一种基于神经变形的可变形场景中人体运动捕捉方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及一种基于神经变形的可变形场景中人体运动捕捉方法,属于计算机视觉和计算机图形学领域。
背景技术
人体运动捕捉在角色动画、人机交互和人类行为理解等方面有着广泛应用。传统的运动捕捉通过光学动捕系统或惯性动捕系统来采集动作人的运动信息。然而,无论是光学动捕还是惯性动捕都需要动作人穿上特定设备,这影响了动捕的使用范围和人体运动的真实性,并且这些设备通常价格昂贵。近年来,随着深度学习的发展和大型数据集的创建,无标记运动捕捉技术研究取得了显著进展。现有大量工作可以从单视角视频和图像中进行三维人体运动捕捉。然而,从单目彩色图像中进行三维人体重建存在尺度模糊问题,现有方法并不能很好的解决。此外,这些方法大多认为背景是静态的,忽略了由人类场景交互引起的潜在场景变化。虽然它们使用人体环境接触和渗透约束来避免碰撞,但忽略场景变形,容易导致大量的三维重建错误。
场景约束可以为全局三维人体运动捕捉提供线索,高质量的场景变形可以指导提高全局三维人体姿态估计精度。现有可变形物体的网格变形方法能够从预定义的稀疏控制顶点指导下变形网格。然而,这个问题通常是严重不适定和欠约束,特别是对于大的表面,因为有许多可能的变形可以与稀疏控制点的部分表面变形相匹配。因此,强先验编码的变形规律性是解决这一问题的必要条件。优化方法使用各种解析先验来定义自然的网格变形,如弹性,拉普拉斯平滑和刚性先验。但这些方法简单的将局部表面限制为以类似的方式进行变换,难以建模复杂的变形。现有基于神经网络的方法估计位移场来建模变形,但是维度大,难以进行泛化。我们基于Transformer建模相互关系,学习局部几何变形先验,基于变形先验推断一组由位移和旋转组成的欧式变换来变形网格。
因此,采用基于Transformer的神经变形网络建模可变形场景的几何形状,同时利用环境约束来为全局三维人体运动捕捉提供额外的线索,能够有效提高全局三维人体姿态的估计精度。
发明内容
本发明提出一种基于神经变形的可变形场景中人体运动捕捉方法。该方法首先使用三维人体姿态估计器初始化人体运动学模型的三维人体姿态,这产生了相对于根节点的三维姿态。接下来,估计三维人体姿态下的人体网格的接触概率图,获得与场景接触的人体网格顶点,并通过光线投射来找到场景网格上相应的接触点,利用人体网格和场景网格的接触点对优化获得全局三维人体姿态。然后,搭建基于Transformer的神经变形网络,根据当前人体网格和场景网格的交互状态对场景网格执行非刚性变形。最后,迭代交替优化全局人体姿态和执行场景网格非刚性变形,实现高质量的无标记单目三维人体运动捕捉和非刚性三维场景变形。
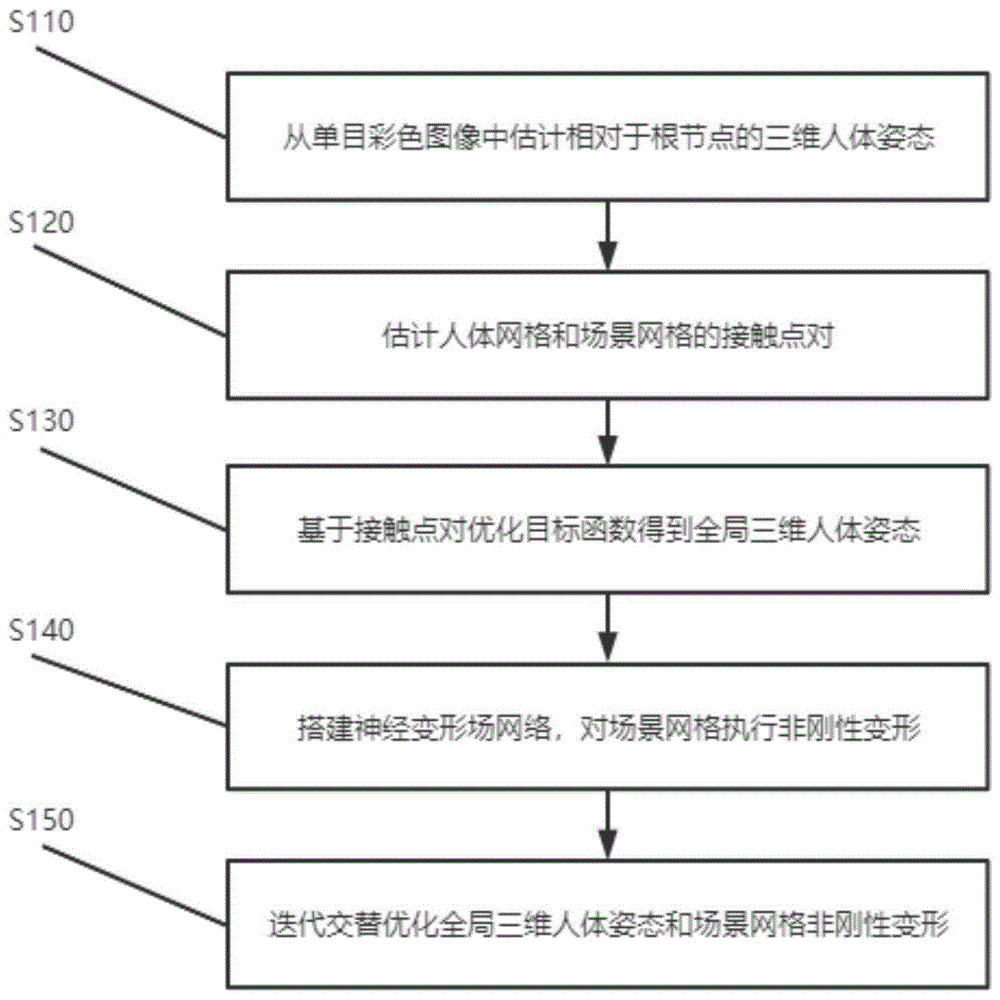
本发明提出的一种基于神经变形的可变形场景中人体运动捕捉方法包含以下步骤:
步骤1,使用三维人体姿态估计器,从单目彩色图像中初始化人体模型的三维人体姿态;
