一种数据同步方法、装置及设备
文献发布时间:2023-06-19 11:11:32
技术领域
本说明书实施例涉及大数据技术领域,特别涉及一种数据同步方法、装置及设备。
背景技术
随着社会的发展以及大数据技术的应用,越来越多的数据产生且被利用,例如用于记录相应的业务操作或预测某一事件的发展状态。而为了对这些数据进行有效利用,往往需要利用不同的存储方式对这些数据进行存储管理。例如,针对某些对实时计算要求较高的场景,可以利用缓存数据库来提供高时效性的快速读写;针对数据量庞大的静态数据,往往利用一般的关系型数据库对这些数据进行大批量存储管理。
但是,由于不同数据库的针对性不同,在实际应用的过程中,往往无法有效利用同一数据库处理综合业务场景,例如,缓存数据库往往得不到大批量数据的支持,关系型数据库往往不存在高时效性的数据,也无法进行快速的数据读写。但在实际应用中,这两种需求往往都是必须的,在缺乏数据库有效支持的情况下,会对实际业务处理过程造成较大的影响。因此,目前亟需一种能够同时保证数据库的高时效性和大批量存储运维的方法。
发明内容
本说明书实施例的目的是提供一种数据同步方法、装置及设备,以解决如何同时保证数据库的高时效性和大批量存储运维的问题。
为解决上述技术问题,本说明书实施例提供一种数据同步方法,包括:获取对应于缓存数据库的第一更新记录;所述第一更新记录用于标识所述缓存数据库中更新的数据;收集对应于批量数据管理系统的第二更新记录;所述第二更新记录用于标识所述批量数据管理系统中更新的数据;将所述缓存数据库中对应于第一更新记录的第一数据复制至所述批量数据管理系统中;将所述批量数据管理系统中对应于所述第二更新记录的第二数据同步至缓存数据库中。
本说明书实施例还提出一种数据同步装置,包括:第一更新记录获取模块,用于获取对应于缓存数据库的第一更新记录;所述第一更新记录用于标识所述缓存数据库中更新的数据;第二更新记录收集模块,用于收集对应于批量数据管理系统的第二更新记录;所述第二更新记录用于标识所述批量数据管理系统中更新的数据;第一数据复制模块,用于将所述缓存数据库中对应于第一更新记录的第一数据复制至所述批量数据管理系统中;第二数据同步模块,用于将所述批量数据管理系统中对应于所述第二更新记录的第二数据同步至缓存数据库中。
本说明书实施例还提出一种数据同步设备,包括存储器和处理器;所述存储器,用于存储计算机程序指令;所述处理器,用于执行所述计算机程序指令以实现以下步骤:获取对应于缓存数据库的第一更新记录;所述第一更新记录用于标识所述缓存数据库中更新的数据;收集对应于批量数据管理系统的第二更新记录;所述第二更新记录用于标识所述批量数据管理系统中更新的数据;将所述缓存数据库中对应于第一更新记录的第一数据复制至所述批量数据管理系统中;将所述批量数据管理系统中对应于所述第二更新记录的第二数据同步至缓存数据库中。
为了解决上述技术问题,本说明书实施例还提出一种数据同步方法,包括:利用第一更新记录标识更新的第一数据,以使同步组件基于所述第一更新记录获取所述第一数据,并将所述第一数据复制至批量数据管理系统中;存储所述同步组件获取的第二数据;所述第二数据包括同步组件根据批量数据管理系统的第二更新记录所复制的数据;所述第二更新记录用于标识所述批量数据管理系统中更新的数据。
本说明书实施例还提出一种数据同步装置,包括:第一数据标识模块,用于利用第一更新记录标识更新的第一数据,以使同步组件基于所述第一更新记录获取所述第一数据,并将所述第一数据复制至批量数据管理系统中;第二数据存储模块,用于存储所述同步组件获取的第二数据;所述第二数据包括同步组件根据批量数据管理系统的第二更新记录所复制的数据;所述第二更新记录用于标识所述批量数据管理系统中更新的数据。
本说明书实施例还提出一种缓存数据库,包括存储器和处理器;所述存储器,用于存储第一数据和计算机程序指令;所述处理器,用于执行所述计算机程序指令以实现以下步骤:利用第一更新记录标识更新的第一数据,以使同步组件基于所述第一更新记录获取所述第一数据,并将所述第一数据复制至批量数据管理系统中;存储所述同步组件获取的第二数据;所述第二数据包括同步组件根据批量数据管理系统的第二更新记录所复制的数据;所述第二更新记录用于标识所述批量数据管理系统中更新的数据。
