一种基于OpenCL实现时序数据延迟压缩的方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及数据处理技术领域,具体的说是一种基于OpenCL实现时序数据延迟压缩的方法。
背景技术
随着物联网技术的发展,越来越多的物(设备或传感器等)相互连接起来,从而产生了大量的时序数据,时间序列数据是指是一段时间内某个特定指标量的一系列数值数据点,通过指标和标签以及时间戳来唯一标识一个指标量,这些指标数据具有不可变性。
OpenCL(全称Open Computing Language,开放运算语言)是第一个面向异构系统通用目的并行编程的开放式、免费标准,也是一个统一的编程环境,便于软件开发人员为高性能计算服务器、桌面计算系统、手持设备编写高效轻便的代码,而且广泛适用于多核心处理器(英文全称Central Processing Unit/Processor,英文简称CPU)、图形处理器(英文全称Graphics Processing Unit,英文简称GPU)、Cell类型架构以及数字信号处理器(DSP)等其他并行处理器,在游戏、娱乐、科研、医疗等各种领域都有广阔的发展前景。
Redis作为一个灵活的高性能key-value数据结构存储,可以用来作为数据库、缓存和消息队列。Redis提供了基于RedisTimeSeries模块保存时间序列数据的方案。RedisTimeseries内存时序数据库采用CPU单线程实现时序数据的存储和压缩,压缩过程中涉及大量运算占用了较多的CPU资源,影响了时序数据的入库效率,然而GPU此时处于空闲状态。
基于此,为达到提升海量时序数据入库效率、降低边缘存储成本需求和边缘计算快速实时响应的目标,设计实现一种利用空闲GPU资源基于OpenCL技术将存储于RedisTimeSeries数据库中未压缩的时序数据延迟压缩的策略。
发明内容
本发明针对目前技术发展的需求和不足之处,提供一种基于OpenCL实现时序数据延迟压缩的方法,来降低数据库进程的CPU和内存空间的占用率。
本发明的一种基于OpenCL实现时序数据延迟压缩的方法,解决上述技术问题采用的技术方案如下:
一种基于OpenCL实现时序数据延迟压缩的方法,包括如下步骤:
S1、设计CLSeries结构体、CLLazyBuffer结构体、CLUncompressedChunk结构体、CLCompressedChunk结构体,作为时序数据异构延迟压缩数据的存储容器和辅助工具,将cl_uncompressed_chunk定义为CLUncompressedChunk具体实例对象,将cl_compressed_chunk定义为CLCompressedChunk具体实例对象;
S2、执行RedisModule_Onload函数,在RedisModule_Onload函数中通过RedisModule_SubscribeToServer函数以回调函数的方式来注册事件处理器EvtTsChunkHandler;
定义REDISMODULE_EVENT_TS_CHUNK类型事件,通过Redis Module的API增加RedisModule_FireServerEvent函数来发送定义的事件;
事件处理器EvtTsChunkHandler根据不同的事件类型和延迟压缩策略中的控制参数驱动是否协调GPU执行实现了压缩算法的内核程序;
S3、定义CPU和GPU异构处理器共享内存区域的内存管理器CLMemoryManager,来为CLUncompressedChunk结构体和CLCompressedChunk结构体申请和回收内存空间,该空间为CPU与GPU的共享内存空间;
CLSeries结构体中的前缀基数树完全由CPU来管理,CPU调用OpenCL标准的CLEnqueueMapBuffer函数将上述申请的共享内存空间映射为CLSeries结构体中间接引用cl_uncompressed_chunk和cl_compressed_chunk的指针;
S4、CPU处理器响应客户端写入时序数据请求为cl_uncompressed_chunk填充时序数据时,事件处理器EvtTsChunkHandler接收到REDISMODULE_EVENT_TS_CHUNK事件,触发延迟压缩策略,随后GPU处理器会将cl_uncompressed_chunk中的填充数据压缩并填充到cl_compressed_chunk中,最后,CPU处理器用cl_compressed_chunk的压缩数据(即节点6)替换基数树中与CLUncompressedChunk结构体相一致的未压缩填充数据。
可选的,执行步骤S1,设计的CLSeries结构体定义了lazy_comp_flag标识和lazy_buffer指针,还定义了NewSeries、AddSample、SeriesTrim三种函数,其中,lazy_comp_flag标识用于定义时序数据序列是否采用延迟压缩策略;
