一种空间定位的方法、系统及设备
文献发布时间:2023-06-19 11:32:36
技术领域
本发明涉及人工智能(artificial intelligence,AI)领域,尤其涉及一种空间定位的方法、系统及设备。
背景技术
随着计算机视觉技术的不断进步,通过对摄像机拍摄的图像进行处理和分析,以解决物理世界的实际问题的应用越来越广泛,这极大的促进了智慧交通、智能安防和智慧城市等行业的发展。
空间定位是计算机视觉的核心技术之一,空间定位是根据摄像机拍摄的图像与物理世界的被拍摄的地理区域之间的映射关系(也称为标定关系),将目标在图像中的位置转换成目标在物理世界的位置的技术。
目前所使用的空间定位的方法通常借助于目标检测技术,根据目标检测获得的目标的检测框在图像中的位置,对目标进行空间定位,这种方法精度不高,误差较大,容易引起各种误判。例如:车辆在靠近实线行驶时被系统误判为压线行驶;机动车、非机动车或行人之间距离偏小造成相撞的误判;车辆在行驶过程中的轨迹抖动,后续无法跟踪和轨迹分析等。
因此,如何实现对目标物体进行准确地空间定位是目前亟待解决的问题。
发明内容
本发明实施例公开了一种空间定位的方法、系统及设备,能够降低成本,提高定位精度。
第一方面,本申请提供一种空间定位的方法,所述方法包括:空间定位系统获取图像,所述图像由设置于地理区域的固定位置的摄像机拍摄得到,所述图像中记录了至少一个待检测目标;空间定位系统输入所述图像至目标定位模型,获得检测结果,其中,所述目标定位模型用于对所述图像中的待检测目标进行定位点检测,所述检测结果包括所述待检测目标在所述图像中的定位点的像素坐标,所述定位点表示所述待检测目标在所述地理区域中的地理位置在所述图像中对应的点;空间定位系统根据所述定位点的像素坐标、以及所述摄像机拍摄的图像与所述地理区域之间的标定关系,确定所述待检测目标的地理坐标。
在本申请提供的方案中,空间定位系统利用目标定位模型对摄像机拍摄的图像中的待检测目标进行定位点检测,可以得到定位点的像素坐标,进而再根据摄像机拍摄的图像与地理区域之间的标定关系,可以得到待检测目标的地理坐标。这样根据摄像机拍摄的图像就可以对待检测目标进行更准确地定位,扩展了适用场景,提高了定位精度。
结合第一方面,在第一方面的一种可能的实现方式中,所述空间定位系统确定初始目标定位模型,所述初始目标定位模型采用一种深度学习模型;该空间定位系统获取多个携带标注信息的样本图像,所述多个样本图像由所述摄像机对所述地理区域进行拍摄得到,所述标注信息包括所述样本图像中记录的目标在所述样本图像中的定位点的像素坐标;空间定位系统利用所述多个携带标注信息的样本图像对所述初始目标定位模型进行训练。
在本申请提供的方案中,空间定位系统提前获取样本图像中记录的目标在样本图像中的定位点的像素坐标,然后利用多个携带定位点像素坐标的样本图像对初始目标定位模型进行训练,以使得训练完成的目标定位模型具备预测图像中记录的目标的定位点的能力,这样可以对输入目标定位模型的待检测图像进行定位点检测,从而可以输出待检测图像中记录的目标的定位点的像素坐标。
结合第一方面,在第一方面的一种可能的实现方式中,空间定位系统获取所述样本图像中记录的目标在所述样本图像中的定位点的像素坐标。
在本申请提供的方案中,目标在样本图像中的定位点的像素坐标的准确性直接影响着目标定位模型的检测性能,因此,为了提高目标定位模型检测的准确性,空间定位系统在对初始模型训练之前,需要准确的获取到样本图像中记录的目标在样本图像中的定位点的像素坐标。
结合第一方面,在第一方面的一种可能的实现方式中,空间定位系统获取所述地理区域的俯视图像,所述俯视图像与所述样本图像为同一时刻采集的数据;然后获取所述样本图像中记录的目标在所述俯视图像中的像素坐标;该空间定位系统根据所述俯视图像与所述地理区域之间的标定关系,获得所述样本图像中记录的目标在所述地理区域中的地理位置;最后,空间定位系统根据所述摄像机拍摄的图像与所述地理区域之间的标定关系,获得所述样本图像中记录的目标在所述样本图像中的定位点的像素坐标。
在本申请提供的方案中,空间标定系统利用俯视图像以及俯视图像与地理区域之间的标定关系,可以得到样本图像中记录的目标在地理区域中的地理位置,又由于俯视图像与样本图像是同一时刻对该地理区域进行采集得到的,因此,可以利用摄像机拍摄的图像与地理区域之间的标定关系,可以获得目标在样本图像中的定位点的像素坐标。
结合第一方面,在第一方面的一种可能的实现方式中,所述目标定位模型还用于对所述图像中的待检测目标进行位置检测和类别检测,所述检测结果还包括所述待检测目标在所述图像中的检测框信息和类别信息,所述检测框信息与所述定位点一一对应。
在本申请提供的方案中,利用目标定位模型对输入的图像进行定位点检测时,对于图像中的每一个待检测目标,不仅需要输出该待检测目标的定位点的像素坐标,还需要用检测框将该待检测目标标注出来,且注明该待检测目标的类型(例如机动车、行人等),每一个检测框对应唯一一个定位点,这样可以避免在待检测目标过多时出现混淆,便于区分。
结合第一方面,在第一方面的一种可能的实现方式中,所述待检测目标在所述地理区域中的地理位置包括所述待检测目标在所述地理区域的垂直投影的中心点的地理坐标。
