一种基于多任务学习的无设备人员动作识别和位置估计方法
文献发布时间:2023-06-19 13:46:35
技术领域
本发明涉及一种基于多任务学习的无设备人员动作识别和位置估计方法,可用于定位导航技术领域。
背景技术
在目标状态估计方面,主要是对目标的动作和姿态变化进行识别,如今有多种方式可以检测和感知这些变化,比如无线信号,可穿戴的智能设备,图像信号和视频信号。其中,需要穿戴设备的方法大多要用到内置无线传感器的集成设备,这些设备虽然价格比较低廉,但是在一些场合下不方便佩戴。而依靠图像和视频的方法存在拍摄死角,拍摄图像和视频也容易受到光线问题的困扰,影响最终判断的准确性,除此之外,图像和视频的方式也容易造成个人隐私的泄露。
随着无线通信技术的不断发展,移动设备的迅速普及,利用无线信号的信道状态信息对人员位置和人体动作进行识别逐渐引起学术界和工业界的广泛关注。由于室内空间环境复杂,信号在传播过程中容易出现多径效应、衰落和延迟失真的情况,在接收端收到的信号会反应环境的特征。接收信号强度是一种粗粒度的信号,与多条路径信号幅度的叠加融合有关。而信道状态信息(CSI)工作在物理层,能够刻画出各个子载波的幅值和相位信息,而非只能表示全部子载波幅度的叠加值,所以CSI数据细粒度更高,而且也更加丰富。
近年来,基于CSI的无线感知方面的大量研究成果发表在了各大期刊和会议上,文献1中,SVM技术被用于基于动作的分类学习和基于每个动作的位置回归学习。文献2利用CSI测量的幅度和相位信息,提出了一种基于分类学习的活动识别和定位算法。作者首先从多个通道构造了基于CSI的无线电图像,然后利用图像特征提取算法和深度学习网络提取图像特征用于离线分类学习。[1.K.Wu,M.Yang,C.Ma,J.Yan,“CSI-based wirelesslocalization and activity recognition using support vector machine,”International Conference on Signal Processing,Communications and Computing(ICSPCC),Dalian,China,September,2019,pp.1-5.][2.Q.Gao,J.Wang,X.Ma,X.Feng andH.Wang,“CSI-based device-free wireless localization and activity recognitionusing radio image features,”IEEE Trans.Veh.Technol.,vol.66,no.11,pp.10346-10356,2017.]
尽管从公开文献中可以看到最近的一些进展,但是基于CSI的状态识别和定位技术作为种新兴技术仍面临许多挑战,其本质问题是如何使用机器学习技术来实现状态识别和定位。
文献1中首先对动作进行识别,然后再进行位置估计。在这种感知系统模式下,动作识别的性能对位置估计有很大的影响。文献2中将动作和位置组合成目标状态标签,采用的是联合估计。并且位置估计问题转化成分类学习,当目标位于参考点之间时,会导致定位错误增加。因此探索一种可以同步进行活动识别和回归定位的基于机器学习的系统框架具有重要的应用价值。
发明内容
本发明的目的就是为了解决现有技术中存在的上述问题,提出一种基于多任务学习的无设备人员动作识别和位置估计方法。
本发明的目的将通过以下技术方案得以实现:一种基于多任务学习的无设备人员动作识别和位置估计方法,该方法包括离线阶段和在现阶段,在离线阶段,对每张CSI图像加上动作,X轴和Y轴等三个标签后形成训练集,再将训练集送入到多任务网络中进行学习训练并保存模型;在线阶段,将获得的CSI图像送入训练好的多任务网络模型中,进行动作识别和位置估计
