新型的果糖-4-差向异构酶以及使用其制备塔格糖的方法
文献发布时间:2023-06-19 11:06:50
技术领域
本发明涉及一种新型的果糖-4-差向异构酶以及使用其制备塔格糖的方法。
背景技术
塔格糖是一种天然甜味剂,其少量存在于诸如牛奶、奶酪和可可等食物,以及诸如苹果和橘子的甜水果中。尽管塔格糖的热量值为1.5kcal/g,约为蔗糖的三分之一,血糖指数(Glycemic index,GI)为3,约为蔗糖的5%,但物理性质和味道类似于蔗糖,并且塔格糖具有多种有益于健康的功能。因此,塔格糖可以用作满足健康和口味的糖替代品。
可以使用半乳糖作为主要原料,并通过本领域已知或常用的方法来制备塔格糖,例如化学方法(催化反应)和生物方法(异构化酶反应)(国际专利公开号WO2006/058092,以及韩国专利号10-0964091和10-1368731)。然而,在传统生产方法中,使用半乳糖作为塔格糖的主要成分,由于用作半乳糖原料的乳糖的价格根据原料奶和乳糖的产量、需求和供应而波动,因而难以稳定地供应乳糖。因此,需要开发使用普通糖(蔗糖,葡萄糖,果糖等)作为原料制备塔格糖的方法。
发明内容
发明人进行了深入的研究以开发具有将果糖转化为塔格糖的活性的酶,结果发现塔格糖-二磷酸醛缩酶(tagatose-bisphosphate aldolase)具有将果糖转化为塔格糖的果糖-4-差向异构酶活性,从而完成本发明。
技术方案
本发明的一个目的是提供一种用于制备塔格糖的组合物,其包含塔格糖-二磷酸醛缩酶、表达所述塔格糖-二磷酸醛缩酶的微生物和所述微生物的培养物中的至少一种。
本发明的另一个目的是提供一种微生物,其包含塔格糖-二磷酸醛缩酶、编码所述塔格糖-二磷酸醛缩酶的多核苷酸和包含所述多核苷酸的表达载体中的至少一种。
本发明的又一个目的是提供一种制备塔格糖的方法,其包括通过使所述组合物与果糖接触,以将果糖转化为塔格糖。
本发明的又一个目的是提供塔格糖-二磷酸醛缩酶用作果糖-4-差向异构酶的用途。
有益效果
根据本发明,塔格糖-二磷酸醛缩酶为果糖-4-差向异构酶,具有优异的耐热性,可以工业化规模制备塔格糖,并将普通糖果糖转化为塔格糖,因此在经济上是可行的。
附图说明
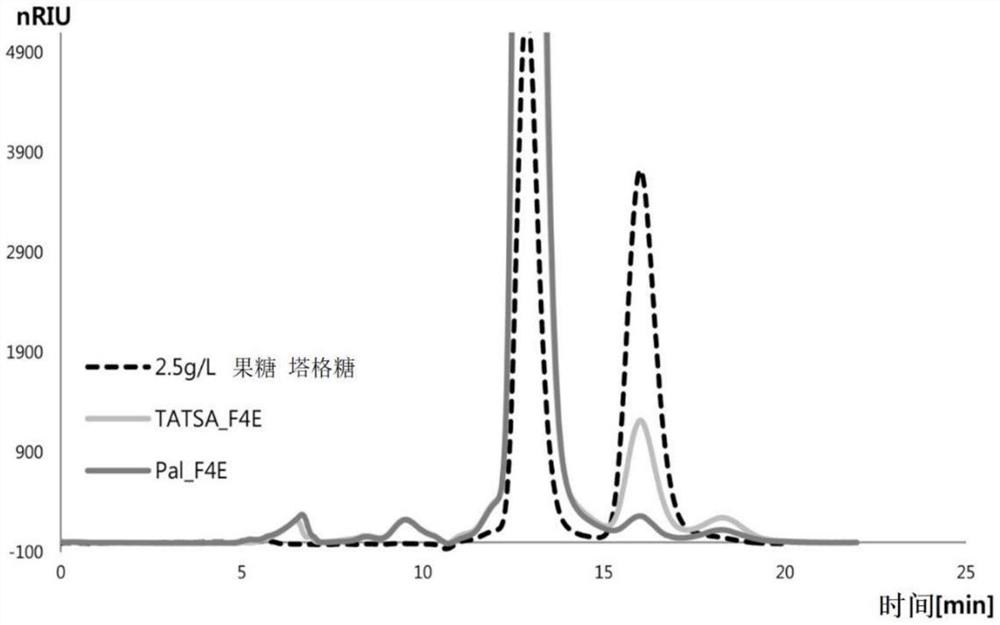
图1是高效液相色谱(HPLC)图,示出塔格糖-二磷酸醛缩酶CJ_TATSA_F4E和CJ_Pal_F4E的果糖-4-差向异构酶活性。
图2A为示出随着温度变化,塔格糖-二磷酸醛缩醛酶CJ_TATSA_F4E的果糖-4-差向异构酶的活性的图表。
图2B为示出随着温度变化,塔格糖-二磷酸醛缩醛酶CJ_Pal_F4E的果糖-4-差向异构酶的活性的图表。
具体实施方式
在下文中,将详细描述本发明。同时,本发明中公开的每个描述和实施方案可以在本文中应用以描述不同的描述和实施方案。即,本发明中公开的各种组分的所有组合都包括在本发明的范围内。此外,本发明的范围不受限于以下具体描述。
本领域技术人员仅使用常规实验就将认识到或能够确定本发明的具体实施方案的许多等同物。本发明的范围意图涵盖这些等同物。
在一方面,为实现上述目的,本发明提供一种用于制备塔格糖的组合物,其包含塔格糖-二磷酸醛缩酶、表达所述塔格糖-二磷酸醛缩酶的微生物和所述微生物的培养物中的至少一种。
本发明的特征在于所述塔格糖-二磷酸醛缩酶具有果糖-4-差向异构酶活性。
果糖-4-差向异构酶或其变体具有将D-果糖在第4碳位置差向异构化转化为D-塔格糖的特征。果糖-4-差向异构酶具有塔格糖-二磷酸醛缩酶活性,并以D-塔格糖1,6-二磷酸(D-tagatose 1,6-bisphosphate)为底物,产生磷酸甘油酮(glycerone phosphate)和D-甘油醛3-磷酸(D-glyceraldehyde3-phosphate)。
同时,如下述反应式1所示,虽然有报道塔格糖-二磷酸醛缩酶(EC4.1.2.40)以D-塔格糖1,6-二磷酸为底物,产生磷酸甘油酮和D-甘油醛3-磷酸,并参与半乳糖代谢,但并无塔格糖-二磷酸醛缩酶是否具有产生塔格糖的活性的研究。
反应式1
发明人发现塔格糖-二磷酸醛缩酶具有果糖-4-差向异构酶活性。因此,根据本发明的一个实施方案,本发明提供了塔格糖-二磷酸醛缩酶的新用途,由果糖制备塔格糖时,将塔格糖-二磷酸醛缩酶用作果糖-4-差向异构酶。另外,根据本发明的另一个实施方案,本发明提供了一种将塔格糖-二磷酸醛缩酶用作果糖-4-差向异构酶,由果糖制备塔格糖的方法。
在本发明中,任何能够以果糖作为底物产生塔格糖的塔格糖-二磷酸醛缩酶均可以使用,而没有限制。特别地,塔格糖-二磷酸醛缩酶将作为底物的果糖转化为塔格糖的转化率(转化率=塔格糖重量/初始果糖重量x100)可以为0.01%或更高,特别地,0.1%或更高,优选0.3%或更高。更特别地,转化率可以为0.01%至40%,0.1%至30%,0.3%至25%,或0.3%至20%。
根据一个实施方案,本发明的塔格糖-二磷酸醛缩酶可以为具有优异的耐热性的酶。特别地,本发明的塔格糖-二磷酸醛缩酶可以在30℃至70℃的温度下表现出其最大活性的50%至100%,60%至100%,70%至100%或75%至100%。更特别地,本发明的塔格糖-二磷酸醛缩酶在40℃至70℃、40℃至65℃、45℃至65℃、45℃至60℃或45℃至55℃的温度下可以表现出其最大活性的80%至100%或85%至100%。
本发明的塔格糖-二磷酸醛缩酶可以是嗜热和耐热微生物衍生的酶或其变体,例如,衍生自嗜热厌氧杆菌(Thermoanaerobacterium sp.)的酶或其变体,或衍生自假单胞菌(Pseudoalteromonas sp.)的酶或其变体,但不限于此。特别地,塔格糖-二磷酸醛缩酶可以是衍生自解热嗜热厌氧杆菌(Thermoanaerobacterium thermosaccharolyticum)或假单胞菌H103(Pseudoalteromonas sp.H103)的酶或其变体。
