机器学习系统及其资源配置方法
文献发布时间:2023-06-19 10:38:35
技术领域
本公开关于一种资源配置方法。
背景技术
机器学习(Machine Learning)算法是一种依据资料进行自动分析以获得规律,再利用规律对未知资料进行预测的算法。具体来说,应用机器学习算法的系统可以使用训练资料集(Dataset)来训练模型,而训练好的模型便可用来对新资料进行预测。为了使训练出来的模型可以具有较佳的准确率,在训练模型之前需要先探索模型的超参数(Hyperparameters)。
所谓超参数是指模型外部的配置,其数值不能在训练模型的过程中取得,而需大量反复试验才得以找到适合的数值,也就是说,在有限时间内所执行的试验数量越多,便越有机会取得好的数值。
公开内容
鉴于上述,本公开提供一种机器学习系统及其资源配置方法。
依据本公开一实施例的资源配置方法,适用于机器学习系统,且包含:以机器学习系统的资源占用量执行至少一第一实验,其中每一第一实验具有第一最低资源需求量,接收关联于目标资料集的实验需求,依据目标资料集决定第二实验,并决定第二实验的第二最低资源需求量,当机器学习系统的总资源量满足第一最低资源需求量及第二最低资源需求量的和且总资源量与资源占用量的差满足第二最低资源需求量时,配置第二最低资源需求量执行第二实验,以及判断机器学习系统具有闲置资源量,并选择性地将闲置资源量配置给所述至少一第一实验及该第二实验中至少一个。
依据本公开一实施例的机器学习系统,包含输入界面、机器学习模型训练执行器、实验产生器、实验排程器及动态资源配置器,其中实验产生器连接于输入界面,实验排程器连接于实验产生器及机器学习模型训练执行器,且动态资源配置器连接于机器学习模型训练执行器。输入界面用于接收关联于目标资料集的实验需求。机器学习模型训练执行器用于以资源占用量执行至少一第一实验,其中每一第一实验具有第一最低资源需求量。实验产生器用于依据目标资料集决定第二实验并决定第二实验的第二最低资源需求量。实验排程器用于在判断机器学习模型训练执行器的总资源量满足第一最低资源需求量及第二最低资源需求量的和且总资源量与资源占用量的差满足第二最低资源需求量时,配置机器学习模型训练执行器以第二最低资源需求量执行第二实验。动态资源配置器用于判断机器学习模型训练执行器具有闲置资源量,并选择性地将闲置资源量配置给所述至少一第一实验及第二实验中至少一个。
通过上述结构,本公开的机器学习系统及其资源配置方法可以依据实验需求自动产生实验设定并建议实验最低资源需求量,先以最低资源需求量执行实验再进行动态配置,且可进行不同实验间的资源调配,使得系统的运算资源可以维持在较佳的执行效率,进而提升有限时间内实验的子实验的完成数量。
以上关于本公开内容的说明及以下实施方式的说明用以示范与解释本公开的精神与原理,并且提供本公开的专利申请范围更进一步的解释。
附图说明
图1为依据本公开一实施例所示的机器学习系统的功能框图。
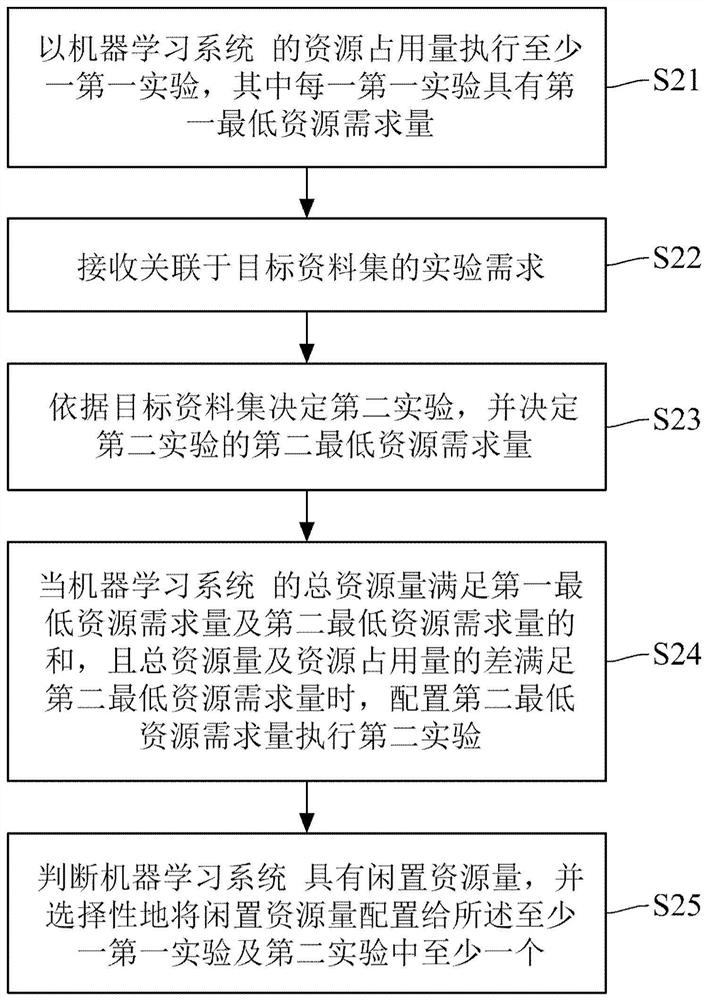
图2为依据本公开一实施例所示的机器学习系统的资源配置方法的流程图。
图3为依据本公开另一实施例所示的资源配置方法的流程图。
图4A及4B分别示例性地示出两种实验的执行效率资料。
图5为依据本公开一实施例所示的资料初始化及收集程序的流程图。
图6为依据本公开又一实施例所示的资源配置方法的流程图。
图7A~图7C分别呈现在三种实验执行情境中,现有资源配置方法与本公开多个实施例的资源配置方法的执行表现比较图。
具体实施方式
以下在实施方式中详细叙述本公开的详细特征以及优点,其内容足以使本领域的技术人员了解本公开的技术内容并据以实施,且根据本说明书所公开的内容、申请专利范围及图式,任何本领域的技术人员可轻易地理解本公开相关的目的及优点。以下实施例进一步详细说明本公开的观点,但非以任何观点限制本公开的范畴。
请参考图1,图1为依据本公开一实施例所示的机器学习系统的功能框图。如图1所示,机器学习系统1可以包含输入界面11、实验产生器12、实验排程器13、机器学习模型训练执行器14、动态资源配置器15、数据库16及输出界面17,其中实验产生器12连接于输入界面11、实验排程器13及数据库16,机器学习模型训练执行器14连接于实验排程器13、动态资源配置器15及输出界面17。
