID NO:21、23、25、27、29或31的任一个中陈述的氨基酸序列具有至少70%序列同一性的蛋白质。
在一些实施方式中,上面的所述异肽蛋白序列与和其比较的序列(SEQ ID NO:21、23、25、27、29或31)具有至少75、80、85、90、95、96、97、98、99或100%同一性。
优选地,衍生自上面限定的异肽蛋白的肽连接体满足上面描述的尺寸和序列同一性标准。
序列同一性可以由本领域中已知的任何适合方式测定,例如使用SWISS-PROT蛋白序列数据库,利用具有可变pamfactor,以及设定为12.0的空位产生罚分(gap creationpenalty)和设定为4.0的空位延伸罚分(gap extension penalty)和2个氨基酸的窗口的FASTApep-cmp。用于测定氨基酸序列同一性的其它程序包括来自威斯康星大学的遗传学计算机组(Genetics Computer Group)(GCG)版本10软件包的BestFit程序。该程序使用Smith和Waterman的局部同源算法,具有一些缺省值:空位产生罚分-8,空位延伸罚分=2,平均匹配=2.912,平均错配=-2.003。
优选地,所述比较针对序列的全长进行,但是可以针对较小的比较窗进行,例如少于200、100或50个连续氨基酸。
优选地,这样的序列同一性相关的蛋白质在功能上等价于在叙述的SEQ ID NO中陈述的多肽。如本文所提及的,“功能上等价”指的是上面讨论的异肽蛋白的同系物,其可以在自发地形成异肽键方面相对于母体分子(即与其显示序列同源性的分子)显示一些降低的功效,但是优选地同样有效的或者更有效的。
在一些实施方式中,正交的肽连接体对可以衍生自上面限定的异肽蛋白中的任意两个或更多个。在优选的实施方式中,第一肽连接体对衍生自具有如在SEQ ID NO:21中陈述的氨基酸序列的异肽蛋白并且第二正交的肽连接体对衍生自具有如在SEQ ID NO:25中陈述的氨基酸序列的异肽蛋白。如上面所讨论的,在一些实施方式中,两个正交的肽连接体对可以衍生自相同的异肽蛋白,例如SEQ ID NO:21。其它正交的肽连接体对可以衍生自具有如在SEQ ID NO:21和23、21和27、21和29、21和31、25和27、25和29或25和31中陈述的氨基酸序列的异肽蛋白。基于本文公开的方法,特别是实施例,技术人员将容易地能够确定任意两个肽连接体对是正交的。例如,来自不同的肽连接体对的肽连接体的各种组合可以在促进异肽键形成的条件下,例如在PBS中,在pH4-9例如pH 7下,在1-40℃例如25℃下接触,例如在溶液中,持续适合的时间段,例如1-24小时。样品可以例如通过凝胶电泳(例如SDS-PAGE)进行分析以确定是否任何连接体已经反应,即通过检索缀合的肽,参见例如图7。因而,在本发明的方法中使用的正交的肽连接体对可以衍生自异肽蛋白的任何适合的组合。
本发明人已经有利地研发了在本发明的方法和用途中发现具体实用性的肽连接体对。在这方面,本发明人已经确定了肽连接体对可以衍生自如上面所限定的RrgA蛋白。但是,如在下面的实施例中详细描述的,本发明人将相对于天然RrgA序列的突变引入肽连接体以改善肽连接体的反应性。具体地,甘氨酸残基被替换为苏氨酸残基以稳定β-链并且天冬氨酸残基被替换为甘氨酸残基以稳定接近反应位点的发夹弯(hairpin turn)。
因而,本发明提供了肽连接体,其包括:
(i)如在SEQ ID NO:1中陈述的氨基酸序列或者与如在SEQ ID NO:1中陈述的氨基酸序列具有至少70%序列同一性的序列,其中所述氨基酸序列包括在位置9处的赖氨酸残基;或
(ii)如在SEQ ID NO:2中陈述的氨基酸序列或者与如在SEQ ID NO:2中陈述的氨基酸序列具有至少70%序列同一性的序列,其中所述氨基酸序列包括在位置55处的谷氨酸或天冬氨酸残基、在位置94处的苏氨酸残基、在位置100处的甘氨酸残基和在位置106处的天冬酰胺或天冬氨酸残基。
在一些实施方式中,(i)中的肽连接体包括如在SEQ ID NO:38中陈述的氨基酸序列和/或(ii)中的肽连接体包括如在SEQ ID NO:39中陈述的氨基酸序列。
在进一步实施方式中,本发明提供了肽连接体,其包括:
(i)如在SEQ ID NO:5中陈述的氨基酸序列或者与如在SEQ ID NO:5中陈述的氨基酸序列具有至少70%序列同一性的序列,其中所述氨基酸序列包括在位置8处的天冬氨酸或天冬酰胺残基;或
(ii)如在SEQ ID NO:6中陈述的氨基酸序列或者与如在SEQ ID NO:6中陈述的氨基酸序列具有至少70%序列同一性的序列,其中所述氨基酸序列包括在位置8处的赖氨酸残基。
在一些实施方式中,(i)中的肽连接体包括如在SEQ ID NO:42中陈述的氨基酸序列和/或(ii)中的肽连接体包括如在SEQ ID NO:43中陈述的氨基酸序列。
在仍进一步实施方式中,本发明提供了肽连接体,其包括:
(i)如在SEQ ID NO:9中陈述的氨基酸序列或者与如在SEQ ID NO:9中陈述的氨基酸序列具有至少70%序列同一性的序列,其中所述氨基酸序列包括在位置17处的天冬酰胺或天冬氨酸残基;或
(ii)如在SEQ ID NO:10中陈述的氨基酸序列或者与如在SEQ ID NO:10中陈述的氨基酸序列具有至少70%序列同一性的序列,其中所述氨基酸序列包括在位置9处的赖氨酸残基和在位置70处的谷氨酸或天冬氨酸残基。
在一些实施方式中,(i)中的肽连接体包括如在SEQ ID NO:109中陈述的氨基酸序列或者与如在SEQ ID NO:109中陈述的氨基酸序列具有至少70%序列同一性的序列,其中所述氨基酸序列包括在位置17处的天冬酰胺或天冬氨酸残基、在位置11处的甘氨酸残基和优选地在位置20处的异亮氨酸残基、在位置21和22处的脯氨酸残基以及在位置23处的赖氨酸残基。
在一些实施方式中,(i)中的肽连接体包括如在SEQ ID NO:46中陈述的氨基酸序列和/或(ii)中的肽连接体包括如在SEQ ID NO:47中陈述的氨基酸序列。
在一些实施方式中,上面的所述肽连接体序列与和其比较的序列(SEQ ID NO:1、2、5、6、9、10或109)具有至少75、80、85、90、95、96、97、98、99或100%同一性。
在优选的实施方式中,在上面的每个部分(i)中限定的肽连接体能够与包括如在上面的每个各自部分(ii)中限定的氨基酸序列的肽连接体自发地形成异肽键。例如,包括如在SEQ ID NO:1中陈述的氨基酸序列的肽连接体或其变体能够与包括如在SEQ ID NO:2中陈述的氨基酸序列的肽连接体或其变体自发地形成异肽键。类似地,包括SEQ ID NO:5和6的肽或其变体能够彼此自发地形成异肽键,并且包括SEQ ID NO:9和10的肽或其变体(例如SEQ ID NO:109)能够彼此自发地形成异肽键(例如SEQ ID NO:109和10)。
因而,本发明提供了可以在本发明的方法和用途中使用的肽连接体对,其包括:
(1)如上面所限定的包括SEQ ID NO:1和2的肽连接体或其变体,例如SEQ ID NO:38和39;
(2)如上面所限定的包括SEQ ID NO:5和6的肽连接体或其变体,例如SEQ ID NO:42和43;
(3)如上面所限定的包括SEQ ID NO:9和10的肽连接体或其变体,例如SEQ ID NO:46和47;或
(4)如上面所限定的包括SEQ ID NO:109和10的肽连接体或其变体。
因而,上面限定的每个肽连接体对可以被限定为关联肽连接体对。
在一些实施方式中,上面限定的每个肽连接体对(即每个关联肽连接体对)可以被视为正交(即非关联)于其它肽连接体对,即对(1)正交于对(2)、(3)和/或对(4),对(2)正交于对(1)、(3)和/或对(4),对(3)正交于对(1)和/或对(2)和对(4)正交于对(1)和/或(2)。在一些实施方式中,这些正交对代表在本发明的方法和用途中使用的优选的正交(非关联)的肽(关联)连接体对。进一步优选的正交的肽连接体对在下面限定。
如本文所讨论的,本发明的肽连接体在合成融合蛋白中发现具体实用性,其中肽连接体被并入蛋白质单元(例如形成该蛋白质单元的结构域或者连接至其),该蛋白质单元将要连接(缀合)至另一蛋白质单元以形成融合蛋白。因而,在进一步实施方式中,本发明提供了包括如上面所限定的多肽和肽连接体的重组或合成多肽。
将显而易见的是本发明的肽连接体可以在其它方法和用途中发现实用性,例如作为在WO2011/098772(通过引用被并入本文)中描述的肽标记物。
可以在本发明的方法和用途中使用的其它肽连接体包括:
(i)如在SEQ ID NO:13中陈述的氨基酸序列或者与如在SEQ ID NO:13中陈述的氨基酸序列具有至少70%序列同一性的序列,其中所述氨基酸序列包括在位置7处的天冬氨酸或天冬酰胺残基;或
(ii)如在SEQ ID NO:14中陈述的氨基酸序列或者与如在SEQ ID NO:14中陈述的氨基酸序列具有至少70%序列同一性的序列,其中所述氨基酸序列包括在位置56处的谷氨酸或天冬氨酸残基以及在位置10处的赖氨酸残基;或
(iii)如在SEQ ID NO:33中陈述的氨基酸序列或者与如在SEQ ID NO:33中陈述的氨基酸序列具有至少70%序列同一性的序列,其中所述氨基酸序列包括在位置8处的赖氨酸残基;或
(iv)如在SEQ ID NO:17中陈述的氨基酸序列或者与如在SEQ ID NO:17中陈述的氨基酸序列具有至少70%序列同一性的序列,其中所述氨基酸序列包括在位置11处的天冬氨酸或天冬酰胺残基;或
(v)如在SEQ ID NO:18中陈述的氨基酸序列或者与如在SEQ ID NO:18中陈述的氨基酸序列具有至少70%序列同一性的序列,其中所述氨基酸序列包括在位置241处的谷氨酸或天冬氨酸残基以及在位置162处的赖氨酸残基。
在一些实施方式中,上面的所述肽连接体序列与和其比较的序列(SEQ ID NO:13、14、17、18或33)具有至少75、80、85、90、95、96、97、98、99或100%同一性。
可以在本发明的方法和用途中使用的其它肽连接体对包括:
(5)如上面所限定的包括SEQ ID NO:13和14的肽连接体或其变体;
