一种目标行为检测方法、系统、计算机设备及机器可读介质
文献发布时间:2023-06-19 11:44:10
技术领域
本发明涉及目标行为检测技术领域,特别是涉及一种目标行为检测方法、系统、计算机设备及机器可读介质。
背景技术
在地铁站、车站、机场等日常公共交通场景中,抽烟是一种最常见的不道德、不安全行为,不但影响他人身体健康,而且是产生火灾的重要隐患来源。长期以来,公共场所的人员普遍存在综合素质参差不齐,安全意识不强的问题,尤其在侥幸心理作祟的情况下大大影响了环境,增加了安全风险。目前常用的吸烟检测方法包括人工监督,机器学习监督方法等。
传统的人工监管存在如下缺点:(1)人力成本增加;(2)人工长时间监控易疲劳,致使监控的疏忽、遗漏或者误判安全隐患;(3)人工监控和人员情绪、状态、工作经验、性格和生活条件的影响,容易在监管治理过程中产生矛盾,引发其他不和谐事件的产生。因此,人工检查存在监管费用高、主观干扰大、不能全程监控等一系列问题。
传统的机器学习监督方法存在以下缺点:在近场景条件下对吸烟行为进行检测,一般摄像头内只有一个人,甚至只有人的上半身,图像信息较为简单,提取的特征也相对单一。如果应用到公共交通场景下,面临多人全景图、人脸分辨率有限、遮挡物较多的问题,以及烟尺度与人体尺度差别较大的问题,检测精度将直线下降。
发明内容
鉴于以上所述现有技术的缺点,本发明的目的在于提供一种目标行为检测方法、系统、计算机设备及机器可读介质,用于解决现有技术中对抽烟行为进行检测时人工监督和/或机器监督存在的缺陷。
为实现上述目的及其他相关目的,本发明提供一种目标行为检测方法,包括以下步骤:
从待检测图像中获取人体框,并基于所述人体框从所述待检测图像中截取出对应的人体框区域图像;
将所述人体框区域图像输入至分类模型中进行行为检测,确定所述待检测图像中的目标对象是否存在目标行为。
可选地,所述分类模型的生成过程包括:
获取多帧图像作为训练图像;
将所述训练图像中存在目标行为的图像标注为正例,不存在目标行为的图像标注为负例;
对标注后的图像进行离线增强,并利用离线增强后的图像训练分类神经网络,生成所述分类模型。
可选地,在生成所述分类模型时,还包括:
对所述分类神经网络中的寻优参数进行调整,形成参数空间;
基于所述参数空间对所述分类神经网络进行寻优,并调整寻优后的分类神经网络的训练参数,形成搜索空间;
按照寻优后的训练策略从所述搜索空间中获取最优的分类模型,并将最优的分类模型作为最终的分类模型;
其中,所述寻优参数包括每个神经单元的Block通道个数、激活函数类型和Block个数;所述训练参数包括分类神经网络的学习率、学习率衰减指数和Batch大小。
可选地,若所述分类模型包括人脸分类模型,则还包括:
获取所述待检测图像的人体关键点,并对所述人体关键点进行解析,从所述人体框中获取人脸框;
基于所述人脸框从所述待检测图像或所述人体框区域图像中获取对应的人脸框区域图像;
将所述人脸框区域图像输入至人脸分类模型,并将所述人脸分类模型输出的概率与第一阈值进行比较;若所述人脸分类模型输出的概率大于等于第一阈值,则认定所述人脸图像以及所述待检测图像中的目标对象存在目标行为;若所述人脸分类模型输出的概率小于第一阈值,则认定所述人脸图像以及所述待检测图像中的目标对象不存在目标行为;
或者,
在所述分类模型包括人手分类模型时,获取所述待检测图像的人体关键点,并对所述人体关键点进行解析,从所述人体框中获取人手框;
基于所述人手框从所述待检测图像或所述人体框区域图像中获取对应的人手框区域图像;
将所述人手框区域图像输入至人手分类模型,并将所述人手分类模型输出的概率与第二阈值进行比较;若所述人手分类模型输出的概率大于等于第二阈值,则确定所述人手图像以及所述待检测图像中的目标对象存在目标行为;若所述人手分类模型输出的概率小于第二阈值,则确定所述人手图像以及所述待检测图像中的目标对象不存在目标行为。
可选地,若所述分类模型包括人手分类模型和人脸分类模型,则分别获取所述人脸分类模型输出的概率以及所述人手分类模型输出的概率,并比较所述人脸分类模型与所述人手分类模型输出的概率,将其中最大的概率值作为所述待检测图像中目标对象是否存在目标行为的最终概率,以及将该最大概率值对应的行为检测结果作为所述待检测图像的行为检测结果。
可选地,所述目标行为包括以下至少之一:人手携带物品行为、人嘴携带物品行为。
本发明还提供一种目标行为检测系统,包括有:
图像框模块,用于从待检测图像中获取人体框;
区域图像模块,用于根据所述人体框从待检测图像中截取出对应的人体框区域图像;
目标行为检测模块,用于将所述人体框区域图像输入至分类模型中进行行为检测,确定所述待检测图像中的目标对象是否存在目标行为。
可选地,在生成所述分类模型时,还包括:
对所述分类神经网络中的寻优参数进行调整,形成参数空间;
基于所述参数空间对所述分类神经网络进行寻优,并调整寻优后的分类神经网络的训练参数,形成搜索空间;
按照寻优后的训练策略从所述搜索空间中获取最优的分类模型,并将最优的分类模型作为最终的分类模型;
其中,所述寻优参数包括每个神经单元的Block通道个数、激活函数类型和Block个数;所述训练参数包括分类神经网络的学习率、学习率衰减指数和Batch大小。
可选地,若所述分类模型包括人脸分类模型,则还包括:
获取所述待检测图像的人体关键点,并对所述人体关键点进行解析,从所述人体框中获取人脸框;
基于所述人脸框从所述待检测图像或所述人体框区域图像中获取对应的人脸框区域图像;
将所述人脸框区域图像输入至人脸分类模型,并将所述人脸分类模型输出的概率与第一阈值进行比较;若所述人脸分类模型输出的概率大于等于第一阈值,则认定所述人脸图像以及所述待检测图像中的目标对象存在目标行为;若所述人脸分类模型输出的概率小于第一阈值,则认定所述人脸图像以及所述待检测图像中的目标对象不存在目标行为;
或者,
在所述分类模型包括人手分类模型时,获取所述待检测图像的人体关键点,并对所述人体关键点进行解析,从所述人体框中获取人手框;
基于所述人手框从所述待检测图像或所述人体框区域图像中获取对应的人手框区域图像;
