自动化MELD评分方法、终端及存储介质
文献发布时间:2023-06-19 11:44:10
技术领域
本申请涉及大数据处理技术领域,具体涉及自动化MELD评分方法、终端及存储介质。
背景技术
世界卫生组织(World Health Organization,WHO)2017年的报告显示全球范围内估计有3.4亿病毒性肝炎感染。另有调查显示普通人群中约有25%患有非酒精性脂肪性肝病,约有4.5%~9.5%患有肝硬化。终末期肝病是慢性肝病的主要死因,是各种慢性肝脏损害所致的肝病晚期阶段。每年约有77万人死于肝硬化疾病,对人民健康和生命造成严重威胁。
终末期肝病模型(Model for End-Stage Liver Disease,MELD)评分是以血清总胆红素、国际标准化比值(INR)、肌酐结合肝硬化病因来评价慢性肝病患者肝功能储备及预后的评分系统,由Malinchoc等人于2000年首先提出,最初称为“Mayo TIPS模型”,用于预测终末期肝病行经颈静脉肝内门-体分流术后患者的死亡率。后为计算方便,Kamath等对评分进行改良,形成现今使用的MELD评分,其计算公式为:MELD评分=3.8×ln[胆红素(mg/dL)]+11.2×ln(INR)+9.6×ln[肌酐(mg/dL)]+6.4×(病因:胆汁性或酒精性为0,其他为1)。MELD评分的分值越高,其风险越大,生存率越低。MELD评分主要用于≥12岁的患者,对终末期肝病患者在经颈静脉肝内门-体分流术后患者的死亡率中具有良好预测能力,可用于评估移植前患者等该供肝期间的死亡率及肝移植术后的死亡率,还可用于预测非肝移植患者肝病死亡率,具有重要的临床使用价值。2002年开始,美国器官分配网络(The UnitedNetwork for Organ Sharing,UNOS)正式将MELD评分作为确定肝移植器官分配优先权的标准。
目前临床医生在使用MELD评分时是通过翻阅三项血清学指标的检验值,对三个数值取对数并乘以相应系数后联合病因评分进行相加计算,过程较为繁琐,人工计算需要消耗一定的时间且过程可能出现失误,增加了临床医务工作者的负担。同时,MELD评分需要人口信息、诊断、检验等数据的支持。但这些数据通常分散在医院信息系统HIS、电子病历系统EMR、实验室检查信息系统LIS等各医院信息系统。由于这些系统所使用的数据库类型不一致,系统间数据标准不一致,导致现有技术中,这些数据没办法统一融合。现有技术的MELD评分工具是由医生手工进行输入,后台再根据规则进行判断,无法实现自动化提取所需数据。随着大数据时代激发的新技术进步和多学科交叉融合,使MELD评分自动化评分的实现成为可能。
因此,如何依托自主研发建立的肝病和肝癌大数据平台,构建MELD评分自动化评分模型,以服务于临床诊疗工作,提高诊疗效率,是目前亟需解决的问题。
发明内容
本发明的目的之一在于提供自动化MELD评分方法、终端及存储介质,技术方案抽取不同系统中的数据进行规整和统一,筛选出关键指标信息,根据预先设置的规则,对患者进行MELD评分,既能提高工作效率又可以提高评估的准确性。
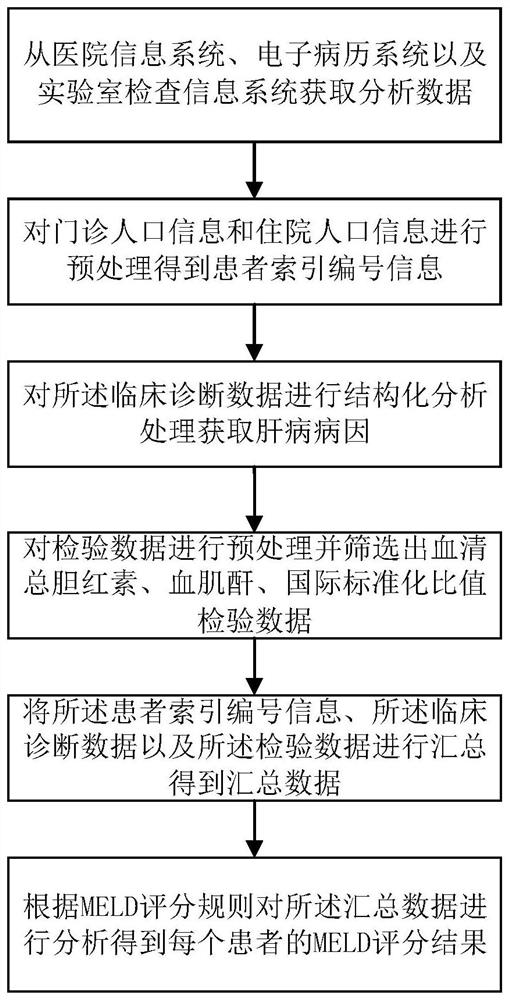
为了解决上述技术问题,本发明提供了自动化MELD评分方法,包括以下步骤:
从医院信息系统、电子病历系统以及实验室检查信息系统获取分析数据;所述分析数据包括人口信息、临床诊断数据以及检验数据;所述人口信息包括门诊人口信息和住院人口信息;
对门诊人口信息和住院人口信息进行预处理得到患者索引编号信息;
对所述临床诊断数据进行结构化分析处理获取肝病病因;
对检验数据进行预处理并筛选出血清总胆红素、血肌酐、国际标准化比值检验数据;
