方面级情感分析方法
文献发布时间:2023-06-19 11:26:00
技术领域
本发明涉及自然与然处理的情感分析领域,具体地说,涉及细粒度情感分析方法。
背景技术
社交媒体和电商平台的快速发展,越来越多的网络用户愿意在网络发表自己对某件事情或商品的评价,这些看法中包含用户的情感信息。因此,对各大平台上带有情感倾向的言论和评价进行分析,可以带来多方面的效益,例如消费者可以根据购物网站的商品评价详细了解商品信息;企业可以通过监控社交媒体的用户评价修改营销信息、品牌定位、产品开发;股民根据评价选择是否买入股票。所以,情感分析是一种具有很大实际应用价值的文本分类技术,被广泛的应用于产品反馈、舆情监控、股市预测和电影票房预测等方面。对含有情感色彩的文本进行情感极性判断具有巨大的商业价值和社会价值,这些实际价值推动了文本情感分析的研究。
文本情感分析(Sentiment Analysis,SA)指利用自然语言处理和文本挖掘技术对带有情感色彩的主观性文本进行分析、处理和抽取的过程。通过对用户评论文本中的情感信息进行分析,可以抽取用户的情感态度。SA一般分为三个层次,文档级(document-level)、句子级(sentence-level)和方面级(aspect-level)。其中,文档级主要是对整个文本进行文本特征抽取并获得其情感倾向,句子级主要针对某个单独的句子分析其情感倾向,方面级则针对某一句子中不同的属性表达的不同的情感倾向。文档级和句子级的情感分析是较粗粒度的情感分析,情感分析的前提是假设整个文本或句子只表达了一种情感,即积极的或者消极的情感,这两类任务已经取得了非常好的效果。方面级情感分析(Aspect-based Sentiment Analysis,ABSA)是细粒度情感分析,它直接关注的是句子中每个方面的情感倾向而不只是句子的结构,有助于更好的解决SA问题。
方面级情感分析旨在捕捉用户生成的评论中对产品、电影、公司等实体的不同方面所表达的情感,在细粒度层次上解决各种情感分析任务,包括方面抽取(AspectExtraction,AE)、意见抽取(Opinion Extraction,OE)、方面情感分类(Aspect SentimentClassification,ASC)等。方面(Aspect)是一个实体的属性。例如:“The waiter isfriendly while the pizza is very bad”中,AE抽取的是“waiter”和“pizza”,ASC将它们分为积极情感和消极情感,OE抽取的是“friendly”和“bad”。三者一起完成细粒度情感分析,即所讨论的方面、对它的情感倾向,以及该情感倾向产生的原因。
发明内容
基于方面的情感分析(ABSA)是指在细粒度级别处理各种情感分析任务,包括但不限于方面提取、方面情感分类和意见提取。本发明将三个字任务结合在一起,实现对文本讨论的方面、对它的情感倾向,以及该情感倾向产生的原因。
为实现上述目的,本发明提供方面级情感分析方法,其方法步骤如下:
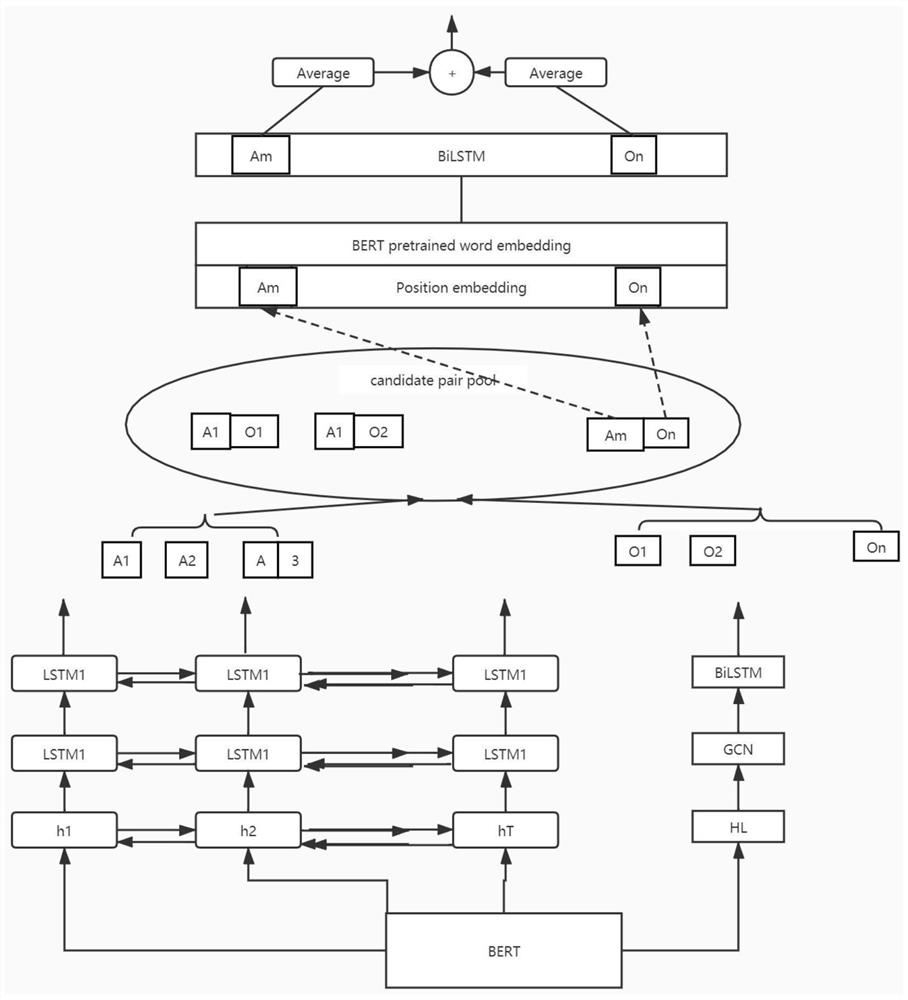
输入层:输入层通过Bert模型将文本进行向量化,token embedding层将每一个词转换成向量形式,segment embeddings层对句子个数进行编码,position Embeddings为每个字向量提供位置表示,Bert模型Transformer作为算法的主要框架,Transformer能更彻底的捕捉语句中上下文的词特征;
