一种基于阅读理解的纠纷调解要素提取方法及系统
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及法律要素提取技术领域,具体为一种基于阅读理解的纠纷调解要素提取方法及系统。
背景技术
要素抽取是法律领域的一项重要任务。在各类司法案件中,民事纠纷占有越来越高的比例,而民事纠纷的解决主要依靠调解的方式进行。由于纠纷调解卷宗内容冗长,了解纠纷情况时需要抽取卷宗要素。
抽取要素常常使用机器阅读理解技术,该技术可以自然地提取细粒度和不受约束的信息。阅读理解任务可以理解为,给定一个问题和包含答案的一段文本,让模型从文本中抽取连续的序列作为问题的答案。在纠纷调解卷宗中进行要素抽取,将案件内容作为输入模型的文本,要素名作为问题,所要提取的要素内容视为答案,计算答案的开始位置和结束位置。
纠纷案件存在较多类型,包括民间借贷纠纷、劳动纠纷、工伤纠纷等,对不同类型的纠纷案件进行要素抽取时,需要抽取的要素并不相同且多达三十种,这要求在对用于纠纷要素提取的阅读理解模型进行训练时使用大规模的数据集,从而确保提取的要素的正确性和精确性。
然而,目前的研究中并没有提供纠纷案件相关的数据集,可用于训练的数据集为中文司法领域的数据集,涉及范围更广,针对性更差,直接使用该数据集训练得到的阅读理解模型,会导致进行纠纷要素提取时较差的效果。
同时,即使自己创建纠纷案件数据集,由于纠纷案件有关的公开数据较少,在人工标注不同类型纠纷案件的多种要素耗费大量时间和精力的同时,仍会存在样本不足的问题,从而导致现有的阅读理解模型无法充分学习纠纷案件的特征,影响提取纠纷要素的正确率和精确性。
发明内容
针对上述现有技术的不足,本发明旨在提供一种基于阅读理解的纠纷调解要素提取方法及系统,以解决纠纷案件数据较少,而使得纠纷案件要素提取的针对性差和正切率低的问题。
为了解决上述问题,本发明采用了如下的技术方案:
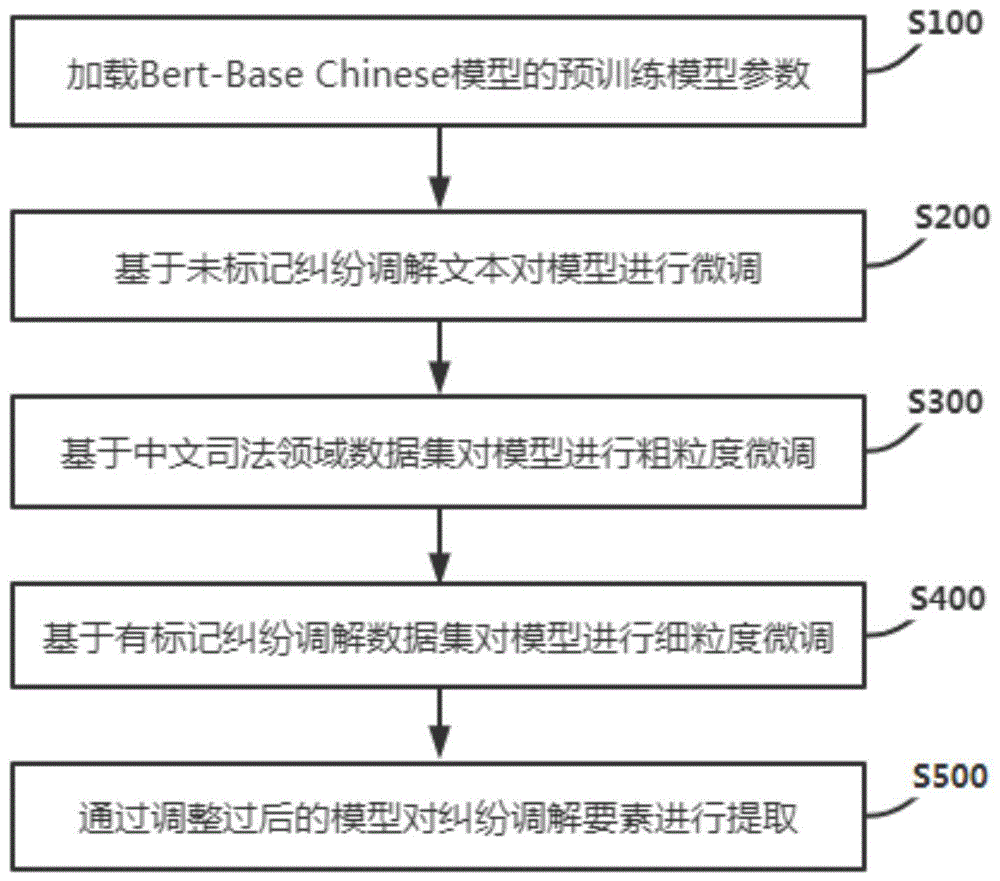
本专利基于阅读理解的纠纷调解要素提取方法可以分为四个阶段:加载Bert-Base Chinese预训练模型参数,基于未标记纠纷调解文本对模型进行微调,基于中文司法领域数据集对模型进行粗粒度微调和基于有标记纠纷调解数据集对模型进行细粒度微调。
基于未标记纠纷调解文本对模型进行微调。该任务与预训练任务之一相似,通过遮挡未标记文本的一些字词,使用“掩码语言模型”模型进行遮挡字词的预测。具体地说,在人工标注的纠纷调解数据较少的情况下,通过遮挡未标记纠纷调解文本中一些字词,使用模型预测遮挡词,从而对模型进行微调,使模型能够学习纠纷调解文本的特征,生成具有更丰富的语义信息尤其是更丰富的纠纷调解相关信息的文本表示,有效解决了由于纠纷调解数据集样本过少带来的语义信息不充分的问题。
基于有标记纠纷调解数据集对模型进行细粒度微调。现有技术使用的中文司法领域数据集涉及范围较广,使用该数据集对模型进行的粗粒度微调不够有针对性,因此选择少样本的有标记纠纷调解数据集对模型进行细粒度微调,从而使本方法使用的模型更加了解不同类型纠纷案件所要提取的要素,更适用于纠纷调解要素提取。
具体的,本发明第一方面提供一种基于阅读理解的纠纷调解要素提取方法,包括:
加载Bert-Base Chinese模型的预训练模型参数;
基于未标记纠纷调解文本对模型进行微调;
基于中文司法领域数据集对模型进行粗粒度微调;
基于有标记纠纷调解数据集对模型进行细粒度微调;
通过调整过后的模型对纠纷调解要素进行提取。
作为一种可实施方式,所述加载Bert-Base Chinese模型的预训练模型参数,包括:
下载并缓存Bert-Base Chinese模型的预训练模型文件,然后加载该文件,读取模型预训练后的模型参数,将所述模型参数用于初始化Bert-Base Chinese模型;该模型层的数量L=12,隐藏大小H=768,自注意力头的数量A=12。
作为一种可实施方式,所述基于未标记纠纷调解文本对模型进行微调,包括:
对模型的输入序列进行预处理;
对预处理后的输入序列输入模型,使用模型计算出对应于遮挡字词的最终隐藏向量,送入基于词汇表的输出softmax函数,得到基于上下文预测的遮挡的字词;第i个输入字词的最终隐藏向量为T
其中,P
作为一种可实施方式,所述对模型的输入序列进行预处理,包括:
由单个句子或一对句子组合的序列,对每个序列的第一个标记使用一个特殊的分类标记[CLS];
对于句子对组合的序列,额外使用一个特殊的标记[SEP]将它们分开;
使用WordPiece嵌入和具有30000个字词的词汇表对序列进行分词;
随机遮挡每个输入序列中所有WordPiece字词的15%,在随机遮挡的过程中,80%的时间使用[mask]标记,10%的时间使用随机字词,剩余10%的时间使用原始字词;
对于输入序列的所有字词,通过对相应的字词、分段和位置嵌入求和来构造模型的输入表示;
输入句子对组合的序列前,还要向每个字词添加一个习得的嵌入,指示它属于哪个句子。
作为一种可实施方式,所述基于中文司法领域数据集对模型进行粗粒度微调,包括:
将中文司法领域数据集中每一个问题和包含答案的文本连接起来表示为单个序列,该序列第一个标记为[CLS],问题与文本之间使用[SEP]标记分开;对于答案类型为是或否的问题,在数据处理阶段,将[YES]和[NO]作为两个标记与文本内容连接起来,使用WordPiece嵌入和具有30000个字词的词汇表对序列进行分词;
引入一个开始向量S和结束向量E,计算对T
将公式中S替换为E,从位置i到位置j的候选答案的得分定义为S·T
在中文司法领域数据集中,若实例中包含所有带标注的短答案,则将开始和结束目标索引设置为指向包含所有带标注的短答案的最短文本;若实例中没有带标注的短答案,但在实例中完全包含一个带标注的长答案,则将开始和结束目标索引设置为指向整个长文本;若在当前实例中找不到短答案和长答案,则将目标开始和结束索引设置为指向[CLS]标记;
粗粒度微调的损失函数为正确开始位置和结束位置的负对数似然之和:
其中P
作为一种可实施方式,所述基于有标记纠纷调解数据集对模型进行细粒度微调,包括:
基于纠纷调解数据集,遍历所述纠纷调解数据集中同一段文本中的不同问题,将其与文本连接成不同的序列,将纠纷调解数据集中每一个问题和包含答案的文本连接起来表示为单个序列,该序列第一个标记为[CLS],问题与文本之间使用[SEP]标记分开;对于答案类型为是或否的问题,在数据处理阶段,将[YES]和[NO]作为两个标记与文本内容连接起来,使用WordPiece嵌入和具有30000个字词的词汇表对序列进行分词;