步骤2,估计三维人体姿态下的人体网格的接触概率图,获得与场景接触的接触点,并通过光线投射找到场景网格上相应的接触点,即得到人体网格和场景网格的接触点对;
步骤3,基于步骤2获得的人体网格和场景网格的接触点对,优化目标函数获得全局三维人体姿态;
步骤4,搭建基于Transformer的神经变形网络,根据全局三维人体姿态下的人体网格和场景网格的交互状态对场景网格执行非刚性变形;
步骤5,迭代交替优化全局三维人体姿态和执行场景网格非刚性变形,实现高质量的无标记单目三维人体运动捕捉和非刚性三维场景变形。
进一步,所述步骤1采用基于优化的SMPLify-X初始化人体模型的三维人体姿态,通过最小化目标函数来优化人体模型SMPL-X的三维人体姿势。
进一步,所述目标函数定义如下:
E
该目标函数优化的参数β表示人体形状参数,θ代表可优化姿势参数的完整集合,t表示全局平移,目标函数第一项E
进一步,所述步骤2中,对于当前三维人体姿态下的人体网格,使用一个条件变分自编码器为该三维姿态下的人体生成接触概率图。训练好的解码器以初始化三维人体姿态下的人体网格顶点和隐变量作为采样条件,其中隐变量空间服从于高斯分布。生成的接触概率图进行阈值操作,则可以得到与环境接触的人体网格顶点。
进一步,所述步骤2,使用现有的光线投射查找策略找到场景网格上相应的接触点,将与环境接触的人体网格顶点重新投影到图像空间中,若重新投影的接触点落在未被遮挡的人体部位上,则投射来自相机的光线,以找到与三维场景网格的相交点;若重新投影的接触点落在被遮挡的人体部位上,则将其最近的场景顶点作为相对应的接触顶点。
进一步,所述步骤3,获得人体网格和场景网格的接触点对后,将人体网格上的接触点对齐到相应的场景网格接触点上,并在步骤1的目标函数优化后的结果基础上进一步优化全局目标函数,获得全局三维人体姿态。所述全局目标函数定义如下:
E
该目标函数优化的参数β表示人体形状参数,θ代表可优化姿势参数的完整集合,t表示全局平移。目标函数第一项E
进一步,所述步骤4,根据全局三维人体姿态下的人体网格和场景网格的交互状态定义稀疏控制点。首先使用训练好的三维场景分割网格对场景进行分割,并对分割部分进行语义标签估计。场景分割和语义标签估计完成之后,屏蔽掉刚性场景,只对可变形场景进行后续的非刚性变形。接下来,对当前人体网格和可变形场景进行碰撞检测,若当前人体网格顶点穿透了场景,并且该人体网格顶点是步骤2所估计的接触点,则将其最近的被穿透的物体顶点设置为控制点,该控制点的目标位置是该人体网格顶点的位置。
进一步,所述步骤4,定义稀疏控制点及其目标位置后,搭建基于Transformer的神经变形网络,对场景网格执行非刚性变形。对于可变形场景网格,固定均匀采样N个点,采样点中包含稀疏控制点,若是控制点则将其目标位移设置为到目标位置的位移,若非控制点则将其目标位移设置为零。将采样得到的N个点的位置以及目标位移送到神经变形网络中,输出得到一组由位移和旋转组成的欧式变换,即M个节点的欧式变换。对于可变形场景网格上每个顶点变形后的位置,由其最近m个节点的欧式变换决定。找到最近m个节点,该顶点变形后的位置是应用最近m个节点的欧式变换的位置的加权和,计算公式可以表述如下:
其中,v是场景网格顶点,v'是场景网格顶点v的变形后的位置,R
进一步,所述步骤5,对人体姿态和场景变形进行迭代交替优化。在每一次迭代中,首先根据步骤2获得人体网格和场景网格的接触点对,在步骤3的全局目标优化函数基础上添加惩罚人体与场景穿透项,优化该目标函数来更新全局人体姿势,然后根据步骤4描述的内容使用神经变形网络来变形更新场景网格。
与现有技术相比,本发明具有以下优点:1.本发明所提出的一种基于神经变形的可变形场景中人体运动捕捉方法,能够从人和可变形环境交互的单视角RGB视频中捕捉三维人体运动和建模可变形场景的非刚性变形。2.本发明建模了可变形环境的非刚性变形,提出了一种基于Transformer的神经变形网络建模可变形场景的变形。3.本发明利用人体和场景相互之间的约束,建模场景变形,并有效提高了全局三维人体运动捕捉的精度。4.本发明输入仅为单视角RGB视频,采集方便,成本较低,易于实现。
附图说明
图1是本发明实施例中的流程图;
图2是本发明实施例中基于Transformer神经变形的网络结构图;
图3是本发明实现的重建效果图,其中,(a)列图为输入的彩色图像,(b)列图为初始化重建结果,(c)列图为最终重建结果。
具体实施方式
以下将结合附图及实施例来详细说明本发明的实施方式,借此对本发明使用的方法及实现效果进行梳理,使使用者对本发明有更清晰的了解。值得注意的是,在不构成冲突的情况下,本发明实施例间的特征可以相互结合,所形成的技术方案均在本发明的保护范围之内。
此外,附图中示出的流程图可以在计算机中以一系列连续的指令执行,并且在某些情况下可以对流程顺序进行适当修改。
实施例一
图1为本发明实施例一的基于神经变形的可变形场景中人体运动捕捉方法的流程图,下面参照图1详细说明各个步骤。
步骤S110,使用三维人体姿态估计器,从单目彩色图像中初始化人体模型的三维人体姿态;
采用基于优化的SMPLify-X初始化人体模型SMPL-X,通过最小化目标函数来获得相对于根节点的三维人体姿态。
三维人体姿态的目标函数定义如下:
E
该目标函数优化的参数β表示人体形状参数,θ代表可优化姿势参数的完整集合,t表示全局平移,目标函数第一项E
步骤S120,估计三维人体姿态下的人体网格的接触概率图,获得与场景接触的接触点,并通过光线投射找到场景网格上相应的接触点,即得到人体网格和场景网格的接触点对;
对于当前三维人体姿态下的人体网格,使用一个条件变分自编码器为该三维姿态下的人体生成接触概率图。训练好的解码器以初始化三维人体姿态下的人体网格顶点和隐变量作为采样条件,其中隐变量空间服从于高斯分布。生成的接触概率图进行阈值操作,则可以得到与环境接触的人体网格顶点。
使用现有的光线投射查找策略找到场景网格上相应的接触点。将生成的人体接触点重新投影到图像空间中。若重新投影的接触点落在未被遮挡的人体部位上,则投射来自相机的光线,以找到与三维场景网格的相交点。若重新投影的接触点落在被遮挡的人体部位上,则将其最近的场景顶点作为相对应的接触。