本发明的塔格糖-二磷酸醛缩酶可以具有与SEQ ID NO:1或3具有至少85%相同性的氨基酸序列。特别地,所述塔格糖-二磷酸醛缩酶可以是具有SEQ ID NO:1或3的氨基酸序列的多肽,或者包含与SEQ ID NO:1或3的氨基酸序列具有至少80%、90%、95%、97%或99%的同源性或相同性的多肽。另外,对于本领域技术人员显而易见的是,包括一个或多个氨基酸的缺失、修饰、取代或添加的氨基酸序列的任何多肽,也落入本发明的范围内,只要所述多肽具有保留同源性或相同性的氨基酸序列,以及与具有SEQ ID NO:1或3的氨基酸序列的蛋白相对应的功能(即果糖-4-差向异构酶活性,通过在第4碳位置将果糖差向异构化以将果糖转化为塔格糖)。另外,具有果糖-4-差向异构酶活性,并由任何已知基因序列制备的探针编码的任何多肽,例如在严格条件下与编码该多肽的核苷酸序列全部或部分互补的序列杂交的多核苷酸都可以使用,而没有限制。另外,所述组合物可以包含至少一种塔格糖-二磷酸醛缩酶,其具有与SEQ ID NO:1或3的氨基酸序列保持至少85%相同性的氨基酸序列。此外,具有SEQ ID NO:1的氨基酸序列的塔格糖-二磷酸醛缩酶可以由SEQ ID NO:2的核苷酸序列编码,具有SEQ ID NO:3的氨基酸序列的塔格糖-二磷酸醛缩酶可以由SEQ IDNO:4的核苷酸序列编码,但不限于此。
特别地,塔格糖-二磷酸醛缩酶可以具有SEQ ID NO:1或3的氨基酸序列。本发明的塔格糖-二磷酸醛缩酶可以具有SEQ ID NO:1或3的氨基酸序列或与其具有至少50%同源性或相同性的氨基酸序列,但不限于此。特别地,本发明的塔格糖-二磷酸醛缩酶可以包括多肽,其具有SEQ ID NO:1或3的氨基酸序列;或者多肽,其与SEQ ID NO:1或3的氨基酸序列具有至少60%、70%、80%、85%、90%、95%、96%、97%、98%或99%的同源性或相同性。另外,对于本领域技术人员而言显而易见的是,具有包含一个或多个氨基酸的缺失、修饰、取代或添加的氨基酸序列的任何辅助蛋白均落入本发明的范围内,只要氨基酸序列保留上述同源性或相同性,并且保留与所述蛋白等同的功能。
对于本领域技术人员显而易见的是,由于密码子简并性,任何翻译成包含SEQ IDNO:1或3的氨基酸序列的蛋白或与其具有同源性或相同性的蛋白的多核苷酸,也落入本发明的范围内。或者,任何可以根据公知基因序列制备的探针,例如可以使用在严格条件下与编码蛋白的核苷酸序列全部或部分互补的序列杂交的核苷酸序列,所述蛋白具有SEQ IDNO:1或3所示的氨基酸序列的蛋白的活性但不限于此。术语“严格条件”是指可以实现多核苷酸之间特异性杂交的条件。这些条件在文献中有具体描述(例如,J.Sambrook et al.,Molecular Cloning,A Laboratory Manual,2nd Edition,Cold Spring HarborLaboratory press,Cold Spring Harbor,New York,1989;F.M.Ausubel et al.,CurrentProtocols in Molecular Biology,John Wiley&Sons,Inc.,New York)。例如,严格的条件可以包括,具有高同源性或相同性的基因彼此杂交,同源性或相同性为80%或更高,85%或更高,特别地90%或更高,更特别地95%或更高,更特别地97%或更高,更特别地99%或更高的基因彼此杂交,而同源性或相同性低于上述同源性或相同性的基因彼此不杂交的条件;或者可以包括Southern杂交的常规清洗条件,即在60℃、1×SSC和0.1%SDS,特别地60℃、0.1×SSC和0.1%SDS,并且更特别地68℃、0.1×SSC和0.1%SDS的盐浓度和温度下,清洗一次,特别地,清洗两次或三次的条件。
另外,即使在本文公开为“包含既定SEQ ID NO:中列出的氨基酸序列的蛋白或多肽”,但对于本技术领域技术人员显而易见的是,具有包含一个或多个氨基酸缺失、修饰、取代、保守取代或添加的氨基酸序列的任何蛋白也可以用于本发明,只要所述蛋白具有与多肽同源或相同的活性,所述多肽具有本发明的氨基酸序列。例如,对于本技术领域的技术人员显而易见的是,只要蛋白与修饰后的多肽具有相同或同源的活性,就不排除具有不改变蛋白功能的序列添加、自然发生的突变或其沉默突变、或者正向或反向的保守取代的任何蛋白,并且具有这种序列添加或突变的任何蛋白也可以落入本发明的范围内。
术语“保守取代”是指一个氨基酸被具有类似结构和/或化学性质的另一氨基酸取代。这类氨基酸取代通常可以基于残基的极性、电荷、溶解性、疏水性、亲水性和/或两亲性质的相似性来进行。例如,带正电荷的(碱性)氨基酸包括精氨酸、赖氨酸和组氨酸;带负电荷的(酸性)氨基酸包括谷氨酸和天冬氨酸;芳香族氨基酸包括苯丙氨酸、色氨酸和酪氨酸;疏水性氨基酸包括丙氨酸,缬氨酸,异亮氨酸,亮氨酸,甲硫氨酸,苯丙氨酸,酪氨酸和色氨酸。
杂交需要两个多核苷酸具有互补序列,即使碱基之间可能错配,这取决于杂交的严格程度。术语“互补的”用于描述能够彼此杂交的核苷酸碱基之间的关系。例如,对于DNA,腺嘌呤与胸腺嘧啶互补,胞嘧啶与鸟嘌呤互补。因此,本发明不仅可以包括基本上相似的多核苷酸序列,还可以包括与整个序列互补的分离的多核苷酸片段。
特别地,具有同源性或相同性的多核苷酸可以使用在上述条件下的T
用于杂交多核苷酸的合适的严格程度可取决于多核苷酸的长度和互补程度,并且其参数是本领域已知的(Sambrook等,同上文,9.50-9.51,11.7-11.8)。
“同源性”或“相同性”是指两个氨基酸序列或核苷酸序列之间的相关程度,并且可以用百分比表示。术语同源性和相同性通常可以互换使用。
保守多核苷酸或多肽的序列同源性或相同性可以通过标准比对算法来确定,并且可以与所使用的程序所建立的默认空位罚分一起使用。基本上,在中等或高度严格的条件下,同源或相同的序列之间可以彼此杂交,所述杂交序列为序列全长的全部或至少约50%、60%、70%、80%或90%。在杂交的多核苷酸中,也可以考虑含有简并密码子而非密码子的多核苷酸。