方面词-情感倾向联合抽取:方面词-情感倾向联合抽取模型通过两个堆叠的双向LSTM网络,下层网络进行边界标签预测,上层网络进行方面词-情感倾向联合标注;
意见词抽取:通过GCN和双向LSTM堆叠的网络中进行意见词抽取,GCN的邻接矩阵是基于句子的依赖程度构建的,通过GCN可获取方面词与意见词之间的依赖关系,将GCN的输出送入双向LSTM网络中进行上下文信息编码,得到意见词标注信息,意见词标签为A
方面词和意见词匹配:将方面词和意见词通过基于距离的方法得到有效配对,把通过方面词-情感倾向联合抽取模型得到的方面词序列和通过意见词抽取得到的意见词序列通过枚举的方式两两配对形成方面-意见对,用方面词和意见词的距离信息编码他们的位置关系,的都位置索引,将位置索引与H
本实施例中的,所述输入层的输入序列为:
x=x
作为本技术方案的改进,所述输入层向量化步骤如下:
Bert层将输入序列打包为:
H
e
通过12个Transformer层的Bert计算输入标记的相应上下文表示:
第L(L∈[1,12])层的表示为:
计算H
作为本技术方案的改进,所述方面词-情感倾向抽取步骤如下:
通过Bert得到长度为T的输入序列
下层BiLSTM
上层BiLSTM
分别用softmax进行预测,对下层BiLSTM
对上层BiLSTM
通过过渡矩阵W
B
为防止
为防止由多词组成的方面词出现不同的情感倾向,引入门控机制,在预测当前词的情感倾向标签时,用前一状态的特征和这一状态的特征共同进行预测:
W
作为本技术方案的改进,所述意见词抽取步骤如下:
通过Bert得到长度为T的输入序列
意见词标签为:A
GCN学习单词之间的依赖关系,GCN的邻接矩阵是基于句子的依赖程度构建的,即W
BiLSTM
作为本技术方案的改进,所述方面词和意见词匹配步骤如下:
经过方面词-情感倾向抽取和意见词抽取后分别得到两个序列,记为:
{A
表示有n个方面词-情感倾向和m个意见词;
枚举方式形成候选对:{(A
计算方面词与意见词之间的距离来编码它们之间的位置关系,得到位置索引;
将Bert输出
把词向量送入BiLSTM层学习距离信息,并将其发送到softmax层进行二进制分类,得到有效配对。
与现有技术相比,本发明的有益效果:
1.研究提出一种基于方面词、情感倾向和意见词三元抽取方法。在这一阶段中,使用Bert模型将文本向量化,将用于方面词和情感倾向联合标注模型与用于意见词标注的BIESO模型耦合在一起。对于方面词和情感倾向联合标注模型,它建立在两个堆叠的双向长短期记忆网络(BiLSTM)网络之上。上一个产生方面词和情感倾向的标注结果。下层主要针对多个单词组成的方面词进行边界预测。意见词标注模型建立在BiLSTM层和GCN之上,充分利用句子中的语义和句法信息。Pontiki等人认为,方面词应当与表明其情感倾向的意见词一同出现。因此,设计了一个目标引导模块传递信息,用于意见词的抽取。
2.提出了一种基于距离的目标词和情感词匹配算法。在第一阶段得到两个序列,分别为(方面词-情感倾向)和(意见词),这一阶段的目标是将两个方面词与与意见词配对。单词之间的距离对于正确配对方面词和情感词是非常具有指示性的。因此,通过距离嵌入获取方面词和意见词之间的距离,使用BiLSTM编码器,将句子上下文编码成方面词和意见词,用于对句子对的最终分类。
附图说明
图1为实施例1方面级情感分析技术的流程框图;
图2为例1实施Bert向量化的流程框图;