(6)如上面所限定的包括SEQ ID NO:13和33的肽连接体或其变体;
(7)如上面所限定的包括SEQ ID NO:17和18的肽连接体或其变体。
在一些实施方式中,在关联肽连接体对包括上面的(6)中限定的对时,反应还包括诱导或催化异肽键形成的组分。例如,反应包括肽连接酶,优选地其中所述肽连接酶包括如在SEQ ID NO:34中陈述的氨基酸序列或者与如在SEQ ID NO:34中陈述的氨基酸序列具有至少70%序列同一性的序列。
在一些实施方式中,上面的所述肽连接酶序列与和其比较的序列(SEQ ID NO:34)具有至少75、80、85、90、95、96、97、98、99或100%同一性。
虽然选自上面的(1)-(7)的任何正交对的肽连接体对可以在本发明的方法和用途中使用,但是特别优选的正交的肽连接体对包括在上面限定的下列对的任一种:(1)和(4)、(1)和(5)、(1)和(6)、(1)和(3)、(1)和(2)、(2)和(4)、(2)和(5)、(2)和(6)、(3)和(5)、(3)和(6)、(4)和(5)以及(4)和(6)。
待要连接至另一蛋白质以形成融合蛋白的蛋白质内的肽连接体的位置不是特别重要的。因而,在一些实施方式中,肽连接体可以位于待要在融合蛋白中连接的重组或合成多肽或蛋白质的N-末端或C-末端处。在一些实施方式中,肽连接体可以位于待要在融合蛋白中连接的重组或合成多肽或蛋白质的内部。因而,在一些实施方式中,肽连接体可以被视为待要在融合蛋白中连接的重组或合成多肽或者蛋白质的N-末端、C-末端或内部结构域。
在一些实施方式中,在融合蛋白中待接合的蛋白质或者待接合至融合蛋白的蛋白质与肽连接体之间包括一个或多个间隔区例如肽间隔区可以是有用的。因而,蛋白质和肽连接体可以直接地连接至彼此或者它们可以通过一个或多个间隔区序列的方式间接地连接。因而,间隔区序列可以间隔或分开重组或合成多肽或待要在融合蛋白中连接的蛋白质的两个或更多个单独的部分。在一些实施方式中,间隔区可以是肽连接体的N-末端或C-末端。在一些实施方式中,间隔区可以在肽连接体的两侧处。
间隔区序列的精确性质不是关键的并且其可以具有可变的长度和/或序列,例如其可以具有1-40,更具体地2-20、1-15、1-12、1-10、1-8或1-6个残基,例如6、7、8、9、10或更多个残基。举代表性实例,间隔区序列——如果存在的话——可以具有1-15、1-12、1-10、1-8或1-6个残基等。残基的性质不是关键的并且它们可以例如是任何氨基酸,例如中性氨基酸或脂肪族氨基酸,或可选地它们可以是疏水的,或极性的或带电的或结构形成的(structure-forming),例如脯氨酸。在一些优选的实施方式中,连接体是富含丝氨酸和/或甘氨酸的序列。
示例性间隔区序列因而包括任何单个氨基酸残基,例如S、G、L、V、P、R、H、M、A或E,或由一个或多个这样的残基组成的二-、三-、四-、五-或六-肽。代表性的和优选的间隔区序列包括如在SEQ ID NO:36或37中陈述的氨基酸序列。
本发明的重组或合成多肽也可以包括纯化部分或标记物以促进它们的纯化(例如在用于本发明的方法和用途中之前和/或在融合蛋白的延伸期间,如下面讨论的)。任何适合的纯化部分或标记物可以被并入多肽并且这样的部分在本领域中是熟知的。例如,在一些实施方式中,重组或合成肽可以包括肽纯化标记物或部分,例如His-标记物序列。这些纯化部分或标记物可以在多肽内的任何位置处并入。在一些优选的实施方式中,纯化部分位于多肽的N-或C-末端处或接近多肽的N-或C-末端处(即N-或C-末端的5、10、15、20个氨基酸内)。
本发明的代表性的重组或合成多肽包括如此多肽:其具有如在SEQ ID NO:50-59的任一个中列出的氨基酸序列或者与如在SEQ ID NO:50-59的任一个中陈述的氨基酸序列具有至少70%序列同一性的序列,其中所述多肽包括如上面所限定的肽连接体。
优选地,重组或合成多肽满足上面限定的序列同一性要求,例如与和其比较的序列具有至少75、80、85、90、95、96、97、98、99或100%同一性。
如上面所指出,本发明的优势起因于如下事实:并入待接合在一起以形成融合蛋白的蛋白质(例如本发明的重组或合成多肽)中的肽连接体可以完全地被基因编码。因而,在进一步方面,本发明提供了编码如上面所限定的肽连接体或多肽的核酸分子。
在一些实施方式中,编码上面限定的肽连接体的核酸分子包括如在SEQ ID NO:3、4、7、8、11、12、40、41、44、45、48、49或110的任一个中陈述的核苷酸序列或者与如在SEQ IDNO:3、4、7、8、11、12、40、41、44、45、48、49或110的任一个中陈述的序列具有至少70%序列同一性的核苷酸序列。
在一些实施方式中,编码上面限定的重组或合成多肽的核酸分子包括如在SEQ IDNO:60-69的任一个中陈述的核苷酸序列或者与如在SEQ ID NO:60-69的任一个中陈述的序列具有至少70%序列同一性的核苷酸序列。
优选地,上面的核酸分子与和其比较的序列具有至少75、80、85、90、95、96、97、98、99或100%同一性。
核酸序列同一性可以通过如下测定:例如使用CGC程序包的FASTA检索,具有缺省值和可变pamfactor,以及设定为12.0的空位产生罚分和设定为4.0的空位延伸罚分以及6个核苷酸的窗口。优选地,所述比较针对序列的全长进行,但是可以针对较小的比较窗口进行,例如少于600、500、400、300、200、100或50个连续的核苷酸。
本发明的核酸分子可以由核糖核苷酸和/或脱氧核糖核苷酸以及能够参与沃森-克里克型(Watson-Crick type)或类似的碱基对相互作用的合成核苷酸残基组成。优选地,核酸分子是DNA或RNA。
上面描述的核酸分子可以可操作地连接至表达控制序列,或者重组DNA克隆媒介或者包含这样的重组DNA分子的载体。这允许用于本发明的方法和用途中的蛋白质的细胞内表达,例如作为基因产物表达本发明的多肽,其表达通过被引入感兴趣细胞的基因(一种或多种)指导。基因表达由在感兴趣细胞中有活性的启动子指导并且可以以任何线性或环状核酸(例如DNA)载体的形式被插入,用于并入基因组或者用于独立复制或瞬时转染/表达。适合的转化或转染技术在文献中充分地描述。可选地,裸核酸(例如DNA)分子可以被直接地引入细胞用于生产本发明的蛋白质和多肽并且在本发明中使用。可选地,核酸可以通过体外转录转化为mRNA并且相关蛋白质可以通过体外翻译生成。
适合的表达载体包括在具有本发明的核酸分子的匹配阅读框中连接的适合控制序列,比如例如翻译(例如起始和终止密码子、核糖体结合位点)和转录控制元件(例如启动子-操纵子区域、终止停止序列(termination stop sequence))。适合的载体可以包括质粒和病毒(包括噬菌体和真核病毒二者)。适合的病毒载体包括杆状病毒,并且也包括腺病毒、腺伴随病毒、疱疹和牛痘/痘病毒。许多其它病毒载体在本领域中描述。优选的载体包括细菌和哺乳动物表达载体pGEX-KG、pEF-neo和pEF-HA。
如上面所指出的,本发明的多肽可以包括额外序列(例如肽/蛋白质标记物以促进多肽的纯化)并且因而核酸分子可以便利地与编码额外肽或多肽——例如His-标记物、麦芽糖结合蛋白——的DNA融合以通过表达产生融合蛋白。
因而,从进一步方面看,本发明提供了载体,优选地表达载体,其包括如上面所限定的核酸分子。
本发明的其它方面包括用于制备根据本发明的重组核酸分子的方法,其包括将编码本发明的肽连接体和/或多肽的本发明的核酸分子插入载体核酸。
本发明的核酸分子,优选地包含在载体中的核酸分子,可以通过任何适合的方式被引入细胞。适合的转化或转染技术在文献中充分地描述。多种技术是已知的并且可以被用于将这些载体引入原核或真核细胞进行表达。用于该目的的优选的宿主细胞包括昆虫细胞系、酵母、哺乳动物细胞系或大肠杆菌,比如菌株BL21/DE3。本发明还延伸至转化的或转染的原核或真核宿主细胞,其包含如上面所限定的核酸分子,特别是载体。
因而,在另一方面,提供了包含如上面所描述的核酸分子和/或载体的重组宿主细胞。
“重组”意思是核酸分子和/或载体已经被引入宿主细胞。宿主细胞可以自然地包含或可以不自然地包含核酸分子的内源拷贝,但是其是重组的,因为核酸分子和/或载体的外源或进一步内源拷贝已经被引入。
本发明的进一步方面提供了制备如上文所限定的本发明的肽连接体和/或多肽的方法,其包括在其中编码所述肽连接体和/或多肽的所述核酸分子被表达的条件下培养包含如上面所限定的核酸分子的宿主细胞,并且回收如此产生的所述分子(肽连接体和/或多肽)。表达的肽连接体和/或多肽形成本发明的进一步方面。
在一些实施方式中,本发明的肽连接体和/或多肽,或者在本发明的方法和用途中使用的肽连接体和/或多肽,可以合成地生成,例如通过连接氨基酸分子或较小的合成地生成的肽,或者更便利地通过重组表达编码如上文描述的所述多肽的核酸分子。
本发明的核酸分子可以通过本领域中已知的任何适合的方式合成地生成。
因而,本发明的肽连接体和/或多肽可以是分离的、纯化的、重组的或合成的肽连接体或多肽。如上面所指出的,术语“多肽”在本文中与术语“蛋白质”可互换地使用。如上面所指出的,术语多肽或蛋白质通常包括任何氨基酸序列,其包括至少40个连续氨基酸残基,例如至少50、60、70、80、90、100、150个氨基酸,比如40-1000、50-900、60-800、70-700、80-600、90-500、100-400个氨基酸。
类似地,本发明的核酸分子可以是分离的、纯化的、重组的或合成的核酸分子。
因而,可选地来看,本发明的肽连接体、多肽和核酸分子优选地是非天然的,即非自然存在的分子。
在本文中使用标准氨基酸命名法。因而,氨基酸残基的全名可以与一个字母代码或三个字母缩写可互换地使用。例如,赖氨酸可以用K或Lys代替,异亮氨酸可以用I或Ile代替,等等。而且,术语天冬氨酸的盐/酯和天冬氨酸,以及谷氨酸的盐/酯和谷氨酸在本文中可互换地使用,并且可以用asp或D,或glu或E分别代替。