将所述人手框区域图像输入至人手分类模型,并将所述人手分类模型输出的概率与第二阈值进行比较;若所述人手分类模型输出的概率大于等于第二阈值,则确定所述人手图像以及所述待检测图像中的目标对象存在目标行为;若所述人手分类模型输出的概率小于第二阈值,则确定所述人手图像以及所述待检测图像中的目标对象不存在目标行为。
可选地,若所述分类模型包括人手分类模型和人脸分类模型,则分别获取所述人脸分类模型输出的概率以及所述人手分类模型输出的概率,并比较所述人脸分类模型与所述人手分类模型输出的概率,将其中最大的概率值作为所述待检测图像中目标对象是否存在目标行为的最终概率,以及将该最大概率值对应的行为检测结果作为所述待检测图像的行为检测结果。
本发明还提供一种计算机设备,包括:
一个或多个处理器;和
存储有指令的一个或多个机器可读介质,当所述一个或多个处理器执行所述指令时,使得所述设备执行如上述中任意一项所述的方法。
本发明还提供一个或多个机器可读介质,其上存储有指令,当由一个或多个处理器执行所述指令时,使得设备执行如上述中任意一项所述的方法。
如上所述,本发明提供一种目标行为检测方法、系统、计算机设备及机器可读介质,具有以下有益效果:通过从待检测图像中获取人体框,并基于人体框从待检测图像中截取出对应的人体框区域图像;将人体框区域图像输入至分类模型中进行行为检测,确定所述待检测图像中的目标对象是否存在目标行为。本发明针对现有技术存在的问题,提出了一种基于深度卷积网络的复杂场景多尺度行为检测方案,适用于公共交通要所等复杂场景条件下的目标行为(例如抽烟行为)监督。本发明可以将图像识别的判断位置精确到人脸和人手,解决了目标尺度与人体尺度差别大的问题,同时分类模型能准确地判断出目标行为的特征信息,大幅提升目标行为的检测精度。现有的检测方案由于输入的是完整图像,分类模型感受野中类烟特征数量庞大,会造成语义信息混淆、检率高的问题。而本发明首先对目标行为发生位置预先进行了精确定位,并在分类模型训练中辅以大量普通人脸、人手及背景环境负例,可以让分类模型的误检率达到0.05%以下,从而给用户带来更好的体验。同时,本发明对于全景图内的人数、人脸分辨率程度和遮挡程度的影响具备较高的鲁棒性。
附图说明
图1为一实施例提供的目标行为检测方法流程示意图;
图2为一实施例提供的数据增强的示意图;
图3a为一实施例提供的寻优搜索的示意图;
图3b为图3a中一个神经元的结构示意图;
图4为一实施例提供的人体关键点示意图;
图5为一实施例提供的抽烟行为检测示意图;
图6为另一实施例提供的目标行为检测方法流程示意图;
图7为一实施例提供的目标行为检测系统的硬件结构示意图;
图8为一实施例提供的终端设备的硬件结构示意图;
图9为另一实施例提供的终端设备的硬件结构示意图。
元件标号说明
M10 图像框模块
M20 区域图像模块
M30 目标行为检测模块
1100 输入设备
1101 第一处理器
1102 输出设备
1103 第一存储器
1104 通信总线
1200 处理组件
1201 第二处理器
1202 第二存储器
1203 通信组件
1204 电源组件
1205 多媒体组件
1206 音频组件
1207 输入/输出接口
1208 传感器组件
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,遂图式中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。
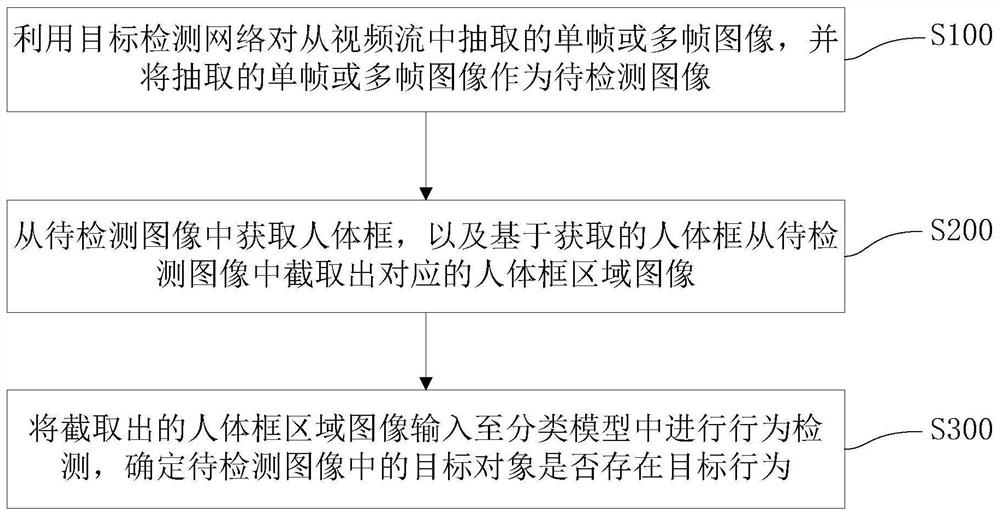
请参阅图1,本发明提供一种目标行为检测方法,包括以下步骤:
S100,利用目标检测网络对从视频流中抽取的单帧或多帧图像,并将抽取的单帧或多帧图像作为待检测图像;
S200,从待检测图像中获取人体框,以及基于获取的人体框从待检测图像中截取出对应的人体框区域图像;
S300,将截取出的人体框区域图像输入至分类模型中进行行为检测,确定待检测图像中的目标对象是否存在目标行为;其中,目标对象为人。
本方法针对现有技术存在的问题,提出了一种基于深度卷积网络的复杂场景多尺度行为检测方案,适用于公共交通要所等复杂场景条件下的目标行为(例如抽烟行为)监督。本方法可以将图像识别的判断位置精确到人脸和人手,解决了目标尺度与人体尺度差别大的问题,同时分类模型能准确地判断出目标行为的特征信息,大幅提升目标行为的检测精度。现有的检测方案由于输入的是完整图像,分类模型感受野中类烟特征数量庞大,会造成语义信息混淆、检率高的问题。而本方法首先对目标行为发生位置预先进行了精确定位,并在分类模型训练中辅以大量普通人脸、人手及背景环境负例,可以让分类模型的误检率达到0.05%以下,从而给用户带来更好的体验。同时,本方法对于全景图内的人数、人脸分辨率程度和遮挡程度的影响具备较高的鲁棒性。本方法基于深度卷积网络对复杂场景下的目标行为进行检测,不仅检测速度快且准确率高,而且还能够应用于公共交通场所等多人群、高遮挡的复杂场景。相较于传统的视觉检测方法在复杂场景吸烟行为中的应用,本方法大幅提升了检测精度,且针对多人、多场景、人脸分辨率低等严苛条件下依旧具备较高的检出率和鲁棒性。
在一示例性实施例中,分类模型的生成过程包括:获取多帧图像作为训练图像,将训练图像中存在目标行为的图像标注为正例,不存在目标行为的图像标注为负例;对标注后的图像进行离线增强,并利用离线增强后的图像训练分类神经网络,生成分类模型。作为示例,本申请实施例可以通过合法爬虫网络图像、影视作品,合法获取地铁、车站等公共场所监控视频中的帧图像,以及自己拍摄图像等图像采集途径来获取大量包含有目标行为和不包含有目标行为的图像作为训练图像。在对训练图像进行标注时,由于正例数据普遍比负例数据难以获取,所以本申请实施例为保证生成的分类模型的精度,还可以调整正例或负例的类别平衡度。本申请对采集的图像进行标注后的正负例分布情况如下:人脸数据集中正例分布为20000个,负例分布为150000个;人手数据集中正例分布为30000个,负例分布为180000个。在对标注后的图像进行离线增强时,可以通过翻转、旋转、仿射变换、噪声等离线增强方式将正例数量增加3倍;且在分类模型的训练过程中,为保证训练图像的多样性和模型泛化性能,采用自动数据增强技术优化得到多种最优增强方法,并在实际的模型训练中进行在线增强。本申请实施例中进行对训练数据自动数据增强的实现流程如图2所示。对训练图像完成离线增强后,再利用离线增强后的图像训练分类神经网络,生成分类模型。
