一种基于机器学习的水流量预测系统和方法
文献发布时间:2023-06-19 10:21:15
技术领域
本发明属于洪水预测领域,具体涉及一种基于机器学习的水流量预测系统和方法。
背景技术
洪水是常见的自然灾害之一,每年有上亿人受洪水影响,流离失所,而洪水所造成的财力物力损失也非常巨大。有效地预测洪水流量并及时发出预警对于防洪减灾具有重大意义。
当前的洪水流量预测模型主要分为传统物理模型和智能洪水预测模型。传统物理模型例如新安江模型,其是在充分挖掘当地的地形地貌、蒸发量、植被覆盖率等物理特征的前提下,进行物理过程的参数计算,最终制定出的一套具有区域针对性的预测模型。而智能洪水预测模型是以海量的历史数据作为先验知识,利用机器学习等智能方法得到的从输入特征到输出特征的函数映射或者联合分布。
但现有的洪水流量预测模型多属于单点预测,即预测未来一个时间点的流量情况,而在实际情况中,预测得到的单个时间点的流量数据缺乏实际应用价值。
发明内容
本发明实施例的目的在于提供一种基于机器学习的水流量预测系统和方法,以实现对未来一个时间段进行洪水流量预测的目的。具体技术方案如下:
第一方面,本发明实施例提供了一种基于机器学习的水流量预测系统,所述系统包括:
包括N个站点端和一个预测端,其中所述N个站点端是预定流域的N个水文站点对应的终端,所述N个水文站点中有一个目标水文站点位于所述预定流域的出口断面处;
每个站点端,用于向所述预测端发送表征该水文站点历史K年各小时降雨数据的单端原始降雨数据,且所述目标水文站点对应的站点端还向所述预测端发送表征该目标水文站点历史K年各小时流量数据的原始流量数据;
预测端,用于获取所述单端原始降雨数据、所述原始流量数据和未来P小时各水文站点的先验降雨数据,并由获取到的所有单端原始降雨数据得到原始降雨数据;将所述原始降雨数据和所述原始流量数据进行预处理,分别得到处理后降雨数据和处理后流量数据;基于所述处理后降雨数据、所述处理后流量数据、所述先验降雨数据,构建输入数据;将所述输入数据输入预先训练得到的洪水流量预测模型进行循环迭代预测,每次迭代时对该次迭代的输入数据提取时序特征并进行分类预测,得到所述目标水文站点未来一小时的流量预测值,并利用得到的所述未来一小时的流量预测值,重新构建针对未来下一小时的迭代的输入数据,直至完成P次迭代,得到所述目标水文站点未来P小时的流量预测值;其中N、K和P为大于1的自然数。
可选的,所述预测端将所述原始降雨数据和所述原始流量数据进行预处理,分别得到处理后降雨数据和处理后流量数据,包括:
将所述原始降雨数据进行数据剔除和数据补全处理,得到补全降雨数据;
将所述补全降雨数据进行归一化处理,得到处理后降雨数据;
将所述原始流量数据进行归一化处理,得到处理后流量数据。
可选的,所述预测端将所述原始降雨数据进行数据剔除和数据补全处理,得到补全降雨数据,包括:
将所述原始降雨数据中,数据数目低于预设数量的水文站点所对应的数据剔除,得到剩余降雨数据;
对所述剩余降雨数据中缺失的降雨数据,利用反距离加权法进行数据补全,得到补全降雨数据。
可选的,所述预测端的归一化处理包括[0,1]归一化处理。
可选的,所述预测端基于所述处理后降雨数据、所述处理后流量数据、所述先验降雨数据,构建输入数据,包括:
基于所述处理后降雨数据,确定T小时中每小时对应的所述N个水文站点的第一归一化降雨总和数据;基于所述先验降雨数据,确定未来P小时中每小时对应的所述N个水文站点的第二归一化降雨总和数据,由所述第一归一化降雨总和数据与所述第二归一化降雨总和数据构成降雨数据分量;
从所述处理后流量数据中选取T小时对应的数据,与用0填充的未来P小时的所述目标水文站点的待预测流量数据构成流量数据分量;
