基于开源数据挖掘的商业网点选址方法、系统、设备及介质
文献发布时间:2023-06-19 11:29:13
技术领域
本发明涉及一种商业网点选址方法,特别是涉及一种基于开源数据挖掘的商业网点选址方法、系统、设备及介质。
背景技术
商业网点的选址意义非常重大,从宏观的城市规划来说,商业网点是城市高质量发展的重要组成部分,影响着城市的活力及市民的出行。合理的商业网点布局能增加城市的运行效率;从微观的企业及个体来说,商业网点是经营发展基本单元,城市不同用地与商业的兼容性也是商业网点选址是否能落实的关键因素。其选址相较于其他因素来说,具有长期性和固定性——当外部环境产生变化时,其他经营因素都可以进行调整,而选址一旦确定就难以变动,选址合适,企业和个体都可以长期受益。
现有的商业选址方法中,主要考虑人口、交通、现有商业聚集度、商铺租金等因素,这些因素固然是商业选址需要考虑的核心指标,但是这些指标并不全面,同时也存在数据使用量小,未从城市整体进行考虑,不同类型规模的商业网点难以用统一标准确定是否适合建设等问题。已有学者使用了共享单车交通出行数据来分析城市的交通热点区域,印证了交通热点区与商业有着高度相关性,同时,城市不同用地与商业的兼容性也是商业网点选址是否能落实的关键因素。
发明内容
为了解决上述现有技术的缺陷,本发明提供了一种基于开源数据挖掘的商业网点选址方法、系统、设备及介质,其基于开源数据挖掘的数据,结合两步聚类算法进行分析,根据分析的结果,可以为城市不同规模、不同类别商业网点选址提供辅助与参考。
本发明的第一个目的在于提供一种基于开源数据挖掘的商业网点选址方法。
本发明的第二个目的在于提供一种基于开源数据挖掘的商业网点选址系统。
本发明的第三个目的在于提供一种计算机设备。
本发明的第四个目的在于提供一种存储介质。
本发明的第一个目的可以通过采取如下技术方案达到:
一种基于开源数据挖掘的商业网点选址方法,所述方法包括:
通过多源数据开放平台获取目标区域的数据;
对所述目标区域进行网格划分并编号,并依据获取的数据构建聚类选址的指标体系;
对所述目标区域的数据进行预处理;
根据预处理后的数据,分别链接划分的网格,统计所述指标体系中每项影响因素的值;
根据所述网格的编号,将所述指标体系中每项影响因素的值进行统计,并运用两步聚类算法进行分析;
根据两步聚类算法的分析结果,给予不同类别、不同规模的商业网点的选址建议。
进一步的,所述对所述目标区域进行网格划分并编号,每一个网格是选址的基本单元,并依据获取的数据构建聚类选址的指标体系,具体包括:
提取所述目标区域的边界,创建网格面要素覆盖所述目标区域边界并依据边界进行裁剪,得到对应编号的网格;
根据商业网点选址需要考虑的因素,将聚类指标分为人口因素、共享单车出行因素、商铺租金因素、交通综合因素、商业聚集度因素、土地利用因素六大类。
进一步的,所述目标区域的数据包括人口密度、共享单车出行、商铺租金、城市道路交通、商业POI、土地利用数据;其中,商业POI数据包括餐饮类商业POI、金融类商业POI、购物类商业POI数据;
所述对所述目标区域的数据进行预处理,具体包括:
根据人口密度栅格数据,基于自然间断点分级法分为五类,对应区间由低到高赋值,得到人口重分类栅格图,并将人口重分类栅格图转化为有序类别变量;
根据共享单车出行数据,选择线追踪间隔工具,基于起始点与结束点进行线追踪分析,得到共享单车的路径线数据;
