一种基于Kmeans和RGB均值快速测定污染物浓度的方法
文献发布时间:2024-04-18 19:58:26
技术领域
本发明属于环境监测技术领域,涉及机器学习,有色污染物的快速测定方法,特别涉及一种基于Kmeans和RGB均值快速测定污染物浓度的方法。
背景技术
工业活动的指数级增长导致水污染事件激增,水质监测滞后成为影响人类健康和地球生态系统的关键问题。因此,开发一种可应用于各种水质(包括生态水、自然资源水和废水)的通用长期连续水质监测方法非常重要。
水中某些污染物的浓度可以通过颜色的变化反映出来。可以训练机器学习模型来识别水质彩色图像并预测污染物浓度,以实现长期连续监测。其中,图像识别技术已成为污染物现场检测和提供预测见解的有用工具。例如,直接计算两幅图像之间的特征距离以实现分类(
图像传感器是一种存储外部可见表型信息(例如颜色和形状)的经济方式。RGB空间是一个包含物体的纹理特征、轮廓和颜色特征的空间。RGB的维度是建立在笛卡尔坐标系上的,可以得到多种三通道。它的坐标系以红、绿、蓝三种基本颜色为基础,不同程度地叠加,产生丰富而广泛的颜色,可以充分表现颜色变化的程度。Kmeans是一种常用的无监督聚类算法,它将数据集划分为K个不同的聚类。各种数据类型(例如图像、RGB值或其他数值数据)都可以作为K均值输入。在图像处理领域,Kmeans可以应用于图像压缩、图像分割等任务。随着目标污染物浓度的增加,溶液的颜色/状态也会变暗,导致像素值减小,Kmeans聚类点的值也会减少,因此可以为测定目标污染物的浓度提供有用的特征。
发明内容
为了克服上述现有技术的缺点与不足,本发明的首要目的在于提供一种基于Kmeans和RGB均值快速测定污染物浓度的方法。
本发明另一目的是提供上述方法在测定同一水域的多个样品中污染物浓度的应用。
本发明的目的通过下述方案实现:
一种基于Kmeans和RGB均值快速测定污染物浓度的方法,包括以下步骤:
(1)配制不同浓度的标准样品;
(2)拍摄步骤(1)所得样品,并且裁剪所获取的照片;
(3)提取步骤(2)所得截图图片的RGB通道信息;
(4)根据步骤(3)所得RGB通道信息计算RGB各个通道均值,得到RGB均值特征数据;
(5)将步骤(4)中得到的RGB均值特征数据进行Kmeans聚类,得到Kmeans特征数据;
(6)将步骤(4)和步骤(5)获取的数据采用K-fold交叉验证训练linear模型,得到最佳Linear模型;
(7)待测样品经步骤(2)~(5)得到RGB均值特征数据及其kmeans特征数据,将得到的特征数据输入到步骤(6)训练好的最佳Linear模型,得到污染物浓度。
步骤(1)所述配制不同浓度的标准样品,具体为:采集一个污染水样,采用常规仪器检测方法确定该水样的浓度,对该水样进行梯度稀释得到不同浓度的标准样品,稀释倍数优选为1~10倍。
所述常规仪器包括电感耦合等离子体质谱仪(ICP)、紫外-可见光吸收光谱(UV-Vis)、原子吸收光谱仪(AAS)、原子荧光光谱仪(AFS)等仪器中的至少一种。
步骤(2)所述拍摄为将样品置于玻璃比色管或PP离心管中进行拍摄;拍摄的工具为高清单反摄像机或手机,拍摄的光线为普通灯光,拍摄的背景为纯色背景,优选白色或黑色。
步骤(2)所述拍摄的条件为:保证同一组溶液的摄影条件一致。
步骤(2)所述裁剪具体为:在数据预处理框架中,使用Lightroom对获取图像批量裁剪,裁掉画面中无用内容,仅保留有溶液的图像区域,并且同一组图像裁剪区域一致,图像大小一致。
步骤(3)所述提取是利用OpenCV库中自带的imread函数来读取出步骤(2)中得到的截图图片的信息。
步骤(3)中使用OpenCV库中imread函数读取图片信息的执行伪代码如下:
Pseudo-code for extracting RGB channels from an image.