在本申请提供的方案中,由于待检测目标不是一个点,而是占据一定的空间,因此为了准确表示待检测目标在地理区域中的地理位置,可以用该待检测目标的垂直投影的中心点的地理坐标来表示该待检测目标的地理位置。可选的,对于车辆等接近对称的待检测目标,还可以利用其质心在地理区域的垂直投影点的地理坐标表示该待检测目标的地理位置,且该质心的垂直投影点与待检测目标的垂直投影的中心点为同一点。
第二方面,提供了一种空间定位系统,包括:获取单元,用于获取图像,所述图像由设置于地理区域的固定位置的摄像机拍摄得到,所述图像中记录了至少一个待检测目标;定位点检测单元,用于输入所述图像至目标定位模型,获得检测结果,其中,所述目标定位模型用于对所述图像中的待检测目标进行定位点检测,所述检测结果包括所述待检测目标在所述图像中的定位点的像素坐标,所述定位点表示所述待检测目标在所述地理区域中的地理位置在所述图像中对应的点;处理单元,用于根据所述定位点的像素坐标、以及所述摄像机拍摄的图像与所述地理区域之间的标定关系,确定所述待检测目标的地理坐标。
结合第二方面,在第二方面的一种可能的实现方式中,所述获取单元,还用于获取多个携带标注信息的样本图像,所述多个样本图像由所述摄像机对所述地理区域进行拍摄得到,所述标注信息包括所述样本图像中记录的目标在所述样本图像中的定位点的像素坐标;所述定位点检测单元,还用于确定初始目标定位模型,所述初始目标定位模型采用一种深度学习模型;利用所述多个携带标注信息的样本图像对所述初始目标定位模型进行训练。
结合第二方面,在第二方面的一种可能的实现方式中,所述获取单元,还用于:获取所述样本图像中记录的目标在所述样本图像中的定位点的像素坐标。
结合第二方面,在第二方面的一种可能的实现方式中,所述获取单元,具体用于:获取所述地理区域的俯视图像,所述俯视图像与所述样本图像为同一时刻采集的数据;获取所述样本图像中记录的目标在所述俯视图像中的像素坐标;根据所述俯视图像与所述地理区域之间的标定关系,获得所述样本图像中记录的目标在所述地理区域中的地理位置;根据所述摄像机拍摄的图像与所述地理区域之间的标定关系,获得所述样本图像中记录的目标在所述样本图像中的定位点的像素坐标。
结合第二方面,在第二方面的一种可能的实现方式中,所述目标定位模型还用于对所述图像中的待检测目标进行位置检测和类别检测,所述检测结果还包括所述待检测目标在所述图像中的检测框信息和类别信息,所述检测框信息与所述定位点一一对应。
结合第二方面,在第二方面的一种可能的实现方式中,所述待检测目标在所述地理区域中的地理位置包括所述待检测目标在所述地理区域的垂直投影的中心点的地理坐标。
第三方面,提供了一种计算设备,所述计算设备包括处理器和存储器,所述存储器用于存储程序代码,所述处理器用于所述存储器中的程序代码执行上述第一方面以及结合上述第一方面中的任意一种实现方式的方法。
第四方面,提供了计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,当该计算机程序被处理器执行时,所述处理器执行上述第一方面以及结合上述第一方面中的任意一种实现方式所提供的空间标定方法。
第五方面,提供了一种计算机程序产品,该计算机程序产品包括指令,当该计算机程序产品被计算机执行时,使得计算机可以执行上述第一方面以及结合上述第一方面中的任意一种实现方式所提供的空间标定方法的流程。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本申请实施例提供的一种利用目标检测实现目标定位的示意图;
图2是本申请实施例提供的一种系统架构的示意图;
图3是本申请实施例提供的又一种系统架构的示意图;
图4是本申请实施例提供的一种空间定位系统的结构示意图;
图5是本申请实施例提供的一种获取标志信息的方法的流程示意图;
图6是本申请实施例提供的一种目标定位模型的结构示意图;
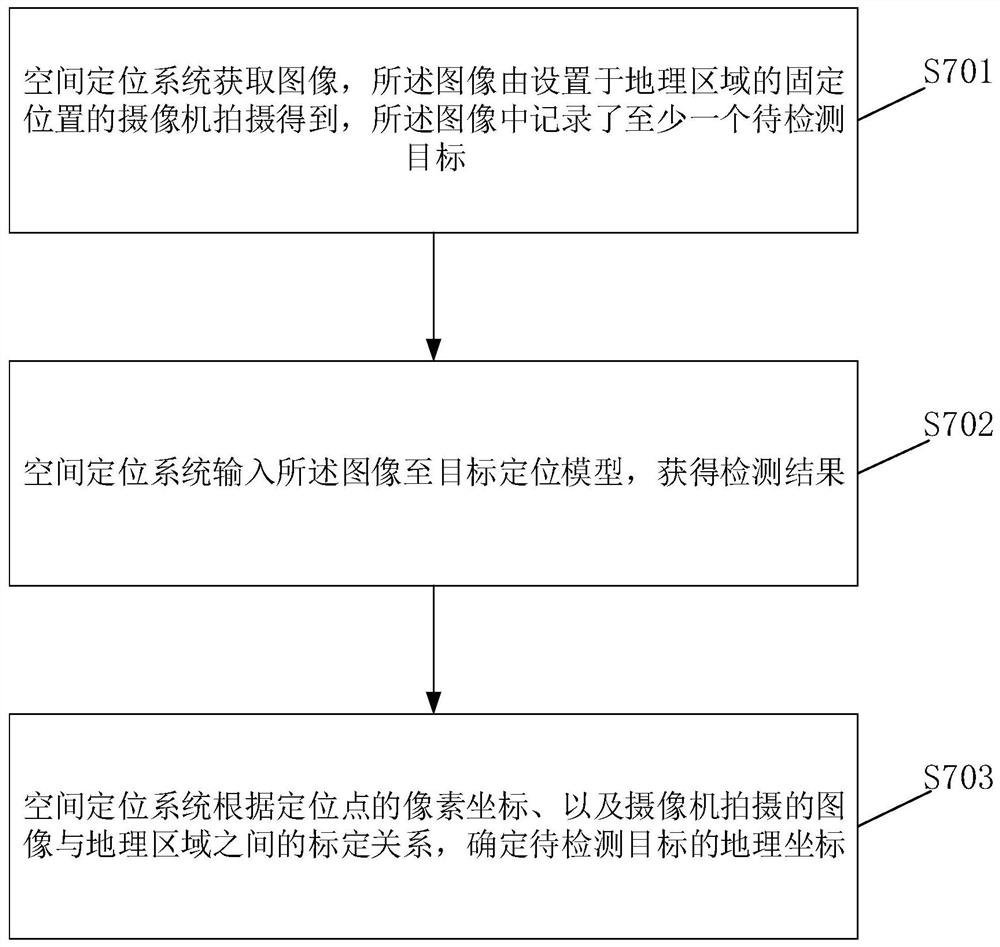
图7是本申请实施例提供的一种空间定位的方法的流程示意图;
图8是本申请实施例提供的一种获取标定关系的方法的流程示意图;
图9是本申请实施例提供的一种计算设备的结构示意图。
具体实施方式
下面结合附图对本申请实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
在本文中提及“实施例”意味着,结合实施例描述的特定特征、结构或特性可以包含在本申请的至少一个实施例中。在说明书中的各个位置出现该短语并不一定均是指相同的实施例,也不是与其它实施例互斥的独立的或备选的实施例。本领域技术人员显式地和隐式地理解的是,本文所描述的实施例可以与其它实施例相结合。
首先,结合附图对本申请中所涉及的部分用语和相关技术进行解释说明,以便于本领域技术人员理解。
地理区域是指物理世界中的一个具体区域,例如交通路口、交通道路、小区门口等区域。
空间标定(calibration)是指确定不同平面或空间之间的空间位置的对应关系,具体可以是计算地理区域中的点的地理坐标与该点在地理区域对应的图像中的像素坐标之间的对应关系,这种对应关系也可以称为标定关系。
