听力装置中的声源分离及相关方法
文献发布时间:2023-06-19 12:07:15
技术领域
本发明公开了一种听力系统的听力装置和附件装置以及包括操作听力装置的方法的相关方法。
背景技术
在听力装置处理中,听力装置用户处于具有多个语音和/或其他声源的多源环境中的情况,即所谓的鸡尾酒会效应,不断对听力装置开发人员提出挑战。
鸡尾酒会效应的问题在于,从与目标语音信号相同频率范围和相近相似接近度的多个其他语音中分离出单个语音。近年来,单边(经典)波束成形器和双边波束成形器已成为助听器的标准解决方案。波束形成器在近场和/或混响情况下的能力并不总是足以提供令人满意的听觉体验。通常,波束形成器的性能是通过使波束变窄从而更强地抑制波束外部的源而得到提高。
然而,在现实生活中,声源和/或助听器用户的头部处于移动过程中,因此会产生所需的声源可能移入和移出波束的情况,这会导致相当混乱的声学情况。
发明内容
因此,需要一种具有改进的声源分离的听力装置和方法。
一种操作包括听力装置和附件装置的听力系统的方法,该方法包括在附件装置中获取表示来自一个或多个音频源的音频的音频输入信号;用附件装置的摄像头获取图像数据;基于图像数据识别包括第一音频源的一个或多个音频源;确定包括第一模型系数的第一模型,其中第一模型基于第一音频源的图像数据和音频输入信号;以及向听力装置传输听力装置信号,其中听力装置信号基于第一模型
此外,公开了一种用于听力系统的附件装置,听力系统包括该附件装置和听力装置,附件装置包括处理单元、存储器、摄像头和接口。处理单元被配置为从一个或多个音频源获取表示音频的音频输入信号;使用摄像头获取图像数据;基于图像数据识别包括第一音频源的一个或多个音频源;确定包括第一模型系数的第一模型,其中第一模型基于第一音频源的图像数据和音频输入信号;以及向听力装置传输听力装置信号,其中听力装置信号基于第一模型
本公开另外提供一种听力装置,其包括用于将来自附件装置的听力装置信号转换为天线输出信号的天线;耦合到天线的无线电收发器,用于将天线输出信号转换为收发器输入信号;一组麦克风,包括用于提供第一输入信号的第一麦克风;用于处理第一输入信号并基于第一输入信号提供电输出信号的处理器;以及用于将电输出信号转换为音频输出信号的接收器。听力装置信号包括深度神经网络的第一模型系数,并且其中处理器被配置为基于第一模型系数来处理第一输入信号以提供电输出信号
此外,听力系统包括附件装置和听力装置。附件装置可以是如本文所述的附件装置并且听力装置可以是如本文所述的听力装置。
本发明允许改进听力装置中声源的分离,进而为用户提供改进的听觉体验。
此外,本发明提供了听力装置中的移动和/或位置独立扬声器分离和/或周围噪声抑制。
本发明还允许用户以简单有效的方式选择要收听的声源。
一个重要的优点在于,附件装置(移动电话、平板电脑等)用于图像-辅助(image-assisted)确定仅基于音频的音频分离的精确模型。基于第一模型的听力装置信号(例如,包括第一模型参数)被传输至听力装置,从而允许听力装置在处理表示来自一个或多个音频源的音频的第一输入信号时使用第一模型。这进而通过利用附件装置的过度计算、电池和通信能力(与听力装置相比)以及图像记录和显示能力,来获得在听力装置中用于处理传入音频的第一模型,来为嘈杂环境中的用户提供改进的听觉体验,从而允许以改进的方式将所需的音频源与其他源分离。
附图说明
通过以下参考附图对示例性实施例的详细描述,以上和其他特征和优点对于本领域技术人员将变得显而易见,其中:
图1示意性地示出了示例性听力系统;
