一种知识图谱压缩存储改进优化算法
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及知识图谱相关领域,具体为一种知识图谱压缩存储改进优化算法。
背景技术
知识图谱:是通过将应用数学、图形学、信息可视化技术、信息科学等学科的理论与方法与计量学引文分析、共现分析等方法结合,并利用可视化的图谱形象地展示学科的核心结构、发展历史、前沿领域以及整体知识架构达到多学科融合目的的现代理论。
稀疏矩阵:在矩阵中,若数值为0的元素数目远远多于非0元素的数目,并且非0元素分布没有规律时,则称该矩阵为稀疏矩阵;与之相反,若非0元素数目占大多数时,则称该矩阵为稠密矩阵。定义非零元素的总数比上矩阵所有元素的总数为矩阵的稠密度。
布鲁姆过滤器:布鲁姆过滤器是一种特殊的哈希表,这个哈希表中的每一个槽只存储0或1,所以可以使用计算机中的最小单位bit来存储每一个01以达到空间的极大节省。在数据集非常大的条件下进行某个数据对象A的查找即使是利用哈希表仍然会有很大的开销,尤其是当要在多个独立分布的数据集中查找的时候开销更加明显。
RLE压缩技术:RLE压缩算法的基本思路是把数据按照线性序列分成两种情况:一种是连续的重复数据块,另一种是连续的不重复数据块。
RLE算法的原理就是用一个表示块数的属性加上一个数据块代表原来连续的若干块数据,从而达到节省存储空间的目的。一般RLE算法都选择数据块的长度为1字节,表示块数的诚性也用1字节表示,对于颜色数小于256色的图像文件或文本文件,块长度选择1字节是比较合适的。
二元组排序技术:二元元组组按照第一个元素从小到大排序,若第一个相同第二个按照从大到小排序,二元元组被数学家们用来描述确定成分的数学对象。
k2-triples:k2-triples是一种专门针对共享属性的元组设计的元组压缩存储方式,其基本思想是建立在k2-tree基础上的。k2-triples利用一个位矩阵存储具有相同属性元组,其中位矩阵的行和列分别对应元组的主语和宾语当位矩阵中任意位所对应的主语和宾语存在时,将其设置为1,否则设为0。
发明内容
本发明的目的在于提供一种知识图谱压缩存储改进优化算法,以知识图谱数据经过二次压缩后,提高压缩存储后的数据的检索效率,将位串中代表1的位块提取出来,并与其下标构成一个二元组,通过二元组数组的排序,将大量连续的代表1的位块优先检索,从而大道提高检索速度的目的,其中稀疏矩阵经过二次RLE压缩后,已经将连续的0或者1压缩成一位数,那么压缩后的位穿两个相邻的位代表的一定是不同的二进制位。这时候我们只需要将二进制位为1的数位和对应的下标记录下来,就可以准确地找到稀疏矩阵中的有效数据,同时数位的数值越大,代表连续的1就越多,优先对这些连续的1检索查询。
为实现上述目的,本发明提供如下技术方案:一种知识图谱压缩存储改进优化算法,包括,包括以下步骤:
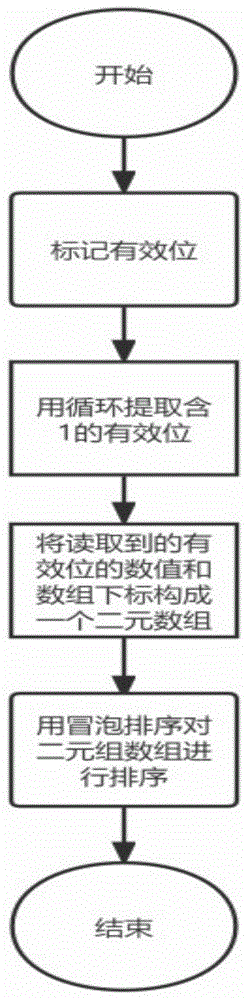
步骤S1、在k2-tree树进行二级压缩后得到一个位串,位串里的每一个数字都代表了二进制位0和1的频数;
步骤S2、根据首位标识符判断哪些位块包含“1”这个二进制位;
步骤S3、对步骤S2中判断得出的有效数位的数值和数组下标构成一个二元组数组,二元组的第一个元素就是该位块有多少个连续的“1”,二元组的第二个元素就是该位块在二次压缩后的位串中的下标;
步骤S4、以步骤S3中每个二元组数据的第一个元素从大到小进行排序,得到的二元组数组越靠前的元素,连续含有的1二进制位越多;
