一种基于机器学习的材料均匀延伸率预测方法
文献发布时间:2023-06-19 11:21:00
技术领域
本发明涉及一种基于机器学习的材料均匀延伸率预测方法,属于材料性能预测研究领域。
背景技术
通过将金属材料晶粒细化到超细晶或纳米晶层次,通常可以获得比粗晶金属更优异的力学和物理性能,如超细晶/纳米晶材料的强度和硬度可以大大提高,是相同成分粗晶材料的几倍甚至几十倍。但强化机制通常会牺牲延性,导致延伸率大幅降低,这严重限制了超细晶/纳米晶材料的工程应用。而双峰结构金属在不明显降低屈服强度的同时,可以显著提高均匀延伸率,可以突破传统均质金属强度—延性的倒置曲线。
影响双峰结构金属力学性能的因素主要有细晶尺寸、粗细晶尺寸比、粗晶体积分数。传统研究主要通过实验或晶体塑性方法来获取双峰结构金属的均匀延伸率等力学性能,原始成本和时间成本较多,且无法倒推双峰金属特定力学性能所对应的微观结构。因此需要一种快速、合理的新方法来有效预测双峰结构金属的力学性能。
发明内容
本发明的目的在于提供一种基于机器学习的材料均匀延伸率预测方法,从而以较小的误差预测双峰结构金属的均匀延伸率。
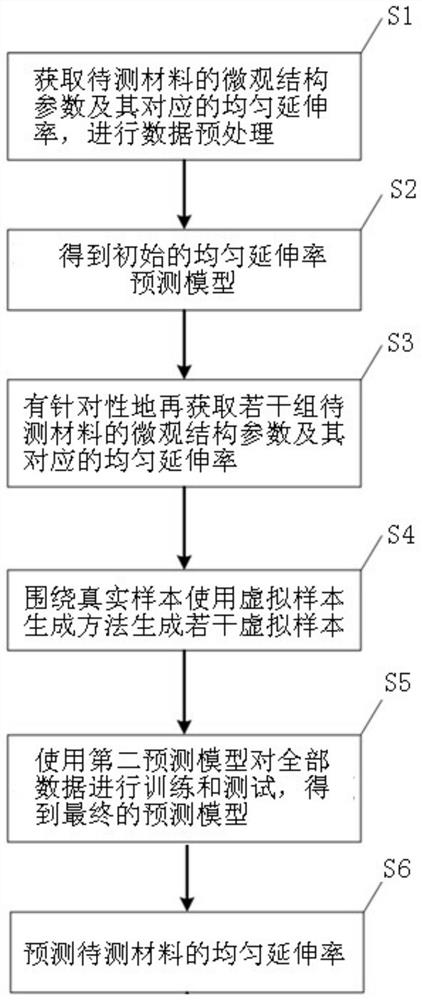
为了实现上述目的,本发明提供一种基于机器学习的材料均匀延伸率预测方法,包括:
S1:初步获取p组待测材料的微观结构参数及其对应的均匀延伸率,进行数据预处理,得到标准数据集;
S2:根据所述标准数据集对第一极限学习机模型进行训练和测试,得到初始的均匀延伸率预测模型;
S3:根据初始的均匀延伸率预测模型的预测结果,有针对性地再获取r组待测材料的微观结构参数及其对应的均匀延伸率,得到含有多个真实样本的真实数据集,并根据所述真实数据集得到第二均匀延伸率预测模型;
S4:在真实数据集的基础上,利用结合粒子群优化算法的虚拟样本生成方法,围绕一部分真实样本生成u个虚拟样本;
S5:使用第二均匀延伸率预测模型对真实样本和虚拟样本共同进行训练和测试,得到最终的均匀延伸率预测模型;
S6:利用待测材料的微观结构参数和最终的均匀延伸率预测模型预测待测材料的均匀延伸率。
所述步骤S1包括:
S11:利用晶体塑性方法获取p组待测材料的微观结构参数及其对应的均匀延伸率,每一组双峰结构金属的微观结构参数和均匀延伸率作为一组原始数据,p组原始数据形成原数据集;对原数据集中的所有数据进行归一化处理,形成初始数据集;
S12:利用微观结构参数计算中间计算参数,并对中间计算参数进行归一化处理,将归一化后的中间计算参数分别作为一个维度的数据添加到初始数据集中,形成标准数据集;
S13:将标准数据集随机分为70%的第一训练集和30%的第一测试集。
所述待测材料为双峰结构金属;在所述步骤S1中,所述微观结构参数包括双峰结构金属的细晶尺寸、粗细晶尺寸比、粗晶体积分数这3个维度的数据,所述中间计算参数包括双峰结构金属中细晶对应的屈服强度σ
所述步骤S2包括:
S21:设置一个第一极限学习机模型的神经元个数,其中输入层的神经元个数等于微观结构参数和中间计算参数的维度数量,输出层的神经元个数为1,隐藏层的神经元个数通过人为设定q个不同的值,以获得q个不同的第一极限学习机模型;q为大于1的正整数;
S22:将第一训练集中的微观结构参数和中间计算参数作为第一极限学习机模型的输入,均匀延伸率作为第一极限学习机模型的输出,对q个第一极限学习机模型均进行训练,得到q个训练好的第一极限学习机模型;
