自由文本去识别
文献发布时间:2023-06-19 11:26:00
技术领域
本发明涉及对诸如患者数据之类的个人可识别信息(PII)的处理的分析。更具体地,本发明涉及对包括例如与疾病或处置有关的自由文本的患者数据的分析和去识别。这样的自由文本包括自然语言短语,并且可以包括临床记录、出院小结、移交记录等,并且在本文档中被称为非结构化文本。
背景技术
最新的法规(例如,通用数据保护条例,欧盟理事会,欧洲议会和理事会于2016年4月27日关于在处理个人数据和此类数据的自由流动方面保护自然人而颁布的条例(eu)2016/679,并废除了指令95/46/ec,2016年4月”,HIPAA“医疗保险可携性和责任法案;美国劳工部,雇员福利安全管理局,2004年”)对处理个人可识别信息(PII)提出了严格要求,同时对不遵守规定的行为处以巨额罚款。
基于文本的患者医学记录是医学研究和数据分析中的重要资源。为了保护患者的隐私和保密性,如HIPAA和GDPR之类法规要求先将受保护的健康信息(PHI)从医学记录中移除,然后再将PHI用于次要目的。对非结构化文本文档的去识别通常是手动实现的并且需要大量资源。
虽然在对结构化临床数据(例如,医院数据库、关系数据仓库)的去识别的领域中已经进行了大量研究,但是由于诸如自由文本临床记录、出院小结和移交记录之类的数据的非结构化性质,对此类数据的去识别的研究尚不成熟。针对该问题的解决方案是使用涉及医学、自然语言处理等领域的知识的多学科方法(例如参见HuiYang和JonathanM.Garibaldi的“Automatic detection of protected health information from clinicnarratives”(生物医学信息学杂志,58(S):S30-S38,2015年12月)),临床文本挖掘、机器学习(例如参见K.Rajput、G.Chetty和R.Davey的“Phis(protected health information)identification from free text clinical records based on machine learning”(2017IEEE计算智能研讨会系列(SSCI),第1-9页,2017年11月))和循环神经网络(例如参见Franck Dernoncourt、Ji Young Lee、Ozlem Uzuner和Peter Szolovits的“De-identification of patient notes with recurrent neural networks”(美国医学信息学学会杂志,24(3):596-606,2017年))。
然而,由于此类数据的非结构化性质,基于黑名单的方法具有大量的真负例。例如,它们无法涵盖异常词(例如“Summer”既可以是名称又可以是时间指示符/季节)、拼写错误(例如拼写成“Jonh”而不是“John”)或非结构化数据的自由性质(例如,圣诞节实际上就是12月25日)。
另外,非结构化文本的去识别取决于领域并且依赖于领域特异性词典,在大多数情况下,领域特异性词典是不可用的。这样的领域特异性词典的示例是MIMIC数据库(参见Ishna Neamatullah、Margaret M.Douglass、Li wei H.Lehman、Andrew T.Reisner、Mauricio Villarroel、William J.Long、Peter Szolovits、George B.Moody、RogerG.Mark和Gari D.Clifford的“Automated de-identification of free-text medicalrecords”(BMC医学信息学和决策制定,8:32-32,2008年)),而大多数其他最新的去识别方法都依赖于使用黑名单(例如参见Stéphane M.Meystre、F.Jeffrey Friedlin、BrettR.South、Shuying Shen和Matthew H.Samore的“Automatic de-identification oftextual documents in the electronic health record:a review of recentresearch”(近期研究综述;BMC医学研究方法论,2010年))。