机器学习系统1可以通过输入界面11接收关联于目标资料集(Dataset)的实验需求,通过实验产生器12依据目标资料集决定目标实验及目标实验的最低资源需求量。其中,目标资料集表示欲用来训练机器学习模型的资料集。进一步来说,数据库16可以预存多种实验(包含目标实验)的执行效率资料,实验产生器12可以依据目标实验的执行效率资料来决定目标实验的最低资源需求量,详细资料内容集决定方式将于后描述。机器学习系统1可以通过实验排程器13判断机器学习模型训练执行器14的资源量是否足够执行目标实验,其中所述资源量例如中央处理单元(Central Processing Unit,CPU)数量、多核心CPU的核心数量。
目标实验可能非为机器学习模型训练执行器14第一个执行的实验,也就是说,机器学习模型训练执行器14可能在其他当前正在执行的实验(至少一第一实验)的状况下被判定所剩的资源量是否足够执行目标实验(第二实验)。因此,实验排程器13可以先判断机器学习模型训练执行器14的总资源量是否满足所述至少一第一实验的最低资源需求量(第一最低资源需求量)与第二实验的最低资源需求量(第二最低资源需求量)的和,再判断机器学习模型训练执行器14的总资源量扣掉当前用于执行所述至少一第一实验的资源占用量的剩余资源量(即总资源量与资源占用量的差)是否满足第二最低资源需求量,以判断机器学习模型训练执行器14的资源量是否足够执行第二实验。
当判断机器学习模型训练执行器14的总资源量满足第一最低资源需求量及第二最低资源需求量的和,且总资源量与资源占用量的差满足第二最低资源需求量时,即判断机器学习模型训练执行器14的资源量足够执行第二实验时,机器学习系统1可以通过实验排程器13配置机器学习模型训练执行器14以第二资源需求量执行第二实验,即使用目标资料集训练机器学习模型,并在第二实验执行完成后通过输出界面17输出实验结果,例如是已训练好的机器学习模型。在实验执行的过程中,机器学习系统1可以通过动态资源配置器15周期性地(例如每2、5或10分钟一次)判断机器学习模型训练执行器14是否具有一闲置资源量,当有的时候,便选择性地将闲置资源量配置给所述至少一第一实验及第二实验中的一个,即配置给机器学习模型训练执行器14当前正在执行的其他实验或目标实验。其中,所述闲置资源量意指未执行任何作业的CPU或CPU核心的数量。
进一步来说明实施机器学习系统1的各装置的硬件。输入界面11例如为键盘、鼠标、触控荧幕等输入设备,以供使用者输入实验需求。实验产生器12、实验排程器13及动态资源配置器15可以由同个处理器或多个处理器来实施,其中所谓处理器例如为CPU、微控制器、可程序化逻辑控制器(Programmable Logic Controller,PLC)等。机器学习模型训练执行器14则包含自建运算环境的CPU资源或是利用云端运算环境的CPU资源来运作,所述CPU资源为不同于实验产生器12、实验排程器13及动态资源配置器15的多个CPU或多核心CPU。实验产生器12、实验排程器13及动态资源配置器15为设定及监控机器学习模型训练执行器14的资源使用状态的组合,详细的设定及监控方法将于后描述。数据库16例如为唯读存储器(Read-only Memory,ROM)、快闪存储器等非挥发性存储器,可以储存上述设定及监控所需要的参考资料,例如多个实验的执行效率资料、多个资料集的描述等,详细的资料内容将于后描述。特别来说,数据库16除了连接于实验产生器12,还可以连接于实验排程器13或/和动态资源配置器15,以供三者执行设定及监控时索取需要的参考资料。或者,数据库16可以为作为实验产生器12、实验排程器13及动态资源配置器15的处理器的内建存储器。输出界面17例如为荧幕或其他输出设备,用于输出机器学习模型训练执行器14的执行结果。
请一并参考图1及图2,图2为依据本公开一实施例所示的机器学习系统的资源配置方法的流程图。图2所示的资源配置方法适用于图1所示的机器学习系统1,但不限于此。如图2所示,资源配置方法包含步骤S11:接收关联于目标资料集的实验需求;步骤S12:依据目标资料集决定至少一目标实验及目标实验的最低资源需求量;步骤S13:判断机器学习系统的资源量是否足够执行目标实验;当判断结果为是时,执行步骤S14:配置目标实验的最低资源需求量以执行目标实验;当判断结果为否时,执行步骤S15:不执行目标实验或减少其他实验的资源占用量直至足够执行目标实验;还包含步骤S16:判断机器学习系统具有闲置资源量,并选择性地配置闲置资源量。以下示例性地以图1所示的机器学习系统1的装置来进一步说明资源配置方法的各种实施态样。