lazy_buffer指针引用CLLazyBuffer结构体;
CLLazyBuffer结构体中定义了指向CLUncompressedChunk结构体和CLCompressedChunk结构体的共享内存空间的指针,还定义了CLLazyCompress函数,CLLazyCompress函数定义了延迟压缩策略;
CLUncompressedChunk结构体用于存储未压缩的数据块;
CLCompressedChunk结构体用于存储压缩的数据块。
进一步可选的,CLLazyCompress函数定义的延迟压缩策略为:
当cl_uncompressed_chunk的size大于等于”capacity*compress_factor”阈值时,调用OpenCL标准定义的clEnqueueTask函数执行内核将CLUncompressedChunk结构体中时序数据压缩后存储到cl_compressed_chunk的内存空间中。
进一步可选的,CLUncompressedChunk结构体用于存储未压缩的数据块,其具体定义了基准时间戳、样本、样本个数、样本大小。
进一步可选的,CLCompressedChunk结构体用于存储压缩的数据块,其具体定义了大小、个数、标识、基准值、基准时间戳、数据。
可选的,执行步骤S2,定义的REDISMODULE_EVENT_TS_CHUNK事件类型包括如下三种:
REDISMODULE_SUBEVENT_TS_CHUNK_NEW,
REDISMODULE_SUBEVENT_TS_CHUNK_SPLIT,
REDISMODULE_SUBEVENT_TS_CHUNK_DEL;
REDISMODULE_EVENT_TS_CHUNK事件关联的数据即CLSeries结构体的NewSeries、AddSample、SeriesTrim三种函数,其中,
NewSeries函数和AddSample函数对NewChunk函数的调用会触发新建事件,
AddSample函数对SplitChunk函数的调用会触发拆分事件,
SeriesTrim函数对FreeChunk函数的调用会触发删除事件。
可选的,执行步骤S3,内存管理器CLMemoryManager包括如下相关函数:
RedisModule_CL_Alloc:通过OpenCL标准定义的clCreateBuffer函数通过传递设置为“CL_MEM_ALLOC_HOST_PTR”的参数申请指定大小的内存空间;
RedisModule_CL_Free:通过OpenCL标准定义的clReleaseMemObject函数释放内存;
RedisModule_CL_Calloc:与RedisModule_CL_Alloc同样的操作申请内存空间,并对空间逐一进行初始化设置值为0;
RedisModule_CL_Realloc:通过OpenCL标准定义的clCreateBuffer函数通过传递设置为“CL_MEM_ALLOC_HOST_PTR”的参数,并基于指定的地址作为起始地址,申请指定大小的内存空间,即基于起始地址扩展内存空间;
RM_CL_MallocUsableSize:计算通过OpenCL标准申请内存空间中已使用空间大小。
可选的,执行步骤S4,设计实现数据块回收策略,
回收cl_uncompressed_chunk中已经被压缩的数据块,并基于cl_uncompressed_chunk中未压缩数据块的地址申请capacity大小的内存空间,以便继续存储客户端写入的时序数据;
回收cl_compressed_chunk中除最后一个压缩数据块之外的数据块,基于最后一个压缩数据块的地址申请capacity大小的内存空间,以便存储下次压缩后的时序数据;
这一过程中,调用OpenCL的clEnqueueUnmapMemObject函数解除已经回收的共享内存空间的映射。
本发明的一种基于OpenCL实现时序数据延迟压缩的方法,与现有技术相比具有的有益效果是:
(1)本发明利用空闲GPU资源将存储于RedisTimeSeries数据库中未压缩的时序数据延迟压缩,可以降低数据库进程的CPU和内存空间的占用率,提升海量时序数据入库效率,降低边缘存储成本和满足边缘计算快速实时响应的需求;
(2)本发明基于OpenCL标准技术,充分利用边缘端空闲GPU处理器实现的压缩算法内核,与CPU处理器通过共享内存存储空间的方式协同处理,延迟压缩策略,提高GPU处理器并发压缩数据时的吞吐量,尤其在物联网应用场景中,可降低边缘设备的存储和硬件成本。
附图说明
附图1是本发明中所提及RedisTimeseries核心数据结构示意图;
附图2是本发明中RedisTimeseries核心数据结构示意图;
附图3是本发明中CPU/GPU共享全局内存协同处理示意图;
附图4是本发明中延迟压缩和解压缩相关结构体类图;
附图5是本发明实施例一所涉及CPU/GPU协同工作延迟压缩流程示意图。
具体实施方式
