综合性多工序数据产品综合评测自主学习模型及系统
文献发布时间:2024-04-18 20:01:23
技术领域
本发明涉及多工序数据产品综合评测技术领域,具体为综合性多工序数据产品综合评测自主学习模型及系统。
背景技术
随着生产过程越来越复杂.多工序制造过程在工业生产中越来越普遍,工序之间相互关联作用,产品质量的影响因素日益复杂,而对于一个综合性多工序的数据产品,不同检测设备,不同的检测手段,往往造成数据产品综合评测的差异,使得评测结果权威性不足。
于是,有鉴于此,针对现有的结构及缺失予以研究改良,提出综合性多工序数据产品综合评测自主学习模型及系统。
发明内容
针对现有技术的不足,本发明提供了综合性多工序数据产品综合评测自主学习模型及系统,解决了上述背景技术中提出的问题。
为实现以上目的,本发明通过以下技术方案予以实现:综合性多工序数据产品综合评测自主学习模型,所述综合性多工序数据产品综合评测自主学习模型包括下述操作步骤:
S1、导入《专家评测意见表》:
于模型输入端导入《专家评测意见表》,《专家评测意见表》为多地、多年专家对综合性多工序数据产品综合评测的意见、报告,包括:财务上的和技术上的审核意见,以及客户或第三方历史《产品检测报告》,《专家评测意见表》简称《病历本》;
S2、《病历本》分析训练:
对《病历本》进行全方位分析,包括结构、语言、内容等方面;
对《病历本》进行全方位分析时,采用以下社会化工具:OCR、拆解王软件、智能拆解软件;
S3、模块化拆分运算训练:
根据《病历本》的结构和内容特点,将全文分成若干独立“小模块”并训练,独立“小模块”简称《诊断单》,并进行完整度分析,分解为一条条具体的《诊断单》,即:问诊+评测意见;并进行语句完整、通顺优化;
实现分析拆解的工具为:拆解王软件、智能拆解软件;
S4、内容优化训练:
对所有的独立《诊断单》进行相关度和重复度运算训练,利用Word sense插件、Google的自然语言搜索、维基百科对《诊断单》的内容进行优化、“合并归类”、“去重”内容相近《诊断单》,使其更加精准、有深度,提高未来规则(包括《退回意见》)的可读性,“去重”的同时,重复度可作为加权因素提升《规则》的重要性;
S5、标题生成训练:
通过运算生成各《诊断单》的“标题”,作为未来新《规则》名称;
S6、关键词优化训练:
运用社会化工具,从《诊断单》抽取适合的关键词,作为问诊关键字,并给出相应的优化建议,进一步完善《诊断单》的问诊能力,采用至少两种社会化工具相互印证;
S7、分类运算训练:
按《评测系统》《规则库》“树关系”对《诊断单》进行“分类”运算训练,确定新《规则》树节点位置和“内容”,包括:规则名、编号、问诊关键词、评测意见,采用至少两种社会化工具相互印证,如:朴素贝叶斯分类器:使用基于贝叶斯定理的算法来分类文档,该算法假设每个单词都是相互独立的;支持向量机:该算法通过在特征空间中找到一个最优的超平面来分类文档;
S8、人工检查训练效果:
对训练过程进行人工验证,对训练结果进行专家论证,随着训练量的增加,并逐步减少人工干预,自主学习模型在线训练部分使用随机、空闲时自主训练,并存储算法模型训练时产生的训练信息及算法模型性能评估信息到自主学习模型数据库历次训练表、模型训练详情表、ROC曲线表中进行可视化展示;
S9、样本训练测试验证:
运用综合评测对象《源数据》样本对新规则进行训练,引用综合评测《源数据》先数据规则、再附件规则、最后综合规则,分析预测结果并进行反馈,根据反馈结果对模型进行优化;
S10、自动进入《规则库》:
样本训练测试通过后即可投入“综合评测”使用,测试通过后即可投入“综合评测”使用,更新或添加进《规则库》。
进一步的,所述步骤S5中,生成各《诊断单》的标题作为未来新规则名称时,借助于社会化专业的文章编辑器提取文章的标题,通过至少两个运算器相互印证,比如,使用Microsoft Word打开一个文档后,通过“文档结构”功能来查看文章的标题和内容,类似的文章编辑器还包括Google Docs、Pages。
进一步的,所述步骤S6中,社会化工具相互印证,如:Jieba中文分词工具,对文本进行分词、词性标注、关键词提取操作,它支持三种分词模式:精确模式、全模式和搜索引擎模式,Jieba采用TF-IDF算法,根据权重计算公式提取文本中的关键词;
TextRank无监督关键词提取算法,通过对文本中单词之间的共现关系进行分析,从而得到文本中的关键词,与TF-IDF算法不同,TextRank不需要预先定义关键词的权重,而是通过图论算法计算单词之间的相似度,并将相似度作为权重进行计算,TextRank算法适用于短文本和长文本的关键词提取。
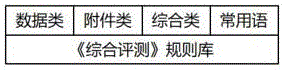