为了解决上述技术问题,本说明书实施例还提出一种数据同步方法,包括:利用第二更新记录标识更新的第二数据,以使同步组件基于所述第二更新记录获取所述第二数据,并将所述第二数据同步至缓存数据库中;存储所述同步组件获取的第一数据;所述第一数据包括同步组件根据缓存数据库的第一更新记录所复制的数据;所述第一更新记录用于标识所述缓存数据库中更新的数据。
本说明书实施例还提出一种数据同步装置,包括:第二数据标识模块,用于利用第二更新记录标识更新的第二数据,以使同步组件基于所述第二更新记录获取所述第二数据,并将所述第二数据同步至缓存数据库中;第一数据存储模块,用于存储所述同步组件获取的第一数据;所述第一数据包括同步组件根据缓存数据库的第一更新记录所复制的数据;所述第一更新记录用于标识所述缓存数据库中更新的数据。
本说明书实施例还提出一种批量数据管理系统,包括存储器和处理器;所述存储器,用于存储第二数据和计算机程序指令;所述处理器,用于执行所述计算机程序指令以实现以下步骤:利用第二更新记录标识更新的第二数据,以使同步组件基于所述第二更新记录获取所述第二数据,并将所述第二数据同步至缓存数据库中;存储所述同步组件获取的第一数据;所述第一数据包括同步组件根据缓存数据库的第一更新记录所复制的数据;所述第一更新记录用于标识所述缓存数据库中更新的数据。
由以上本说明书实施例提供的技术方案可见,本说明书实施例通过让缓存数据库和批量数据管理系统分别利用第一更新记录和第二更新记录标识各自所更新的数据,使得同步组件能够通过获取第一更新记录和第二更新记录确定要同步至另一个数据库中的数据。相应的,根据所获取的更新记录可以实现缓存数据库和批量数据管理系统之间的数据双向同步。在实现双向数据同步的情况下,缓存数据库能够得到批量数据管理系统中的大批量数据的支持,批量数据管理系统能够获取缓存数据库中高时效性的数据,从而使得不同类型的数据库弥补自身的缺陷,更好地适应实际应用中业务的不同需求。
附图说明
为了更清楚地说明本说明书实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本说明书中记载的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本说明书实施例一种数据同步系统的结构图;
图2为本说明书实施例一种数据同步方法的流程图;
图3为本说明书实施例一种Redis和Oracle双向数据同步的示意图;
图4为本说明书实施例一种Flink模块数据流向的示意图;
图5为本说明书实施例一种Flink模块程序设计样板的示意图;
图6为本说明书实施例一种数据同步方法的流程图;
图7为本说明书实施例一种数据同步方法的流程图;
图8为本说明书实施例一种数据同步方法的流程图;
图9为本说明书实施例一种数据同步装置的模块图;
图10为本说明书实施例一种数据同步装置的模块图;
图11为本说明书实施例一种数据同步装置的模块图;
图12为本说明书实施例一种数据同步设备的结构图;
图13为本说明书实施例一种缓存数据库的结构图;
图14为本说明书实施例一种批量数据管理系统的结构图。
具体实施方式
下面将结合本说明书实施例中的附图,对本说明书实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本说明书一部分实施例,而不是全部的实施例。基于本说明书中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本说明书保护的范围。
为了更好地理解本申请的发明构思,首先介绍本说明书实施例一种数据同步系统。如图1所示,所述数据同步系统100包括同步组件110、缓存数据库120和批量数据管理系统130。