将所述患者索引编号信息、所述临床诊断数据以及所述检验数据进行汇总得到汇总数据;
根据MELD评分规则对所述汇总数据进行分析得到每个患者的MELD评分结果。
进一步地,所述对门诊人口信息和住院人口信息进行预处理得到患者索引编号信息,包括以下步骤:
对所述门诊人口信息以及所述住院人口信息进行数据校验;
将所述门诊人口信息以及所述住院人口信息进行合并并过滤重复数据;
采用Hash算法为每个患者创建唯一索引号;
将患者的唯一索引号与所述临床诊断数据关联形成患者索引编号信息。
进一步地,所述对所述临床诊断数据进行结构化分析处理获取肝病病因,包括以下步骤:
从所述临床诊断数据的诊断结论中分析出肝病病因;
将分析出的肝病病因进行合并并保存至所述临床诊断数据中。
进一步地,所述对检验数据进行预处理并筛选出血清总胆红素、血肌酐、国际标准化比值检验数据,包括以下步骤:
对所述检验数据中的错误数据进行清理;
根据检验类型从所述检验数据中筛选出血清总胆红素、血肌酐以及国际标准化比值的检验数据;
根据检验日期对所述血清总胆红素、血肌酐以及国际标准化比值的检验数据进一步筛选。
进一步地,所述根据MELD评分规则对所述汇总数据进行分析得到每个患者的MELD评分结果,包括以下步骤:
若所述汇总数据中不包含该患者的肝病病因,则设置病因系数为空;若所述汇总数据中包含该患者的肝病病因,则进一步判断该患者的肝病病因若为胆汁性或酒精性,则将病因系数设置为0,否则将病因系数设置为1;
若所述汇总数据中存在该患者的血清总胆红素检测数据,则将血清总胆红素检测结果转换为所需单位的对应值;
若所述汇总数据中存在该患者的血肌酐检测数据,则将血肌酐检测结果转换为所需单位的对应值;
根据所述病因系数、所血清总胆红素检测结果、所述血肌酐检测结果以及所述国际标准化比值,通过MELD计算公式计算得到MELD评分结果。
进一步地,所述的自动化MELD评分方法,包括以下步骤:
将所述MELD评分结果展示在终端界面上。
相应地,本申请还提供了一种自动化MELD评分终端,包括:存储器、处理器以及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述任一项所述方法的步骤。
相应地,本申请还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有一个或者多个程序,所述一个或者多个程序可被一个或者多个处理器执行,以实现上述任一项自动化MELD评分方法的步骤。
区别于现有技术,本发明技术方案的有益效果有:
通过信息化手段将同一患者分散在不同数据库的数据进行规整和统一,提供完善而准确无误的MELD评分数据。构建自动化计算模型进行MELD评分,获取精准地评分结果,为临床与科研带来巨大便利性,从而具备非常高的实用价值,既能提高工作效率又可以提高评估的准确性。
附图说明
图1是本发明自动化MELD评分方法步骤流程图。
图2是本发明对门诊人口信息和住院人口信息进行预处理得到患者索引编号信息步骤流程图。
图3是本发明对所述临床诊断数据进行结构化分析处理获取肝病病因步骤流程图。
图4是本发明对检验数据进行预处理并筛选出血清总胆红素、血肌酐、国际标准化比值检验数据步骤流程图。
图5是本发明根据MELD评分规则对所述汇总数据进行分析得到每个患者的MELD评分结果步骤流程图。
图6是本发明自动化MELD评分终端的结构图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例一
如图1所示,是本发明自动化MELD评分方法步骤流程图,包括以下步骤:
步骤S1、从医院信息系统、电子病历系统以及实验室检查信息系统获取分析数据;所述分析数据包括人口信息、临床诊断数据以及检验数据;所述人口信息包括门诊人口信息和住院人口信息;