利用核密度估计法,选取租金字段处理商铺租金数据,得到商铺租金评价栅格图;根据得到的商铺租金评价栅格图,基于自然间断点分级法分类,对应区间由低到高赋值,得到商铺租金重分类栅格图,并将商铺租金重分类栅格图转化为有序类别变量;
利用核密度估计法处理商业POI数据,分别得到餐饮类、购物类、金融类商业聚集度分布栅格图;
根据得到的餐饮类、购物类、金融类商业聚集度分布栅格图,基于自然间断点分级法分类,对应区间由低到高赋值,得到餐饮类、购物类、金融类商业聚集度重分类栅格图,并将所有的重分类栅格图转化为有序类别变量;
针对城市道路交通数据中的城市主干道POI数据、次干道POI数据、城市地铁站点POI数据和城市公交站点POI数据,分别根据距离对城市主干道、城市次干道、公交站点和地铁站点建立缓冲区,并根据距离的远近对各缓冲区赋值,将城市主干道、城市次干道、公交站点和地铁站点转变为有序类别变量;
将土地利用现状图转化成矢量数据,对商业地块和非商业地块赋值分别赋值,得到土地利用分类面要素。
进一步的,所述根据预处理后的数据,分别链接划分的网格,统计所述指标体系中每项影响因素的值,具体包括:
将所述人口重分类栅格图、商铺租金重分类栅格图以及餐饮类、购物类、金融类商业聚集度重分类栅格图分别转化成面要素,并分别与所述划分的网格进行空间链接,分别得到人口密度因素评价、商铺租金因素评价以及餐饮类商业聚集度评价、购物类商业聚集度评价、金融类商业聚集度评价;其中,单个网格的链接值取网格内栅格值的平均值;
将所述共享单车的路径线数据与划分的网格进行空间链接,得到共享单车出行路径长度因素评价;其中,单个网格的链接值取网格内路径长度的总值;
根据所述城市主干道、城市次干道、公交站点和地铁站点缓冲区,运用多因子加权叠加分析法,得到交通综合因素图;
将交通综合因素图转化成面要素,并与划分的网格进行空间链接,得到城市道路交通因素评价;其中,单个网格的链接值取网格内栅格值的平均值;
将土地利用分类面要素与划分的网格进行空间链接,得到土地利用评价;其中,单个网格的链接值取网格内要素值的平均值。
进一步的,所述多因子加权叠加分析法,具体为:
令主干道距离、次干道距离、地铁站点距离和公交站点距离,四个因子进行叠加分析得出交通综合因素评价,评价模型为:
式中,S为最终交通综合因素评价,W
进一步的,所述根据所述网格的编号,将所述指标体系中每项影响因素的值进行统计,并运用两步聚类算法进行分析,具体包括:
将人口密度因素评价、共享单车出行路径长度因素、商铺租金因素评价、交通因素评价、餐饮类商业聚集度评价、金融类商业聚集度评价、购物类商业聚集度评价、土地利用评价的值统计到一张表格;
根据统计的表格,运用两步聚类算法分析,生成聚类结果表,使类别号对应相应的网格编号;
根据聚类结果表,得到最终成果图;
根据聚类结果表和最终成果图的空间分布,给予不同类别、不同规模的商业网点的选址建议。
进一步的,所述两步聚类算法包括预聚类阶段和聚类阶段,所述预聚类阶段和聚类阶段中均使用了距离测度;
所述预聚类阶段包括:采用BIRCH算法中CF树生长的思想,逐个读取数据集中的数据点,在生成CF树的同时,预先聚类密集区域的数据点,形成诸多小的子簇;
所述聚类阶段包括:以预聚类阶段的结果即子簇作为对象,利用凝聚法,逐个合并子簇,直到达到期望的簇数量。
本发明的第二个目的可以通过采取如下技术方案达到:
一种基于开源数据挖掘的商业网点选址系统,所述系统包括:
获取数据模块,用于通过多源数据开放平台获取目标区域的数据;
网格划分模块,用于对所述目标区域进行网格划分并编号,并依据获取的数据构建聚类选址的指标体系;