机器学习技术需要训练数据,此外还需要对训练数据进行注释。至少在短时间内很难满足这样的要求,并且对于不同领域需要重复这样的要求。此外,训练所需的数据量比仅进行一次简单的去识别任务要大得多。
然而,当前的自由文本去识别方法不会掩盖黑名单未涵盖的识别符,并且还存在以下问题:
·领域语言。对非结构化文本的去识别可能需要领域知识(例如,MIMIC数据库、领域特异性词语),并且在许多情况下,由于尚未建立基于领域的白名单,因此基于领域的白名单是不可用的。去识别专家也可能会因领域的特殊性而放慢速度。
·真负例。拼写错误是PHI的应在去识别输出中将其掩盖的部分,但是它们会使通常的去识别方法无效。
·效率低下。当前的方法需要建立领域知识和基于手动审核的白名单。对非结构化文本文档的去识别通常是手动实现的并且需要大量资源。
发明内容
本发明的目的是提供考虑了前述问题中的至少一个问题的用于自由文本去识别的方法和系统。
为此目的,提供了如权利要求所定义的用于根据患者数据的数据集来生成去识别输出的设备和方法。根据本发明的一个方面,提供了如权利要求1所定义的用于根据多个患者的患者数据的数据集来生成去识别输出的方法。提供了根据权利要求13所定义的系统。根据本发明的另外的方面,提供了能从网络下载和/或被存储在计算机可读介质和/或微处理器可执行介质上的计算机程序产品,该产品包括程序代码指令,该程序代码指令用于当在计算机上被执行时实施上述方法。
为了克服这些缺点,用于非结构化文本的去识别方法掩盖或移除(盖住)了在文本中不常出现的词项和被列入黑名单的词项。为此,通过执行词计数并在去识别输出中仅允许在文本中的出现次数多于最少出现次数的词语来对非结构化文本进行去识别。该方法还抑制或替换了被列入黑名单的词语(例如,18个HIPAA识别符)。词计数提供了在非结构化文本中的出现次数(k)低于阈值的低比率词项的列表。然后,从非结构化文本中移除低比率词项和黑名单词项或者在非结构化文本中掩盖低比率词项和黑名单词项,以生成去识别输出。除了词语原样之外,词项还可以包括词语序列、词干和词语模式。
有利地,与现有技术的解决方案相比,该方法和系统不需要初始领域知识输入并且能够降低真负例的量。
在本发明的实施例中,词计数和/或黑名单条目中的词项与该词语在文本中具有的句法范畴(动词、名词等)相关联,如自然语言处理(NLP)所确定的那样。通过发现作为潜在识别符但由于静态黑名单的已知限制而未被黑名单涵盖的词语,这可以提高黑名单的质量。
在本发明的另一实施例中,根据通过词计数的词语来创建领域特异性白名单词语列表。即使在一些情况下这些词语的出现频率并不高,以后在去识别输出中也能够允许这些词语。
根据本发明的方法可以在计算机上被实施为计算机实施的方法,或者可以被实施在专用硬件中,或者可以被实施在这两者的组合中。用于根据本发明的方法的可执行代码可以被存储在计算机程序产品上。计算机程序产品的示例包括存储器设备(例如,记忆棒)、光学存储设备(例如,光盘)、集成电路、服务器、在线软件等。
非瞬态形式的计算机程序产品可以包括被存储在计算机可读介质上的非瞬态程序代码单元,该非瞬态程序代码单元用于当所述程序产品在计算机上被执行时执行根据本发明的方法。在实施例中,计算机程序包括计算机程序代码单元,该计算机程序代码单元适于当计算机程序在计算机上运行时执行根据本发明的方法的所有步骤或阶段。优选地,计算机程序被体现在计算机可读介质上。还提供了一种瞬态形式的计算机程序产品,该计算机程序产品可从网络下载和/或被存储在易失性计算机可读存储器和/或微处理器可执行介质中,该产品包括程序代码指令,该程序代码指令用于当在计算机上被执行时实施上述方法。