为使本发明的技术方案、解决的技术问题和技术效果更加清楚明白,以下结合具体实施例,对本发明的技术方案进行清楚、完整的描述。
针对实施例中英文单词进行如下解释:(请对此进行对应的中文解释)
CLUncompressedChunk与cl_uncompressed_chunk表述含义一致,都表示使用OpenCL尚未压缩的内存数据块,cl_uncompressed_chunk定义为
CLUncompressedChunk具体实例对象。
CLCompressedChunk与cl_compressed_chunk表述含义一致,都表示使用OpenCL已经压缩的内存数据块,cl_compressed_chunk定义为CLCompressedChunk具体实例对象。
capacity*compress_factor表示内存容量*压缩因子,用来定义触发压缩事件的内存大小阈值。
REDISMODULE_SUBEVENT_TS_CHUNK:时序内存数据块事件类型。
REDISMODULE_SUBEVENT_TS_CHUNK_NEW:时序内存数据块新建事件。
REDISMODULE_SUBEVENT_TS_CHUNK_SPLIT:时序内存数据块拆分事件。
REDISMODULE_SUBEVENT_TS_CHUNK_DEL:时序内存数据块删除事件。
实施例一:
本实施例提出一种基于OpenCL实现时序数据延迟压缩的方法,包括如下步骤:
S1、设计CLSeries结构体、CLLazyBuffer结构体、CLUncompressedChunk结构体、CLCompressedChunk结构体,作为时序数据异构延迟压缩数据的存储容器和辅助工具。
众所周知,Redis是典型的支持键值对数据模型的内存数据库,如附图1所示,RedisTimeseries的主要数据结构:在quicklistEntry结构体中的node指针指向存储了键的quicklistNode结构体,而value指针指向存储了值的Series结构体;在Series结构体中采用前缀基数树结构来存储时序数据库块(Chunk_t列表),其中将时间戳作为字典项存储在前缀基数树中,指针指向对应的时序数据数据块;在该图中以未压缩的数据块为例,basetimestamp为该数据库中的最小时间戳值即前述基数树中的字典项,samples列表中的每项指针则指向时间序列数据Sample(时间戳和值)。在RedisTimeseries的Series、UncompressedChunk、CompressedChunk的基础上,执行步骤S1,设计了CLSeries结构体、CLLazyBuffer结构体、CLUncompressedChunk结构体、CLCompressedChunk结构体。
如附图4所示,设计的CLSeries结构体定义了lazy_comp_flag标识和lazy_buffer指针,还定义了NewSeries、AddSample、SeriesTrim三种函数,其中,lazy_comp_flag标识用于定义时序数据序列是否采用延迟压缩策略;
lazy_buffer指针引用CLLazyBuffer结构体;
CLLazyBuffer结构体中定义了指向CLUncompressedChunk结构体和CLCompressedChunk结构体的共享内存空间的指针,还定义了CLLazyCompress函数,CLLazyCompress函数定义了延迟压缩策略:当cl_uncompressed_chunk的size大于等于”capacity*compress_factor”阈值时,调用OpenCL标准定义的clEnqueueTask函数执行内核将CLUncompressedChunk结构体中时序数据压缩后存储到cl_compressed_chunk的内存空间中;
CLUncompressedChunk结构体定义了基准时间戳、样本、样本个数、样本大小,用于存储未压缩的数据块;
CLCompressedChunk结构体定义了大小、个数、标识、基准值、基准时间戳、数据,用于存储压缩的数据块。
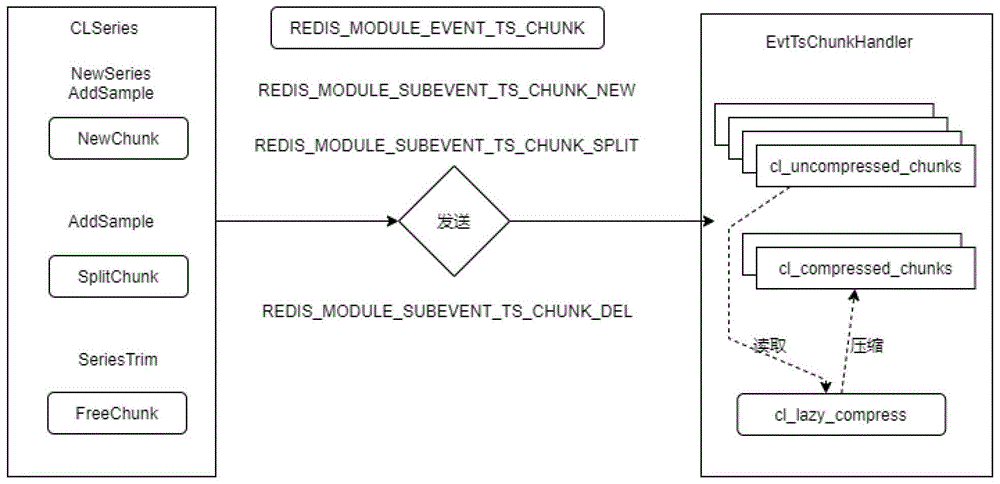
S2、执行RedisModule_Onload函数,在RedisModule_Onload函数中通过RedisModule_SubscribeToServer函数以回调函数的方式来注册事件处理器EvtTsChunkHandler,如附图2所示;
定义REDISMODULE_EVENT_TS_CHUNK类型事件,通过Redis Module的API增加RedisModule_FireServerEvent函数来发送定义的事件;
事件处理器EvtTsChunkHandler根据不同的事件类型和延迟压缩策略中的控制参数驱动是否协调GPU执行实现了压缩算法的内核程序。
所涉及步骤S2定义的REDISMODULE_EVENT_TS_CHUNK事件类型包括如下三种:
REDISMODULE_SUBEVENT_TS_CHUNK_NEW,即新建事件;