于步骤S11中,输入界面11可以接收关联于目标资料集的实验需求。其中,实验需求包含用以训练机器学习模型的目标资料集。进一步来说,使用者可以预先将多个资料集的档案上传至一档案系统(可称为Dataset Store),目标资料集的描述则可储存于数据库16中。使用者在欲使用目标资料集来训练机器学习模型时,可以通过输入界面11输入目标资料集的选择指令,实验产生器12再依据此选择指令向档案系统索取目标资料集的档案,档案系统再据以于数据库16查找目标资料集的描述。或者,使用者可以直接通过输入界面11提供目标资料集的档案给机器学习系统1。目标资料集例如为CSV档案,包含多笔资料,每笔资料包含多个栏位,所述多个栏位之一可被指定为目标栏位,而其余栏位则作为特征栏位,其中目标栏位代表欲以完成训练的机器学习模型进行预测的栏位。机器学习模型可以依据目标资料集,归纳特征栏位的数值与目标栏位的数值之间的规则,再以归纳出的规则对新资料进行预测。
于步骤S12中,实验产生器12可以依据目标资料集决定至少一目标实验及每个目标实验的最低资源需求量。进一步来说,每个目标实验可以对应于一特定模型且包含多个目标子实验(Trial),每个目标子实验可以对应于不同超参数(Hyperparameters)组合,目标子实验的执行便依据对应的超参数组合来使用目标资料集进行机器学习模型的训练。换句话说,实验产生器12可以依据目标资料集决定实验所对应的特定模型,所述特定模型具有许多超参数(举例来说,模型sklearn.svm.SVC具有超参数C:float、kernel:{‘linear’,…}、degree:int等等),实验产生器12便可以自动产生超参数的多种数值搭配分别作为多个超参数组合,并将依据各超参数组合来使用目标资料集训练机器学习模型的作业设定为一目标子实验。
除了产生目标实验的多个子实验,实验产生器12也会决定目标实验的最低资源需求量。进一步来说,实验产生器12可以依据目标实验的执行效率资料及目标实验执行表现来计算最低资源需求量。执行效率资料可以预先储存于数据库16,包含一最高资源忙碌量对应的目标实验的单个子实验的执行时间。一般而言,每个子实验仅会配置给单组资源(例如单个CPU或CPU核心)来执行。因此,所谓最高资源忙碌量对应的目标实验的单个子实验的执行时间即表示当机器学习模型训练执行器14处于最忙碌状态时,单组资源完成单个子实验的执行时间。目标实验执行表现指示在一预设时间内目标实验的目标子实验完成量(Trial Throughput),可以为实验产生器12的预设值或是由使用者通过输入界面11输入,也就是说,前述实验需求可以包含目标实验执行表现。举例来说,若目标实验的执行效率资料为900秒且目标实现执行表现为每小时完成20个子实验,则实验产生器12可以计算出同时至少要有5个子实验同时进行,即最低资源需求量为5组资源,然本公开不以此为限。
于步骤S13中,实验排程器13可以判断机器学习系统的资源量是否足够执行目标实验。当判断结果为是时,于步骤S14中,实验排程器13可以配置机器学习模型训练执行器14以目标实验的最低资源需求量以执行目标实验。当判断结果为否时,于步骤S15中,实验排程器13不执行目标实验或减少其他实验的资源占用量直至足够执行目标实验。
进一步来说,当目标实验被实验产生器12产生时,机器学习模型训练执行器14可能有其他当前正在执行的实验。因此,实验排程器13可以先判断机器学习模型训练执行器14的总资源量是否满足目标实验及其他实验的最低资源需求量。当判断结果为否时便不执行目标实验,且可将目标实验先储存于待执行实验队列;当判断结果为是时,实验排程器13再判断机器学习模型训练执行器14当前的闲置资源量,即总资源量与其他实验当前的资源占用量的差,是否满足目标实验的最低资源需求量。当判断结果为否时,表示有其他实验是以高于其最低资源需求量的资源占用来在运作,实验排程器13便可以减少其他实验的资源占用量,直至机器学习模型训练执行器14当前的闲置资源量足够执行目标实验,也就是当前的闲置资源量等于目标实验的最低资源需求量。此时,实验排程器13便可配置机器学习模型训练执行器14以目标实验的最低资源需求量以执行目标实验。