由所述降雨数据分量和所述流量数据分量构成维度为[T+P,2]的输入数据,其中T为大于1的自然数,且T小于等于所述K年对应的小时数。
可选的,所述预测端将所述输入数据输入预先训练得到的洪水流量预测模型进行循环迭代预测,每次迭代时对该次迭代的输入数据提取时序特征并进行分类预测,得到所述目标水文站点未来一小时的流量预测值,并利用得到的所述未来一小时的流量预测值,重新构建针对未来下一小时的迭代的输入数据,包括:
针对第i次迭代,在该次迭代的输入数据中,对最新的T小时对应的降雨数据和流量数据利用所述洪水流量预测模型的三层一维卷积层提取时序特征,并利用所述洪水流量预测模型的三层全连接层进行分类预测,得到所述目标水文站点未来第i小时的流量预测值;
将所述未来第i小时的流量预测值存储在结果列表中,并在i小于P时,替换该次迭代的输入数据中,对应位置为0的流量数据,得到第i+1次迭代的输入数据,其中i=1,2,…,P。
可选的,所述预测端的所述洪水流量预测模型中,三层一维卷积层的卷积核数量分别为50、30、10;所述三层一维卷积层的卷积核大小均为5×2;所述三层全连接层的神经元数量分别为10、10、1。
可选的,所述预测端在得到所述目标水文站点未来P小时的流量预测值之后,还用于:
向所述目标水文站点对应的站点端发送所述目标水文站点未来P小时的流量预测值。
可选的,所述预测端为所述目标水文站点对应的站点端。
第二方面,本发明实施例提供了一种基于机器学习的水流量预测方法,应用于基于机器学习的水流量预测系统中的预测端,所述基于机器学习的水流量预测系统还包括N个站点端,其中,所述N个站点端是预定流域的N个水文站点对应的终端,所述N个水文站点中有一个目标水文站点位于所述预定流域的出口断面处;每个站点端向所述预测端发送表征该水文站点历史K年各小时降雨数据的单端原始降雨数据,且所述目标水文站点对应的站点端还向所述预测端发送表征该目标水文站点历史K年各小时流量数据的原始流量数据;所述方法包括:
获取所述单端原始降雨数据、所述原始流量数据和未来P小时各水文站点的先验降雨数据,并由获取到的所有单端原始降雨数据得到原始降雨数据;将所述原始降雨数据和所述原始流量数据进行预处理,分别得到处理后降雨数据和处理后流量数据;基于所述处理后降雨数据、所述处理后流量数据、所述先验降雨数据,构建输入数据;将所述输入数据输入预先训练得到的洪水流量预测模型进行循环迭代预测,每次迭代时对该次迭代的输入数据提取时序特征并进行分类预测,得到所述目标水文站点未来一小时的流量预测值,并利用得到的所述未来一小时的流量预测值,重新构建针对未来下一小时的迭代的输入数据,直至完成P次迭代,得到所述目标水文站点未来P小时的流量预测值;其中N、K和P为大于1的自然数。
本发明实施例所提供的基于机器学习的水流量预测系统中,预测端基于循环递归方法论建立洪水流量预测模型,利用历史数据中多年的降雨数据、流量数据,以及未来P小时的先验降雨数据构建预训练的洪水流量预测模型的输入数据,通过多次循环迭代,用每次预测得到的未来一小时的流量预测值构建未来下一小时迭代的输入数据,通过P次迭代,可以由模型一次性输出未来P小时的流量预测值,从而实现未来一个时间段的洪水流量预测的目的。
附图说明
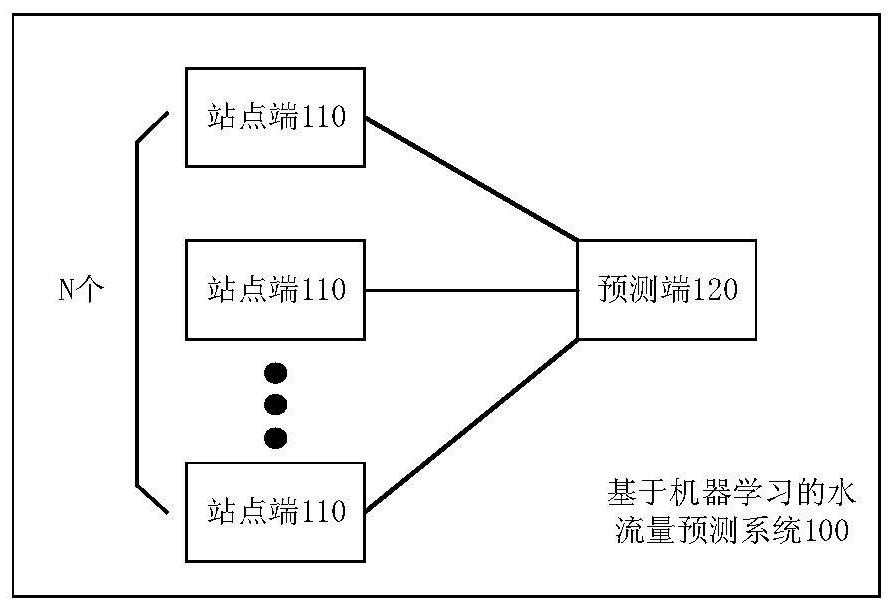
图1为本发明实施例所提供的一种基于机器学习的水流量预测系统的结构示意图;
图2为本发明实施例所提供的基于机器学习的水流量预测系统的预测端的结构示意图;
图3为本发明实施例的输入数据的示例图;
图4为本发明实施例的洪水流量预测模型的结构示意图;
图5为本发明实施例的预测过程示意图;