可以使用本领域已知的计算机算法,例如使用默认参数的“FASTA”程序(Pearsonet al(1988)[Proc.Natl.Acad.Sci.USA 8:2444],来确定任何两个多核苷酸或多肽序列之间的同源性、相似性或相同性程度。或者,也可以通过Needleman-Wunsch算法(Needlemanand Wunsch,1970,J.Mol.Biol.48:443-453)来确定,其通过欧洲分子生物学开放软件套件(EMBOSS)软件包(Rice et al.,2000,Trends Genet.16:276-277)(version 5.0.0 orlater)的Needleman程序执行(包括GCG程序包(Devereux,J.,et al,Nucleic AcidsResearch 12:387(1984)),BLASTP,BLASTN,FASTA(Atschul,[S.][F.,][ET AL,J MOLECBIOL 215]:403(1990);Guide to Huge Computers,Martin J.Bishop,[ED.,]AcademicPress,San Diego,1994,and[CARILLO ETA/.](1988)SIAM J Applied Math 48:1073)。另外,同源性、相似性或相同性可以使用美国家生物技术信息中心(NCBI)数据库的BLAST或ClustalW确定。
多核苷酸或多肽之间的同源性、相似性或相同性可以通过使用GAP计算机程序比对序列信息来确定,例如在Smith and Waterman,Adv.Appl.Math(1981)2:482中公开的Needleman et al.(1970),J Mol Biol.48:443引入的程序。简而言之,GAP程序将相似性定义为相似的比对符号(即核苷酸或氨基酸)的数目除以两个序列中较短者的符号的数值。GAP程序的默认参数可以包括:(1)二进制数系统(其包含的数值对于相同1;对于不同为0);以及在Schwartz and Dayhoff,eds.,Atlas Of Protein Sequence And Structure,National Biomedical Research Foundation,pp.353-358(1979)(或EDNAFULL(NCBINUC4.4的EMBOSS版本)替换矩阵)中描述的Gribskov et al.(Nucl.Acids Res.14:6745(1986))的加权比较矩阵;(2)每个空位罚分是3.0,对于每个符号的每个空位另加0.10罚分(或空位开放罚分10和空位扩展罚分0.5);和(3)末端空位不罚分。因此,如本文所用,术语“同源性”或“相同性”是指序列之间的相关性。
本发明的另一方面提供了一种微生物,其包含塔格糖-二磷酸醛缩酶、编码所述塔格糖-二磷酸醛缩酶的多核苷酸和包含所述多核苷酸的表达载体中的至少一种。
如本文所用,术语“多核苷酸”具有共同包括DNA或RNA分子的含义。并且,作为多核苷酸中的基本结构单元的核苷酸不仅可以包括天然核苷酸,还可以包括糖或碱基被修饰的类似物(Scheit,Nucleotide Analogs,John Wiley,New York(1980);Uhlman and Peyman,Chemical Reviews,90:543-584(1990))。
多核苷酸可以是编码多肽的多核苷酸,所述多肽包含与本发明的SEQ ID NO:1或3具有至少85%相同性的氨基酸序列;或者可以是编码多肽的多核苷酸,所述多肽具有果糖-4-差向异构酶活性,以及与本发明的塔格糖-二磷酸醛缩酶具有至少80%、85%、90%、95%、96%、97%、98%或99%的同源性。特别地,例如,编码塔格糖-二磷酸醛缩酶的多核苷酸可以是与SEQ ID NO:2或4的核苷酸序列具有至少80%、85%、90%、95%、96%、97%、98%、99%或100%同源性或相同性的多核苷酸,所述塔格糖-二磷酸醛缩酶包含与SEQ IDNO:1或3具有至少85%相同性的氨基酸序列。此外,如上所述,显然,本发明的多核苷酸还可以包括由于密码子简并性而翻译成本发明的塔格糖-二磷酸醛缩酶的多核苷酸,以及由在严格条件下与SEQ ID NO:2或4互补的核苷酸序列组成的多核苷酸杂交的多核苷酸,并且所述塔格糖-二磷酸醛缩酶具有本发明的果糖-4-差向异构酶活性。
可用于本发明的表达塔格糖-二磷酸醛缩酶的微生物可以是这样的微生物,其包含多肽、编码所述多肽的多核苷酸和包含所述多核苷酸的重组载体中的至少一种。所述载体可以是与本发明的多核苷酸可操作连接的形式。如本文所用,术语“可操作地连接”是指为执行一般功能而将核苷酸表达调节序列与编码目标蛋白的核苷酸序列连接,并且可操作地连接可以影响编码核苷酸序列的表达。可以通过本领域已知的遗传重组技术形成与载体的可操作连接,并且可以使用本领域已知的限制酶、连接酶等进行位点特异性DNA切割和连接。
如本文所用,术语“载体”是指用于将核苷酸克隆和/或转移至生物体(例如宿主细胞)的介质。载体可以是复制子,其能够对DNA片段进行复制,所述DNA片段被另一个DNA片段结合。如本文所用,术语“复制子”是指遗传单位(例如质粒,噬菌体,粘粒,染色体和病毒),其作为体内DNA复制的自复制单元起作用,通过自调节进行复制。如本文所用,术语“载体”可以包括用于在体外、离体或体内将核苷酸引入生物体(例如宿主细胞)的病毒和非病毒介质,并且还可以包含微环DNA、转座子(如睡美人)(Izsvak et al.,J.MoI.Biol.302:93-102(2000))或人工染色体。常见载体的实例可以包括天然或重组形式的质粒、粘粒、病毒和噬菌体。例如,pWE15、M13、MBL3、MBL4、IXII、ASHII、APII、t10、t11,Charon4A和Charon21A可用作噬菌体载体或粘粒载体,基于pBR、pUC、pBluescriptII、pGEM、pTZ、pCL和pET的载体可用作质粒载体。本发明的载体没有特别限制,并且可以使用任何已知的重组载体。另外,载体可以是进一步包括各种抗生素抗性基因的重组载体。如本文所用,术语“抗生素抗性基因”是指对抗生素具有抗性的基因,并且具有该基因的细胞可以在经相应抗生素处理的环境中存活。因此,在大肠杆菌中大量生产质粒的过程中,将抗生素抗性基因有效地用作选择标记。在本发明中,抗生素抗性基因并非对本发明的核心技术(由载体的最佳组合实现的表达效率)产生较大影响的因素,因此可以无限制地将任何通常使用的抗生素抗性基因用作选择标记。例如,可以使用对氨苄青霉素、四环素、卡那霉素、氯霉素、链霉素或新霉素具有抗性的基因。