单应变换(homograph transform)又称射影变换,是指两个中心投影之间的空间位置变换关系,它可以把一个射影平面上的点映射到另一个射影平面,并且把直线映射为直线,具有保线性质,两个射影平面之间的映射关系可以用一个单应变换矩阵进行表示。
空间定位(location)是指确定图像或视频中的目标在物理世界的地理区域中的位置的过程,即通过目标在图像或视频中的像素坐标确定该目标在物理世界的地理区域对应的地理坐标。
定位点表示目标的地理位置在图像中对应的点,目标的地理位置一般是指目标在地面上的垂直投影的中心点,该点可以准确地表示目标的地理位置,目标的地理坐标即为目标在地理区域的垂直投影的中心点的坐标。而目标在图像中的位置可以用其在地理上垂直投影的中心点在记录该地理区域的图像中所对应的像素点进行表示,该像素点即为目标在图像中的定位点。
人工智能(artificial intelligence,AI)模型是一种机器学习模型,其本质是一种包括大量参数和数学公式(或数学规则)的数学模型。其目的是学习一些数学表达,使该数学表达能提供输入值x和输出值y之间的相关性,能够提供x和y之间的相关性的数学表达即为训练后的AI模型。一般情况,利用一些历史数据(即x和y),通过训练初始AI模型得到的AI模型,可用于根据新的x得到新的y,从而实现预测分析,预测分析的过程也称为推理。
有监督学习(supervised learning)是利用多个携带标注信息的训练数据对初始AI模型进行训练的过程。每个训练数据作为该初始AI模型的输入数据,每个训练数据的标注信息是该初始AI模型的期望输出。训练的过程即是输入训练数据至初始AI模型,该初始AI模型对输入数据进行一系列数学计算,获得输出结果,将输出结果与该训练数据的标注信息进行对比,调整初始AI模型中的参数,依次迭代地对初始AI模型进行训练,以使得初始AI模型输出的结果越接近输入的训练数据对应的标注信息。训练完成的AI模型可用于预测未知的数据的结果。例如,训练数据可以为摄像机拍摄的样本图像,每个样本图像所携带的标注信息为样本图像中记录的目标的检测框的像素坐标,然后将携带标注信息的样本图像依次输入初始AI模型进行训练,每一次训练之后,根据初始AI模型输出的目标的检测框的像素坐标与对应的标注信息中的目标的检测框的像素坐标进行对比,调整初始AI模型中的参数,不断进行迭代训练,以使初始AI模型输出的目标的检测框的像素坐标接近输入的样本图像对应的标注信息中的检测框的像素坐标,这样,初始AI模型被训练完成,即训练完成的AI模型具备了预测输入的图像中待检测目标的检测框的能力。
在对目标进行空间定位的过程中,相关技术借助于目标检测技术获得目标对应的检测框,利用图像中的检测框的下边缘中点或中心点作为目标在图像中的位置,然后通过单应变换将该点映射到物理世界的地理区域中,从而得到该目标的地理坐标。如图1所示,在交通路口中,对于通过摄像头拍摄得到的图像进行目标检测,其检测的目标对象为该交通路口中的车辆,检测结果是对图像中每个车辆都用矩形检测框标注出来,然后利用该矩形检测框的下边缘中点或中心点表示车辆在图像中的位置,将点的坐标确定为车辆的像素坐标。但是根据矩形检测框下边缘的中点(或中心点)的像素坐标和该图像与地理区域的标定关系获得的该点在地理区域中的地理坐标,往往与目标在地理区域的地理坐标相差较大。因此,用这种方式获得的目标在地理区域的地理坐标用于后续车辆违章检测、交通分析等,会带来较大的误差。例如,在上述图1所示的交通路口的场景下,车辆在路口转弯过程中空间定位带来的误差将超过两米。
基于上述问题,本申请提供了一种空间定位的方法,可以通过设置于地理区域的固定位置的摄像机获取到记录了至少一个待检测目标的图像,并将该图像输入至目标定位模型进行检测,得到待检测目标在图像中的定位点的像素坐标,该定位点表示待检测目标在地理区域中的地理位置在图像中对应的点,然后利用定位点的像素坐标以及摄像机拍摄的图像与地理区域之间的标定关系,得到待检测目标在地理区域的地理坐标。通过这种方法,降低了成本,提高了定位准确性,扩展了适用场景。
其中,在本申请中,目标定位模型可以是一种AI模型,在利用AI模型进行检测之前需要对初始AI模型进行训练,本申请利用摄像机拍摄的包含目标的样本图像以及定位点在该样本图像中的像素坐标对初始AI模型进行训练,以使得训练后的AI模型具备定位点检测的能力,可以对摄像机拍摄的待检测图像进行定位点检测。
获取定位点在样本图像中的像素坐标可以借助于无人机等拍摄得到的高点图像或视频进行计算得到。例如在得到无人机等拍摄得到的高点图像或视频后,计算得到目标在地理区域中的地理位置,在得到目标的地理位置之后,可以进一步得到目标的地理位置在摄像机拍摄的样本图像中的定位点,最终得到定位点在样本图像中的像素坐标。
本申请实施例的技术方案可以应用于各种需要进行空间定位的场景,包括但不限于交通路口、交通道路、学校门口、小区门口等。
本申请中的目标包括图像中记录的车辆、行人、动物、静态物体等,图像中需要被检测到且需要进行空间定位的目标也称为待检测目标。
本申请中的像素坐标是图像中的像素点的坐标,像素坐标是二维坐标。