图6为本发明实施例的洪水峰值预测效果对比图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
为了实现对未来一个时间段进行洪水流量预测的目的,本发明实施例提供了一种基于机器学习的水流量预测系统和方法。
下面,首先对本发明实施例所提供的一种基于机器学习的水流量预测系统进行介绍。
第一方面,如图1所示,本发明实施例所提供的一种基于机器学习的水流量预测系统100,可以包括N个站点端110和一个预测端120。
其中,N个站点端110是预定流域的N个水文站点对应的终端,N个水文站点中有一个目标水文站点位于预定流域的出口断面处。
每个站点端110,用于向预测端120发送表征该水文站点历史K年各小时降雨数据的单端原始降雨数据,且目标水文站点对应的站点端110还向预测端120发送表征该目标水文站点历史K年各小时流量数据的原始流量数据。
预测端120,用于获取单端原始降雨数据、原始流量数据和未来P小时各水文站点的先验降雨数据,并由获取到的所有单端原始降雨数据得到原始降雨数据;将原始降雨数据和原始流量数据进行预处理,分别得到处理后降雨数据和处理后流量数据;基于处理后降雨数据、处理后流量数据、先验降雨数据,构建输入数据;将输入数据输入预先训练得到的洪水流量预测模型进行循环迭代预测,每次迭代时对该次迭代的输入数据提取时序特征并进行分类预测,得到目标水文站点未来一小时的流量预测值,并利用得到的未来一小时的流量预测值,重新构建针对未来下一小时的迭代的输入数据,直至完成P次迭代,得到目标水文站点未来P小时的流量预测值;其中N、K和P为大于1的自然数。
以下针对各部分分别进行说明:
1)针对站点端110:
预定流域是一个地理区域,在该地理区域内包含N个水文站点,用于监测降雨情况,N个水文站点中有一个目标水文站点位于预定流域的出口断面,用于监测该预定流域出口断面的水位及流量的变化情况。
每个水文站点记录并存储有该水文站点在每小时的降雨数据,目标水文站点还记录并存储有该目标水文站点在每小时的流量数据。水文站点可以将上述降雨数据或者流量数据存储在对应的站点端110中。站点端110可以是一个处理器或者其余电子设备等。或者,水文站点也可以将上述降雨数据或者流量数据存储在与对应的站点端110具有通信连接的一个存储地址中,这都是合理的。
每个站点端110可以在响应于预测端120的一个数据请求之后,从存储的降雨数据中,提取该水文站点在历史K年中每小时的降雨数据形成单端原始降雨数据,并向预测端120发送;并且目标水文站点对应的站点端110还可以从存储的流量数据中提取该目标水文站点在历史K年中每小时的流量数据形成原始流量数据,并向预测端120发送。
作为优选的实施方案,历史K年可以为历史数据中,距离当前时间最近的连续K年。
2)针对预测端120:
参见图2,图2为本发明实施例所提供的基于机器学习的水流量预测系统的预测端的结构示意图;预测端120可以包括数据确定模块1201、数据预处理模块1202、输入数据构建模块1203以及模型预测模块1204。以下分别介绍各个模块的具体工作过程。
①数据确定模块1201,用于获取单端原始降雨数据、原始流量数据和未来P小时各水文站点的先验降雨数据,并由获取到的所有单端原始降雨数据得到原始降雨数据。
数据确定模块1201将获取到的所有单端原始降雨数据依据时间进行合并整合,并计算每小时所有水文站点的降雨总和数据,从而得到原始降雨数据。
作为本发明实施例的具体示例,选择中国河南省的息县流域作为预定流域,息县流域共有50个水文站点,时间范围可以选择为2013年~2018年,即N=50,K=6。数据确定模块1201得到的原始降雨数据和原始流量数据的示例如表1和表2所示,因作为形式示例,具体数值不进行示出。其中,TM为时间戳,以一小时为单位;S1~S50表示50个水文站点的降雨数据;SUM表示50个水文站点的降雨总和数据。Q表示目标水文站点的流量数据,S1~S50、SUM、Q均以毫米为单位。