虽然设想本发明的和在本发明中使用的肽连接体和多肽可以重组地产生,并且这是本发明的优选的实施方式,但是将显而易见的是本发明的肽连接体可以通过其它方式缀合至待在融合蛋白中接合的蛋白质。换句话说,肽连接体和蛋白质可以通过任何适合的方式例如重组地分开地产生,并且随后缀合(接合)以形成可以在本发明的方法中使用的肽连接体-蛋白质缀合物。例如,本发明的肽连接体可以如上面描述的合成地或重组地产生,并且经由非肽连接体或间隔区例如化学连接体或间隔区缀合至蛋白质(根据本发明的方法待在融合蛋白中连接的蛋白质)。
因而,在一些实施方式中,待并入融合蛋白的肽连接体和蛋白质可以直接地通过键或者间接地通过连接基团接合在一起。在连接体基团被采用的情况下,可以选择这些基团以通过连接基团提供肽连接体和蛋白质组分的共价附接。感兴趣的连接基团可以根据蛋白质组分的性质宽泛地改变。连接基团——当存在时——在许多实施方式中是生物学上惰性的。
多种连接基团对于技术人员是已知的并且在本发明中发现用途。在代表性实施方式中,连接基团通常是至少大约50道尔顿、常常至少大约100道尔顿并且可以大至1000道尔顿或更大,例如如果连接基团包含间隔区,则多至1000000道尔顿,但是通常将不超过大约500道尔顿并且常常将不超过300道尔顿。一般而言,这些连接体将包括在任一端以能够共价地结合至肽连接体和蛋白质组分的反应性官能团封端的间隔区基团。感兴趣的间隔区基团可以包括脂肪族和不饱和烃链、包含杂原子比如氧(醚类,比如聚乙二醇)或氮(聚胺类)的间隔区、肽类、糖类、可能包含杂原子的环状或非环状体系。间隔区基团也可以由结合至金属的配体组成,使得金属离子的存在配位两个或更多个配体以形成复合体。具体的间隔区元件包括:1,4-己二胺、苯二甲胺、对苯二酸、3,6-二氧辛二酸、乙二胺-N,N-双乙酸、1,1'-乙烯双(5-氧-3-吡咯烷羧酸)、4,4'-乙烯二哌啶。潜在的反应性官能团包括亲核官能团(胺类、醇类、硫醇类、酰肼类),亲电子官能团(醛类、酯类、乙烯酮类、环氧衍生物、异氰酸酯类、马来酰亚胺类),能够环加成反应、形成二硫键或结合至金属的官能团。具体实例包括伯胺和仲胺、异羟肟酸、N-羟基琥珀酰亚胺基酯类、N-羟基琥珀酰亚胺基碳酸酯类、氧羰基咪唑类、硝基苯基酯类、三氟乙基酯类、缩水甘油醚类、乙烯砜类和马来酰亚胺类。可以在对象封闭试剂中发现用途的具体的连接体基团包括杂官能化合物,比如叠氮基苯甲酰肼、N-[4-(p-叠氮基水杨基氨基)丁基]-3'-[2'-吡啶基二硫]丙酰胺)、双-磺基琥珀酰亚胺基辛二酸酯、二甲基己二酰亚胺酯、二琥珀酰亚胺基酒石酸酯、N-马来酰亚胺基丁酰氧基琥珀酰亚胺酯、N-羟基磺基琥珀酰亚胺基-4-叠氮基苯甲酸酯、N-琥珀酰亚胺基[4-叠氮基苯基]-1,3'-二硫丙酸酯、N-琥珀酰亚胺基[4-碘代乙酰基]氨基苯甲酸酯、戊二醛和琥珀酰亚胺基-4-[N-马来酰亚胺基甲基]环己烷-1-羧酸酯、3-(2-吡啶基二硫)丙酸N-羟基琥珀酰亚胺酯(SPDP)、4-(N-马来酰亚胺基甲基)-环己烷-1-羧酸N-羟基琥珀酰亚胺酯(SMCC)等。
在一些实施方式中,修饰肽连接体和/或蛋白质中的一个或多个残基以促进这些分子的缀合和/或以改善肽连接体和/或蛋白质的稳定性可以是有用的。因而,在一些实施方式中,本发明的或在本发明中使用的肽连接体、多肽或蛋白质可以包括非自然或非标准氨基酸。
在一些实施方式中,本发明的或在本发明中使用的肽连接体、多肽或蛋白质可以包括一个或多个,例如至少1、2、3、4、5个非常规氨基酸,比如10、15、20或更多个非常规氨基酸,即具备不由标准遗传密码编码的侧链的氨基酸,在本文中被称为“非编码的氨基酸”(参见例如表1)。这些可以选自通过代谢过程形成的氨基酸比如鸟氨酸或牛磺酸,和/或人工修饰的氨基酸比如9H-芴-9-基甲氧基羰基(Fmoc)、(叔)-丁氧基羰基(Boc)、2,2,5,7,8-五甲基苯并二氢吡喃-6-磺酰基(Pmc)保护的氨基酸,或具有苯氧基-羰基(Z)基团的氨基酸。
可以在本发明的和在本发明中使用的肽连接体或多肽中使用的非标准或结构类似氨基酸的实例是D氨基酸、酰胺等排物(比如N-甲酰胺、后-逆酰胺(retro-inverseamide)、硫代酰胺、硫酯、膦酸酯、酮亚甲基、羟基亚甲基、氟代烯基、(E)-乙烯基、亚甲基氨基、亚甲基硫或链烷)、L-N甲基氨基酸、D-α甲基氨基酸、D-N-甲基氨基酸。非常规即非编码氨基酸的实例在表1中列举。
表1
/>
/>
在一些实施方式中,本发明的方法可以使用固相非均质地(heterogeneously)(如上面描述的)执行,例如,其中生长的融合蛋白,优选地融合蛋白链中的第一或第二蛋白质可以固定在固相上,这允许使用洗涤步骤。因而,在一些实施方式中,方法是固相方法(即非均质方法)。可选地来看,方法在固相或固体基底上执行。固相分析的使用提供了优势。例如,洗涤步骤可以有助于去除可能干扰后续轮次反应(即加入进一步蛋白质至融合蛋白)的过量的、未反应的蛋白质和/或组分,例如肽连接酶、参与解封闭(解笼蔽、解掩蔽、去保护)肽连接体的组分等。
在固相上融合蛋白的固定可以以多种方式实现。融合蛋白可以以任何便利方式固定,即结合至支持体。在一些实施方式中,融合蛋白的第一或第二蛋白质固定在固体支持体上。因而,在一些实施方式中,方法可以包括在固体支持体上固定第一蛋白质的步骤。在一些实施方式中,方法可以包括在固体支持体上固定包括第一和第二蛋白质的连接的蛋白质的步骤。
因而,可以根据选项,从本领域中众所周知的和文献中描述的任意数目的固定手段以及固体支持体选择固定的方式或手段和固体支持体。因而,融合蛋白可以直接地结合至支持体,例如经由融合蛋白中至少一种蛋白质的结构域或部分(例如化学交联的)。在一些实施方式中,融合蛋白可以借助肽连接体基团,或者通过中间结合基团(一个或多个)(例如借助生物素-链霉亲和素相互作用)间接地结合。因而,融合蛋白可以共价地或非共价地连接至固体支持体。连接可以是可逆的(例如可裂解的)或不可逆的连接。因而,在一些实施方式中,连接可以酶促地、化学地或利用光裂解,例如连接可以是光敏连接。
因而,在一些实施方式中,待包含在融合蛋白中的蛋白质可以利用在支持体上提供的固定手段(例如亲和结合配偶体,例如生物素或半抗原——其能够结合至其结合配偶体,即关联结合配偶体,例如链霉亲和素或抗体)提供。在一些实施方式中,待固定在支持体上的蛋白质可以是结合蛋白,例如麦芽糖结合蛋白、抗体等。融合蛋白与固体支持体之间的相互作用必须是足够强健的以允许洗涤步骤,即融合蛋白与固体支持体之间的相互作用不被洗涤步骤破坏(显著地破坏)。例如,优选的是利用每个洗涤步骤,少于5%,优选地少于4、3、2、1、0.5或0.1%的融合蛋白从固相移出或洗脱。在这方面,本发明人已经研发了对麦芽糖具有提高的结合亲和力的修饰的麦芽糖结合蛋白并且因而在本发明的方法中发现具体实用性。
因而,本发明的进一步方面提供了麦芽糖结合蛋白,其包括如在SEQ ID NO:70中陈述的氨基酸序列或与如在SEQ ID NO:70中陈述的氨基酸序列具有至少70%同一性的序列。
在一些实施方式中,上面的麦芽糖结合蛋白与和其比较的序列具有至少75、80、85、90、95、96、97、98、99或100%同一性。
优选地,与如在SEQ ID NO:70中陈述的氨基酸序列具有至少70%同一性的麦芽糖结合蛋白在功能上等价于由如在SEQ ID NO:70中陈述的氨基酸序列组成的蛋白质,即与由如在SEQ ID NO:70中陈述的氨基酸序列组成的蛋白质相比能够以相同亲和力或更大亲和力结合麦芽糖。例如,本发明的麦芽糖结合蛋白对于麦芽糖具有低于0.2μM,例如0.1、0.08、0.05、0.03或0.01μM或更低的结合亲和力。在优选的实施方式中,与如在SEQ ID NO:70中陈述的氨基酸序列具有至少70%同一性的麦芽糖结合蛋白包括在位置312和317处的缬氨酸。
本发明还提供了编码上面限定的麦芽糖结合蛋白的核酸分子。在一些实施方式中,核酸分子包括如在SEQ ID NO:71中陈述的核苷酸序列或者与如在SEQ ID NO:71中陈述的核苷酸序列具有至少70%序列同一性的序列。
在一些实施方式中,麦芽糖结合蛋白包括(例如缀合至)如本文限定的肽连接体。在仍进一步实施方式中,麦芽糖结合蛋白包括多于一个(例如2或3个)如上面所限定的氨基酸序列,即其包括重复序列。
融合蛋白,例如待并入融合蛋白的第一蛋白质,可以在其与待并入融合蛋白的进一步蛋白质(例如第二蛋白质)接触之前或之后被固定。进一步,这样的“可固定的”融合蛋白可以与进一步蛋白质连同支持体接触。
固体支持体可以是当前广泛用于或计划用于固定、分离等的众所周知的支持体或基质的任一种。这些可以采取颗粒(例如珠,其可以是磁性的、顺磁性的或非磁性的)、片、凝胶、过滤器、膜、纤维、毛细管、载玻片、阵列或微量滴定条(microtitre strip)、管、板或孔等的形式。
支持体可以由玻璃、二氧化硅、乳胶或聚合材料制成。适合的是为结合融合蛋白呈现高表面积的材料。这些支持体可以具有不规则表面并且可以是例如多孔的或颗粒的,例如颗粒、纤维、网、烧结物或筛。颗粒材料例如珠是有用的,这是由于它们更大的结和能力,尤其是聚合珠。
便利地,根据本发明使用的颗粒固体支持体将包括球形珠。珠的尺寸不是关键的,但是它们可以例如具有至少1μm并且优选地至少2μm的直径量级,并且具有优选地不超过10μm,并且例如不超过6μm的最大直径。
单分散颗粒,即尺寸基本上均匀的那些(例如,具有低于5%的直径标准偏差的尺寸)具有优势:它们提供非常一致的反应再现性。代表性的单分散聚合物颗粒可以通过在US-A-4336173中描述的技术生产。
但是,为了有助于操作和分离,磁珠是有利的。如本文所使用的术语“磁性”意思是当置于磁场中时,支持体能够具有赋予其的磁矩,并且因而在那个磁场的作用下是可位移的(displaceable)。换句话说,包括磁性颗粒的支持体可以容易地通过磁性聚集去除,这提供了在异肽键形成步骤之后分离颗粒的快速、简单和有效的方式。
在一些实施方式中,固体支持体是直链淀粉树脂。
一旦在融合蛋白中的倒数第二与最后蛋白质之间形成异肽键,从固体支持体移出或洗脱蛋白质可以是期望的。因而,在一些实施方式中,方法包括从固体支持体洗脱或移出融合蛋白的步骤。