图2是根据本发明的示例性方法的流程图;
图3是根据本发明的示例性方法的流程图;
图4是示例性附件装置的框图;
图5是示例性听力装置的框图;以及
图6是根据本发明的示例性方法的流程图。
附图标记列表:
2 听力系统
4 听力装置
6 附件装置
8 听力装置系统
10 服务器装置
12 听力应用
20 第一通信链路
22 第二通信链路
24 天线
26 无线电收发器
27 听力装置信号
28 第一麦克风
30 第二麦克风
32 处理器
34 接收器
36 处理单元
38 存储器单元
40 接口
42 无线收发器
44 触敏显示装置
46 摄像头
48 麦克风
100、100A、100B 操作听力系统的方法
102 在附件装置中获取表示来自一个或多个音频源的音频的音频输入信号
104 通过附件装置的摄像头获取图像数据
106 基于图像数据识别包括第一音频源和/或第二音频源的一个或多个音频源
106A 基于图像数据确定第一音频源的第一位置和/或第二音频源的第二位置
106B 显示指示第一音频源的第一用户接口元素和/或指示第二音频源的第二用户接口元素
106C 检测选择第一用户接口元素和/或第二用户接口元素的用户输入
106D 确定图像数据的第一图像数据,第一图像数据与第一音频源相关联和/或确定图像数据的第二图像数据,第二图像数据与第二音频源相关联
108 基于图像数据确定第一模型和/或第二模型
108A 基于图像数据确定第一音频源的唇部运动和/或第二音频源的唇部运动
108B 训练深度神经网络
108C 基于与第一音频源相关联的第一图像数据确定第一模型和/或基于与第二音频源相关联的第二图像数据确定第二模型
108D 基于图像数据和音频输入信号确定第一语音输入信号
108E 基于第一语音输入信号训练/确定第一模型
110 将听力装置信号传输到听力装置
110A 将第一模型系数和/或第二模型系数传输到听力装置
110B 将第一输出信号传输到听力装置
112 从一个或多个音频源获得表示音频的第一输入信号
114 基于第一模型系数和/或第二模型系数处理第一输入信号以提供电输出信号
114A 对第一输入信号应用盲源分离
114B 对第一输入信号应用深度神经网络
116 将电输出信号转换为音频输出信号
118 在附件装置中基于第一模型和/或基于第二模型处理音频输入信号以提供第一输出信号
120 处理第一输出信号以提供电输出信号
具体实施方式
下文将在相关时参考附图描述各种示例性实施例和细节。应当注意,附图可以按比例绘制或不按比例绘制,并且具有类似结构或功能的元件在整个附图中由相同的附图标记表示。还应当注意,附图仅旨在促进实施例的描述。它们无意作为所要求保护的发明的详尽描述或对所要求保护的发明的范围的限制。此外,示出的实施例不必具有所示的所有方面或优点。结合特定实施例描述的方面或优点不必限于该实施例,并且即使未如此示出或未如此明确地描述,也可以在任何其他实施例中实践。
本文公开了一种听力装置。听力装置可以是可听的或助听器,其中处理器被配置为补偿用户的听力损失。听力装置可以是耳后(BTE)式、耳内(ITE)式、耳道内(ITC)式、耳道内接收器(RIC)式或耳内接收器(RITE)式。助听器可以是双耳助听器。听力装置可包括第一耳机和第二耳机,其中第一耳机和/或第二耳机是如本文所公开的耳机。
本文公开了一种操作听力系统的方法。听力系统包括听力装置和附件装置。