表1原始降雨数据示例表
表2原始流量数据示例表
本领域技术人员可以理解的是,表1示例的原始降雨数据的整个表格维度为[(6×365×24+1),52]=[52561,52]。表2示例的原始流量数据的整个表格维度为[52561,2]。
数据确定模块1201除了从站点端获取单端原始降雨数据、原始流量数据之外,还可以通过天气预报等手段,获取未来P小时各水文站点的先验降雨数据。未来P小时即为需要预测的未来时间段。比如P可以为24小时等。
②数据预处理模块1202,用于将原始降雨数据和原始流量数据进行预处理,分别得到处理后降雨数据和处理后流量数据。
可选的,数据预处理模块1202可以包括剔除补全子模块和归一化子模块。
剔除补全子模块,用于将原始降雨数据进行数据剔除和数据补全处理,得到补全降雨数据;
在实际中,由于疏漏等原因,水文站点的降雨数据可能存在缺失,可以理解的是,如果使用缺失数据过多的原始降雨数据进行计算,会影响后续预测的准确性,因此,在该步骤中,首先需要对缺失数据过多的水文站点的数据进行剔除。
剔除补全子模块具体用于以下(1)和(2):
(1),将原始降雨数据中,数据数目低于预设数量的水文站点所对应的数据剔除,得到剩余降雨数据;
比如针对表1的原始降雨数据,如果某一个水文站点的降雨数据的数目低于预设数量30000,则表明现存数据比例已经小于3520500600×100%=57%,意味着数据缺失近半数,对于如此多的缺失数据,没有必要在后续进行缺失值补全。因为如果对其进行缺失值补全,将会引入过多人工因素,使得模型泛化能力下降。使得最终神经网络学习到的规律不符合真实的数据关系。因此,可以将缺失数据较多的水文站点所对应的数据剔除,保留优选水文站点的降雨数据,得到剩余降雨数据。
关于预设数量可以根据原始降雨数据的维度以及数据精度的需要进行合理选择。
(2),对剩余降雨数据中缺失的降雨数据,利用反距离加权法进行数据补全,得到补全降雨数据。
本领域技术人员可以理解的是,在剩余降雨数据中仍会有一些时间点的降雨数据存在缺失,可以使用缺失值补全算法对缺失的降雨数据进行补全。
其中,反距离加权算法(Inverse Distance Weighted,IDW)是缺失值补全的经典算法。反距离加权算法按照距离越远,相关性越小的原则,使用临近水文站点的降雨数据来对某一水文站点的缺失降雨数据进行补全。反距离加权算法的公式如下公式(1)所示。
其中,x为出现数据缺失的水文站点的降雨数据估计值;M为参与计算的水文站点个数;x
利用上述反距离加权算法可以对剩余降雨数据中缺失降雨数据的水文站点的降雨数据补全,并得到完整的降雨量总和数据,从而得到补全降雨数据。即表1中的数据得以完整填充。
归一化子模块用于将补全降雨数据进行归一化处理,得到处理后降雨数据。以及,将原始流量数据进行归一化处理,得到处理后流量数据。
归一化是一种无量纲处理手段,使物理系统数值的绝对值变成某种相对值关系。是简化计算,缩小量值的有效办法。通过合适的归一化处理,可以加快梯度下降求最优解的速度,降低模型参数数值大小,加快模型训练过程中的收敛速度,改善模型的性能,提高精度。
常用的归一化方法包括:min-max标准化、标准差标准化、非线性归一化等。由于降雨数据和流量数据并不满足正态分布,因此,本发明实施例优选的实施方案中,归一化处理包括[0,1]归一化处理。
[0,1]归一化处理属于min-max标准化,其通过对数据的每一个维度的值进行重新调节,使得最终的数据向量落在[0,1]之间。[0,1]归一化处理具体公式如下公式(2)所示。