REDISMODULE_SUBEVENT_TS_CHUNK_SPLIT,即拆分事件;
REDISMODULE_SUBEVENT_TS_CHUNK_DEL,即删除事件;
REDISMODULE_EVENT_TS_CHUNK事件关联的数据即CLSeries结构体的NewSeries、AddSample、SeriesTrim三种函数,其中,
NewSeries函数和AddSample函数对NewChunk函数的调用会触发新建事件,
AddSample函数对SplitChunk函数的调用会触发拆分事件,
SeriesTrim函数对FreeChunk函数的调用会触发删除事件。
S3、定义CPU和GPU异构处理器共享内存区域的内存管理器CLMemoryManager,来为CLUncompressedChunk结构体和CLCompressedChunk结构体申请和回收内存空间,该空间为CPU与GPU的共享内存空间;
如附图3所示,CLSeries结构体中的前缀基数树完全由CPU来管理,CPU调用OpenCL标准的CLEnqueueMapBuffer函数将上述申请的共享内存空间映射为CLSeries结构体中间接引用cl_uncompressed_chunk和cl_compressed_chunk的指针。
内存管理器CLMemoryManager包括如下相关函数:
RedisModule_CL_Alloc:通过OpenCL标准定义的clCreateBuffer函数通过传递设置为“CL_MEM_ALLOC_HOST_PTR”的参数申请指定大小的内存空间,该参数指明从主机内存中分配内存空间;
RedisModule_CL_Free:通过OpenCL标准定义的clReleaseMemObject函数释放内存;
RedisModule_CL_Calloc:与RedisModule_CL_Alloc同样的操作申请内存空间,并对空间逐一进行初始化设置值为0;
RedisModule_CL_Realloc:通过OpenCL标准定义的clCreateBuffer函数通过传递设置为“CL_MEM_ALLOC_HOST_PTR”的参数,并基于指定的地址作为起始地址,申请指定大小的内存空间,即基于起始地址扩展内存空间;
RM_CL_MallocUsableSize:计算通过OpenCL标准申请内存空间中已使用空间大小。
S4、如附图5所示,基数树“标准圆”节点如1,2,3,4,5是压缩后的节点,“非标准圆”节点如6,7,8是未压缩的节点。处理流程描述如下:
CPU处理器响应客户端写入时序数据请求为cl_uncompressed_chunk填充时序数据时,事件处理器EvtTsChunkHandler接收到REDISMODULE_EVENT_TS_CHUNK事件,触发延迟压缩策略,随后GPU处理器会将cl_uncompressed_chunk中的填充数据(图5左侧CLSeries结构体的节点6,7)压缩并填充到cl_compressed_chunk中(即节点6),最后,CPU处理器用cl_compressed_chunk的压缩数据(即节点6)替换基数树中与CLUncompressedChunk结构体相一致的未压缩填充数据(图5左侧CLSeries结构体的节点6,7)。
执行步骤S4,设计实现数据块回收策略,
回收cl_uncompressed_chunk中已经被压缩的数据块,并基于cl_uncompressed_chunk中未压缩数据块(图5中cl_compressed_chunk中的节点8)的地址申请capacity大小的内存空间,以便继续存储客户端写入的时序数据;
回收cl_compressed_chunk中除最后一个压缩数据块之外的数据块(图5中cl_compressed_chunk中节点6之外的数据块),基于最后一个压缩数据块(图5右侧CLSeries结构体的节点6)的地址申请capacity大小的内存空间,以便存储下次压缩后的时序数据;
这一过程中,调用OpenCL的clEnqueueUnmapMemObject函数解除已经回收的共享内存空间的映射。
根据多次压缩结果计算出压缩率,不断调整优化compress_factor参数的值,以达到GPU最优的吞吐量和内存空间最优的利用率。
综上可知,采用本发明的一种基于OpenCL实现时序数据延迟压缩的方法,利用空闲GPU资源将存储于RedisTimeSeries数据库中未压缩的时序数据延迟压缩,可以降低数据库进程的CPU和内存空间的占用率。
以上应用具体个例对本发明的原理及实施方式进行了详细阐述,这些实施例只是用于帮助理解本发明的核心技术内容。基于本发明的上述具体实施例,本技术领域的技术人员在不脱离本发明原理的前提下,对本发明所作出的任何改进和修饰,皆应落入本发明的专利保护范围。
- 基于延迟嵌入分析的建筑动态时序数据重构方法及系统
- 一种基于关系型数据库的工业数采时序数据压缩存储和解压查询方法