这里使用的术语“附件装置”是指能够与听力装置通信的装置。附件装置可以指在听力装置的用户的控制下的计算装置。附件装置可以包括或可以是手持设备、平板电脑、个人计算机、移动电话,例如智能电话。附件装置可以配置为通过接口与听力装置通信。附件装置可以配置为例如通过向听力装置传输信息来控制听力装置的操作。附件装置的接口可以包括触敏显示装置。
本发明提供一种附件装置,该附件装置形成听力系统的一部分,该听力系统包括该附件装置和听力装置。附件装置包括:存储器;耦合至存储器的处理单元;以及耦合至处理单元的接口的接口。此外,附件装置包括用于获取图像数据的摄像头。接口配置为与听力系统的听力装置和/或其他装置进行通信。
该方法包括在附件装置中获取表示来自一个或多个音频源的音频的音频输入信号。获取表示来自一个或多个音频源的音频的音频输入信号的步骤可以包括使用附件装置的一个或多个麦克风检测音频。
在一个或多个示例性方法/附件装置中,音频输入信号可以基于来自外部源的无线输入信号,例如配偶麦克风设备、无线TV音频发射器和/或与无线发射器相关联的分布式麦克风阵列。
该方法包括使用附件装置的摄像头获取图像数据。图像数据可以包括运动图像数据,也称为视频图像数据。
该方法包括基于图像数据识别包括第一音频源的一个或多个音频源(例如通过附件装置)。基于图像数据识别包括第一音频源的一个或多个音频源可以包括将面部识别算法应用于图像数据。因此,该方法包括原位确定第一模型,然后将第一模型原位应用于听力装置或附件装置中。
第一模型是第一音频源的模型,例如第一音频源的语音模型。第一模型可以是由DNN系数定义(或至少部分定义)的深度神经网络(DNN)。因此,第一模型系数可以是DNN的DNN系数。第一模型或第一模型系数可以应用于(语音)分离过程中,例如,在处理第一输入信号的听力装置中或在附件装置中,以从第一输入信号中分离出例如第一音源的语音。换言之,在听力装置中处理第一输入信号可以包括将DNN作为第一模型(并因此基于第一模型系数)应用于第一输入信号以提供电输出信号。第一模型/第一模型系数可以表示或指示作为基于第一模型处理第一输入信号的一部分的应用于在听力装置中执行的盲源分离算法中参数。因此,第一模型可以是盲源分离模型,也表示为BSS模型,例如纯音频BSS模型。纯音频BSS模型仅接收表示音频的输入作为输入。第一模型可以是语音分离模型,例如,允许从表示音频的输入信号中分离语音。
确定包括第一模型系数的第一模型的步骤可以包括基于第一音频源的图像数据和音频输入信号确定第一语音信号。关于图像-辅助语音/音频源分离的示例可以在Ephrat、Ariel等人的“Looking to Listen atthe Cocktail Party:A Speaker-IndependentAudio-Visual Model for SpeechSeparation,arXiv:1804.03619v1[cs.SD],2018年4月10日”中找到。因此,可以在附件装置中训练和/或应用第二DNN/第二模型以基于第一音频源的图像数据和音频输入信号来提供第一语音信号。
确定包括第一模型系数的第一模型的步骤可以包括基于第一语音输入信号确定第一模型。换言之,图像-辅助音频源分离可用于提供高质量的第一语音输入信号(具有低噪声或无噪声的纯净语音),并且其中第一语音输入信号(例如表示来自第一音频源的纯净语音)然后用于确定/训练第一模型,从而从第一音频源获得第一音频的精确第一模型。本发明的优点在于,至少与听力装置的处理能力相比,需要高处理能力的第一模型的确定至少部分地在附件装置中现场或原位执行,以及可以在听力装置中执行与第一模型的确定/训练相比在计算上要求更低的第一模型的应用,进而提供具有低延迟(例如,基本上实时的)的电输出信号/音频输出信号。这对于用户体验很重要,因为不同步的唇部运动和音频(例如,与相应的唇部运动相比,音频延迟太多)使听力装置的用户感到烦恼和混乱,甚至可能不利于与听力装置用户交谈的人的理解。