本发明的另一方面提供了一种使瞬态形式的计算机程序可供下载的方法。当该计算机程序被上传到例如Apple的App商店、Google的Play商店或Microsoft的Windows商店时以及当可从此类商店下载该计算机程序时,将使用这方面。
在权利要求书中给出了根据本发明的设备和方法的其他优选实施例,通过引用将其公开内容并入本文。
附图说明
参考附图并参考在以下描述中以示例方式描述的实施例,本发明的这些方面和其他方面将变得显而易见并且得到阐明。
图1示出了图示用于对包含非结构化文本的患者数据集进行去识别的方法的实施例的示意性流程图,
图2示出了图示包含对非结构化文本的自然语言处理的用于对患者数据集进行去识别的方法的实施例的示意性流程图,
图3示出了图示用于使用白名单对非结构化文本进行去识别的方法的实施例的示意性流程图,
图4示出了图示用于使用置信度列表对非结构化文本进行去识别的方法的实施例的示意性流程图,
图5示出了用于对包含非结构化文本的患者数据集进行去识别的方法的实施例,
图6a示出了计算机可读介质,并且
图6b以示意图表示示出了处理器系统。
这些附图仅是示意性的且并未按比例绘制。在附图中,与已经描述的元件相对应的元件可以具有相同的附图标记。
具体实施方式
将针对特定实施例并参考附图来描述本发明,但是本发明不限于此,而仅限于权利要求。
术语“个体”是指人类对象。所述人类对象可以受到要研究的疾病的影响或者可以遭受要研究的疾病的折磨,也可以不受要研究的疾病的影响或者可以不受要研究的疾病的折磨。因此,在本公开内容中同义地使用术语“个体”、“人”和“患者”。
表述“提供患者数据”应被理解为需要获得至少一个个体的患者数据。然而,不必与该方法直接关联地或者为了执行该方法而获得至少一个个体的患者数据。通常,至少一个个体的患者数据是在先前的时间点或时间段获得的,并且以电子方式被存储在合适的电子存储设备和/或数据库中。为了执行该方法,能够从存储设备或数据库中检索患者数据并加以利用。
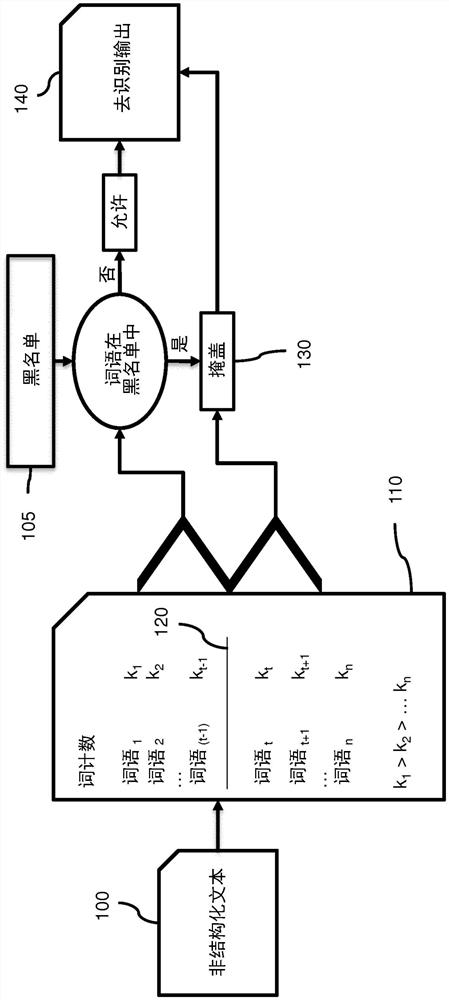
图1示出了图示用于对包含非结构化文本的患者数据集进行去识别的方法的实施例的示意性流程图。该方法通常将被实施为使整个过程实际可用的软件框架。该附图描绘了用于根据多个患者的患者数据的数据集来生成去识别输出的计算机实施的方法。患者数据包括非结构化文本100。非结构化文本由以自然语言短语排列的词项(例如,词语、数字和符号)组成。黑名单105具有在去识别输出中不允许的黑名单词项。
在第一阶段中,该方法处理非结构化文本以确定词计数110。词计数具有在非结构化文本中的出现次数(k)低于阈值120的低比率词项的列表,用将低比率词项(k
黑名单可以被设计为寻找HIPAA 18识别符。为此,黑名单可以是复合词,并且可以包括字典(例如,名称)和针对邮政编码、日期、电子邮件、URL、IP地址以及其他唯一识别号(例如,驾驶执照)的正则表达式。即使利用如此广泛的正则表达式列表,黑名单也有其局限性。例如,黑名单无法涵盖异常词(例如,“聪明”既能够是名称又能够是形容词)、拼写错误(例如拼写成“Jonh”而不是“John”)或非结构化数据的自由性质(例如,圣诞节实际上就是12月25日)。这样的示例在全文中的出现次数会很少,低于阈值,因此会在去识别输出中会被掩盖。
可以通过将阈值设置为由去识别专家认为安全的数值T来静态地设置阈值。而且,可以通过遍历词计数列表中的词语直到在去识别输出中允许至少文本的期望百分比P%为止来动态地设置阈值。这应该在未通过上述最小静态阈值的情况下发生。因此,该处理可以包括:根据在去识别输出中允许的非结构化文本的期望百分比来将阈值设置为高于最小阈值。