S23:利用第一测试集的微观结构参数、中间计算参数和均匀延伸率对q个训练好的第一极限学习机模型进行测试,确定q个训练好的第一极限学习机模型各自的平均绝对百分比误差;
平均绝对百分比误差MAPE为:
其中,n
S24:对各个训练好的第一极限学习机模型的平均绝对百分比误差进行比较,确定使平均绝对百分比误差最小的隐藏层的神经元个数a,设定初始的均匀延伸率预测模型的隐藏层的神经元个数为a。
所述步骤S3包括:
S31:进行待测材料的微观结构参数的多个维度的全因子分析,水平数设置为s,进而获得s
S32:对新的微观结构数据集中的所有数据进行归一化处理,形成新的初始微观结构数据集;
S33:将新的标准微观结构数据集的微观结构参数和中间计算参数作为输入,利用初始的均匀延伸率预测模型对其进行均匀延伸率预测,每一组微观结构参数均重复预测多次来得到对应的多个均匀延伸率的预测值;
S34:分别计算新的标准微观结构数据集中的每一组微观结构参数和中间计算参数对应的多个均匀延伸率的预测值的方差值;选取r组最大的方差值所对应的微观结构参数,分别获取其中间计算参数和利用晶体塑性方法获取其均匀延伸率,并将微观结构参数、中间计算参数和均匀延伸率均进行归一化处理,形成补充数据集;
S35:结合所述步骤S1的标准数据集和所述步骤S34的补充数据集,形成真实数据集;
S36:将真实数据集随机分为70%的第二训练集和30%的第二测试集,通过试参法设置不同的隐藏层的神经元个数,使用第二训练集的数据对一第二极限学习机模型进行训练,使用第二测试集的数据对所述第二极限学习机模型进行测试;确定使平均绝对百分比误差最小的第二极限学习机模型的隐藏层的神经元个数b;设定第二均匀延伸率预测模型的隐藏层的神经元个数为b,并将此时第二极限学习机模型的权重矩阵和偏置向量保存为第二均匀延伸率预测模型的权重矩阵和偏置向量。
在所述步骤S4中,围绕第二训练集中的每一个真实样本生成u个虚拟样本。
所述步骤S4包括:
S41:将真实数据集中的微观结构参数和中间计算参数均作为虚拟样本的输入参数,并确定虚拟样本的所有输入参数的上界和下界;
S42:随机选定真实数据集中的一个真实样本,初始化粒子群优化算法的最大迭代次数和种群规模;初始化待生成的虚拟样本的所有输入参数并将该输入参数作为粒子的空间位置,根据步骤S41确定的下界和上界对粒子的空间位置的取值范围进行约束,此时粒子的迭代次数为1;
S43:利用步骤S3的第二均匀延伸率预测模型根据所述粒子的空间位置进行预测,得到待生成的虚拟样本的输出参数的预测值,并得到粒子的适应度;
S44:增加粒子的迭代次数,使用粒子群优化算法对粒子的位置和速度进行更新;
S45:再次确定粒子的适应度,更新每个粒子的个体极值和所有粒子的全局极值;
S46:重复所述步骤S44和步骤S45,直到迭代次数满足预设的最大迭代次数T
S47:将此时所有粒子的全局极值作为生成的虚拟样本的输入参数;通过第二均匀延伸率预测模型对输入参数进行预测,得到对应的输出参数;将输入参数和输出参数结合,以得到一个完整的虚拟样本;
S48:重复步骤S42—步骤S47,直到围绕第二训练集中的每一个真实样本生成u个虚拟样本。
所述步骤S41包括:
S41:描述真实数据集中所有输入参数的每一维变量的中间位置;
所有输入参数的每一维变量的中间位置为:
其中,真实数据集中的第k组真实样本中的所有输入参数的第i维变量,CL
步骤S42:确定虚拟样本所有输入参数的第i维变量的上界和下界;
虚拟样本所有输入参数的第i维变量的上界和下界为:
其中,LB
在所述步骤S43和步骤S45中,粒子的适应度为:
其中,x
所述步骤S5包括:
S51:将所述真实数据集中的数据随机分为70%的第三训练集和30%的第三测试集;将第三训练集和虚拟样本结合,构成第四训练集;
S52:将第四训练集中的微观结构参数和中间计算参数作为所述第二均匀延伸率预测模型的输入,均匀延伸率作为所述第二均匀延伸率预测模型的输出,对一第三极限学习机模型进行训练;
S53:利用第三测试集的数据对第三极限学习机模型进行测试,计算其平均绝对百分比误差;保存经过训练和测试的第三极限学习机模型的权重矩阵和偏置向量,得到最终的均匀延伸率预测模型。
p在20-50之间;r在5-20之间;且u在1-10之间。
本发明的基于机器学习的材料均匀延伸率预测方法,(1)通过训练和测试选取合适的ELM模型,可以以较小的误差预测特定细晶尺寸、粗细晶尺寸比、粗晶体积分数的微观结构所对应的均匀延伸率,比传统实验手段或晶体塑性模拟方法得到均匀延伸率,可以节省材料成本和时间成本;(2)通过有针对性地再获取若干组待测材料的微观结构参数及其对应的均匀延伸率,可以以较少的工作量提高模型的预测精度;(3)通过使用结合PSO算法的虚拟样本生成方法,可以有效地减少真实数据之间的信息隔阂,减少预测误差;(4)引入的细晶和粗晶分别对应的Hall-Petch项是一个非线性函数,可以有效地增加标准数据集的维度,增加标准数据集的原始信息,从而提高ELM模型的预测精度。
附图说明
图1为根据本发明的一个实施例的基于机器学习的材料均匀延伸率预测方法的流程图;
图2为根据本发明的一个实施例的第一ELM模型的隐藏层的不同神经元个数的预测误差示意图;
图3为根据本发明的一个实施例的利用第一ELM模型得到的初始数据集的均匀延伸率的预测值和相对应的通过晶体塑性方法得到的均匀延伸率的对比图,其中第一ELM模型的隐含层神经元个数设置为10;
图4为根据本发明的一个实施例的第二ELM模型的隐藏层的不同神经元个数对真实数据集和初始数据集的预测误差对比示意图;
图5为根据本发明的一个实施例的利用第二均匀延伸率预测模型得到的真实数据集的均匀延伸率的预测值和相对应的通过晶体塑性方法得到的均匀延伸率的对比图,其中第二均匀延伸率预测模型的隐含层神经元个数设置为10;
图6为根据本发明的一个实施例的真实数据集的第二训练集中每个真实样本生成6个虚拟样本后,根据步骤S5训练时得到的MAPE图;为更明显地展示加入虚拟样本后有利于减少预测误差,特将隐藏层的神经元个数为5和20的结果也展示其中;
图7为根据本发明的一个实施例的经过真实样本和虚拟样本训练和测试后得到的最终ELM模型和已发表文献中的实验均匀延伸率的对比结果。
具体实施方式
下面对本发明的实施例作详细说明,本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
如图1所示为根据本发明的一个实施例的基于机器学习的材料均匀延伸率预测方法。
本发明的基于机器学习的材料均匀延伸率预测方法主要基于以下的理论基础和假设:(1)采用合理且现有的晶体塑性方法获取待测材料的微观结构参数及其对应的均匀延伸率;(2)ELM模型具有良好的非线性拟合能力和泛化能力,可以较好地预测输出;(3)引入的Hall-Petch项是非线性函数,可以有效增加原始数据的维度,增加原始数据的信息量;(4)添加合适的虚拟样本有利于提高机器学习模型的预测精度。
在本实施例中,所述预测方法具体用于预测双峰结构低碳钢单轴拉伸的均匀延伸率。此外,在其他实施例中,本发明的预测方法还可以用于预测其他材料的均匀延伸率,例如,还可以适用于层片(lamellar)结构、谐波(harmonic)结构等结构的材料。ELM模型训练和测试内容基于MATLAB平台。完成步骤S1—S5,则实现了双峰结构金属单轴拉伸时的均匀延伸率预测。
