一种应用程序的运行方法,计算设备及存储介质
文献发布时间:2023-06-19 11:35:49
技术领域
本发明涉及互联网领域,具体涉及一种应用程序的运行方法,计算设备及存储介质。
背景技术
随着计算机的发展和普及,各种信息安全事件频发,从安全和产业价值的角度来考量,必须发展自主可控的操作系统,而基于Linux(内核采用开源的Linux内核且提供桌面环境的各种Linux发行版,流行的有Ubuntu,RedHat,Deepin,UOS等)内核来开发操作系统是一个最优选择。由于Windows系统绝对占有率,Linux桌面生态不完善,现有计算机系统从Windows迁移到Linux之后,出现大量Windows应用程序无法使用,特别是在国产处理器上面。
如果在国产处理器(基于精简指令集的处理器,比如arm架构的鲲鹏和飞腾处理器,mips架构的龙芯处理器等)上的Linux能够直接使用Windows系统x86架构(一种复杂指令集)的高频率应用程序,将大大有利于Windows用户向Linux系统迁移,同时也能够促使更多的软件开发商主动为Linux桌面开发原生应用程序,使Linux桌面生态发展进入良性循环。
发明内容
鉴于上述问题,提出了本发明以便提供一种克服上述问题或者至少部分地解决上述问题的一种应用程序的运行方法、计算设备以及存储介质。
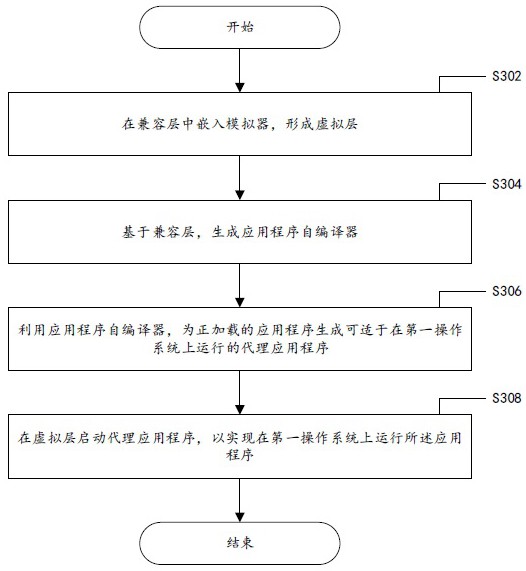
根据本发明的一个方面,提供一种应用程序的运行方法,在计算设备的第一操作系统中执行,第一操作系统上布置有可兼容第二操作系统的兼容层,应用程序的运行环境为第二操作系统,该方法包括:在兼容层中嵌入模拟器,形成虚拟层;基于兼容层,生成应用程序自编译器;利用应用程序自编译器,为正加载的应用程序生成可适于在第一操作系统上运行的代理应用程序;在虚拟层启动代理应用程序,以实现在第一操作系统上运行应用程序。
可选地,在根据本发明的应用程序的运行方法中,在兼容层中嵌入模拟器,形成虚拟层的步骤之前,还包括步骤:对模拟器进行预处理,以使得模拟器能够嵌入兼容层。
可选地,在根据本发明的应用程序的运行方法中,对模拟器进行预处理包括步骤:对组成模拟器的代码进行筛选,获取其中关于进程模式的代码;将关于进程模式的代码嵌入兼容层。
可选地,在根据本发明的应用程序的运行方法中,所在兼容层中嵌入模拟器,形成虚拟层的步骤包括:在兼容层中创建模拟器文件;在模拟器文件中,对每个线程的局部存储空间保存该线程的唯一模拟对象,作为一个应用程序的CPU模拟器;设置用于启动CPU模拟器的函数。
可选地,在根据本发明的应用程序的运行方法中,基于兼容层,生成应用程序自编译器包括:基于编译器的过滤机制,生成编译插件;利用编译插件解析兼容层中的所有函数,获得兼容层中的所有函数的函数原型;通过编译插件与函数原型生成应用程序自编译器。
可选地,在根据本发明的应用程序的运行方法中,利用应用程序自编译器,为正加载的应用程序生成可适于在第一操作系统上运行的代理应用程序的步骤包括:在兼容层的所有函数的头部预留预定区域;获取所有函数的函数原型;基于函数原型的签名信息,按照预定模板利用应用程序自编译器在预定区域写入代理模块。
可选地,在根据本发明的应用程序的运行方法中,在虚拟层启动代理应用程序,以实现在第一操作系统上运行应用程序的步骤包括:将应用程序调用兼容层的函数地址替换为应用程序调用代理模块的函数地址。
可选地,根据本发明的应用程序的运行方法,在虚拟层启动代理应用程序,以实现在第一操作系统上运行应用程序的步骤还包括:对代理应用程序的启动过程进行异常捕获。
根据本发明的又一个方面,提供一种计算设备,包括:至少一个处理器;和存储有程序指令的存储器,其中,程序指令被配置为适于由至少一个处理器执行,程序指令包括用于执行上述方法的指令。
根据本发明的又一个方面,提供一种存储有程序指令的可读存储介质,当程序指令被计算设备读取并执行时,使得计算设备执行上述的方法。
根据本发明的方案,一方面通过在兼容层代码中嵌入模拟器的代码,为x86应用程序在非x86架构且非Windows系统上运行提供运行环境,使得应用程序运行过程中,在函数调用时候能够自动识别要调用的目标函数是guest端代码的还是host端代码,如果是guest端代码,则自动启动CPU模拟器模拟执行,最后将模拟结果放回给host端。
另一方面,利用编译器的过滤机制,开发编译插件,通过编译插件解析出wine模块中的每个API(应用程序编程接口,主要功能为提供函数功能集合),动态生成每个API的guest端代理桩代码。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