步骤(4)所述计算为利用Python软件计算,具体计算如下:
其中,R,G,B分别代表各个通道计算出来的均值;M和N分别为图片的宽高,F
步骤(5)所述Kmeans聚类的具体步骤如下:
Step1将获得的包含RGB像素值的矩阵连接成(H*W*3)的列向量作为Kmeans输入,RGB像素值矩阵是步骤(4)获得的均值特征数据;其中H表示图像的高度(Height);W表示图像的宽度(Width);3表示图像的通道数,通常是红色(R)、绿色(G)和蓝色(B)三个通道,用于表示彩色图像;
Step2选择K个初始化中心点作为聚类中心点;
Step3在第N次迭代中,对任意一个样本计算其到K个中心的距离,将样本归到距离最近得中心点所在的类;
Step 4重新计算每个聚类中所有的点的平均值,并将其更新为新的聚类中心;
Step 5重复Step2和Step3的过程,直到聚类中心不再产生变化或达到预定的迭代次数;所述预定的迭代次数为2,3,4,6或8,优选为8。
步骤(5)中Step 3采用欧氏距离作为衡量聚类中心点和输入数据点的距离,其计算公式为:
其中x为输入数据点,μ为聚类中心点。
具体的,步骤(4)和步骤(5)中RGB通道均值和Kmeans聚类执行伪代码如下:
Pseudo-code for RGB features and Kmeans feature extracted method.
步骤(6)所述最佳linear模型具体由以下步骤得到:
Step 1将得到的RGB均值特征数据和kmeans特征数据融合成一个特征向量,得到n个数据集以及对应的污染物浓度;
Step 2对数据集进行K-fold交叉验证;
Step 3对step 2中的训练集进行linear模型训练,得出最佳的linear模型;
其中,n为步骤(1)所述标准样品的样品数。
步骤(7)所述待测样品的图片需要与标准样品的图片保持同样的拍摄条件。
上述方法在测定同一水域的多个样品中污染物浓度的应用。
本发明的机理:
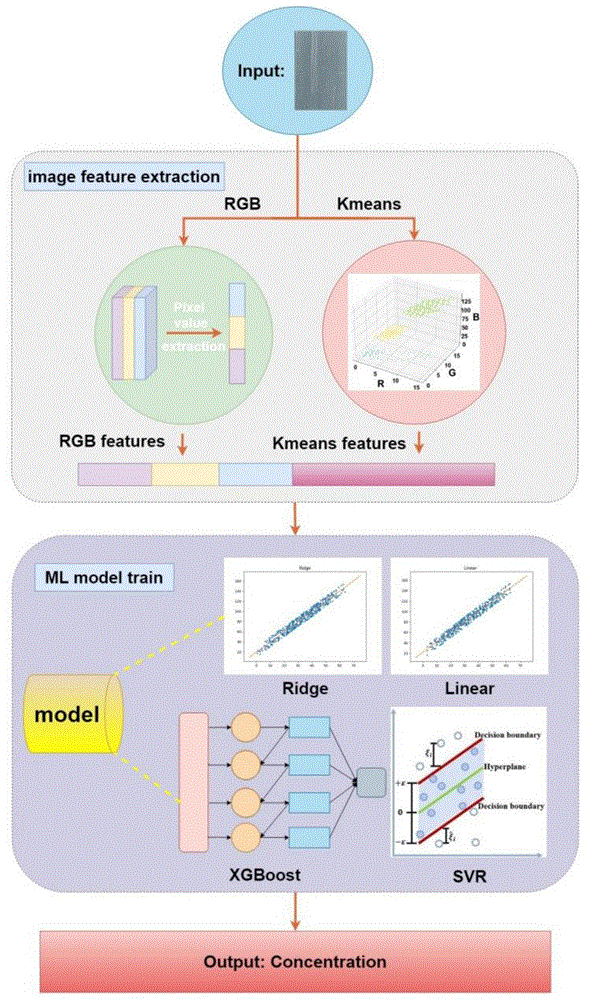
本发明提供一个完整的污染物浓度测试流程,包括图像获取与预处理,RGB特征及其kmeans特征图像提取过程,以及linear model训练流程,测试污染物浓度。其中,在训练和测试的图片均需要经过图像获取与预处理,RGB特征及其kmeans特征图像提取过程,获得对应的图像特征向量。解决机器学习无法获取有效图像特征的问题,建立图像特征与浓度的关系,使得机器学习模型可以根据训练数据的特征获取先验信息用于预测污染物浓度。
由于本发明不对污水进行前处理,所测试的水样可能表现浑浊并包含漂浮物,会对照片拍摄效果产生影响,若用去离子水和污染物标准品配制相应浓度,则无法对应实际水域环境中的污染物浓度,故本发明以水域中原水样品作为标准样,以常规检测仪器测得的浓度为对应的标准浓度。
本发明相对于现有技术,具有如下的优点及有益效果:
本发明的方法在测定多个样品的污染物浓度时,仅在标准样的浓度确定使用一次常规仪器检测方法,其余样品可拍照后按本方法得到相应浓度,减少大型仪器的使用,大大节省了现场即时检测成本及检测时间,无需制备和投加传感器材料或者比色材料,大大降低了检测门槛和成本。并且全程基于手机和计算机平台,方便便携,检测具有及时性,因此适用于污染物的现场实时检测。
1.本发明与已有的基于机器学习模型预测污染物浓度的工作相比,不需要准备比色材料或者荧光传感器作为颜色指示剂,大大节约了检测成本,简化了检测步骤。
2.本发明与已有的基于机器学习模型预测污染物浓度的工作相比,不是仅仅使用第三方提供的RGB软件提取颜色特征,而是将RGB和Kmeans特征提取方法融合,大大提高了检测灵敏度和稳定性,因此能够实现对浓度变化极低的污染物精准和稳定的检测。
3.本发明与已有的基于机器学习模型预测污染物浓度的工作相比,不仅仅局限于某一个浓度范围的某种污染物,而是可以用于任何有色污染物以及大部分浓度区间,具有高度的普适性。
4.本发明相对于电感耦合等离子光谱发生仪(ICP),火焰原子吸收(AFS)等传统检测方法,无需使用大型的检测仪器和专业的检测技术人员,制样简单,检测结果等待时间短,大大降低了检测成本。
5.本发明加入了交叉验证训练的方法,将训练数据集分成了5个部分,从中有规律提取4各部分进行训练,剩下的1个子数据进行验证,得到的机器学习模型具有更加具有泛化能力,能更准确预测污染物浓度。
附图说明
图1为实施例2原水水样图。
图2为实施例2裁剪后的图。
图3为实施例2经过RGB和Kmeans特征提取后输入到Linear模型的输出结果的决定系数(R
图4为实施例3原水水样图。
图5为实施例3裁剪后的图。
图6中(a)和(c)为本发明方法输出的结果,(b)和(d)为传统的机器学习模型主成分分析方法输出的结果。
图7为实施例4原水水样图。
图8为实施例4裁剪后的图。
图9为本发明方法与ICP方法的模型对比。
图10为实施例4的Linear模型输出结果。
图11为本发明方法的过程示意图。
具体实施方式
下面结合实施例和附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。实施例中未注明具体条件者,按照常规条件或制造商建议的条件进行。所用试剂或仪器未注明生产厂商者,均为可以通过市售购买获得的常规产品。
实施例中所用试剂如无特殊说明均可从市场常规购得。
本发明的一种基于Kmeans和RGB均值快速测定污染物浓度的方法,包括以下步骤:首先采集一个污染水样,采用常规检测仪器确定该水样的浓度,对该水样进行1~10倍的浓度稀释得到不同浓度的标准样品;然后将标准样品逐一拍摄,获取含污染物溶液的图像并裁剪,使用OpenCV库中imread函数读取图片信息;接着进行RGB通道均值和Kmeans聚类,得到RGB特征及其kmeans特征的数据集;再对数据集进行切分并输入Linear模型后输出线性模型,然后采集实际污染水样进行拍摄,提取的数据集输入Linear模型中输出污染物浓度。
使用OpenCV库中imread函数读取图片信息的执行伪代码如下:
Pseudo-code for extracting RGB channels from an image.