优选地,所述离线阶段包括以下步骤:
S11:训练数据采集
在不同参考位置点上,人员做出不同的动作,在接收端接收WiFi信号的信道状态信息、CSI;
S12:训练数据库构建
根据CSI测量值的幅度信息,利用CSI的时域,空域和频域信息构建CSI图像,作为训练样本的指纹;
利用所对应的参考点坐标值和所对应的动作作为训练样本标签,构建CSI图像,动作标签,参考点坐标的位置估计训练数据库;
S13:训练数据离线训练
利用多任务卷积神经网络进行基于动作和位置的学习,得到能同时进行动作分类和位置回归的多任务网络模型。
优选地,所述在线阶段包括以下步骤:
S21:CSI图像构建
将接收到的CSI测量值,按照S12所描述的方法,构建基于CSI幅度的图像;
S22:目标动作识别和位置估计
将S21步骤得到的CSI图像作为输入,带入到S13步骤得到的多任务网络模型中,估计出目标动作和位置。
优选地,在所述S13步骤中,
基于目标动作和位置的多任务学习包含如下步骤:
S131:建立多任务学习模型
构建CSI图像,动作类别,X轴坐标,Y轴坐标训练数据集,形成动作识别,X轴坐标估计和Y轴坐标估计3个不同的学习任务;将动作识别问题转化为分类学习,X轴坐标估计和Y轴坐标估计问题转化为回归学习;
S132:设计基于硬共享机制的多任务学习网络
多任务深度神经网络中所有的任务共用一个主干网络,对于不同任务之间的差异性则构造对应的分支网络对各个任务的结果进行输出;
S133:设计多任务学习的损失函数
对于每个任务,动作分类任务选用交叉熵损失作为损失函数X轴坐标估计任务和Y轴估计任务选用均方差误差MSE作为损失函数。
优选地,在所述S13步骤中,多任务卷积神经网络包括主干网络和分支网络,主干网络部分由三层卷积层组成,在这三个卷积层中,网络参数是所有任务共享的,在网络进行训练调整的过程中,主干网络的学习参数受到所有任务的影响,从而进行参数调整;对于分支网络部分三个网络分支,所有的网络分支均由一层卷积层,两层全连接层以及输出层组成。
本发明采用以上 技术方案与现有技术相比,具有以下技术效果:该技术方案主要利用WiFi信号的信道状态信息(CSI),通过深度学习算法,实现在无设备条件下,目标的动作识别和位置估计。
本发明利用WIFI信号的信道状态信息联合估计目标的动作和位置,能够充分利用现有设备,从而提高方法的实用性和便捷性。
本发明利用硬参数共享机制的多任务深度神经网络,在主干网络只研究网络参数的相关关系,侧重各个任务之间的相互关系和作用,而忽略了其特异性。而在分支网络中,结构相互独立,保留各个任务的特异性。
本发明将动作识别和位置估计分别转化为分类学习和回归学习,通过线性相加的方法构建损失函数,从而完成多任务离线学习。该发明与现有方法相比,动作和位置估计彼此独立,能够提高估计性能。
附图说明
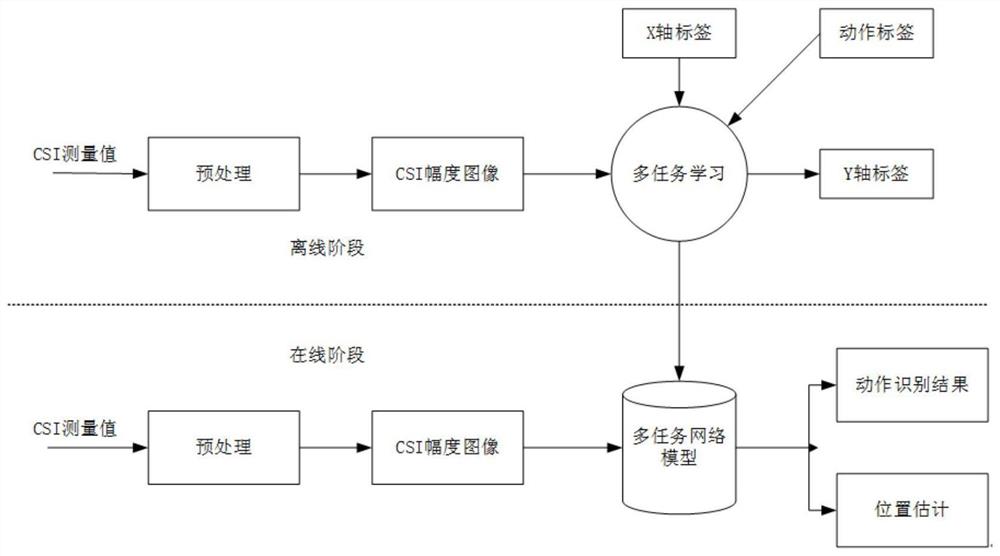
图1为本发明的一种基于多任务学习的无设备人员动作识别和位置估计方法的具体框图。
图2为本发明中参数硬连接网络示意图。
图3为本发明在离线学习中采用的多任务卷积神经网络结构。
图4为本发明的状态分类的性能图。
图5为本发明的位置回归的性能图。
具体实施方式
本发明的目的、优点和特点,将通过下面优选实施例的非限制性说明进行图示和解释。这些实施例仅是应用本发明技术方案的典型范例,凡采取等同替换或者等效变换而形成的技术方案,均落在本发明要求保护的范围之内。
本发明揭示了一种基于多任务学习的无设备人员动作识别和位置估计方法,针对现有技术存在的缺陷,提出了一种基于多任务学习的无设备人员动作识别和位置估计方法,该方法不仅定位精度和动作识别率高,而且结构简单,实现成本低。