在本申请实施例中,利用自动数据增强技术进行数据增强是提升训练数据集质量、优化数据集分布的有效手段之一,所以神经网络模型的训练效果强烈依赖于训练数据集的质量和分布。然而,目前可用的数据增强方法有数百种之多,如何选择最适用于当前数据集特点的增强方法是模型训练的难点之一,现有的多是依赖于算法工程师的经验。因此,本方法还提出了采用寻优算法对训练数据集进行数据增强方法的优化求解方法,相比神经网络模型的变化,数据增强方法的优劣更取决于数据集分布,基于此特点,本发明在深度神经网络模型训练之前,预先采用基础神经网络对数据增强方法进行寻优,由于其个体训练速度较快,能够很快获得针对此数据集分布特点的较优数据增强方法。具体地,在生成分类模型时,还包括:对分类神经网络中的寻优参数进行调整,形成参数空间;基于参数空间对分类神经网络进行寻优,并对寻优后的分类神经网络进行超参数搜索或者调整寻优后的分类神经网络的训练参数,形成搜索空间;按照寻优后的训练策略从搜索空间中获取最优的分类模型,并将最优的分类模型作为最终的分类模型;其中,寻优参数包括每个神经单元的Block通道个数、激活函数类型和Block个数;训练参数包括分类神经网络的学习率、学习率衰减指数和Batch大小。
目前深度学习技术已应用于各个领域,并解决了包括对象分类和检测,语言建模,推荐系统等关键AI任务。然而,现有技术中的大部分模型是设计者通过反复试验手动设计的,强烈依赖专家经验,意味着必须花费大量的资源和时间来设计性能良好的模型。而本方法通过应用AutoML(Auto Machine Learning,自动机器学习)技术,采用寻优算法对图像分类模型的超参数以及网络结构进行优化设计,能够自动寻找在当前数据集下的最优模型。本方法中首先采用NAS(Neural Architecture Search,神经网络架构搜索)方法对模型结构进行寻优,神经网络架构搜索的示意图如图3所示。神经网络的神经元CELL包括VGGBlock,ResNet Block、MobileNet Block、ResNeXt Block等神经网络块。本申请实施例首先通过对神经元CELL中Block的通道个数、激活函数类型、Block个数等寻优参数进行调整形成参数空间,进而利用参数空间进行寻优。然后在寻找得到较优的深度模型后,对其进行进一步超参数搜索(HPO),即对学习率、学习率衰减指数、Batch size等训练参数微调形成搜索空间,最终通过最优的训练策略获得最优的分类模型。其中,分类模型包括人脸分类模型和/或人手分类模型。作为示例,本申请实施例采用AutoML训练框架对人脸分类模型和/或人手分类模型进行训练。采用VGG Block,ResNet Block,MobileNet Block,ResNeXt Block等block作为NAS搜索的基本单元,将分类模型的宽度设置为64~256的通道数范围,将分类模型的深度设置为4个block;输入尺寸为128像素*128像素的人脸图像和/或人手图像,并以模型精度和FLOPS的加权值作为寻优目标,最终优化得到了精度和性能综合最优的人脸模型和人手模型。
在一示例性实施例中,若分类模型包括人脸分类模型,则还包括:获取待检测图像的人体关键点,并对人体关键点进行解析,从人体框中获取人脸框;基于人脸框从待检测图像或人体框区域图像中获取对应的人脸框区域图像;将人脸框区域图像输入至人脸分类模型,并将人脸分类模型输出的概率与预设阈值进行比较;若人脸分类模型输出的概率大于等于第一阈值,则认定人脸图像以及待检测图像中的目标对象存在目标行为;若人脸分类模型输出的概率小于第一阈值,则认定人脸图像以及待检测图像中的目标对象不存在目标行为。具体地,首先采用CenterNet作为目标检测网络,利用CenterNet对抽帧图像进行人体检测和人体关键点检测,将抽帧出的原始图像尺寸进行重新调整resize,调整到640像素*480像素的尺寸,并将调整后的图像经过归一化处理后输入至CenterNet中,得到图像中每个人体框以及14个人体关键点坐标。其中,14个人体关键点坐标如图4所示。其次,对人体框中的人脸进行检测,将人体框的尺寸重新调整resize到128像素*128像素的尺寸,并将调整后的人体框输入至人脸检测模型resnet50+ssd中,结合人体关键点坐标从人体框中得到人脸的关键点坐标,同时基于得到的人脸关键点坐标形成对应的人脸框,并根据得到的人脸框从抽帧得到的原始图像中裁剪出对应的人脸框区域图像,再将裁剪出的人脸框区域图像输入至人脸分类模型中,比较人脸分类模型输出的概率与预设阈值的大小关系;若人脸分类模型输出的概率大于等于第一阈值,则认定人脸图像以及待检测图像中的目标对象存在目标行为;若人脸分类模型输出的概率小于第一阈值,则认定人脸图像以及待检测图像中的目标对象不存在目标行为。其中,目标行为包括但不限于人脸携带物品行为,例如人嘴抽着烟的行为。利用人脸分类模型检测抽烟行为时,只要人员嘴里有烟就算该人员存在抽烟行为,即认定对应的人脸图像和原始的抽帧图像就存在抽烟行为;抽烟行为的检测过程如图5所示。本申请实施例中的第一阈值可以根据实际情况进行设定,本申请不对其进行数值限定。
在另一示例性实施例中,若分类模型包括人手分类模型时,则获取待检测图像的人体关键点,并对人体关键点进行解析,从人体框中获取人手框;基于人手框从待检测图像或人体框区域图像中获取对应的人手框区域图像;将人手框区域图像输入至人手分类模型,并将人手分类模型输出的概率与预设阈值进行比较;若人手分类模型输出的概率大于等于第二阈值,则确定人手图像以及待检测图像中的目标对象存在目标行为;若人手分类模型输出的概率小于第二阈值,则确定人手图像以及待检测图像中的目标对象不存在目标行为。具体地,首先采用CenterNet作为目标检测网络,利用CenterNet对抽帧图像进行人体检测和人体关键点检测,将抽帧出的原始图像尺寸进行重新调整resize,调整到640像素*480像素的尺寸,并将调整后的图像经过归一化处理后输入至CenterNet中,得到图像中每个人体框以及14个人体关键点坐标。其中,14个人体关键点坐标如图4所示。其次,将人体框的尺寸重新调整resize到128像素*128像素的尺寸,对人体框中的人体关键点进行解析,在人体关键点坐标的基础上,再通过逻辑判断获取手心位置和人手框大小,得到对应的人手框。然后根据得到的人手框从抽帧得到的帧图像中裁剪出对应的人手框区域图像,再将裁剪出的人手框区域图像输入至人手分类模型中,比较人手分类模型输出的概率与预设阈值的大小关系;若人手分类模型输出的概率大于等于第二阈值,则认定人手图像以及待检测图像中的目标对象存在目标行为;若人手分类模型输出的概率小于第二阈值,则认定人手图像以及待检测图像中的目标对象不存在目标行为。其中,目标行为包括但不限于人手携带物品行为,例如人手拿着烟的行为。利用人手分类模型检测抽烟行为时,只要人员手里有烟就算该人员存在抽烟行为,即认定对应的人手图像和原始的抽帧图像就存在抽烟行为;抽烟行为的检测过程如图5所示。本申请实施例中的第二阈值可以根据实际情况进行设定,本申请不对其进行数值限定。
