基于云边协同的联邦学习的业务类型识别方法
文献发布时间:2023-06-19 13:48:08
技术领域
本发明属于通信技术领域,涉及一种业务类型识别方法,具体涉及一种基于云边协同的联邦学习的业务类型识别方法,可用于云端服务器与边缘服务器协同工作时,对流经边缘服务器中的业务数据流类型进行识别。
背景技术
随着5G带来大带宽、低时延、广连接三大特点,海量的数据业务(网络直播业务、游戏业务,视频业务等)涌现在移动网络和互联网中。为了识别出网络中流经数据流的业务类型,便出现了业务类型识别技术。服务器通过业务类型识别方法识别用户请求数据业务的类型(网络直播、游戏,视频等),进而为该业务分配相应的计算资源、网络资源以更好的保证用户的服务质量,进而提高用户的满意度。早期基于端口进行业务识别是最快捷、最简单的方式,但随着业务的增多,不同业务占用相同端口越来越多,导致采用基于端口进行业务类型识别的准确率下降甚至失效。基于深度包检测的业务类型识别方法通过提取数据流大量关于业务特征的信息,并与特征库进行匹配实现对业务类型识别,虽然避免了采用端口进行业务识别,获得很好的识别精度,但需要人工手动进行特征库的提取与设计,且难度较大,同时随着网络应用的发展,数据流业务的特征库也随之变换,因此业务类型识别精度也会随着特征库的变化而降低。
基于机器学习的业务识别方法克服了需要人工手动进行特征库的提取与设计的缺陷,例如,申请公布号为CN 111917665 A,名称为“一种终端应用数据流识别方法及系统”的专利申请,公开了一种机器学习的终端应用数据流识别方法,该方法首先对实时采集的待识别终端应用数据流进行预处理,得到按照五元组信息进行分类后的多个类别的数据包集合;再对所得各类别的数据包集合,提取其第一数据特征,分别与多个预设应用业务的特征进行匹配,若能够与任意一种预设应用行为的特征匹配成功,则该类别的数据包集合中的所有数据包的所属应用业务均为该预设应用业务,操作结束;否则,对所得各类别的数据包集合,提取其第二数据特征,并输入到预训练好的数据流识别模型中,对数据流进行识别。该方法避免了人工手动进行特征库的提取与设计,大大提高数据流识别的准确率。但其终端应用数据流的数据集较少,训练得到的模型不具备很好的泛化能力,导致业务类型识别适用范围较小。
随着边缘计算概念的提出,更多的服务提供商将其提供服务的服务器放置在更靠近用户的边缘端,并与具有强大计算能力的云端服务器进行云边协同为用户提供服务。云边协同指的是在边缘服务器资源不足的情况下,可以调用云端服务器的资源进行补充,并满足边缘侧应用对资源的需要。联邦学习作为分布式的机器学习范式,可以有效解决数据孤岛问题,让参与方在不共享数据的基础上联合建模,能从技术上打破数据孤岛,实现人工智能协同。通过云边协同和联邦学习方法提供了一种通过扩大数据流的数据集范围,实现扩大业务类型识别范围的可能。
发明内容