RGB通道均值和Kmeans聚类执行伪代码如下:
Pseudo-code for RGB features and Kmeans feature extracted method.
实施例1
对Kmeans的聚类数量进行优化,在进行Kmeans聚类时,聚类的数量通常影响到特征提取的效果,本实施例为对Kmeans聚类数量进行优化:
(1)配制Co
(2)将拍摄后的照片用Lightroom软件批量裁剪,裁掉画面中无用内容,仅保留有溶液的图像区域,并且所有图像裁剪区域一致;
(3)将裁剪后的照片利用OpenCV库中自带的imread函数提取RGB通道信息;
(4)根据步骤(3)得到的通道信息(即:F
其中,R,G,B分别代表各个通道计算出来的均值。M和N分别为图片的宽高,F
(5)对获得的RGB均值特征数据进行Kmeans聚类,具体步骤如下:
Step 1将获得的包含RGB像素值的矩阵连接成(H*W*3)的列向量作为Kmeans输入,RGB像素值矩阵是步骤(4)获得的均值特征数据;其中H表示图像的高度(Height);W表示图像的宽度(Width);3表示图像的通道数,通常是红色(R)、绿色(G)和蓝色(B)三个通道,用于表示彩色图像;
Step 2选择聚类中心点数分别为0,2,3,4,6,8;
Step 3采用欧氏距离作为衡量聚类中心点和输入数据点的距离,其中x为输入数据点,μ为聚类中心点;
Step 4重新计算每个聚类中所有的点的平均值,并将其更新为新的聚类中心;
Step 5重复第二步和第三步的过程,直到聚类中心不再产生变化或达到预定的迭代次数(0,2,3,4,6或8)。
(6)将步骤(5)所得输入到模型中,得到R
Co
从表中可以看出,当不使用Kmeans聚类时,也就是k=0时,Ridge,XGB,SVR和Linear四种模型的R
实施例2
本实施例电镀废水水样采集于中国广东省江门市新财富环保公司。
取污染严重段的电镀废水作为Cr(VI)标准样,采用电感耦合等离子光谱发生仪(ICP)确定原废水中Cr(VI)的浓度为357.851mg L
检测该水域任一处电镀废水中Cr(VI)的浓度:
(1)将原废水用去离子水稀释1-10倍,得到浓度分别为35.7851,71.5702,107.3553,143.1404,178.9255,214.7106,250.4957,286.2808,322.0659,357.851mg L
(2)将拍摄后的照片用Lightroom软件批量裁剪,裁掉画面中无用内容,仅保留有溶液的图像区域,并且所有图像裁剪区域一致,裁剪后的图片如图2前10张图片所示,图2中各样品位置与图1一一对应;
(3)将所有污染物处理后的照片利用OpenCV库中自带的imread函数提取RGB通道信息;
(4)根据步骤(3)得到的通道信息(即:F
其中,R,G,B分别代表各个通道计算出来的均值。M和N分别为图片的宽高,F
(5)对获得的RGB均值特征数据进行Kmeans聚类,具体步骤如下:
Step 1将获得的包含RGB像素值的矩阵连接成(H*W*3)的列向量作为Kmeans输入,RGB像素值矩阵是步骤(4)获得的均值特征数据;其中H表示图像的高度(Height);W表示图像的宽度(Width);3表示图像的通道数,通常是红色(R)、绿色(G)和蓝色(B)三个通道,用于表示彩色图像;
Step 2选择聚类中心点数为8,随机选取8个点作为质心(即聚类中心)。
Step 3采用欧氏距离作为衡量聚类中心点和输入数据点的距离,其中x为输入数据点,μ为聚类中心点。