缓存数据库一般情况下即为将数据存储在内存中的数据库。由于内存的数据读写速度远快于硬盘,使得所述缓存数据库能够用于处理较高时效性的数据。所述缓存数据库在数据缓存、快速算法、并行处理等方面存在独特的数据,使得缓存数据库中可以直接完成数据的快速处理。但是,缓存数据库往往不能提供OLTP服务,也不能直接支持批量的查询、更新操作,查询速度也较慢。限于自身的体量,批量服务和运维的开销也较大。
在一些实施方式中,所述缓存数据库可以是Redis数据库。Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库。相应的能够实现数据的高性能读写。
批量数据管理系统可以用于存储并管理大批量的数据。相应的,可以针对所述批量数据管理系统中的数据进行大批量查询,相应的运维开销也较小。但是,批量数据管理系统中的数据一般都是用于持久化存储的数据,不具有较高的时效性,无法用于处理时效性要求较高的业务。相应的也无法直接应用至实时计算场景中。
在一些实施方式中,所述批量数据管理系统可以是Oracle数据库。Oracle是一个数据库管理系统,支持多用户,大业务量,分布式的数据处理,可以提供OLTP服务。
同步组件可以是用于实现所述缓存数据库和批量数据管理系统之间的数据双向同步的设备。所述同步组件可以通过读取缓存数据库和批量数据管理系统的系统日志的方式,分别获取不同数据库的更新记录。所述同步组件也包括有存储模块,从而可以根据所述更新记录将缓存数据库或批量数据管理系统中的数据复制至所述存储模块中,并将所复制的数据同步至另一数据库中,从而实现数据库之间的双向同步。此外,所述同步组件还可以比对两者的更新记录以避免重复更新数据甚至是出现数据更新的死循环的问题。
在一些实施方式中,所述同步组件可以是Flink分布式流数据处理引擎。Flink可以以流水线的方式处理流式数据,支持高吞吐,低延迟,高性能的有状态计算。
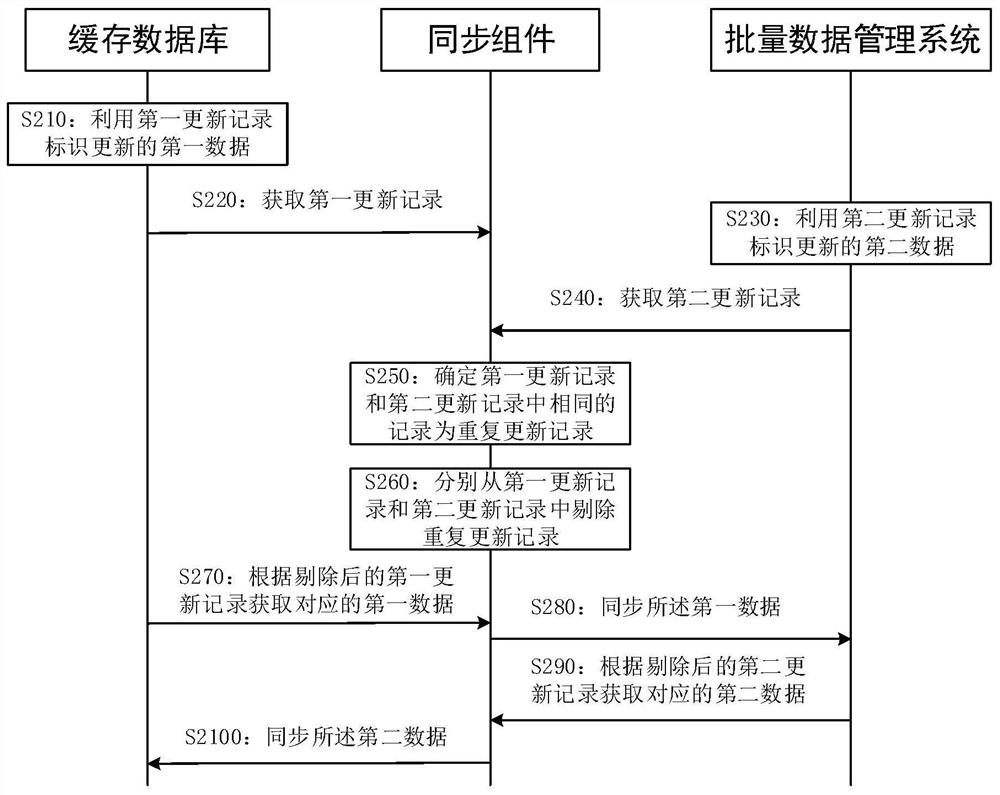
基于上述数据同步系统,介绍本说明书实施例一种数据同步方法。所述数据同步方法的执行主体为所述数据同步系统。如图2所示,所述数据同步方法可以包括以下具体实施步骤。
S210:缓存数据库利用第一更新记录标识更新的第一数据。
缓存数据库在更新数据时,可以利用第一更新记录标识所更新的第一数据。
所述第一数据可以是缓存数据库从其他数据来源所获取的数据,也可以是缓存数据库本身直接生成的数据。例如在所述缓存数据库中包含有实时预测模型的情况下,所述实时预测模型可以不断生成新的数据更新到所述缓存数据库中。这些更新到缓存数据库中的数据都可以作为第一数据。
所述第一更新记录即用于标识所述第一数据的记录,例如可以在所述第一更新记录中标记第一数据的存储位置,从而直接根据所述第一更新记录查找到对应的第一数据。具体的,所述第一更新记录可以包含于系统日志中,当需要获取第一更新记录时,可以从所述缓存数据库的系统日志中调取所述第一更新记录。
所述第一更新记录也可以对应有相应的时间戳,从而能够确定对应的第一数据更新至缓存数据库中的时刻,以对需要进行同步的数据进行筛选。
S220:同步组件从缓存数据库中获取第一更新记录。
为了使两个数据库之间的数据同步,所述同步组件可以从缓存数据库中获取所述第一更新记录,以确定缓存数据库中新增加的数据。具体的可以是通过查看缓存数据库的系统日志来获取所述第一更新记录。
S230:批量数据管理系统利用第二更新记录标识更新的第二数据。
相应的,所述批量管理系统也可以利用第二更新记录来标识更新的第二数据。
所述第二数据可以是批量数据管理系统从其他来源所获取的数据。例如,为了将用户所上传的数据进行持久化存储。具体应用中对于存储至所述批量数据管理系统的第二数据不做限制。
所述第二更新记录即用于标识所述第二数据的记录,例如可以在所述第二更新记录中标记第二数据的存储位置,从而直接根据所述第二更新记录查找到对应的第二数据。具体的,所述第二更新记录可以包含于系统日志中,当需要获取第二更新记录时,可以从所述缓存数据库的系统日志中调取所述第二更新记录。
所述第二更新记录也可以对应有相应的时间戳,从而能够确定对应的第二数据更新至缓存数据库中的时刻,以对需要进行同步的数据进行筛选。
S240:同步组件从批量数据管理系统中获取第二更新记录。