本发明的目的在于克服上述现有技术存在的缺陷,提出了一种基于云边协同的联邦学习的业务类型识别方法,在保证业务类型识别精度和效率的同时,拓宽业务类型识别的适用范围。
为实现上述目的,本发明采取的技术方案包括如下步骤:
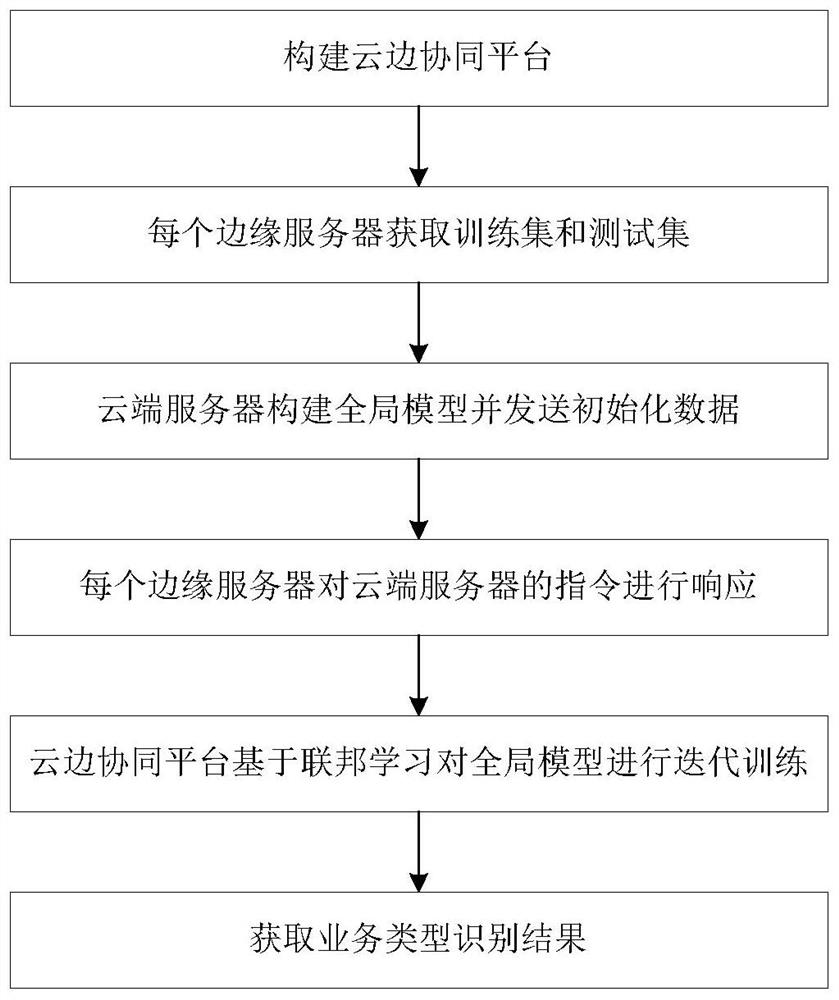
(1)构建云边协同平台:
构建包括云端服务器以及与其通过互联网连接的N个边缘服务器E={e
(2)每个边缘服务器获取训练集和测试集:
(2a)每个边缘服务器e
(2b)每个边缘服务器e
(3)云端服务器构建全局模型并发送初始化数据:
云端服务器构建包括全连接输入层input、多个卷积层、多个池化层、dropout层、全连接输出层output和softmax层的全局模型,并将该全局模型和性能请求指令PerformRequest作为初始化数据发送至每个边缘服务器e
(4)每个边缘服务器对云端服务器的指令进行响应:
每个边缘服务器e
(5)云边协同平台基于联邦学习对全局模型进行迭代训练:
(5a)云端服务器按照计算资源的剩余量从大到小的顺序对N个边缘服务器进行排序,得到排序后的包括N个边缘服务器的集合E
(5b)云端服务器按照先行后列的顺序依次从边缘服务器数据表T中选取边缘服务器,共选取R次,每次选取M个边缘服务器,R≥1000,2≤M≤N,得到包括R组边缘服务器的边缘服务器组集合S={s
(5c)云端服务器通过WebSocket协议向每个边缘服务器
(5d)每个边缘服务器
(5e)云端服务器采用联邦平均算法对边缘服务器组集合S发送的R×M个全局模型进行聚合,得到聚合后的全局模型,并通过WebSocket协议将该聚合后的全局模型发送至每个边缘服务器e
(6)获取业务类型识别结果:
每个边缘服务器e
本发明与现有技术相比,具有如下优点:
本发明所构建的云边协同平台中包括多个边缘服务器,每个边缘服务器抓取终端请求流经自己的多条包括不同业务类型的数据流,并基于联邦学习通过对多条数据流进行采样得到多个数据流块合成的灰度图片及其标签作为训练集,对全局模型进行迭代训练,扩大了数据流的数据集范围,进而可以获得泛化能力更强的全局模型,训练好的全局模型能够扩大业务类型识别的适用范围。
附图说明
图1为本发明的实现流程图。
具体实施方式
以下结合附图和具体实施例,对本发明作进一步详细描述。
步骤1)构建云边协同平台:
构建包括云端服务器以及与其通过互联网连接的N个边缘服务器E={e
本发明所构建的云边协同平台中包含N个边缘服务器,能够避免单个服务器导致的终端应用数据流的数据集较少的缺陷,有助于提高全局模型的泛化能力,进而拓宽业务类型识别的适用范围。
云端服务器按照计算资源的剩余量从大到小的顺序对N个边缘服务器进行排序后,构建边缘服务器数据表,避免了单个服务器导致的终端应用数据流的数据集较少的缺陷。
步骤2)每个边缘服务器获取训练集和测试集:
(2a)每个边缘服务器e
(2b)每个边缘服务器e