本申请中的地理坐标是表示一个地理区域中的点的三维坐标值,应理解,同一个点在不同的坐标系下其对应的坐标值是不同的。本申请中点的地理坐标可以是任意坐标系下的坐标值,例如,本申请中目标的地理坐标可以是目标对应的经度、纬度和海拔组成的三维坐标,也可以是目标对应的自然坐标系下的X坐标、Y坐标和Z坐标组成的三维坐标,还可以是其它形式的坐标,只要该坐标可以唯一确定一个点在地理区域中的位置,本申请对具体选用何种形式的坐标不作限定。
本申请提供的空间定位方法由空间标定系统执行,在一个具体的实施例中,空间定位系统可以部署在任意一个涉及空间定位的计算设备中。例如,如图2所示,可以部署在云环境上的一个或多个计算设备(例如中心服务器),或者边缘环境中的一个或多个计算设备(边缘计算设备)上,边缘计算设备可以为服务器。其中,云环境是指云服务提供商拥有的,用于提供计算、存储、通信资源的中心计算设备集群,云环境中具备较多的存储资源和计算资源。边缘环境是指在地理位置上距离原始数据采集设备较近的,用于提供计算、存储、通信资源的边缘计算设备集群。本申请中的空间定位系统还可以部署在一个或多个终端设备上,如图3所示,空间定位系统部署在一个终端计算设备上,该终端设备具有一定的计算、存储和通信资源,可以是计算机、服务器等。原始数据采集设备指采集空间定位系统所需的原始数据的设备,包括但不限于摄像机、红外相机、激光雷达等,原始数据采集设备包括置于交通道路的固定位置,用于以自身视角采集交通道路的原始数据(例如:视频数据、红外数据等)的设备等。
空间定位系统用于对摄像机拍摄得到的图像进行目标检测和定位,空间定位系统利用训练好的目标定位模型对图像中的待检测目标进行定位点检测,得到待检测目标在图像中的定位点的像素坐标,进而根据摄像机拍摄的图像与地理区域之间的标定关系得到待检测目标的地理坐标,目标定位模型可以是前述由初始AI模型经训练后形成的AI模型,该目标定位模型具备定位点检测的功能,即可以对图像进行定位点检测,得到目标在图像中的定位点的像素坐标。空间定位系统内部的单元可以有多种划分方式,本申请对此不作限制。图4为一种示例性的划分方式,如图4所示,下面将分别简述每个功能单元的功能。
所示空间定位系统400包括多个功能单元,其中,获取单元410,用于获取图像,该图像由设置于地理区域的固定位置的摄像机拍摄得到,该图像中记录了至少一个待检测目标;定位点检测单元420,用于将获取单元410获取到的图像输入目标定位模型,对图像中的待检测目标进行定位点检测,得到定位点的像素坐标;处理单元430,用于根据定位点检测单元420检测得到的待检测目标在图像中的定位点的像素坐标以及摄像机拍摄的图像与地理区域之间的标定关系,确定该待检测目标的地理坐标。
可选的,处理单元430还用于确定初始目标定位模型,并利用获取单元410获取到的多个携带标注信息的样本图像对初始目标定位模型进行训练,以使得训练后的目标定位模型具备检测目标位置、类别和在图像中的定位点的像素坐标的能力,该多个样本图像是由摄像机对所述地理区域拍摄得到,该标注信息包括样本图像中记录的目标的类别信息、检测框信息、以及在样本图像中的定位点的像素坐标,处理单元430在训练完成后,将训练得到的目标定位模型部署到定位点检测单元420。定位点检测单元420还用于对图像中的待检测目标进行位置和类别检测,得到待检测目标的类别、以及在图像中的检测框信息,该检测框信息与定位点一一对应。
本申请提供的空间定位的方法通过目标定位模型进行目标的定位点检测,进一步地根据检测到的定位点的像素坐标确定目标在地理区域的地理坐标,从而实现目标的空间标定,可以有效地提高空间标定的精度。
应理解,本申请中的目标定位模型是一种已训练完成的AI模型。目标定位模型在用于本申请的空间定位方法之前需要进行训练,以使其具有预测目标在图像中的定位点的像素坐标的能力。本申请中的目标定位模型还可以具有确定目标的类别和位置(检测框信息)的能力。在训练过程中,需要使用特别的训练数据进行训练,从模型能力需求出发进行分析,需要使用携带标注信息的摄像机拍摄的样本图像进行训练,样本图像中记录了目标(例如车辆、行人等),标注信息包括目标在样本图像中的类别信息、位置(检测框信息)、定位点的像素坐标。目标的类别信息用于表示目标的类别,例如:“公交车”、“自行车”、“行人”等,检测框与定位点一一对应,该检测框用于在样本图像中将目标标注出来,例如矩形检测框对应的检测框信息具体可以由四个像素坐标组成,即检测框的左上角横坐标、左上角纵坐标、右下角横坐标、右下角纵坐标。需要说明的是,标注信息可以以可扩展标记语言(extensible markup language,XML)或JavaScript对象简谱(JavaScript objectnotation,JSON)等文件进行保存。
下面首先描述本申请中目标定位模型的训练所需的训练数据以及标注信息的获取过程。
目标的类别信息和检测框信息可以利用目标检测算法对样本图像进行检测得到样本图像中记录的目标的检测框信息和类别信息,也可以通过人工标注的方式得到检测框信息和类别信息。
下面介绍目标在样本图像中的定位点的像素坐标的获取过程,如图5所示:
S501:获取地理区域的N个俯视图像。
具体地,可以利用无人机停留在该地理区域的正上方对该地理区域进行垂直拍摄,得到该地理区域的N个俯视图像,该N个俯视图像对应不同时刻的该地理区域中的交通状况,其中,N为大于1的整数,例如N可以为50。