在另一示例性实施例中,若分类模型包括人手分类模型和人脸分类模型,则分别获取人脸分类模型输出的概率以及人手分类模型输出的概率,并将人脸分类模型输出的概率与人手分类模型输出的概率进行比较,将其中最大的概率值作为认定待检测图像中的目标对象是否存在目标行为的最终概率,以及将该最大概率值对应的行为检测结果作为所述待检测图像的行为检测结果。
由于目前的One stage/Two stage目标检测识别往往在图像上将目标用矩形框形式框出,该框的水平和垂直轴与图像的水平和垂直相平行,所以现有的大多数目标检测器都先穷举出潜在目标位置,然后对该位置进行分类;但是这种做法不仅浪费时间,还低效,也需要额外的后处理。因此,本申请在上述实施例中采用源模型CenterNet作为人体检测或人体关键点检测的深度神经网络。本申请实施例采用CenterNet作为检测网络,构建模型时将目标作为一个点,即目标Bounding Box的中心点。检测器采用关键点估计来找到中心点,并回归到其他目标属性,例如尺寸、3D位置、方向、甚至姿态。相比较于基于Bounding Box的检测器,本发明中的模型是端到端可微的,具有更简单、更快、更精确的优点,且实现了速度和精确的最好权衡。
根据上述记载,在训练得到人脸分类模型和/或人手分类模型,以及完成对应的行为检测后,本方法还可以将所有的分类模型转换为plan格式,并部署在TensorRT上进行深度学习判断和推理,使分类模型的性能得到进一步的提升。
如图2至6所示,以检测抽烟行为为例,本方法还提供一个具体的检测图像中的目标对象是否存在抽烟行为的过程,包括有:
从监控视频流中抽取单帧或多帧图像作为待检测图像;其中,监控视频流由一个或多个摄像头拍摄形成。
采用CenterNet作为人体检测网络和人体关键点检测网络,对待检测图像进行人体检测和人体关键点检测,得到包含有待检测图像中人员的人体框和每个人体框对应的人体关键点坐标。具体地,将待检测图像的尺寸进行重新调整resize,调整到640像素*480像素的尺寸,并将调整后的图像经过归一化处理后输入至CenterNet中,得到待检测图像中每个人体框以及14个人体关键点坐标。其中,14个人体关键点坐标如图4所示。由于目前的Onestage/Two stage目标检测识别往往在图像上将目标用矩形框形式框出,该框的水平和垂直轴与图像的水平和垂直相平行,所以现有的大多数目标检测器都先穷举出潜在目标位置,然后对该位置进行分类;但是这种做法不仅浪费时间,还低效,也需要额外的后处理。因此,本申请实施例采用源模型CenterNet作为人体/关键点检测的深度神经网络。本申请实施例采用CenterNet作为检测网络,构建模型时将目标作为一个点,即目标Bounding Box的中心点。检测器采用关键点估计来找到中心点,并回归到其他目标属性,例如尺寸、3D位置、方向、甚至姿态。相比较于基于Bounding Box的检测器,本发明中的模型是端到端可微的,具有更简单、更快、更精确的优点,且实现了速度和精确的最好权衡。
获取人体框和每个人体框对应的人体关键点坐标,并在人体关键点坐标的基础上,按照人脸检测方式和人手区域检测逻辑对人体框进行人脸检测和人手检测,分别得到人脸框和人手框。具体地,对人体框中的人脸进行检测:将人体框的尺寸重新调整resize到128像素*128像素的尺寸,并将调整后的人体框输入至人脸检测模型中,结合人体关键点坐标从人体框中得到人脸的关键点坐标,同时基于得到的人脸关键点坐标形成对应的人脸框;然后将得到的人脸框输入至人脸分类模型中。本申请实施例采用resnet50+ssd作为人脸检测模型。对人体框中的人手进行检测:将人体框的尺寸重新调整resize到128像素*128像素的尺寸,对人体框中的人体关键点进行解析,在人体关键点坐标的基础上,再通过逻辑判断获取手心位置和人手框大小,得到对应的人手框。
根据人脸框对人脸进行分类,以及根据人手框对人手进行分类,得到人脸和人手的分类结果。具体地,基于该人脸框从待检测图像中截取出对应的人脸图像,并将截取出的人脸图像输入至人脸分类模型中,通过人脸分类模型中的softmax层输出存在抽烟行为的概率或对应的行为评分,并将该概率或该行为评分作为人脸分类模型的分类结果。其中,本申请实施例采用resnet50+ssd作为人脸检测模型。以及基于该人手框从原始的抽帧图像中截取出对应的人手图像,并将截取出的人手图像输入至人手分类模型中,通过人手分类模型中的softmax层输出目标行为的概率或对应的行为评分,并将该概率或该行为评分作为人手分类模型的分类结果。
基于人脸和人手的分类结果判断待检测图像中是否存在抽烟行为。如果人脸分类模型输出的行为评分或行为概率大于等于预设阈值,和/或人手分类模型输出的行为评分或行为概率大于等于预设阈值,则确定待检测图像中存在抽烟行为。对于同一个人体中,以人脸分类模型、人手分类模型输出的最大概率值作为待检测图像的最终抽烟概率。并在判断出待检测图像存在抽烟行为后,按照预设报警条件进行报警。如果人脸分类模型输出的行为评分或行为概率小于预设阈值,且人手分类模型输出的行为评分或行为概率小于预设阈值,则确定待检测图像中不存在抽烟行为。并继续从监控视频流中抽取单帧或多帧图像作为待检测图像,继续检测待检测图像是否存在抽烟行为。
