一种频段切割方法及频段切割装置
文献发布时间:2023-06-19 11:27:38
技术领域
本发明涉及听力学领域,特别涉及一种频段切割方法及频段切割装置。
背景技术
每个人的听觉心理基准是不同的,例如不同的人对同样的声音会有不同的心理感知,同样的歌曲,有些人觉得动听,有些人觉得普通;同样强度的声音,有人觉得刚刚好,有人就觉得声音太大或太小。对于存在听力损失的患者,他们的声音感知更加敏感,然而目前的听力康复手段所采用的助听器或人工电子耳蜗植入则甚少考虑听觉心理基准和听觉感知喜好,它们的目的主要是为了放大外界声音和提高语音清晰度。助听器或人工电子耳蜗之所以无法做到个性化地输出声音,一个方面是技术上存在一定的局限,不能满足精细个性化需求;另一个方面是传统听觉康复的主要对象是严重的听力损失患者,而大多数不严重的听损者或者还没有达到严重程度的听力损失患者的需求还没引起医生和患者重视,因为不完全听力损失患者交流障碍不显著,自身可以应对大多数交流环境,所以按照目前的算法,不完全听力损失的患者是难以接受使用助听器来矫正听力的。
目前市面上确实除了助听器之外,就没有其他专门针对于那些不完全听力损失(新近发生听力损失或者听力损失没有导致显著听力交流障碍) 患者的矫正听力的产品可供选择,既然没有产品,自然就没有专门的测量和评估这些患者听觉生理的具体方法了。
目前常用的评估助听器效果的方式一般采用例如声场测听和真耳测试等,这些方式只能从物理声学的角度测量助听器验配以后的增益,而无法测量助听器验配以后的听觉心理基准和听觉心理感知状态,即缺少助听器验配满意度的测量方式。例如助听器使用者需要欣赏音乐,而现有助听器声音输出模块就不能满足对音乐这种宽频谱声音的表达,通常助听器声音输出模块主要偏重于对语音频谱的表达,缺少低音和高音部的表达能力。而现有TWS耳机(TWS,True Wireless Stereo的缩写,即真正无线立体声),由于偏向低音部的表达,所以通常采用动圈喇叭,缺少高音部。因此,目前的助听器均无法得知患者的听觉到底需要哪些声音或者个体听力状态适合哪些声音。
发明内容
本发明的目的是为了提供一种频段切割方法,该频段切割方法专门用于测量和评估那些不完全听力损失患者对声音,尤其是音乐的输出是否达到其心理感知的需求,通过把声音分割成不同的频段,让受试者自己去调试和匹配输出的声音音量大小,得到更个性化的声音,从而指导后续助听器的验配,有效提高使用者佩戴不同听力矫正装置的舒适性,还提供了一种频段切割装置,至少可以解决上述问题之一。
为实现上述目的,根据本发明的一个方面,提供了一种频段切割方法,包括相互连接的频段切割装置和听力计,频段切割方法包括以下步骤:
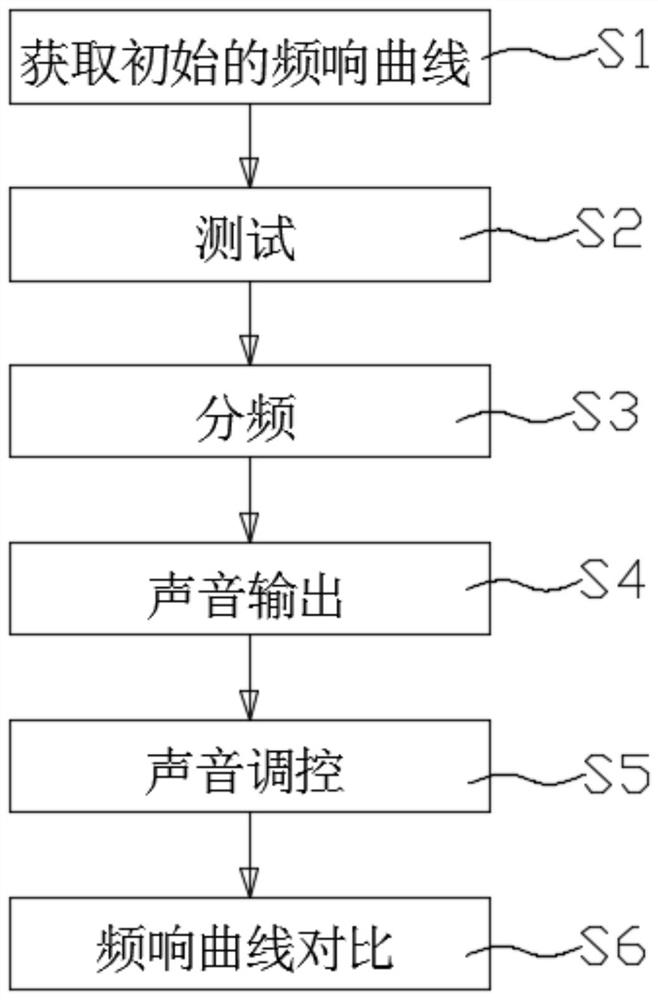
S1、获取初始的频响曲线:将频段切割装置与听力计进行数据连接,预先获得受试者的听力阈值数据,将获得的听力阈值数据与频段切割装置的存储器中的声音信号进行匹配,得到初始的频段切割装置,确定初始状态的声音输出强度;
S2、测试:听力计设有声音输出模块,让受试者佩戴好声音输出模块,然后让其随意选择一段音乐声或者或者其他声音信号,并开始进行测试;
S3、分频:频段切割装置把选择的一段音乐声或者或者其他声音信号切割成低、中、高三个频段;
S4、声音输出:通过声音输出模块将分割完成后的不同频段的声音信号输出;
S5、声音调控:受试者根据听到的不同频段的声音信号对各频段声音信号的强度进行调节,直到受试者感觉各频段声音信号的强度舒适为止。
本发明提供了一种频段切割方法,具体过程为:受试者自主选择播放自己喜爱的音乐,通过将播放的音乐与受试者通过测听获得的听力阈值匹配,保证受试者对音乐所包含的频响做出响应;然后,将匹配到的音乐声或者或者其他声音信号切割低、中、高三个不同的频段,让受试者自己去调试和匹配输出的声音音量大小,得到更个性化的声音,从而指导后续助听器的验配,有效提高验配速度和验配质量,且由此获得的助听器等听力矫正装置的舒适性强。