进一步的,所述步骤S7中,《规则库》包括:数据类规则;附件类规则;综合类规则;常用语规则,具体的,数据类规则:即“产品数据资料”评测规则,主要为《审核申请表》,包括:完整度检测规则;企业属性检测规则;数据检测规则;文字检测规则,对填报文字及数字类型进行审核的规则。
进一步的,所述附件类规则:即“产品文档资料”评测规则,包括:文档完整度检测规则;文档检测规则;文档数据提取规则,对上传为PDF格式(或图片)的附件材料进行审核的规则。
进一步的,所述综合类规则:即综合评测规则,产品数据与产品附件比较规则,对上述数据类与附件类进行交叉比较审核的规则。
进一步的,所述常用语规则:不属于上述三类的其他常见问题的审核规则,《退回意见》中便于描述的词语,如:其他自查、四舍五入、注意上传附件大小一致,便于专家查看。
进一步的,所述步骤S9中,《源数据》结构包括企业属性情况信息、主要情况数据、技术储备资源情况、人力资源明细情况、企业研究开发活动情况、企业近三年创新投入结构明细表、上年主要产品性能/指标情况、企业综合创新能力、企业参与国标/行标制定情况、科技成果转化情况、附件目录清单、企业人员情况相关材料、创新活动RD证明材料、近三年创新投入费用报告、近一年高品(服务)收入报告、成果转化证明材料、创新组织管理证明材料、近三年财务报告、近三年企业税表、企业人员比对、创新投入经费/创新活动/创新活动证明材料比对、高品数据/高品财务报告/高品检测报告等证明材料比对、创新组织管理与填报数据比对、成果转化/创新数据/高品数据比对、创新投入费/创新费用报告/财务报表/税表比对。
进一步的,所述企业属性情况信息包括企业名称;统一社会信用代码;注册资金;所属行业;企业规模;企业所得税征收方式;通信地址;企业法人信息;联系人信息;技术属性;股权结构;经营范围;企业简介等;
主要情况数据包括技术储备情况;人力资源情况;近三年经营情况包括净资产、销售收入、利润总额;近三年创新投入情况;近一年总收入;近一年高品收入。
系统,该系统包含有上述综合性多工序数据产品综合评测自主学习模型。
本发明提供了综合性多工序数据产品综合评测自主学习模型及系统,具备以下有益效果:
该综合性多工序数据产品综合评测自主学习模型及系统,具有自主学习的能力,在遍历了各种情况下的检测结果、检测方法,通过总结、提炼,补充更新自己的规则库,从而实现对一个综合性多工序数据产品的综合评测智能化,结果具有权威性,通用性。
附图说明
图1为本发明综合性多工序数据产品综合评测自主学习模型及系统的规则库结构示意图;
图2为本发明综合性多工序数据产品综合评测自主学习模型及系统的自我学习模型示意图。
具体实施方式
下面结合附图和实施例对本发明的实施方式作进一步详细描述。以下实施例用于说明本发明,但不能用来限制本发明的范围。
如图1-图2所示,本发明提供技术方案:综合性多工序数据产品综合评测自主学习模型,所述综合性多工序数据产品综合评测自主学习模型包括下述操作步骤:
S1、导入《专家评测意见表》:
于模型输入端导入《专家评测意见表》,《专家评测意见表》为多地、多年专家对综合性多工序数据产品综合评测的意见、报告,包括:财务上的和技术上的审核意见,以及客户或第三方历史《产品检测报告》等,《专家评测意见表》简称《病历本》,模型为自主学习模型也叫做自我学习模型;
S2、《病历本》分析训练:
对《病历本》进行全方位分析,包括结构、语言、内容等方面;
对《病历本》进行全方位分析时,根据《病历本》的属性采用不同的技术处理手段,如以下社会化工具:OCR、拆解王软件、智能拆解软件等;
S3、模块化拆分运算训练:
根据《病历本》的结构和内容特点,将全文分成若干独立“小模块”并训练,独立“小模块”简称《诊断单》,并进行完整度分析,分解为一条条具体的《诊断单》,即:问诊+评测意见;并进行语句完整、通顺优化;
实现分析拆解的工具为:拆解王软件、智能拆解软件等;
S4、内容优化训练:
对所有的独立《诊断单》进行相关度和重复度运算训练,利用Word sense插件、Google的自然语言搜索、维基百科等对《诊断单》的内容进行优化、“合并归类”、“去重”内容相近《诊断单》,使其更加精准、有深度,提高未来规则(包括《退回意见》)的可读性,“去重”的同时,重复度可作为加权因素提升《规则》的重要性;
S5、标题生成训练:
通过运算生成各《诊断单》的“标题”,作为未来新《规则》名称;
生成各《诊断单》的标题作为未来新规则名称时,借助于社会化专业的文章编辑器可以帮助我们提取文章的标题,多个运算器相互印证,比如,使用Microsoft Word打开一个文档后,可以通过“文档结构”功能来查看文章的标题和内容,类似的文章编辑器还包括Google Docs、Pages等;