由于MELD评分需要人口信息、诊断、检验等数据的支持,但这些数据通常分散在医院信息系统HIS、电子病历系统EMR、实验室检查信息系统LIS等各医院信息系统中。由于这些系统所使用的数据库类型可能不一致,系统间数据标准不一致,因此,要利用这些数据进行分析首先要将这些分散在不同系统的数据抽取到统一平台,通常的步骤包括:1、分别获取医院信息系统HIS、电子病历系统EMR、实验室检查信息系统LIS的数据库账号或热备数据库账号,并赋予该账号对人口信息、临床诊断信息、检验报告的访问权限。2、构建与源数据库类型相同的数据库系统(即目标数据库),将所需数据通过结构化查询语言SQL的CREATETABLE AS SELECT(以下简称为CTAS)创建本地备份表。优选的,为了避免对业务系统的影响,将限制创建临时表的查询频率与时间访问限制。数据查询备份频率默认为30分钟更新,除人口信息外的数据查询时间范围限制为180天内。3、不同数据库之间的数据类型存在差异,将无法匹配的数据类型,使用数据类型转换函数CONVERT进行格式转换,以保证数据在数据库同步时内容不丢失,并形成视图。4、利用数据库同步技术(Oracle GateWay、OracleGoldenGate、ODBC等),将不同类型的数据库包括SQL Server,MySQL等的数据同步到目标数据库,实现在目标数据库系统上的统一查询。5、采用CTAS方法,在目标数据库上创建人口信息、临床诊断信息、检验数据(包括生化和凝血)数据备份表。
步骤S2、对门诊人口信息和住院人口信息进行预处理得到患者索引编号信息;如图2所示,是本发明对门诊人口信息和住院人口信息进行预处理得到患者索引编号信息步骤流程图,包括以下步骤:
步骤S21、对所述门诊人口信息以及所述住院人口信息进行数据校验。
为了保证患者信息的准确性,避免后续分析过程产生各种异常问题,需要对门诊人口信息以及所述住院人口信息进行数据校验,过滤掉其中不正常的数据。具体地,针对人口信息的关键信息处理通常包括:姓名处理,将数字、空格、特殊字符进行清空;生日处理,将字符串格式日期利用to_date函数转换为统一的日期格式,若无法转换类型则标注为异常,将生日小于1900年或大于当前日期的记录标记为异常;性别处理,对数字类型的性别转义为男或女,无法转义的其他类型标记为异常;身份证处理,身份应该满足15位和18位身份证号码,满足地址编码、出身日期、校验位校验,若身份证信息为空或不符合校验机制,将该记录标记为异常;就诊编号处理,将不符合就诊编号格式规范的数据标记为异常;校验病人性别、生日与身份证是否一致,若存在冲突,以身份证信息为主,并记录异常;异常处理,将标记为异常的字段清空,保留该记录的其他字段;重复的个人信息处理,利用字段的相似度匹配方法(Smith-Waterman算法,编辑距离、Cosine相似度函数),对重复人口信息进行排序和合并。通过上述一系列的处理之后,得到的门诊人口信息表和住院人口信息表,其内容包括就诊编号(门诊号、住院号)、姓名、生日、性别、生日、身份证、就诊医院、就诊类型等。
步骤S22、将所述门诊人口信息以及所述住院人口信息进行合并并过滤重复数据。通常,采用数据库SQL的联合查询UNION ALL将门诊人口信息表和住院人口信息表进行合并。同时,对合并之后存在的重复数据进行处理,将数据库中的记录排序,然后通过比较邻近记录是否相似来检测记录是否重复,利用消除重复记录的算法(优先队列算法、近邻排序算法、多趟近邻排序等)或模糊匹配的策略,对姓名、身份证、性别、生日相同的病人进行个人信息合并。
步骤S23、采用Hash算法为每个患者创建唯一索引号。