如上面所指出的,在某些方案中,本发明的方法可以允许在相同固体支持体例如阵列上同时产生两种或更多种融合蛋白。因而,在一些实施方式中,本发明的方法可以被视为多重和/或高通量格式。
在进一步实施方式中,本发明提供了由本发明的方法获得或可获得的融合蛋白。在一些实施方式中,融合蛋白被固定在固体基底上。因而,在又进一步实施方式中,本发明提供了固体基底,其包括由本发明的方法获得或可获得的至少一种融合蛋白。在一些实施方式中,固体基底可以是阵列(即蛋白质阵列,具体地融合蛋白阵列)的形式,该阵列包括由本发明的方法获得或可获得的两种或更多种融合蛋白(具有不同序列的融合蛋白)。在一些实施方式中,阵列包括至少10、20、50、100、200、300、400、500、1000、1500、2000、5000或10000种融合蛋白,即不同的融合蛋白(具有不同结构或序列)。
在一些实施方式中,由本发明的方法获得或可获得的两种或更多种融合蛋白可以混合在一起以形成融合蛋白文库。因而,在进一步实施方式中,本发明提供了融合蛋白文库,其包括由本发明的方法获得或可获得的至少两种融合蛋白。在一些实施方式中,该文库包括至少10、20、50、100、200、300、400、500、1000、1500、2000、5000或10000种融合蛋白,即不同的融合蛋白(具有不同结构或序列)。在一些实施方式中,该文库可以包括在固体基底例如珠或颗粒上固定的融合蛋白。例如,每个固体基底例如珠或颗粒可以包括不同的融合蛋白。
虽然已经使用非均质实施方式示例了本发明的方法,但是从本文的公开内容将容易显而易见的是方法可以被均质地(即在溶液中)采用。但是,为了防止产生融合蛋白的混合物,在一些实施方式中,在每轮延伸之后将融合蛋白与反应中的其它组分分离可能是必要的。分离或纯化可以通过任何适合的方式实现。例如,融合蛋白链中的蛋白质的一种可以包括纯化标记物或者可以是结合蛋白(例如麦芽糖结合蛋白),其将促进融合蛋白与反应中的其它组分的分离,例如亲和色谱法。另外地或可选地,可以利用其它纯化/分离方法,例如离子交换色谱法、尺寸排阻色谱法、超速离心、自旋过滤(spin-filtration)、透析、透滤(dia-filtration)等。
因而,在一些实施方式中,本发明的方法可以包括在异肽键形成的步骤之后分离或纯化融合蛋白的步骤。
在进一步实施方式中,本发明提供了试剂盒,具体地在本发明的方法和用途中——即在生产或合成融合蛋白中——使用的试剂盒,其中所述试剂盒包括:
(a)包括如上面所限定的肽连接体的重组或合成多肽;和
(b)包括如限定的肽连接体的重组或合成多肽,该肽连接体能够与(a)的多肽中的肽连接体形成异肽键;和/或
(c)编码如上面所限定的肽连接体的核酸分子,特别是载体;和/或
(d)编码肽连接体的核酸分子,特别是载体,该肽连接体能够与由(b)的核酸分子编码的肽连接体形成异肽键,
任选地,其中(a)和/或(b)的重组或合成多肽包括为肽连接体——其正交于在(a)和(b)的多肽中的肽连接体——的对的一部分的进一步肽连接体。
本发明的方法和用途可以被限定为体外方法和用途,即用于合成融合蛋白的体外方法。
将显而易见的是本发明的方法不限于将任何特定蛋白质连接在一起以形成融合蛋白。因而,方法可以利用如本文所限定的任何蛋白质或多肽,即任何期望的蛋白质或多肽。换句话说,本发明可以利用期望包含或并入融合蛋白的任何蛋白质或多肽。而且,本发明的重组或合成多肽可以包括连接至本发明的肽连接体的任何蛋白质。蛋白质可以衍生或获得自任何适合的来源。例如,蛋白质可以体外翻译或纯化自生物学和临床样品,例如生物体(真核、原核)的任何细胞或组织样品,或者由其衍生的任何体液或制品,以及这样的样品,比如细胞培养物、细胞制品、细胞溶胞产物等。蛋白质可以衍生或获得例如纯化自环境样品,例如也包括土壤和水样品或者食物样品。样品可以是新鲜制备的或者它们可以以任何便利方式预先处理,例如便于储存。
如上面所指出的,在优选的实施方式中,待并入融合蛋白的蛋白质可以重组地产生并且因而编码所述蛋白质的核酸分子可以衍生或获得自任何适合来源,例如任何病毒或细胞材料,包括所有原核或真核细胞、病毒、噬菌体、支原体、原生质体和细胞器。这类生物学材料可以因而包括所有类型的哺乳动物和非哺乳动物细胞、植物细胞、藻类——其包括蓝绿藻、真菌、细菌、原生动物等。在一些实施方式中,待在融合蛋白中连接在一起的蛋白质可以是合成蛋白质。
作为代表性实例,待要在根据本发明的融合蛋白中接合的蛋白质可以是酶、结构蛋白质、抗体、抗原、朊病毒、受体、配体、细胞因子、趋化因子、激素等,或其任意组合。
在一些实施方式中,本发明的和在方法中使用的重组或合成多肽不是异肽蛋白或者与肽连接体衍生自的异肽蛋白不同的异肽蛋白。
在一些实施方式中,融合蛋白包括重复结构,例如相同蛋白质可以连接在一起。可选地来看,融合蛋白可以包含相同序列的两个或更多个蛋白质单元。当融合蛋白包括相同序列的两个或更多个蛋白质单元时,这些蛋白质单元可以是连续的,例如仅由将蛋白质单元接合在一起的肽连接体分开,或者它们可以是非连续的或非顺序性的(例如,由具有不同序列的一个或多个蛋白质分开)。在一些优选的实施方式中,融合蛋白包括具有不同序列的至少两种蛋白质,例如具有不同序列的至少2、3、4、5、6种蛋白质。具有不同序列的蛋白质可以以任何适合的顺序排列,这取决于融合蛋白的目的。
在仍进一步实施方式中,蛋白质可以由如本文所限定的两种或更多种肽连接体以及任选地接合所述肽连接体的一个或多个间隔区例如肽间隔区组成。在这方面,蛋白质可以被视为非功能性蛋白质或者被视为连接体蛋白质/肽,如上面所描述的。在这些实施方式中,融合蛋白中的其它蛋白质是不同蛋白质或功能性蛋白质,即包括非肽连接体和间隔区的序列。因而,在一些实施方式中,融合蛋白包括一种或多种蛋白质,其包括如在SEQ IDNO:56-59任一个中陈述的氨基酸序列或者与如在SEQ ID NO:56-59任一个中陈述的氨基酸序列具有至少70%序列同一性的氨基酸序列,其中所述蛋白包括如上面所限定的至少两种肽连接体。例如,非功能性蛋白质可以被用作融合蛋白中的第二蛋白质,即连接第一和第三蛋白质,或者被用作融合蛋白中的第四蛋白质,即连接第三和第五蛋白质,等等。在该代表性实例中,第二和第四蛋白质可以是相同蛋白质或不同蛋白质。因而,在一些实施方式中,融合蛋白中的蛋白质单元可以交替地包括连接体蛋白质,例如功能蛋白质-连接体蛋白质-功能性蛋白质,或者连接体蛋白质-功能性蛋白质-连接体蛋白质等。
在一些实施方式中,上面的蛋白质与和其比较的序列具有至少75、80、85、90、95、96、97、98、99或100%同一性。
“融合蛋白”可以被限定为聚合物,其包括至少两个蛋白质单元,例如2、3、4、5、6、7、8、9或10或更多个蛋白质单元,例如15、20、25或50个蛋白质单元,其通过共价键——优选地如本文所限定的异肽键——连接在一起。蛋白质单元可以被限定为包括至少40个连续氨基酸的分子,优选地其中蛋白质在体内具有功能,例如其中蛋白质能够特异性地与一种或多种生物学组分相互作用,例如其中蛋白质在体内是有活性的。因而,融合蛋白可以被视为巨型结构(megastructure)、大分子、巨型分子(megamolecule)或多蛋白,其包括至少两个蛋白质单元,例如2、3、4、5、6、7、8、9或10或更多个蛋白质单元,例如15、20、25或50个蛋白质单元,其通过共价键——优选地如本文所限定的异肽键——连接在一起。
在本发明的背景下,关于融合蛋白中两种或更多种蛋白质的术语“连接(link,linked,linking)”指的是经由共价键特别是异肽键接合或缀合所述蛋白质,所述键在并入所述蛋白质中的肽连接体(例如形成所述蛋白质的结构域的肽连接体)之间形成。
虽然上文在肽连接体——其反应在一起形成异肽键——方面描述了本发明,但是每个(关联)连接体对可选地可以被视为单一肽连接体,其由反应以形成异肽键(以连接/缀合所述蛋白质)的两个分离的或可分离的部分(标记物,标记物和结合配偶体)形成。因而,从这个角度看,本发明可以被视为两个正交肽连接体用于生产融合蛋白的用途,其中每个肽连接体包括反应以形成异肽键的两个可分离的部分或由其组成,并且其中连接体的每个部分被并入待要连接(缀合)在一起的蛋白质(形成其结构域)。
将显而易见的是本文描述的方法和用途以及从本文描述的方法获得或可获得的融合蛋白具有宽范围的实用性。可选地来看,由本文描述的方法生产的融合蛋白可以在许多工业中被采用。例如,本发明的方法可以用于生产用于疫苗接种的融合蛋白。在这方面,方法可以用于连接蛋白抗原进入链——直接地被注射或被用于装饰病毒样颗粒(VLPS),因为抗原多聚化给出大大加强的免疫应答。
本发明的方法可以用于生产具有增强的酶促性质的融合蛋白,例如底物引导。在这方面,酶通常集合在一起以在细胞内的途径中起作用,并且传统上,其难以在细胞外(体外)将多种酶连接在一起。因而,本发明的方法可以被用于增强多步酶途径的活性,其在一系列工业转换中可以是有用的并且可以用于诊断学。
本发明的融合蛋白关于它们稳定性也可以具有改善的性质,即融合蛋白中蛋白质单元的稳定性相对于它们作为独立蛋白质的稳定性可以增强。具体而言,融合蛋白可以改善蛋白质单元的热稳定性。在这方面,酶在许多过程中是有价值的工具但是不稳定并难以恢复。酶聚合物对温度、pH和有机溶剂具有较强稳定性,并且在工业过程中使用酶聚合物存在增加的期望。但是,在本发明之前,酶聚合物生成通常使用戊二醛非特异性反应并且这将损害或变性许多潜在有用的酶(即降低其活性)。通过根据本发明的异肽键将蛋白质位点特异性连接入链(聚合物)预计增强酶复原,比如在加入至动物饲料诊断工具(diagnostics)中或酶中。在特别优选的实施方式中,酶可以通过环化稳定,如上面所讨论的。
本发明的方法也将在抗体聚合物的生产中发现实用性。在这方面,抗体是最重要类别的药物中的一种并且通常附接至表面使用。但是,在样品中混合的抗原,并且因此在所述样品中所述抗原的捕获在接近表面处是无效的。通过延伸抗体的链,预期捕获效率将被改善。这在循环肿瘤细胞分离中将是尤其有价值的,其在目前是能够进行早期癌症诊断的最有希望的途径之一。再者,不同特异性的抗体可以以任何期望顺序组合。