综上所述,本方法针对现有技术存在的问题,提出了一种基于深度卷积网络的复杂场景多尺度行为检测方案,适用于公共交通要所等复杂场景条件下的目标行为(例如抽烟行为)监督。本方法首先采用最新基于中心点的开源目标检测网络CenterNet对人群场景下进行人体检测和人体关键点检测;在获取人体框信息和关键点信息之后,通过人脸检测和人手区域逻辑判断获得人脸框和人手框。然后通过AutoML技术训练生成人脸分类模型和人手分类模型,并利用得到的人脸分类模型和人手分类模型输出人脸和双手的抽烟行为概率,获的最终的检测结果。本方法可以将图像识别的判断位置精确到人脸和人手,解决了目标尺度与人体尺度差别大的问题,同时分类模型能准确地判断出目标行为的特征信息,大幅提升目标行为的检测精度。现有的检测方案由于输入的是完整图像,分类模型感受野中类烟特征数量庞大,会造成语义信息混淆、检率高的问题。而本方法首先对目标行为发生位置预先进行了精确定位,并在分类模型训练中辅以大量普通人脸、人手及背景环境负例,可以让分类模型的误检率达到0.05%以下,从而给用户带来更好的体验。同时,本方法对于全景图内的人数、人脸分辨率程度和遮挡程度的影响具备较高的鲁棒性。另外,本方法基于深度卷积网络对复杂场景下的目标行为进行检测,不仅检测速度快且准确率高,而且还能够应用于公共交通场所等多人群、高遮挡的复杂场景。相较于传统的视觉检测方法在复杂场景吸烟行为中的应用,本方法大幅提升了检测精度,且针对多人、多场景、人脸分辨率低等严苛条件下依旧具备较高的检出率和鲁棒性。
如图7所示,本发明还提供一种目标行为检测系统,包括有:
图像框模块M10,用于从待检测图像中获取人体框;
区域图像模块M20,用于根据所述人体框从待检测图像中截取出对应的人体框区域图像;
目标行为检测模块M30,用于将所述人体框区域图像输入至分类模型中进行行为检测,确定所述待检测图像中的目标对象是否存在目标行为。
本系统针对现有技术存在的问题,提出了一种基于深度卷积网络的复杂场景多尺度行为检测方案,适用于公共交通要所等复杂场景条件下的目标行为(例如抽烟行为)监督。本系统可以将图像识别的判断位置精确到人脸和人手,解决了目标尺度与人体尺度差别大的问题,同时分类模型能准确地判断出目标行为的特征信息,大幅提升目标行为的检测精度。现有的检测方案由于输入的是完整图像,分类模型感受野中类烟特征数量庞大,会造成语义信息混淆、检率高的问题。而本系统首先对目标行为发生位置预先进行了精确定位,并在分类模型训练中辅以大量普通人脸、人手及背景环境负例,可以让分类模型的误检率达到0.05%以下,从而给用户带来更好的体验。同时,本系统对于全景图内的人数、人脸分辨率程度和遮挡程度的影响具备较高的鲁棒性。本系统基于深度卷积网络对复杂场景下的目标行为进行检测,不仅检测速度快且准确率高,而且还能够应用于公共交通场所等多人群、高遮挡的复杂场景。相较于传统的视觉检测方法在复杂场景吸烟行为中的应用,本系统大幅提升了检测精度,且针对多人、多场景、人脸分辨率低等严苛条件下依旧具备较高的检出率和鲁棒性。
在一示例性实施例中,分类模型的生成过程包括:获取多帧图像作为训练图像,将训练图像中存在目标行为的图像标注为正例,不存在目标行为的图像标注为负例;对标注后的图像进行离线增强,并利用离线增强后的图像训练分类神经网络,生成分类模型。作为示例,本申请实施例可以通过合法爬虫网络图像、影视作品,合法获取地铁、车站等公共场所监控视频中的帧图像,以及自己拍摄图像等图像采集途径来获取大量包含有目标行为和不包含有目标行为的图像作为训练图像。在对训练图像进行标注时,由于正例数据普遍比负例数据难以获取,所以本申请实施例为保证生成的分类模型的精度,还可以调整正例或负例的类别平衡度。本申请对采集的图像进行标注后的正负例分布情况如下:人脸数据集中正例分布为20000个,负例分布为150000个;人手数据集中正例分布为30000个,负例分布为180000个。在对标注后的图像进行离线增强时,可以通过翻转、旋转、仿射变换、噪声等离线增强方式将正例数量增加3倍;且在分类模型的训练过程中,为保证训练图像的多样性和模型泛化性能,采用自动数据增强技术优化得到多种最优增强方法,并在实际的模型训练中进行在线增强。本申请实施例中进行对训练数据自动数据增强的实现流程如图2所示。对训练图像完成离线增强后,再利用离线增强后的图像训练分类神经网络,生成分类模型。
在本申请实施例中,利用自动数据增强技术进行数据增强是提升训练数据集质量、优化数据集分布的有效手段之一,所以神经网络模型的训练效果强烈依赖于训练数据集的质量和分布。然而,目前可用的数据增强方法有数百种之多,如何选择最适用于当前数据集特点的增强方法是模型训练的难点之一,现有的多是依赖于算法工程师的经验。因此,本系统还提出了采用寻优算法对训练数据集进行数据增强方法的优化求解方法,相比神经网络模型的变化,数据增强方法的优劣更取决于数据集分布,基于此特点,本发明在深度神经网络模型训练之前,预先采用基础神经网络对数据增强方法进行寻优,由于其个体训练速度较快,能够很快获得针对此数据集分布特点的较优数据增强方法。具体地,在生成分类模型时,还包括:对分类神经网络中的寻优参数进行调整,形成参数空间;基于参数空间对分类神经网络进行寻优,并对寻优后的分类神经网络进行超参数搜索或者调整寻优后的分类神经网络的训练参数,形成搜索空间;按照寻优后的训练策略从搜索空间中获取最优的分类模型,并将最优的分类模型作为最终的分类模型;其中,寻优参数包括每个神经单元的Block通道个数、激活函数类型和Block个数;训练参数包括分类神经网络的学习率、学习率衰减指数和Batch大小。