引入一个开始向量S和结束向量E,计算对T
将公式中S替换为E,从位置i到位置j的候选答案的得分定义为S·T
在纠纷调解数据集中,若实例中包含所有带标注的短答案,则将开始和结束目标索引设置为指向包含所有带标注的短答案的最短文本;若实例中没有带标注的短答案,但在实例中完全包含一个带标注的长答案,则将开始和结束目标索引设置为指向整个长文本;若在当前实例中找不到短答案和长答案,则将目标开始和结束索引设置为指向[CLS]标记;
细粒度微调的损失函数为正确开始位置和结束位置的负对数似然之和:
其中P
作为一种可实施方式,所述调整过后的模型的损失函数
第二方面,本发明提供一种基于阅读理解的纠纷调解要素提取系统,包括加载模块、微调模块、粗颗粒度微调模块、细颗粒度微调模块和提取模块;
所述加载模块,用于加载Bert-Base Chinese模型的预训练模型参数;
所述微调模块,用于基于未标记纠纷调解文本对模型进行微调;
所述粗颗粒度微调模块,用于基于中文司法领域数据集对模型进行粗粒度微调;
所述细颗粒度微调模块,用于基于有标记纠纷调解数据集对模型进行细粒度微调;
所述提取模块,用于通过调整过后的模型对纠纷调解要素进行提取。
第三方面,本发明提供一种电子设备,包括处理器和存储器;其中,所述处理器执行所述存储器中保存的计算机程序时实现如上述的基于阅读理解的纠纷调解要素提取方法。
第四方面,本发明提供一种计算机可读存储介质,用于存储计算机程序;其中,所述计算机程序被处理器执行时实现如上述的基于阅读理解的纠纷调解要素提取方法。
本发明的有益效果在于:本发明采用两个针对特定纠纷调解的微调阶段,在原有的预训练阶段和微调阶段之间增加了基于未标记纠纷调解文本对模型进行的微调,以及原微调阶段之后基于有标记纠纷调解数据集对模型进行细粒度微调;基于有标记纠纷调解数据集对模型进行细粒度微调较使用的中文司法领域数据集涉及范围较广,因此选择少样本的有标记纠纷调解数据集对模型进行细粒度微调,从而使本方法使用的模型更加了解不同类型纠纷案件所要提取的要素,更适用于纠纷调解要素提取。
附图说明
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步的详细描述,其中:
图1为本发明实施例一种基于阅读理解的纠纷调解要素提取方法流程示意图。
图2为本发明实施例步骤S200流程示意图。
图3为本发明实施例步骤S300流程示意图。
图4为本发明实施例一种基于阅读理解的纠纷调解要素提取系统示意图。
具体实施方式
下面结合具体实施例对本发明作进一步的详细说明。
需要说明的是,这些实施例仅用于说明本发明,而不是对本发明的限制,在本发明的构思前提下本方法的简单改进,都属于本发明要求保护的范围。
参见图1,为一种基于阅读理解的纠纷调解要素提取方法,包括:
S100、加载Bert-Base Chinese模型的预训练模型参数;
S200、基于未标记纠纷调解文本对模型进行微调;
S300、基于中文司法领域数据集对模型进行粗粒度微调;
