一种机载声学检测设备的硬件及软件降噪方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及一种机载声学检测设备的硬件及软件降噪方法,属于无人机声学检测的技术领域。
背景技术
架空线路塔上绝缘子、金具等设备受环境影响容易产生运行缺陷和安全隐患,常用的无人机巡检基于可见光、红外方式,难以对早期无破损、无温升设备缺陷进行检测预警。
声学检测是无损检测的研究热点之一,目前已有成熟产品应用在手持局放检测、变电站异响检测、气体泄露检测等领域,但以上产品受无人机桨叶噪声干扰严重,机载环境下无法准确识别局放噪声,故在可大范围巡检的无人机领域得到应用尚属首次。
对此,本发明提出一个基于无人机声学检测设备降噪方案,通过将硬件降噪和软件降噪相结合,实现高准确的环境声采集。
发明内容
为了解决现有技术所存在的上述问题,本发明提供了一种机载声学检测设备的硬件及软件降噪方法。
本发明的技术方案如下:
一种机载声学检测设备的硬件降噪方法,包括
加装减震结构,消除部分机械振动产生的噪音;以及
设置定向收音结构,削弱从其它方向入射的噪音,增强正向可能声源声波的信噪比。
作为进一步具体实施方式
所述减震结构采用钢丝绳结构,利用多根环列分布设置的弧形钢丝绳围合构成一个鼓状笼体结构,并将笼体结构上下两端连接于无人机的机架与云台之间。
作为进一步具体实施方式
所述定向收音结构包括具有一定长度的声波传导腔体,声波传导腔体一端设置声学检测阵列,声学检测阵列采用MEMS麦克风,另一端敞口作为收音端;其中,声波传导腔体的腔壁为疏松多孔结构,且腔体内采用倒角和转角平滑设计。
一种机载声学检测设备的软件降噪方法,包括
声学检测阵列获取高质量信号:
声学检测阵列综合多路麦克风的观测结果进行系统降噪:
通过阵列达波模型定位算法的基础理论原理,得到多个声源在阵列处叠加后的振动模型,并考虑麦克风的噪声矢量,得到完整的声场建模方程;
基于时差的声源定位技术,通过计算信号的延迟,结合麦克风的位置,从而通过达波模型计算声源位置;利用波束形成理论进行声源定位,通过上述过程计算声场模型和时延求和后,得到对声场中的声源估计结果;
进行噪声分离,在声源定位的计算过程中,利用矩阵的性质,对信号子空间和噪声子空间进行分解,通过噪声子空间的正交矢量,估计声源方向,降低无关噪音。
作为进一步具体实施方式
所述声学检测阵列获取高质量信号:
通过小波包降噪及重构算法对信号进行降噪;降噪后通过最优小波包基算法,采用熵最小原则;用最佳小波包树重构信号,提升信号的信噪比并突出主要特征。
作为进一步具体实施方式
所述声学检测阵列综合多路麦克风的观测结果进行系统降噪:
利用声源质点的振动方程为:
经历了一定的时延后,得到空间质点P的振动方程为:
其中,c为声速,x为传播距离;
上述基于时延的波动方程求解,进行了平面波假设,即振幅与传播距离无关,传播中频率不变,相位随距离的变化而变化;而球面波模型中,仅仅将振幅A对距离做了衰减处理;根据声学的基本理论,声压振幅与传播距离成反比,由此可得球面波的传播模型。
作为进一步具体实施方式
所述达波模型问题描述:
当m个麦克风的声场中具有k个声源,假设m>k,第k个声源的振动方程已由上文定义,k与m之间的距离为r
考虑一个近场模型:
声源K在参考中心产生的振动为:
声源k在阵元m处产生的信号为:
二者相除后:
从中可以提取时延项:
/>
故而,第m个麦克风收到的总信号就可以认为是空间所有声源在这一点处的叠加:
通过以上原理,可通过简单推导,得到m个声源在阵列处叠加后的振动模型,即声源达波模型:
其中,每一列均为M维的方向矢量,M为麦克风的个数,表达了第k个声源声波传播到麦克风上时的作用方式;
其中,等式右侧第一项为达波矩阵,这是一个M*K维的矩阵,描述了在流型矩阵中,声波的作用模式;
对上式可以做一定程度的简化,并且还要考虑麦克风的噪声矢量:
Y=AX+N
其中Y是麦克风阵列的观测量,A为达波矩阵,X为传播方程,N为麦克风的噪声矢量;得到了完整的声场建模方程。
作为进一步具体实施方式
所述对声场中的声源估计结果过程:
信号时延的计算需要依赖于对平稳随机信号的假设,而变压器属于较为稳定的设备,声源位置相对固定,可以满足计算时延所需的基本假设;
假设X(t)与Y(t)为广义平稳随机的离散信源,数学期望不随时间改变,其自相关函数为:
R
互相关函数为:
R
当相关函数取到最大值时,其时间偏移量就是在此方法下最优估计的信号时延:
τ=ΔTargmaxR
将时域上的卷积运算转化为了频域的乘积过程;PSD与互相关函数之间的关系为:
/>
或采用广义互相关法,采用了频域滤波器对相关函数进行处理,最佳滤波器H为信号自功率谱的倒数:
通过上述过程计算声场模型和时延求和后,即可得到对声场中的声源估计结果。
作为进一步具体实施方式
所述进行噪声分离:
基于噪声空间分离问题描述,麦克风处的声源波动方程为:
故而,第m个麦克风处,所有声源的波动叠加可以表示为:
由几何关系可知,理论时延可由下式得到:
将方程中人为引进噪音项后,可将麦克风阵列的波动方程使用矩阵形式进行表达,其中最后一项为引入的噪声项:
采用矩阵形式进行表达:
X(n)=AS(N)+V(n)
其中X为麦克风接收到的振动数据,A为导向向量,S为声源波动模型,V为噪声;
X为观测数据,内含有场景中的其他噪声,假设各个麦克风阵元的噪声相互独立且满足一个方差为
R=E[X(n)X
通过理论推导:
/>
其中:
R
对R进行特征值分解,并依据特征值分解性质进行计算:
R=UΛU
UU
U为特征向量构成的酉矩阵,具有正交性质;∧为矩阵特征值构成的对角矩阵;根据特征值对角阵的性质,将协方差矩阵代入:
由于Rs是一个K维矩阵,最多只有K个特征值,当麦克风数量M超过K时,矩阵并非一个满秩矩阵,后面的对角元素必然为零,在引入了噪声项之后,特征值矩阵的表达形式转变为:
基于噪声空间的强度小于待监测声源的基本假设,在对角阵中的对角元素产生值跳跃,由此即可判定在特征值矩阵中的信号源成分和噪声成分;
而后利用分块矩阵的性质即将场景中的耦合声源分解为了信号子空间和噪音子空间,结合对城市变电站噪音特性,对信号的分布进行进一步建模,提升噪音子空间的分解精确度。
本发明具有如下有益效果:
本发明一种机载声学检测设备的硬件及软件降噪方法,包括硬件降噪部分和软件降噪部分,其中,硬件降噪部分主要通过设置钢丝绳减震结构和特殊定向收音结构,通过采用降噪材料、设计降噪结构的手段,从物理上减少被麦克风阵列拾取的噪声;软件降噪部分主要通过后期信号处理,对采集到的信号进行降噪。这里主要描述数字降噪方法的实验及测试结果;通过将硬件降噪和软件降噪相结合,实现高准确的环境声采集。
附图说明
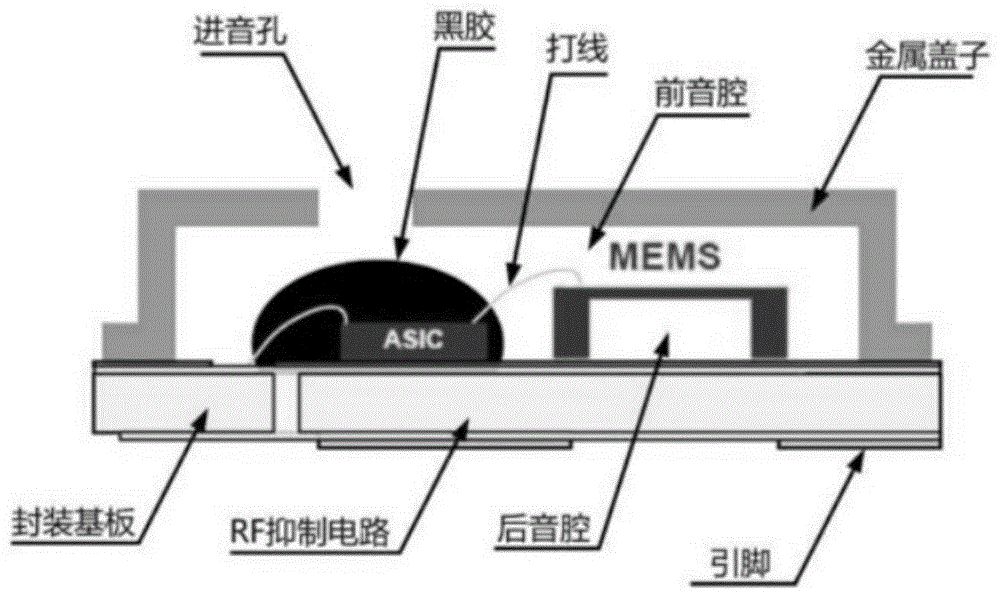
图1为本发明MEMS结构示意图;
图2为本发明标准云台结构示意图;
图3为本发明定制的钢丝绳减震结构;
图4为本发明吸音棉吸音原理示意图;
图5为本发明小波包分解结构图;
图6为本发明最大熵树搜索原理;
图7为本发明达波模型示意图;
图8为本发明噪声空间分离问题描述。
具体实施方式
下面结合附图和具体实施例来对本发明进行详细的说明。
参见图1-8,一种机载声学检测设备,包括