图1示出了现有技术中在非x86架构运行Windows x86程序的方法1的框架图100;
图2示出了根据本发明一个实施例的计算设备200的示意图;
图3示出了根据本发明一个实施例的应用程序的执行方法300的流程图;
图4示出了根据本发明一个实施例的应用程序进行函数调用方法400的流程图。
图5示出了根据本发明一个实施例的可用于应用程序的执行方法的框架图500。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
因为架构的差异带来的指令集不一样,要在国产处理器上运行x86架构的Windows应用程序,首先要解决的问题是对cpu指令的模拟和转换,其次是实现Windows的兼容层环境。
目前已知的在非x86架构运行Windows x86程序的方案大致有两种:
方案一是直接使用CPU模拟器qemu的进程模式来模拟运行x86版本的wine和x86版本的PE格式程序,该方案的缺点是,在qemu的进程模式下wine依赖的所有第三方库都是x86版本的,都要模拟执行,跟原生版本相比,公开研究表面性能下降10倍左右。
需要说明的是,Wine是一个能够在多种 POSIX 兼容操作系统(比如 Linux,MacOS X及BSD等)上运行 Windows 应用的兼容层。 Wine 不是类似虚拟机一样模仿整个Windows 系统,而是将Windows API 调用动态转成本机的POSIX 调用,相对虚拟机方式来说消耗的内存大大减少,性能几乎跟在Windows系统上运行一样。另外,Wine是一个全世界的开源项目
还需要说明的是,qemu是一种著名的CPU模拟器,其有两种工作模式,分别为:
内核模式:类似 virtualbox 和 vmware,可以虚拟运行完整的操作系统;
进程模式:在 host 端用户态(直接运行在物理cpu上的应用,在本方案的行文描述中指运行于非x86平台的wine)直接模拟运行 guest 端程序(通过指令集模拟间接运行在物理cpu上的应用,在本方案的行文描述中指x86应用)。
方案二是编译qemu用户态模式的window版本的PE执行程序,由wine arm版加载执行程序qemu-x86¬_64.exe.so,该方案的系统架构100如图1所示。该方案的确定是对于每个Windows模块,需要实现一个对应guest端代理模块,在代理模块里面实现通过出发一个syscall(系统调用)事件,从guest端进入host端,调用host端Windows API。这导致每个Windows模块都要手写一个代理模块,代码量较大,目前该项目只实现了不到50个Windows核心模块的guest端代理模块,大约是所有wine模块的10%。
为了避免以上方案一单独启动qemu进程带来的性能损耗及方案二中需要手写guest端代理模块带来的巨大迁移工作量,提出本发明的技术方案。本方案一方面通过在国产处理器上布置wine(兼容层),并且在Wien代码中嵌入CPU模拟器的代码,使得应用程序运行过程中,在函数调用时候自动识别要调用的目标函数是guest端代码的还是host端代码,如果是guest端代码,则自动启动CPU模拟器模拟执行,最后将模拟结果放回给host端;另一方面,利用编译器的过滤机制,开发编译插件,通过编译插件解析出wine模块中的每个API(应用程序编程接口,主要功能为提供函数功能集合),动态生成每个API的guest端代理桩代码。本发明提供的技术方案现有技术相比,从性能上比前述方案一更快,从迁移速度上比前述方案二更快(迁移工作量较方案二更少)。
具体地,如图2所示,图2示出了根据本发明一个实施例可执行应用程序的运行方法的计算设备200的示意图。如图2所示,在基本的配置202中,计算设备200典型地包括系统存储器206和一个或者多个处理器204。存储器总线208可以用于在处理器204和系统存储器206之间的通信。
取决于期望的配置,处理器204可以是任何类型的处理,包括但不限于:微处理器(µP)、微控制器(µC)、数字信息处理器(DSP)或者它们的任何组合。处理器204可以包括诸如一级高速缓存210和二级高速缓存212之类的一个或者多个级别的高速缓存、处理器核心214和寄存器216。示例的处理器核心214可以包括运算逻辑单元(ALU)、浮点数单元(FPU)、数字信号处理核心(DSP核心)或者它们的任何组合。示例的存储器控制器218可以与处理器204一起使用,或者在一些实现中,存储器控制器218可以是处理器204的一个内部部分。
取决于期望的配置,系统存储器206可以是任意类型的存储器,包括但不限于:易失性存储器(诸如RAM)、非易失性存储器(诸如ROM、闪存等)或者它们的任何组合。系统存储器106可以包括操作系统220、一个或者多个应用222以及程序数据224。应用222实际上是多条程序指令,其用于指示处理器204执行相应的操作。在一些实施方式中,应用222可以布置为在操作系统上使得处理器204利用程序数据224进行操作。