在一些实施方式中,在步骤S5之后还包括:
S6、频响曲线对比:经受试者调整后,获得新的频响曲线,将新的频响曲线与初始的频响曲线进行比对,获取调试参数。
由此,根据该调试参数可以对助听器等听力矫正设备进行参数调整,采用新的频响曲线来进行助听器等矫正听力设备的调试参数,通过这样的调试后,使用者将获得更符合自身听觉感知的聆听体验,大大提高验配效率和验配质量。
在一些实施方式中,在步骤S5中,声音信号强度的调节包括以下步骤:
首先,低频频段和高频频段的强度初始设置到零,然后由受试者自己去调控这两个频段的音量大小;
其次,再进行中频频段音量的调节,直到受试者感觉各频段声音信号的强度舒适为止。
由此,既能做到主(中频频段)次(低频频段和高频频段)分明,又可以保证所有频段都可以覆盖。
在一些实施方式中,在步骤S3中,低频频段为125~500Hz,中频频段为500~3000Hz,高频频段为3000~8000Hz。由此,由于绝大部分的言语和音乐声等声音信号主要集中在500~3000Hz,所以优选以这部分频段作为中频,实际操作中可以根据具体情况和具体对象进行改变。
根据本发明的另一个方面,还提供了一种能够与听力计连接的频段切割装置,该频段切割装置包括控制器、编码均衡器、分频器、频带控制器、存储器和数据传输模块,数据传输模块分别与听力计、控制器连接,编码均衡器、分频器、频带控制器、存储器均与控制器连接;
数据传输模块配置为将听力计中的数据转录至控制器以及将分频完成后的声音信号输出;
存储器配置为存储不同类型的音乐声或者其他声音信号;
编码均衡器配置为预先将播放的声音信号与受试者通过测听获得的听力数据进行匹配;
分频器配置为将匹配到的全频段声音信号分割成若干个不同的频段;
听力计设置有声音输出模块,声音输出模块配置为将分割后的不同频段的声音信号输出;
频带控制器配置为对不同频段输出声音的强度进行调节。
由此,本发明的频段切割装置的工作原理为:受试者自主选择播放自己喜爱的音乐,通过编码均衡器把播放的音乐与受试者通过测听获得的听力阈值匹配,保证受试者能够对音乐所包含的频响做出响应;然后,利用分频器切割成多个频段,受试者利用频带控制器自主调节各频段的声音强度(即音量)至最舒适状态,得到调节完成的频响曲线;最后,我们对比初始播放频响曲线与受试者调节后的频响曲线差异判定受试者的听觉心理感知需求,便于后续进行精准有效的助听器等矫正听力设备的验配。
本发明提供了一种全新结构的频段切割装置,该装置专门用于测量和评估那些不完全听力损失患者对声音,尤其是音乐的输出是否达到其心理感知的需求,通过把声音分割成不同的频段,让受试者自己去调试和匹配输出的声音音量大小,得到更个性化的声音,从而指导后续助听器的验配,有效提高使用者佩戴不同听力矫正装置的舒适性。
在一些实施方式中,频段切割装置还包括操控模块,操控模块与控制器连接,操控模块配置为受试者在测试过程中进行自主操控。
在一些实施方式中,操控模块包括操控屏和操控键。
在一些实施方式中,操控键包括输出音乐类型选择按钮、音量强度调节按钮、耳别选择按钮。
在一些实施方式中,分频器配置为将匹配到的全频段声音信号分割成低、中、高三个不同的频段。
在一些实施方式中,听力计设置有输入端口和处理器,输入端口和声音输出模块均与处理器连接,处理器通过数据传输模块与控制器通信连接,存储器可写入患者听力图和/或HLD数据,声音输出模块包括多个扬声器;
输入端口配置为输入声音信号;
处理器配置为接收来自输入端口的声音信号并将其传输至控制器以及控制不同数量的扬声器将分割完成后的不同频段的声音信号输出;
处理器可以独立控制每个扬声器的开启与闭合。