“词计数”列表可以是仅对词项(例如,原词)进行简单的计数操作的结果。
图2示出了图示包含对非结构化文本的自然语言处理的用于对患者数据集进行去识别的方法的实施例的示意性流程图。词计数可以包括对非结构化文本的预处理210(通常被称为自然语言处理,例如参见Steven Bird、Ewan Klein和Edward Loper的“NaturalLanguage Processing with Python”(O’Reilly Media,Inc.,第一版,2009年))。现在描述这样的处理的各种实施例,这些实施例可以组合。
任选地,该方法可以包括:将针对在短语中具有不同句法位置的相同词语的分离的词项确定为多个词项。如图2所描绘的,自然语言处理210可以被布置用于将词语的句法位置这一因素考虑在内。词语句法位置可以例如是名词短语、动词词组、介词短语、限定词、名词、动词、介词。例如,在句子“聪明去了商店”中,词语“聪明”用作名词;而在句子“聪明的孩子去了商店”中,“聪明”用作形容词。用作形容词的“聪明”将比用作名词的“聪明”出现得更多,因此该名词条目将被掩盖。此外,词计数或句法位置可以不考虑词语是否以大写字母开头。然而,当将词语用作名词时,大写字母可以指示名称,并且可以对这样的词项进行有区别地计数。
任选地,该方法可以包括:将多个词语模式确定为多个词项,一个词语模式包括在短语中的至少一个词语与相邻的数字或符号的模式的组合。自然语言处理210可以被布置用于确定模式,例如:“[0-9]+词语”或“[0-9]+词语”,其中,允许或掩盖的决定基于该词项内的词语。这样,在掩盖“1月23日”时,由于“星期一”未被列入黑名单而将允许“星期一11:00”,而基于作为日期的HIPAA 18识别符,“一月”被列入黑名单。
任选地,该方法可以包括:将多个词串确定为多个词项,一个词串包括特定的词语序列。自然语言处理210可以被布置用于确定词语组合、短序列或小句子。这样的串可以被自动确定为最长重复串,其中,出现次数k高于阈值。
可以组合以上选项。因此,该处理可以包括使用以上定义的词项来确定黑名单。
任选地,该方法可以包括:将多个词干确定为多个词项,一个词干是在不同短语中具有相似语义功能的不同词语的集合。自然语言处理210可以被布置用于检测和组合这样的不同的词语以将它们计数在一起。例如,动词的词干(例如“was”、“is”、“were”都是“tobe”类的部分)可以涵盖本应在去识别输出中允许的更多词语。
可以组合以上选项。因此,该处理可以包括使用以上定义的词项来确定词计数。
图3示出了图示使用白名单对非结构化文本进行去识别的方法的实施例的示意性流程图。即使来自白名单的词项的出现不超过阈值,稍后也能够在去识别输出中允许来自白名单的词项。白名单可以是通用的,也可以是为相应领域建立的,也可以是基于过去的去识别事件及时生成的。
在该附图中,该处理描绘了确定白名单310,白名单310包括在去识别输出中允许的词项。而且,通过白名单测试320,通过在去识别输出中允许在白名单中的低比率词项来防止所述移除或掩盖低比率词项。因此,可以创建即使没有通过词计数标准也会被允许的词项(即,低比率词项)的领域特异性白名单。图3示出了使用白名单310的第一方式。将测试在词计数中检测到的任何低比率词语是否存在于白名单中。如果存在于白名单中,则在去识别输出140中允许该词语,如果不存在于白名单中,则掩盖130该词语。
图4示出了图示用于使用置信度列表对非结构化文本进行去识别的方法的实施例的示意性流程图。该实施例中的置信度列表可以是及时建立的领域特异性列表。在该附图中,处理包括确定置信度列表410,置信度列表410包括基于在先前的去识别事件中的词计数结果的针对置信度词项的置信度得分,如由虚线箭头420所指示的。而且,该附图示出了指示调整词计数的虚线箭头430。通过根据置信度得分调节出现次数(k)或阈值来针对置信度词项调整词计数。