相应的,为了将批量数据管理系统中的数据同步至缓存数据库中,所述同步组件可以从批量数据管理系统中获取所述第一更新记录,以确定所述批量数据管理系统中新增加的数据。具体的可以是通过查看批量数据管理系统的系统日志来获取所述第一更新记录。
需要说明的是,本说明书实施例只是为了表述方便,采取了先说明利用第一更新记录标识更新的第一数据,并获取第一更新记录,再说明利用第二更新记录标识更新的第二数据,并获取第二更新记录的顺序。实际应用中执行上述步骤的顺序不做限制,例如可以先生成第二更新记录,或同时生成第一更新记录和第二更新记录,也可以在生成第一更新记录和第二更新记录后再分别获取第一更新记录和第二更新记录,对此不做限制。
S250:同步组件确定第一更新记录和第二更新记录中相同的记录为重复更新记录。
由于所述第一更新记录和第二更新记录只是用于对相应的数据库中更新的数据进行标识,因此,在本实施方式中,在双向数据同步过程中所同步的数据也会记录为第一更新记录或第二更新记录。若不对该部分数据进行识别,则会造成不断在两个数据库之间复制同一份数据,即造成数据同步的死循环。因此,需要在同步数据时避免出现上述情况。
因此,所述同步组件可以比对所述第一更新记录和第二更新记录,确定其中相同的记录为重复更新记录。其中,记录相同可以只是代表两个记录所指向的数据相同,分别对应的同步时间以及记录自身的标识信息可以不相同。
在一些实施方式中,所述第一更新记录和第二更新记录分别对应有操作记录。所述操作记录可以用于表示具体同步的是何种数据,以及同步操作的时间。通过比较所述操作记录对应的数据是否相同,以及操作时间是否较为接近,可以判断是否为重复更新记录。
通过确定所述重复更新记录,可以在后续步骤中剔除所述重复更新记录,以避免重复更新数据。
S260:同步组件从第一更新记录和第二更新记录中剔除重复更新记录。
确定所述重复更新记录后,可以从所述第一更新记录和第二更新记录中去除所述重复更新记录,以避免对一些数据重复同步而影响数据库的正常运转。
在一些实施方式中,为了避免对数据库的系统日志造成修改,同步组件可以是将第一更新记录和第二更新记录复制至自身的存储器中,在确定重复更新记录后剔除自身存储器中的第一更新记录和第二更新记录的重复更新记录,从而避免对实际的系统日志造成修改。
S270:同步组件根据剔除后的第一更新记录从缓存数据库中获取对应的第一数据。
在所述第一更新记录中剔除重复更新记录后,同步组件可以根据剔除后的第一更新记录从缓存数据库中获取对应的第一数据。由于第一更新记录可以用于标识第一数据,相应的可以根据所述第一更新记录查找到第一数据所存储的位置,进而获取所述第一数据。
具体的,所述同步组件可以利用自身的缓存模块存储所述第一数据,从而在之后的步骤中将缓存模块的第一数据同步至批量数据管理系统中。
S280:同步组件将所述第一数据同步至批量数据管理系统中。
在获取到第二数据之后,同步组件可以将所述第一数据同步至批量数据管理系统中,以完成缓存数据库至批量数据管理系统的数据同步。具体的同步方式可以基于实际应用中数据库的特点进行设置,在此不再赘述。
在一些实施方式中,在同步组件将第一数据同步至批量数据管理系统中之后,可以利用第二更新记录来记录所更新的第一数据,从而使得在后续步骤中确定已经对第一数据完成同步。
S290:同步组件根据剔除后的第二更新记录从批量数据管理系统中获取对应的第二数据。
在所述第二更新记录中剔除重复更新记录后,同步组件可以根据剔除后的第二更新记录从批量数据管理系统中获取对应的第二数据。由于第二更新记录可以用于标识第二数据,相应的可以根据所述第二更新记录查找到第二数据所存储的位置,进而获取所述第二数据。
具体的,所述同步组件可以利用自身的缓存模块存储所述第二数据,从而在之后的步骤中将缓存模块的第二数据同步至缓存数据库中。
S2100:同步组件将所述第二数据同步至缓存数据库中。
在获取到第二数据之后,同步组件可以将所述第二数据同步至缓存数据库中,以完成批量数据管理系统至缓存数据库的数据同步。具体的同步方式可以基于实际应用中数据库的特点进行设置,在此不再赘述。