计算设备200还可以包括有助于从各种接口设备(例如,输出设备242、外设接口244和通信设备246)到基本配置202经由总线/接口控制器230的通信的接口总线240。示例的输出设备242包括图形处理单元248和音频处理单元250。它们可以被配置为有助于经由一个或者多个A/V端口252与诸如显示器或者扬声器之类的各种外部设备进行通信。示例外设接口244可以包括串行接口控制器254和并行接口控制器256,它们可以被配置为有助于经由一个或者多个I/O端口258和诸如输入设备(例如,键盘、鼠标、笔、语音输入设备、触摸输入设备)或者其他外设(例如打印机、扫描仪等)之类的外部设备进行通信。示例的通信设备246可以包括网络控制器260,其可以被布置为便于经由一个或者多个通信端口264与一个或者多个其他计算设备262通过网络通信链路的通信。
网络通信链路可以是通信介质的一个示例。通信介质通常可以体现为在诸如载波或者其他传输机制之类的调制数据信号中的计算机可读指令、数据结构、程序模块,并且可以包括任何信息递送介质。“调制数据信号”可以这样的信号,它的数据集中的一个或者多个或者它的改变可以在信号中编码信息的方式进行。作为非限制性的示例,通信介质可以包括诸如有线网络或者专线网络之类的有线介质,以及诸如声音、射频(RF)、微波、红外(IR)或者其它无线介质在内的各种无线介质。这里使用的术语计算机可读介质可以包括存储介质和通信介质二者。
在根据本发明的计算设备200中,应用222包括执行方法300的多条程序指令。
图3示出了根据本发明一个实施例的应用程序的执行方法300的流程图。方法300适于在计算设备(例如前述计算设备200)的第一操作系统中执行,第一操作系统上布置有可兼容第二操作系统的兼容层,应用程序的运行环境为第二操作系统。示例性的,第一操作系统为linux系统,第二操作系统为Windows系统,兼容层为wine。
如图3所示,方法300的目的是在国产处理器上运行x86架构的Windows程序,始于步骤S302,在步骤S302中,在兼容层中嵌入模拟器,形成虚拟层。
在一个具体示例中,该模拟器可选用qemu的一个fork版本叫unicorn(独角兽),unicorn是一个CPU模拟器的sdk库。
Unicorn的用法分这几个步骤:
X86-32bit 模式初始化模拟器对象,具体执行代码如下:
err = uc_open(UC_ARCH_X86, UC_MODE_32, &uc);
if (err != UC_ERR_OK) {
printf("Failed on uc_open() with error returned: %u\n", err);
return -1;
}
给模拟器申请工作内存或者映射已经分配好的内存,具体执行代码如下:uc_mem_map(uc, ADDRESS, 2 * 1024 * 1024, UC_PROT_ALL);
初始化寄存器,具体执行代码如下:
uc_reg_write(uc, UC_X86_REG_ECX, &r_ecx);
uc_reg_write(uc, UC_X86_REG_EDX, &r_edx);
printf(">>> ECX = 0x%x\n", r_ecx);
printf(">>> EDX = 0x%x\n", r_edx);
注册事件处理,这里主要关心 sysenter事件和segfault事件,具体执行代码如下:
uc_hook_add(ret->uc, &ret->sysenter_hook,UC_HOOK_INSN, sysenter, ret,1, 0, UC_X86_INS_SYSENTER);
uc_hook_add(ret->uc,&ret->segfault_hook,UC_HOOK_MEM_UNMAPPED,segfault, ret, 1, 0);
在sysenter事件触发的时候,我们可以得到通知,把guest端的API调用转成host端API调用,使得guest端安全进入host端。
在 segfault事件触发的时候,我们可以有机会把新的host端内存段映射进guest端进程空间。
模拟执行代码,具体执行代码如下:
err = uc_emu_start(uc, ADDRESS, ADDRESS + sizeof(X86_CODE32) - 1, 0,0);
if (err) {
printf("Failed on uc_emu_start() with error returned %u: %s\n",