在仍进一步实施方式中,本发明的方法可以在用于激活细胞信号传导的药物的生产中发现实用性。在这方面,许多激活细胞功能的最有效途径通过蛋白质配体。但是,实际上,蛋白质配体将通常不单独操作而是与其它信号传导分子的特定组合一起操作。因而,本发明的方法使得生成定制的(tailored)融合蛋白(即蛋白质组(protein team)),其可以给出细胞信号传导的最佳激活。这些融合蛋白质(蛋白质组)可以用于控制细胞存活、分裂或分化。
在又进一步实施方式中,本发明的肽连接体,具体地本发明的连接体对可以在生成用于干细胞生长的水凝胶、制备生物材料、利用染料或酶的抗体功能化和通过环化稳定酶中发现实用性。
附图说明
现在将参照附图在下面的非限制性实施例中更详细地描述本发明:
图1示出了使用两个正交肽连接体对——SnoopTag/Snoop Catcher和SpyTag/SpyCatcher——的融合蛋白的固相合成的代表性实例的示意图。
图2示出了RrgA蛋白——SnoopTag和SnoopCatcher肽连接体衍生自其(基于蛋白质数据库ID 2WW8编号)——中的异肽键形成的示意图。
图3示出了利用Coomassie染色的SDS-PAGE凝胶的照片,其表征SnoopTag-MBP与SnoopCatcher的反应,连同具有SnoopTag的反应性Lys(KA)或SnoopCatcher的反应性Asn(NA)的丙氨酸突变的对照。
图4示出了(A)描绘SnoopCatcher与SnoopTag-MBP以1:1或2:1的比进行的SnoopTag反应的时程的图;(B)利用Coomassie染色的SDS-PAGE凝胶的照片,其表征以SnoopCatcher与SnoopTag-MBP的2:1的比进行的SnoopTag-MBP与SnoopCatcher的反应;(C)描绘SnoopCatcher与SnoopTag-MBP以1:1、2:1或4:1的比进行的SnoopTag反应的时程的曲线图;和(D)利用Coomassie染色的SDS-PAGE凝胶的照片,其表征以SnoopCatcher与SnoopTag-MBP的4:1的比进行的SnoopTag-MBP与SnoopCatcher的反应。
图5示出了(A)描绘SnoopTag-MBP与SnoopCatcher之间的异肽键形成的pH依赖性的图;和(B)描绘SnoopTag-MBP与SnoopCatcher之间的异肽键形成的温度依赖性的图。
图6示出了(A)描绘SnoopTag-MBP与SnoopCatcher之间的异肽键形成对盐、还原剂和清洁剂的依赖性的柱状图;和(B)描绘SnoopTag-MBP与SnoopCatcher之间的异肽键形成的TMAO依赖性的曲线图。
图7示出了利用Coomassie染色的SDS-PAGE凝胶的照片,其表征SnoopTag/SnoopCatcher和SpyTag/SpyCatcher正交反应性。
图8示出了(A)利用Coomassie染色的SDS-PAGE凝胶的照片,其表征PsCsTag/PsCsCatcher、SnoopTag/SnoopCatcher和SpyTag/SpyCatcher正交反应性;和(B)利用Coomassie染色的SDS-PAGE凝胶的照片,其表征RrgATag/RrgACatcher、SnoopTag/SnoopCatcher和SpyTag/SpyCatcher正交反应性。
图9示出了(A)利用Coomassie染色的SDS-PAGE凝胶的照片,其分析固相融合蛋白合成。泳道1-3示出了分离的MBPx-SpyCatcher、SnoopTag-Affi-SpyTag和SpyCatcher-SnoopCatcher。MBPx-SpyCatcher结合至直链淀粉树脂并且实施SnoopTag-亲合体-SpyTag和SpyCatcher-SnoopCatcher的逐步反应。在每个阶段之后,一个等分试样利用麦芽糖从树脂洗脱(泳道4-13)。在不进行任何进一步纯化的情况下分析样品;和(B)利用Coomassie染色的SDS-PAGE凝胶的照片,其分析固相融合蛋白合成。泳道1-3示出了分离的生物素-SpyCatcher、SnoopTag-Affi-SpyTag和SpyCatcher-SnoopCatcher。生物素-SpyCatcher结合至链霉亲和素琼脂糖并且实施SnoopTag-亲合体-SpyTag和SpyCatcher-SnoopCatcher的逐步反应。在每个阶段之后,一个等分试样利用生物素从琼脂糖洗脱(泳道4-13)。在不进行任何进一步纯化的情况下分析样品。
图10示出了(A)描绘测试十聚体融合蛋白生物素-SpyCatcher:(SnoopTag-Affi-SpyTag:SpyCatcher-SnoopCatcher)
图11示出了(A)利用Coomassie染色的SDS-PAGE凝胶的照片,其分析十聚体融合蛋白
MBPx-SpyCatcher:(SnoopTag-Affi-SpyTag:SpyCatcher-SnoopCatcher)
图12示出了利用Coomassie染色的SDS-PAGE凝胶的照片,其分析固相融合蛋白合成。泳道1-3示出了分离的MBPx-SpyCatcher、SnoopTag-mEGFP-SpyTag和SpyCatcher-SnoopCatcher。MBPx-SpyCatcher结合至直链淀粉树脂并且实施SnoopTag-mEGFP-SpyTag和SpyCatcher-SnoopCatcher的逐步反应。在每个阶段之后,一个等分试样利用麦芽糖从树脂洗脱(泳道4-9)。在不进行任何进一步纯化的情况下分析样品;和(B)利用Coomassie染色的SDS-PAGE凝胶的照片,其分析固相融合蛋白合成。泳道1-3示出了分离的MBPx-SpyCatcher、SnoopTag-SpyTag-Affi3和SpyCatcher-SnoopCatcher。如在(A)中一样实施逐步反应并进行分析。
图13示出了可以使用本发明的方法获得的两个简单的分支融合蛋白结构的卡通。
图14示出了利用Coomassie染色的SDS-PAGE凝胶的照片,其将融合至与RrgACatcher反应的MBP的突变的RrgATag(RrgATag2.0,SEQ ID NO:111)的活性和融合至与RrgACatcher反应的MBP的未突变的RrgATag(SEQ ID NO:9)进行比较。
图15示出了利用Coomassie染色的SDS-PAGE凝胶的照片,其表征与RrgACatcher反应的不同RrgATag肽连接体突变体(融合至SUMO)。
图16示出了RrgATag2与RrgACatcher以1:1、2:1或4:1的比进行RrgATag2反应的时程的曲线图。插图曲线图示出了在反应的前8分钟内的反应。
图17示出了利用Coomassie染色的SDS-PAGE凝胶的照片,其表征RrgACatcher与SnoopTag、SnoopCatcher、SpyTag、SpyCatcher和RrgATag2的反应性。
图18示出了利用Coomassie染色的SDS-PAGE凝胶的照片,其表征RrgATag2/RrgACatcher、SnoopTag/SnoopCatcher和SpyTag/SpyCatcher正交反应性。
具体实施方式
实施例
实施例1-设计和合成形成自发异肽键的关联肽连接体对
RrgA(SEQ ID NO:21)是来自革兰氏阳性菌肺炎链球菌的黏附素,其可以引起人的败血症、肺炎和脑膜炎。自发异肽键在RrgA的D4免疫球蛋白样结构域中残基Lys742与Asn854之间形成(图2)。本发明人将D4结构域分裂为一对称为SnoopTag(残基734-748,SEQID NO:1)的肽连接体和命名为SnoopCatcher(残基749-860,SEQ ID NO:2)的蛋白质。
但是,本发明人发现将两种突变引入SnoopCatcher肽连接体从而形成在本发明中使用的稳定肽连接体对是必要的。在这方面,本发明人在SnoopCatcher中引入了G842T突变以稳定β-链和D848G以稳定接近反应位点的发夹弯。
SnoopTag肽表达为融合至麦芽糖结合蛋白(MBP)和His-标记物(SEQ ID NO:50)的重组多肽。SnoopCatcher表达为融合至His-标记物(SEQ ID NO:39)的重组多肽。SnoopTag-MBP和SnoopCatcher在大肠杆菌的胞质溶胶中有效地表达为可溶性蛋白质并且通过Ni-NTA亲和色谱法纯化。SnoopTag-MBP和SnoopCatcher,简单地在混合之后,形成对于在SDS中煮沸稳定的复合体(图3)。在SnoopTag(SnoopTag KA-MBP)的推定的反应性Lys742和SnoopCatcher(SnoopCatcherNA)的推定的反应性Asn854中的突变废除反应(图3)。电喷雾电离质谱支持来自在SnoopCatcher与合成SnoopTag肽之间异肽键形成的NH
利用1:1的SnoopCatcher与SnoopTag-MBP,反应达到~80%产率。但是,利用两倍过量的SnoopCatcher,SnoopTag-MBP定量反应(图4A和B)。与过量的SnoopTag-MBP类似,SnoopCatcher约100%消耗(图4C和D)。
本发明人进一步确立了反应从pH 6-9有效地进行,但是在pH 5下进行缓慢(图5A)。反应在室温下最快但是也在4℃和37℃下进行(图5B)。半胱氨酸不存在于SnoopTag和SnoopCatcher,因此如预期的,反应对于二硫苏糖醇(DTT)是不敏感的。不需要特定的缓冲液组分,其中反应在PBS中以及在清洁剂Triton X-100和吐温20,或高盐的存在下进行(图6A)。化学分子伴侣三甲胺N-氧化物(TMAO)给出了适度的增强(图6B)。
酰胺键的自发水解在中性条件下通常需要数年,但是我们测试了在该特定的蛋白质环境中水解是否加速。我们通过与过量的可选的SnoopTag连接的蛋白质或与氨竞争寻找SnoopTag-MBP/SnoopCatcher相互作用的裂解(cleavage),但是我们没有观察到可逆性。