在一些实施方式中,在同步组件将第二数据同步至缓存数据库中之后,可以利用第一更新记录来记录所更新的第二数据,从而使得在后续步骤中确定已经对第二数据完成同步。
利用一个具体的场景示例进行说明,在该场景示例中,所述缓存数据库为Redis,批量数据管理系统为Oracle,同步组件为Flink。在反欺诈交易场景中,需要维护一张用户黑名单表,所述用户黑名单表用于提醒客户相应的交易风险。如图3所示,可以利用Redis中的实时模型计算相应的数据,并插入黑名单表格中,以达到交易途中拦截交易报警的目的相应的,Oracle可以用于记录其他数据来源所获取到的黑名单数据,并对这些黑名单内容进行批量管理和查询。
首先Redis获取到实时计算模型的数据后,将其复制到Kafka模块1中,flink模块1可以通过消费Kafka模块1中的Redis记录来实时操作记录转化为生成文件,并将所生成的文件加载至Oracle中,以此完成Redis到Oracle数据的单向同步。接着,将其他渠道获取的数据以自定义文件数据的形式插入Oracle,并利用Oracle的实时复制工具将变更记录同步至Kafka模块2中。通过Flink模块2消费Kafka模块2中的Oracle操作记录,实现将记录实时写入到Redis中。
为了避免重复同步,可以分别对不同的记录进行过滤。如图4所示,可以通过分析Redis操作记录和Oracle操作记录,从而分别对Redis操作记录和Oracle操作记录进行过滤。根据过滤后的Redis更新记录同步数据至Oracle中,并根据过滤后的Oracle更新记录同步数据至Redis中。
具体的过滤过程可以如图5所示,首先,上游数据源为分别包含Redis记录与Oracle记录的Kafka,作为两条待处理数据流进入Flink模块,对这两条流进行预处理加工,例如可以是去除噪声数据等自定义预加工。Flink作业使用事件时间作为处理时间,并使用水印(WaterMark)机制作为推动窗口计算的触发器。即使用数据本身发生的时间来推动运算,可以避免更新记录有时间差,更新记录时间乱序的问题。此处设计获取时间戳以及生成水印模块来获取时间戳。在获取后,流入窗口函数进行运算,此处,窗口类型(即采用何种模式进行合并计算),窗口大小(即窗口持续时间),延迟时间(即等待迟到数据时间)均可根据实际业务需求评估制定。
具体的运算可以是针对每条Redis操作记录,遍历窗口内的Oracle操作记录是否有相同的操作记录,如果有,则说明该记录为原Redis更新过的记录,从窗口中剔除。此外,针对更新同一个数据的两个不同操作,可以设定优先级策略,例如根据时间先后,只采用最新的更新,或只以Redis更新为准。实际应用中也可以根据需求设计其他自定义操作,从而实现对记录更为精细的监控或操作。
窗口计算完成后,将过滤后的原Redis操作记录输出到下游,废弃操作可以丢弃或采用侧输出,输出进行分析操作,然后输出到专用的分析Kafka中进行后续数据分析核对。将输出数据进行自定义处理,可以自定义输出策略,如可以根据数据操作类型,只对Oracle进行插入操作或删除操作等等。当这些操作均完成后,将对应操作落地为文件,通过Oracle加载该文件即完成数据同步。Redis部分的同步操作可以参照上述过程,在此不再赘述。
通过上述实施例的介绍,可以看出,所述方法通过让缓存数据库和批量数据管理系统分别利用第一更新记录和第二更新记录标识各自所更新的数据,使得同步组件能够通过获取第一更新记录和第二更新记录确定要同步至另一个数据库中的数据。相应的,根据所获取的更新记录可以实现缓存数据库和批量数据管理系统之间的数据双向同步。在实现双向数据同步的情况下,缓存数据库能够得到批量数据管理系统中的大批量数据的支持,批量数据管理系统能够获取缓存数据库中高时效性的数据,从而使得不同类型的数据库弥补自身的缺陷,更好地适应实际应用中业务的不同需求。
基于图2所对应的数据同步方法,介绍本说明书实施例另一种数据同步方法。所述数据同步方法的执行主体为所述数据同步设备。如图6所示,所述数据同步方法可以包括以下具体实施步骤。