err, uc_strerror(err));
}
打印寄存器值和结果,具体执行代码如下:
printf("Emulation done. Below is the CPU context\n");
uc_reg_read(uc, UC_X86_REG_ECX, &r_ecx);
uc_reg_read(uc, UC_X86_REG_EDX, &r_edx);
printf(">>> ECX = 0x%x\n", r_ecx);
printf(">>> EDX = 0x%x\n", r_edx);
销毁模拟器对象和释放资源,具体执行代码如下:
uc_close(uc);
对于具体的嵌入过程,本实施例提供了该步骤302的子步骤:
在兼容层中创建模拟器文件。
在模拟器文件中,对每个线程的局部存储空间保存该线程的唯一模拟对象,作为一个应用程序的CPU模拟器。
设置用于启动CPU模拟器的函数。
在一个具体示例中,在兼容层wine中,包括模块nedll,该模块是创建和管理进程和线程的模块,在ntdll模块的unix目录里面新加了一个emulator.c文件,在该文件里面对每个wine线程的局部存储空间保存该线程的唯一unicorn对象来表示一个guest端的cpu;并暴露了一个 x86_emulator_start函数给需要模拟执行的地方调用,该函数的代码表达为:
long long CDECL x86_emulator_start(void* addr, const char *sig,struct TO_ARG * args)
该函数的第一个参数是要模拟执行的目标函数首地址,第二个参数是目标函数原型签名,描述该函数的每个参数的字节大小,第三个参数是传递在线程栈里面的具体参数值,返回值是模拟执行的运算结果。
在该步骤S302中,兼容层能够为在linux系统上运行Windows应用程序提供运行环境,而模拟器可为应用程序提供在非x86架构的处理器上提供运行环境。
另外,为易于将模拟器嵌入兼容层中,在步骤S302开始之前,进行了以下准备工作:
对模拟器进行预处理,以使得模拟器能够嵌入兼容层。具体地,对组成模拟器的代码进行筛选,获取其中关于进程模式的代码。将关于进程模式的代码嵌入兼容层。示例性的,前述提到,qmeu具有两种工作模式,内核模式和进程模式,在此,我们只保qmeu的进程模式的代码,不仅更容易嵌入wine代码中,而且在性能上更优化。
在步骤S304中,基于兼容层,生成应用程序自编译器。
具体地,该步骤S304包括子步骤:
基于编译器的过滤机制,生成编译插件。
利用编译插件解析兼容层中的所有函数,获得兼容层中的所有函数的函数原型;
通过编译插件与函数原型生成应用程序自编译器。
示例性地,在本示例中,编译器选择LLVM,LLVM是一个现代的、基于SSA的、能够支持任意静态和动态编译的编程语言的编译器框架。利用LLVM编译器的pass(过滤器)机制,开发LLVM编译插件,在得到IR时候解析出wine模块的每个API的函数原型。利用编译插件与函数原型生成应用程序自编译器。
需要说明的是,IR为编译器的中间表示(Intermediate Representation),是编译器的前端的输出数据,编译器后端的输入数据。IR的设计很大程度体现着LLVM插件化、模块化的设计哲学,LLVM的各种pass(过滤器)其实都是作用在LLVM IR上的。
在步骤S306中,利用应用程序自编译器,为正加载的应用程序生成可适于在第一操作系统上运行的代理应用程序。
具体地,步骤S306包括如下子步骤:
在兼容层的所有函数的头部预留预定区域;
获取所有函数的函数原型;
基于函数原型的签名信息,按照预定模板利用应用程序自编译器在预定区域写入代理模块。
在一个具体示例中,对代理模块的生成过程进行详细描述:
利用编译器的编译选项-fpatchable-function-entry=24,在编译时候把全部wine函数头部都预留24个字节,作为应用程序的代理桩代码区域。
利用LLVM pass编译插件,从ModulePass(模块过滤)继承,重载runOnModule方法,通过该方法遍历wine的每个模块的每个函数,得到每个函数的原型,保存在一个新的的ELF文件节里面,节名称可定义为__wine_ctags__,框架代码如下:
truct LegacyWinePatch : public ModulePass {
static char ID;
LegacyWinePatch() : ModulePass(ID) {}
// Main entry point - the name conveys what unit of IR this is tobe run on.