通过在与SnoopTag/SnoopCatcher肽连接体对不同的方向中分裂D4免疫球蛋白样结构域,从RrgA蛋白质开发进一步肽连接体对。该肽连接体对被称为RrgATag(SEQ ID NO:9)和RrgACatcher(SEQ ID NO:10)。也基于PsC蛋白质(SEQ ID NO:31)开发肽连接体对,其被称为PsCsTag(SEQ ID NO:5)和PsCsCatcher(SEQ ID NO:6)。
每个肽连接体对能够在与上面讨论的SnoopTag/SnoopCatcher对类似的多种条件下自发地形成异肽键。
实施例2-调查肽连接体对的交叉反应性
先前已经研发了自发地反应以形成异肽键的肽标记物和结合配偶体SpyTag和SpyCatcher(SEQ ID NO:13和14)(WO2011/098772)。
SnoopTag具有反应性Lys,而SpyTag具有反应性Asp,因此本发明人假设SnoopTag/SnoopCatcher和SpyTag/SpyCatcher对将是完全正交的,即将不显示交叉反应性。在以各种组合混合肽连接体后,发现每个关联肽连接体对有效地反应,但是在对之间没有发现交叉反应痕迹——这甚至在过夜培育之后(图7)。该结果确认了SnoopTag/SnoopCatcher对正交于SpyTag/SpyCatcher。
本发明人也测试了PsCsTag/PsCsCatcher对和RrgATag/RrgACatcher对与SnoopTag/SnoopCatcher和SpyTag/SpyCatcher对的交叉反应性。如图8A和8B中示出的,在“PsCs”对与“Spy”对或“Snoop”对之间没有发现显著的交叉反应性。类似地,在“RrgA”对与“Spy”对或“Snoop”对之间没有发现显著的交叉反应性。因此,每个肽连接体对正交于其它肽连接体对。
实施例3-使用两个正交肽连接体对合成融合蛋白
本发明人使用“Spy”和“Snoop”肽连接体对证明了这类正交肽连接体对可以被成功地用于合成融合蛋白。
大肠杆菌MBP与直链淀粉树脂的相互作用广泛地用于亲和纯化中:MBP融合通常折叠和很好地表达并且示出了低的非特异性树脂结合。MBP示出了使用麦芽糖的选择性温和洗脱,这避免了对于蛋白酶去除的需要。野生型MBP对于麦芽糖的亲和力为1.2μM,其对于蛋白质纯化是实用的但是对于在融合蛋白合成中的多轮洗涤和链延伸是不足的。因此,本发明人研发了突变的MBP以改善其麦芽糖结合稳定性。首先,本发明人通过引入突变A312V和I317V并缺失残基172、173、175和176修饰了多肽序列。其次,MBP突变体(SEQ ID NO:70)被串联地连接以生成MBPx(His
对于起始链构建,本发明人并入了亲合体(affibody)——一种在大肠杆菌胞质溶胶中有效表达的非免疫球蛋白支架。利用SnoopTagand在其N末端并利用SpyTag在其C末端将亲合体连接至HER2(SnoopTag-Affi-SpyTag,SEQ ID NO:72)。使用通过螺旋形间隔区连接至SnoopCatcher的SpyCatcher桥接亲合体单元(SpyCatcher-SnoopCatcher(SEQ ID NO:56),其也在大肠杆菌中有效地表达为可溶性蛋白质)(图1)。由于每种连接是共价的,因此可以链合成,然后加入麦芽糖以从树脂洗脱并且然后煮沸上清液,之后利用Coomassie染色的SDS-PAGE,以跟踪融合蛋白的延伸(图9)。MBPx-SpyCatcher(结合至直链淀粉树脂)与SnoopTag-Affi-SpyTag定量反应(图9A,泳道5)。该构建体然后与SpyCatcher-SnoopCatcher定量反应(图9A,泳道6)。SnoopTag-Affi-SpyTag和SpyCatcher-SnoopCatcher的顺序添加能够使得有效的链生长,延伸至10单元长的产物(十聚体,图9A,泳道13)。
为了证明利用不同种类的固相附接的固相延伸,生成修饰的SpyCatcher蛋白质AviTag-SpyCatcher以允许位点特异性N末端生物素化。在连接生物素化的SpyCatcher至链霉亲和素包被的珠之后,融合蛋白链以相同的方式被装配至十聚体的长度并且利用游离生物素洗脱(图9B)。
为了证实装配的十聚体,进行电喷雾电离质谱,其显示了在观察到的和预期的质量之间的良好一致性(图10A)。虽然质谱法给出了同一性的良好指示,但是SDS-PAGE对于评估纯度更好的多,这是因为较低分子量副产物更有效地电离。亲合体通常是单体的,显示很少的自缔合,因而进行尺寸排阻色谱法(SEC)分析形成的十聚体是否聚集。SEC给出了一个主峰,与利用球状蛋白质标准物校准的十聚体的预期单体质量一致,这表明在这些条件下存在最低的十聚体自缔合(图10B)。
为了评估热稳定性,将十聚体在一系列温度下短暂地加热并且甚至在70℃下保持大部分可溶(图11A)。也测试十聚体的储存完整性并且在1或4天之后观察到很少的降解和很少的溶解度损失。
从将AffiHER2起始并入链延伸,显示了可以使用正交异肽键形成有效地并入其它蛋白质单元(图12)。在这方面,生成荧光蛋白融合蛋白链(图12A)。也通过将针对HER2的串联连接的亲合体与在N末端处的两个标记物接合(SnoopTag-SpyTag-Affi-Affi-Affi)(图12B),产生瓶刷形融合蛋白聚合物。
总之,本发明人已经研发了通过在肽连接体之间的自发异肽键形成来合成融合蛋白的模块式途径。根据本发明的方法生成的融合蛋白通过不可逆的酰胺键连接,因此随着时间是稳定的(如果使其免受蛋白酶)并且允许通过SDS-PAGE简单分析。起始、延伸和释放步骤使用温和条件、独立于氧化还原状态,因此应当适用于宽范围的蛋白质。利用链生长的仅单一途径,产物被分子上限定,这有利于再现性和功能的精确调谐。再者,亚单元不需要以N-至C-方位连接,如利用上面描述的瓶刷形聚合物结构体示出的。不需要模块的化学修饰,这避免了耗时的和难于控制的生物缀合步骤,因此该方法可面向能够表达重组蛋白的任何实验室。自发异肽键形成具有如下优势:在具有低固有反应性——胺与羧酸或甲酰胺——的两个官能团之间的简单反应途径,因此存在很少的副反应。
虽然该实施例证明了使用“Spy”和“Snoop”肽连接体对的融合蛋白合成,但是将显而易见的是根据本发明的任何正交肽连接体对可以用于本发明的方法中,并且如上面所讨论的,使用多于两个正交肽连接体对对于合成具有复杂结构例如分支或环状结构的融合蛋白可以是特别有利的。
实施例4-基于RrgA蛋白质设计和合成改善的关联肽连接体对
在生产相对于RrgATag/RrgACatcher肽连接体对具有改善活性的肽连接体对的目标下,使在实施例1中描述的RrgATag经历多种修饰。
本发明人合成了突变体RrgATag肽连接体,其包括被称为RrgATag2.0(参见下面的表2)的在位置11处的置换——天冬氨酸至甘氨酸(D11G)。RrgATag2.0(SEQ ID NO:111)和RrgATag(SEQ ID NO:9)被表达为连接至麦芽糖结合蛋白(MBP)的融合蛋白并且比较它们与RrgACatcher的反应性。反应在磷酸盐缓冲盐水(PBS)中在pH 7.4和室温下进行6小时。在每个反应中使用10μM的每种蛋白质。
图14示出了当与RrgATag比较时,RrgATag2.0大大增加了与RrgACatcher的反应性。
本发明人合成了包括相对于RrgATag(SEQ ID NO:9)的多种突变的进一步八种肽连接体,包括延伸、截短、置换和其组合。表2示出了突变体RrgATag肽连接体的序列,其中置换和延伸是加下划线的。
表2
突变的RrgATag肽连接体被表达为连接至SUMO(小泛素修饰物)蛋白的融合蛋白并且测试该融合蛋白与RrgACatcher(SEQ ID NO:10)的反应性。反应在磷酸盐缓冲盐水(PBS)中在pH 7.4和室温下进行30分钟。在每个反应中使用10μM的每种蛋白质。图15示出了仅四种修饰的RrgATag肽连接体显示与RrgACatcher的可观察到的反应性:RrgATag 2.0、RrgATag2.3、RrgATag2和RrgATag2.7。但是,RrgATag2显示了相对于RrgATag2.0的活性的显著增加,如上面所讨论的,RrgATag2.0具有相对于RrgATag的增加的活性。因而,与RrgATag相比,RrgATag2具有与RrgACatcher的显著改善的反应性。
RrgATag2(以与SUMO的融合蛋白的形式)和RrgACatcher之间的反应速度在图16中示出并且表明了过量的RrgATag2增加反应速度。但是,在所有浓度的RrgATag2下反应接近完成,即100%消耗RrgACatcher。
虽然不希望受到理论束缚,但是假设RrgATag2的显著改善的活性是相对于RrgATag的修饰/突变的组合的结果。在这方面,基于天然RrgA序列的C末端延伸被认为形成与RrgACatcher肽连接体的有利的相互作用。而且,假设RrgATag2肽连接体中间的D至G突变(即侧链尺寸的减小)使肽中的发夹弯稳定(如在存在于全长结构域中的结晶结构中可见的)。
实施例5-调查改善的RrgATag2肽连接体的交叉反应性
测试RrgATag2/RrgACatcher肽连接体对针对SnoopTag/SnoopCatcher和SpyTag/SpyCatcher肽连接体对的交叉反应性,如上面的实施例3中所描述的。RrgATag2肽连接体表达为连接至SUMO的融合蛋白,如在实施例4中描述的。
图17示出了在RrgACatcher肽连接体与SpyTag或SnoopTag肽连接体之间没有发现显著的交叉反应性。图18示出在RrgATag2肽连接体与SpyCatcher或SnoopCatcher肽连接体之间没有发现显著交叉反应性。因而,每个肽连接体对正交于其它肽连接体对。
材料和方法
克隆
KOD热启动DNA聚合酶(Roche)被用于进行所有PCR和位点定向诱变。Gibson
pET28a SpyTag-MBP(Addgene质粒ID 35050)、谷胱甘肽-S-转移酶-BirA和pDEST14-SpyCatcher(基因库JQ478411,Addgene质粒ID 35044)已经在B.Zakeri et al.,2012(Proc NatlAcad Sci U SA 109,E690-697)中描述。
