基于傅里叶变换的轻量化多模态知识图谱表示学习方法
文献发布时间:2024-04-18 19:58:26
技术领域
本发明属于知识图谱技术领域,尤其涉及一种基于傅里叶变换的轻量化多模态知识图谱表示学习方法。
背景技术
知识图谱是一种基于语义关系构成的大规模语义网络,其节点为实体和概念,边为概念之间的语义关系。知识图谱通常表示为三元组形式(e
以往的工作为了提升信息的抽取能力和融合分析能力,更好地处理来自各个模态的信息,往往引入复杂模型结构,如基于transformer的视觉处理模型ViT以及语言处理模型BERT等。这些复杂模型多采用切割叠加的方式来处理输入,尽管可以在某种程度上增强表示学习的效果,但这一处理方式也会增加模型的整体参数量,使得模型的计算复杂度和空间占用大幅增加。计算资源的大量耗费不仅降低了表示学习任务的效率,而且不利于多模态知识图谱表示学习模型向现实中迁移。考虑到社交场景下多模态信息的即时更新性和复杂性,时间和空间效率是多模态知识图谱表示学习模型在实际应用中更值得关注的方面,所以如何在保证高质量的表示能力的同时兼顾模型的效率是亟待解决的问题。
发明内容
针对现有技术中的上述不足,本发明提供的一种基于傅里叶变换的轻量化多模态知识图谱表示学习方法,解决了考虑到社交场景下多模态信息的即时更新性和复杂性,以往的多模态知识图谱表示学习方法在效率和质量方面仍存在不足的问题。
为了达到以上目的,本发明采用的技术方案为:
本方案提供一种基于傅里叶变换的轻量化多模态知识图谱表示学习方法,包括以下步骤:
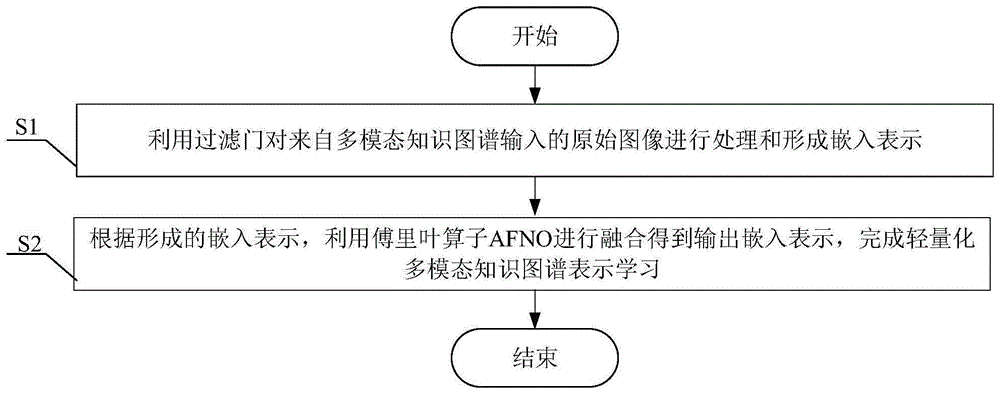
S1、利用过滤门对来自多模态知识图谱输入的原始图像进行处理和形成嵌入表示;
S2、根据形成的嵌入表示,利用傅里叶算子AFNO进行融合得到输出嵌入表示,完成轻量化多模态知识图谱表示学习。
本发明的有益效果是:本发明能够在保证多模态知识图谱的表示学习效果的同时显著减少对于计算资源的消耗。本发明首先对来自多模态知识图谱的原始输入进行处理和嵌入表示,然后将来自各个模态信息进行对齐和融合,以最大程度地保留来自各个模态的信息,获得高质量的社交知识图谱表示。在模态处理部分,本发明引入过滤门filter gate消除来自视觉模态的噪声影响,并减少模型处理图片的数量从而提高效率。此外,本发明引入了去卷积化的convolution-free策略对视觉模态输入的图像进行处理,降低了视觉模态处理所消耗的计算资源。在模态融合部分,本发明利用傅里叶算子AFNO对来自各个模态的信息进行融合,在保证信息提取效果的同时减少了模型对于计算资源的浪费,从而实现高效的社交多模态知识图谱表示学习。
进一步地,所述步骤S1包括以下步骤:
S101、利用过滤门对来自多模态知识图谱的原始图像进行相似度计算,并选取具有最高相似度的图像作为图片集的代表;
S102、利用去卷积的视觉处理方式对具有最高相似度的图像进行线性扁平映射处理,得到视觉模态嵌入表示
S103、将实体结构信息
上述进一步方案的有益效果是:本发明能够在保留来自各个模态有效信息的同时,去除来自视觉模态的噪声,减少视觉噪声对表示学习的负面影响。本发明通过引入过滤门filter gate消除来自视觉模态的噪声影响,并减少模型处理图片的数量从而提高效率,有效过滤了来自数据集级别的噪声信息,并有效将模型需要处理的图片数量减至原来的1/10;此外,本发明引入了去卷积化的convolution-free策略对视觉模态输入的图像进行处理,降低了视觉模态处理所消耗的计算资源,能够在保证模态信息嵌入表示效果的同时摒除了以往的卷积化方法,节约了时间和空间资源。
再进一步地,所述步骤S101包括以下步骤:
S1011、将来自多模态知识图谱的原始图像缩放至固定大小;
S1012、将经缩放处理的图像进行灰度化处理;