其中,y
通过上述[0,1]归一化处理,可以对补全降雨数据中所有水文站点的降雨数据进行归一化处理,并对降雨总和数据进行单独的归一化处理。得到补全降雨数据进行归一化处理后的处理后降雨数据。以及得到原始流量数据进行归一化处理后的处理后流量数据。
③输入数据构建模块1203,用于基于处理后降雨数据、处理后流量数据、先验降雨数据,构建输入数据。
可选的实施方式中,输入数据构建模块1203可以包括降雨数据分量构建子模块、流量数据分量构建子模块和输入数据构建子模块。
降雨数据分量构建子模块,用于基于处理后降雨数据,确定T小时中每小时对应的N个水文站点的第一归一化降雨总和数据;基于先验降雨数据,确定未来P小时中每小时对应的N个水文站点的第二归一化降雨总和数据,由第一归一化降雨总和数据与第二归一化降雨总和数据构成降雨数据分量;其中T为大于1的自然数,且T小于等于K年对应的小时数。即T≤K×365×24,比如T可以为100小时等等。且优选的实施方式中T小时为距离当前时间最近的连续T小时。
通过前面步骤的处理,从处理后降雨数据中可以获得N个水文站点在过去的T小时中每个小时的归一化的降雨总和数据,本发明实施例为了区别将其命名为第一归一化降雨总和数据。
本发明实施例对先验降雨数据中每个小时,求取所有水文站点的降雨数据之和,即每小时的降雨总和数据,再对P个降雨总和数据进行归一化处理,从而得到未来P小时中每小时对应的所有水文站点的归一化的降雨总和数据,本发明实施例将其命名为第二归一化降雨总和数据。
然后,由第一归一化降雨总和数据与第二归一化降雨总和数据依据时间先后顺序排列,构成维度为[T+P,1]的降雨数据分量。
流量数据分量构建子模块,用于从处理后流量数据中选取T小时对应的数据,与用0填充的未来P小时的目标水文站点的待预测流量数据构成流量数据分量;
由于未来P小时的目标水文站点的流量数据是需要预测的数据,为了与降雨数据分量保持一致的数据维度,可以先用0填充该部分数据。从处理后流量数据中选取T小时对应的数据,与用0填充的未来P小时的目标水文站点的待预测流量数据依据时间先后顺序排列,构成维度为[T+P,1]的流量数据分量;
输入数据构建子模块,用于由降雨数据分量和流量数据分量构成维度为[T+P,2]的输入数据。
为了便于理解输入数据的形式,请参见图3,图3为本发明实施例的输入数据的示例图。该图仅作为形式示例,具体数据不进行示出。其中0表示当前时刻。可以理解的是,所得到的输入数据为一个向量,维度为[T+P,2]。需要说明的是,图3中的文字说明进行了简化示意。图3中下行左右分别为第一归一化降雨总和数据和第二归一化降雨总和数据。
本发明实施例中,降雨数据分量构建子模块、流量数据分量构建子模块并行设置,并均与输入数据构建子模块连接。
④模型预测模块1204,用于将输入数据输入预先训练得到的洪水流量预测模型进行循环迭代预测,每次迭代时对该次迭代的输入数据提取时序特征并进行分类预测,得到目标水文站点未来一小时的流量预测值,并利用得到的未来一小时的流量预测值,重新构建针对未来下一小时的迭代的输入数据,直至完成P次迭代,得到目标水文站点未来P小时的流量预测值。
模型预测模块1204内置有预先训练得到的洪水流量预测模型。为了便于理解本发明实施例的预测过程,首先,对本发明实施例的洪水流量预测模型的结构和训练过程予以介绍。
本发明实施例为了实现未来一个时间段的洪水流量预测,在循环递归方法论的基础上,利用一维卷积提出具体的洪水流量预测模型。
其中,循环递归方法论如下公式(3)所示。
针对于本发明实施例,公式(3)中的[q