第一语音输入信号可用于确定第一模型,例如基于第一语音输入信号或利用第一语音输入信号训练初始第一模型以获得第一模型/第一模型的第一模型系数。换言之,在附件装置中执行图像-辅助语音分离以依次训练第一模型,该第一模型随后被传输至听力装置并用于第一输入信号的纯音频盲源分离。因此,附件装置有利地基本上实时地或以几秒或几分钟的低延迟提供或确定第一音频源的精确第一模型,然后听力装置将其用于听力装置中的基于纯音频的音频源分离。
该方法包括向听力装置传输(例如,无线传输)听力装置信号,其中听力装置信号基于第一模型。向听力装置传输听力装置信号的步骤可以包括向听力装置发送第一模型系数。换言之,听力装置信号可以包括和/或指示第一模型的第一模型系数。将包括在附件装置中确定的第一模型/第一模型系数的听力装置信号传输到听力装置可以允许听力装置通过应用第一模型/第一模型系数来提供具有改进的源分离和低延迟的音频输出信号,例如,在源分离处理算法中作为处理第一输入信号的一部分。第一模型系数可以指示或对应于纯音频盲源分离的BSS/DNN系数。
因此,该方法可以包括基于第一模型确定听力装置信号。
在一种或多种示例性方法中,该方法包括:在听力装置中获得在听力装置中表示来自一个或多个音频源的音频的第一输入信号;在听力装置中基于第一模型系数处理第一输入信号以提供电输出信号;以及在听力装置中将电输出信号转换为音频输出信号。
在听力装置中获得表示来自一个或多个音频源的音频的第一输入信号的步骤可以包括使用听力装置的一个或多个麦克风检测音频。在听力装置中获得表示来自一个或多个音频源的音频的第一输入信号的步骤可以包括无线地接收第一输入信号。
在一种或多种示例性方法中,基于第一模型系数处理第一输入信号的步骤包括对第一输入信号应用盲源分离。在一个或多个示例性方法中,基于第一模型系数处理第一输入信号的步骤包括将深度神经网络应用于第一输入信号,其中深度神经网络基于第一模型系数。
在一种或多种示例性方法中,识别一个或多个音频源的步骤包括基于图像数据确定第一音频源的第一位置、显示(例如,在附件装置的触敏显示装置上)指示第一音频源的第一用户接口元素、以及检测选择第一用户接口元素的用户输入。该方法可以包括,根据检测选择第一用户接口元素的用户输入,确定图像数据的第一图像数据,第一图像数据与第一音频源相关联。
确定包括第一模型系数的第一模型,其中第一模型基于图像数据可选地包括确定包括第一模型系数的第一模型,其中第一模型基于第一图像数据。换言之,确定包括第一模型系数的第一模型的步骤可选地包括基于与第一音频源相关联的第一图像数据确定第一模型。
显示(例如,在附件装置的触敏显示装置上)指示第一音频源的第一用户接口元素的步骤可以包括将第一用户接口元素覆盖在图像数据的至少一部分上,例如,图像数据的图像。第一用户接口元素可以是第一音频源的帧元素和/或图像。
在一种或多种示例性方法中,确定第一模型的步骤包括基于诸如第一图像数据之类的图像数据确定第一音频源的唇部运动,并且其中第一模型是基于第一音频源的唇部运动的。
在一种或多种示例性方法和/或附件装置中,第一模型是具有N层的深度神经网络DNN,其中N大于3。DNN可以具有多个隐藏层,也表示为N_Hidden。DNN的隐藏层数可以是2、3或更多。
在一种或多种示例性方法中,确定包括第一模型系数的第一模型的步骤包括基于图像数据,例如第一图像数据,训练深度神经网络,以提供第一模型系数。