S1013、利用傅里叶变换将经灰度处理后的图像从像素域转换至频域,生成离散余弦变换DCT矩阵,并保留左上角的8×8低频矩阵;
S1014、计算当前离散余弦变换DCT矩阵的DCT均值;
S1015、将每个图像像素的灰度与DCT均值进行比较,得到当前图像的哈希矩阵,并组合成64位二进制整数,形成当前的图像指纹;
S1016、对比不同图像的指纹,比较各个位数,计算图像之间的汉明距离,得到图像之前的相似度;
S1017、选取具有最高相似度的图像作为图像集的代表。
上述进一步方案的有益效果是:本发明基于傅里叶算子的模态融合结构可以有效提取来自各个模态信息,同时减少了模型的计算量。
再进一步地,所述具有最高相似度的图像的表达式如下:
其中,
上述进一步方案的有益效果是:本发明通过具有最高相似度的图像,能够快速简单地判别出图片集中与实体最相关的图片。
再进一步地,所述嵌入表示
其中,
上述进一步方案的有益效果是:所获得的嵌入表示能够最大程度上保留来自各个模态的信息,并将其转化为在多模态预训练任务中的常用表示。
再进一步地,所述步骤S2包括以下步骤:
S201、将形成的嵌入表示分割为h×w个块,得到输入张量,其中,每个块表示为d维分词序列,h表示高度,w表示宽度;
S202、利用傅里叶算子AFNO对输入张量进行空间混合,得到输出嵌入表示,完成轻量化多模态知识图谱表示学习。
上述进一步方案的有益效果是:本发明利用傅里叶算子AFNO对来自各个模态的信息进行融合,在保证信息提取效果的同时减少了模型对于计算资源的浪费,从而实现高效的社交多模态知识图谱表示学习。
再进一步地,所述步骤S202包括以下步骤:
S2021、对输入张量进行傅里叶变换,得到中间表示z:
z=FFT(X)
其中,FFT(·)表示傅里叶变换,X表示输入张量;
S2022、根据中间表示z,利用双层MLP结构对所有的输入共享权重
其中,MLP(·)表示MLP结构;
S2023、根据输入共享权重
其中,IFFT(·)表示反傅里叶变换;
S2024、利用双重归一算法对中间输出X'作归一化处理,得到输出嵌入表示
上述进一步方案的有益效果是:在达到transformer中attention模块所能实现的效果的同时,减少了原attention模块所需的计算量,提高了计算速度。
再进一步地,所述输出嵌入表示
其中,LayerNorm(·)表示归一化操作。
附图说明
图1为本发明的方法流程图。
图2为本发明应用于社交场景下的方法流程图。
图3为本实施例中本发明在多模态知识图谱补全任务上的性能和计算资源耗费示意图。
图4为本实施例中各个模型在WN18-IMG数据集上的性能和时间复杂度对比示意图。
图5为本实施例中各模型在WN18-IMG数据集上的性能和空间复杂度对比图。
具体实施方式
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
实施例1
如图1所示,本发明提供了一种基于傅里叶变换的轻量化多模态知识图谱表示学习方法:MLFormer,其实现方法如下:
S1、利用过滤门对来自多模态知识图谱输入的原始图像进行处理和形成嵌入表示,其实现方法如下:
S101、利用过滤门对来自多模态知识图谱的原始图像进行相似度计算,并选取具有最高相似度的图像作为图片集的代表,其实现方法如下:
S1011、将来自多模态知识图谱的原始图像缩放至固定大小;
S1012、将经缩放处理的图像进行灰度化处理;
S1013、利用傅里叶变换将经灰度处理后的图像从像素域转换至频域,生成离散余弦变换DCT矩阵,并保留左上角的8×8低频矩阵;
S1014、计算当前离散余弦变换DCT矩阵的DCT均值;
S1015、将每个图像像素的灰度与DCT均值进行比较,得到当前图像的哈希矩阵,并组合成64位二进制整数,形成当前的图像指纹;
S1016、对比不同图像的指纹,比较各个位数,计算图像之间的汉明距离,得到图像之前的相似度;