请参阅图1,基于机器学习的材料均匀延伸率预测方法包括以下步骤:
步骤S1:初步获取p组待测材料的微观结构参数及其对应的均匀延伸率,进行数据预处理,得到标准数据集。其中,p一般在20-50之间。在本实施例中,p=40。
其中,所述步骤S1具体包括以下步骤:
步骤S11:利用晶体塑性方法,获取p组待测材料的微观结构参数及其对应的均匀延伸率,每一组双峰结构金属的微观结构参数和均匀延伸率作为一组原始数据,得到p组原始数据并作为原数据集;随后,为避免具有不同物理意义和量纲的微观结构参数和均匀延伸率不能平等使用,需要对原数据集中的所有数据进行归一化处理,形成初始数据集;
在本实施例中,所述待测材料为双峰结构金属,且所述微观结构参数包括双峰结构金属的细晶尺寸、粗细晶尺寸比、粗晶体积分数这3个维度的数据。
晶体塑性方法为现有技术,在本实施例中,所利用的晶体塑性方法基于如申请号为CN201911016500.3的专利文件所公开的晶体的弹塑性本构方程。即,晶体塑性方法基于ABAQUS软件平台,建立不同细晶尺寸、粗细晶尺寸比、粗晶体积分数的双峰结构模型,结合用户材料子程序UMAT,计算得到均匀延伸率,从而构成真实数据集。其中用户材料子程序UMAT的晶体塑性方法的合理性已在文献[Zhang Y,et al.A modified kinematichardening model considering hetero-deformation induced hardening for bimodalstructure based on crystal plasticity[J].International Journal of MechanicalSciences,2021,191:106068]中得到验证。
虽然现有技术中,已经可以通过晶体塑性方法来得到待测材料均匀延伸率的仿真结果,但是该方法往往耗时比较长晶体塑性方法所需的时间一般以小时为单位;而采用传统实验手段来得到待测材料的均匀延伸率,则不仅需要耗费时间还需要耗费待测材料。本发明的方法通过对待测材料的仿真结果进行学习,可以节约计算时间,ELM模型预测所需时间一般以秒为单位。
原数据集中的数据的归一化公式为:
其中,x是归一化后的数据,x
步骤S12:利用微观结构参数计算中间计算参数,并对中间计算参数进行归一化处理,将归一化后的中间计算参数分别作为一个维度的数据添加到初始数据集中,形成标准数据集;
在本实施例中,由于待测材料为双峰结构金属,因此中间计算参数包括双峰结构金属中细晶对应的屈服强度σ
σ
σ
其中,σ
步骤S13:将标准数据集随机分为70%的第一训练集和30%的第一测试集;
步骤S2:根据所述标准数据集对第一极限学习机模型进行训练和测试,得到初始的均匀延伸率预测模型;
在所述步骤S2中,初始的均匀延伸率预测模型是通过试参法和所述第一测试集确定第一极限学习机模型的隐含层的神经元个数,进而得到的。
所述步骤S2包括:
步骤S21:设置一个第一ELM(极限学习机)模型的神经元个数,其中输入层的神经元个数等于微观结构参数和中间计算参数的维度数量(在本实施例中,输入层的神经元个数为5),输出层的神经元个数为1,隐藏层的神经元个数通过人为设定q个不同的值,以获得q个不同的第一极限学习机模型;q为大于1的正整数;