可以用于本发明的表达塔格糖-二磷酸醛缩酶的微生物可以使用将包含编码所述酶的多核苷酸的载体引入宿主细胞的方法获得。转化载体的方法可以包括任何能够将多核苷酸引入细胞的方法,并可以通过选择本领域已知的适当标准技术进行。例如,可以使用电穿孔、磷酸钙共沉淀、逆转录病毒感染、显微注射、DEAE-葡聚糖法、阳离子脂质体法和热激法,但不限于此。根据一个实施方案,表达塔格糖-二磷酸醛缩酶的微生物可以是用于产生塔格糖的微生物,其包括塔格糖-二磷酸醛缩酶,所述塔格糖-二磷酸醛缩酶包含与SEQ IDNO:1或3具有至少85%相同性的氨基酸序列或编码所述塔格糖-二磷酸醛缩酶的多核苷酸。
转化的基因可以包括插入宿主细胞的染色体的形式或位于染色体外部的形式,只要所述基因在宿主细胞中表达即可。另外,所述基因包括DNA和RNA作为编码多肽的多核苷酸,并且任何可引入宿主细胞并在宿主细胞中表达的基因都可以不受限制地使用。例如,可以以表达盒的形式将基因引入宿主细胞,所述表达盒为包含自主表达所需的所有必需元件的多核苷酸构建体。通常,表达盒可以包含与基因可操作地连接的启动子、转录终止信号、核糖体结合结构域和翻译终止信号。表达盒可以是能够自复制的重组载体的形式。另外,可以将基因本身或多核苷酸构建体形式的基因引入宿主细胞,并与在宿主细胞中表达所需的序列可操作地连接。
本发明的微生物可以包括任何原核和真核微生物,其能够产生本发明的塔格糖-二磷酸醛缩酶,并且包含本发明的多核苷酸或重组载体。微生物的实例可以包括但不限于属于埃希氏菌(Escherichia)属、欧文氏菌(Erwinia)属、沙雷氏菌(Serratia)属、普罗维登斯(Providencia)菌、棒状杆菌(Corynebacteria)属和短杆菌(Brevibacteria)属的微生物菌株,特别是,大肠杆菌(E.coli)或谷氨酸棒杆菌(Corynebacterium glutamicum)。
可以通过在培养基中培养本发明的微生物来制备本发明的微生物的培养物。
如本文所用,术语“培养”是指微生物在适当调节的环境中生长。在本发明中,可以在本领域已知的合适的培养基和培养条件下进行培养。根据所选择的微生物菌株,本领域普通技术人员可以容易地调整所述培养。微生物的培养可以通过本领域已知的分批培养、连续培养、补料分批培养等连续进行,但不限于此。特别地,至于培养条件,可以使用适当的碱性化合物(例如氢氧化钠、氢氧化钾或氨水)或酸性化合物(例如磷酸或硫酸),将pH调节到合适的pH(如pH5-9,特别地pH7-9)。另外,在培养过程中可以使用例如脂肪酸聚乙二醇酯的消泡剂来抑制泡沫的产生。此外,可以向培养物中引入氧气或含氧气体,以维持培养物的有氧条件,也可以不引入其他气体或向培养物中引入氮气、氢气或二氧化碳气体,以维持培养物的厌氧和微需氧状态。培养温度可以维持在25℃至40℃,特别地,维持在30℃至37℃,但不限于此。另外,可以持续培养直至获得所需物质的所需产量,特别地,持续约0.5小时至60小时,但不限于此。另外,作为培养基中使用的碳源,可以单独或组合使用糖和碳水化合物(例如葡萄糖、蔗糖、乳糖、果糖、麦芽糖、糖蜜、淀粉和纤维素)、油脂(例如大豆油、葵花籽油、花生油和椰子油)、脂肪酸(例如棕榈酸、硬脂酸和亚油酸)、醇(例如甘油和乙醇)和有机酸(例如乙酸),但不限于此。作为培养基中使用的氮源,可以单独或组合使用含氮有机化合物(例如蛋白胨、酵母提取物、肉汁、麦芽提取物、玉米浆、大豆粉和尿素)或无机化合物(例如硫酸铵、氯化铵、磷酸铵、碳酸铵和硝酸铵)等,但不限于此。作为培养基中使用的磷源,可以单独或组合使用磷酸二氢钾、磷酸氢二钾、其相应的含钠盐等,但不限于此。另外,培养基中可以包含金属盐(例如硫酸镁或硫酸铁)、氨基酸、维生素等必需的生长激素物质。
本发明的用于制备塔格糖的组合物可以包含其他果糖。
本发明的用于制备塔格糖的组合物包含塔格糖-二磷酸醛缩酶、表达所述塔格糖-二磷酸醛缩酶的微生物或所述微生物的培养物,其中所述塔格糖-二磷酸醛缩酶具有直接将果糖直接转化为塔格糖的果糖-4-差向异构酶活性,并且所述塔格糖-二磷酸醛缩酶或其变体可以利用果糖为底物产生塔格糖。
本发明的用于制备塔格糖的组合物可以进一步包含在用于制备塔格糖的组合物中通常使用的任何合适的赋形剂。赋形剂的实例可以是防腐剂、湿润剂、分散剂、悬浮液、缓冲溶液、稳定剂或等渗剂,但不限于此。
本发明的用于制备塔格糖的组合物可以进一步包含金属。根据本发明的一个实施方案,金属可以是具有二价阳离子的金属。特别地,本发明的金属可以是镍(Ni)、镁(Mg)或锰(Mn)。更具体地,本发明的金属可以是金属离子或金属盐。更具体地,金属盐可以是MgSO
本发明另一方面提供了一种制备塔格糖的方法,其包括通过使所述组合物与果糖接触而将果糖转化为塔格糖。
塔格糖-二磷酸醛缩酶如上所述。
根据一个实施方案,本发明的接触可以在pH 5.0至9.0,30℃至80℃的温度下进行,和/或进行0.5小时至48小时。