一维卷积指的是在给定的输入数据上进行一个维度上的卷积核移动计算,一个卷积核得到的输出是一个一维向量。一维卷积主要应用在时间序列的分析上,而在洪水预测任务中,作为输入数据的降雨量和流量都是具有很明显时序关系的数据。因此使用一维卷积对其进行特征提取较为合适。而且相比于在时间序列分析领域同样出色的LSTM结构的网络来说,其结构更简单,运算更快。
本发明实施例基于python搭建洪水流量预测模型,包括三层一维卷积层和三层全连接层,具体结构如图4所示,图4为本发明实施例的洪水流量预测模型的结构示意图。其中,Conv1D表示一维卷积层,Dense表示全连接层。具体各层的参数见表3。
表3洪水流量预测模型的层参数
洪水流量预测模型是利用N个水文站点的历史数据中,在前的T小时的降雨数据、流量数据,以及在后的P小时的降雨数据和流量数据循环迭代训练得到的。
比如,可以利用历史数据中2013至2017年的100小时的降雨数据和流量数据、针对待预测时间段为24小时的已知的降雨数据,构建样本输入数据(参考前文)。以针对待预测时间段为24小时的已知的流量数据作为真值,进行循环迭代训练,比如迭代达到100次,直至获得训练好的模型参数,即得到训练完成的洪水流量预测模型。关于模型训练过程概述为如下步骤。
1)将样本输入数据中每一样本数据和对应的真值,通过如图3结构所示的初始的网络模型进行训练,获得各样本数据的训练结果。
2)将每一样本数据的训练结果与该样本数据对应的真值进行比较,得到该样本数据对应的预测结果。
3)根据各个样本数据对应的预测结果,计算网络模型的损失值。
4)根据损失值调整网络模型的参数,并重新进行1)-3)步骤,直至网络模型的损失值达到了一定的收敛条件,也就是损失值达到最小,这时,意味着每一样本数据的训练结果与该样本数据对应的真值一致,从而完成网络模型的训练,得到训练完成的洪水流量预测模型。
具体的,训练过程采用Adam(Adaptive moment estimation)梯度下降的优化算法,以获得较好的损失下降过程。损失函数采用MSE(mean-square error,均方误差)。学习率为0.01。同时,添加了dropout操作,Dropout是一种在深度学习环境中应用的参数正则化手段。可以作为训练深度神经网络的一种trick供选择。在每个训练批次中,通过忽略一半的特征检测器(让一半的隐层节点值为0),可以明显地减少过拟合现象。
在训练完成后,可以将待预测的输入数据输入预先训练得到的洪水流量预测模型进行循环迭代预测。具体的,模型预测模块1204用于:
针对第i次迭代,在该次迭代的输入数据中,对最新的T小时对应的降雨数据和流量数据利用洪水流量预测模型的三层一维卷积层提取时序特征,并利用洪水流量预测模型的三层全连接层进行分类预测,得到目标水文站点未来第i小时的流量预测值;
将未来第i小时的流量预测值存储在结果列表中,并在i小于P时,替换该次迭代的输入数据中,对应位置为0的流量数据,得到第i+1次迭代的输入数据,其中i=1,2,…,P。
具体过程可以参见图5,图5为本发明实施例的预测过程示意图。以T=100,P=24,N=50为例说明。
将维度为[124,2]的输入数据输入洪水流量预测模型作为第1次迭代的输入数据,当i=1时,即第1次迭代时,具体选用最新的T小时对应的数据,即100小时的流量数据和降雨数据参与迭代。对其利用三层一维卷积层提取时序特征,并利用三层全连接层进行分类预测,得到未来第1小时的流量预测值,存储在结果列表中;并且此时判定i<24,则利用未来第1小时的流量预测值重构关于第2次迭代的输入数据。具体的,将原先输入数据中填充为0的未来第1小时的流量预测值替换为第1次迭代预测得到的未来第1小时的流量预测值,即图4中的黑色矩形部分,便得到可用于第2次迭代的输入数据。当i=2时,即第2次迭代时,在更新的输入数据中,仍选用最新的100小时对应的数据,可以形象化的理解为虚线框所示的100小时数据向右移一个数据列,摒弃掉针对第1次迭代的输入数据的最左侧数据。即每次用预测得到的流量预测值用于下一次迭代的预测过程,并保持每次迭代的数据维度不变。如此循环迭代,直至完成24小时的预测。针对本发明实施例的洪水流量预测模型,可以由结果列表一次性得到未来24小时的流量预测值,实现未来一个时间段的洪水流量预测。
