一种法律法规名称识别装置及方法
文献发布时间:2023-06-19 11:19:16
技术领域
本发明涉及法律法规名称识别技术领域,尤其涉及一种法律法规名称识别装置及方法。
背景技术
未登录词识别是自然语言处理领域的一项关键技术,对提升信息提取与检索、文本分类、文本推荐、智能问答、机器翻译等方面的应用效果具有重要作用。在对互联网信息、民众信访投诉内容、法律文书等文本进行分析挖掘时,常需要智能识别法律法规名称。法律法规名称属于未登录词,具有构成成分较为复杂、无法穷举、表述方式多样等特点。同时,由于目前国内较为常用的自然语言处理工具,如哈工大语言技术平台(LTP)、HanLP等,均未具备法律法规名称的识别功能,法律法规名称快速有效识别仍是政务、法律等领域的文本应用一个难题。
当前对于法律法规名称识别的通常采用文本匹配的方法,该方法的缺点较多,主要体现在:(1)法律法规识别的完整度与预设法律法规名称库的完整度成正比,而通常情况下难以获得全面、完整的法律法规名称库,因此本方法提取的法律法规名称查全率较低;(2)中文表述复杂多样,本方法无法识别出文本中简写、缩写的法律法规名称,通用性较差。
综上所述,当前法律法规名称识别方法查全率低,通用性差,因此我们提出了一种法律法规名称识别装置及方法,用来解决上述问题。
发明内容
本发明的目的是为了解决现有技术中存在当前法律法规名称识别方法查全率低,通用性差的缺点,而提出的一种法律法规名称识别装置及方法。
为了实现上述目的,本发明采用了如下技术方案:
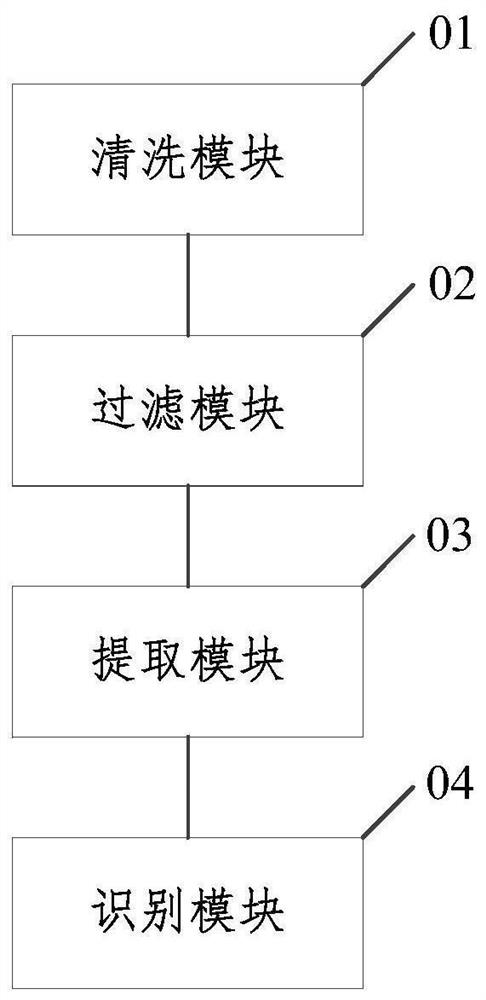
一种法律法规名称识别装置,包括依次连接的清洗模块、过滤模块、提取模块和识别模块,所述清洗模块,用于将长文本处理为标准化短文本;
过滤模块,用于根据预设核心词库过滤标准短文本,获取核心短文本;
提取模块,用于从核心短文本中分别提取显性法律法规名称和隐形法律法规名称对应的候选空间。
识别模块,对候选空间进行依存句法分析,并结合分析结果,识别满足预设条件的候选空间为法律法规名称。
本发明还提出了一种法律法规名称识别方法,包括以下步骤:
S1:将长文本处理为标准短文本;
S2:根据预设核心词库过滤标准短文本,获取核心短文本;
S3:从核心短文本中分别提取显性法律法规名称和隐形法律法规名称对应的候选空间;
S4:对候选空间进行依存句法分析,并结合分析结果识别满足预设条件的候选空间为法律法规名称。
优选的,所述将长文本处理为标准短文本包括:根据中英文标点符号将长文本切割为短文本;去除短文本中无效字符,获得标准短文本,中英文标点符号通常包括句号、问号、感叹号,若长文本为群众投诉、互联网公开帖子或博文表述自由、较不规范的文本数据,还需考虑空格、逗号符号。
优选的,所述根据预设核心词库过滤标准短文本,获取核心短文本包括:利用正则表达式匹配各标准短文本,将包含任意一个预设核心词库中词汇或词组的短文本划分为核心短文本,预设核心词库由现有法律法规名称的结束词汇或结束词组构成。
优选的,所述S3中,所述显性法律法规名称指代在所述核心短文本中采用引号、括号、书名号标识的法律法规名称;所述隐形法律法规名称指代在所述核心短文本中未采用引号、括号、书名号标识的法律法规名称。
优选的,所述S3中,从核心短文本中提取显性法律法规名称的候选空间包括:截取核心短文中采用引号、括号、书名号标识的文本内容;判断文本内容是否满足以所述预设核心词库中任意一个词汇或词组结尾的条件,若满足条件,则文本内容作为显性法律法规名称的候选空间。
优选的,所述S3中,从核心短文本中提取隐性法律法规名称的候选空间包括:T1:根据预设句式模板库采用正则表达式提取核心短文本中非采用引号、括号、书名号标识的文本内容;T2:对上述文本内容分词并按照词汇在文本内容顺序存储分词结果;T3:预设候选空间包含词汇个数为N,分词结果中属于所述核心词库的最后一个词汇或词组的位置为M,截取分词结果中第M-N+1至第M位置的词汇并重新拼接,得到隐性法律法规名称的一个候选空间;T4:修改候选空间包含词汇个数的预设值N,重复上一过程获得隐性法律法规名称的若干候选空间。