一种基于多任务学习的无设备人员动作识别和位置估计方法,该方法包括离线阶段和在现阶段,在离线阶段,对每张CSI图像加上动作,X轴和Y轴等三个标签后形成训练集,再将训练集送入到多任务网络中进行学习训练并保存模型;在线阶段,将获得的CSI图像送入训练好的多任务网络模型中,进行动作识别和位置估计
所述离线阶段包括以下步骤:
S11:训练数据采集
在不同参考位置点上,人员做出不同的动作,在接收端接收WiFi信号的信道状态信息CSI;
S12:训练数据库构建
根据CSI测量值的幅度信息,利用CSI的时域,空域和频域信息构建CSI图像,作为训练样本的指纹;
利用所对应的参考点坐标值和所对应的动作作为训练样本标签,构建CSI图像,动作标签,参考点坐标的位置估计训练数据库;
S13:训练数据离线训练
利用多任务卷积神经网络进行基于动作和位置的学习,得到能同时进行动作分类和位置回归的多任务网络模型。
所述在线阶段包括以下步骤:
S21:CSI图像构建
将接收到的CSI测量值,按照S12所描述的方法,构建基于CSI幅度的图像;
S22:目标动作识别和位置估计
将S21步骤得到的CSI图像作为输入,带入到S13步骤得到的多任务网络模型中,估计出目标动作和位置。
在所述S13步骤中,
基于目标动作和位置的多任务学习包含如下步骤:
S131:建立多任务学习模型
构建CSI图像,动作类别,X轴坐标,Y轴坐标训练数据集,形成动作识别,X轴坐标估计和Y轴坐标估计3个不同的学习任务;将动作识别问题转化为分类学习,X轴坐标估计和Y轴坐标估计问题转化为回归学习;
S132:设计基于硬共享机制的多任务学习网络
多任务深度神经网络中所有的任务共用一个主干网络,对于不同任务之间的差异性则构造对应的分支网络对各个任务的结果进行输出;
S133:设计多任务学习的损失函数
对于每个任务,动作分类任务选用交叉熵损失作为损失函数X轴坐标估计任务和Y轴估计任务选用均方差误差MSE作为损失函数。
在所述S13步骤中,多任务卷积神经网络包括主干网络和分支网络,主干网络部分由三层卷积层组成,在这三个卷积层中,网络参数是所有任务共享的,在网络进行训练调整的过程中,主干网络的学习参数受到所有任务的影响,从而进行参数调整。对于分支网络部分三个网络分支,所有的网络分支均由一层卷积层,两层全连接层以及输出层组成。
本发明的实验场景模式图如图1所示,在定位区域的每个参考点上,分别进行不同的动作,然后记录在接收机测量的CSI值,接着利用CSI幅度的时域,空域和频域信息构建CSI图像。
本发明的具体框架如图1所示,在离线阶段,对每张CSI图像加上动作,X轴和Y轴等三个标签后形成训练集,再将训练集送入到多任务网络中进行学习训练并保存模型。在线阶段,将获得的CSI图像送入训练好的多任务网络模型中,进行动作识别和位置估计。
下面将具体说明本发明的实施方案。从多任务神经网络的网络结构上来看,本发明采用硬共享机制。如图2所示,在参数硬共享机制的多任务深度神经网络,参数共享只发生在共用的一些隐藏层,即主干网络。多个任务通过不同训练数据之间的相互作用最终得到一个通用的、能够学习到所有任务信息统一表示的主干网络模型,只在分支网络,为每个任务设计不同的输出层,输出每个任务的结果。
本技术方案的网络结构如图3所示,多任务卷积神经网络由两个主要的部分组成:主干网络和分支网络。对于主干网络部分,其由三层卷积层组成。在第一层卷积层中,有8个卷积核,后两层卷积层的卷积核个数均为12。在这三个卷积层中,其网络参数是所有任务共享的。在网络进行训练调整的过程中,主干网络的学习参数受到所有任务的影响,从而进行参数调整。
对于分支网络部分,由于需要利用多任务卷积神经网络同时对动作分类、X轴位置回归和Y轴位置回归进行训练和结果输出,所以有三个网络分支。所有的网络分支均由一层卷积层,两层全连接层以及输出层组成。其中所有任务分支网络的卷积层的卷积核个数均为8个,第一层全连接层均由卷积层进行维度转化而来,而卷积层特征图像尺寸为48×48×12,所以第一层全连接层神经元个数均为27648个。第二层全连接层均由256个神经元构成,最后根据不同的任务设计不同的输出层。除此之外,整个多任务卷积神经网络中,卷积层的卷积核大小均为3×3,卷积核的深度与输入图像的深度相同,卷积层和全连接层的激活函数均为ReLu函数。