数据预处理模块,用于对所述目标区域的数据进行预处理;
统计模块,用于根据预处理后的数据,分别链接划分的网格,统计所述指标体系中每项影响因素的值;
统计与分析模块,用于根据所述网格的编号,将所述指标体系中每项影响因素的值进行统计,并运用两步聚类算法进行分析;
商业网点的选址建议模块,用于根据两步聚类算法的分析结果,给予不同类别、不同规模的商业网点的选址建议。
本发明的第三个目的可以通过采取如下技术方案达到:
一种计算机设备,包括处理器以及用于存储处理器可执行程序的存储器,所述处理器执行存储器存储的程序时,实现上述的商业网点选址方法。
本发明的第四个目的可以通过采取如下技术方案达到:
一种存储介质,存储有程序,所述程序被处理器执行时,实现上述的商业网点选址方法。
本发明相对于现有技术具有如下的有益效果:
本发明基于开源数据挖掘的数据,从城市整体出发,综合考虑了多种因素,城市不同用地与商业的兼容性也是商业网点选址落实的关键因素;并结合两步聚类算法,为城市不同类别、不同规模商业网点选址提供辅助与参考。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图示出的结构获得其他的附图。
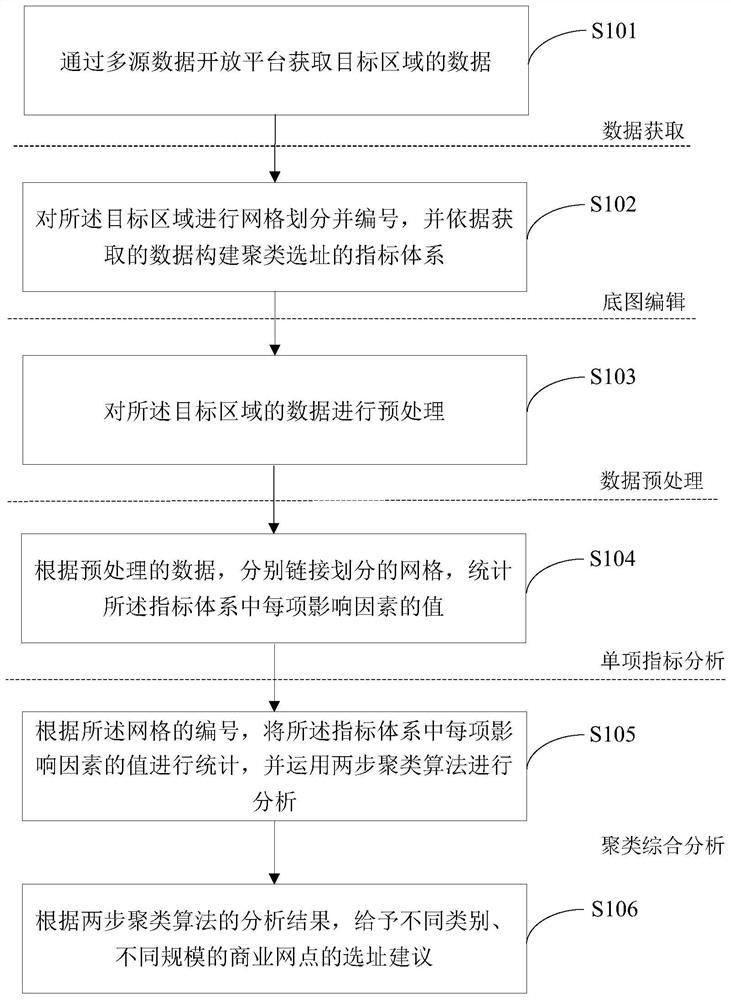
图1为本发明实施例1的基于开源数据挖掘的商业网点选址方法的流程图。
图2为本发明实施例1的人口密度因素评价图。
图3为本发明实施例1的共享单车出行路径长度图。
图4为本发明实施例1的商业租金因素评价图。
图5为本发明实施例1的餐饮类商业聚集度评价图。
图6为本发明实施例1的金融类商业聚集度评价图。
图7为本发明实施例1的购物类商业聚集度评价图。
图8为本发明实施例1的交通因素评价图。
图9为本发明实施例1的用地评价图。
图10为本发明实施例1的模型概要图。
图11为本发明实施例1的聚类质量图。
图12为本发明实施例1的聚类结果表的示意图。
图13为本发明实施例1的基于两步聚类算法的商业选址分区图。
图14为本发明实施例2的基于开源数据挖掘的商业网点选址系统的结构框图。
图15为本发明实施例3的计算机设备的结构框图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1
本实施例以广州市天河区为例,提供了一种基于开源数据挖掘的网点辅助规划选址方法,下面参考附图描述本发明实施例。
图1是本发明实施例1的基于开源数据挖掘的商业网点选址方法的流程图。
S101、通过多源数据开放平台获取目标区域的数据。
所述数据包括人口密度、共享单车出行、商铺租金、城市道路交通、商业POI、土地利用数据;其中,商业POI数据包括餐饮类商业POI、金融类商业POI、购物类商业POI数据;城市道路交通数据包括城市道路数据、公交车站点距离和地铁站站点距离,城市道路数据包括城市主干道距离、城市次干道距离。
在一种实施案例中,对于步骤S101中数据的获取,具体实施方法为:
广州市天河区的人口密度,通过WorldPop网站获得;广州市天河区excel格式的共享单车出行点由摩拜单车App提供2019年9月16日的数据;商铺租金数据、广州市天河区城市道路数据、城市公交车站点数据、城市地铁站站点数据、餐饮类商业POI数据、金融类商业POI数据、购物类商业POI数据,通过高德地图数据库获得;广州市天河区土地利用现状图通过政府官网公示文件获得。
S102、对所述目标区域进行网格划分并编号,并依据获取的数据构建聚类选址的指标体系。