优选的,所述S4中,对候选空间进行依存句法分析,得到各候选空间的句式结构;针对各核心短文本的显性法律法规名称的候选空间,若满足预设条件则识别为显性法律法规名称;针对各核心短文本的隐性法律法规名称的若干候选空间,选择满足预设条件且长度最大的候选空间为隐形法律法规名称,所述预设条件包括:法律法规名称的句式结构不包括主谓结构、主谓宾结构和动宾结构;法律法规名称的字数不超过某一预设值K;由于法律法规名称作为未登录词,是一个独立的词汇,因此不能出现主谓结构、主谓宾结构、动宾结构句子特有的结构,如候选空间[“国家颁布了新的继承法”]的句式结构为“主谓宾”,因此该候选空间不为独立的词汇,也不能构成法律法规名称;法律法规名称字数的界定可过滤许多缩写、简写后指代不明的候选空间,如[“相关条例”]、[“规定”];通常除“刑法”、“宪法”、“民法”、“水法”外,法律名称字数个数不少于3个,法律解释、行政法规、地方性法规、自治条例和单行条例、规章的名称字数不少于5个。
与现有技术相比,本发明的有益效果在于:
(1)本发明同时针对显性法律法规名称和隐形法律法规名称进行识别,查全率较高;
(2)本发明仅依赖少量法律法规名称样本用于生成预设句式模版库,对原始法律法规名称的依赖度不高,具有较强的通用性;
(3)本发明最终识别的法律法规名称,以及显性法律法规名称所在的核心短文本可进一步分别添加至预备法律法规库和文本语料库中,用于完善和补充预设模版库,即本发明所述方法可形成闭环,实用性和可操作性较强。
本发明查全率较高,具有较强的通用性,实用性和可操作性较强。
附图说明
图1为本发明提出的一种法律法规名称识别装置的结构示意图;
图2为本发明提出的一种法律法规名称识别方法的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
图2是本发明实施例提供的一种法律法规名称识别方法的流程图,方法包括:
S1、将长文本处理为标准短文本;
其中,法律法规类型包括:法律、法律解释、行政法规、地方性法规、自治条例和单行条例、规章。
其中,将长文本处理为标准短文本包括:
根据中英文标点符号将长文本切割为短文本;
去除短文本中无效字符,获得标准短文本。
中英文标点符号通常包括句号、问号、感叹号,若长文本为群众投诉、互联网公开帖子或博文等表述自由、较不规范的文本数据,还需考虑空格、逗号等符号。
根据预设核心词库过滤标准短文本,获取核心短文本;
其中,根据预设核心词库过滤标准短文本,获取核心短文本包括:
利用正则表达式匹配各标准短文本,将包含任意一个预设核心词库中词汇或词组的短文本划分为核心短文本。
预设核心词库由现有法律法规名称的结束词汇或结束词组构成。
如法律类名称《中华人民共和国刑法》的结束词汇“刑法”、法律解释类名称《最高人民法院关于人民法院登记立案若干问题的规定》的结束词汇“规定”、行政法规类名称《中华人民共和国商标法实施条例》的结束词组“实施条例”、地方性法规类名称《广州市地方性法规制定办法》的结束词汇“办法”、自治条例和单行条例类名称《甘肃省肃北蒙古族自治县自治条例》的结束词组“自治条例”、规章类名称《河北省内河交通安全管理规定》的结束词汇“管理规定”均为预设核心词库中的词汇或词组。
从核心短文本中分别提取显性法律法规名称和隐形法律法规名称对应的候选空间;
显性法律法规名称指代在核心短文本中采用引号、括号、书名号标识的法律法规名称;隐形法律法规名称指代在核心短文本中未采用引号、括号、书名号标识的法律法规名称。
其中,从核心短文本中提取显性法律法规名称的候选空间包括:
截取核心短文中采用引号、括号、书名号标识的文本内容;
判断文本内容是否满足以预设核心词库中任意一个词汇或词组结尾的条件,若满足条件,则文本内容作为显性法律法规名称的候选空间。
举例说明,假设核心短文本为“2015年12月29日公安部制定印发了《公安部关于改革完善受案立案制度的意见》。”,“意见”为核心词库中词汇,则获得的候选空间为[“公安部关于改革完善受案立案制度的意见”]。
其中,从核心短文本中提取隐性法律法规名称的候选空间包括:
S3.2.1:根据预设句式模板库采用正则表达式提取核心短文本中非采用引号、括号、书名号标识的文本内容;
举例说明,假设句式模版为“……依据/根据……自治条例/管理办法/保护法第……”,核心短文本为“法律专家说根据中华人民共和国消费者保护法第十条的相关规定本人可提起诉讼”,则采用该句式模版对核心短文本进行提取的结果为“中华人民共和国消费者保护法”。
其中,预设句式模板库的生成过程包括:
预备包含较多规范法律法规名称的文本语料,并将文本语料按照上述方法处理为标准短文本;
特别地,标准短文本中用于标识显示法律法规名称的引号、括号、书名号也需作为无效字符去除,以保证最终获得句式模版能适用隐形法律法规名称的匹配。
利用预备法律法规名称库匹配标准短文本,保留匹配成功的标准短文本为模版文本;
针对各个模版文本以法律法规名称为中心,向前截取预设前缀窗口长度文本形成前缀库,向后截取预设后缀窗口长度文本形成后缀库;
以前缀库文本、核心词库中词汇或词组、后缀库文本的顺序拼接获得候选句式模板;
对候选句式模板进行人工归纳整合,形成预设句式模版库。
举例说明,现有模板文本“本院依据中华人民共和国民事诉讼法第六十四条之规定”、“根据北京市信访条例第四章第二十三条的内容规定”,通过法律法规库名称分别匹配出对应法律法规名称“中华人民共和国民事诉讼法”、“北京市信访条例”,设置前缀窗口长度为2,后缀窗口长度为1,则形成前缀库[“依据”,“根据”]、后缀库[“第”],若的核心词库包括词汇或词组有[“自治条例”,“管理办法”,“保护法”],以前缀库文本、核心词库中词汇或词组、后缀库文本的顺序拼接,并人工整合可获得句式模板“……依据/根据……自治条例/管理办法/保护法第……”。
S3.2.2:对上述文本内容分词并按照词汇在文本内容顺序存储分词结果;
S3.2.3:预设候选空间包含词汇个数为N,分词结果中属于核心词库的最后一个词汇或词组的位置为M,截取分词结果中第M-N+1至第M位置的词汇并重新拼接,得到隐性法律法规名称的一个候选空间;
S3.2.4:修改候选空间包含词汇个数的预设值N,重复上一过程获得隐性法律法规名称的若干候选空间。
上述样例“中华人民共和国消费者保护法”的分词结果为[“中华人民共和国”,“消费者”,“保护法”]。假设N的取值为2至3,则可获取候选空间[“消费者保护法”、“中华人民共和国消费者保护法”]。
S4、对候选空间进行依存句法分析,并结合分析结果,识别满足预设条件的候选空间为法律法规名称。
其中,对候选空间进行依存句法分析,并结合分析结果,识别满足预设条件的候选空间为法律法规名称包括:
对候选空间进行依存句法分析,得到各候选空间的句式结构;
针对各核心短文本的显性法律法规名称的候选空间,若满足预设条件则识别为显性法律法规名称;
针对各核心短文本的隐性法律法规名称的若干候选空间,选择满足预设条件且长度最大的候选空间为隐形法律法规名称。
其中,预设条件包括:
法律法规名称的句式结构不包括主谓结构、主谓宾结构和动宾结构;
法律法规名称的字数不超过某一预设值K。
由于法律法规名称作为未登录词,是一个独立的词汇,因此不能出现主谓结构、主谓宾结构、动宾结构等句子特有的结构,如候选空间[“国家颁布了新的继承法”]的句式结构为“主谓宾”,因此该候选空间不为独立的词汇,也不能构成法律法规名称。