在图5中标记有各层处理后的数据维度,以便于理解数据变化。关于一维卷积层和全连接层的具体处理过程请参见现有技术理解,在此不再赘述。
具体预测结果请参见图6,图6为本发明实施例的洪水峰值预测效果对比图。其中,flow为洪水峰值,单位为毫米。time为时间,单位h表示小时。real-q为洪水峰值的真实值,pred-q为洪水峰值的预测值,可以看到,利用本发明实施例的基于机器学习的水流量预测方法可以获得较为精确的预测结果。
可以理解的是,通过本发明实施例的洪水流量预测模型得到的流量预测值也是归一化的数据,之后,可选的,可以利用相应的数据处理,得到与真实测量得到的流量值同一数据规格的数值。对此不再赘述。
可选的实施方式中,预测端120还可以包括输出模块,输出模块可以将得到的目标水文站点未来P小时的流量预测值进行输出,比如发送给另一设备或者进行显示,如显示在预定电子设备的显示屏上等等。
可选的实施方式中,预测端120在得到目标水文站点未来P小时的流量预测值之后,还用于:
向目标水文站点对应的站点端110发送目标水文站点未来P小时的流量预测值。其中,该过程可以由预测端120的一个发送模块执行。
可选的实施方式中,预测端120还可以将得到的目标水文站点未来P小时的流量预测值与预定阈值进行比较,当目标水文站点未来P小时的流量预测值大于等于预定阈值时,发出警示信息。其中,该过程可以由预测端120的一个报警模块执行。
可选的实施方式中,预测端120为目标水文站点对应的站点端110。
也就是说,目标水文站点对应的站点端接收其余水文站点发送的单端原始降雨数据,并结合自身的单端原始降雨数据和原始流量数据进行预测。因此,可以省去目标水文站点向外发送数据的环节,提高处理速度。
本发明实施例所提供的基于机器学习的水流量预测系统中,预测端基于循环递归方法论建立洪水流量预测模型,利用历史数据中多年的降雨数据、流量数据,以及未来P小时的先验降雨数据构建预训练的洪水流量预测模型的输入数据,通过多次循环迭代,用每次预测得到的未来一小时的流量预测值构建未来下一小时迭代的输入数据,通过P次迭代,可以由模型一次性输出未来P小时的流量预测值,从而实现未来一个时间段的洪水流量预测的目的。
第二方面,本发明实施例还提供了一种基于机器学习的水流量预测方法,应用于基于机器学习的水流量预测系统中的预测端,基于机器学习的水流量预测系统还包括N个站点端,其中,N个站点端是预定流域的N个水文站点对应的终端,N个水文站点中有一个目标水文站点位于预定流域的出口断面处;每个站点端向预测端发送表征该水文站点历史K年各小时降雨数据的单端原始降雨数据,且目标水文站点对应的站点端还向预测端发送表征该目标水文站点历史K年各小时流量数据的原始流量数据;方法包括:
获取单端原始降雨数据、原始流量数据和未来P小时各水文站点的先验降雨数据,并由获取到的所有单端原始降雨数据得到原始降雨数据;将原始降雨数据和原始流量数据进行预处理,分别得到处理后降雨数据和处理后流量数据;基于处理后降雨数据、处理后流量数据、先验降雨数据,构建输入数据;将输入数据输入预先训练得到的洪水流量预测模型进行循环迭代预测,每次迭代时对该次迭代的输入数据提取时序特征并进行分类预测,得到目标水文站点未来一小时的流量预测值,并利用得到的未来一小时的流量预测值,重新构建针对未来下一小时的迭代的输入数据,直至完成P次迭代,得到目标水文站点未来P小时的流量预测值;其中N、K和P为大于1的自然数。