在一种实施案例中,对于步骤S102中依照天河区行政边界,对目标区域进行网格化处理,对网格编号并构建聚类的指标体系,具体实施方法为:
提取广州市天河区行政边界导入GIS软件,创建300m*300m网格面要素覆盖全行政边界并依据边界进行裁剪,得到由对应编号的网格1729个。根据商业网点选址需要考虑的各项因素,将聚类指标分为:人口因素、共享单车出行因素、商铺租金因素、交通综合因素、商业聚集度因素、土地利用因素六大类,涉及10项指标,具体如下表1所示:
表1聚类指标表
S103、对所述目标区域的数据进行预处理。
在一种实施案例中,对于步骤S103中对获取的天河区人口密度、共享单车出行点、商铺租金、城市道路交通、各类商业POI、土地利用数据进行预处理,具体实施方法为:
对于人口因素,将天河区人口密度栅格数据导入GIS软件,选择“重分类”工具基于自然间断点分级法分为五类,对应区间由低到高赋值为“1、2、3、4、5”,得到天河区人口重分类栅格图,其转化为有序类别变量,方便后续聚类分析。
自然间断点分级法,是基于数据中固有的自然分组,对分类间隔加以识别,可对相似值进行最恰当的分组,并可使各个类之间的差异最大化。该分组方法是将数据划分为多个类,而对于这些类,在数据值的差异相对较大的位置处设置其边界。
针对分类结果中某一类的数组计算总偏差平方和(SDAM),记一组结果为A
则其总偏差平方和(SDAM)为:
式(1)、式(2)中,n为数组中元素个数;X
针对分类结果中每个范围的组合,计算类总偏差平方和(SDCM),找到其中最小的一个值,记作SDCM
SDCM
同理分类结果也可以划分为k类的其他情况,依次计算出SDCM
通过计算各种分类的梯度gvf
gvf
对于共享单车出行因素,将广州市天河区周末共享单车出行点数据导入ArcGIS软件,选择线追踪间隔工具,基于起始点与结束点进行线追踪分析,得到共享单车的路径线要素数据。商业网点选址与居民出行有重要关系,而周末的共享单车路径能一定程度上反映居民活动出行的路径,所以共享单车线密度越高、路径越密集的区域,商业价值越高。
对于商业聚集度因素,利用核密度估计法处理天河区餐饮类、购物类、金融类商业POI点可以分别得到餐饮类、购物类、金融类商业聚集度分布栅格图,商业聚集度是商业网带点选址需要参考的重要因素。餐饮店的聚集性越高,对应客流量也会越大,同时餐饮店和周边也会形成良性竞争循环效应,故一般情况下,相关类别聚集性越高的地区越适合该类商业网点的选址。
对于商铺租金因素,利用核密度估计法选取租金字段作为价值参考处理商铺POI点,可以得到天河区商铺租金因素评价示意图,商铺租金对于商业网点选址具有重要意义。
核密度估计法(Kernel Density Estimation)是借助一个移动的单元格对点或线格局的密度进行估计。给定样本点x1,x2,……,xn,利用核心估计模拟出属性变量数据的详细分布。计算二维数据时,d值取2,一个常用的核密度估计函数公式如下:
式中,K(x)称为核函数,(x-x
在核密度估计中,带宽是定义平滑量大小的自由参数,带宽过大或过小均会影响f(x)的结果。采用Silverman的“经验法则”,在f(x)呈正态的假定下,根据Ker,A.P.和B.K.Goodwin的工作,宽带优化计算的公式可简化为:
式中,σ是样本方差。
得到天河区餐饮类、购物类、金融类商业聚集度分布栅格图以及商铺租金评价栅格图后,选择“重分类”工具基于自然间断点分级法分为五类,对应区间由低到高赋值为“1、2、3、4、5”,得到天河区餐饮类、购物类、金融类商业聚集度重分类栅格图以及商铺租金重分类栅格图,这些栅格图被转化为有序类别变量,方便后续聚类分析。