步骤S5、当读取数据时候,首先读取二元组数组中每个元素的第二个数,该数就是二次压缩后位串对应的下标,然后利用该下标访问位串;
步骤S6、当需要查询数据的时候,对排序后的二元组数组依次检索,越靠前的数组元素代表二次压缩后位串中越多的“1”二进制位,所包含的信息量也就越大。
优选的,所述步骤S1中位串的格式为:[首位标识符]+二进制位的频数,例如[1]21 1 1 2 1 1 2 1 1 1 1 1 2 2 2 2 2 1 3 1 4 1 2 1 1,在这个位串中,[1]表示二进制字符串从1开始,0和1位块交替排列因此第0位上的2就表示2个1,第一位上的1表示一个0,第二位上的一表示一个1,第三位上的1表示一个0,第四位上的2表示2个1,依次类推,1代表的是矩阵中任意位所对应的主语和宾语存在,反之则为0。
优选的,所述步骤S2中根据首位标识符判断哪些位块包含“1”这个二进制位具体为:
首先,根据步骤S1中的首位标识符,找出所有含1的位块,由于二次压缩后的位串中,第一位为标识位,然后要对第一位进行判断,标识位为1则表示位串有效位是从1开始的;标识位为0,则表示位串是从0开始的,其中如果判断出第一位为1,则读取偶数位,因为下标是从0开始的,如果判断出第一位为0,则读取奇数位。
优选的,所述步骤S3中二元组的格式如下:args{{data,index}},其中,data为位串中的数据,index为位串的下标,使用二元组存储数据既存储目标对象,又存储该对象在原字符串中的位置;将所有含有1的位块数值和在二次压缩后的位串中的下标构成二元数组,第一个元素为数值,第二个元素为下标。
优选的,所述步骤S4中使用冒泡排序对每个二元组数据的第一个元素从大到小进行排列,具体冒泡排序为:
For(int i=0;i IF args[i][1] Swap(args[i],args[i+1]) End。 与现有技术相比,本发明的有益效果是:本发明通过在k2-tree树进行二级压缩后,对子矩阵进行数据块大小的优先级排序,当检索数据时,根据优先级检索,这样排在前面的块均为主语和宾语同时存在,可以提高数据读取效率,该方法也可应用于电商领域的个性化排序,能够针对用户偏好将用户最想要的排在前面优先检索到。 附图说明 图1为本发明的二次压缩后存储查询的优化算法流程示意图; 图2为本发明的数据读取流程示意图; 图3为本发明再电商用户查询领域的实际应用流程示意图。 具体实施方式 下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。 请参阅图1-3,本发明提供一种技术方案:一种知识图谱压缩存储改进优化算法,包括,包括以下步骤: 步骤S1、在k2-tree树进行二级压缩后得到一个位串,位串里的每一个数字都代表了二进制位0和1的频数; 步骤S2、根据首位标识符判断哪些位块包含“1”这个二进制位; 步骤S3、对步骤S2中判断得出的有效数位的数值和数组下标构成一个二元组数组,二元组的第一个元素就是该位块有多少个连续的“1”,二元组的第二个元素就是该位块在二次压缩后的位串中的下标; 步骤S4、以步骤S3中每个二元组数据的第一个元素从大到小进行排序,得到的二元组数组越靠前的元素,连续含有的1二进制位越多; 步骤S5、当读取数据时候,首先读取二元组数组中每个元素的第二个数,该数就是二次压缩后位串对应的下标,然后利用该下标访问位串; 步骤S6、当需要查询数据的时候,对排序后的二元组数组依次检索,越靠前的数组元素代表二次压缩后位串中越多的“1”二进制位,所包含的信息量也就越大。 