特别地,本发明的接触可以在6.0至9.0的pH或7.0至9.0的pH下进行。另外,本发明的接触可以在30℃至80℃、35℃至80℃、40℃至80℃、50℃至80℃、55℃至80℃、60℃至80℃、30℃至70℃、35℃至70℃、40℃至70℃、45℃至70℃、50℃至70℃、55℃至70℃、60℃至70℃、30℃至65℃、35℃至65℃、40℃至65℃、45℃至65℃、50℃至65℃、55℃至65℃、30℃至60℃、35℃至60℃、40℃至60℃、45℃至60℃、40℃至55℃或45℃至55℃的温度下进行。另外,本发明的接触可以进行0.5小时至36小时、0.5小时至24小时、0.5小时至12小时、0.5小时至6小时、1小时至48小时、1小时至36小时、1小时至24小时、1小时至12小时、1小时至6小时、3小时至48小时、3小时至36小时、3小时至24小时、3小时至12小时、3小时至6小时、6小时至48小时、6小时至36小时、6小时至24小时、6小时至12小时、12小时至48小时、12小时至36小时、12小时至24小时、18小时至48小时、18小时至36小时或18小时至30小时。
根据一个实施方案,本发明的接触可以在金属的存在下进行。可以使用的金属如上所述。
本发明的制备方法可以进一步包括分离和/或纯化制备的塔格糖。分离和/或纯化可以使用本领域通常使用的方法进行、例如但不限于,透析、沉淀、吸附、电泳、离子交换色谱和分级结晶。可以单独或组合使用这些方法来实施纯化。
另外,本发明的制备方法可以进一步包括在分离和/或纯化之前或之后,对制备的塔格糖进一步脱色和/或脱盐。通过进行脱色和/或脱盐,可以获得质量更高的塔格糖。
根据另一个实施方案,本发明的制备方法可以包括在转化、分离和/或纯化,或脱色和/或脱盐之后使塔格糖进一步结晶。塔格糖的结晶可以通过本领域常用的结晶方法来进行。例如,可以通过冷却结晶使塔格糖结晶。
根据另一个实施方案,本发明的制备方法可以进一步包括在结晶之前浓缩塔格糖。浓缩可以提高结晶效率。
根据另一个实施方案,本发明的制备方法可以进一步包括在分离和/或纯化塔格糖后,将未反应的果糖与本发明的酶、表达所述酶的微生物或所述微生物的培养物接触;在结晶塔格糖后,于分离和/或纯化中再使用已经从中分离出晶体的溶液;或其任何组合。
本发明的另一方面提供了塔格糖-二磷酸醛缩酶用作果糖-4-差向异构酶的用途。
塔格糖-二磷酸醛缩酶、同源性和相同性如上所述。
在下文中,将参考以下实施例和实验例更详细地描述本发明。然而,这些实施例和实验例仅用于示例性目的,并且本发明不意图被这些实施例和实验例所限制。
实施例1:包含塔格糖-二磷酸醛缩酶基因的重组表达载体和转化的微生物的制备
为了发现新型的热稳定的果糖-4-差向异构酶,获得类似于衍生自解热嗜热厌氧杆菌或假单胞菌H103的塔格糖-二磷酸醛缩酶的基因信息,并通过大肠杆菌(E.Coli)制备表达载体并制备转化的微生物。
特别地,从登记在京都基因与基因组百科全书(Kyoto Encyclopedia of Genesand Genomes,KEGG)和美国国家生物技术信息中心(NCBI)的解热嗜热厌氧杆菌或假单胞菌H103的基因序列中,选择与塔格糖-二磷酸醛缩酶相似的基因序列,并且基于所述两种微生物的氨基酸序列(SEQ ID NO:1和3)和核苷酸序列(SEQ ID NO:2和4)信息,利用pBT7-C-His载体(韩国Bioneer公司)制备pBT7-C-His-CJ_TATSA_F4E和pBT7-C-His-CJ_Pal_F4E的重组载体,其包含所述酶的核苷酸序列,并可在大肠杆菌中表达。
使用如上所述制备的各重组载体,通过热激转化(Sambrook and Russell:Molecular cloning,2001)来转化大肠杆菌BL21(DE3)。具体地,将1μL制备的各重组质粒载体DNA加入到1.5mL试管中,并向其中加入50μL的大肠杆菌BL21(DE3)感受态细胞(
实施例2:重组酶的制备和纯化
为了制备重组酶,将上述实施例1中制备的转化菌株(即大肠杆菌BL21(DE3)/CJ_TATSA_F4E和大肠杆菌BL21(DE3)/CJ_Pal_F4E)接种到装有5mL补充有氨苄西林作为抗生素的LB液体培养基的培养管中,然后在37℃的震荡培养箱中进行种培养,直至在600nm的吸光度达到2.0。将通过种培养获得的培养液接种在含有液体培养基的培养瓶中,该液体培养基补充有LB和作为蛋白表达调节因子的乳糖,进行主培养。种培养和主培养在180rpm的搅拌速度和37℃下进行。随后,将培养液在8000rpm和4℃下离心20分钟,并从中收集菌株。将收集的菌株用50mM Tris-HCl缓冲溶液(pH 8.0)洗涤两次,并重悬于包含10mM咪唑和300mMNaCl的50mM NaH
实施例3:自果糖转化为塔格糖以及活性鉴定
为了测量本发明在上述实施例2中制备的重组酶CJ_TATSA_F4E和CJ_Pal_F4E的果糖-4-差向异构酶活性,将50mM Tris-HCl(pH 8.0)、1mM NiSO
反应终止后,通过HPLC对果糖和产物塔格糖进行定量分析。使用Shodex SugarSP0810层析柱进行HPLC,柱温保持在80℃,以流速为1mL/min的水作为流动相(图1)。
实验结果证实,通过CJ_TATSA_F4E和CJ_Pal_F4E的酶促反应将果糖转化为塔格糖的转化率分别为9.51%和2.39%。
实施例4:根据温度鉴定重组酶的活性
为了研究温度对上述实施例2中制备的酶CJ_TATSA_F4E和CJ_Pal_F4E的果糖-4-差向异构酶活性的影响,将10mg/mL的CJ_TATSA_F4E和CJ_Pal_F4E各添加到补充有10重量%果糖的50mM Tris HCl缓冲溶液(pH 8.0)中,并使各混合物在不同的温度下反应,例如在45℃、50℃、55℃、60℃和65℃的温度下,反应10小时。反应终止后,通过HPLC对塔格糖进行定量分析。
实验结果证实,在50℃下,CJ_TATSA_F4E具有最大活性,在45℃至60℃的温度下,CJ_TATSA_F4E保持最大活性的80%或更高,并且在所有温度范围内保持最大活性的50%或更高(图2A)。另外,CJ_Pal_F4E在45℃下具有最大活性(图2B)。
本发明的以上描述是出于示例性的目的,并且本领域技术人员将理解,在不改变本发明的技术概念和基本特征的情况下,可以进行各种改变和修改。因此,显然,在所有方面,上述实施方案都是示例性的,并且不限制本发明。因此,本发明的范围并非由详细的描述所限定,而是由权利要求及其等同物所限定,并且在权利要求及其等同物的范围内,所有变化都应解释为包括在本发明的范围内。