目前深度学习技术已应用于各个领域,并解决了包括对象分类和检测,语言建模,推荐系统等关键AI任务。然而,现有技术中的大部分模型是设计者通过反复试验手动设计的,强烈依赖专家经验,意味着必须花费大量的资源和时间来设计性能良好的模型。而本系统通过应用AutoML(Auto Machine Learning,自动机器学习)技术,采用寻优算法对图像分类模型的超参数以及网络结构进行优化设计,能够自动寻找在当前数据集下的最优模型。本系统首先采用NAS(Neural Architecture Search,神经网络架构搜索)方法对模型结构进行寻优,神经网络架构搜索的示意图如图3所示。神经网络的神经元CELL包括VGG Block,ResNet Block、MobileNet Block、ResNeXt Block等神经网络块。本申请实施例首先通过对神经元CELL中Block的通道个数、激活函数类型、Block个数等寻优参数进行调整形成参数空间,进而利用参数空间进行寻优。然后在寻找得到较优的深度模型后,对其进行进一步超参数搜索(HPO),即对学习率、学习率衰减指数、Batch size等训练参数微调形成搜索空间,最终通过最优的训练策略获得最优的分类模型。其中,分类模型包括人脸分类模型和/或人手分类模型。作为示例,本申请实施例采用AutoML训练框架对人脸分类模型和/或人手分类模型进行训练。采用VGG Block,ResNet Block,MobileNet Block,ResNeXt Block等block作为NAS搜索的基本单元,将分类模型的宽度设置为64~256的通道数范围,将分类模型的深度设置为4个block;输入尺寸为128像素*128像素的人脸图像和/或人手图像,并以模型精度和FLOPS的加权值作为寻优目标,最终优化得到了精度和性能综合最优的人脸模型和人手模型。
在一示例性实施例中,若分类模型包括人脸分类模型,则还包括:获取待检测图像的人体关键点,并对人体关键点进行解析,从人体框中获取人脸框;基于人脸框从待检测图像或人体框区域图像中获取对应的人脸框区域图像;将人脸框区域图像输入至人脸分类模型,并将人脸分类模型输出的概率与预设阈值进行比较;若人脸分类模型输出的概率大于等于第一阈值,则认定人脸图像以及待检测图像中的目标对象存在目标行为;若人脸分类模型输出的概率小于第一阈值,则认定人脸图像以及待检测图像中的目标对象不存在目标行为。具体地,首先采用CenterNet作为目标检测网络,利用CenterNet对抽帧图像进行人体检测和人体关键点检测,将抽帧出的原始图像尺寸进行重新调整resize,调整到640像素*480像素的尺寸,并将调整后的图像经过归一化处理后输入至CenterNet中,得到图像中每个人体框以及14个人体关键点坐标。其中,14个人体关键点坐标如图4所示。其次,对人体框中的人脸进行检测,将人体框的尺寸重新调整resize到128像素*128像素的尺寸,并将调整后的人体框输入至人脸检测模型resnet50+ssd中,结合人体关键点坐标从人体框中得到人脸的关键点坐标,同时基于得到的人脸关键点坐标形成对应的人脸框,并根据得到的人脸框从抽帧得到的原始图像中裁剪出对应的人脸框区域图像,再将裁剪出的人脸框区域图像输入至人脸分类模型中,比较人脸分类模型输出的概率与预设阈值的大小关系;若人脸分类模型输出的概率大于等于第一阈值,则认定人脸图像以及待检测图像中的目标对象存在目标行为;若人脸分类模型输出的概率小于第一阈值,则认定人脸图像以及待检测图像中的目标对象不存在目标行为。其中,目标行为包括但不限于人脸携带物品行为,例如人嘴抽着烟的行为。利用人脸分类模型检测抽烟行为时,只要人员嘴里有烟就算该人员存在抽烟行为,即认定对应的人脸图像和原始的抽帧图像就存在抽烟行为;抽烟行为的检测过程如图5所示。本申请实施例中的第一阈值可以根据实际情况进行设定,本申请不对其进行数值限定。
在另一示例性实施例中,若分类模型包括人手分类模型时,则获取待检测图像的人体关键点,并对人体关键点进行解析,从人体框中获取人手框;基于人手框从待检测图像或人体框区域图像中获取对应的人手框区域图像;将人手框区域图像输入至人手分类模型,并将人手分类模型输出的概率与预设阈值进行比较;若人手分类模型输出的概率大于等于第二阈值,则确定人手图像以及待检测图像中的目标对象存在目标行为;若人手分类模型输出的概率小于第二阈值,则确定人手图像以及待检测图像中的目标对象不存在目标行为。具体地,首先采用CenterNet作为目标检测网络,利用CenterNet对抽帧图像进行人体检测和人体关键点检测,将抽帧出的原始图像尺寸进行重新调整resize,调整到640像素*480像素的尺寸,并将调整后的图像经过归一化处理后输入至CenterNet中,得到图像中每个人体框以及14个人体关键点坐标。其中,14个人体关键点坐标如图4所示。其次,将人体框的尺寸重新调整resize到128像素*128像素的尺寸,对人体框中的人体关键点进行解析,在人体关键点坐标的基础上,再通过逻辑判断获取手心位置和人手框大小,得到对应的人手框。然后根据得到的人手框从抽帧得到的帧图像中裁剪出对应的人手框区域图像,再将裁剪出的人手框区域图像输入至人手分类模型中,比较人手分类模型输出的概率与预设阈值的大小关系;若人手分类模型输出的概率大于等于第二阈值,则认定人手图像以及待检测图像中的目标对象存在目标行为;若人手分类模型输出的概率小于第二阈值,则认定人手图像以及待检测图像中的目标对象不存在目标行为。其中,目标行为包括但不限于人手携带物品行为,例如人手拿着烟的行为。利用人手分类模型检测抽烟行为时,只要人员手里有烟就算该人员存在抽烟行为,即认定对应的人手图像和原始的抽帧图像就存在抽烟行为;抽烟行为的检测过程如图5所示。本申请实施例中的第二阈值可以根据实际情况进行设定,本申请不对其进行数值限定。
在另一示例性实施例中,若分类模型包括人手分类模型和人脸分类模型,则分别获取人脸分类模型输出的概率以及人手分类模型输出的概率,并将人脸分类模型输出的概率与人手分类模型输出的概率进行比较,将其中最大的概率值作为认定待检测图像中的目标对象是否存在目标行为的最终概率,以及将该最大概率值对应的行为检测结果作为所述待检测图像的行为检测结果。
由于目前的One stage/Two stage目标检测识别往往在图像上将目标用矩形框形式框出,该框的水平和垂直轴与图像的水平和垂直相平行,所以现有的大多数目标检测器都先穷举出潜在目标位置,然后对该位置进行分类;但是这种做法不仅浪费时间,还低效,也需要额外的后处理。因此,本申请在上述实施例中采用源模型CenterNet作为人体检测或人体关键点检测的深度神经网络。本申请实施例采用CenterNet作为检测网络,构建模型时将目标作为一个点,即目标Bounding Box的中心点。检测器采用关键点估计来找到中心点,并回归到其他目标属性,例如尺寸、3D位置、方向、甚至姿态。相比较于基于Bounding Box的检测器,本发明中的模型是端到端可微的,具有更简单、更快、更精确的优点,且实现了速度和精确的最好权衡。