pET28a SnoopCatcher通过来自肺炎链球菌黏附素RrgA(基于蛋白质数据库ID2WW8编号)的残基749-860的DNAWorks引物介导的装配生成,利用HindIII和NdeI消化并且亚克隆入pET28a。为了优化与SnoopTag的反应,通过QuikChange在该构建体中进行具有5′-GTGCCGCAGGATATTCCGGCTACATATGAATTTACCAACG(SEQ ID NO:73)的G842T突变,和具有5′-GCTACATATGAATTTACCAACGGTAAACATTATATCACCAATGAACC(SEQ ID NO:74)的D848G突变以及它们的反向互补序列。SnoopCatcher为132个残基长度(假设fMET裂解)并具有N末端凝血酶切割位点和His
pET28a SnoopTag-MBP以两个步骤生成。首先,使用5′-GGTAGTGGTGAAAGTGGTAAAATCGAAGAAG(SEQ ID NO:76)、5′-AAACTGGGCGATATTGAATTTATTAAAGTGAACAAAAACGATAAAGGTAGTGGTGAA AGTGGTAAAATCGAAGAAG(SEQ ID NO:77)、5′-TCCCATATGGCTGCCGCGCG(SEQ ID NO:78)和5′-TTTATCGTTTTTGTTCACTTTAATAAATTCAATATCGCCCAGTTTTCCCATATGGCTGCC GCGCG(SEQ ID NO:79)将基于RrgA的D4结构域的N末端β-链的反应性肽(残基734-748)通过位点定向的、连接酶独立的诱变(SLIM)PCR(Chiu et al.,2004)克隆入pET28a-SpyTag-MBP。使用QuikChange利用5'-GAATTTATTAAAGTGAACAAAGGTAGTGGTGAAAGTGGTAAAATCG(SEQ ID NO:80)和其反向互补序列去除该肽的3个C末端残基。使用5′-GGGCGATATTGAATTTATTGCAGTGAACAAAGGTAGTGG(SEQ ID NO:81)和其反向互补序列通过在pET28a SnoopTag-MBP上K742至A的QuikChange生成pET28aSnoopTag KA-MBP——SnoopTag的不反应性版本。
通过在MBP的C末端处融合SpyCatcher与Gly/Ser间隔区,通过重叠延伸PCR生成pET28a MBP-SpyCatcher。使用正向引物5′-GTTCGGGCGGTAGTGGTGCCATGGTTGATACCTTATCAGGTTTATCAAGTGAGCAAG(SEQ ID NO:82)和反向引物5′-TACTAAGCTTCTATTAAATATGAGCGTCACCTTTAGTTGCTTTGCCATTTACAG(SEQ IDNO:83)由pDEST14-SpyCatcher扩增SpyCatcher。正向引物5′-ATCTCATATGGGCAGCAGCCATCATCATCATCATCAC(SEQ ID NO:84)和反向引物5′-GTATCAACCATGGCACCACTACCGCCCGAACCCGAGCTCGAATTAGTCTGCG(SEQ ID NO:85)被用于由pET28aSpyTag-MBP扩增MBP。将两种得到的PCR产物混合并且使用SpyCatcher正向引物和MBP反向引物再次扩增,利用NdeI和HindIII消化,并且亚克隆入pET21。为了增加MBP-SpyCatcher对直链淀粉的亲和力,我们首先使用正向引物5′-GTCTTACGAGGAAGAGTTGGTGAAAGATCCACGTGTGGCCGCCACTATGGAAAAC GC(SEQ ID NO:86)和其反向互补序列通过QuikChange在MBP中进行A312V和I317V突变。使用QuikChange利用5'-GGGTTATGCGTTCAAGTATGGCGACATTAAAGACGTGGGCG(SEQ ID NO:87)和其反向互补序列从MBP缺失残基172、173、175和176。我们然后通过QuikChange使用5'-CACCATCACCATCACGATTACGATAGTGCTACCCATATTAAATTCTC(SEQ ID NO:88)和其反向互补序列缩短了SpyCatcher的N末端。为了更进一步降低与直链淀粉树脂的解离,生成该突变体MBP的串联连接以得到MBPx-SpyCatcher(N末端His
pET28a SpyCatcher-SnoopCatcher以几个步骤产生。最初,SpyCatcher与Gly/Ser间隔区在SnoopCatcher的N末端处融合,然后将Gly/Ser间隔区替换为α-螺旋形间隔区(序列PANLKALEAQKQKEQRQAAEELANAKKLKEQLEK,SEQ ID NO:93)。正向引物5'-CTTTAAGAAGGAGATATACATATGTCGTACTACCATCACCATC(SEQ ID NO:94)和反向引物5′-CCGCTGCTTCCGGATCCAATATGAGCGTCACCTTTAGTTG(SEQ ID NO:95)被用于由pDEST14-SpyCatcher扩增SpyCatcher部分。使用正向引物5'-CATATTGGATCCGGAAGCAGCGGCCTGGTGCCGCGCGGATCCCATATGAAGCCGCTGC(SEQ ID NO:96)和反向引物5′-GTGGTGGTGGTGGTGCTCGAGTTATTATTTCGGCGGTATCGGTTC(SEQID NO:97)由pET28a SnoopCatcher克隆SnoopCatcher部分。在SpyCatcher和SnoopCatcher融合之后,使用正向引物5'-CTAAAGGTGACGCTCATATTGGATCCCCCGCCAACCTGAAGGCCCTGGAGGCCCAG AAGCAGAAGGAGCAGAGACAGGCCGCCGAGGAGC(SEQ ID NO:98)和反向引物5′-CACGGCACCACGCAGCGGCTTCATATGGGATCCCTTCTCCAGCTGCTCCTTCAGCT TCTTGGCGTTGGCCAGCTCCTCGGCGGCCTGTC(SEQ ID NO:99)将Gly/Ser间隔区替换为稳定的α-螺旋形连接体。经由QuikChange使用正向引物5'-CACCATCACCATCACGATTACGATAGTGCTACCCATATTAAATTCTC(SEQ ID NO:100)和其反向互补序列从SpyCatcher的N末端缺失35个残基。
通过Gibson装配使用正向引物5'-GTGAACAAAGGCAGTGGTGAGTCGGGATCCGGAGCTAGCATGACTGGTGG(SEQ ID NO:101)和反向引物5'CATCACGATGTGGGCACCGGAACCTTCCCCGGATCCCTCGAGGCCTTTCGG(SEQ IDNO:102)由pET28a-KTag-AffiHer2-SpyTag生成pET28a SnoopTag-Affi-SpyTag(针对HER2-间隔区-SpyTag的N末端His
使用5’-CTACCCAACCTAAACGGGGTACAAGTAAAGGCTTTCATAGACTCGCTAAGGGATGACCCAAGCCAAAGCGC(SEQ ID NO:103)和5’-GTTGAATATCTCCCAAGTAGCCCACCCTAGCTCCTTGTTGAACTTGTTGTCTACTTC TTTGTTGAATTTGTTGTCCACGCC(SEQ ID NO:104)通过反向PCR由pET28aSnoopTag-AffiHer2-SpyTag生成pET28a SnoopTag-AffiTaq-SpyTag——一种针对Taq DNA聚合酶的亲合体。
通过在pET28a SnoopTag-Affi-SpyTag中的BamHI位点处置换mEGFP并且通过PCR克隆pET28a SnoopTag-mEGFP-SpyTag以延伸间隔区。通过由Gly/Ser间隔区连接的AffiHER2的串联拷贝的PCR装配生成pET28a SnoopTag-SpyTag-Affi3。
通过由pDEST14-SpyCatcher的SLIM PCR使用5′-GATTACGACATCCCAACGACCGAAAACCTG(SEQ ID NO:105)、5′-GCCTGAACGATATTTTTGAAGCGCAGAAAATTGAATGGCATGAAGGCGATTACGACAT CCCAACGACCGAAAACCTG(SEQ ID NO:106)、5′-GTGATGGTGATGGTGATGGTAGTACGACATATG(SEQ ID NO:107)和5′-TGCCATTCAATTTTCTGCGCTTCAAAAATATCGTTCAGGCCGCTGCCGTGATGGTGAT GGTGATGGTAGTACGACATATG(SEQ ID NO:108)克隆AviTag-SpyCatcher,其在N末端处包含用于位点特异性生物素化的肽标记物。
所有突变和构建体通过测序验证。
蛋白质表达和纯化
蛋白质在大肠杆菌BL21 DE3 RIPL(Agilent)中表达。在包含0.5mg/mL卡那霉素——对于pET28a载体——和0.1mg/mL氨苄青霉素——对于pET21——的LB中在37℃下使菌落生长过夜。过夜培养物在包含0.8%葡萄糖的LB中利用适合的抗生素1:100稀释,在37℃、200rpm下生长至OD
对于MBPx-SpyCatcher的纯化,在从Ni-NTA洗脱之后,缓冲液通过透析更换为4℃下pH 8.0的20mM Tris HCl,装载至季铵(quaternary)高性能(Q-HP)树脂(GE Healthcare)上并且通过10倍柱体积(即10mL)、0–0.15M NaCl的线性梯度以1mL/min的流速进行洗脱。额外的洗脱步骤利用0.15–0.35M NaCl的线性梯度以1.5mL/min的流速进行并收集0.5mL馏分。收集的馏分透析入TBS,使用Vivaspin离心浓缩机5kDa截止(GE Healthcare)浓缩并且在-80℃下储存。