进一步的,步骤S1中位串的格式为:[首位标识符]+二进制位的频数,例如[1]2 11 1 2 1 1 2 1 1 1 1 1 2 2 2 2 2 1 3 1 4 1 2 1 1,在这个位串中,[1]表示二进制字符串从1开始,0和1位块交替排列因此第0位上的2就表示2个1,第一位上的1表示一个0,第二位上的一表示一个1,第三位上的1表示一个0,第四位上的2表示2个1,依次类推,1代表的是矩阵中任意位所对应的主语和宾语存在,反之则为0。 进一步的,步骤S2中根据首位标识符判断哪些位块包含“1”这个二进制位具体为: 首先,根据步骤S1中的首位标识符,找出所有含1的位块,由于二次压缩后的位串中,第一位为标识位,然后要对第一位进行判断,标识位为1则表示位串有效位是从1开始的;标识位为0,则表示位串是从0开始的,其中如果判断出第一位为1,则读取偶数位,因为下标是从0开始的,如果判断出第一位为0,则读取奇数位 进一步的,步骤S3中二元组的格式如下:args{{data,index}},其中,data为位串中的数据,index为位串的下标,使用二元组存储数据既存储目标对象,又存储该对象在原字符串中的位置;将所有含有1的位块数值和在二次压缩后的位串中的下标构成二元数组,第一个元素为数值,第二个元素为下标 进一步的,所述步骤S4中使用冒泡排序对每个二元组数据的第一个元素从大到小进行排列,具体冒泡排序为: For(int i=0;i IF args[i][1] Swap(args[i],args[i+1]) End。 具体的,本知识图谱压缩存储改进优化算法可用于其可用于电商领域的用户偏好检索服务,个性化之前的搜索对于同一个查询,不同用户看到的结果是完全相同的,这可能并不符合所有用户的需求。在商品搜索中,这个问题尤为特出,因为商品搜索的用户可能特别青睐某些品牌、价格、店铺的商品,为了减少用户的筛选成本,需要对搜索结果按照用户进行个性化展示,个性化的第一步是对用户和商品分别建模,第二步是将模型服务化,有了这两步之后,上述的步骤是现有的技术,故在此不进行赘述;在用户进行查询时,借用merger服务模型同时调用用户模型服务和在线检索服务,用户模型服务返回用户维度特征,在线检索服务返回商品信息,排序模块运用这两部分数据对结果进行重排序,根据提取到的用户维度特征就可以对不同类型的商品赋予不同的权重,再将这些数据进行二级压缩,二级压缩之后连续的1越多就代表该商品用户偏爱的程度越高所占权重也越大,如果是0就表示用户对于这一类商品毫无兴趣,二级压缩后的数据就可以根据本文中设计的优化算法对其排序,这样含连续1较多的数据块就排在了前面,也就代表了用户优先可以检索到自己比较偏爱的一类商品,其中本知识图谱压缩存储改进优化算法相当于是可以用作里面的一个嵌入式的模块功能。 本发明通过在k2-tree树进行二级压缩后,对子矩阵进行数据块大小的优先级排序,当检索数据时,根据优先级检索,这样排在前面的块均为主语和宾语同时存在,可以提高数据读取效率,该方法也可应用于电商领域的个性化排序,能够针对用户偏好将用户最想要的排在前面优先检索到。 尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 一种基于改进型EmbedKGQA模型的知识图谱问答方法、电子设备及存储介质
- 一种基于RotatE改进的知识图谱表示学习方法及链接预测方法