序列表
<110> CJ第一制糖株式会社
<120> 果糖-4-差向异构酶以及使用其制备塔格糖的方法
<130> OPA19112
<150> KR10-2018-0115113
<151> 2018-09-27
<160> 4
<170> KoPatentIn 3.0
<210> 1
<211> 434
<212> PRT
<213> 人工序列
<220>
<223> CJ_TATSA_F4E
<400> 1
Met Ala Lys Glu His Pro Leu Lys Glu Leu Val Asn Lys Gln Lys Ser
1 5 10 15
Gly Ile Ser Glu Gly Ile Val Ser Ile Cys Ser Ser Asn Glu Phe Val
20 25 30
Ile Glu Ala Ser Met Glu Arg Ala Leu Thr Asn Gly Asp Tyr Val Leu
35 40 45
Ile Glu Ser Thr Ala Asn Gln Val Asn Gln Tyr Gly Gly Tyr Ile Gly
50 55 60
Met Thr Pro Ile Glu Phe Lys Lys Phe Val Phe Ser Ile Ala Lys Lys
65 70 75 80
Val Asp Phe Pro Leu Asp Lys Leu Ile Leu Gly Gly Asp His Leu Gly
85 90 95
Pro Leu Ile Trp Lys Asn Glu Ser Ser Asn Leu Ala Leu Ala Lys Ala
100 105 110
Ser Glu Leu Ile Lys Glu Tyr Val Leu Ala Gly Tyr Thr Lys Ile His
115 120 125
Ile Asp Thr Ser Met Arg Leu Lys Asp Asp Thr Asp Phe Asn Thr Glu
130 135 140
Ile Ile Ala Gln Arg Ser Ala Val Leu Leu Lys Ala Ala Glu Asn Ala
145 150 155 160
Tyr Met Glu Leu Asn Lys Asn Asn Lys Asn Val Leu His Pro Val Tyr
165 170 175
Val Ile Gly Ser Glu Val Pro Ile Pro Gly Gly Ser Gln Gly Ser Asp
180 185 190
Glu Ser Leu Gln Ile Thr Asp Ala Lys Asp Phe Glu Asn Thr Val Glu
195 200 205
Ile Phe Lys Asp Val Phe Ser Lys Tyr Gly Leu Ile Asn Glu Trp Glu
210 215 220
Asn Ile Val Ala Phe Val Val Gln Pro Gly Val Glu Phe Gly Asn Asp
225 230 235 240
Phe Val His Glu Tyr Lys Arg Asp Glu Ala Lys Glu Leu Thr Asp Ala
245 250 255
Leu Lys Asn Tyr Lys Thr Phe Val Phe Glu Gly His Ser Thr Asp Tyr
260 265 270
Gln Thr Arg Glu Ser Leu Lys Gln Met Val Glu Asp Gly Ile Ala Ile
275 280 285
Leu Lys Val Gly Pro Ala Leu Thr Phe Ala Leu Arg Glu Ala Leu Ile
290 295 300
Ala Leu Asn Asn Ile Glu Asn Glu Leu Leu Asn Asn Val Asp Ser Ile
305 310 315 320
Lys Leu Ser Asn Phe Thr Asn Val Leu Val Ser Glu Met Ile Asn Asn
325 330 335
Pro Glu His Trp Lys Asn His Tyr Phe Gly Asp Asp Ala Arg Lys Lys
340 345 350
Phe Leu Cys Lys Tyr Ser Tyr Ser Asp Arg Cys Arg Tyr Tyr Leu Pro
355 360 365
Thr Arg Asn Val Lys Asn Ser Leu Asn Leu Leu Ile Arg Asn Leu Glu
370 375 380
Asn Val Lys Ile Pro Met Thr Leu Ile Ser Gln Phe Met Pro Leu Gln
385 390 395 400
Tyr Asp Asn Ile Arg Arg Gly Leu Ile Lys Asn Glu Pro Ile Ser Leu
405 410 415
Ile Lys Asn Ala Ile Met Asn Arg Leu Asn Asp Tyr Tyr Tyr Ala Ile
420 425 430
Lys Pro
<210> 2
<211> 1305
<212> DNA
<213> 人工序列
<220>
<223> CJ_TATSA_F4E
<400> 2
atggctaaag aacatccatt aaaggaatta gtaaataaac aaaaaagtgg tatatccgag 60
ggtatagttt ctatttgtag ttcaaatgaa tttgttattg aagcatctat ggagcgtgca 120
ttaacaaatg gtgattatgt tttaattgaa tcaacagcaa atcaggtgaa tcaatatggt 180