无人机挂载平台
M300无人机,机身长度0.81米(对角桨间距),机身宽度0.67米(对角桨间距),机身高度0.430米(地面到机舱上盖)。双电池系统提升飞行安全系数,空载续航时间45-55分钟,最大挂载2.7KG,支持接口定制。其尺寸可以保障声学阵列的挂载空间和载重量。故而M300是当前最适合与机载声纹探测设备进行适配的机型,后续的定制开发工作也基于M300 RTK进行。本报告将重点研究基于声学阵列挂载大疆M300无人机的噪声特性。依据无人机整体设计需求,需要将声纹设备负载进行定制轻量化,保证无人机在负载情况下依然能达到20分钟左右的续航时间。
声学采集阵列
麦克风是目前常用的采集器,指的是采用微电机技术制作而成的麦克风,将感知压力的薄膜直接制作在芯片上。在芯片上也可以集成诸多计算单元,如放大器,数字信号转换器等,可以直接产生可供算法读取的数字信号。这类麦克风体积小,声学性能稳定,频率响应范围大。
传统麦克风就是根据声波产生的空气流动对薄片的冲击,使其产生形变,从而改变电容,使输出电信号改变,从而反映出入口处的声波的频率和幅度的变化。MEMS麦克风的组成一般是由MEMS微电容传感器、微集成转换电路、声腔、RF抗干扰电路这几个部分组成的。MEMS微电容极头包括接受声音的硅振膜和硅背极。硅振膜可以直接接收到音频信号,其原理即为胡克定律:
F=-kx
相比于传统麦克风,构成MEMS振膜和背极的单晶硅是一种几乎完美的胡克材料,这意味着当它弯曲时几乎没有迟滞现象,也因此几乎没有能量耗散。这保证了MEMS精确的响应和可靠的使用寿命。振动信号经过MEMS微电容传感器传输给微集成电路,微集成电路把高阻的音频电信号转换并放大成低阻的电信号,同时经RF抗噪电路滤波,输出与前置电路匹配的电信号,就完成了声电转换。通过对电信号的读取,从而实现对声音的识别。MEMS的结构示意如图1所示。
噪声分析
机载声纹相机采集的声信号中,除了包含局放的目标信号外,还有大量噪声,如风声、马达声、桨叶声、其它环境噪声。日常大部分噪声的能量主要分布在低频波段,而局放信号能量主要集中在超声波段。利用这一点,可通过滤波、FFT等方法提取超声波段,在一定程度上剔除低频噪声的干扰;另一方面,与地面和室内使用的声纹相机比,机载式声纹相机场景中引入了大量能量较高的宽频噪声,如马达声、桨叶声、风声等。这类噪声在超声频段上也具有较高能量,难以通过滤波手段剔除。
减少噪声、提高局放信号信噪比主要有两种途径:
1)硬件降噪。通过采用降噪材料、设计降噪结构的手段,从物理上减少被麦克风阵列拾取的噪声。该方法效果直接、显著,是信号降噪的重要手段。但物理降噪装置受设备使用场景、无人机搭载能力的限制,难以做到完全阻隔噪声。因此,我们还需要:
2)软件降噪。通过后期信号处理,对采集到的信号进行降噪。这里主要描述数字降噪方法的实验及测试结果。
硬件降噪
通过固体机械振动传播的噪音,会直接传递至阵列上,通过加装减震结构,可以达成消除部分机械振动的目的。考虑到线路巡检的应用场景,应使得阵列尽可能保持稳定,由于声学阵列必须保持一定的孔径才能确保其空间指向性达到声学定位算法的要求,这是由物理原理决定的,故而阵列的要保持在一定的尺寸和重量之上。在这个尺寸和挂载之下,传统的减震结构,在飞行中会使得阵列的摆动幅度变大,减震球结构的弹性较大,在空中飞行时会产生较大幅度的摆动,减震球结构如图2所示:
通过改装云台的减震球结构,将其替换为了钢丝绳结构,其载重更大,具有一定的刚性,可以确保声学阵列在空中仅随无人机本身的运动而发生位移,不会产生大幅度摆动。钢丝绳减震器的物理特性对高频振动的抵消作用更加明显,可以更好吸收高频噪音,防止与局放易发生频段产生过高的耦合,如图3所示;