S1017、选取具有最高相似度的图像作为图像集的代表:
其中,
S102、利用去卷积的视觉处理方式对具有最高相似度的图像进行线性扁平映射处理,得到视觉模态嵌入表示
S103、将实体结构信息
其中,
S2、根据形成的嵌入表示,利用傅里叶算子AFNO进行融合得到输出嵌入表示,完成轻量化多模态知识图谱表示学习,其实现方法如下:
S201、将形成的嵌入表示分割为h×w个块,得到输入张量,其中,每个块表示为d维分词序列,h表示高度,w表示宽度;
S202、利用傅里叶算子AFNO对输入张量进行空间混合,得到输出嵌入表示,完成轻量化多模态知识图谱表示学习,其实现方法如下:
S2021、对输入张量进行傅里叶变换,得到中间表示z:
z=FFT(X)
其中,FFT(·)表示傅里叶变换,X表示输入张量;
S2022、根据中间表示z,利用双层MLP结构对所有的输入共享权重
其中,MLP(·)表示MLP结构;
S2023、根据输入共享权重
其中,IFFT(·)表示反傅里叶变换;
S2024、利用双重归一算法对中间输出X'作归一化处理,得到输出嵌入表示
其中,LayerNorm(·)表示归一化操作。
本发明需要首先对来自多模态知识图谱的原始输入进行处理和嵌入表示,然后将来自各个模态信息进行对齐和融合,以最大程度地保留来自各个模态的信息,获得高质量的社交知识图谱表示。在模态处理部分,本发明引入过滤门filter gate消除来自视觉模态的噪声影响,并减少模型处理图片的数量从而提高效率。此外,本发明引入了去卷积化的convolution-free策略对视觉模态输入的图像进行处理,降低了视觉模态处理所消耗的计算资源。在模态融合部分,本发明利用傅里叶算子AFNO对来自各个模态的信息进行融合,在保证信息提取效果的同时减少了模型对于计算资源的浪费,从而实现高效的社交多模态知识图谱表示学习。
实施例2
下面对本发明作进一步说明。
基于背景技术中阐述可知:考虑到社交场景下多模态信息的即时更新性和复杂性,时间和空间效率是多模态知识图谱表示学习模型在实际应用中更值得关注的方面,所以如何在保证高质量的表示能力的同时兼顾模型的效率是亟待解决的问题,因此,如图2所示,本发明提供了一种基于傅里叶变换的轻量化多模态知识图谱表示学习方法(MLFormer,即本发明所提方法),其实现方法如下:
S1、利用过滤门对来自社交多模态知识图谱输入的原始图像进行处理和形成嵌入表示,其实现方法如下:
S101、利用过滤门对来自社交多模态知识图谱的原始图像进行相似度计算,并选取具有最高相似度的图像作为图片集的代表,其实现方法如下:
S1011、将来自社交多模态知识图谱的原始图像缩放至固定大小;
S1012、将经缩放处理的图像进行灰度化处理;
S1013、利用傅里叶变换将经灰度处理后的图像从像素域转换至频域,生成离散余弦变换DCT矩阵,并保留左上角的8×8低频矩阵;
S1014、计算当前离散余弦变换DCT矩阵的DCT均值;
S1015、将每个图像像素的灰度与DCT均值进行比较,得到当前图像的哈希矩阵,并组合成64位二进制整数,形成当前的图像指纹;
S1016、对比不同图像的指纹,比较各个位数,计算图像之间的汉明距离,得到图像之前的相似度;
S1017、选取具有最高相似度的图像作为图像集的代表;
S102、利用去卷积的视觉处理方式对具有最高相似度的图像进行线性扁平映射处理,得到视觉模态嵌入表示
S103、将社交实体结构信息
S2、根据形成的嵌入表示,利用傅里叶算子AFNO进行融合得到输出嵌入表示,完成轻量化多模态知识图谱表示学习,其实现方法如下:
S201、将形成的嵌入表示分割为h×w个块,得到输入张量,其中,每个块表示为d维分词序列,h表示高度,w表示宽度;
S202、利用傅里叶算子AFNO对输入张量进行空间混合,得到输出嵌入表示,完成轻量化多模态知识图谱表示学习,其实现方法如下:
S2021、对输入张量进行傅里叶变换,得到中间表示z:
z=FFT(X)
其中,FFT(·)表示傅里叶变换,X表示输入张量;
S2022、根据中间表示z,利用双层MLP结构对所有的输入共享权重
其中,MLP(·)表示MLP结构;
S2023、根据输入共享权重
其中,IFFT(·)表示反傅里叶变换;
S2024、利用双重归一算法对中间输出X'作归一化处理,得到输出嵌入表示
本实施例中,基于傅里叶变换的轻量化社交多模态知识图谱表示学习方法共分为两个部分:模态处理与模态融合,其中,在模态处理部分又分为两个步骤:原始数据集处理与模态特征处理:
原始数据集处理:在基于社交知识图谱的原始数据集处理中,考虑到来自图像模态的信息可能会引入噪声干扰知识图谱的表示,因此使用过滤门对要输入的原始图像进行处理。已知对于社交实体集中的第i个社交实体e
其中,
其中,相似度算法的基本流程如下:
将输入图片放缩至合适大小(一般为32×32);
对图片进行灰度化处理,以简化图像矩阵,提高运算速度;
利用傅里叶变换将图像从像素域转换为频域,生成离散余弦变换(DCT)矩阵,并保留左上角的8×8低频矩阵。二维DCT变换公式如下:
F=AfA
其中,F表示生成的变换矩阵,A表示变换的系数矩阵,f表示转换到频域的原始信息输入,A
计算当前DCT系数矩阵的DCT均值;
将每个像素的灰度与DCT均值比较,得到当前图片的哈希矩阵,组合成64位二进制整数,形成当前图片的指纹:
其中,hash(i”,j”)表示当前图片的指纹,F(i”,j”)表示哈希矩阵,
对比不同图片的指纹,比较各个位数,计算图片之间的汉明距离hammingdistance,得到社交图片之间的相似度。
本实施例中,过滤门的操作不仅可以消除数据集级别的噪声,还可以减少模型所需要处理的社交图片数量,节约了计算资源。多模态知识图谱的训练、测试和验证集由大量的社交三元组构成,三元组来自现实社交知识图谱数据集中的一对一、一对多和多对多关系对。社交知识图谱数据集中的社交关系和社交实体字典则是文本描述和结构信息的一一对应。考虑到文本模态的噪声,对于文本模态的输入,本发明在原始数据集处理阶段剔除了无法在字典中查询到对应关系或对应实体的社交三元组。
本实施例中,模态特征处理包括视觉模态特征处理和文本模态特征处理。
本实施例中,针对视觉模态特征处理,经由过滤门处理后,每个社交实体对应的社交图片数量缩减为一张,对于某些社交实体的缺失图像,本发明采用随机产生一张空白图像的方法进行补充。在视觉特征处理环节,本发明抛弃了以往的卷积化处理方法,采用去卷积的视觉处理方式对原始图像进行线性扁平映射处理获得视觉模态嵌入表示
本实施例中,针对文本模态特征处理,考虑到知识图谱的文本模态信息来自两个方面,即社交实体结构信息
其中,
本实施例中,在训练时,文本特征处理模块模仿预训练任务中的文本掩码任务对文本序列表示进行进一步的处理如下:
视觉与文本模态的嵌入表示将会与模态类型信息
其中,
本实施例中,模态融合部分考虑到transformer模型在多模态信息处理上的优越性,使用transformer encoder对来自各个模态的嵌入表示进行融合。由于transformer中的自注意力机制self-attention计算复杂度与输入的序列长度成二次相关,为了提高模型的推理速度,该方法使用计算复杂度与输入成对数相关的傅里叶算子AFNO替代自注意力机制。
已知嵌入表示在输入AFNO层前会被分割成h×w个块patch,h表示高度,w表示宽度,每个块都可表示为d维的分词序列token。则输入傅里叶算子AFNO层的为一个h×w×d大小的块张量X∈R
对输入张量进行傅里叶变换得到中间表示z:
z=FFT(X)
其中,FFT(·)表示傅里叶变换,X表示输入张量;
使用双层MLP结构对所有的输入共享权重