本实施例K=200000,D=3,G=32,W=32,H=6250。
每个边缘服务器e
每个边缘服务器e
(2b1)每个边缘服务器e
(2b2)每个边缘服务器e
步骤3)云端服务器构建全局模型并发送初始化数据:
云端服务器构建包括全连接输入层input、多个卷积层、多个池化层、dropout层、全连接输出层output和softmax层的全局模型,并将该全局模型和性能请求指令PerformRequest作为初始化数据发送至每个边缘服务器e
本实施例卷积层和池化层的数量均为2个,该全局模型的具体结构为:全连接输入层input→第一卷积层→第一池化层→第二卷积层→第二池化层→dropout层→全连接输出层output→softmax层,其中,全连接输入层input具有的神经元个数为1024个,两个卷积层中采用的激活函数均为ReLU函数,全连接输出层output具有的神经元个数为3;第一卷积层、第二卷积层的卷积核大小分别为3*3*64、3*64*32,该两个卷积层的全零填充步长均为1,第一池化层、第二池化层的过滤器大小均为2*2,全零填充步长均为1。
步骤4)每个边缘服务器对云端服务器的指令进行响应:
每个边缘服务器e
每个边缘服务器e
步骤5)云边协同平台基于联邦学习对全局模型进行迭代训练:
(5a)云端服务器按照计算资源的剩余量从大到小的顺序对N个边缘服务器进行排序,得到排序后的包括N个边缘服务器的集合E
(5b)云端服务器按照先行后列的顺序依次从边缘服务器数据表T中选取边缘服务器,共选取R次,每次选取M个边缘服务器,R≥1000,2≤M≤N,得到包括R组边缘服务器的边缘服务器组集合S={s
本实施例中L=4000,R=10000,M=4。
本发明所构建的云边协同平台中包含N个边缘服务器,虽然能够避免单个服务器导致的终端应用数据流的数据集较少的缺陷,但相比于单个边缘服务器又会降低全局模型训练的效率,按照计算资源的剩余量从大到小的顺序对N个边缘服务器进行排序,并构建大小L×N的边缘服务器数据表T,然后从中选取R次,每次选取M个边缘服务器构成边缘服务器组,由于选取的大多数组边缘服务器的计算资源剩余量相差不大,所以大多数组边缘服务器完成全局模型训练的时间偏差较小,避免了每次都从N个边缘服务器随机选择M个边缘服务器,由于每组边缘服务器的计算资源剩余量偏差较大,导致完成全局模型训练的时间偏差较大的问题,能够有效消除N个边缘服务器对全局模型训练效率的影响。
(5c)云端服务器通过WebSocket协议向每个边缘服务器
(5d)每个边缘服务器
边缘服务器
(5e)云端服务器采用联邦平均算法对边缘服务器组集合S发送的R×M个全局模型进行聚合,得到聚合后的全局模型,并通过WebSocket协议将该聚合后的全局模型发送至每个边缘服务器e
步骤6)获取业务类型识别结果:
每个边缘服务器e
- 基于云边协同的联邦学习的业务类型识别方法
- 基于联邦迁移学习的驾驶员行为云边协同学习系统