在基于深度神经网络的多任务学习中,由于用于输出各任务结果的分支网络结构是相互独立的,所以设计损失函数时分为两个部分:(1)针对每个任务设计各自适合的损失函数;(2)设计整个多任务网络学习的损失函数。
在分类问题中,损失函数有交叉熵损失、0-1损失以及指数损失等。在神经网络中,交叉熵损失往往和softmax函数一起使用,损失函数在向最后一层权重传递梯度时,只跟输出值和真实值的差值成正比,而不再与激活函数的导数相关。又因为反向传播是以连乘的方式进行的,所以整个网络的权重矩阵更新都会加快。
在所有的损失函数中,0-1损失是原理最简单的一种。对于二分类问题,预测结果
其中
指数损失与交叉熵损失类似,但由于它是指数下降的,因此指数损失函数梯度较其它损失函数来说要更大一些,其可表示为
L(y,f(x))=e
其中y为真实值,f(x)为预测值。
由于AdaBoost算法能由指数损失通过加法模型推导出来,所以指数函数一般作为AdaBoost中的损失函数。此外,由于指数损失本身对异常点敏感,所以鲁棒性较差。
而对于回归问题,均方差误差(MSE)和平均绝对误差(MAE)是回归问题中最常用的损失函数。MSE损失也被称为L2损失,其表达式为
而MAE损失可以表示为
其中y
在该技术方案中,动作分类任务选用交叉熵损失作为损失函数,MSE作为X轴回归任务和Y轴回归任务的损失函数。
本发明只有一个训练数据集,训练数据集里的每张图像都有三个标签:动作标签、X轴位置标签、Y轴位置标签。因此整个多任务网络的损失函数为各任务损失函数线性相加。假设动作分类、X轴回归和Y轴回归同样重要,所以损失函数为
Loss=loss
其中loss
图4描述了本章算法在不同训练样本数目时,在动作识别方面的性能。可以看出,训练样本越多,动作识别准确率呈现出缓慢上升的趋势。当训练样本仅为4750张图片时,准确率可以达到97.28%,而在训练样本数目达到23750时,准确率为99.60%。
图5描绘了本章算法在不同样本数目时,位置估计错误的累积概率分布。当训练样本数目为4750时,67%和95%处的位置估计错误分别为65.85厘米和164.05厘米。当训练样本数目为19000时,67%和95%处的位置估计错误分别为35.52厘米和83.99厘米。
本发明利用WIFI信号的信道状态信息联合估计目标的动作和位置,能够充分利用现有设备,从而提高方法的实用性和便捷性。
本发明利用硬参数共享机制的多任务深度神经网络,在主干网络只研究网络参数的相关关系,侧重各个任务之间的相互关系和作用,而忽略了其特异性。而在分支网络中,结构相互独立,保留各个任务的特异性。
本发明将动作识别和位置估计分别转化为分类学习和回归学习,通过线性相加的方法构建损失函数,从而完成多任务离线学习。该发明与现有方法相比,动作和位置估计彼此独立,能够提高估计性能。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而目在不背离本发明的精神和基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内,不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。本发明尚有多种实施方式,凡采用等同变换或者等效变换而形成的所有技术方案,均落在本发明的保护范围之内。
- 一种基于多任务学习的无设备人员动作识别和位置估计方法
- 一种基于信道状态信息的人员动作识别和位置估计方法