需要说明的是,在进行地理区域的俯视图像的拍摄过程中,还应同时通过摄像机拍摄同一个地理区域的N个样本图像。每一个俯视图像与摄像机拍摄的样本图像所拍摄的时刻为同一时刻,示例性的,摄像机对地理区域拍摄了两个样本图像,其拍摄时刻分别为t1时刻和t2时刻,那么无人机相应的也拍摄了地理区域的两个俯视图像,其对应的拍摄时刻也为t1时刻和t2时刻,即对于每一个时刻摄像机拍摄的样本图像,存在一个相同时刻拍摄同一地理区域的俯视图像,保证同一时刻样本图像中记录的目标的地理位置和俯视图像中记录的目标的地理位置是相同的。
S502:获取俯视图像中记录的目标的像素坐标。
具体地,利用目标检测算法,例如仅看一次(you only look once,Yolo)、单点多锚检测器(single shot multi-box detector,SSD)、更快的基于区域生成网络的卷积神经网络(faster region proposal network-convolutional neural network,Faster-RCNN)等,对每一个俯视图像进行目标检测,检测得到俯视图像中记录的目标的检测框(例如矩形检测框),每个检测框的中心点的像素坐标即为目标的像素坐标。
值得说明的是,由于目标在地理区域中的地理位置可以用目标在地理区域的垂直投影的中心点的地理坐标来表示。在俯视图像中,目标的地理位置在图像中对应的点与目标的检测框的中心点为同一点,因此,俯视图像中检测框的中心点的像素坐标就是目标的地理位置在俯视图像中的像素坐标。
S503:根据俯视图像与地理区域之间的标定关系,获得目标在地理区域中的地理位置。
具体地,通过步骤S502得到了目标的地理位置在俯视图像中的像素坐标,再利用俯视图像与地理区域之间的标定关系,经过简单的计算就可以得到目标在地理区域中的地理位置,即目标在地理区域的垂直投影的中心点的地理坐标。
应理解,俯视图像与地理区域之间的标定关系可以提前获取得到,并保存在空间定位系统中,其具体的获得方法将在后续步骤中详细描述。
S504:根据摄像机拍摄的图像与地理区域之间的标定关系,获得目标在样本图像中的定位点的像素坐标。
具体地,由于摄像机和无人机都是对同一地理区域进行拍摄,因此,在同一时刻摄像机拍摄的样本图像中记录的目标和无人机拍摄的俯视图像中记录的目标为同一时刻的同一个目标,目标在样本图像中的定位点的像素坐标所对应的地理位置与俯视图像中检测框的中心点的像素坐标所对应的地理位置为同一个地理位置。
而在上述步骤S503中已经获得目标在地理区域的地理位置,再利用样本图像与地理区域之间的标定关系,经过一次简单的坐标转换,就可以得到目标在摄像机拍摄的样本图像中的定位点的像素坐标。同理,样本图像与地理区域之间的标定关系可以提前获得,并保存在空间定位系统中,其具体的获得方法将在后续步骤中详细描述。
示例性的,假设俯视图像与地理区域之间的标定矩阵为H1,即将俯视图像中的点的像素坐标转换到地理区域中的地理坐标的转换矩阵为H1,目标在俯视图像中的像素坐标为(m,n),则目标在地理区域中的地理坐标为(a,b,c)=(m,n)*H1。摄像机拍摄的图像与地理区域之间的标定矩阵为H2,那么H2
在获得目标在样本图像中的定位点的像素坐标以后,将该定位点的像素坐标作为该样本图像对应的标注信息,通过上述图5所述的方法,可以获得多个样本图像的标注信息,将这多个样本图像作为训练样本,连同该多个样本图像对应的标注信息一起用于后续目标定位模型的训练。
需要说明的是,在利用无人机等设备在拍摄得到俯视图像的过程中,可能因为无人机的抖动或外界因素影响(例如刮风下雨等),造成无人机无法在地理区域正上方做到绝对静止,这样将会造成地理区域中的同一个点在该无人机不同时刻拍摄的俯视图像中对应不同的像素坐标,这样也会导致获取到的目标(例如车辆)在地理区域的地理位置不够准确。
可选的,为了消除这种影响,一种可能的实现方法是将其它时刻拍摄的俯视图像中的目标都映射到同一个俯视图像中,这样目标在任意一个时刻只存在一个像素坐标,对应唯一一个地理位置,这样就可以消除无人机抖动等所带来的影响。
在一种可能的应用场景中,无人机停留在地理区域的正上方的固定高度处对地理区域进行垂直拍摄,得到一段时间内的俯视图像,在无人机拍摄的同时,摄像机也会对该同一地理区域进行拍摄。在得到的多个俯视图像中,选取清晰可见的N个不同时刻拍摄的俯视图像,并根据选出的N个俯视图像的拍摄时刻,确定摄像机在对应时刻拍摄的N个样本图像。
在选取N个俯视图像之后,可以选择任意一个俯视图像作为基准图像,其余剩下的N-1个俯视图像为非基准图像,其目的为将所有非基准图像中的目标映射到基准图像中以提高获取得到的目标的地理位置的准确性。
然后,获取N个俯视图像的静态背景信息。本申请中,静态背景信息指将目标物体(一般都是运动物体)除去之后所剩下的图像信息,例如图像中所记录的交通路口的静态的物体,包括:道路标记线、警示牌、交通信号杆、站岗亭、周边建筑、行道树、花坛等。具体可以利用目标检测算法对每一个俯视图像进行目标检测,得到俯视图像中的目标的检测框,然后将检测框内的信息进行覆盖或删除,余下的即为静态背景信息。