步骤S16示例性地示于步骤S14后,但实际上步骤S16可以在机器学习模型训练执行器14开始执行实验后周期性地执行(例如每2、5或10分钟执行一次),也就是在机器学习模型训练执行器14开始第一个实验起每一特定时间执行一次。或者,步骤S16可以在机器学习模型训练执行器14执行任何实验的期间执行。于步骤S16中,动态资源配置器15可以判断机器学习模型训练执行器14是否具有一闲置资源量,当有的时候,便选择性地将闲置资源量配置给机器学习模型训练执行器14当前正在执行实验中的至少一个,即增加该至少一实验的资源占用量。
请一并参考图1及图3,图3为依据本公开另一实施例所示的资源配置方法的流程图。如前所述,当有新的目标实验产生时,机器学习系统1可能有其他当前正在执行的实验。若以至少一第一实验代称机器学习系统1当前正在执行的实验且以第二实验代称新产生的目标实验,则至少第一实验及第二实验的资源配置方法可以如图3所示,包含步骤S21:以机器学习系统1的资源占用量执行至少一第一实验,其中每一第一实验具有第一最低资源需求量;步骤S22:接收关联于目标资料集的实验需求;步骤S23:依据目标资料集决定第二实验,并决定第二实验的第二最低资源需求量;步骤S24:当机器学习系统1的总资源量满足第一最低资源需求量及第二最低资源需求量的和,且总资源量及资源占用量的差满足第二最低资源需求量时,配置第二最低资源需求量执行第二实验;以及步骤S25:判断机器学习系统1具有闲置资源量,并选择性地将闲置资源量配置给所述至少一第一实验及第二实验中至少一个。其中,步骤S25中的判断并选择性地配置闲置资源量的实施内容可以在机器学习系统1开始执行实验后周期性地执行(例如每2、5或10分钟执行一次),也可以在机器学习系统1执行任何实验的期间执行。
上述步骤S21可以机器学习系统1的机器学习模型训练执行器14来执行,步骤S22以输入界面11执行,步骤S23以实验产生器12执行,步骤S24以实验排程器13指示机器学习模型训练执行器14执行,步骤S25则以动态资源配置器15执行。另外,当机器学习系统1的机器学习模型训练执行器14的总资源量满足第一最低资源需求量及第二最低资源需求量的和,但总资源量与资源占用量的差不满足第二最低资源需求量时,机器学习系统1的实验排程器13可以减少资源占用量,以使总资源量与该资源占用量的差满足第二最低资源需求量。
上述实验排程器13所执行的减少当前正在执行的实验(第一实验)的资源占用量以及动态资源配置器15所执行的选择性地配置闲置资源量的方式各可依循多种原则,其中有几种原则是基于预先储存于数据库16的多种实验的执行效率资料。请参考图4A及4B,图4A及4B分别示例性地示出两种实验的执行效率资料。如图4A所示,第一种实验的执行效率资料包含多种资源忙碌量各自对应的第一种实验的单个子实验的执行时间。如图4B所示,第二种实验的执行效率资料包含多种资源忙碌量各自对应的第二种实验的单个子实验的执行时间。其中,资源忙碌量指示机器学习模型训练执行器14中正在运行的CPU数量,单个子实验的执行时间指示单组资源完成单个子实验的执行时间。特别来说,第一种实验与第二种实验可以分别基于不同模型(例如SVC、GBR等等)。
图4A及4B所示的资源忙碌量的范围为1~20,也是于图4A及4B对应的实施例中,机器学习模型训练执行器14的总资源量(CPU总数量或CPU核心总数量)为20。另外,如前所述,实验产生器12可以依据最高资源忙碌量所对应的目标实验的单个子实验的执行时间,产生目标实验的最低资源需求量的,以图4A及4B为例,最高资源忙碌量所对应的单个子实验的执行时间即为资源忙碌量20所对应的单个子实验的执行时间。于此要特别说明的是,图4A及4B所呈现的资源忙碌量及单个子实验的执行时间的数值仅为示例,并非意图限制本公开。
进一步说明实验排程器13所执行的减少当前正在执行的实验的资源占用量的方式。当第一实验(当前正在执行的实验)的数量仅有一个时,实验排程器13便会减少该实验的资源占用量。当第一实验数量有多个时,于一实施例中,实验排程器13所执行的减少资源占用量包含:对于每一第一实验,依据第一实验的执行效率资料,判断将第一实验对应的资源占用量减少后第一实验的子实验完成量的预估下降幅度;以及减少第一实验中具有最低预估下降幅度的实验所对应的该资源占用量。