其中,MLP(·)表示MLP结构;
使用反傅里叶变换得到中间输出X':
其中,IFFT(·)表示反傅里叶变换;
使用双重归一算法对中间输出作归一化得到最终输出嵌入
其中,LayerNorm(·)表示归一化操作。
本实施例中,在社交多模态知识图谱补全任务中,给定一个查询q=(eh,r,未知数),模型将从给定的候选社交尾实体中对每个社交尾实体赋予不同的可能性得分并根据得分从高到低排序,其中排名最高的社交尾实体将其选为最终预测社交实体,与真实的社交实体进行比对。这一思想与预训练任务中的文本掩码任务MLM从原理上是一致的,都属于多标签分类任务。因此在训练时,我们选择了交叉熵损失函数对模型进行训练,公式如下:
loss=-log(p
其中,p
在社交知识图谱补全的场景中,给定一个社交知识图谱查询,模型将根据打分函数为候选社交实体集
本实施例中,采用上述算法的优点在于,本发明所提供的表示学习方法,不仅可以有效地提取来自多模态知识图谱的各类信息,减少来自社交知识图谱视觉模态噪声所带来的影响,还可以提高表示学习模型在社交场景下的推理速度,节省模型的空间占用。在FB15k-237和WN18-IMG两个现实数据集上对模型的表示效果进行了验证。
FB15k-237:是知识图谱补全任务常用数据集FB15k的子集,包含237类关系和14451个实体。其中有训练三元组272115个,验证组17535个,测试组20466个。
WN18-IMG:WN18是来自于WordNet的知识图谱数据集,而WN18-IMG是WN18知识图谱数据对应的多模态数据集,每个实体对应十张图片,包含18类关系和40943个实体。其中有训练三元组141442个,验证组5000个,测试组5000个。
本发明验证了本方法MLFormer在多模态知识图谱补全任务上的性能和计算资源耗费,见图3。其中,Hits@n(n=1,3,10)是指在链接预测中排名小于n的三元组的平均占比,MR是正确实体评分函数的平均排名。FLOPs和Parameters是衡量模型时间复杂度和空间复杂度的常用指标。本发明对比了MLFormer和目前的多模态知识图谱表示学习方法以及预训练多模态模型在多模态知识图谱补全任务上的性能和计算资源耗费,图3中加粗部分为本发明的效果,可以看出本发明在补全任务上的性能基本与最好的多模态知识图谱表示模型持平,并在时间和空间复杂度上都远远优于现有方法。
本实施例中,关于时间复杂度对比:图4是各个模型在WN18-IMG数据集上的性能和时间复杂度对比。由图4可以看出,MLFormer相比目前最好的多模态知识图谱表示学习方法MKGformer在时间复杂度上减少了99.4%,相比RSME减少了95.5%,相比预训练多模态模型减少了98.5%。已知FLOPs的大小与模型输入的大小成正比,MKGformer的输入大小为(224,64),其中224代表图像大小,64代表序列长度;而RSME的输入大小为(224,100),MLFormer的输入大小为(384,32)。可以看出,在MLFormer的图像输入大小大于其他模型的情况下,其仍具有最小的时间复杂度,这证明了本发明有效提升了模型在社交媒体场景下的推理速度。
本实施例中,关于空间复杂度对比:图5是各模型在WN18-IMG数据集上的性能和空间复杂度对比图。由图5可以看出,MLFormer相比MKGformer在参数量上减少了48.4%,相比TransAE减少了45.9%,相比RSME减少了16.2%。MLFormer可以做到在性能与最好模型效果相同的同时,参数量得到了大幅下降,这证明本发明在降低社交知识图谱推理空间复杂度方面起到了很好的效果。
- 一种基于结构信息与文本描述的知识图谱表示学习方法
- 一种基于实体和关系结构信息的知识图谱表示学习方法
- 一种基于图神经网络的多模态知识图谱表示学习方法
- 一种基于图谱表示学习的知识表示学习方法