值得说明的是,获取俯视图像的静态背景信息的目的是为了方便计算得到所有非基准图像与基准图像之间的映射关系,由于静态的物体不会随着时间而发生移动,因此只需要得多个静态的物体在基准图像和非基准图像中的像素坐标,就可以计算得到基准图像和非基准图像之间的映射关系。
接着,将基准图像的静态背景信息与每一个非基准图像的静态背景信息分别进行特征匹配,并计算得到基准图像与每一个非基准图像之间的坐标转换矩阵。可以利用图像特征提取算法,例如尺度不变特征变换(scale-invariant feature transform,SIFT)、加速稳健特征(speeded up robust features,SURF)、快速特征点提取和描述(orientedfast and rotated brief,ORB)等算法对所有俯视图像的静态背景信息(包括基准图像和非基准图像)进行特征提取,提取得到每个俯视图像的静态背景信息的特征点以及描述特征点的特征向量。
进一步的,利用特征匹配算法,例如坏的帧掩蔽(bad frame masking,BFM)算法或K近邻(K-Nearest Neighbour,KNN)等对基准图像的静态背景信息的特征点对应的特征向量与每一个非基准图像的静态背景信息的特征点对应的特征向量进行匹配,得到多个特征点匹配对,每个特征点匹配对对应一个像素坐标对,即特征点在基准图像中的像素坐标和特征点在非基准图像中的像素坐标,根据得到的多个特征点匹配对,利用单应变换法等可以计算得到基准图像与每一个非基准图像之间的映射关系,即得到它们之间的坐标转换矩阵。需要说明的是,对于基准图像与每一个非基准图像来说,需要至少获取三对特征点匹配对才能计算得到坐标转换矩阵,为了提高计算结果的准确性,一般都是获取数十对特征点匹配对进行计算。
最后,根据得到的基准图像与每一个非基准图像之间的坐标转换矩阵,将所有非基准图像中记录的目标映射到基准图像中。
下面将描述目标定位模型的训练过程。
通过上述图5所述的方法,可以得到多个不同时刻拍摄的样本图像的标注信息,多个携带标注信息的样本图像构成了训练集,利用训练集中的训练样本进行模型训练,首先确定初始目标定位模型,本申请中,初始目标定位模型为一种AI模型,具体可以选用一种深度神经网络模型,不同于一般的目标检测神经网络,该网络不仅可以对目标的类别以及在图像中的位置进行检测,同时还具有定位点检测的功能。因此,本申请的初始目标定位模型在结构上也进行了相应的改进。
如图6所示,本申请的初始目标定位模型600的结构主要包括三部分,即骨干网络610、检测网络620和损失函数计算单元630。骨干网络610用于对输入的样本图像进行特征提取,其内部包含若干卷积层,可以选用视觉几何组网络(visual geometry groupnetwork,VGG)、残差网络(residual network)、密集卷积网络(dense convolutionalnetwork)等。检测网络620用于对骨干网络610提取的特征进行检测和识别,输出目标类别信息、目标位置信息(即检测框信息)、目标的定位点的像素坐标,其内部本质上也是由若干卷积层组成,对骨干网络610的输出结果进行进一步的卷积计算。
需要说明的是,本申请的目标定位模型与一般的目标检测模型(例如yolo、fasterRCNN等)相比,骨干网络610可以选用同一种网络,但由于目标定位模型可以进行定位点检测,因此在检测网络620中,本申请在每个负责回归检测框的卷积层上增加了多个通道,优先增加两个通道,用于表示定位点在样本图像中的横坐标和纵坐标,当然也可以增加更多个通道,每个通道赋予相应的物理含义,例如增加表示定位点的置信度的通道,本申请对此不作限定。
首先,将初始定位模型600的参数初始化,之后将样本图像输入至初始目标定位模型600。骨干网络610对样本图像中记录的目标进行特征提取,得到抽象的特征,然后将抽象的特征输入至检测网络620,检测网络进行进一步的检测和识别,预测出该目标的类别、位置以及定位点的像素坐标,并通过相应的通道进行输出至损失函数计算单元630;然后将该样本图像对应的标注信息也输入损失函数计算单元630,损失函数计算单元630将检测网络620预测得到的预测结果与该样本图像对应的标注信息进行比对,并计算出损失函数,以损失函数为目标函数使用反向传播算法更新调整模型中的参数。依次输入携带标注信息的样本图像,不断迭代执行上述训练过程,直到损失函数值收敛时,即每次计算得到的损失函数值在某一个值附近上下波动,则停止训练,此时,目标定位模型已经训练完成,即目标定位模型已经具备检测图像中目标的类别、位置、以及定位点的功能,可以用于空间定位。
值得说明的是,由于本申请在每个负责回归检测框的卷积层上增加了两个通道,因此在损失函数的构造上需要重新设计。假设本申请的目标定位模型是在经典的目标检测模型(例如yolo、faster RCNN等)上进行的改进,经典的目标检测模型的损失函数为Loss1,那么构造的本申请的目标定位模型的损失函数Loss可以表示为:Loss=Loss1+Loss2,Loss2为新增的两个通道所对应的损失函数。