bool runOnModule(Module &M) override {
for (auto &F : M) {
func_nums ++;
}
Constant * ctags = CreateGlobalCtags(M, "__wine_ctags__", func_nums* 3);
PointerType *PTy = PointerType::getUnqual(Type::getInt8Ty(CTX));
std::vector
for (auto &F : M) {
if (!F.isDeclaration())
Arrs.push_back(ConstantExpr::getBitCast(&cast
else
Arrs.push_back(ConstantPointerNull::get(PTy));
Arrs.push_back(ConstantExpr::getBitCast(cast
Arrs.push_back(ConstantExpr::getBitCast(cast
}
}
};
在兼容层wine的tools/winebuild模块链接完成wine的模块时候,根据__wine_ctags节里面保存的函数原型签名信息,按照以下模板填充应用程序代理的桩代码:
BYTE guest_proxy_stub[] = {
/* jmp target */
0xEB, 0x11,
/* tag,第一字节是参数个数,第二个字节是调用约定,比如thiscall,fastcall,stdcall等 */
0xff, 0xff, 0xff, 0xff,
/* 如果非零表示跟对应host端实现函数的偏移值 */
0x00, 0x00, 0x00, 0x00,
/* 函数每个参数字节大小签名,每个参数占用3位,8字节, 最多支持21个参数 */
0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00,
/* Reserved fields */
0x00,
/* sysenter */
0x0F, 0x34,
/* ret or ret N */
0xC3,
0xff, 0xff
};
至此,完成代理应用程序的构建。
在步骤S308中,在虚拟层启动代理应用程序,以实现在第一操作系统上运行应用程序。
具体地,将应用程序调用兼容层的函数地址替换为应用程序调用代理模块的函数地址。
容易理解的是,应用程序执行的本质实际为多函数相互配合进行计算的过程,程序执行的结果实际为函数计算的结果。
在继续在先的示例,程序执行中涉及到,应用程序端调用虚拟层中的函数(guest端调用host端API)以及虚拟层回调应用程序端函数(host端回调guest端函数)的过程。
对于guest端调用host端API而言,具体可通过以下步骤完成:
当guest端加载 host端模块的时候,将guest模块的导入表的函数地址由host端函数地址改成指向guest端代理的桩代码首地址,为guest端调用host 端API做准备工作。
guest端调用具体的 host 端API时候,触发了sysenter事件,在sysenter事件里面,根据函数参数签名和保存在栈的具体参数,利用 dyncall 库进行动态调用,代码如下:
DCCallVM* dc = dcNewCallVM(VM_STACK_SIZE);
dcMode(dc, DC_CALL_C_DEFAULT);
dcReset(dc);
dcArgPointer(dc);
dcArgFloat(dc);
dcArgDouble(dc);
dcArgLong(dc);
dcCallPointer(dc, (DCpointer)func);
最后在guest端代理的ret指令返回到 guest 端。
对于host端回调guest端函数而言,host端回调guest端函数时,需要借助Unicorn来模拟执行。具体可通过以下步骤完成:
构建Unicorn执行guest端指令所需的环境。为Unicorn分配一定大小的栈空间,根据NtCurrentTeb函数获取回调函数所在线程TEB,根据TEB来初始化Unicorn模拟执行所需的寄存器。代码如下:
unsigned char stack [STACK_SIZE] = { 0 }
const uint64_t teb = (uint32_t)NtCurrentTeb();
uc_open(UC_ARCH_X86, UC_MODE_32, &uc);