法律法规名称字数的界定可过滤许多缩写、简写后指代不明的候选空间,如[“相关条例”]、[“规定”]等。通常除“刑法”、“宪法”、“民法”、“水法”外,法律名称字数个数不少于3个,法律解释、行政法规、地方性法规、自治条例和单行条例、规章的名称字数不少于5个。
通过步骤S4,显性法律法规名称候选空间[“公安部关于改革完善受案立案制度的意见”]可识别出显性法律法规名称“公安部关于改革完善受案立案制度的意见”;隐性法律法规候选空间[“消费者保护法”、“中华人民共和国消费者保护法”]可识别隐性法律法规名称“中华人民共和国消费者保护法”。
本发明方法同时针对显性法律法规名称和隐形法律法规名称进行识别,查全率较高。
本发明仅依赖少量法律法规名称样本用于生成预设句式模版库,对原始法律法规名称的依赖度不高,具有较强的通用性。
进一步地,完成法律法规名称识别后,显性法律法规名称所在核心短文本可添加至预备语料中,所有成功识别法律法规名称可纳入法律法规名称库中,用于补充和完善句式模版库,即方法可形成闭环。
图1是本发明实施例提供的一种法律法规名称识别装置的示意图,装置包括:
清洗模块01,用于将长文本处理为标准化短文本;
过滤模块02,用于根据预设核心词库过滤标准短文本,获取核心短文本;
提取模块03,用于从核心短文本中分别提取显性法律法规名称和隐形法律法规名称对应的候选空间。
识别模块04,对候选空间进行依存句法分析,并结合分析结果,识别满足预设条件的候选空间为法律法规名称。
本发明实施例提出的一种法律法规名称识别装置的技术特征和技术效果与本发明实施例提出的方法相同,在此不予赘述。
本发明还提供一种法律法规名称识别设备,包括处理器、存储器以及存储在存储器中且被配置为由处理器执行的计算机程序,处理器执行计算机程序时实现上述法律法规名称识别方法。
本发明还提供一种计算机可读的存储介质,计算机可读存储介质包括存储的计算机程序,其中,在计算机程序运行时控制计算机存储介质所在设备执行上述法律法规名称识别方法。
在流程图中表示或在此以其他方式描述的逻辑和/或步骤,例如,可以被认为是用于实现逻辑功能的可执行指令的定序列表,可以具体实现在任何计算机可读介质中,以供指令执行系统、装置或设备(如基于计算机的系统、包括处理器的系统或其他可以从指令执行系统、装置或者设备取指令并执行指令的系统)使用,或结合这些指令执行系统、设备或设备而使用。就本说明书而言,“计算机可读介质”可以是任何可以包含、存储、通信、传播或传输程序以供指令执行系统、装置或设备或结合这些指令执行系统、装置或设备而使用的装置。
计算机可读介质的更具体示例(非穷尽式列表)包括如下:具有一个或多个布线的电连接部(电子装置),便携式计算机盘盒(磁装置),随机存取存储器(RAM),只读存储器(ROM),可擦除可编辑只读存储器(EPROM或闪速存储器),光纤装置,以及便携式光盘只读存储器(CDROM)。另外,计算器可读介质甚至可以是可在其上打印程序的纸或其他合适的介质,因为可以通过对纸或其他介质进行光学扫描,接着进行编辑、解译或必要时以其他合适方式进行处理来以电子方式获得程序,然后将其存储在计算机存储器中。
应当理解,本发明的各个部分可以用硬件、软件、固件或它们的组合来实现。在上述实施方式中,多个步骤或方法可以用存储在存储器中且由合适的指令执行系统执行的软件或固件来实现。例如,如果用硬件来实现,和在另一实施方式中一样,可用本领域公知的下列技术中的任一项或他们的组合来实现:具有用于对数字信号实现逻辑功能的逻辑门电路的离散逻辑电路,具有合适的组合逻辑门电路的专用逻辑电路,可编程门阵列(PGA),现场可编程门阵列(FPGA)等。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 一种法律法规名称识别装置及方法
- 一种对象名称识别方法及装置