基于h-core剪枝的网络拓扑重叠群组发现方法及装置
文献发布时间:2023-06-19 11:49:09
技术领域
本发明属于网络拓扑图中的群组发现技术领域,特别涉及一种基于h-core剪枝的网络拓扑重叠群组发现方法及装置。
背景技术
寻找网络中的群组有助于发现各种不同领域中大型网络的基本特性。因此,人们对群组发现问题进行了大量的研究。网络拓扑图中的群组发现可以检测网络拓扑中具有相似特征的节点群,有助于进一步了解潜在的网络拓扑特征和节点属性功能。在网络安全方面,蠕虫病毒的爆发、分式拒绝攻击等网络安全事件的出现都会在网络群组层面有所体现。在拓扑网络分析方面,可以根据IP网络中的群组位置信息映射具体IP节点的地理位置,为IP实体定位提供技术支撑;网络负载均衡也可以通过分析网络节点的性能属性对网络终端集群。因此,网络拓扑群组发现技术在很多方面都有着重要意义。
通过网络群组发现深入理解互联网的拓扑特性,有助于进一步展开与互联网有关的路由、安全等方面的研究。在网络安全方面,Kuai等人使用二部图来描述源主机和目的主机之间的通信关系,然后分别对源主机集合和目的主机集合使用单模投影,并构建单模投影图的相似度矩阵,最后对相似度矩阵进行谱聚类,以此得到行为相似的网络群组;李乔等人提出一种基于信任的网络群体行为计算模型,通过分析网络中结点间的群组关系,发现网络中的潜在恶意群体,识别木马行为和蠕虫病毒,为网络安全预警提供参考;和亮等人提出一种基于并行群组发现的网络蠕虫抑制方法,该方法利用不同策略筛选出群组中的关键结点,并对其进行优先免疫,之后再借助这些关键结点来对周围邻居结点进行免疫,进而保证能够有效抑制在线社交网络中蠕虫的快速传播。在IP实体定位方面,Tian等人提出了一种基于网络拓扑结构的启发式聚类IP定位算法,结合网络拓扑测量和数据库查询,对网络实体进行地理位置映射,根据同一集群内部的IP节点地理位置往往相同的特点,通过目标IP所属群组的地理位置确定目标IP的地理位置;Li等人提出一种基于网络节点聚类的目标IP定位方法,利用Louvain社团发现算法对网络拓扑中的节点进行群组发现,通过模块度等标准将网络拓扑划分为不同的群组,并对IP节点进行位置归属分析;Yang等人引入生物学网络中的“模体”概念,从网络中挖掘出来的“模体”结构作为扩展的初始种子,结合群组密度的思想进行群组扩展,将网络中与各个群组相连的简单路径上的节点选择性地合并到网络群组,在不影响结果准确性的前提下建立更多节点与地理位置的映射关系。在网络负载均衡方面,Pi等人提出了一种数据驱动的客户机聚合算法,根据客户机的路径性能把客户机划分到各个群组,数据驱动特性使AP-atoms动态地适应网络变化,有效提高全局负载均衡效率。综上所述,网络群组发现方法在网络安全、IP实体定位和负载均衡方面有大量应用研究并取得了一定的成果,但是,在互联网领域,由于网络拓扑图规模较大,且终端节点较多,现有的重叠群组发现方法大多复杂度较高,使得可处理的数据规模有限,不能直接应用于网络拓扑图。
发明内容
针对现有技术中存在的问题,本发明提出了一种基于h-core剪枝的网络拓扑重叠群组发现(Network Topology Overlapped Group Detection Based on h-core Pruning,简称OGD)方法及装置,将h-core剪枝运用到网络拓扑图的重叠群组发现中,解决full-enum可处理数据规模有限的问题。
为了实现上述目的,本发明采用以下的技术方案:
本发明提供了一种基于h-core剪枝的网络拓扑重叠群组发现方法,包含以下步骤:
遍历点的连接关系,构建网络拓扑图;
通过基于h-core的最小群组剪枝迭代去除目标网络上的噪声节点;
根据去除噪声节点的目标网络进行基于k-plex结构的网络群组发现。
进一步地,所述遍历点的连接关系,构建网络拓扑图,包括:
在公开数据集上充分遍历拓扑网络中所有节点的度值和节点间的连接关系,得到完整的拓扑信息,删除掉网络拓扑图中所有的自连边,构建网络拓扑图G,G被定义为二元组(V,E),V={v