对于交通因素,将天河区主干道、次干道、城市地铁站点POI数据、城市公交站点POI数据分别导入ArcGIS软件,选择“多重缓冲区”工具。对城市主干道以“25m、50m、75m、100m、125m”;对城市次干道以“20m、40m、60m、80m、100m”;对公交站点以“30m、60m、90m、120m、150m”;对地铁站点以“50m、100m、150m、200m、250m”建立缓冲区。同时,因为商业网点选址与道路交通可达性有重要关系,离公共交通站点、主要道路越近,可达性越高,越适合布置商业网点,所以各类因素由远到近赋值“1、2、3、4、5”对应相应缓冲区,使其转变为有序类别变量,方便后续聚类分析。
对于土地利用因素,将天河区土地利用现状图转化成矢量数据导入ArcGIS软件,对商业地块和非商业地块赋值,对商业地块赋值为“5”,对非商业地块赋值为“1”,与商业地块相关性越高,土地利用分类的值越高,从而得到土地利用分类面要素。
至此完成对各项聚类因素数据的初步处理。
S104、根据预处理的数据,分别链接划分的网格,统计所述指标体系中每项影响因素的值。
在一种实施案例中,对于步骤S104根据预处理的数据,链接天河区单元网格,统计各项影响因素的值,具体实施方法为:
将步骤S103中得到的天河区人口重分类栅格图在GIS中利用“栅格转面要素”工具转化成面要素,并与300m*300m的网格进行空间链接,根据相应的有序类别变量,单个网格的链接值取网格内栅格值的平均值,得到图2;
将步骤S103中得到的天河区周末共享单车的路径线要素数据与300m*300m的网格进行空间链接,根据相应的有序类别变量,单个网格的链接值取网格内路径长度的总值,得到图3;
将步骤S103中得到的天河区商铺租金重分类栅格图在GIS中利用“栅格转面要素”工具转化成面要素,并与300m*300m的网格进行空间链接,根据相应的有序类别变量,单个网格的链接值取网格内栅格值的平均值,得到图4;
将步骤S103中得到的天河区餐饮类、金融类、购物类商业聚集度重分类栅格图分别在ArcGIS中利用“栅格转面要素”工具转化成面要素,并与天河区300m*300m的划分网格进行空间链接,根据相应的有序类别变量,单个网格的链接值取网格内栅格值的平均值,得到图5、图6、图7;
将步骤S103中得到的天河区主次干道、公共交通站点缓冲区,运用多因子加权叠加分析法,将主干道距离、次干道距离、地铁站点距离、公交站点距离四个因子进行叠加分析得出交通综合因素评价,评价模型为:
式(7)中,S为最终交通综合因素评价;W
将步骤S103中得到的天河区土地利用分类面要素与300m*300m的网格进行空间链接,单个网格的链接值取网格内要素值的平均值,得到图9;
S105、根据所述网格的编号,将所述指标体系中每项影响因素的值进行统计,并运用两步聚类算法进行分析。
根据天河区单元网格的编号将所有影响因素值统计到一张表格并运用两步聚类算法分析,依据聚类算法分析结果,给予不同类别、规模的商业在天河区的规划选址建议。
在一种实施案例中,对于步骤S105根据天河区单元网格的编号将所有影响因素值统计到一张表格并运用两步聚类算法分析,依据聚类算法分析结果,给予不同类别、规模的商业在天河区的规划选址建议,具体实施方法为:
将步骤S104中的图2、图3、图4、图5、图6、图7、图8、图9依据网格编号导入同一个EXCEL表格,再将表格导入SPSS软件,选择两步聚类工具进行分析。