S610:获取对应于缓存数据库的第一更新记录;所述第一更新记录用于标识所述缓存数据库中更新的数据。
对于该步骤的具体描述可以参考步骤S210、S220中的说明,在此不再赘述。
S620:收集对应于批量数据管理系统的第二更新记录;所述第二更新记录用于标识所述批量数据管理系统中更新的数据。
对于该步骤的具体描述可以参考步骤S230、S240中的说明,在此不再赘述。
S630:将所述缓存数据库中对应于第一更新记录的第一数据复制至所述批量数据管理系统中。
对于该步骤的具体描述可以参考步骤S250、S260、S270、S280中的说明,在此不再赘述。
S640:将所述批量数据管理系统中对应于所述第二更新记录的第二数据同步至缓存数据库中。
对于该步骤的具体描述可以参考步骤S250、S260、S290、S2100中的说明,在此不再赘述。
基于图2所对应的数据同步方法,介绍本说明书实施例另一种数据同步方法。所述数据同步方法的执行主体为所述缓存数据库。如图7所示,所述数据同步方法可以包括以下具体实施步骤。
S710:利用第一更新记录标识更新的第一数据,以使同步组件基于所述第一更新记录获取所述第一数据,并将所述第一数据复制至批量数据管理系统中。
对于该步骤的具体描述可以参考步骤S210、S220、S250、S260、S270、S280中的说明,在此不再赘述。
S720:存储所述同步组件获取的第二数据;所述第二数据包括同步组件根据批量数据管理系统的第二更新记录所复制的数据;所述第二更新记录用于标识所述批量数据管理系统中更新的数据。
对于该步骤的具体描述可以参考步骤S230、S240、S250、S260、S290、S2100中的说明,在此不再赘述。
基于图2所对应的数据同步方法,介绍本说明书实施例另一种数据同步方法。所述数据同步方法的执行主体为所述批量数据管理系统。如图8所示,所述数据同步方法可以包括以下具体实施步骤。
S810:第二更新记录标识更新的第二数据,以使同步组件基于所述第二更新记录获取所述第二数据,并将所述第二数据同步至缓存数据库中。
对于该步骤的具体描述可以参考步骤S230、S240、S250、S260、S290、S2100中的说明,在此不再赘述。
S820:存储所述同步组件获取的第一数据;所述第一数据包括同步组件根据缓存数据库的第一更新记录所复制的数据;所述第一更新记录用于标识所述缓存数据库中更新的数据。
对于该步骤的具体描述可以参考步骤S210、S220、S250、S260、S270、S280中的说明,在此不再赘述。
基于图6所对应的数据同步方法,介绍本说明书实施例一种数据同步装置。所述数据同步装置设置于所述数据同步设备。如图9所示,所述数据同步装置包括以下模块。
第一更新记录获取模块910,用于获取对应于缓存数据库的第一更新记录;所述第一更新记录用于标识所述缓存数据库中更新的数据。
第二更新记录收集模块920,用于收集对应于批量数据管理系统的第二更新记录;所述第二更新记录用于标识所述批量数据管理系统中更新的数据。
第一数据复制模块930,用于将所述缓存数据库中对应于第一更新记录的第一数据复制至所述批量数据管理系统中。
第二数据同步模块940,用于将所述批量数据管理系统中对应于所述第二更新记录的第二数据同步至缓存数据库中。
基于图7所对应的数据同步方法,介绍本说明书实施例一种数据同步装置。所述数据同步装置设置于所述缓存数据库。如图10所示,所述数据同步装置包括以下模块。
第一数据标识模块1010,用于利用第一更新记录标识更新的第一数据,以使同步组件基于所述第一更新记录获取所述第一数据,并将所述第一数据复制至批量数据管理系统中。
第二数据存储模块1020,用于存储所述同步组件获取的第二数据;所述第二数据包括同步组件根据批量数据管理系统的第二更新记录所复制的数据;所述第二更新记录用于标识所述批量数据管理系统中更新的数据。
基于图8所对应的数据同步方法,介绍本说明书实施例一种数据同步装置。所述数据同步装置设置于所述批量数据管理系统。如图11所示,所述数据同步装置包括以下模块。
第二数据标识模块1110,用于利用第二更新记录标识更新的第二数据,以使同步组件基于所述第二更新记录获取所述第二数据,并将所述第二数据同步至缓存数据库中。