在本实施例中,q=5,隐藏层的神经元个数分别人为设定为5、10、15、20、25,进而获得5个不同的ELM模型;
步骤S22:将第一训练集中的微观结构参数和中间计算参数作为第一ELM模型的输入,均匀延伸率作为第一ELM模型的输出,对q个第一ELM模型均进行训练,得到q个训练好的第一ELM模型;
步骤S23:利用第一测试集的微观结构参数、中间计算参数和均匀延伸率对q个训练好的第一ELM模型进行测试,确定q个训练好的第一ELM模型各自的平均绝对百分比误差MAPE;平均绝对百分比误差MAPE的数学表达式为:
其中,n
步骤S24:如图2所示,对各个训练好的第一ELM模型的平均绝对百分比误差进行比较,确定使平均绝对百分比误差最小的隐藏层的神经元个数a,设定初始的均匀延伸率预测模型的隐藏层的神经元个数为a。由此,得到了形式为ELM模型的初始的均匀延伸率预测模型,以进行后续操作。在本实施例中,平均绝对百分比误差最小的第一ELM模型的隐藏层的神经元个数为10。
步骤S3:根据初始的均匀延伸率预测模型的预测结果,有针对性地再获取r组待测材料的微观结构参数及其对应的均匀延伸率,得到含有多个真实样本且分为第二训练集和第二测试集的真实数据集,并根据所述真实数据集得到第二均匀延伸率预测模型;
其中,r一般在5-20之间;在本实施例中,r=10。
所述S3步骤包括:
步骤S31:使用Minitab软件进行待测材料的微观结构参数的多个维度(即细晶尺寸、粗细晶尺寸比、粗晶体积分数3个维度)的全因子分析,水平数设置为s(即微观结构参数的每个维度分别设置s个数值),进而获得s
水平数s可以设置在2-10之间,在本实施例中,水平数s设置为6,具体为:细晶尺寸的6个数值为0.29um,0.84um,1.39um,1.94um,2.49um,3.04um;粗细晶粒尺寸比的6个数值为3,4.4,5.8,7.2,8.6,10;粗晶体积分数的6个数值为15%,21%,27%,33%,39%,45%。将3个因子的6个数值进行随机组合,获得216组双峰结构金属的微观结构数据,形成新的微观结构数据集;在本实施例中,微观结构参数的每个维度设置的6个数值之间的保持等间隔,可以使初始的均匀延伸率预测模型的输入尽可能地遍历整个空间。微观结构参数的每个维度设置的6个数值的最大值和最小值是根据经验选定的,一般的双峰结构参数就集中在这个范围。
步骤S32:对新的微观结构数据集中的所有数据进行归一化处理,以形成新的标准微观结构数据集;
步骤S33:将新的标准微观结构数据集的微观结构参数和中间计算参数作为输入,利用初始的均匀延伸率预测模型对其进行均匀延伸率预测,每一组微观结构参数均重复预测10次(一共预测2160次)来得到对应的10个均匀延伸率的预测值;
由于每次ELM模型的权重矩阵和偏置向量均为随机赋予,因此每次记录的预测微观结构对应的均匀延伸率均有所不同;此外,在其他实施例中,重复预测的次数也可以根据需要进行调整,只要满足重复预测的次数为多次即可。
步骤S34:分别计算新的标准微观结构数据集中的每一组微观结构参数和中间计算参数(共s
由此,该补充数据集包括归一化后的微观结构参数、中间计算参数和均匀延伸率。
步骤S35:结合所述步骤S1的标准数据集和所述步骤S34的补充数据集,形成真实数据集;
由此,真实数据集中真实样本的总组数为t组,t=p+r;在本实施例中,由于p=40且r=10,因此真实数据集中真实样本的总组数为50组。