ggatatattg gtatgacacc tattgagttt aaaaaatttg tattttcaat agctaaaaaa 240
gtagattttc cattagataa attgattctt ggtggggatc atttaggccc attaatatgg 300
aaaaatgaat ctagtaattt ggcgttagca aaagcatccg agcttattaa agaatatgta 360
ttagccggat atactaaaat tcatatagac actagtatgc ggctaaaaga tgatactgat 420
tttaatacag aaattattgc tcaaagaagt gcagtattgt taaaggcagc ggaaaatgca 480
tatatggaat tgaataaaaa taataaaaat gttttacatc ctgtctatgt tataggaagt 540
gaagtcccaa tacctggggg cagccaaggc agtgatgaat cgctccaaat tactgatgct 600
aaggattttg aaaatacagt tgaaatattt aaagatgttt tttcaaaata tggattaatt 660
aatgagtggg aaaacatagt agcatttgtt gttcaaccag gagttgagtt tggaaatgat 720
tttgtacatg aatataaacg tgatgaagca aaagaattaa cagatgcact taaaaattat 780
aaaacatttg tttttgaagg acattctact gattatcaaa cacgtgaatc attaaaacaa 840
atggtggaag atggcattgc aattttaaaa gttggacctg cattaacatt tgcactacgt 900
gaagccttaa tagcactaaa taatatagaa aatgagttgc ttaataatgt agatagtata 960
aaattatcaa attttactaa tgtactcgta agtgaaatga tcaataaccc cgaacattgg 1020
aaaaatcatt attttggtga tgatgcaagg aaaaagtttc tatgtaaata tagttattcg 1080
gatagatgta ggtactattt accaactaga aatgtaaaaa actcattaaa tcttcttatt 1140
agaaatctag aaaatgtgaa aataccaatg acattaataa gtcaatttat gcctttgcaa 1200
tatgataata ttagaagagg actcataaaa aatgaaccaa tttctttaat taaaaatgca 1260
ataatgaacc gacttaatga ctattattat gctataaagc cgtaa 1305
<210> 3
<211> 434
<212> PRT
<213> 人工序列
<220>
<223> CJ_Pal_F4E
<400> 3
Met Arg Gly Asp Lys Arg Val Thr Thr Asp Phe Leu Lys Glu Ile Val
1 5 10 15
Gln Gln Asn Arg Ala Gly Gly Ser Arg Gly Ile Tyr Ser Val Cys Ser
20 25 30
Ala His Arg Leu Val Ile Glu Ala Ser Met Gln Gln Ala Lys Ser Asp
35 40 45
Gly Ser Pro Leu Leu Val Glu Ala Thr Cys Asn Gln Val Asn His Glu
50 55 60
Gly Gly Tyr Thr Gly Met Thr Pro Ser Asp Phe Cys Lys Tyr Val Leu
65 70 75 80
Asp Ile Ala Lys Glu Val Gly Phe Ser Gln Glu Gln Leu Ile Leu Gly
85 90 95
Gly Asp His Leu Gly Pro Asn Pro Trp Thr Asp Leu Pro Ala Ala Gln
100 105 110
Ala Met Glu Ala Ala Lys Lys Met Val Ala Asp Tyr Val Ser Ala Gly
115 120 125
Phe Ser Lys Ile His Leu Asp Ala Ser Met Ala Cys Ala Asp Asp Val
130 135 140
Glu Pro Leu Ala Asp Glu Val Ile Ala Gln Arg Ala Thr Ile Leu Cys
145 150 155 160
Ala Ala Gly Glu Ala Ala Val Ser Asp Lys Asn Ala Ala Pro Met Tyr
165 170 175
Ile Ile Gly Thr Glu Val Pro Val Pro Gly Gly Ala Gln Glu Asp Leu
180 185 190
His Glu Leu Ala Thr Thr Asn Ile Asp Asp Leu Lys Gln Thr Ile Lys
195 200 205
Thr His Lys Ala Lys Phe Ser Glu Asn Gly Leu Gln Asp Ala Trp Asp
210 215 220
Arg Val Ile Gly Val Val Val Gln Pro Gly Val Glu Phe Asp His Ala
225 230 235 240