第一数据存储模块1120,用于存储所述同步组件获取的第一数据;所述第一数据包括同步组件根据缓存数据库的第一更新记录所复制的数据;所述第一更新记录用于标识所述缓存数据库中更新的数据。
基于图6所对应的数据同步方法,本说明书实施例提供一种数据同步设备。如图12所示,所述数据同步设备可以包括存储器和处理器。
在本实施例中,所述存储器可以按任何适当的方式实现。例如,所述存储器可以为只读存储器、机械硬盘、固态硬盘、或U盘等。所述存储器可以用于存储计算机程序指令。
在本实施例中,所述处理器可以按任何适当的方式实现。例如,处理器可以采取例如微处理器或处理器以及存储可由该(微)处理器执行的计算机可读程序代码(例如软件或固件)的计算机可读介质、逻辑门、开关、专用集成电路(Application SpecificIntegrated Circuit,ASIC)、可编程逻辑控制器和嵌入微控制器的形式等等。所述处理器可以执行所述计算机程序指令实现以下步骤:获取对应于缓存数据库的第一更新记录;所述第一更新记录用于标识所述缓存数据库中更新的数据;收集对应于批量数据管理系统的第二更新记录;所述第二更新记录用于标识所述批量数据管理系统中更新的数据;将所述缓存数据库中对应于第一更新记录的第一数据复制至所述批量数据管理系统中;将所述批量数据管理系统中对应于所述第二更新记录的第二数据同步至缓存数据库中。
基于图7所对应的数据同步方法,本说明书实施例提供一种缓存数据库。如图13所示,所述缓存数据库可以包括存储器和处理器。
在本实施例中,所述存储器可以按任何适当的方式实现。例如,所述存储器可以为只读存储器、机械硬盘、固态硬盘、或U盘等。所述存储器可以用于存储第一数据和计算机程序指令。
在本实施例中,所述处理器可以按任何适当的方式实现。例如,处理器可以采取例如微处理器或处理器以及存储可由该(微)处理器执行的计算机可读程序代码(例如软件或固件)的计算机可读介质、逻辑门、开关、专用集成电路(Application SpecificIntegrated Circuit,ASIC)、可编程逻辑控制器和嵌入微控制器的形式等等。所述处理器可以执行所述计算机程序指令实现以下步骤:利用第一更新记录标识更新的第一数据,以使同步组件基于所述第一更新记录获取所述第一数据,并将所述第一数据复制至批量数据管理系统中;存储所述同步组件获取的第二数据;所述第二数据包括同步组件根据批量数据管理系统的第二更新记录所复制的数据;所述第二更新记录用于标识所述批量数据管理系统中更新的数据。
基于图8所对应的数据同步方法,本说明书实施例提供一种批量数据管理系统。如图14所示,所述批量数据管理系统可以包括存储器和处理器。
在本实施例中,所述存储器可以按任何适当的方式实现。例如,所述存储器可以为只读存储器、机械硬盘、固态硬盘、或U盘等。所述存储器可以用于存储第二数据和计算机程序指令。
在本实施例中,所述处理器可以按任何适当的方式实现。例如,处理器可以采取例如微处理器或处理器以及存储可由该(微)处理器执行的计算机可读程序代码(例如软件或固件)的计算机可读介质、逻辑门、开关、专用集成电路(Application SpecificIntegrated Circuit,ASIC)、可编程逻辑控制器和嵌入微控制器的形式等等。所述处理器可以执行所述计算机程序指令实现以下步骤:利用第二更新记录标识更新的第二数据,以使同步组件基于所述第二更新记录获取所述第二数据,并将所述第二数据同步至缓存数据库中;存储所述同步组件获取的第一数据;所述第一数据包括同步组件根据缓存数据库的第一更新记录所复制的数据;所述第一更新记录用于标识所述缓存数据库中更新的数据。