第一实验的执行效率资料如前列图4A及4B的实施例所述,包含多种资源忙碌量各自对应的第一实验的单个子实验的执行时间。至于子实验完成量的预估下降幅度,详细来说,实验排程器13可以所有第一实验的当前资源占用量作为资源忙碌数量,用此资源忙碌数量查找各第一实验的执行效率资料以取得各第一实验的单个子实验执行时间,据以计算在未减少任一第一实验的资源占用量的状态(第一运作状态)下,各第一实验在预设时间内的子实验完成量,并以所有第一实验的当前资源占用量减去一预设量的值作为资源忙碌数量,用此资源忙碌数量查找各第一实验的执行效率资料以取得各第一实验的单个子实验执行时间,据以计算各第一实验中的资源占用量在减少所述预设量的状态(第二运作状态)下,在预没时间内的子实验完成量,再将各第一实验在上述两种运作状态下计算而得的子实验完成量相减以取得预估下降幅度。
举例来说,第一实验包含实验A、实验B及实验C,当前分别以8、6及6个CPU执行。实验排程器13取得实验A、实验B及实验C分别在资源忙碌量为20时的单个子实验执行时间,计算在10分钟内,实验A以8个CPU所能完成的子实验数量、实验B以6个CPU所能完成的子实验数量以及实验C以6个CPU所能完成的子实验数量,假设如下所示:
A[8]=30;
B[6]=22;
C[6]=30。
实验排程器13也取得实验A、实验B及实验C分别在资源忙碌量为19(预设量为1)时的单个子实验执行时间,计算在10分钟内,实验A以7个CPU所能完成的子实验数量、实验B以5个CPU所能完成的子实验数量以及实验C以5个CPU所能完成的子实验数量,假设如下所示:
A[7]=27;
B[5]=20;
C[5]=26。
依据上列计算结果,实验排程器13会判断实验B的下降幅度(2)为最低,因此将实验B的资源占用量减少1。实验排程器13可以依上述原理不断选择减少资源占用量的实验,直至总资源量与所有实验的资源占用量之间的差值满足第二实验的最低资源需求量。于此要特别说明的是,上述的预设时间的数值以及预设减少的资源量的数值仅为举例,本公开不以上述为限。另外,若有第一实验的资源占用量已等于其最低资源需求量,则不选择此第一实验。
通过上述基于各实验的执行效率资料的减少资源占用量的方式,机器学习系统1可以进行横跨不同任务的运算资源调配,考量到资源忙碌状态与执行效率的关系,且不限制固定工作时间(例如实验完成时间或子实验执行时间)。相较于现行的资源配置方法,例如先进先出法(First In First Out,FIFO),在资源分配上可以更具弹性,且能够实时修正资源负载,以维持在较佳的执行效率。
于另一实施例中,实验排程器13会从所述多个第一实验中最晚开始执行的实验开始减少资源占用量,减少的数量可以为1也可以为其他数量,本公开不予限制。另外,若有第一实验的资源占用量已等于其最低资源需求量,则跳过此第一实验。
进一步说明动态资源配置器15所执行的选择性地配置闲置资源量的方式。当目标实验(第二实验)已被实验排程器13配置由机器学习模型训练执行器14执行,也就是机器学习模型训练执行器14当前正在执行的实验包含至少一第一实验及第二实验时,动态资源配置器15所执行的选择性地配置闲置资源量可以包含:依据每一第一实验的执行效率资料及第二实验的执行效率资料,判断多个配置策略的预估实验执行表现,以及依据所述多个配置策略中具有最高预估实验执行表现的实验配置闲置资源量。于此实施例中,动态资源配置器15会连接于数据库16以取得其内储存的执行效率资料。
如前列图4A及4B的实施例所述,第一实验的执行效率资料包含多种资源忙碌量各自对应的第一实验的单个子实验的执行时间,第二实验的执行效率资料包含多种资源忙碌量各自对应的第二实验的单个子实验的执行时间。所述多个配置策略分别为将闲置资源量配置给所述至少一第一实验及第二实验。更进一步来说,所述多个配置策略包含将闲置资源量配置给第一实验的第一配置策略(当第一实验数量为多个时,便为多个第一配置策略),且包含将闲置资源量配置给第二实验的第二配置策略。预估实验执行表现的详细指示内容可以有两个实施态样,如下所述。
于第一实施态样中,第一配置策略的预估实验执行表现指示在预设时间内对应的第一实验的预估子实验完成量,第二配置策略的预估实验执行表现指示在预设时间内对应的第二实验的预估子实验完成量。详细来说,动态资源配置器15可以所有实验的当前资源占用量加一预设量的值作为资源忙碌数量,用此资源忙碌数量查找第一实验及第二实验中的每一个实验的执行效率资料以取得各实验的单个子实验执行时间,据以计算各实验在资源占用量增加所述预设量的状态下,预设时间内的子实验完成量,以作为各实验的预估实验执行表现。