在不同的医疗子系统中,使用的主索引各有不同,比如无法用住院号查询病人在门诊做的实验室检查。因此,在本发明的实施例中,需要通过建立主索引作为病人唯一的标识,将病人在不同的信息化系统的数据库有效地关联在一起,保证了病人在各个医疗信息系统中个人信息的一致性、完整性和准确性,以及门诊或住院期间信息共享。具体实现上,将人口信息用Hash算法创建病人主索引(Enterprise Master PatientIndex,简称EMPI)。
步骤S24、将患者的唯一索引号与所述临床诊断数据关联形成患者索引编号信息,其内容包括EMPI、就诊编号、姓名、身份证、性别、生日、入院日期。
步骤S3、对所述临床诊断数据进行结构化分析处理获取肝病病因。如图3所示,是本发明对所述临床诊断数据进行结构化分析处理获取肝病病因步骤流程图,包括以下步骤:
步骤S31、从所述临床诊断数据的诊断结论中分析出肝病病因;使用自然语言处理技术,对诊断数据的诊断结论进行后结构化处理,分别获取结构化的诊断数据。具体而言,可以通过下述过程实现:在目标数据库中,对于初步诊断、入院诊断中涉及的肝病病因,利用Oracle的正则化表达式regexp_substr,通过正则表达式“[^+;;,,、]*(酒精性)?肝(炎|硬化|损伤|损害)[^+;;,,、]*”、“[^+;;,,、]*胆汁[^+;;,,、]*肝[^+;;,,、]*”、“[^+;;,,、]*(甲|乙|丙|丁|戊)[^+;;,,、]*(病毒性)?肝[^+;;,,、]*”、“非酒精性脂肪肝”等,其中[^+;;,,、]*的目的是将多个诊断名称进行分割,多次匹配后得到肝病病因诊断语句。
步骤S32、将分析出的肝病病因进行合并并保存至所述临床诊断数据中。具体地,将结构化处理得到的多个病因描述通过Oracle字符串拼接,使用“+”作为分隔符将肝病病因诊断合并,得到“肝病病因”字段中。
步骤S4、对检验数据进行预处理并筛选出血清总胆红素、血肌酐、国际标准化比值检验数据。如图4所示,是本发明对检验数据进行预处理并筛选出血清总胆红素、血肌酐、国际标准化比值检验数据步骤流程图,包括一下步骤:
步骤S41、对所述检验数据中的错误数据进行清理。例如,对检验数据中的逻辑错误数据处理,包括清除关键信息缺失的记录,关键信息包括送检日期、检验名称、检验报告日期、检验结果、检验参考范围、检验单位。又如,根据检验报告格式规则,删除各字段中逻辑错误的记录。
步骤S42、根据检验类型从所述检验数据中筛选出血清总胆红素、血肌酐以及国际标准化比值的检验数据。根据检验报告的项目类型,检索出生化报告与凝血报告,根据这两类报告中的检验名称,检索出检验名称包括血清总胆红素、血肌酐、国际标准化比值(INR)的检验数据。
步骤S43、根据检验日期对所述血清总胆红素、血肌酐以及国际标准化比值的检验数据进一步筛选。为保证数据的有效性,通常根据检验时间进行进一步处理,包括,时间范围处理,根据MELD评分的检验数据有效期要求,筛选检查日期在30天内的检验报告。另外,若30天内有多次检验报告,则进一步进行检验日期筛选,即将各类型的检验报告,按检验日期进行倒序排序,分别选择最近的一次检验报告,形成检验数据视图,视图内容包括“就诊编号”“检验项目类型”“检验名称”“检验结果”“检验日期”“检验单位”“参考范围”,“检验结果”等。
步骤S5、将所述患者索引编号信息、所述临床诊断数据以及所述检验数据进行汇总得到汇总数据;将患者索引编号信息与结构化的诊断数据表以及预处理筛选之后的检验数据进行SQL多表关联查询,将肝病病因数据、血清胆红素、血肌酐、INR进行汇总,得到MELD评分汇总数据视图。通过汇总数据,只要根据患者的唯一主索引EMPI,就可以查询到该患者的肝病病因数据、血清胆红素、血肌酐以及INR数据。