在一种或多种示例性方法中,该方法包括在附件装置中基于第一模型处理第一音频输入信号以提供第一输出信号。传输听力装置信号的步骤可选地包括将第一输出信号传输到听力装置。因此,听力装置信号可以包括或指示第一输出信号。
在一种或多种示例性方法中,例如用附件装置识别一个或多个音频源包括基于图像数据识别包括第二音频源。基于图像数据识别第二音频源的步骤可以包括对图像数据应用面部识别算法。
在一种或多种示例性方法中,该方法包括确定包括第二模型系数的第二模型,其中第二模型基于第二音频源的图像数据和音频输入信号。
在一种或多种示例性方法中,向听力装置传输听力装置信号的步骤可以包括向听力装置传输第二模型系数。换言之,听力装置信号可以包括和/或指示第二模型的第二模型系数。因此,该方法可以包括基于第二模型确定听力装置信号。
在一种或多种示例性方法中,该方法包括:在听力装置中,在听力装置中获得表示来自一个或多个音频源的音频的第一输入信号;在听力装置中基于第二模型系数处理第一输入信号以提供电输出信号;以及在听力装置中将电输出信号转换为音频输出信号。电输出信号可以是第一输出信号和第二输出信号的总和,第一输出信号是基于第一模型系数处理第一输入信号而产生的,第二输出信号是基于第二模型系数处理第一输入信号而产生的。
在一种或多种示例性方法中,基于第二模型系数处理第一输入信号的步骤包括对第一输入信号应用盲源分离
在一种或多种示例性方法中,基于第二模型系数处理第一输入信号的步骤包括将深度神经网络应用于第一输入信号,其中深度神经网络基于第二模型系数。
在一种或多种示例性方法中,识别一个或多个音频源的步骤包括基于图像数据确定第二音频源的第二位置、显示(例如,在附件装置的触敏显示装置上)指示第二音频源的第二用户接口元素、以及检测选择第二用户接口元素的用户输入。该方法可以包括,根据检测选择第二用户接口元素的用户输入,确定图像数据的第二图像数据,第二图像数据与第二音频源相关联。
确定包括第二模型系数的第二模型,其中第二模型基于图像数据可选地包括确定包括第二模型系数的第二模型,其中第二模型基于第二图像数据。换言之,确定包括第二模型系数的第二模型的步骤可选地包括基于与第二音频源相关联的第二图像数据确定第二模型。
显示(例如,在附件装置的触敏显示装置上)指示第二音频源的第二用户接口元素的步骤可以包括将第二用户接口元素覆盖在图像数据的至少一部分上,例如,图像数据的图像。第二用户接口元素可以是第二音频源的帧元素和/或图像。
在一种或多种示例性方法中,确定第二模型的步骤包括基于诸如第二图像数据之类的图像数据确定第二音频源的唇部运动,并且其中第二模型是基于第二音频源的唇部运动的。
第二模型是具有N层的深度神经网络DNN,其中N大于3。DNN可可以具有多个隐藏层,也表示为N_Hidden。DNN的隐藏层数可以是2、3或更多。
在一种或多种示例性方法中,确定包括第二模型系数的第二模型的步骤包括基于图像数据,诸如第二图像数据,训练深度神经网络,以提供第二模型系数。
在一种或多种示例性方法中,该方法包括在附件装置中基于第二模型处理第一音频输入信号以提供第二输出信号。传输听力装置信号的步骤可选地包括将第二输出信号传输到听力装置。因此,听力装置信号可以包括或指示第二输出信号。
进一步公开了一种用于听力系统的附件装置,听力系统包括听力装置和该附件装置。附件装置包括处理单元、存储器、摄像头和接口,其中,处理单元配置为从一个或多个音频源获得表示音频的音频输入信号,处理单元配置为通过摄像头获取图像数据,例如视频数据;基于图像数据识别包括第一音频源的一个或多个音频源;确定包括第一模型系数的第一模型,其中第一模型基于第一音频源的图像数据和音频输入信号;以及通过接口向听力装置传输听力装置信号。