由于本申请中新增两个通道的目的是用于预测定位点的像素坐标,因此在构造Loss2时,可以用预测得到的定位点的像素坐标和标注信息中定位点的像素坐标之间的距离来表示Loss2,可选的,可以用一维(L1)范数或二维(L2)范数来表示距离,其中,L1范数表示预测得到的定位点的像素坐标与定位点的真实的像素坐标的差值的绝对值,L2范数表示预测得到的定位点的像素坐标与定位点的真实的像素坐标的差值的平方之后再开方;或者是通过其它的方式来构造Loss2,本申请对此不作限定。
利用构造的损失函数Loss为目标函数,使用反向传播算法更新目标定位模型中的参数,不断的迭代执行,直到Loss的值已经收敛,即每次计算得到的Loss的值都在某个稳定值附近波动,则表示目标定位模型已经训练完成,可以用于空间定位。
对目标定位模型训练完成后,可以利用该目标定位模型进行空间定位,下面将结合图7具体描述如何进行空间定位的过程。如图7所示,该方法包括但不限于以下步骤:
S701:空间定位系统获取图像,所述图像由设置于地理区域的固定位置的摄像机拍摄得到,所述图像中记录了至少一个待检测目标。
具体地,空间定位系统可以通过设置于地理区域的摄像机获取到该摄像机拍摄的一段视频数据,该视频数据由不同时刻的视频帧组成,其中视频数据中的视频帧是按照时间顺序排列的,每个视频帧都是一个图像、用于反映当前时刻被拍摄地理区域的状况,每个图像中记录了至少一个待检测目标。
值得说明的是,该摄像机与上述拍摄样本图像所使用的摄像机为同一个摄像机,即该设置于地理区域的固定位置的摄像机不仅需要拍摄得到用于目标定位模型训练的样本图像,还需要拍摄用于空间定位的待检测的图像。
应理解,本申请中,目标可以指在交通道路上的运动的物体或在一段时间内静止的可运动的物体,例如:机动车、行人、非机动车、动物等。
S702:空间定位系统输入所述图像至目标定位模型,获得检测结果。
具体地,利用上述已经训练好的目标定位模型对图像中的待检测目标进行定位点检测,得到的检测结果包括待检测目标在该图像中的定位点的像素坐标、待检测目标的类别、检测框,其中,定位点表示待检测目标在地理区域中的地理位置在所述图像中对应的点。例如,以待检测目标为车辆为例,车辆在地理区域中的地理位置可以事先获得,车辆的地理位置可以是指车辆在地理区域的垂直投影的中心点的地理坐标,该地理坐标可以测量得到,一般来说,对于车辆这种接近对称的目标来说,车辆的垂直投影的中心点与车辆的质心的垂直投影点重合,即车辆的质心在地理区域的垂直投影点的地理坐标表示车辆在地理区域中的地理位置,在摄像机对地理区域拍摄得到的图像中,该车辆的质心所对应的点即为车辆在图像中的定位点。
S703:空间定位系统根据定位点的像素坐标、摄像机拍摄的图像与地理区域之间的标定关系,确定待检测目标的地理坐标。
具体地,空间定位系统在得到定位点的像素坐标之后,利用摄像机拍摄的图像与地理区域之间的标定关系,经过简单的坐标转换,就可以得到定位点的地理坐标,即得到了待检测目标的地理坐标,实现了对待检测目标进行空间定位。
待检测的目标可以根据应用场景的不同而具有不同的含义。例如,在确定交通路口的车辆违章的应用场景中,待检测目标为目标交通路口的车辆;在确定可疑车辆的行车位置的应用场景中,待检测目标即为交通道路上的可疑车辆;在确定某区域(例如居民小区内部)的可疑人员时,待检测目标即为该区域中的可疑人员;在确定某区域(例如:工厂)的危险情况时,待检测目标即为该区域中的危险目标(例如:出故障机器、着火物体等)。
空间定位系统可以根据应用场景的不同而部署在不同的处理装置上,例如:处理装置可以是交通管理系统中的用于确定车辆的地理坐标的装置,也可以是警务系统中用于确定可疑车辆的地理坐标的装置,还可以是安全管理系统中用于确定可疑人员的地理坐标的装置,还可以是危险排查管理系统中用于确定危险目标的地理坐标的装置。
应理解,摄像机拍摄的图像与地理区域之间的标定关系、以及上述步骤S503中涉及的俯视图像与地理区域之间的标定关系可以通过多种方法获取得到,它们原理类似,下面结合图8,示例性的描述一种获取摄像机拍摄的图像与地理区域之间的标定关系的方法:
S801:预先获取地理区域中的控制点的地理坐标。
为获取目标的像素坐标与目标在物理世界的地理坐标之间的映射关系,需预先选择一些地理区域中的控制点,获取并记录控制点的地理坐标。例如在交通路口中选择控制点,控制点的选择通常为一些具有显著特征的点,以便于直观的找到该控制点在图像中的像素点的位置。例如:以交通道路中的交通标志线的直角点、箭头的尖点、绿化带拐角点等作为控制点,控制点的地理坐标(例如经度、维度、海拔)可以通过人工采集,也可以通过无人驾驶汽车采集,选取的交通道路的控制点需均匀地分布在交通道路上,避免全部分布在一条直线周围,以保证在摄像机视角下可以观测到至少没有分布在一条直线上的三个控制点,控制点的选取数目可以根据实际情况进行选取。
S802:获取采集的控制点在摄像机拍摄的图像中的像素坐标。
读取固定设置于地理区域的摄像机拍摄的地理区域的图像,在拍摄得到的图像中获取可观测到的控制点对应的像素坐标值,可以通过人工获取也可以通过程序获取,例如利用角点检测、短时傅里叶变换边缘提取算法获取地理区域的控制点在图像中相应的像素坐标。
