一种针对多模态数据离散语义编码的装置和方法
文献发布时间:2023-06-19 13:49:36
技术领域
本发明涉及人工智能领域,尤其是涉及针对多模态数据离散语义编码的装置和方法。
背景技术
将多模态数据转换为离散编码在许多行业有着重大意义。首先因为离散变量相较于连续的模拟数据占据更小的空间,因此可以大大的节省数据存储的空间,对于数据湖、物联网和边缘计算领域有着很高的作用,大大节省成本。其次,对于离散编码可以更加高效的被检索,因此对于大规模的信息(图片、文本、视频等)信息检索,离散编码有着巨大的优势。最后,离散编码相较于连续的向量有着更好的可读性,对于促进科研人员理解人工智能系统,进行人工智能决策优化有着重要的作用。
发明内容
本发明主要是提供一种针对多模态数据离散语义编码的方法和装置,对原始数据中的信息点有较好的保留。
本发明针对上述技术问题主要是通过下述技术方案得以解决的:一种针对多模态数据离散语义编码的装置,包括:
数据编码器:对输入数据x编码,输出结果为一个多维张量h;
编码生成器:根据张量h生成M个K维的离散变量z的概率分布q(z|h),离散变量有M个,每个离散变量均为K维;
针对给定张量h,编码生成器是一套神经网络,基于M个K维的离散变量生成概率分布作为编码结果q(z|h);同时针对每一个维度,每个不同的变量,编码器包括离散符号和嵌入向量,嵌入向量的维数为D,嵌入向量为M×D的矩阵;编码器生成的输出包含两部分,第一部分是M个离散符号,另外是M个相对应的嵌入向量e(z),大小为e(z)∈R
一种针对多模态数据离散语义编码的方法,基于前述的编码装置,包括以下步骤:
S1、通过数据编码器对输入数据进行编码,输出结果为多维张量h;
S2、将h中代表现实意义的维度作为主要坐标输入Transfomer模型,然后经过若干层(一般为12层)Transfomer计算后,用Transfomer模型的前M个输出作为q(z|h)。
作为优选,步骤S1中,对于文本数据采用LSTM进行编码,对于图片文件采用CNN模型进行编码。
作为优选,步骤S2中,h中代表现实意义的维度包括文字中的时间轴和图片中的方位信息。
作为优选,一种针对多模态数据离散语义编码的方法还包括对模型的训练方法,训练方法采用的损失函数为:
式中,q(z)按以下方式进行仿真:
式中,L
训练时,得到编码结果以后通过解码器重建原始数据。
本发明带来的实质性效果是,通过构建神经网络模型,对于数据进行编码和解码的工作,并且通过我们提出的新颖损失函数实现数据编码z的离散化,保证z包含丰富的信息,最大程度的保留原始数据中的信息点。
附图说明
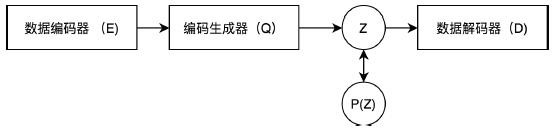
图1是本发明的一种数据编码神经网络模型架构示意图。
具体实施方式
下面通过实施例,并结合附图,对本发明的技术方案作进一步具体的说明。
实施例:本发明提出了一种针对文本,图片等多模态信息的离散数据编码方法。此方法通过构建神经网络模型,对于数据进行编码和解码的工作,并且通过我们提出的新颖损失函数实现数据编码z的离散化,保证z包含丰富的信息,最大程度的保留原始数据中的信息点。
我们提出的模型包含三大模块:
1.数据编码器:随着深度学习的发展,文本、图片等数据都有着非常成熟的编码神经网络模块。假设输入数据为x,我们采用LSTM对于文本数据进行编码,采用CNN模型对于图片进行编码,输出结果为一个多维张量h;
2.编码生成器:给定张量h,编码生成器是一套神经网络产生M个K维的离散变量的概率分布q(z|h)。同时针对每一个维度,每个不同的变量(一共K×M个),编码器配有他们的符号嵌入向量,向量的维数我们设为D;编码器生成的输出包含两部分,第一步是M个离散符号z,另外是M个相对应的嵌入向量e(z),大小为e(z)∈R
3.解码器:解码器是另一套生成式神经网络用来通过离散编码来重建原始数据。同样的,解码器有很多成熟的架构可以选择,例如Transfomer或者FFHQ等模型。
我们通过SGD来训练上述模型。具体来说,训练分为两部分:
训练数据的采集:本发明提出的方法无需对于数据进行人工标注,只需要大量的数据本身,例如大量的文档,或者大量的图库。
损失函数:为ELBO损失+最大互信息损失
其中q(z)在过去很难被模拟,我们创新的提出下属模拟方法,来对于q(z)进行仿真。
此外,当某些情况下,业务专家对于数据的编码有着先验的知识时,我们可以手工对于p(z)进行设定,并且融入到模型训练当中。
最后,当那个我们获得上述模型之后,我们只需要通过数据编码器和编码生成,可以对于任意数据,我们都可以用他们对于数据进行编码,获得M个离散编码。这些编码被用作数据的压缩存储,或者用作检索的索引等。等数据需要被重现构建时,我们可以利用解码器对于原数据进行重建。
本方案的主要创新点在于:
1.利用Transformer作为编码生成器,效果大大超过传统基于MLP的编码生成器。
2.创新的损失函数,利用ELBO配合最大互信息来对于模型进行训练。
3.创新的互信息模拟方法。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
尽管本文较多地使用了网络升级模型、编码、向量等术语,但并不排除使用其它术语的可能性。使用这些术语仅仅是为了更方便地描述和解释本发明的本质;把它们解释成任何一种附加的限制都是与本发明精神相违背的。
- 一种针对多模态数据离散语义编码的装置和方法
- 一种针对临床疾病的多模态大数据的数据分析方法