S400、基于有标记纠纷调解数据集对模型进行细粒度微调;
S500、通过调整过后的模型对纠纷调解要素进行提取。
本发明采用两个针对特定纠纷调解的微调阶段,在原有的预训练阶段和微调阶段之间增加了基于未标记纠纷调解文本对模型进行的微调,以及原微调阶段之后基于有标记纠纷调解数据集对模型进行细粒度微调;基于有标记纠纷调解数据集对模型进行细粒度微调较使用的中文司法领域数据集涉及范围较广,因此选择少样本的有标记纠纷调解数据集对模型进行细粒度微调,从而使本方法使用的模型更加了解不同类型纠纷案件所要提取的要素,更适用于纠纷调解要素提取。
作为一种可实施方式,步骤S100、加载Bert-Base Chinese模型的预训练模型参数,包括:
下载并缓存Bert-Base Chinese模型的预训练模型文件,然后加载该文件,读取模型预训练后的模型参数,将所述模型参数用于初始化Bert-Base Chinese模型;该模型层的数量L=12,隐藏大小H=768,自注意力头的数量A=12。
作为一种可实施方式,参见图2,步骤200、基于未标记纠纷调解文本对模型进行微调,包括:
对模型的输入序列进行预处理;对模型的输入序列进行预处理具体为:
由单个句子或一对句子组合的序列,对每个序列的第一个标记使用一个特殊的分类标记[CLS];
对于句子对组合的序列,额外使用一个特殊的标记[SEP]将它们分开;
使用WordPiece嵌入和具有30000个字词的词汇表对序列进行分词;
随机遮挡每个输入序列中所有WordPiece字词的15%,在随机遮挡的过程中,80%的时间使用[mask]标记,10%的时间使用随机字词,剩余10%的时间使用原始字词;
对于输入序列的所有字词,通过对相应的字词、分段和位置嵌入求和来构造模型的输入表示;
输入句子对组合的序列前,还要向每个字词添加一个习得的嵌入,指示它属于哪个句子。
对预处理后的输入序列输入模型,使用模型计算出对应于遮挡字词的最终隐藏向量,送入基于词汇表的输出softmax函数,得到基于上下文预测的遮挡的字词;第i个输入字词的最终隐藏向量为T
其中,P
作为一种可实施方式,参见图3,步骤S300、基于中文司法领域数据集对模型进行粗粒度微调,包括:
将中文司法领域数据集中每一个问题和包含答案的文本连接起来表示为单个序列,该序列第一个标记为[CLS],问题与文本之间使用[SEP]标记分开;对于答案类型为是或否的问题,在数据处理阶段,将[YES]和[NO]作为两个标记与文本内容连接起来,使用WordPiece嵌入和具有30000个字词的词汇表对序列进行分词;
引入一个开始向量S和结束向量E,计算对T
将公式中S替换为E,从位置i到位置j的候选答案的得分定义为S·T
在中文司法领域数据集中,若实例中包含所有带标注的短答案,则将开始和结束目标索引设置为指向包含所有带标注的短答案的最短文本;若实例中没有带标注的短答案,但在实例中完全包含一个带标注的长答案,则将开始和结束目标索引设置为指向整个长文本;若在当前实例中找不到短答案和长答案,则将目标开始和结束索引设置为指向[CLS]标记;
粗粒度微调的损失函数为正确开始位置和结束位置的负对数似然之和:
其中P