Step 4重新计算每个聚类中所有的点的平均值,并将其更新为新的聚类中心;
Step 5重复Step2和Step3的过程,直到聚类中心不再产生变化或达到预定的迭代次数8。
(6)将步骤(4)和步骤(5)得到的RGB均值特征和kmeans特征融合成一个特征向量,得到的10个数据集以及对应的污染物浓度,对数据集进行K-fold交叉验证。用Linearmodel进行训练,得到江门市新财富环保公司的电镀废水中Cr(VI)浓度的线性模型。
(7)随机采集待测的废水样品,在保持与训练数据同样条件下进行拍摄,得到测试图片如图1第11,12张图片所示,用同样的方法进行裁剪得到图片如图2第11,12张图片所示,然后经过步骤(3)~(5)得到了RGB均值特征和Kmeans特征,把得到的特征输入到步骤(6)中训练好的最佳Linear模型进行检测,输出Cr(VI)浓度。
结果如图3所示,该模型在预测Cr(VI)浓度方面表现稳定,R
实施例3
本实施例污染的河流水水样采集于河南省新乡市渭河流域。
取污染严重段的被污染的河流水作为Cr(VI)标准样,采用电感耦合等离子光谱发生仪(ICP)确定原河流水中Cr(VI)的浓度为435.82mg L
检测该水域任一处污染河流水中Cr(VI)的浓度:
(1)将原河流水用去离子水稀释1-5倍,得到浓度分别为87.164,174.328,261.492,348.656,435.82mg L
(2)将拍摄后的照片用Lightroom软件批量裁剪,裁掉画面中无用内容,仅保留有溶液的图像区域,并且所有图像裁剪区域一致,裁剪后的图片如图5前5张图片所示,图5中各样品位置与图4一一对应;
(3)将所有污染物处理后的照片利用OpenCV库中自带的imread函数提取RGB通道信息;
(4)根据步骤(3)得到的通道信息,分别对R,G,B三个矩阵计算像素的均值,每个浓度得到了三个通道均值:
其中,R,G,B分别代表各个通道计算出来的均值。M和N分别为图片的宽高,F
(5)对获得的RGB通道进行Kmeans聚类,具体步骤如下:
Step 1将获得的包含RGB像素值的矩阵连接成(H*W*3)的列向量作为Kmeans输入,RGB像素值矩阵是步骤(4)获得的均值特征数据;其中H表示图像的高度(Height);W表示图像的宽度(Width);3表示图像的通道数,通常是红色(R)、绿色(G)和蓝色(B)三个通道,用于表示彩色图像;
Step 2选择聚类中心点数为8,随机选取8个点作为质心。
Step 3采用欧氏距离作为衡量聚类中心点和输入数据点的距离,其中x为输入数据点,μ为聚类中心点。
Step 4重新计算每个聚类中所有的点的平均值,并将其更新为新的聚类中心;
Step 5重复Step2和Step3的过程,直到聚类中心不再产生变化或达到预定的迭代次数8。
(6)将得到的RGB均值特征和kmeans特征融合成一个特征向量,得到5个数据集以及对应的污染物浓度,对数据集进行K-fold交叉验证。用Linear model进行训练,得到河南省新乡市渭河流域污染河流中Cr(VI)的线性模型。
(7)随机采集待测的污染河流水样品,在保持与训练数据同样条件下进行拍摄如图4第6,7张图片所示,用同样的方法进行裁剪得到图片如图如图5第6,7张图片所示,经过步骤(3)~(5)得到了RGB均值特征和Kmeans特征,把得到的特征输入到步骤(6)中训练好的最佳Linear模型进行检测,输出Cr(VI)浓度。