步骤S6、根据MELD评分规则对所述汇总数据进行分析得到每个患者的MELD评分结果。
由于MELD评分计算公式为:MELD评分=3.8×ln[胆红素(mg/dL)]+11.2×ln(INR)+9.6×ln[肌酐(mg/dL)]+6.4×(病因:胆汁性或酒精性为0,其他为1)。在MELD评分体系中中病因的定义为:0:肝病病因为胆汁性或酒精性;1:肝病病因为非酒精性且非胆汁性;若同时存在多个肝病病因,非酒精性或非胆汁性的权重更高。病因的优先级为1>0;NULL:若诊断中未包含肝病病因,则判断MELD评分结果为“非肝病无法评分”。血清胆红素和血肌酐的单位为mg/dL,若不符合需要进行转换。INR为比值,通常不用转换。因此,需要根据汇总数据获取同一患者的肝病病因数据、血清胆红素、血肌酐以及INR数据,并符合公式中的取值以及单位要求条件。在具体计算的时候,只有MELD评分计算公式中的4个参数均有值,才能够计算MELD评分,若任意一个参数为空,则不能计算MELD评分,通常返回结果为该参数为空的提示信息,用户可以通过web界面输入参数或等待相关诊断、检验数据更新。
如图5所示,是本发明根据MELD评分规则对所述汇总数据进行分析得到每个患者的MELD评分结果步骤流程图,包括以下步骤:
步骤S61、若所述汇总数据中不包含该患者的肝病病因,则设置病因系数为空;若所述汇总数据中包含该患者的肝病病因,则进一步判断该患者的肝病病因若为胆汁性或酒精性,则将病因系数设置为0,否则将病因系数设置为1。具体地,胆汁性或酒精性肝病病因的判断规则如下:根据“肝病病因”字段,逐个诊断名称进行判断,若“肝病病因”字段包含“胆汁”时,病因为胆汁性。若“肝病病因”字段不包含“非酒精”且包含“酒精”时,病因为酒精性。若以上条件都不满足,则判断为其他病因。
步骤S62、若所述汇总数据中存在该患者的血清总胆红素检测数据,则将血清总胆红素检测结果转换为所需单位的对应值。判断胆红素的单位是否为mg/dl,若单位为不同时根据原单位换算为mg/dl。
步骤S63、若所述汇总数据中存在该患者的血肌酐检测数据,则将血肌酐检测结果转换为所需单位的对应值。判断肌酐的单位是否为mg/dl,若单位为不同时根据原单位换算为mg/dl。
步骤S64、根据所述病因系数、所血清总胆红素检测结果、所述血肌酐检测结果以及所述国际标准化比值,通过MELD计算公式计算得到MELD评分结果。
在一具体的实施例中,病患的EMPI匹配到入院诊断为:乙型肝炎肝硬化代偿期活动期+胆汁淤积性肝炎+低(白)蛋白血症+非酒精性脂肪性肝病(NAFLD)+慢性胆囊炎+肝囊肿。利用Oracle的正则化表达式regexp_substr,通过正则表达式“[^+;;,,、]*(酒精性)?肝(炎|硬化|损伤)[^+;;,,、]*”、“[^+;;,,、]*胆汁[^+;;,,、]*肝[^+;;,,、]*”、“[^+;;,,、]*(甲|乙|丙|丁|戊)[^+;;,,、]*(病毒性)?肝[^+;;,,、]*”、“非酒精性脂肪肝”。通过“+”将诊断内容进行拼接,得到“肝病病因”为“乙型肝炎肝硬化代偿期活动期+胆汁淤积性肝炎+非酒精性脂肪性肝”,则病因系数判定为1。该病人的EMPI匹配到的检验报告为“检验结果”=54.4,“检验单位”=μmol/L,“参考范围”=0~26。胆红素的单位不为mg/dl,将“血清总胆红素_检验结果”/17.1得到检验值(mg/dL)≈3.18。该病人的EMPI匹配到的检验报告为“检验结果”=82,“检验单位”=μmol/L,“参考范围”=57~111。胆红素的单位不为mg/dl,将“检验结果”/88.4得到检验值(mg/dL)≈0.93。该病人的EMPI匹配到的检验报告为“检验结果”=1.16,“检验单位”=NULL,“参考范围”=0.72~1.20;该值无需换算。则计算MELD评分为:3.8×ln(3.18)+11.2×ln(1.16)+9.6×ln(0.93)+6.4×(1)=11.76,结果取整数,故最终MELD评分为11分。