作为一种可实施方式,步骤S400、基于有标记纠纷调解数据集对模型进行细粒度微调,包括:
本阶段做法与粗粒度微调类似,主要的区别在于数据集内容与格式的不同。粗粒度微调的中文司法领域的数据集涉及范围更广,针对性更弱,而细粒度微调使用的数据集来源于脱敏后的真实纠纷调解数据。且中文司法领域的数据集一段文本仅需从中提取仅一个问题对应的一个答案,而纠纷调解要素提取则需要从一段文本中提取多个要素对应的内容。因此在进行相似的操作之前,需要遍历同一段文本中的不同问题,将其与文本连接成不同的序列。
具体为:
基于纠纷调解数据集,遍历所述纠纷调解数据集中同一段文本中的不同问题,将其与文本连接成不同的序列,将纠纷调解数据集中每一个问题和包含答案的文本连接起来表示为单个序列,该序列第一个标记为[CLS],问题与文本之间使用[SEP]标记分开;对于答案类型为是或否的问题,在数据处理阶段,将[YES]和[NO]作为两个标记与文本内容连接起来,使用WordPiece嵌入和具有30000个字词的词汇表对序列进行分词;
引入一个开始向量S和结束向量E,计算对T
将公式中S替换为E,从位置i到位置j的候选答案的得分定义为S·T
在纠纷调解数据集中,若实例中包含所有带标注的短答案,则将开始和结束目标索引设置为指向包含所有带标注的短答案的最短文本;若实例中没有带标注的短答案,但在实例中完全包含一个带标注的长答案,则将开始和结束目标索引设置为指向整个长文本;若在当前实例中找不到短答案和长答案,则将目标开始和结束索引设置为指向[CLS]标记;
细粒度微调的损失函数为正确开始位置和结束位置的负对数似然之和:
/>
其中P
作为一种可实施方式,所述调整过后的模型的损失函数
参见图4,为一种基于阅读理解的纠纷调解要素提取系统,包括加载模块100、微调模块200、粗颗粒度微调模块300、细颗粒度微调模块400和提取模块500;
所述加载模块100,用于加载Bert-Base Chinese模型的预训练模型参数;
所述微调模块200,用于基于未标记纠纷调解文本对模型进行微调;
所述粗颗粒度微调模块300,用于基于中文司法领域数据集对模型进行粗粒度微调;
所述细颗粒度微调模块400,用于基于有标记纠纷调解数据集对模型进行细粒度微调;
所述提取模块500,用于通过调整过后的模型对纠纷调解要素进行提取。
本发明提供一种电子设备,包括处理器和存储器;其中,所述处理器执行所述存储器中保存的计算机程序时实现如上述的基于阅读理解的纠纷调解要素提取方法。
本发明提供一种计算机可读存储介质,用于存储计算机程序;其中,所述计算机程序被处理器执行时实现如上述的基于阅读理解的纠纷调解要素提取方法。
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管通过参照本发明的优选实施例已经对本发明进行了描述,但本领域的普通技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离所附权利要求书所限定的本发明的精神和范围。
- 一种基于特征迁移和自适应学习的人民调解案例分类系统及方法
- 基于阅读理解的汉越跨语言新闻事件要素抽取方法
- 基于阅读理解的汉越跨语言新闻事件要素抽取方法