S6、关键词优化训练:
运用社会化工具,从《诊断单》抽取适合的关键词,作为问诊关键字,并给出相应的优化建议,进一步完善《诊断单》的问诊能力,采用多种社会化工具相互印证,如:Jieba(结巴)中文分词工具,可以对文本进行分词、词性标注、关键词提取等操作,它支持三种分词模式:精确模式、全模式和搜索引擎模式,Jieba采用TF-IDF算法,可以根据一定的权重计算公式提取文本中的关键词;
TextRank无监督关键词提取算法,通过对文本中单词之间的共现关系进行分析,从而得到文本中的关键词,与TF-IDF算法不同,TextRank不需要预先定义关键词的权重,而是通过图论算法计算单词之间的相似度,并将相似度作为权重进行计算,TextRank算法适用于短文本和长文本的关键词提取;
S7、分类运算训练:
按《评测系统》《规则库》“树关系”对《诊断单》进行“分类”运算训练,确定新《规则》树节点位置和“内容”,包括:规则名、编号、问诊关键词、评测意见等,采用多种社会化工具相互印证,如:朴素贝叶斯分类器:使用基于贝叶斯定理的算法来分类文档,该算法假设每个单词都是相互独立的;支持向量机:该算法通过在特征空间中找到一个最优的超平面来分类文档;
《规则库》包括:数据类规则;附件类规则;综合类规则;常用语规则,具体的,数据类规则:即“产品数据资料”评测规则,主要为《审核申请表》。包括:完整度检测规则;企业属性检测规则;数据检测规则;文字检测规则。对填报文字及数字类型进行审核的规则;
附件类规则:即“产品文档资料”评测规则,包括:文档完整度检测规则;文档检测规则;文档数据提取规则,对上传为PDF格式(或图片)的附件材料进行审核的规则;
综合类规则:即综合评测规则,产品数据与产品附件比较规则,对上述数据类与附件类进行交叉比较审核的规则;
常用语规则:不属于上述三类的其他常见问题的审核规则,《退回意见》中便于描述的词语,如:其他自查、四舍五入、注意上传附件大小一致,便于专家查看等等;
S8、人工检查训练效果:
对训练过程进行人工验证,对训练结果进行专家论证,随着训练量的增加,并逐步减少人工干预,自主学习模型在线训练部分使用随机、空闲时自主训练,并存储算法模型训练时产生的训练信息及算法模型性能评估信息到自主学习模型数据库历次训练表、模型训练详情表、ROC曲线表中进行可视化展示;
S9、样本训练测试验证:
运用综合评测对象《源数据》(样本)对新规则进行训练,引用综合评测《源数据》先数据规则、再附件规则、最后综合规则,分析预测结果并进行反馈,根据反馈结果对模型进行优化;
《源数据》结构包括企业属性情况信息、主要情况数据、技术储备资源情况、人力资源明细情况、企业研究开发活动情况、企业近三年创新投入结构明细表、上年主要产品性能/指标情况、企业综合创新能力、企业参与国标/行标制定情况、科技成果转化情况、附件目录清单、企业人员情况相关材料、创新活动RD证明材料、近三年创新投入费用报告、近一年高品(服务)收入报告、成果转化证明材料、创新组织管理证明材料、近三年财务报告、近三年企业税表、企业人员比对、创新投入经费/创新活动/创新活动证明材料比对、高品数据/高品财务报告/高品检测报告等证明材料比对、创新组织管理与填报数据比对、成果转化/创新数据/高品数据比对、创新投入费/创新费用报告/财务报表/税表比对;
其中,企业属性情况信息包括企业名称;统一社会信用代码;注册资金;所属行业;企业规模;企业所得税征收方式;通信地址;企业法人信息;联系人信息;技术属性;股权结构;经营范围;企业简介等;
主要情况数据包括技术储备情况;人力资源情况;近三年经营情况(净资产、销售收入、利润总额);近三年创新投入情况;近一年总收入;近一年高品收入;
S10、自动进入《规则库》:
样本训练测试通过后即可投入“综合评测”使用,测试通过后即可投入“综合评测”使用,更新或添加进《规则库》。
系统,该系统包含有上述综合性多工序数据产品综合评测自主学习模型,。
该综合性多工序数据产品综合评测自主学习模型及系统,具有自主学习的能力,在遍历了各种情况下的检测结果、检测方法,通过总结、提炼,补充更新自己的规则库,从而实现对一个综合性多工序数据产品的综合评测智能化,结果具有权威性,通用性。
本发明的实施例是为了示例和描述起见而给出的,而并不是无遗漏的或者将本发明限于所公开的形式。很多修改和变化对于本领域的普通技术人员而言是显而易见的。选择和描述实施例是为了更好说明本发明的原理和实际应用,并且使本领域的普通技术人员能够理解本发明从而设计适于特定用途的带有各种修改的各种实施例。
- 电子雾化器的自动控温方法及具有该方法的电子雾化器
- 一种可自动控温的电子雾化器