init_gdtr(uc, teb);
uc_reg_write(uc,UC_X86_REG_ESP,(uint32_t*)&(stack+STACK_SIZE));
将回调函数的参数传入Unicorn的栈中,向Unicorn注册sysexit指令回调处理函数,当回调函数执行完成后,停止Unicorn模拟,返回到host端继续执行。代码如下:
uc_hook_add(tls->uc, &sysexit_hook, UC_HOOK_INSN, sysexit,tls, (uint32_t)_exit, (uint32_t)(_exit + sizeof(_exit)), UC_X86_INS_SYSEXIT);
uc_reg_read(uc, UC_X86_REG_ESP, &esp);
esp -= ( 4 * (1 + arg_num));
uc_reg_write(uc, UC_X86_REG_ESP, &esp);
for ( int i = 0; i < arg_num; i++ ) {
((void **)esp)[1 + i] = ((void **)args)[i];
}
uc_emu_start(uc, callback, 0, 0, 0);
uc_reg_read(tls->uc, UC_X86_REG_EAX, &eax);
return (int)eax;
在一个具体示例中,以下面这段代码调用为例对程序执行过程中的函数调用关系进行说明,应用程序需要调用Windows API EnumWindows枚举一个标题为wine-test的窗口,其中EnumWindowsProc 为应用定义的回调函数,供Windows API回调。代码如下:
BOOL CALLBACK EnumWindowsProc(HWND hwnd, LPARAM lParam)
{
char title[MAX_PATH];
GetWindowTextA(hwnd, title);
if (strcmpA(title, "wine-test") == 0)
{
MessageBox("这是一个wine-test窗口!")
}
reutrn True;
}
EnumWindows(EnumWindowsProc, 0);
函数调用方法400的执行流程如图4所示。
本发明提供的方案,在wine代码里面直接嵌入cpu模拟器,在函数调用时候自动识别要调用的目标函数是guest端代码的还是host端代码,如果是guest端代码,自动启动cpu模拟器模拟运行,最后将模拟结果返回给host端。并且利用开源的LLVM编译器的pass(过滤器)机制,开发LLVM编译插件,在得到IR时候解析出wine模块的每个API的原型,动态生成每个API的guest端代理桩代码段。具体的系统框架500结构可参考图5.
另外,为完善本方案,还提供了对在运行应用程序时,发生函数调用过程中的异常进行捕获以及实现应用程序多线程的功能。
在一些实施例中,当guest端调用host端API时,异常捕获是在Unicorn注册的sysenter指令回调函数中处理的。借助setjmp和longjmp来时来实现try catch功能。代码如下:
#define TRY do { jmp_buf ex_buf__; switch( setjmp(ex_buf__) ) { case0: while(1) {
#define CATCH(x) break; case x:
#define FINALLY break; } default: {
#define ETRY break; } } } while(0)
#define THROW(x) longjmp(ex_buf__, x)
在一些实施例中,guest端创建多线程函数最终会调用host端的NtCreateThreadEx函数。在此函数中需要将线程回调函数作下处理,如果该线程函数来自guest端需要进行包装,即创建并填充guest_proxy_stub,并通过dcbNewCallback返回处理完毕的函数指针;如果是host端API则只需将函数指针偏移sizeof(guest_proxy_stub)即可。处理完的函数指针便可以用来创建线程了。
这里描述的各种技术可结合硬件或软件,或者它们的组合一起实现。从而,本发明的方法和设备,或者本发明的方法和设备的某些方面或部分可采取嵌入有形媒介,例如可移动硬盘、U盘、软盘、CD-ROM或者其它任意机器可读的存储介质中的程序代码(即指令)的形式,其中当程序被载入诸如计算机之类的机器,并被所述机器执行时,所述机器变成实践本发明的设备。