由此,本发明的听力计改变了传统声音输出设备使用的单个扬声器的一贯做法,利用多个扬声器匹配来自频段切割装置切割形成的多个频段和频宽的变化需求,当处理器接收到输入端口输入的声音信号时,将其与存储器的数据进行比对,在声强级较大的环境中,处理器控制部分扬声器关闭,使得部分频段无法输出;而在安静环境中,处理器控制所有扬声器全部开启,即可以实现所有频段声音的输出。
本发明可以实现频段数量以及频宽的控制,改变固定频段数量以及固定处理参数的弊端,可以更好地依据随机声音的特征匹配个体听力状态。
本发明装置一方面可以有效地让扬声器输出清晰而不繁杂的声音,改善使用者的聆听体验,另一方面可以有效地控制外界复合声进入人耳的强度,从而保护使用者的听力减少“听觉疲劳”,很好地保护使用者的听力不受损害。
在一些实施方式中,输入端口与麦克风组件连接,用于输入麦克风组件采集到的声音信号。由此,麦克风组件用于接收来自外界的声音。
在一些实施方式中,输入端口与音频播放器连接,用于输入音频播放器播放的声音信号。由此,音频播放器用于播放声音、音乐等声音信号。
本发明的有益效果:
本发明提供了一种频段切割方法,具体过程为:受试者自主选择播放自己喜爱的音乐,通过将播放的音乐与受试者通过测听获得的听力阈值匹配,保证受试者对音乐所包含的频响做出响应;然后,将匹配到的音乐声或者或者其他声音信号切割低、中、高三个不同的频段,让受试者自己去调试和匹配输出的声音音量大小,得到更个性化的声音,从而指导后续助听器的验配,有效提高验配速度和验配质量,且由此获得的助听器等听力矫正装置的舒适性强。
本发明提供了一种全新结构的频段切割装置,该装置专门用于测量和评估那些不完全听力损失患者对声音,尤其是音乐的输出是否达到其心理感知的需求,通过把声音分割成不同的频段,让受试者自己去调试和匹配输出的声音音量大小,得到更个性化的声音,从而指导后续助听器的验配,有效提高使用者佩戴不同听力矫正装置的舒适性。
附图说明
图1为本发明一实施方式的频段切割方法的简化流程图;
图2为本发明一实施方式的声音信号分频段装置的简化结构框图;
图3为图2所示的声音信号分频段装置的进一步细化后的结构框图;
图4为图2所示的声音信号分频段装置的操控模块的简化结构示意图。
图1~4中的附图标记:1-听力计;2-频段切割装置;21-控制器;22-编码均衡器;23-分频器;24-频带控制器;25-存储器;26-数据传输模块;27- 操控模块;11-处理器;12-输入端口;13-声音输出模块;14-麦克风组件; 15-音频播放器;16-电池;17-充电端口;18-DC/DC转换模块;19-充放电控制模块;271-操控屏;272-操控键;271a-主屏幕;271b-项目名称显示区; 272a-输出音乐类型选择按钮;272b-音量强度调节按钮;272c-耳别选择按钮。
具体实施方式
下面结合附图对本发明作进一步详细的说明。
图1示意性地显示了一种实施方式的一种频段切割方法。
本频段切割方法基于相互连接的频段切割装置2和听力计1。
该频段切割方法包括以下步骤:
S1、获取初始的频响曲线:将频段切割装置2与听力计1进行数据连接,预先获得受试者的听力阈值数据,将获得的听力阈值数据与频段切割装置2的存储器25中的声音信号进行匹配,得到初始的频段切割装置2,确定初始状态的声音输出强度;
S2、测试:听力计1设有声音输出模块13,让受试者佩戴好声音输出模块13,然后让其随意选择一段音乐声或者或者其他声音信号,并开始进行测试;
S3、分频:频段切割装置2把选择的一段音乐声或者或者其他声音信号切割成低、中、高三个频段;
S4、声音输出:通过声音输出模块13将分割完成后的不同频段的声音信号输出;
S5、声音调控:受试者根据听到的不同频段的声音信号对各频段声音信号的强度进行调节,直到受试者感觉各频段声音信号的强度舒适为止。