两步聚类算法,分为两个阶段:
预聚类(pre-clustering)阶段。采用了BIRCH算法中CF树生长的思想,逐个读取数据集中数据点,在生成CF树的同时,预先聚类密集区域的数据点,形成诸多的小的子簇(sub-cluster)。
聚类(clustering)阶段。以预聚类阶段的结果——子簇为对象,利用凝聚法,逐个地合并子簇,直到期望的簇数量。
在这两类运算中都使用了距离测度,距离测度主要采用欧式距离和对数似然距离。
欧式距离是测两个类中心的距离,类中心是指类中所有变量的均值。假设一个数据集Q,有m个样本,每个样本有n个变量指标。则有:
在这个矩阵中(此矩阵在计算过程中并不保存),x
在这个过程当中,欧式距离用d
似然对数距离能处理连续变量和分类变量。它是基于距离的概率值,两类之间的距离会随着两类合并为一类时似然对数的减少而变化。计算似然对数时,连续变量在理想情况下需要满足正态分布,分类变量需要满足多项式分布,而且假定变量之间彼此独立。我们将分类j和分类s的之间的距离定义为d(j,s):
d(j,s)=ξ
在这个过程中,贝叶斯(BIC)或Akaik(AIC)两种判据会对每一种分类进行计算,并对分类数目做初始估计,最终聚类数目将被确定为在初始分类中使两个最接近的类之间距离增长最大的那个聚类数。假定聚类数为J,其计算公式分别如下:
其中,N代表观测量总数,K
分类变量选取:商铺租金因素、餐饮类商业聚集度、购物类商业聚集度、金融类商业聚集度、交通因素评价、人口密度因素评价、用地因素评价7个分项。
连续变量选取:共享单车出行路径长度因素1个分项。
分析结果如图10、图11、图12和下表2所示;其中,模型概要和聚类质量分别如图10和图11所示;聚类结果分为了6类,具体每类的各分项因素情况如下表2所示;在SPSS中生成聚类结果表,如图12所示,类别号对应相应的300m*300m网格的ID编号,重新导入ArcGIS软件,得到最终成果,如图13所示。
表2每类的各分项因素情况表
S106、根据两步聚类算法的分析结果,给予不同类别、不同规模的商业网点的选址建议。
依据图13的空间分布和图12的数据,对不同类别、不同规模商业网点的选址建议,如下表3所示:
表3对不同类别、不同规模商业网点的选址建议
应当注意,尽管以特定顺序描述了上述实施例的方法操作,但是这并非要求或者暗示必须按照该特定顺序来执行这些操作,或是必须执行全部所示的操作才能实现期望的结果。相反,描绘的步骤可以改变执行顺序。附加地或备选地,可以省略某些步骤,将多个步骤合并为一个步骤执行,或将一个步骤分解为多个步骤执行。
实施例2:
如图14所示,本实施例提供了一种基于开源数据挖掘的商业网点选址系统,该系统包括获取数据模块1401、网格划分模块1402、数据预处理模块1403、统计模块1404、统计与分析模块1405和商业网点的选址建议模块1406,各个模块的具体功能如下:
获取数据模块1401,用于通过多源数据开放平台获取目标区域的数据;
网格划分模块1402,用于对所述目标区域进行网格划分并编号,并依据获取的数据构建聚类选址的指标体系;
数据预处理模块1403,用于对所述目标区域的数据进行预处理;
统计模块1404,用于根据预处理后的数据,分别链接划分的网格,统计所述指标体系中每项影响因素的值;
统计与分析模块1405,用于根据所述网格的编号,将所述指标体系中每项影响因素的值进行统计,并运用两步聚类算法进行分析;