听力装置信号基于第一模型。例如,听力装置信号可以包括第一模型的第一模型系数。因此,向听力装置传输听力装置信号可以包括向听力装置传输第一模型系数。
在一个或多个示例性附件装置中,识别一个或多个音频源的步骤包括基于图像数据确定第一音频源的第一位置、显示(例如,在接口的触敏显示装置上)指示第一音频源的第一用户接口元素、以及例如通过接口的触敏显示装置检测选择第一用户接口元素的用户输入。在一个或多个示例性附件装置中,确定第一模型包括基于图像数据确定第一音频源的唇部运动,并且其中第一模型基于第一音频源的唇部运动。
在一个或多个示例性附件装置中,确定包括第一模型系数的第一模型的步骤包括基于图像数据训练作为深度神经网络的第一模型以提供第一模型系数。基于图像数据训练作为深度神经网络的第一模型以提供第一模型系数的步骤可以包括基于图像数据和表示来自一个或多个音频源的音频的音频输入信号确定第一语音输入信号,以及基于第一语音输入信号训练第一模型。
基于图像数据训练深度神经网络的步骤可以包括基于第一音频源的唇部运动来训练深度神经网络,例如通过使用图像或视频-辅助的语音分离,基于唇部运动确定第一语音输入信号,并根据第一语音输入信号训练DNN(第一模型)。第一音频源的唇部运动(基于图像数据)可以指示音频输入信号中源自第一音频源的第一音频的存在,即所需的音频。
在一个或多个示例性附件装置中,处理单元配置为基于第一模型处理第一音频输入信号以提供第一输出信号,并且其中传输听力装置信号的步骤包括将第一输出信号传输到听力装置。因此,可以将经净化的音频输入信号传输到听力装置以直接用于处理器的听力补偿处理。
公开了一种听力装置,该听力装置包括:天线,用于将来自附件装置的听力装置信号转换为天线输出信号;无线电收发器,耦合到天线以将天线输出信号转换为收发器输入信号;一组麦克风,包括用于提供第一输入信号的第一麦克风;处理器,用于处理第一输入信号并基于第一输入信号提供电输出信号;以及接收器,用于将电输出信号转换为音频输出信号,其中听力装置信号包括深度神经网络的第一模型系数,并且其中处理器配置为基于第一模型系数来处理第一输入信号以提供电输出信号。
图1示出了示例性听力系统。听力系统2包括听力装置4和附件装置6。听力装置4和附件装置6通常可以被称为听力装置系统8。听力系统2可以包括服务器装置10。
附件装置6配置为与听力装置4无线通信。听力应用(hearing application)12安装在附件装置6上。听力应用可以用于控制和/或辅助听力装置4和/或辅助听力装置用户。附件装置6/听力应用12可以配置为执行本文所公开的方法的任何动作。听力装置4可以配置为补偿听力装置4的用户的听力损失。听力装置4配置为例如,使用无线和/或有线第一通信链路20与附件装置6/听力应用12通信。第一通信链路20可以是单跳通信链路或多跳通信链路。第一通信链路20可以通过短距离通信系统承载,例如蓝牙、低功耗蓝牙、IEEE802.11和/或Zigbee。
附件装置6/听力应用12可选地配置为经由第二通信链路22通过诸如因特网和/或移动电话网络之类的网络连接到服务器装置10。服务器装置10可以由听力装置制造商控制。