进一步地,所述通过基于h-core的最小群组剪枝迭代去除目标网络上的噪声节点,包括:
根据最大k-plex群组的规模设置参数,不断过滤掉拓扑网络上度过小的噪声节点,保留目标网络上局部连接密集的目标子图;
目标网络降噪是一个迭代循环的过程,不断判断目标子图中节点是否满足大于阈值的最大k-plex群组特征,若满足则进入网络群组发现阶段,否则返回循环步骤继续目标网络降噪;
拓扑图G经过最小群组剪枝后记成D。
进一步地,所述基于h-core的最小群组剪枝具体包括:
根据k-plex的定义,规模为d的k-plexes群组中,所有节点的度都不低于d-k,其中d表示k-plex的规模大小,k为k-plex中定义的常数k;
假设要求最大k-plexes的大小至少是d,这意味着需要删除目标网络上任何度小于d-k的节点,最小群组剪枝通过最小k-plex迭代删除掉拓扑图G中度小于d-k不能组成有效k-plexes群组的节点,定义最小群组剪枝准则如下:
拓扑图G中所有大于或等于d的k-plex都由度大于或等于d-k的节点组成,
G→D={D
其中,D
进一步地,所述根据去除噪声节点的目标网络进行基于k-plex结构的网络群组发现,具体包括:
枚举剪枝后子图D上所有的最大连通k-plex群组,首先初始化一个B树,存储所有生成的结果;然后根据连接k-plex的图属性,生成单个子图存到H,与B树的数据比较是否重复,不重复即存到B树;最后输出目标子图上所有的k-plex群组,实现所有大于指定阈值的k-plex重叠群组检测。
本发明还提供了一种基于h-core剪枝的网络拓扑重叠群组发现装置,该装置包括:
网络拓扑图构建模块,用于遍历点的连接关系,构建网络拓扑图;
目标网络降噪模块,用于通过基于h-core的最小群组剪枝迭代去除目标网络上的噪声节点;
目标网络上k-plex结构枚举模块,用于根据去除噪声节点的目标网络进行基于k-plex结构的网络群组发现。
与现有技术相比,本发明具有以下优点:
本发明的基于h-core剪枝的网络拓扑重叠群组发现方法,该方法将网络分解成更小的强连通分量,降低噪声节点对重叠群组发现的干扰,更高效地发现目标网络上的最大k-plex群组,与full-enum方法对比,本发明的方法将发现最大k-plex群组可处理的网络规模提高了两个数量级,可以更高效地检测网络拓扑中的重叠群组。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例的基于h-core剪枝的网络拓扑重叠群组发现方法的原理示意图;
图2是本发明实施例的3-core子图剪枝过程图;
图3是本发明实施例的数据集AS19990829不同k值对群组发现的影响,其中3.1是不同k值对群组数量的影响,3.2是不同k值对群组发现速度的影响;
图4是本发明实施例的基于h-core剪枝的网络拓扑重叠群组发现方法在AS733中四个不同规模数据集上的群组发现结果与full-enum方法结果还原度比较情况;
图5是本发明实施例的基于h-core剪枝的网络拓扑重叠群组发现方法和full-enum方法在不同规模输入图上枚举所有2-plexes所需的时间比较情况。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
首先给出必要的符号定义及简要描述本发明要解决的技术问题。
本发明中把网络拓扑抽象成复杂网络图,拓扑网络中的对象用节点v表示,两个相邻对象的连接关系用边来表示。网络的拓扑结构用图G表示,图G被定义为二元组(V,E),V={v
表1
给定网络拓扑图G(V,E),重叠群组发现是根据节点v
(1)允许
(2)群组P
网络拓扑中有大量的噪声节点,在进行群组发现时,这些节点会影响计算时间降低运行效率,而现有技术中的重叠群组发现方法可处理的数据规模有限。为了实现网络拓扑图上的重叠群组发现,本发明引入目标网络降噪,把网络聚焦到网络中连接紧密的区域,降低噪声节点对重叠群组发现的影响。
下面对full-enum方法模型进行分析。
一、k-plex群组模型分析