在步骤S5之后还包括:
S6、频响曲线对比:经受试者调整后,获得新的频响曲线,将新的频响曲线与初始的频响曲线进行比对,获取调试参数。
由此,根据该调试参数可以对助听器等听力矫正设备进行参数调整,采用新的频响曲线来进行助听器等矫正听力设备的调试参数,通过这样的调试后,使用者将获得更符合自身听觉感知的聆听体验,大大提高验配效率和验配质量。
在步骤S5中,声音信号强度的调节包括以下步骤:
首先,低频频段和高频频段的强度初始设置到零,然后由受试者自己去调控这两个频段的音量大小;
其次,再进行中频频段音量的调节,直到受试者感觉各频段声音信号的强度舒适为止。
由此,既能做到主(中频频段)次(低频频段和高频频段)分明,又可以保证所有频段都可以覆盖。
在步骤S3中,低频频段为125~500Hz,中频频段为500~3000Hz,高频频段为3000~8000Hz。由此,由于绝大部分的言语和音乐声等声音信号主要集中在500~3000Hz,所以优选以这部分频段作为中频,实际操作中可以根据具体情况和具体对象进行改变。
本发明提供了一种频段切割方法,具体过程为:受试者自主选择播放自己喜爱的音乐,通过将播放的音乐与受试者通过测听获得的听力阈值匹配,保证受试者对音乐所包含的频响做出响应;然后,将匹配到的音乐声或者或者其他声音信号切割低、中、高三个不同的频段,让受试者自己去调试和匹配输出的声音音量大小,得到更个性化的声音,从而指导后续助听器的验配,有效提高验配速度和验配质量,且由此获得的助听器等听力矫正装置的舒适性强。
图2~4示意性地显示了一种实施方式的一种频段切割装置2。
如图2~4所示,该频段切割装置2包括控制器21、编码均衡器22、分频器23、频带控制器24、存储器25和数据传输模块26。数据传输模块26 分别与听力计1、控制器21连接。编码均衡器22、分频器23、频带控制器24、存储器25均与控制器21电性连接。
数据传输模块26配置为将听力计1中的数据转录至控制器21以及将分频完成后的声音信号输出至听力计1;
存储器25配置为存储不同类型的音乐声或者其他声音信号;
编码均衡器22配置为预先将播放的声音信号与受试者通过测听获得的听力数据进行匹配;
分频器23配置为将匹配到的全频段声音信号分割成若干个不同的频段;
听力计1设置有声音输出模块13,声音输出模块13配置为将分割后的不同频段的声音信号输出;
频带控制器24配置为对不同频段输出声音的强度进行调节。
本实施方式的频段切割装置2还包括操控模块27,操控模块27与控制器21连接,操控模块27配置为受试者在测试过程中进行自主操控。
如图3所示,操控模块27包括操控屏271和操控键272。本实施方式的操控屏271可以为触摸屏。操控键272包括但不限于输出音乐类型选择按钮272a、音量强度调节按钮272b、耳别选择按钮272c。比如还可以根据需要设置电源按钮、紧急呼叫按钮等。
本实施方式的分频器23主要将匹配到的全频段声音信号分割成低、中、高三个不同的频段,其中,低频频段为125~500Hz,中频频段为500~3000Hz,所述高频频段为3000~8000Hz。由于绝大部分的言语和音乐声等声音信号主要集中在500~3000Hz,所以优选以这部分频段作为中频,实际操作中可以根据具体情况和具体对象对该范围进行微调。
如图2所示,本实施方式的听力计1设置有输入端口12和处理器11。输入端口12可以设置于听力计1的壳体外壁,处理器11可以设置于听力计1的内部。本实施方式的处理器11可以为控制芯片等。输入端口12和声音输出模块13均与处理器11连接,处理器11通过数据传输模块26与控制器21通信连接,存储器25可写入患者听力图和/或HLD数据。声音输出模块13包括多个扬声器131。
输入端口12配置为输入声音信号;