步骤S36:将真实数据集随机分为70%的第二训练集和30%的第二测试集,通过试参法设置不同的隐藏层的神经元个数,使用第二训练集的数据对一第二ELM模型进行训练,使用第二测试集的数据对所述第二ELM模型进行测试;确定使平均绝对百分比误差MAPE最小的第二ELM模型的隐藏层的神经元个数b;设定第二均匀延伸率预测模型的隐藏层的神经元个数为b,并将此时第二ELM模型的权重矩阵和偏置向量保存为第二均匀延伸率预测模型的权重矩阵和偏置向量,从而得到第二均匀延伸率预测模型;由此进行后续操作。
在本实施例中,由于真实数据集中真实样本的总组数为50组,因此第二训练集中具有35组真实样本,第二测试集具有15组真实样本。需要说明的是,b的大小可以与a不同。
步骤S4:在真实数据集的基础上,利用结合粒子群优化(PSO)算法的虚拟样本生成方法,围绕一部分真实样本生成u个虚拟样本;
在本实施例中,具体是围绕第二训练集中的每一个真实样本生成u个虚拟样本;u一般在1-10之间,在本实施例中,u=6。
所述步骤S4包括:
步骤S41:将真实数据集中的微观结构参数和中间计算参数均作为虚拟样本的输入参数,并确定虚拟样本的所有输入参数的上界和下界;
其中,所述步骤S41包括:
步骤S411:描述真实数据集中所有输入参数的每一维变量的中间位置;
所有输入参数的每一维变量的中间位置为:
其中,x
步骤S412:通过公式(6)—(9)确定待生成的虚拟样本所有输入参数的第i维变量的上界和下界:
其中,LB
步骤S42:随机选定真实数据集中的一个真实样本,初始化粒子群优化(PSO)算法的最大迭代次数和种群规模;初始化粒子的空间位置,即初始化待生成的虚拟样本的所有输入参数并将该输入参数作为粒子的空间位置,根据步骤S41确定的下界和上界对粒子的空间位置的取值范围进行约束,此时粒子的迭代次数为1;由此,处于不同位置的粒子有不同的输入参数的数值。
在本实施例中,最大迭代次数T
步骤S43:利用步骤S3的第二均匀延伸率预测模型根据所述粒子的空间位置进行预测,得到待生成的虚拟样本的输出参数的预测值,并得到粒子的适应度;
其中,粒子的适应度为:
其中,x
步骤S44:增加粒子的迭代次数,使用粒子群优化(PSO)算法对粒子的位置和速度进行更新;
其中,更新公式如下:
其中,
在每一轮迭代中,惯性权重ω(k)为:
ω(k)=ω
其中,ω(k)为每次迭代的惯性权重,ω
步骤S45:根据公式(10)再次确定粒子的适应度,更新每个粒子的个体极值和所有粒子的全局极值;
步骤S46:重复所述步骤S44和步骤S45,直到迭代次数满足预设的最大迭代次数T
步骤S47:将此时所有粒子的全局极值(也就是最佳粒子的空间位置)作为生成的虚拟样本的输入参数;通过第二均匀延伸率预测模型对输入参数进行预测,得到对应的输出参数,即均匀延伸率;将输入参数和输出参数结合,以得到一个完整的虚拟样本;
步骤S48:重复步骤S42—步骤S47,直到围绕第二训练集中的每一个真实样本生成u个虚拟样本。
在本实施例中,根据步骤S4可以生成第二训练集中的35组真实样本所对应的210组虚拟样本数据。需要说明的是,尽管直接用晶体塑性方法得到对应的输出参数的方法精度是会更高,但这种方法的时间成本太大,通常需要花费1-2天;而本发明通过第二均匀延伸率预测模型预测对应的输出参数则要快得多,一般只需要几秒钟时间,因而降低了时间成本。
步骤S5:使用第二均匀延伸率预测模型对真实样本和虚拟样本共同进行训练和测试,得到最终的均匀延伸率预测模型;
所述S5步骤包括:
步骤S51:将所述真实数据集中的真实样本随机分为70%的第三训练集和30%的第三测试集;将第三训练集和虚拟样本结合,构成第四训练集;