在一具体的实施例中,本申请的自动化MELD评分方法,包括以下步骤:将所述MELD评分结果展示在终端界面上,为医生或患者提供直观的展示结果。
为验证本申请方法的效率及准确性,随机抽取肝病病例30例,由自动化MELD评分系统进行自动评分、由1位肝胆外科住院医师及1位肝病内科住院医师对测试病例进行人工评分,记录三者之间的用时及准确率,以多学科(multiple disciplineteam,MDT)讨论作为金标准,比较三者间差异,以观察模型的准确性和实用性。使用SPSS 25.0软件进行统计学处理,计量资料以均值±标准差表示,组间比较采用独立样本t检验。检验水准(α)为0.05,P<0.05表示存在统计学差异。统计结果显示,自动化MELD评分系统每例病例用时24.9±1.99秒、准确率为100%,肝胆外科医师每例病例用时70.13±9.08秒、准确率为100%,肝病内科医师每例病例用时68.17±7.76秒、准确率为100%。自动化MELD评分系统用时较肝胆外科医师及肝病内科医师均少且均有统计学差异(P<0.001),肝胆外科医师及肝病内科医师用时无统计学差异(P=0.371),三者准确率均为100%,无统计学差异,说明肝病自动化MELD评分系统高效、准确,值得向临床推广。
综上所述,本发明提供的肝病MELD评分方法及其系统,不仅能够实现多源异构数据库的数据同步,构建出肝病大数据平台,为针对肝病的临床和科研都具有非常高的使用价值;而且,能够实现高效自动化MELD评分,规避人工录入数据的错误概率,保证分期结果的准确性;同时,也能够显著提高分期结果的获取效率,帮助缩短结果获取时间;另外,本发明还提供可视化展示效果,更有助于结果分析,优化用户体验。
实施例二
本实施例还提供一种自动化MELD评分终端,如可以执行程序的智能手机、平板电脑、笔记本电脑、台式计算机、机架式服务器、刀片式服务器、塔式服务器或机柜式服务器(包括独立的服务器,或者多个服务器所组成的服务器集群)等。如图6所示,是本发明自动化MELD评分终端的结构图,本实施例的终端至少包括但不限于:可通过系统总线相互通信连接的存储器、处理器。在一些实施例中,存储器可以是自动化MELD评分终端的内部存储单元,例如该自动化MELD评分终端的硬盘或内存,也可以是自动化MELD评分终端的外部存储设备,例如该自动化MELD评分终端上配备的插接式硬盘,智能存储卡等。处理器在可以是中央处理器(Central Processing Unit,CPU)、控制器、微控制器、微处理器、或其他数据处理芯片,用于控制自动化MELD评分终端的总体操作。具体的,在本实施例中,处理器用于运行存储在所述存储器上计算机程序,所述处理器执行所述计算机程序时实现上述任一项自动化MELD评分方法的步骤。
实施例三
本申请的技术方案还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有一个或者多个程序,所述一个或者多个程序可被一个或者多个处理器执行,以实现上述任一项自动化MELD评分方法的步骤。
上述具体实施方式只是对本发明的技术方案进行详细解释,本发明并不只仅仅局限于上述实施例,凡是依据本发明原理的任何改进或替换,均应在本发明的保护范围之内。
- 自动化MELD评分方法、终端及存储介质
- 充电健康指数评分方法、装置、终端设备及存储介质