SnoopTag-Affi-SpyTag在4℃下pH 5.8的20mM 2-(N-吗啉基)乙磺酸(MES)中透析并且装载至磺丙基高性能(SP-HP)树脂(GE Healthcare)上。通过应用0.2–0.5M NaCl的线性梯度洗脱蛋白质并收集1mL馏分。洗脱的馏分使用Vivaspin离心浓缩机5kDa截止(GEHealthcare)浓缩至1-2mg/mL,透析入pH 8.0的TBS并且在-80℃下储存。
对于SpyCatcher-SnoopCatcher的纯化,在从Ni-NTA洗脱之后,通过透析入4℃下pH8.0的20mM Tris HCl更换缓冲液,装载至季铵高性能(Q-HP)树脂上并且利用0.2–0.5MNaCl的线性梯度进行洗脱。收集的馏分被透析入TBS,使用Vivaspin离心浓缩机5kDa截止浓缩并且在-80℃下储存。
纯化的AviTag-SpyCatcher在包含5mM MgCl
SDS-PAGE
在规定百分比聚丙烯酰胺凝胶上使用XCell SureLock凝胶容器(LifeTechnologies)在200V下进行SDS-PAGE。凝胶利用Instant Blue Coomassie染色剂(TripleRed Ltd.)进行染色,并且使用Gel Doc XR成像器和Image Lab 3.0软件(Bio-Rad)光密度地(densitometrically)分析条带。所有运行缓冲液为Tris-甘氨酸,除了图9A之外,其为Tris-醋酸盐以改善高M
异肽键重构
为了评估SnoopTag和SnoopCatcher之间共价键的形成,蛋白质每种在10μM最终浓度下在包含1.5M三甲胺N-氧化物(TMAO;Sigma-Aldrich)的pH 8.0的TBS中进行混合。TMAO充当化学分子伴侣。通过加入6×SDS加样缓冲液(0.23M Tris-HCl,pH 6.8,24%v/v甘油,120μM溴酚蓝,0.23M SDS)停止反应。随后在16%聚丙烯酰胺凝胶上进行SDS-PAGE之前,使用Bio-Rad C1000热循环仪在95℃下加热样品持续5min。
为了测试正交性,在SDS-PAGE之前,将10μM SnoopTag-MBP和10μM SnoopCatcher或SpyCatcher在pH 8.0的TBS中在25℃下培育1hr。同样地,如上面培育10μMSpyTag-MBP和10μM SnoopCatcher或SpyCatcher。
对于其它肽连接体对,在SDS-PAGE之前,将10μM RrgATag-MBP或10μMPsCsTag-MBP和10μM SnoopCatcher、SpyCatcher、SnoopTag-MBP或SpyTag-MBP在pH 7.4的TBS中在25℃下培育24hr。
为了评估pH依赖性,每种蛋白质在琥珀酸-磷酸盐-甘氨酸缓冲液(12.5mM琥珀酸、43.75mM NaH
为了测定温度的作用,在规定温度下在包含1.5M TMAO的pH 8.0的磷酸盐缓冲盐水(PBS,10mM Na
为了调查缓冲液组成的敏感度,在pH 8.0的PBS、pH 8.0的TBS或pH 8.0的TBS——包含1%Triton X-100(w/v)、1%吐温20(v/v)、10mM乙二胺四乙酸(EDTA)、10mM MgCl
通过在规定浓度下在包含1.5M TMAO的pH 8.0的TBS中使SnoopTag-MBP和SnoopCatcher反应并且在25℃下培育持续各种时间来测定反应速率。如上面描述的,在SDS-PAGE之前,在SDS加样缓冲液中停止反应。%重构被计算为100×共价加合物的带强度/SnoopTag-MBP、SnoopCatcher和共价加合物的带强度的总和。
为了测试使用竞争标记物的可逆性,10μM SnoopCatcher与15μM SnoopTag-MBP一起培育6hr并且然后加入在130μM的最终浓度下的SnoopTag-Affi-SpyTag持续16hr,都在25℃下。为了测试使用氨的可逆性,10μM SnoopCatcher与10μM SnoopTag-MBP在包含1.5MTMAO的pH 8.0的TBS中培育2hr,并且然后加入pH 8.0的TBS或pH 9.0的NH
质谱法
20μM SnoopTag-MBP和20μM SnoopCatcher在pH 7.4的PBS中在25℃下培育2hr。使用Micromass LCT飞行时间电喷雾电离MS(Micromass)进行质谱法分析并且使用最大熵算法和V4.00.00软件(Waters)将m/z谱转化为分子质量分布。ExPASy ProtParam被用于基于蛋白质的氨基酸序列预测分子质量,其中N末端fMET被裂解并减去用于异肽键形成的17.0Da。非酶促葡糖酸化常常从大肠杆菌中His标记的蛋白质的表达观察到并且增加178Da。同样地,大肠杆菌表达的蛋白质也经历一些程度的乙酰化。
使用具有10kDa截止的Amicon Ultra 0.5mL离心过滤器(Millipore),将十聚体浓缩至15μM和缓冲液更换为200mM醋酸铵。在第一代Synapt高分辨质谱四极飞行时间质谱仪(Waters)上进行测量,使用10mg/mL碘化铯在250mM醋酸铵中校准。通过纳升(nano)电喷雾电离经由在室内制备的镀金毛细管递送样品的2.5μL等分试样。仪器参数如下:源压力6.0mbar、毛细管电压1.20kV、锥电压150V、陷阱能30V、转移能10V、偏压5V和陷阱压力0.0163mbar。质谱是平滑的和峰居中的,并且使用MassLynx v4.1(Waters)分配(assign)质量。
融合蛋白的固相合成
40μL的浆体直链淀粉树脂(NEB)被施加至1mL poly-prep柱(Bio-Rad),利用1mLMilliQ水清洗并且利用1mLpH 8.0的TBS平衡。将最终体积为80μL的在pH 8.0的TBS中的320pmol串联MBPx-SpyCatcher加入至树脂并且在25℃下培育1hr,同时在恒温混匀仪(ThermoMixer comfort)(Eppendorf)上700rpm振荡。未反应的蛋白质通过重力流从柱移出并且利用1mL洗涤缓冲液(含有500mM NaCl的50mM pH 8.0的Tris HCl)洗涤树脂。将最终体积为80μL的在pH 8.0的TBS中的3nmol SnoopTag-Affi-SpyTag加入至树脂并且在25℃下培育1hr,同时700rpm振荡。未反应的SnoopTag-Affi-SpyTag通过重力流从柱移出并且利用1mL洗涤缓冲液洗涤树脂。将含有1.5M TMAO的pH 8.0的TBS中的4nmol SpyCatcher-SnoopCatcher加入至树脂并且在25℃下培育2hr,同时700rpm振荡。未反应的SpyCatcher-SnoopCatcher通过重力流从柱移出并且利用1mL洗涤缓冲液洗涤树脂。通过连续添加SnoopTag-Affi-SpyTag和SpyCatcher-SnoopCatcher根据上面描述的条件产生链。在树脂洗涤之后,通过添加包含50mM D-麦芽糖(Sigma)的pH 8.0的40μLTBS并且在25℃下培育10min同时700rpm振荡洗脱链。通过在17,000g下在1.5mL微量离心管中离心柱持续10s收集链。包含SnoopTag-mEGFP-SpyTag和SnoopTag-SpyTag-Affi3的链以完全相同的方式合成。
对于在每个步骤之后的SDS-PAGE测试,样品如前面描述的进行洗脱,与6×SDS加样缓冲液混合,并且在95℃下加热5min,然后SDS-PAGE。
对于生物素化的SpyCatcher基装配,将40μL浆体单体抗生物素蛋白树脂(ThermoScientific)施加至1mLpoly-prep柱,如上面所述的进行清洗和平衡。将最终体积为80μL的在pH 8.0的TBS中的4μM生物素化的SpyCatcher加入至树脂并且25℃下培育1hr,同时700rpm振荡。未反应的生物素化的SpyCatcher通过重力流从柱移出,利用1mL洗涤缓冲液洗涤树脂,并且如上面所描述进行SnoopTag-Affi-SpyTag和SpyCatcher-SnoopCatcher的连续添加。在树脂洗涤之后,通过将在pH 8.0的TBS中的40μL1mM D-生物素施加至柱上并且在25℃下培育4hr同时700rpm振荡洗脱链。如前面所指出的收集链并且通过在16%和8%Tris-甘氨酸凝胶上进行SDS-PAGE来分析。
凝胶过滤色谱法
通过在Superdex 200GL 10/300柱(24mL床体积)(GE Healthcare)上进行凝胶过滤色谱法分析十聚体链。通过使用凝胶过滤标准物(甲状腺球蛋白670kDa,IgG 158kDa,卵清蛋白44kDa,肌红蛋白17kDa,和维生素B121.35 kDa)(Bio-Rad)校准柱。以0.4mL/min在含有500mM NaCl的pH 8.0的50mM Tris HCl中洗脱样品,在
链的稳定性测试
对于温度稳定性测试,最终体积为30μL的在pH 8.0的150mM醋酸铵中的3μM下的十聚体链在25、37、50、60或70℃下培育3min并且在3℃/s下在Bio-Rad C1000热循环仪中冷却至10℃。样品然后在17,000g、4℃下旋转30min以移出聚集物并且通过在8%Tris-甘氨酸凝胶上利用Coomassie染色进行SDS-PAGE分析上清液。对于时间依赖性稳定性测试,最终体积为30μL的在包含0.1%叠氮化钠、1mM苯甲基磺酰氟(PMSF)、1mM EDTA和无EDTA(EDTA-free)的混合的蛋白酶抑制剂(Roche)的pH 8.0的150mM醋酸钠中的3μM下的十聚体链在25℃下培育1或4天。在每个时间点下,样品在17,000g、4℃下旋转30min并且通过在8%Tris-甘氨酸凝胶上利用Coomassie染色进行SDS-PAGE分析上清液。
- 融合蛋白合成的方法和产品
- 融合蛋白合成的方法和产品