基于h-core剪枝的网络拓扑重叠群组发现方法主要使用连通的k-plex图结构。k-plex由团的概念衍生而来,如果图G中的所有顶点都是相邻的,即图G的所有元素都是相互“直接联系”的,则图G被称为团。团内的成员之间非常熟悉和接近,但是,团的定义过于严格,使得团无法在实际应用中使用。在许多实际情况中,更符合实际应用的k-plexes概念被提出:将每个节点都与图中其它节点有连接的要求放宽到一个k-plex的成员在群组内最多可以有k-1个非邻居。例如,k=1时,k-plexes是团,k=2时群组内每个节点缺失一条边。
k-plex具有遗传性(删除顶点后的子图依然符合k-plex结构),组内节点可达性高和连通性强(结构不容易因为部分成员移除而被破坏)。通过改变k可以平衡模型对错误遗漏的边的敏感度和在错误包含的边下检测到的网络群组的保真度。k-plex群组结构信息有利于我们进一步对网络拓扑鲁棒性、连通性进行分析研究。低k值的k-plex类似于现实网络中的有凝聚力的子群,因此,本发明基于k-plex进行网络拓扑重叠群组发现。
二、full-enum方法分析
针对网络中的具有遗传属性的最大子图枚举问题,Berlowitz等人于2015年在SIGKDD发表论文提出了full-enum方法,full-enum方法优化了最大连通k-plex的枚举问题,在之前的研究中用于枚举随机网络中的最大连通k-plex。
Full-enum根据定义的连通k-plex图属性进行剪枝主要包含三种类型:
1.节点v至少有2k-1个邻居,此时与不连通的k-plex结果相同;
2.H中至多有3k个节点,此时遍历每个节点的子集;
3.节点v有小于2k-1个邻居,而H有大于3k个节点,这种情况下v的结果在已经生成的k-plex中。
Enum方法主要分为如下步骤:
Step1先初始化一个B树,存储所有生成的结果,避免有重复结果;
Step2根据图属性(这里指连通的k-plex的性质),不断删除图G中的节点,生成单个子图H记为群组P
Step3判断子图H与B树上的子图比较是否重复,如果不重复把子图H存到B树;
Step4迭代执行上述步骤,直到枚举出图G上全部k-plex;
Full-enum通过连通k-plex图属性对拓扑图进行剪枝,优化了k-plex群组发现方法,对比之前的并行枚举方法,full-enum的方法效率有了明显提高。但面向具有海量信息的网络拓扑图时full-enum有以下不足:(1)full-enum可处理的数据规模有限,最多只能处理上百个节点的真实数据集,无法应用于规模庞大的网络拓扑图。full-enum随着网络规模增大,时间呈指数型增长。(2)枚举结果中存在大量没有实际意义的极小群组。极小群组的数量也随着网络规模增加呈指数型增长,降低了运行效率。
为了解决full-enum方法在网络拓扑图上的应用局限性,本实例通过分析群组结构特性与网络拓扑的关系,提出一种基于h-core剪枝的网络拓扑重叠群组发现方法,通过枚举所有大于阈值的k-plex检测目标拓扑网络中的网络群组信息。群组结构在复杂网络中普遍存在,网络拓扑图是典型的复杂网络图。网络拓扑中任意两个节点之间都可以通过有限的几跳路径相互连接,符合复杂网络的小世界特性。实际的互联网拓扑也呈现出很强的局部聚团现象,节点更倾向于和物理临近的或属于同一个行政管理范围内的节点连接。
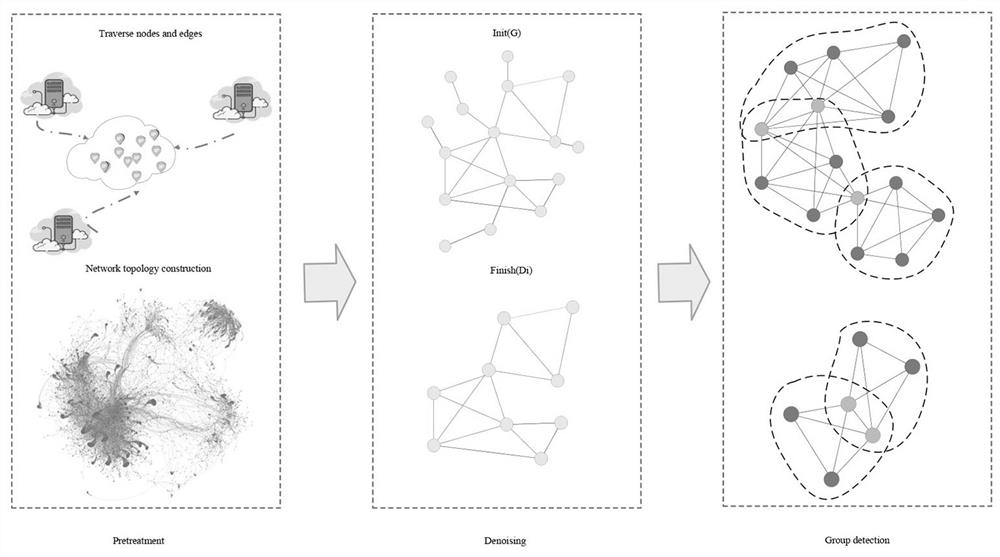
如图1所示,本实施例提出一种基于h-core剪枝的网络拓扑重叠群组发现方法,具体包含以下步骤:
步骤S101,遍历点的连接关系,构建网络拓扑图;
在公开数据集上充分遍历拓扑网络中所有节点的度值和节点间的连接关系,得到较为完整的拓扑信息,删除掉网络拓扑图中所有的自连边,构建网络拓扑图G。
步骤S102,通过基于h-core的最小群组剪枝迭代去除目标网络上的噪声节点,从而保证群组发现更高效。
在拓扑图G上,利用h-core思想迭代删除掉不符合k-plex群组特征的节点。目标网络降噪是根据最大k-plex群组的规模设置参数,不断过滤掉拓扑网络上度过小的噪声节点,保留目标网络上局部连接密集的目标子图,降低噪声节点对群组发现效率的影响。目标网络降噪是一个迭代循环的过程,不断判断目标子图中节点是否满足大于阈值的最大k-plex群组特征,若满足则进入网络群组发现阶段,否则返回循环步骤继续目标网络降噪。拓扑图G经过最小群组剪枝后记成D。