根据上述记载,在训练得到人脸分类模型和/或人手分类模型,以及完成对应的行为检测后,本系统还可以将所有的分类模型转换为plan格式,并部署在TensorRT上进行深度学习判断和推理,使分类模型的性能得到进一步的提升。
如图2至6所示,以检测抽烟行为为例,本系统还提供一个具体的检测图像中的目标对象是否存在抽烟行为的过程,包括有:
从监控视频流中抽取单帧或多帧图像作为待检测图像;其中,监控视频流由一个或多个摄像头拍摄形成。
采用CenterNet作为人体检测网络和人体关键点检测网络,对待检测图像进行人体检测和人体关键点检测,得到包含有待检测图像中人员的人体框和每个人体框对应的人体关键点坐标。具体地,将待检测图像的尺寸进行重新调整resize,调整到640像素*480像素的尺寸,并将调整后的图像经过归一化处理后输入至CenterNet中,得到待检测图像中每个人体框以及14个人体关键点坐标。其中,14个人体关键点坐标如图4所示。由于目前的Onestage/Two stage目标检测识别往往在图像上将目标用矩形框形式框出,该框的水平和垂直轴与图像的水平和垂直相平行,所以现有的大多数目标检测器都先穷举出潜在目标位置,然后对该位置进行分类;但是这种做法不仅浪费时间,还低效,也需要额外的后处理。因此,本申请实施例采用源模型CenterNet作为人体/关键点检测的深度神经网络。本申请实施例采用CenterNet作为检测网络,构建模型时将目标作为一个点,即目标Bounding Box的中心点。检测器采用关键点估计来找到中心点,并回归到其他目标属性,例如尺寸、3D位置、方向、甚至姿态。相比较于基于Bounding Box的检测器,本发明中的模型是端到端可微的,具有更简单、更快、更精确的优点,且实现了速度和精确的最好权衡。
获取人体框和每个人体框对应的人体关键点坐标,并在人体关键点坐标的基础上,按照人脸检测方式和人手区域检测逻辑对人体框进行人脸检测和人手检测,分别得到人脸框和人手框。具体地,对人体框中的人脸进行检测:将人体框的尺寸重新调整resize到128像素*128像素的尺寸,并将调整后的人体框输入至人脸检测模型中,结合人体关键点坐标从人体框中得到人脸的关键点坐标,同时基于得到的人脸关键点坐标形成对应的人脸框;然后将得到的人脸框输入至人脸分类模型中。本申请实施例采用resnet50+ssd作为人脸检测模型。对人体框中的人手进行检测:将人体框的尺寸重新调整resize到128像素*128像素的尺寸,对人体框中的人体关键点进行解析,在人体关键点坐标的基础上,再通过逻辑判断获取手心位置和人手框大小,得到对应的人手框。
根据人脸框对人脸进行分类,以及根据人手框对人手进行分类,得到人脸和人手的分类结果。具体地,基于该人脸框从待检测图像中截取出对应的人脸图像,并将截取出的人脸图像输入至人脸分类模型中,通过人脸分类模型中的softmax层输出存在抽烟行为的概率或对应的行为评分,并将该概率或该行为评分作为人脸分类模型的分类结果。其中,本申请实施例采用resnet50+ssd作为人脸检测模型。以及基于该人手框从原始的抽帧图像中截取出对应的人手图像,并将截取出的人手图像输入至人手分类模型中,通过人手分类模型中的softmax层输出目标行为的概率或对应的行为评分,并将该概率或该行为评分作为人手分类模型的分类结果。
基于人脸和人手的分类结果判断待检测图像中是否存在抽烟行为。如果人脸分类模型输出的行为评分或行为概率大于等于预设阈值,和/或人手分类模型输出的行为评分或行为概率大于等于预设阈值,则确定待检测图像中存在抽烟行为。对于同一个人体中,以人脸分类模型、人手分类模型输出的最大概率值作为待检测图像的最终抽烟概率。并在判断出待检测图像存在抽烟行为后,按照预设报警条件进行报警。如果人脸分类模型输出的行为评分或行为概率小于预设阈值,且人手分类模型输出的行为评分或行为概率小于预设阈值,则确定待检测图像中不存在抽烟行为。并继续从监控视频流中抽取单帧或多帧图像作为待检测图像,继续检测待检测图像是否存在抽烟行为。
综上所述,本系统针对现有技术存在的问题,提出了一种基于深度卷积网络的复杂场景多尺度行为检测方案,适用于公共交通要所等复杂场景条件下的目标行为(例如抽烟行为)监督。本系统首先采用最新基于中心点的开源目标检测网络CenterNet对人群场景下进行人体检测和人体关键点检测;在获取人体框信息和关键点信息之后,通过人脸检测和人手区域逻辑判断获得人脸框和人手框。然后通过AutoML技术训练生成人脸分类模型和人手分类模型,并利用得到的人脸分类模型和人手分类模型输出人脸和双手的抽烟行为概率,获的最终的检测结果。本系统可以将图像识别的判断位置精确到人脸和人手,解决了目标尺度与人体尺度差别大的问题,同时分类模型能准确地判断出目标行为的特征信息,大幅提升目标行为的检测精度。现有的检测方案由于输入的是完整图像,分类模型感受野中类烟特征数量庞大,会造成语义信息混淆、检率高的问题。而本系统首先对目标行为发生位置预先进行了精确定位,并在分类模型训练中辅以大量普通人脸、人手及背景环境负例,可以让分类模型的误检率达到0.05%以下,从而给用户带来更好的体验。同时,本系统对于全景图内的人数、人脸分辨率程度和遮挡程度的影响具备较高的鲁棒性。另外,本系统基于深度卷积网络对复杂场景下的目标行为进行检测,不仅检测速度快且准确率高,而且还能够应用于公共交通场所等多人群、高遮挡的复杂场景。相较于传统的视觉检测方法在复杂场景吸烟行为中的应用,本系统大幅提升了检测精度,且针对多人、多场景、人脸分辨率低等严苛条件下依旧具备较高的检出率和鲁棒性。
本申请实施例还提供了一种计算机设备,该设备可以包括:一个或多个处理器;和其上存储有指令的一个或多个机器可读介质,当由所述一个或多个处理器执行时,使得所述设备执行图1所述的方法。在实际应用中,该设备可以作为终端设备,也可以作为服务器,终端设备的例子可以包括:智能手机、平板电脑、电子书阅读器、MP3(动态影像专家压缩标准语音层面3,Moving Picture Experts Group Audio Layer III)播放器、MP4(动态影像专家压缩标准语音层面4,Moving Picture Experts Group Audio Layer IV)播放器、膝上型便携计算机、车载电脑、台式计算机、机顶盒、智能电视机、可穿戴设备等等,本申请实施例对于具体的设备不加以限制。