步骤S52:将第四训练集中的微观结构参数和中间计算参数(即σ
步骤S53:利用第三测试集的数据对第三ELM模型进行测试,计算其平均绝对百分比误差MAPE;保存经过训练和测试的第三ELM模型的权重矩阵和偏置向量,得到最终的均匀延伸率预测模型;
步骤S6:利用待测材料的微观结构参数和最终的均匀延伸率预测模型预测待测材料的均匀延伸率。由此,最终实现在已知待测材料的微观结构参数的条件下,较为快速、准确地预测均匀延伸率的目的。
实验结果:
通过本实施例,能够获得如下预测结果:
1、第一ELM模型的隐藏层的不同神经元个数对初始数据集的预测精度。
通过步骤S1和步骤S2可以得到图2。图2为使用不同隐含层神经元个数的第一ELM模型对初始数据集的40组真实样本进行训练和预测的结果图,预测精度以平均绝对百分比误差MAPE指标体现。
2、第一ELM模型对初始数据集的预测结果
图3为隐藏层的神经元个数为10时,利用第一ELM模型得到的初始数据集的均匀延伸率的预测值和相对应的通过晶体塑性方法得到的均匀延伸率的直观对比图,其中横坐标为通过晶体塑性方法得到的均匀延伸率仿真结果,纵坐标为机器学习预测的均匀延伸率结果。
3、第二ELM模型的隐藏层的不同神经元个数对真实数据集的预测精度。
通过步骤S3和步骤S4可以得到图4。图4为使用不同隐含层神经元个数的第二ELM模型对真实数据集(50组样本)和初始数据集(40组样本)的预测误差对比示意图,预测精度以平均绝对百分比误差指标体现。由此可以得到预测误差最小的第二均匀延伸率预测模型。
4、第二均匀延伸率预测模型对真实数据集的预测结果
图5为隐藏层的神经元个数为10时,第二均匀延伸率预测模型对真实数据集的50组真实样本进行训练和预测的直观对比图,其中横坐标为通过晶体塑性方法得到的均匀延伸率仿真结果,纵坐标为机器学习预测的均匀延伸率结果。
5、加入虚拟样本后对第二均匀延伸率预测模型的预测精度影响
图6为本发明的一个实施例的真实数据集的第二训练集中每个真实样本生成6个虚拟样本后,根据步骤S5训练时得到的MAPE图,并且示出了第二均匀延伸率预测模型对加入虚拟样本前后的MAPE的比较;为更明显地展示加入虚拟样本后有利于减少预测误差,特将隐藏层的神经元个数为5和20的结果也展示其中。
6、最终的均匀延伸率预测模型和已发表文献中的实验均匀延伸率的对比结果
图7为最终的均匀延伸率预测模型根据已发表文献[Patra S,et al.Effect ofbimodal distribution in ferrite grain sizes on the tensile properties of low-carbon steels[J].Materials Science and Engineering A,2012,538:145-155]中的微观结构参数进行均匀延伸率预测,其中点1的微观结构参数为:细晶尺寸7.1um,粗细晶尺寸比7.54,粗晶体积分数24%;点2的的微观结构参数为:细晶尺寸3.8um,粗细晶尺寸比8.68,粗晶体积分数36%;点3的的微观结构参数为:细晶尺寸2.6um,粗细晶尺寸比16.15,粗晶体积分数40%。其说明了本发明的预测结果误差很小。
以上记载的,仅为本发明的较佳实施例,并非用以限定本发明的范围,本发明的上述实施例还可以做出各种变化。即凡是依据本发明申请的权利要求书及说明书内容所作的简单、等效变化与修饰,皆落入本发明专利的权利要求保护范围。
- 一种基于机器学习的材料均匀延伸率预测方法
- 一种基于机器学习的材料屈服强度预测方法