下面详细介绍下基于h-core的最小群组剪枝。
h-core分解(常用命名是k-core,为了和k-plex的k区别,本发明我们定义为h-core)是为了寻找网络中最大的子图,其中每个节点在子图中至少有h个邻居。由于思想简单、适用性广,该方法被广泛应用于生物学、网络科学、计算机科学、生态学、经济学、社会科学等多个学科中,寻找网络中最密集的部分。下面给出h-core概念的定义。
定义h-core概念如下:G的h-core是G的极大连通子图,其中所有节点的度都至少为h。h-core通过迭代删除所有度小于h的节点形成的各个子图是G的连通分量之一。节点u如果属于h核,则具有h-core,但不属于任何(h+1)-core。
h-core分解最常用在方法的剪枝过程,即递归地删除度小于h的节点。基于h-core分解的最小群组剪枝思想来源于自治系统(Autonomous System,简称AS)网络的h-core分解,迭代去除AS网络边缘的非核心节点。根据k-plex的定义,规模为d的k-plexes群组中,所有节点的度都不低于d-k,其中d表示k-plex的规模大小,k为k-plex中定义的常数k。假设要求最大k-plexes的大小至少是d,这意味着需要删除目标网络上任何度小于d-k的节点,最小群组剪枝通过最小k-plex(规模为d)迭代删除掉拓扑图G中度小于d-k不能组成有效k-plexes群组的节点,这相当于在G上寻找(d-k)-core。
定义最小群组剪枝准则如下:拓扑图G中所有大于或等于d的k-plex都由度大于或等于d-k的节点组成。
G→D={D
其中,G通过多次剪枝后可能已经不是连通图,D
图2给出了一个简单的3-core子图剪枝的过程。基于h-core剪枝的网络拓扑重叠群组发现方法中,最小群组剪枝是至关重要的一步,尤其在较为稀疏的拓扑网络中。通过迭代删除网络中的噪声节点,能够使网络拓扑的群组结构特性更加明显。一方面基于h-core的最小群组剪枝缩小了目标网络规模,剪枝后的网络结构内聚性更强;另一方面,最小群组剪枝保留了网络中紧密连接的部分,有效降低了极小的群组数量,提高了重叠网络群组发现方法的处理效率。
步骤S103,根据去除噪声节点的目标网络进行基于k-plex结构的网络群组发现。
重叠群组发现利用图属性枚举剪枝后子图D上所有的最大连通k-plex群组。函数prune去除掉度小于d-k的噪声节点,把网络聚焦到网络中连接紧密的区域。函数enun用来枚举子图D上所有连通的最大k-plex群组。Enum函数首先始化一个B树,存储所有生成的结果,避免有重复结果,(A)表示连通k-plex的图属性,ExtendMax根据图属性(A)和图G中节点的连接关系为每个节点计算出节点所在的所有最大k-plex群组,然后生成单个子图存到H,与B树的数据比较是否重复,不重复即存到B树。最后输出目标子图上所有的k-plex,实现所有大于指定阈值的k-plex重叠群组检测。
下面对本发明的方法进行实验评估,将在不同的数据集上比较本发明和full-enum方法。
A、实验设置
数据集。我们考虑了具有不同规模的现实世界的AS网络。这些图集来自于SNAP。
(1)AS733来自俄勒冈大学路线图项目。该数据集包含从1997年11月8日到2000年1月2日的733个每日实例自治系统(AS)图。
(2)Oregon-1是从俄勒冈州的路由视图,镜像和路由注册表中推断出的AS对等信息。我们选取的是2001年4月7日的自治系统(AS)图。
表2是从上面两个项目中选择的实验所用数据集,n表示数据集中节点的数量,m表示数据集中边的数量。
表2
基线方法。full-enum方法优化了最大连通k-plex的枚举问题,在之前的研究中用于枚举随机网络中的最大连通k-plex。本文将在不同规模的数据集上,与full-enum方法进行比较,对OGD方法进行实验评估。