举例来说,第一实验及第二实验包含实验D、实验E及实验F,当前分别以8、6及5个CPU执行。动态资源配置器15取得实验D、实验E及实验F分别在资源忙碌量为20(预设量为1)时的单个子实验执行时间,计算在10分钟内,实验D以9个CPU所能完成的子实验数量、实验E以7个CPU所能完成的子实验数量以及实验F以6个CPU所能完成的子实验数量,假设如下所示:
D[9]=33;
E[7]=25;
F[6]=30。
依据上列计算结果,动态资源配置器15会判断具有最高子实验完成量的实验D具有最高预估实验执行表现,并将闲置资源量中的1个CPU配置给实验D。动态资源配置器15可以依上述原理不断配置闲置资源量,直至闲置资源量为0。于此要特别说明的是,上述的预设时间的数值以及预设量的数值仅为举例,本公开不以上述为限。另外,动态资源配置器15还可以判断尚未新配置资源量给任何实验前的所有实验的子实验完成量(原先子实验总完成量),且当经上述计算所得的各实验对应的预估子实验完成量加上其他实验的原先子实验完成量皆不大于原先子实验完成量时,动态资源配置器15便不配置闲置资源量。
于第二实施态样中,预估实验执行表现则是指示在一预设时间内所有实验的预估子实验完成量。承第一实施态样的举例,动态资源配置器15会另依据实验D、实验E及实验F分别在资源忙碌量为20时的单个子实验执行时间,计算在10分钟内,实验D以8个CPU所能完成的子实验数量、实验E以6个CPU所能完成的子实验数量以及实验F以5个CPU所能完成的子实验数量,进而分别计算将1个CPU新配置给实验D时所有实验的预估子实验完成数量、将1个CPU新配置给实验E时所有实验的预估子实验完成数量以及将1个CPU新配置给实验F时所有实验的预估子实验完成数量,假设如下所示:
D[9]+E[6]+F[5]=33+22+25=80;
D[8]+E[7]+F[5]=30+25+25=80;
D[8]+E[6]+F[6]=30+22+30=82。
如上列计算所示,将1个CPU新配置给实验F时所对应的所有实验的预估子实验完成量最高,动态资源配置器15据以判断实验F具有最高预估实验执行表现,并将闲置资源量中的1个CPU配置给实验D。动态资源配置器15可以依上述原理不断配置闲置资源量,直至闲置资源量为0。于此要特别说明的是,上述的预设时间的数值以及预设量的数值仅为举例,本公开不以上述为限。另外,动态资源配置器15还可以判断尚未新配置资源量给任何实验前的所有实验的子实验完成量(原先子实验总完成量),且当经上述计算所得的各实验对应的预估实验执行表现皆不大于原先子实验总完成量时,动态资源配置器15便不配置闲置资源量。上述判断各实验对应的预估实验执行表现是否大于原先子实验完成量的步骤可以执行于最高预估实验执行表现的判断之前或之后,本公开不予限制。
通过上述基于各实验的执行效率资料的动态配置方式,机器学习系统1可以进行横跨不同任务的运算资源调配,且考量到资源忙碌状态与执行效率的关系,且不限制固定工作时间(例如实验完成时间或子实验执行时间)。相较于现行的资源配置方法,例如一般先进先出法(First In First Out,FIFO),在资源分配上可以更具弹性,且能够避免资源满载而效率不彰的问题,进而提升有限时间内的子实验完成数量。
于又一实施例中,动态资源配置器15可以直接将闲置资源量配置给所有当前正在执行的实验(第一实验及第二实验)中最早开始执行的实验,闲置资源量可以为1也可以为其他数量,本公开不予限制。
上述说明了机器学习系统1在训练机器学习模型的过程中的各种实施内容,另外,机器学习系统1在开始接收实验需求之前,可以先执行资料初始化及收集程序,以生成前述的预先储存于数据库16中的多种实验的执行效率资料。请参考图5,图5为依据本公开一实施例所示的资料初始化及收集程序的流程图。如图5所示,资料初始化及收集程序包含步骤S8:载入多个预设资料集;步骤S9:依据所述多个预设资料集产生多个测试实验;以及步骤S10:对于每一测试实验,取得多种资源忙碌量各自对应的测试实验的子实验执行时间,并储存为此测试实验的执行效率资料。以下示例性地以图1所示的机器学习系统1的装置来进一步说明资料初始化及收集程序。
于步骤S8中,实验产生器12可以从档案系统(Dataset Store)载入多个预设资料集,其中,档案系统中所预存的资料集可以为使用者上传或是政府公开的资料集。于步骤S9中,实验产生器12可以依据预设资料集产生多个测试实验,其中,所述测试实验包含前列实施例所述的第一实验及第二实验。于步骤S10中,机器学习模型训练执行器14对于每一测试实验,执行:取得多种资源忙碌量各自对应的测试实验的单个子实验的执行时间,并将取得的资料储存于数据库16中以作为测试实验的执行效率资料。进一步来说,机器学习模型训练执行器14可以使用各种资源忙碌量的运作状态来执行测试实验,并记录单组资源在各种运作状态下完成单个子实验的时间,以组合成测试实验的执行效率资料,例如图4A及4B所示的执行效率资料。