Met Val Ile Gly Tyr Gln Ser Glu Lys Ala Gln Thr Leu Ser Lys Thr
245 250 255
Ile Leu Asp Phe Asp Asn Leu Val Tyr Glu Ala His Ser Thr Asp Tyr
260 265 270
Gln Thr Glu Thr Ala Leu Thr Asn Leu Val Asn Asp His Phe Ala Ile
275 280 285
Leu Lys Val Gly Pro Gly Leu Thr Tyr Ala Ala Arg Glu Ala Leu Phe
290 295 300
Ala Leu Ser Tyr Ile Glu Gln Glu Trp Ile Thr Asn Lys Pro Leu Ser
305 310 315 320
Asn Leu Arg Gln Val Leu Glu Glu Arg Met Leu Glu Asn Pro Lys Asn
325 330 335
Trp Ala Lys Tyr Tyr Thr Gly Thr Glu Gln Glu Gln Ala Phe Ala Arg
340 345 350
Lys Tyr Ser Phe Ser Asp Arg Ser Arg Tyr Tyr Trp Ala Asp Pro Ile
355 360 365
Val Asp Gln Ser Val Gln Thr Leu Ile Asn Asn Leu Thr Glu Gln Pro
370 375 380
Ala Pro Met Thr Leu Leu Ser Gln Phe Met Pro Leu Gln Tyr Ala Ala
385 390 395 400
Phe Arg Ala Gly Gln Leu Asn Asn Asp Pro Leu Ser Leu Ile Arg His
405 410 415
Trp Ile Gln Glu Val Val Ser Thr Tyr Ala Arg Ala Ser Gly Leu Ala
420 425 430
Val Lys
<210> 4
<211> 1305
<212> DNA
<213> 人工序列
<220>
<223> CJ_Pal_F4E
<400> 4
atcagaggag ataaaagggt gactacagat tttctgaaag aaattgttca acaaaacaga 60
gccggtggta gcagaggtat ttactctgtt tgttctgcgc atcgccttgt tattgaagcg 120
tctatgcagc aagccaaaag cgatggctca ccactgttag tagaggcaac atgtaatcag 180
gttaatcacg aaggtggtta taccggtatg accccaagcg acttttgcaa atacgtgtta 240
gatattgcaa aagaagtggg cttttcccaa gagcaactta ttttaggggg cgaccactta 300
gggcctaacc cgtggactga cctaccagct gcacaggcaa tggaagcggc caaaaaaatg 360
gttgctgatt acgtaagtgc gggcttttca aaaatacatt tagatgcaag catggcatgt 420
gcagatgatg tagagccgct tgctgatgag gttatagcgc agcgcgccac tattttatgt 480
gctgccggcg aagctgctgt tagcgataaa aatgcagccc caatgtatat tattggtacc 540
gaagtgccgg taccaggtgg cgcacaagaa gatttacacg aacttgctac aaccaatatt 600
gatgatttaa aacaaaccat taaaacccat aaagcaaaat ttagcgaaaa cggtttgcaa 660
gacgcatggg atagagtaat tggtgtagta gtgcagcctg gtgttgagtt tgaccacgcg 720
atggtaattg gctatcaaag cgaaaaagca caaacactaa gtaaaactat tttagatttt 780
gataatttgg tttatgaagc gcattcaacc gattatcaaa ccgaaacagc gttaactaac 840
ttggttaacg accactttgc tattttaaaa gtgggcccag ggcttactta tgcagcgcgc 900
gaagcgttgt ttgcacttag ttatattgag caagagtgga taaccaataa gcctctttct 960
aatttgcgcc aagtgcttga agagcgcatg ctcgaaaacc ctaaaaactg ggctaagtat 1020
tacacaggta cagagcaaga gcaggccttt gcacgaaaat atagctttag cgatagatcg 1080
cgttactatt gggccgatcc tattgttgat caaagtgttc aaacactcat taataactta 1140
actgagcagc cagcgccaat gaccttgctg agtcaattta tgccacttca atatgcggca 1200
tttcgtgcag gacaattaaa taacgatccg ctttctttga tcagacactg gatccaagaa 1260
gttgtatcaa cctacgcccg cgctagcgga cttgcagtaa aatag 1305
- 新型的果糖-4-差向异构酶以及使用其制备塔格糖的方法
- 新型果糖-4-差向异构酶以及使用其制备塔格糖的方法