听力装置4包括天线24和耦合到天线4的无线电收发器26,无线电收发器用于接收/发送无线通信,包括经由第一通信链路20接收听力装置信号27。听力装置4包括一组麦克风,包括第一麦克风28,例如,用于基于第一麦克风输入信号28A提供第一输入信号。该组麦克风可以包括第二麦克风30。第一输入信号可以基于来自第二麦克风30A的第二麦克风输入信号。第一输入信号可以基于听力装置信号27。听力装置4包括:处理器32,用于处理第一输入信号并基于第一输入信号提供电输出信号32A;以及接收器34,用于将电输出信号32A转换为音频输出信号。
附件装置6包括处理单元36、存储器单元38和接口40。听力应用12安装在附件装置6的存储单元38中。接口40包括用于形成通信链路20、22的无线收发器42和用于接收用户输入的触敏显示装置44。
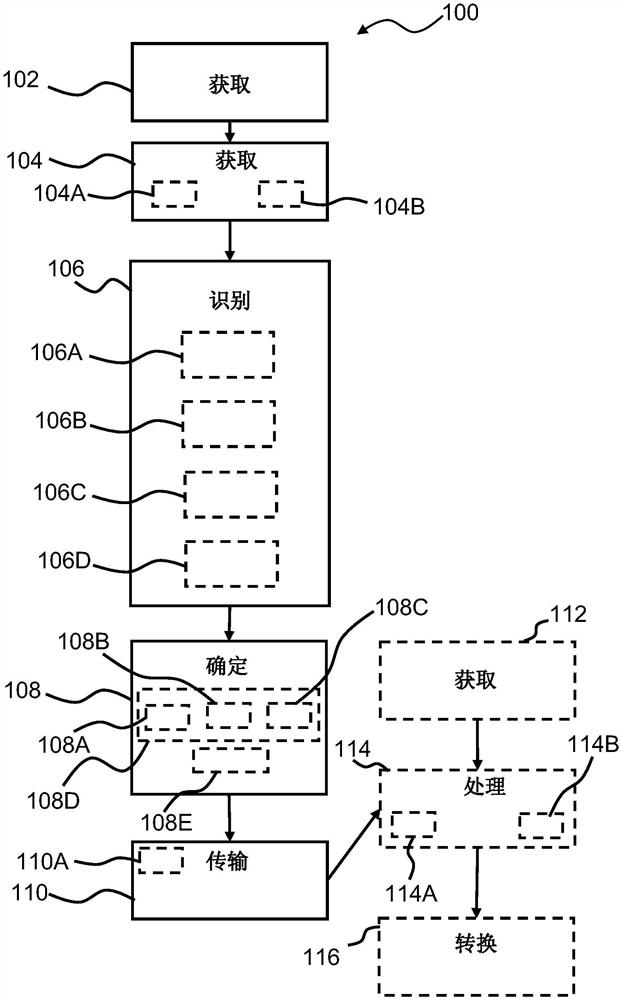
图2是操作包括听力装置和附件装置的听力系统的示例性方法的流程图。方法100包括在附件装置中获得102表示来自一个或多个音频源的音频的音频输入信号;通过附件装置的摄像头获取104图像数据;基于图像数据识别106包括第一音频源的一个或多个音频源;确定108包括第一模型系数MC_1的第一模型M_1,其中,第一模型M_1是基于第一音源的图像数据ID和音频输入信号;以及向听力装置传输110听力装置信号,其中听力装置信号基于第一模型。
在方法100中,识别一个或多个音频源的步骤106可选地包括基于图像数据确定第一音频源的第一位置的步骤106A、显示指示第一音频源的第一用户接口元素的步骤106B、以及检测选择第一用户接口元素的用户输入的步骤106C。方法100可以包括,根据检测选择第一用户接口元素的用户输入的步骤106C来确定图像数据的第一图像数据的步骤106D,第一图像数据与音频源相关联。
在方法100中,确定第一模型M_1的步骤108可选地包括基于诸如第一图像数据的图像数据确定第一音频源的唇部运动的步骤108A,并且其中第一模型M_1基于唇部运动。在方法100中,第一模型是具有N层的深度神经网络,其中N大于3。
在方法100中,确定包括第一模型系数的第一模型的步骤108可选地包括基于图像数据来训练深度神经网络以提供第一模型系数的步骤108B。确定包括第一模型系数的第一模型的步骤108可选地包括基于与第一音频源相关联的第一图像数据确定第一模型的步骤108C。
在方法100中,确定包括第一模型系数的第一模型的步骤108可选地包括基于图像数据和音频输入信号确定第一语音输入信号的步骤108D和基于第一语音输入信号来训练/确定第一模型的步骤108E,也可参见图6。基于图像数据和音频输入信号确定第一语音输入信号的步骤108D可以包括基于图像数据确定第一音频源的唇部运动。
向听力装置传输110听力装置信号的步骤可选地包括向听力装置传输第一模型系数的步骤110A。
在一种或多种示例性方法中,方法100包括:在听力装置中从一个或多个音频源获得表示音频的第一输入信号的步骤112;基于第一模型系数处理第一输入信号以提供电输出信号的步骤114;以及将电输出信号转换为音频输出信号的步骤116。因此,由听力装置执行步骤112、114、116。
在方法100中,基于第一模型系数处理第一输入信号的步骤114可选地包括将盲源分离BSS应用于第一输入信号的步骤114A,其中盲源分离基于第一模型系数MC_1。
在方法100中,基于第一模型系数处理第一输入信号的步骤114可选地包括将深度神经网络DNN应用于第一输入信号的步骤114B,其中深度神经网络DNN基于第一模型系数MC_1。