处理器11配置为接收来自输入端口12的声音信号并将其传输至控制器21以及控制不同数量的扬声器131将分割完成后的不同频段的声音信号输出;
处理器11可以独立控制每个扬声器131的开启与闭合。
由此,本发明的听力计1改变了传统声音输出设备使用的单个扬声器131的一贯做法,利用多个扬声器131匹配来自频段切割装置2切割形成的多个频段和频宽的变化需求,当处理器11接收到输入端口12输入的声音信号时,将其与存储器25的数据进行比对,在声强级较大的环境中,处理器11控制部分扬声器131关闭,使得部分频段无法输出;而在安静环境中,处理器11控制所有扬声器131全部开启,即可以实现所有频段声音的输出。
输入端口12可以与麦克风组件14或者音频播放器15连接。麦克风组件14用于接收来自外界的声音,输入端口12用于输入麦克风组件14采集到的声音信号。音频播放器15用于播放声音、音乐等声音信号,输入端口 12用于输入音频播放器15播放的声音信号。
本实施方式的HLD数据包括单耳听力阈值差和双耳听力阈值差。由此,单双耳都可以适用,适用范围广。
听力计1还设置有电池16,电池16与存储器25、处理器11和扬声器 4均电性连接。
听力计1还设置有充电端口17,充电端口17与电池16、处理器11电性连接。由此,充电端口17用于给听力计1充电。
如图3所示,本实施方式的听力计1还设有充放电控制模块19和DC/DC转换模块18。充放电控制模块19与处理器11电性连接,充放电控制模块19分别与电池16和DC/DC转换模块18电性连接,充电端口17与 DC/DC转换模块18电性连接。由此,当将装置通过充电端口17与外界电源连接时,通过充电端口17为各用电部件提供电能并把多余的电能输送到电池16进行存储,在断开电源后时,电池16内存储的电能则可继续为各设备提供电能,可保证断电情况下也能正常运行一定时间,便于随身携带。
本实施方式的电池16可以为蓄电池,充放电控制模块19可以为单片机。充放电控制模块19可以控制电池16的充放电并显示电压。当蓄电池 16电压大于蓄电池16额定电压24V的5%时,单片机控制蓄电池16的充电电路截止,同时,保持蓄电池16的放电电路导通,对外送电。电池16 电压小于18V时,单片机发出让放电电路截止,充电电路导通的信号,停止对外送电,进入充电状态。电池16电压介于24V与18V之间时,充电电路和放电电路都保持导通,充放电同时进行。电压显示原理是储电池16 电压通过分路电阻将分压送入单片机,经过处理器11计算把电压值显示在三位数码管上。
DC/DC转换模块18可以为采用9个以AOZ1014为核心的DC-DC模块。
本发明的听力计1改变了传统声音输出设备使用的单个扬声器 131的一贯做法,利用多个扬声器131匹配来自处理器11的频段和频宽的变化需求,当麦克风接收到声音信号时,与存储器3的数据比对,在声强级较大的环境中,处理器11控制部分扬声器131关闭,使得部分频段无法输出;而在安静环境中,处理器11控制所有扬声器131全部开启,即可以实现所有频段声音的输出。本发明可以实现频段数量以及频宽的控制,改变固定频段数量以及固定处理参数的弊端,可以更好地依据随机声音的特征匹配个体听力状态。本发明装置一方面可以有效地让扬声器131 输出清晰而不繁杂的声音,改善使用者的聆听体验,另一方面可以有效地控制外界复合声进入人耳的强度,从而保护使用者的听力减少“听觉疲劳”,很好地保护使用者的听力不受损害。
以上所述的仅是本发明的一些实施方式。对于本领域的普通技术人员来说,在不脱离本发明创造构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
- 一种频段切割方法及频段切割装置
- 一种多频段天线装置及具有该多频段天线装置的手持终端