置信度列表410中的词语(其可以是通用的,也可以是针对相应领域确定的)具有置信度得分ConfScore。任选地,置信度得分表示在先前的去识别事件中在词计数中置信度词项高于阈值的次数的百分比。调整词计数可以涉及使用ConfScore来调整“词计数”列表中的k,例如变成k=k*ConfScore。针对白名单(领域)中尚不存在的词语的ConfScore的初始值将为1,并且如果在较早的去识别事件中允许该词语,则针对该词语的ConfScore的初始值将根据出现次数而大于1。替代地,可以基于ConfScore来降低阈值,并且/或者可以对ConfScore进行归一化。
在各个实施例中,将黑名单与基于词计数对低比率词项的掩盖进行组合。因此,除了移除诸如HIPAA 18识别符之类的被列入黑名单的词项之外,所提出的方法还移除了出现次数少于阈值的异常词。例如,在本文“我在去医院的路上用兰博基尼接孩子”中,词语“兰博基尼”在全文中很少出现。所提出的方法将通过压制或替换词语“兰博基尼”来掩盖它。
已经在包括6670个不同词语(总共239218)的数据集上测试了如图所示的方法。阈值T被设置为最少出现10次的值。结果如下:
·允许的文本:95%;
·7个允许的来自医学领域的领域词语;
·3个被掩盖的名称(每个出现1次);
·被掩盖的月份的示例:6月(出现3次)、9月(出现1次)。
图5示出了用于对包含非结构化文本的患者数据集进行去识别的方法的实施例。该附图描绘了用于根据多个患者的患者数据的数据集来生成去识别输出的计算机实施的方法。
该方法开始于节点START 301,并且步骤DAT 302表示获得(例如收集和存储)多个个体的患者数据集。患者数据包括非结构化文本。非结构化文本由以自然语言短语排列的词项(例如,词语、数字和符号)组成。而且,获得黑名单,该黑名单具有在去识别输出中不允许的黑名单词项。
任选地,在预处理步骤NLP 303中,对非结构化文本执行自然语言处理以识别词项(例如,如上面所讨论的句法词语位置、词串、词语模式和词干)。
在第一处理词计数WCNT 304中,该方法处理非结构化文本以确定词计数。词计数具有在非结构化文本中的出现次数低于阈值的低比率词项的列表。
在第二过程MASK 305中,该方法处理非结构化文本以移除或掩盖非结构化文本中的低比率词项。而且,应用黑名单:(当词项在黑名单中时)掩盖该词项,或者(当词项不在黑名单中时)允许该词项。最终在步骤OUT306中,该方法生成去识别输出。然后,该方法在步骤END 307中终止。
可以应用以上方法来独立于数据领域地去识别任何非结构化文本数据。可以例如在健康数据分析平台或类似平台中使用以上方法来使去识别医学数据可用于作为研究和数据分析的次级目的。还可以使用以上方法作为与数据湖进行交互的客户端应用程序,以向该应用程序的客户端提供可用数据。此外,还可以将这些方法应用于任何形式的隐私保护计算,该隐私保护计算得到仍然包含个人信息和(例如,用于研究的)任何数据导出的数据集。在实施例中,可以在诊断中使用该方法,其中,针对所述个体的特定疾病或病症的遗传倾向和/或出现情况来分析个体的遗传信息。
该方法可以应用于任何疾病、病症或医学状况。要研究的疾病可以是故意选择的特定疾病。在实施例中,已知要研究的疾病是与特定基因型相关联的疾病。这样的疾病的示例是癌症、免疫系统疾病、神经系统疾病、心血管疾病、呼吸系统疾病、内分泌和代谢疾病、消化系统疾病、泌尿系统疾病、生殖系统疾病、肌肉骨骼疾病、皮肤疾病、先天性代谢紊乱以及其他先天性疾病(例如,前列腺癌、糖尿病、代谢紊乱或精神疾病)。