步骤S130,基于获得的人体网格和场景网格的接触点对,优化目标函数获得全局三维人体姿态。
获得人体网格和场景网格的接触点对后,将人体网格上的接触点对齐到相应的场景网格接触点上,通过最小化全局目标函数来获得粗糙的全局三维人体姿态。
所述全局目标函数定义如下:
E
该目标函数优化的参数β表示人体形状参数,θ代表可优化姿势参数的完整集合,t表示全局平移,目标函数第一项E
步骤S140,搭建基于Transformer的神经变形网络,根据全局三维人体姿态下的人体网格和场景网格的交互状态对场景网格执行非刚性变形;
根据全局三维人体姿态下的人体网格和场景网格的交互状态定义稀疏控制点。首先使用训练好的三维场景分割网格对场景进行分割,并对分割部分进行语义标签估计。场景分割和语义标签估计完成之后,屏蔽掉刚性场景,只对可变形场景进行后续的非刚性变形。接下来,对当前人体网格和可变形场景进行碰撞检测,若当前人体网格顶点穿透了场景,并且该人体网格顶点是估计的接触点,则将其最近的被穿透的物体顶点设置为控制点,该控制点的目标位置是该人体网格顶点的位置。
定义稀疏控制点及其目标位置后,搭建基于Transformer的神经变形网络,对场景网格执行非刚性变形。该神经变形网络的结构图如图2所示。对于可变形场景网格,固定均匀采样N个点,采样点中包含稀疏控制点,若是控制点则将其目标位移设置为到目标位置的位移,若非控制点则将其目标位移设置为零。将采样得到的N个点的位置以及目标位移送到神经变形网络中,输出得到一组由位移和旋转组成的欧式变换,即M个节点的欧式变换。对于可变形场景网格上每个顶点变形后的位置,由其最近m个节点的欧式变换决定。找到最近m个节点,该顶点变形后的位置是应用最近m个节点的欧式变换的位置的加权和,计算公式可以表述如下:
其中,v是场景网格顶点,v'是顶点v的变形后的位置,R
步骤S150,迭代交替优化全局人体姿态和场景变形,实现高质量的无标记单目三维人体运动捕捉和非刚性三维场景变形。
对人体姿态和场景变形进行迭代交替优化。在每一次迭代中,首先根据步骤S120获得人体网格和场景网格的接触点对,在步骤S130的全局目标优化函数基础上添加惩罚人体与场景穿透项,优化该目标函数来更新全局人体姿势,然后根据步骤S140描述的内容使用神经变形网络来变形更新场景网格。
本实施例一中,实现的重建效果如图3所示。其中,图3的第一列表示输入的彩色图像,第二列图为初始化重建结果,第三列图为最终重建结果。
本领域的技术人员应该明白,上述的本发明的各模块或各步骤可以用通用的计算装置来实现,它们可以集中在单个的计算装置上,或者分布在多个计算装置所组成的网络上,可选地,它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本发明不限制于任何特定的硬件和软件结合。
- 一种基于可变形卷积神经网络的人体姿态估计方法
- 一种基于可变形卷积神经网络的人体姿态估计方法