通过空气传播的噪音,会从视场的各个方向直接入射麦克风。在上方的旋翼的强烈干扰下,从非正向入射的声波会携带更大的旋翼噪音。故而,在结构消音上,还添加了定向收音结构,削弱从其它方向入射的噪音,从而达到增强正向可能声源声波的信噪比的目的。
定向收音结构原理如图4所示。自其它方向入射的声波会首先在腔体内壁上进行反射,故而此处的消音的目的在于抑制从的反射音。只有从正向入射的声波才能直接抵达麦克风阵列。如此达到了从结构上降低空气传播的噪音的目的。反射声主要在腔体内进行传播,通过疏松多孔的结构,可以更加有效的针对超声波段的噪音进行结构降噪。
在抑制投射声方面,主要的噪音来自无人机从上方吹下的强气流直接击打声纹检测装置壳体产生的,通过对外观结构的流体力学设计,包括腔体倒角设计,转角平滑设计,以及通过延长了腔体的长度,将压强异常点延伸至远离阵列的区域。这保障了声学检测装置在飞行中的平稳姿态,不会产生过大的振动和干扰噪音。
软件降噪
为获取高质量信号,本项目通过小波包降噪及重构算法对信号进行降噪。
如图5-6,小波包可将原信号进行多层级分解,且各层均保留了信号的全部信息。通过动态阈值计算可对分解后每个节点的小波包系数进行降噪。降噪后通过最优小波包基算法,其通常采用熵最小原则,即熵越小的节点其信息规律性更大。我们计算每个小波包节点的Shannon熵,当子节点熵之和小于父节点时,保留子节点;反之则去掉子节点(及其后的节点),只保留父节点。最后用最佳小波包树重构信号,有效提升信号的信噪比并突出主要特征。
由于声学检测是由一组阵列构成,除了对一路麦克风信号进行分解之外,还可综合多路麦克风的观测结果进行系统降噪。
声波传播模型描述了阵列接受信号与声源信号之间关系的声波叠加合成模型,需要考虑到阵列的参数、时延、方位等信息。考虑到了声源质点的振动方程:
/>
则在空间一点P的振动方程,就是此波动经历了一定的时延后的波动。设声速为c,传播距离为x,那么可以得到空间质点P的振动方程为:
这种基于时延的波动方程求解,进行了平面波假设,即振幅与传播距离无关,传播中频率不变,相位随距离的变化而变化。而球面波模型中,仅仅将振幅A对距离做了衰减处理。根据声学的基本理论,声压振幅与传播距离成反比,由此可得球面波的传播模型。
阵列达波模型是定位算法的基础理论,它描述了多声源声波传播中,在一个麦克风上的叠加。达波模型问题描述:当m个麦克风的声场中具有k个声源,假设m>k,第k个声源的振动方程已由上文定义,k与m之间的距离为r
考虑一个近场模型:
声源K在参考中心产生的振动为:
声源k在阵元m处产生的信号为:
二者相除后:
从中可以提取时延项:
故而,第m个麦克风收到的总信号就可以认为是空间所有声源在这一点处的叠加:
通过以上原理,可通过简单推导,得到m个声源在阵列处叠加后的振动模型,即声源达波模型:
/>
其中,每一列均为M维的方向矢量,M为麦克风的个数,表达了第k个声源声波传播到麦克风上时的作用方式。其中等式右侧第一项为达波矩阵,这是一个M*K维的矩阵,描述了在流型矩阵中,声波的作用模式。我们对上式可以做一定程度的简化,并且还要考虑麦克风的噪声矢量:
Y=AX+N
其中Y是麦克风阵列的观测量,A为达波矩阵,X为传播方程,N为麦克风的噪声矢量。至此我们得到了完整的声场建模方程。