在实施例中,如图6b(稍后将对其进行讨论)所描绘的,可以在系统1100中实施如利用图1至图4所描述的方法(例如被实施为在计算机上的计算机实施的方法,被实施为专用硬件或这两者的组合)。还如图6a所图示的,用于计算机的指令(例如,可执行代码1020)可以以一系列机器可读物理标记的形式和/或作为一系列具有不同的电学(例如,磁性或光学)性质或值的元件被存储在计算机可读介质1000中。可执行代码可以以瞬态或非瞬态的方式进行存储。计算机可读介质的示例包括存储设备、光学存储设备、集成电路、服务器、在线软件等。该附图示出了光盘1010。
将意识到,本发明适用于适于将本发明付诸实践的计算机程序,特别是载波上或载波中的计算机程序。程序可以为源代码、目标代码、代码中间源以及为部分编译形式的目标代码的形式,或者为适合于在根据本发明的方法的实施方式中使用的任何其他形式。也将认识到,这样的程序可以具有许多不同的架构设计。例如,实施根据本发明的方法或系统的功能的程序代码可以被细分成一个或多个子例程。将功能分布在这些子例程之中的许多不同方式对本领域技术人员来说将是明显的。子例程可以被一起存储在一个可执行文件中,以形成自含程序。这样的可执行文件可以包括计算机可执行指令,例如,处理器指令和/或解读器指令(例如,Java解读器指令)。替代地,子例程中的一个或多个或全部可以被存储在至少一个外部库文件中,并且例如在运行时间时被静态地或动态地与主程序链接。主程序包含对子例程中的至少一个的至少一次调用。子例程也可以包括彼此的功能调用。涉及计算机程序产品的实施例包括对应于在本文中阐述的方法中的至少一个的每个处理阶段的计算机可执行指令。这些指令可以被细分成子例程和/或被存储在可以被静态地或动态地链接的一个或多个文件中。涉及计算机程序产品的另一实施例包括对应于在本文中阐述的系统和/或产品中的至少一个的每个单元的计算机可执行指令。这些指令可以被细分成子例程和/或被存储在可以被静态地或动态地链接的一个或多个文件中。
计算机程序的载体可以为能够承载程序的任何实体或设备。例如,载体可以包括数据存储装置,例如,ROM(例如,CD ROM或半导体ROM),或者磁性记录介质(例如,硬盘)。此外,载体可以为可传输载体,例如,电信号或光信号,它们可以经由电缆或光缆或通过无线电或其他手段来传送。当程序被实施在这样的信号中时,载体可以包括这样的线缆或其他设备或器件。替代地,载体可以为程序被嵌入其中的集成电路,所述集成电路适于执行相关的方法,或者适于在对相关的方法的执行中使用。
图6a示出了具有包括计算机程序1020的可写部分1010的计算机可读介质1000,计算机程序1020包括用于使处理器系统在参考图1-4描述的系统中执行上述方法和过程中的一项或多项的指令。计算机程序1020可以作为物理标记或者借助于对计算机可读介质1000的磁化而被体现在计算机可读介质1000上。然而,也可以想到任何其他合适的实施例。此外,将意识到,虽然计算机可读介质1000在这里被示为光盘,但是计算机可读介质1000可以是任何合适的计算机可读介质(例如,硬盘、固态存储器、闪存存储器等)并且可以是不可记录的或可记录的。计算机程序1020包括用于使处理器系统执行所述方法的指令。
图6b以示意性表示示出了根据参考图1-5描述的设备或方法的实施例的处理器系统1100。处理器系统可以包括电路1110(例如,一个或多个集成电路)。在该附图中示意性地示出了电路1110的架构。电路1110包括处理单元1120(例如,CPU),其用于运行计算机程序部件以执行根据实施例的方法和/或实施其模块或单元。电路1110包括用于存储编程的代码、数据等的存储器1122。存储器1122的部分可以是只读的。电路1110可以包括数据接口1126,其包括例如天线、用于互联网的收发器、连接器或两者等。电路1110可以包括专用集成电路1124,其用于执行该方法中定义的部分或全部处理。处理器1120、存储器1122、专用IC 1124和通信元件1126可以经由互连1130(例如,总线)彼此连接。处理器系统1110可以被布置用于分别使用连接器和/或天线来进行有线和/或无线通信。