特别来说,图2所示的资源配置方法可以还包含图5所示的资料初始化及收集程序,且执行于步骤S11之前,而图3所示的资源配置方法也可以还包含图5所示的资料初始化及收集程序可以执行于步骤21之前。
请一并参考图1及图6,图6为依据本公开又一实施例所示的资源配置方法的流程图。如图6所示,资源配置方法可以包含步骤S31:执行资料初始化与收集程序;步骤S32:接收关联于目标资料集的实验需求;步骤S33:决定目标实验及其设定;步骤S34:将目标实验放入队列;步骤S35:判断总资源量是否足够执行队列中的第一个实验;当步骤S35的判断结果为否时,经过一预设时间或有其他实验完成后再次执行步骤S35;当步骤S35的判断结果为是时,执行步骤S36:判断闲置资源量是否足够执行此实验;当步骤36的判断结果为否时,执行步骤S37:减少其他执行中的实验的资源占用量;当步骤S36的判断结果为是时,执行步骤S38:执行实验,且执行动态配置资源程序;步骤S39:周期性地记录当前资源忙碌量及子实验当前执行时间;步骤S40:输出实验结果。以下示例性地以图1所示的机器学习系统1的装置来进一步说明图6所示的资源配置方法。
于步骤S31中,实验产生器12、机器学习模型训练执行器14及数据库16可以共同执行资料初始化与收集程序,详细的执行内容如同前列图5的实施例的步骤S8~S10的执行内容。步骤S32及S33可以分别由输入界面11及实验产生器12所执行,详细执行内容如同前列图2的实施例的步骤S11及S12的执行内容。于步骤S34中,实验产生器12将目标实验放入队列,以等待实验排程器13执行后续配置,其中所述队列可以储存于数据库16中。
于步骤S35及S36中,实验排程器13判断机器学习模型训练执行器14的总资源量是否足够执行队列中的第一个实验,且在判断结果为是时,进一步判断机器学习模型训练执行器14的闲置资源量(总资源量减掉当前资源占用量)是否足够执行队列中的第一个实验。上述二阶段的判断的详细执行内容如同前列图2的实施例的步骤S13的执行内容。当第一阶段判断的结果为否时,实验排程器13便不配置机器学习模型训练执行器14执行队列中的第一个实验,而在一预设时间后或在机器学习模型训练执行器14完成某一先前执行的实验后,再次执行总资源量是否足够的判断。当第二阶段判断的结果为否时,如步骤S37所述,实验排程器13便减少其他执行中的实验的资源占用量,其中详细的执行内容如同前列图2的实施例的步骤S15的执行内容。
于步骤S38中,实验排程器13配置机器学习模型训练执行器14执行队列中的第一个实验,且动态资源配置器15可以执行动态配置资源程序,其中详细的执行内容如前列图2的实施例的步骤S14及S16的执行内容。于步骤S39中,在实验执行的过程中,机器学习模型训练执行器14可以周期性地记录当前资源忙碌量以及对应的单个子实验的当前执行时间(单组资源在当前资源忙碌量的状态下完成单个子实验的时间)。于此实施例中,机器学习模型训练执行器14连接于数据库16以将上述周期性记录的资料传送至数据库16。特别来说,上述周期性记录的资料可以用以更新数据库16中的执行效率资料。另外,机器学习模型训练执行器14也可以通过输出界面17周期性地输出当前执行时间,以供操作人员确认系统的运算资源的执行效率。其中,输出的形式例如为显示画面。
于步骤S40中,机器学习模型训练执行器14可以输出执行实验的结果,例如为训练完成的机器学习模型。进一步来说,假设目标资料集属于分类问题,机器学习模型训练执行器14在以目标资料集执行模型训练时,会将一部分资料作为训练资料,剩下部分资料作为测试资料。机器学习模型训练执行器14每完成一个子实验会产生一个训练模型。机器学习模型训练执行器14可以使用测试资料对各训练模型进行分类测试,以产生各训练模型对应的测试分数(例如0.99,代表99%正确率)。机器学习模型训练执行器14再将具有最高测试分数的训练模型作为训练完成的机器学习模型以输出。
请参考图7A~图7C及表1~表3,其中,图7A~图7C分别呈现在三种实验执行情境中,现有资源配置方法与本公开多个实施例的资源配置方法的执行表现比较图;表1~表3则分别呈现所述三种实验执行情境中所执行的实验的编号、抵达时间及最低资源需求量。