S803:根据控制点的地理坐标和像素坐标建立摄像机视角下的图像到物理世界的标定关系。例如,可以根据单应变换原理计算由像素坐标转换为地理坐标的单应变换矩阵H,单应变换公式为(m,n,h)=H*(x,y),由前述步骤S801和S802获得的摄像机的拍摄视角下的图像中至少三个控制点的像素坐标(x,y)和地理坐标(m,n,h)可以计算得到摄像机拍摄的图像对应的H矩阵。应理解,若存在多个摄像机,由于每个摄像机的拍摄视角不同,因此计算得到的H矩阵不同。
可以看出,只要得到待检测目标的定位点的像素坐标,以及摄像机拍摄的图像与地理区域之间的标定关系(即摄像机拍摄的图像对应的H矩阵),通过简单的计算就可以得到待检测目标的地理坐标。
需要说明的是,前述步骤S801-S803的执行时间不应晚于步骤S703,其具体执行时间不限定,例如,可以在目标定位模型训练之前即执行完成。此外,俯视图像与地理区域之间的标定关系的获取方法与上述类似,为了简洁,在此不再赘述。
上述详细阐述了本申请实施例的方法,为了便于更好的实施本申请实施例的上述方案,相应地,下面还提供用于配合实施上述方案的相关设备。
如图4所示,本申请还提供一种空间定位系统,该空间定位系统用于执行前述空间定位的方法。本申请对该空间定位系统中的功能单元的划分不做限定,可以根据需要对该空间定位系统中的各个单元进行增加、减少或合并。图4示例性的提供了一种功能单元的划分:
空间定位系统400包括获取单元410、定位点检测单元420以及处理单元430。
具体地,所述获取单元410用于执行前述步骤S501、S701、S801-S802,且可选的执行前述步骤中可选的方法。
所述定位点检测单元420用于执行前述步骤S502、S702,且可选的执行前述步骤中可选的方法。
所述处理单元430用于执行前述步骤S503-S504、S703、S803,且可选的执行前述步骤中可选的方法。
上述三个单元之间互相可以通过通信通路进行数据传输,应理解,空间定位系统400包括的各单元可以为软件单元、也可以为硬件单元、或部分为软件单元部分为硬件单元。
参见图9,图9是本申请实施例提供的一种计算设备的结构示意图。如图9所示,该计算设备900包括:处理器910、通信接口920以及存储器930,所述处理器910、通信接口920以及存储器930通过内部总线940相互连接。应理解,该计算设备900可以是云计算中的计算设备,或边缘环境中的计算设备。
所述处理器910可以由一个或者多个通用处理器构成,例如中央处理器(centralprocessing unit,CPU),或者CPU和硬件芯片的组合。上述硬件芯片可以是专用集成电路(application-specific integrated circuit,ASIC)、可编程逻辑器件(programmablelogic device,PLD)或其组合。上述PLD可以是复杂可编程逻辑器件(complexprogrammable logic device,CPLD)、现场可编程逻辑门阵列(field-programmable gatearray,FPGA)、通用阵列逻辑(generic array logic,GAL)或其任意组合。
总线940可以是外设部件互连标准(peripheral component interconnect,PCI)总线或扩展工业标准结构(extended industry standard architecture,EISA)总线等。所述总线940可以分为地址总线、数据总线、控制总线等。为便于表示,图9中仅用一条粗线表示,但不表示仅有一根总线或一种类型的总线。
存储器930可以包括易失性存储器(volatile memory),例如随机存取存储器(random access memory,RAM);存储器930也可以包括非易失性存储器(non-volatilememory),例如只读存储器(read-only memory,ROM)、快闪存储器(flash memory)、硬盘(hard disk drive,HDD)或固态硬盘(solid-state drive,SSD);存储930还可以包括上述种类的组合。
需要说明的是,计算设备900的存储器930中存储了空间定位系统400的各个单元对应的代码,处理器910执行这些代码实现了空间定位系统400的各个单元的功能,即执行了S701-S703的方法。
上述各个附图对应的流程的描述各有侧重,某个流程中没有详述的部分,可以参见其他流程的相关描述。
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用软件实现时,可以全部或部分地以计算机程序产品的形式实现。所述计算机程序产品包括一个或多个计算机指令。在计算机上加载和执行所述计算机程序指令时,全部或部分地产生按照本发明实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输。所述计算机可读存储介质可以是计算机能够存取的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如,DVD)、或者半导体介质(例如SSD)等。
- 空间定位方法、空间定位设备、空间定位系统及计算机可读存储介质
- 一种攀爬机器人空间定位方法及空间定位系统