本申请实施例还提供了一种非易失性可读存储介质,该存储介质中存储有一个或多个模块(programs),该一个或多个模块被应用在设备时,可以使得该设备执行本申请实施例的图1中数据处理方法所包含步骤的指令(instructions)。
图8为本申请一实施例提供的终端设备的硬件结构示意图。如图所示,该终端设备可以包括:输入设备1100、第一处理器1101、输出设备1102、第一存储器1103和至少一个通信总线1104。通信总线1104用于实现元件之间的通信连接。第一存储器1103可能包含高速RAM存储器,也可能还包括非易失性存储NVM,例如至少一个磁盘存储器,第一存储器1103中可以存储各种程序,用于完成各种处理功能以及实现本实施例的方法步骤。
可选的,上述第一处理器1101例如可以为中央处理器(Central ProcessingUnit,简称CPU)、应用专用集成电路(ASIC)、数字信号处理器(DSP)、数字信号处理设备(DSPD)、可编程逻辑器件(PLD)、现场可编程门阵列(FPGA)、控制器、微控制器、微处理器或其他电子元件实现,该处理器1101通过有线或无线连接耦合到上述输入设备1100和输出设备1102。
可选的,上述输入设备1100可以包括多种输入设备,例如可以包括面向用户的用户接口、面向设备的设备接口、软件的可编程接口、摄像头、传感器中至少一种。可选的,该面向设备的设备接口可以是用于设备与设备之间进行数据传输的有线接口、还可以是用于设备与设备之间进行数据传输的硬件插入接口(例如USB接口、串口等);可选的,该面向用户的用户接口例如可以是面向用户的控制按键、用于接收语音输入的语音输入设备以及用户接收用户触摸输入的触摸感知设备(例如具有触摸感应功能的触摸屏、触控板等);可选的,上述软件的可编程接口例如可以是供用户编辑或者修改程序的入口,例如芯片的输入引脚接口或者输入接口等;输出设备1102可以包括显示器、音响等输出设备。
在本实施例中,该终端设备的处理器包括用于执行各设备中语音识别装置各模块的功能,具体功能和技术效果参照上述实施例即可,此处不再赘述。
图9为本申请的另一个实施例提供的终端设备的硬件结构示意图。图9是对图8在实现过程中的一个具体的实施例。如图所示,本实施例的终端设备可以包括第二处理器1201以及第二存储器1202。
第二处理器1201执行第二存储器1202所存放的计算机程序代码,实现上述实施例中图1所述方法。
第二存储器1202被配置为存储各种类型的数据以支持在终端设备的操作。这些数据的示例包括用于在终端设备上操作的任何应用程序或方法的指令,例如消息,图片,视频等。第二存储器1202可能包含随机存取存储器(random access memory,简称RAM),也可能还包括非易失性存储器(non-volatile memory),例如至少一个磁盘存储器。
可选地,第二处理器1201设置在处理组件1200中。该终端设备还可以包括:通信组件1203,电源组件1204,多媒体组件1205,音频组件1206,输入/输出接口1207和/或传感器组件1208。终端设备具体所包含的组件等依据实际需求设定,本实施例对此不作限定。
处理组件1200通常控制终端设备的整体操作。处理组件1200可以包括一个或多个第二处理器1201来执行指令,以完成上述图1所示方法的全部或部分步骤。此外,处理组件1200可以包括一个或多个模块,便于处理组件1200和其他组件之间的交互。例如,处理组件1200可以包括多媒体模块,以方便多媒体组件1205和处理组件1200之间的交互。
电源组件1204为终端设备的各种组件提供电力。电源组件1204可以包括电源管理系统,一个或多个电源,及其他与为终端设备生成、管理和分配电力相关联的组件。
多媒体组件1205包括在终端设备和用户之间的提供一个输出接口的显示屏。在一些实施例中,显示屏可以包括液晶显示器(LCD)和触摸面板(TP)。如果显示屏包括触摸面板,显示屏可以被实现为触摸屏,以接收来自用户的输入信号。触摸面板包括一个或多个触摸传感器以感测触摸、滑动和触摸面板上的手势。所述触摸传感器可以不仅感测触摸或滑动动作的边界,而且还检测与所述触摸或滑动操作相关的持续时间和压力。
音频组件1206被配置为输出和/或输入语音信号。例如,音频组件1206包括一个麦克风(MIC),当终端设备处于操作模式,如语音识别模式时,麦克风被配置为接收外部语音信号。所接收的语音信号可以被进一步存储在第二存储器1202或经由通信组件1203发送。在一些实施例中,音频组件1206还包括一个扬声器,用于输出语音信号。
输入/输出接口1207为处理组件1200和外围接口模块之间提供接口,上述外围接口模块可以是点击轮,按钮等。这些按钮可包括但不限于:音量按钮、启动按钮和锁定按钮。
传感器组件1208包括一个或多个传感器,用于为终端设备提供各个方面的状态评估。例如,传感器组件1208可以检测到终端设备的打开/关闭状态,组件的相对定位,用户与终端设备接触的存在或不存在。传感器组件1208可以包括接近传感器,被配置用来在没有任何的物理接触时检测附近物体的存在,包括检测用户与终端设备间的距离。在一些实施例中,该传感器组件1208还可以包括摄像头等。
通信组件1203被配置为便于终端设备和其他设备之间有线或无线方式的通信。终端设备可以接入基于通信标准的无线网络,如WiFi,2G或3G,或它们的组合。在一个实施例中,该终端设备中可以包括SIM卡插槽,该SIM卡插槽用于插入SIM卡,使得终端设备可以登录GPRS网络,通过互联网与服务器建立通信。
由上可知,在图9实施例中所涉及的通信组件1203、音频组件1206以及输入/输出接口1207、传感器组件1208均可以作为图8实施例中的输入设备的实现方式。
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
- 一种目标行为检测方法、系统、计算机设备及机器可读介质
- 一种目标检测方法、系统、计算机设备及机器可读介质