其中,本发明实施例中的基于机器学习的水流量预测系统即为第一方面的系统。
可选的,将原始降雨数据和原始流量数据进行预处理,分别得到处理后降雨数据和处理后流量数据,包括:
将原始降雨数据进行数据剔除和数据补全处理,得到补全降雨数据;
将补全降雨数据进行归一化处理,得到处理后降雨数据;
将原始流量数据进行归一化处理,得到处理后流量数据。
可选的,将原始降雨数据进行数据剔除和数据补全处理,得到补全降雨数据,包括:
将原始降雨数据中,数据数目低于预设数量的水文站点所对应的数据剔除,得到剩余降雨数据;
对剩余降雨数据中缺失的降雨数据,利用反距离加权法进行数据补全,得到补全降雨数据。
可选的,的归一化处理包括[0,1]归一化处理。
可选的,基于处理后降雨数据、处理后流量数据、先验降雨数据,构建输入数据,包括:
基于处理后降雨数据,确定T小时中每小时对应的N个水文站点的第一归一化降雨总和数据;基于先验降雨数据,确定未来P小时中每小时对应的N个水文站点的第二归一化降雨总和数据,由第一归一化降雨总和数据与第二归一化降雨总和数据构成降雨数据分量;
从处理后流量数据中选取T小时对应的数据,与用0填充的未来P小时的目标水文站点的待预测流量数据构成流量数据分量;
由降雨数据分量和流量数据分量构成维度为[T+P,2]的输入数据,其中T为大于1的自然数,且T小于等于K年对应的小时数。
可选的,将输入数据输入预先训练得到的洪水流量预测模型进行循环迭代预测,每次迭代时对该次迭代的输入数据提取时序特征并进行分类预测,得到目标水文站点未来一小时的流量预测值,并利用得到的未来一小时的流量预测值,重新构建针对未来下一小时的迭代的输入数据,包括:
针对第i次迭代,在该次迭代的输入数据中,对最新的T小时对应的降雨数据和流量数据利用洪水流量预测模型的三层一维卷积层提取时序特征,并利用洪水流量预测模型的三层全连接层进行分类预测,得到目标水文站点未来第i小时的流量预测值;
将未来第i小时的流量预测值存储在结果列表中,并在i小于P时,替换该次迭代的输入数据中,对应位置为0的流量数据,得到第i+1次迭代的输入数据,其中i=1,2,…,P。
可选的,三层一维卷积层的卷积核数量分别为50、30、10;三层一维卷积层的卷积核大小均为5×2;三层全连接层的神经元数量分别为10、10、1。
可选的,在得到目标水文站点未来P小时的流量预测值之后,方法还包括:
向目标水文站点对应的站点端发送目标水文站点未来P小时的流量预测值。
可选的,预测端为目标水文站点对应的站点端。
关于各部分的具体内容请参见第一方面的描述,在此不再赘述。
本发明实施例所提供的方案中,预测端基于循环递归方法论建立洪水流量预测模型,利用历史数据中多年的降雨数据、流量数据,以及未来P小时的先验降雨数据构建预训练的洪水流量预测模型的输入数据,通过多次循环迭代,用每次预测得到的未来一小时的流量预测值构建未来下一小时迭代的输入数据,通过P次迭代,可以由模型一次性输出未来P小时的流量预测值,从而实现未来一个时间段的洪水流量预测的目的。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括要素的过程、方法、物品或者设备中还存在另外的相同要素。
以上仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所作的任何修改、等同替换、改进等,均包含在本发明的保护范围内。
- 一种基于机器学习的水流量预测系统和方法
- 基于深度学习的洪水流量预测系统和方法