而定位算法目前主流的波束形成(Beamforming)思想是最主要的定位算法,不同的波束形成算法具有不同的空间感知特性以及对不同波段的敏感度。基本思想是基于时差的声源定位技术(TDOA:time difference of arrival),通过计算信号的延迟,结合麦克风的位置,从而通过达波模型计算声源位置。在基本思想的基础上,波束形成思想产生了数量众多的变种,以适应不同的定位场景:如超声定位、多声源定位、单声源定位、声源追踪、以及低频声源定位。在各个应用场景中均会从阵列设计和算法设计两个方面进行适配。
近场声源定位模型与远场定位模型的差别在于对声波的入射假设不同,近场模型认为入射声波为球面波,远场模型认为入射声波可以近似为平面波。故而两种算法的本质区别在于达波矩阵的元素有差异。通过切换矩阵A的系数,可以达到切换远场和近场模型的目的。
信号时延的计算需要依赖于对平稳随机信号的假设,也就是在声源定位的一次计算的数据中,声源的位置和强度不能发生较大的改变,否则将破坏平稳信号假设。而变压器属于较为稳定的设备,声源位置相对固定,考虑到变压器负载也不会发生较大的变化,故而强度也相对固定,可以满足计算时延所需的基本假设。
假设X(t)与Y(t)为广义平稳随机的离散信源,数学期望不随时间改变,其自相关函数为:
R
互相关函数为:
R
当相关函数取到最大值时,其时间偏移量就是在此方法下最优估计的信号时延:
τ=ΔTargmaxR
但是此方法的计算量相对较大,需要对信号进行时间尺度上的反复平移和计算,故而互功率谱法的提出,将时域上的卷积运算转化为了频域的乘积过程。此方法的有效性由维纳-辛钦定理(Wiener-Khinchin)定理保障,PSD与互相关函数之间的关系为:
/>
除此之外,还有广义互相关法,采用了频域滤波器对相关函数进行处理,理论研究表明最佳滤波器H为信号自功率谱的倒数:
波束形成理论是声源定位的有效方式,通过上述过程计算声场模型和时延求和后,即可得到对声场中的声源估计结果。
噪声分离技术,是在各个场景下均十分有效的信号处理手段。在声源定位的计算过程中,涉及到大量的矩阵运算,利用矩阵的性质,可以对信号子空间和噪声子空间进行分解,通过噪声子空间的正交矢量,估计声源方向,最终达到降低无关噪音的效果。
噪声空间分离问题描述如图8所示,其中麦克风处的声源波动方程为:
故而,第m个麦克风处,所有声源的波动叠加可以表示为:
由几何关系可知,理论时延可由下式得到:
将方程中人为引进噪音项后,可将麦克风阵列的波动方程使用矩阵形式进行表达,其中最后一项为引入的噪声项:
在这里可以使用简洁的矩阵形式进行表达:
X(n)=AS(n)+V(n)
其中X为麦克风接收到的振动数据,A为导向向量,S为声源波动模型,V为噪声。
X为观测数据,内含有场景中的其他噪声,应当假设,各个麦克风阵元的噪声相互独立且满足一个方差为
R=E[X(n)X
通过理论推导:
其中:
R
对R进行特征值分解,并依据特征值分解性质进行计算:
R=UΛU
UU
在这里U为特征向量构成的酉矩阵,具有正交性质。Λ为矩阵特征值构成的对角矩阵。根据特征值对角阵的性质,将协方差矩阵代入:
由于Rs是一个K维矩阵,最多只有K个特征值,当麦克风数量M超过K时,矩阵并非一个满秩矩阵,后面的对角元素必然为零,在引入了噪声顶之后,特征值矩阵的表达形式转变为:
基于噪声空间的强度小于待监测声源的基本假设,在对角阵中的对角元素产生值跳跃,由此即可判定在特征值矩阵中的信号源成分和噪声成分。
而后利用分块矩阵的性质即将场景中的耦合声源分解为了信号子空间和噪音子空间。通过对城市变电站噪音的进一步研究,还可以对信号的分布进行进一步建模,进一步提升噪音子空间的分解精确度。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。