图3为例1实施方面词-情感倾向抽取的流程框图;
图4为例1实施意见词抽取的流程框图;
图5为例1实施方面词与意见词匹配的流程框图;
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1
请参阅图1-图5所示,本实施例提供方面级情感分析方法,其方法步骤如下:
输入层:输入层通过Bert模型将文本进行向量化,token embedding层将每一个词转换成向量形式,segment embeddings层对句子个数进行编码,position Embeddings为每个字向量提供位置表示,Bert模型Transformer作为算法的主要框架,Transformer能更彻底的捕捉语句中上下文的词特征;
方面词-情感倾向联合抽取:方面词-情感倾向联合抽取模型通过两个堆叠的双向LSTM网络,下层网络进行边界标签预测,上层网络进行方面词-情感倾向联合标注;
意见词抽取:通过GCN和双向LSTM堆叠的网络中进行意见词抽取,GCN的邻接矩阵是基于句子的依赖程度构建的,通过GCN可获取方面词与意见词之间的依赖关系,将GCN的输出送入双向LSTM网络中进行上下文信息编码,得到意见词标注信息,意见词标签为AOPT={B,I,E,S,O};
方面词和意见词匹配:将方面词和意见词通过基于距离的方法得到有效配对,把通过方面词-情感倾向联合抽取模型得到的方面词序列和通过意见词抽取得到的意见词序列通过枚举的方式两两配对形成方面-意见对,用方面词和意见词的距离信息编码他们的位置关系,的都位置索引,将位置索引与H
本实施例中的,所述输入层的输入序列为:
x={x
作为本技术方案的改进,所述输入层向量化步骤如下:
Bert层将输入序列打包为:
H
e
通过12个Transformer层的Bert计算输入标记的相应上下文表示:
第L(L∈[1,12])层的表示为:
计算H
作为本技术方案的改进,所述方面词-情感倾向抽取步骤如下:
通过Bert得到长度为T的输入序列
下层BiLSTMΓ进行边界标签预测,公式为:
上层BiLSTM
分别用softmax进行预测,对下层BiLSTM
对上层BiLSTM
通过过渡矩阵W
B
为防止
为防止由多词组成的方面词出现不同的情感倾向,引入门控机制,在预测当前词的情感倾向标签时,用前一状态的特征和这一状态的特征共同进行预测:
W
作为本技术方案的改进,所述意见词抽取步骤如下:
通过Bert得到长度为T的输入序列
意见词标签为:A
GCN学习单词之间的依赖关系,GCN的邻接矩阵是基于句子的依赖程度构建的,即W
BiLSTM
作为本技术方案的改进,所述方面词和意见词匹配步骤如下:
经过方面词-情感倾向抽取和意见词抽取后分别得到两个序列,记为:
{A
表示有n个方面词-情感倾向和m个意见词;
枚举方式形成候选对:{(A
计算方面词与意见词之间的距离来编码它们之间的位置关系,得到位置索引新信息;
将Bert输出
把词向量送入BiLSTM层学习距离信息,并将其发送到softmax层进行二进制分类,得到有效配对。
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的仅为本发明的优选例,并不用来限制本发明,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 基于BERT和方面特征定位模型的方面级情感分析方法及模型
- 基于门控空洞卷积和图卷积的方面级情感分析方法及系统