评价标准。还原度。该评价指标反映了对full-enum方法的复现程度。实验通过上述重叠群组发现方法得到的大于阈值的群组与full-enum结果中大于阈值的群组作比较,若比较结果一致则认为群组复现成功。则还原度为:
其中,R表示还原度,T表示复现成功的群组数量,F表示复现失败的群组数量。
实验环境。我们的实验机器采用Intel
B、k值对群组发现的影响
通过不同规模(节点数,边数)的真实数据集,来研究基于h-core剪枝的网络拓扑重叠群组发现方法的可伸缩性,从不同k值对群组数量的影响和对方法运行速度的影响两个方面展示k值对网络群组发现的影响。
如图3所示,我们在数据集AS19990829进行多次实验,分别展示了在k=2,3,4时k值变化对群组的数量以及群组发现速度的影响。实验表明,群组的总数量随着k的增加呈指数上升。由于群组数量的增加,群组发现方法的运行时间也随着k的增大而增长。
C、群组还原度对比
通过比较结果中各规模段群组的数量来展示基于h-core剪枝的网络拓扑重叠群组发现方法枚举出来的k-plex群组对full-enum方法结果的还原程度。
图4分别展示了我们的方法在AS733中四个不同规模数据集上的群组发现结果与full-enum方法结果还原度比较情况。由图4可以看出我们的方法在大于阈值的情况下群组的数量和full-enum持平,可以在有效时间内找到大于指定阈值(大于4的群组)的几乎所有2-plex。我们提出的OGD方法通过目标网络降噪迭代删除边缘节点降低目标网络的规模,有针对性地分析目标网络中密集连接的网络部分。在对大于指定阈值的k-plex枚举时,我们的方法可以有效还原full-enum方法的结果,并且有效降低了极小群组的数量。
D、群组发现效率
通过对比方法在不同规模数据集上的运行时间分析数据规模对方法运行效率的影响。
在图5上我们展示了本方法和full-enum方法在不同规模输入图上枚举所有2-plexes所需的时间。full-enum方法最多只能处理几百个节点的数据集,在上千个节点的数据集中full-enum运行时间都超过了6个小时。本发明提出的OGD方法迭代删除度值过小的噪声节点,保留网络中紧密连接的网络部分,有效降低了噪声节点对群组发现方法的影响,从而提高运行效率。实验表明,本发明方法是有效的,在对大于指定阈值的k-plex枚举时,基于h-core剪枝的网络拓扑重叠群组发现方法将计算大k-plex的网络规模从几百个节点增加到上万个节点。
本发明提出的基于h-core剪枝的网络拓扑重叠群组发现方法,这是一种在现实拓扑网络中寻找具有实际应用意义的群组的有效方法。基于h-core分解的最小群组剪枝过滤掉了影响效率的大量噪声节点,把网络聚焦到网络中连接紧密的区域,有效减少了极小群组的数量,提高了群组发现方法的效率。对比full-enum方法,我们的方法能够将枚举最大k-plex的网络规模提高两个数量级。同时面向目标网络时本文的方法更具有针对性,引导了full-enum朝着特定的网络部分枚举k-plex。
与基于h-core剪枝的网络拓扑重叠群组发现方法相应地,本实施例还提出基于h-core剪枝的网络拓扑重叠群组发现装置,该装置包括:
网络拓扑图构建模块,用于遍历点的连接关系,构建网络拓扑图;
目标网络降噪模块,用于通过基于h-core的最小群组剪枝迭代去除目标网络上的噪声节点;
目标网络上k-plex结构枚举模块,用于根据去除噪声节点的目标网络进行基于k-plex结构的网络群组发现。
需要说明的是,在本发明中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
最后需要说明的是:以上所述仅为本发明的较佳实施例,仅用于说明本发明的技术方案,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所做的任何修改、等同替换、改进等,均包含在本发明的保护范围内。
- 基于h-core剪枝的网络拓扑重叠群组发现方法及装置
- 适用TCMF网络的基于多三角形群组相似性凝聚的重叠社区发现方法