商业网点的选址建议模块1406,用于根据两步聚类算法的分析结果,给予不同类别、不同规模的商业网点的选址建议。
本实施例中各个模块的具体实现可以参见上述实施例1,在此不再一一赘述;需要说明的是,本实施例提供的系统仅以上述各功能模块的划分进行举例说明,在实际应用中,可以根据需要而将上述功能分配给不同的功能模块完成,即将内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。
实施例3:
本实施例提供了一种计算机设备,该计算机设备可以是计算机,如图15所示,其包括通过系统总线1501连接的处理器1502、存储器、输入装置1503、显示器1504和网络接口1505,该处理器用于提供计算和控制能力,该存储器包括非易失性存储介质1506和内存储器1507,该非易失性存储介质1506存储有操作系统、计算机程序和数据库,该内存储器1507为非易失性存储介质中的操作系统和计算机程序的运行提供环境,处理器1502执行存储器存储的计算机程序时,实现上述实施例1的商业网点选址方法,如下:
通过多源数据开放平台获取目标区域的数据;
对所述目标区域进行网格划分并编号,并依据获取的数据构建聚类选址的指标体系;
对所述目标区域的数据进行预处理;
根据预处理后的数据,分别链接划分的网格,统计所述指标体系中每项影响因素的值;
根据所述网格的编号,将所述指标体系中每项影响因素的值进行统计,并运用两步聚类算法进行分析;
根据两步聚类算法的分析结果,给予不同类别、不同规模的商业网点的选址建议。
实施例4:
本实施例提供了一种存储介质,该存储介质为计算机可读存储介质,其存储有计算机程序,计算机程序被处理器执行时,实现上述实施例1的商业网点选址方法,如下:
通过多源数据开放平台获取目标区域的数据;
对所述目标区域进行网格划分并编号,并依据获取的数据构建聚类选址的指标体系;
对所述目标区域的数据进行预处理;
根据预处理后的数据,分别链接划分的网格,统计所述指标体系中每项影响因素的值;
根据所述网格的编号,将所述指标体系中每项影响因素的值进行统计,并运用两步聚类算法进行分析;
根据两步聚类算法的分析结果,给予不同类别、不同规模的商业网点的选址建议。
需要说明的是,本实施例的计算机可读存储介质可以是计算机可读信号介质或者计算机可读存储介质或者是上述两者的任意组合。计算机可读存储介质例如可以是——但不限于——电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子可以包括但不限于:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机访问存储器(RAM)、只读存储器(ROM)、可擦式可编程只读存储器(EPROM或闪存)、光纤、便携式紧凑磁盘只读存储器(CD-ROM)、光存储器件、磁存储器件、或者上述的任意合适的组合。
综上所述,本发明通过多源数据开放平台获取多项指标数据,统计各项指标中的每项影响因素的值,将所有影响因素的值统计到一张表格并运用两步聚类算法分析,依据聚类算法分析结果,给予不同类别、不同规模的商业选址建议。可以为城市不同类别、不同规模商业网点规划选址提供辅助与参考。
以上所述实施例仅表达了本发明可能的实施方式,其描述较为具体和详尽,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 基于开源数据挖掘的商业网点选址方法、系统、设备及介质
- 基于区块链的网点选址方法、装置、设备和存储介质