于图7A~图7C中,FIFO表示先进先出法,E1~E6分别表示本公开的资源配置方法的六个实施例(后称第一至第六实施例)。于第一实施例E1中,减少资源占用量的执行对象的选择是通过预估各实验原先状态下2分钟内的子实验完成量,以及在资源占用量减少1的状态下2分钟内的子实验完成量,并选择下降幅度最低的实验;配置闲置资源量的执行对象的选择是通过预估各实验在资源占用量增加1的状态下2分钟内的子实验完成量,并选择数量最高的实验。于第二实施例中,减少资源占用量的执行对象的选择同于第一实施例E1,而配置闲置资源量的执行对象的选择则是通过预估各实验在资源占用量增加1的状态下,2分钟内所有实验的子实验完成量,并选择数量最高的实验。
于第三实施例E3中,减少资源占用量的执行对象的选择是通过预估各实验原先状态下5分钟内的子实验完成量,以及在资源占用量减少1的状态下5分钟内的子实验完成量,并选择下降幅度最低的实验;配置闲置资源量的执行对象的选择是通过预估各实验在资源占用量增加1的状态下5分钟内的子实验完成量,并选择数量最高的实验。于第四实施例E4中,减少资源占用量的执行对象的选择同于第三实施例,而配置闲置资源量的执行对象的选择则是通过预估各实验在资源占用量增加1的状态下,5分钟内所有实验的子实验完成量,并选择数量最高的实验。
于第五实施例E5中,减少资源占用量的执行对象的选择是通过预估各实验原先状态下10分钟内的子实验完成量,以及在资源占用量减少1的状态下10分钟内的子实验完成量,并选择下降幅度最低的实验;配置闲置资源量的执行对象的选择是通过预估各实验在资源占用量增加1的状态下10分钟内的子实验完成量,并选择数量最高的实验。于第六实施例中,减少资源占用量的执行对象的选择同于第五实施例E5,而配置闲置资源量的执行对象的选择则是通过预估各实验在资源占用量增加1的状态下,10分钟内所有实验的子实验完成量,并选择数量最高的实验。
特别要说明的是,第一实施例~第六实施例所执行的减少资源占用量、配置闲置资源量及资源配置方法中的其他步骤的详细实施内容皆如前列各实施例所述,于此不再赘述。
图7A~图7C的实验执行情境分别如表1~表3所示。表1~表3分别呈现三组随机产生的实验组合,每个实验组合中的多个实验各具有实验编号、实验抵达时间及最低资源需求量。实验编号的格式为模型名称-资料集中的资料笔数(单位:千)。SVC表示C-支持向量分类(C-Support Vector Classification)模型,是基于支持向量机的程序库(LIBSVM)实作的支持向量机分类算法,可以针对资料集训练多个分类的机器学习模型;GBR表示梯度提升回归(Gradient Boosting Regressor)模型,是一种梯度增强机器学习技术用于解决回归问题(待预测的目标为连续数值),可以针对资料集训练回归问题的机器学习模型。于表1~表3所示的实验执行情境中,SVC所使用的分类资料集包含使用Scikit-learn机器学习程序库随机产生的5、10或20万笔分类问题使用资料,其中每份资料皆有10个分类类别及10个有效信息栏位;GBR所使用的回归资料集则包含使用Scikit-learn机器学习程序库随机产生的20、50或100万笔回归问题使用资料,其中每份资料有10个有效信息栏位。
实验抵达时间表示从系统开始运作起算,对应的实验由实验产生器12产生的时间。最低资源需求量则表示由实验产生器12决定的执行对应实验所需的最少资源量,决定的方式如前列实施例所述,于此不再赘述。
表1
表2
表3
由图7A~图7C及表1~表3可知,本公开的资源配置方法的第一实施例E1~第六实施例E6,无论是在实验抵达时间不一、实验抵达时间紧凑或是实验抵达时间稀疏的状况下,特定时间内所完成的子实验量皆远超过习知的先进先出法FIFO。特别来说,以2分钟作为预估执行效率的预设时间以进行减少资源占用量及配置闲置资源量的第一及第二实施例E1及E2,相较于其他实施例具有更佳的执行表现。
通过上述结构,本公开的机器学习系统及其资源配置方法可以依据实验需求自动产生实验设定并建议实验最低资源需求量,先以最低资源需求量执行实验再进行动态配置,且可进行不同实验间的资源调配,使得系统的运算资源可以维持在较佳的执行效率,进而提升有限时间内实验的子实验的完成数量。
- 机器学习系统及其资源配置方法
- 基于机器学习的Web应用自适应资源配置方法