结果如图6所示,图6中(a)和(c)为本发明方法输出的结果,图6中(b)和(d)为传统的机器学习模型主成分分析方法输出的结果,从图中可以看出,我们的方法在预测Cr(VI)浓度方面表现稳定,与传统机器学习方法主成分分析法相比,四种机器学习模型(Ridge、XGB、SVR和Linear模型)的准确率都有大幅度提升,其中Ridge、SVR、Linear模型分别提高了56.13%、63.1%和42.11%。因此可以看出,我们的方法相对于主成分分析方法来说错误率低,稳定性高,适合监测天然水样。
实施例4
本实施例电镀废水水样采集于中山市中粤马口铁有限公司。
取污染严重段的电镀废水作为Cr(VI)标准样,采用电感耦合等离子光谱发生仪(ICP)确定原废水中Cr(VI)的浓度为6.6654mg L
检测该水域任一处电镀废水中Cr(VI)的浓度:
(1)将原电镀废水用去离子水稀释1-10倍,得到浓度分别为0.66654,1.33308,1.99962,2.66616,3.3327,3.99924,4.66578,5.33232,5.99886,6.6654mg L
(2)将拍摄后的照片用Lightroom软件批量裁剪,裁掉画面中无用内容,仅保留有溶液的图像区域,并且所有图像裁剪区域一致,裁剪后的图片如图8所示,图8中各样品位置与图7一一对应;
(3)将所有污染物处理后的照片利用OpenCV库中自带的imread函数提取RGB通道信息;
(4)根据步骤(3)得到的通道信息,分别对R,G,B三个矩阵计算像素的均值,每个浓度得到了三个通道均值:
/>
其中,R,G,B分别代表各个通道计算出来的均值。M和N分别为图片的宽高,F
(5)对获得的RGB通道进行Kmeans聚类,具体步骤如下:
Step 1将获得的包含RGB像素值的矩阵连接成(H*W*3)的列向量作为Kmeans输入,RGB像素值矩阵是步骤(4)获得的均值特征数据;其中H表示图像的高度(Height);W表示图像的宽度(Width);3表示图像的通道数,通常是红色(R)、绿色(G)和蓝色(B)三个通道,用于表示彩色图像;
Step 2选择聚类中心点数为8,随机选取8个点作为质心。
Step 3采用欧氏距离作为衡量聚类中心点和输入数据点的距离,其中x为输入数据点,μ为聚类中心点。
Step 4重新计算每个聚类中所有的点的平均值,并将其更新为新的聚类中心;
Step 5重复第二步和第三步的过程,直到聚类中心不再产生变化或达到预定的迭代次数8。
(6)将得到的RGB均值特征和kmeans特征融合成一个特征向量,得到的10个数据集以及对应的污染物浓度,对数据集进行K-fold交叉验证,用Linear model进行训练,得到验证集Cr(VI)的线性模型1;再从10个子数据集抽出第2,4,6,8,10作为子数据集融合成训练集,剩下的一个子数据集为验证集,用Linear model进行训练,得到验证集Cr(VI)的线性模型2。
(7)将步骤(6)所得的第1,3,5,7,9数据集分别输入线性模型2得到下表中样品1,3,5,7,9对应的浓度Cr(VI);将步骤(6)所得的第2,4,6,8,10数据集分别输入线性模型1得到下表中样品2,4,6,8,10对应的浓度Cr(VI)。
结果如下表所示:
图9为本发明方法与ICP方法的对比,从图中可以看出,我们的方法在预测Cr(VI)浓度方面表现稳定,与传统ICP法相比,所获得的R
在四个机器学习模型中,线性模型表现出了卓越的性能,R
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 基于RGB的图像比色的浓度测定方法、系统、存储介质
- 基于RGB的图像比色的浓度测定方法、系统、存储介质