在程序代码在可编程计算机上执行的情况下,计算设备一般包括处理器、处理器可读的存储介质(包括易失性和非易失性存储器和/或存储元件),至少一个输入装置,和至少一个输出装置。其中,存储器被配置用于存储程序代码;处理器被配置用于根据该存储器中存储的所述程序代码中的指令,执行本发明的方法。
以示例而非限制的方式,可读介质包括可读存储介质和通信介质。可读存储介质存储诸如计算机可读指令、数据结构、程序模块或其它数据等信息。通信介质一般以诸如载波或其它传输机制等已调制数据信号来体现计算机可读指令、数据结构、程序模块或其它数据,并且包括任何信息传递介质。以上的任一种的组合也包括在可读介质的范围之内。
在此处所提供的说明书中,算法和显示不与任何特定计算机、虚拟系统或者其它设备固有相关。各种通用系统也可以与本发明的示例一起使用。根据上面的描述,构造这类系统所要求的结构是显而易见的。此外,本发明也不针对任何特定编程语言。应当明白,可以利用各种编程语言实现在此描述的本发明的内容,并且上面对特定语言所做的描述是为了披露本发明的较佳实施方式。
在此处所提供的说明书中,说明了大量具体细节。然而,能够理解,本发明的实施例可以在没有这些具体细节的情况下被实践。在一些实例中,并未详细示出公知的方法、结构和技术,以便不模糊对本说明书的理解。
类似地,应当理解,为了精简本公开并帮助理解各个发明方面中的一个或多个,在上面对本发明的示例性实施例的描述中,本发明的各个特征有时被一起分组到单个实施例、图、或者对其的描述中。然而,并不应将该公开的方法解释成反映如下意图:即所要求保护的本发明要求比在每个权利要求中所明确记载的特征更多特征。更确切地说,如下面的权利要求书所反映的那样,发明方面在于少于前面公开的单个实施例的所有特征。因此,遵循具体实施方式的权利要求书由此明确地并入该具体实施方式,其中每个权利要求本身都作为本发明的单独实施例。
本领域那些技术人员应当理解在本文所公开的示例中的设备的模块或单元或组件可以布置在如该实施例中所描述的设备中,或者可替换地可以定位在与该示例中的设备不同的一个或多个设备中。前述示例中的模块可以组合为一个模块或者此外可以分成多个子模块。
本领域那些技术人员可以理解,可以对实施例中的设备中的模块进行自适应性地改变并且把它们设置在与该实施例不同的一个或多个设备中。可以把实施例中的模块或单元或组件组合成一个模块或单元或组件,以及此外可以把它们分成多个子模块或子单元或子组件。除了这样的特征和/或过程或者单元中的至少一些是相互排斥之外,可以采用任何组合对本说明书(包括伴随的权利要求、摘要和附图)中公开的所有特征以及如此公开的任何方法或者设备的所有过程或单元进行组合。除非另外明确陈述,本说明书(包括伴随的权利要求、摘要和附图)中公开的每个特征可以由提供相同、等同或相似目的的替代特征来代替。
此外,本领域的技术人员能够理解,尽管在此所述的一些实施例包括其它实施例中所包括的某些特征而不是其它特征,但是不同实施例的特征的组合意味着处于本发明的范围之内并且形成不同的实施例。例如,在下面的权利要求书中,所要求保护的实施例的任意之一都可以以任意的组合方式来使用。
此外,所述实施例中的一些在此被描述成可以由计算机系统的处理器或者由执行所述功能的其它装置实施的方法或方法元素的组合。因此,具有用于实施所述方法或方法元素的必要指令的处理器形成用于实施该方法或方法元素的装置。此外,装置实施例的在此所述的元素是如下装置的例子:该装置用于实施由为了实施该发明的目的的元素所执行的功能。
如在此所使用的那样,除非另行规定,使用序数词“第一”、“第二”、“第三”等等来描述普通对象仅仅表示涉及类似对象的不同实例,并且并不意图暗示这样被描述的对象必须具有时间上、空间上、排序方面或者以任意其它方式的给定顺序。
尽管根据有限数量的实施例描述了本发明,但是受益于上面的描述,本技术领域内的技术人员明白,在由此描述的本发明的范围内,可以设想其它实施例。此外,应当注意,本说明书中使用的语言主要是为了可读性和教导的目的而选择的,而不是为了解释或者限定本发明的主题而选择的。因此,在不偏离所附权利要求书的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。对于本发明的范围,对本发明所做的公开是说明性的而非限制性的,本发明的范围由所附权利要求书限定。
- 一种应用程序运行方法、计算设备及存储介质
- 一种应用程序的运行方法,计算设备及存储介质