系统1100被配置为如利用以上方法(例如,参考图3所阐述的方法)所描述的那样对患者数据进行匿名化。该系统包括被配置为访问多个个体的患者数据的数据接口1126。数据接口可以与本地存储单元或服务器上的数据库通信。数据接口可以被连接到包括患者数据的外部储存库(例如,合适的电子存储设备和/或数据库)。替代地,可以从系统1122的内部数据存储装置访问患者数据或数据库。通常,数据接口可以采用各种形式,例如,去往局领域网或广域网(例如,互联网)的网络接口、去往内部或外部数据存储装置的存储接口等。
此外,系统1100可以具有用户输入接口,其被配置为从用户输入设备接收用户输入命令以使得用户能够提供用户输入,例如选择或定义特定疾病、病症或医学状况,以便随后确定与所述疾病、病症或医学状况有关的患者数据的子集。用户输入设备可以采用各种形式,包括但不限于计算机鼠标、触摸屏、键盘等。
将意识到,为了清楚起见,以上描述参考不同的功能单元和处理器来描述本发明的实施例。然而,将意识到,可以在不脱离本发明的情况下使用不同的功能单元或处理器之间的任何合适的功能分布。例如,被图示为由单独的单元、处理器或控制器执行的功能可以由相同的处理器或控制器来执行。因此,对特定功能单元的引用仅被视为对用于提供所描述的功能的合适单元的引用,而不是指示严格的逻辑或物理结构或组织。本发明能够以包括硬件、软件、固件或这些项目的任意组合的任意适合形式来实施。
根据另外的方面,本发明涉及该方法和/或计算机程序产品在研究和/或诊断中的用途。在实施例中,该方法和/或计算机程序产品用于生物信息学研究。该方法、系统和/或计算机程序产品在生物信息学研究中的用途包括采集多个个体的患者数据。研究领域的示例包括基因组学、遗传学、转录组学、蛋白质组学和系统生物学。
在替代实施例中,该方法、系统和/或计算机程序产品可以用于诊断,其中,利用个体的患者数据来分析该个体是否受到特定疾病的影响或者是否处于罹患所述疾病的风险或者是否受到所述疾病的影响。个体确定他们的患者数据已经得到恰当匿名化。
在当提及单数名词时使用不定冠词或定冠词(例如,“一”、“一个”、“该”)的情况下,除非特别说明,否则这些不定冠词或定冠词(例如,“一”、“一个”、“该”)包括该名词的复数形式。此外,说明书和权利要求书中的术语第一、第二、第三等用于区分相似的元件,而不一定是用于描述序列或时间顺序。应当理解,如此使用的术语在适当的情况下是可互换的,并且本文描述的本发明的实施方式能够以不同于本文描述或图示的其他顺序来操作。此外,说明书和权利要求书中的顶部、底部、上方、下方、之外等术语仅用于描述目的,而不一定是用于描述相对位置。应当理解,如此使用的术语在适当的情况下是可互换的,并且本文描述的本发明的实施例能够以不同于本文描述或图示的其他取向来操作。应当注意,在本说明书和权利要求书中使用的术语“包括”不应被解读为限于此后列出的单元;本发明并不排除其他元件或步骤。因此,表述“包括单元A和单元B的设备”的范围不应限于仅由部件A和部件B组成的设备。这意味着关于本发明,仅仅是设备的相关部件是A和B。
应当注意,上述实施例说明而不是限制本发明,并且本领域技术人员将能够在不脱离权利要求书的范围的情况下设计出许多替代实施例。在权利要求中,括号内的任何附图标记都不应被解释为对权利要求书的限制。本发明可以借助于包括若干有区别的元件的硬件来实施,也可以借助于经适当编程的计算机来实施。在列举了若干单元的装置型权利要求中,这些单元中的若干单元可以由同一项硬件来体现。在互不相同的从属权利要求中记载某些措施的事实并不指示无法有利地使用这些措施的组合。
- 自由文本去识别
- 干扰信息去除方法、去干扰模型组件及垃圾文本识别系统