在20世纪90年代,对于一个技术的改进可以很明显地区分是硬件上的改进(例如,对二极管、晶体管、开关等电路结构的改进)还是软件上的改进(对于方法流程的改进)。然而,随着技术的发展,当今的很多方法流程的改进已经可以视为硬件电路结构的直接改进。设计人员几乎都通过将改进的方法流程编程到硬件电路中来得到相应的硬件电路结构。因此,不能说一个方法流程的改进就不能用硬件实体模块来实现。例如,可编程逻辑器件(Programmable Logic Device,PLD)(例如现场可编程门阵列(Field Programmable GateArray,FPGA))就是这样一种集成电路,其逻辑功能由用户对器件编程来确定。由设计人员自行编程来把一个数字系统“集成”在一片PLD上,而不需要请芯片制造厂商来设计和制作专用的集成电路芯片。而且,如今,取代手工地制作集成电路芯片,这种编程也多半改用“逻辑编译器(logic compiler)”软件来实现,它与程序开发撰写时所用的软件编译器相类似,而要编译之前的原始代码也得用特定的编程语言来撰写,此称之为硬件描述语言(Hardware Description Language,HDL),而HDL也并非仅有一种,而是有许多种,如ABEL(Advanced Boolean Expression Language)、AHDL(Altera Hardware DescriptionLanguage)、Confluence、CUPL(Cornell University Programming Language)、HDCal、JHDL(Java Hardware Description Language)、Lava、Lola、MyHDL、PALASM、RHDL(RubyHardware Description Language)等,目前最普遍使用的是VHDL(Very-High-SpeedIntegrated Circuit Hardware Description Language)与Verilog。本领域技术人员也应该清楚,只需要将方法流程用上述几种硬件描述语言稍作逻辑编程并编程到集成电路中,就可以很容易得到实现该逻辑方法流程的硬件电路。
上述实施例阐明的系统、装置、模块或单元,具体可以由计算机芯片或实体实现,或者由具有某种功能的产品来实现。一种典型的实现设备为计算机。具体的,计算机例如可以为个人计算机、膝上型计算机、蜂窝电话、相机电话、智能电话、个人数字助理、媒体播放器、导航设备、电子邮件设备、游戏控制台、平板计算机、可穿戴设备或者这些设备中的任何设备的组合。
通过以上的实施方式的描述可知,本领域的技术人员可以清楚地了解到本说明书可借助软件加必需的第一硬件平台的方式来实现。基于这样的理解,本说明书的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在存储介质中,如ROM/RAM、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本说明书各个实施例或者实施例的某些部分所述的方法。
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于系统实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
本说明书可用于众多第一或专用的计算机系统环境或配置中。例如:个人计算机、服务器计算机、手持设备或便携式设备、平板型设备、多处理器系统、基于微处理器的系统、置顶盒、可编程的消费电子设备、网络PC、小型计算机、大型计算机、包括以上任何系统或设备的分布式计算环境等等。
本说明书可以在由计算机执行的计算机可执行指令的一般上下文中描述,例如程序模块。一般地,程序模块包括执行特定任务或实现特定抽象数据类型的例程、程序、对象、组件、数据结构等等。也可以在分布式计算环境中实践本说明书,在这些分布式计算环境中,由通过通信网络而被连接的远程处理设备来执行任务。在分布式计算环境中,程序模块可以位于包括存储设备在内的本地和远程计算机存储介质中。
虽然通过实施例描绘了本说明书,本领域普通技术人员知道,本说明书有许多变形和变化而不脱离本说明书的精神,希望所附的权利要求包括这些变形和变化而不脱离本说明书的精神。
- 时间同步方法、数据同步方法、装置、系统、设备和介质
- 数据通信方法、数据同步方法、系统、装置、网关设备、服务器及基站设备