图3是操作包括听力装置和附件装置的听力系统的示例性方法的流程图。方法100A包括:在附件装置中获得表示来自一个或多个音频源的音频的音频输入信号的步骤102;通过附件装置的摄像头获取图像数据的步骤104;基于图像数据识别包括第一音频源的一个或多个音频源的步骤106;确定包括第一模型系数MC_1的第一模型M_1的步骤108,其中第一模型M_1是基于第一音频源的图像数据ID和音频输入信号;以及向听力装置传输听力装置信号的步骤110,其中听力装置信号基于第一模型。
在方法100A中,识别一个或多个音频源的步骤106可选地包括基于图像数据确定第一音频源的第一位置的步骤106A、显示指示第一音频源的第一用户接口元素的步骤106B、以及检测选择第一用户接口元素的用户输入的步骤106C。方法100A可以包括,根据检测选择第一用户接口元素的用户输入的步骤106C来确定图像数据的第一图像数据的步骤106D,第一图像数据与音频源相关联。
在方法100A中,确定第一模型M_1的步骤108可选地包括基于诸如第一图像数据的图像数据确定第一音频源的唇部运动的步骤108A,并且其中第一模型M_1基于唇部运动。在方法100A中,第一模型是具有N层的深度神经网络,其中N大于3。
在方法100A中,确定包括第一模型系数的第一模型的步骤108可选地包括基于图像数据来训练深度神经网络以提供第一模型系数的步骤108B。确定包括第一模型系数的第一模型的步骤108可选地包括基于与第一音频源相关联的第一图像数据确定第一模型的步骤108C。
方法100A包括在附件装置中基于第一模型处理第一音频输入信号以提供第一输出信号的步骤118,并且其中传输110听力装置信号的步骤包括将第一输出信号传输到听力装置的步骤110B。
方法100A包括处理第一输出信号(从附件装置接收)以提供电输出信号的步骤120;以及将电输出信号转换为音频输出信号的步骤116。因此,由听力装置执行步骤120和116。
在方法100A中,基于第一模型系数处理第一输入信号的步骤114可选地包括将盲源分离BSS应用于第一输入信号的步骤114A,其中盲源分离基于第一模型系数MC_1。在方法100A中,基于第一模型系数处理第一输入信号的步骤114可选地包括将深度神经网络DNN应用于第一输入信号的步骤114B,其中深度神经网络DNN基于第一模型系数MC_1。
图4是示例性附件装置的示意框图。附件装置6包括处理单元36、存储器单元38和接口40。听力应用12安装在附件装置6的存储单元38中。接口40包括用于形成通信链路的无线收发器42和用于接收用户输入的触敏显示装置44。此外,附件装置包括用于获得图像数据的摄像头46和用于检测来自一个或多个音频源的音频的麦克风48。
处理单元36配置为使用麦克风48和/或经由无线收发器获得表示来自一个或多个音频源的音频的音频输入信号;使用摄像头获取图像数据;基于图像数据识别包括第一音频源的一个或多个音频源;确定包括第一模型系数的第一模型,其中第一模型基于第一音频源的图像数据和音频输入信号;以及向听力装置传输听力装置信号,其中听力装置信号基于第一模型。
在附件装置6中,向听力装置传输听力装置信号的步骤可选地包括向听力装置传输第一模型系数。此外,识别一个或多个音频源传输包括基于图像数据确定第一音频源的第一位置、显示指示第一音频源的第一用户接口元素、以及检测选择第一用户接口元素的用户输入。
在附件装置6中,确定第一模型的步骤包括基于图像数据确定第一音频源的唇部运动,并且其中第一模型基于第一音频源的唇部运动。第一模型是N层的深度神经网络,其中N大于3,例如4、5或更多。确定包括第一模型系数的第一模型的步骤包括基于图像数据训练深度神经网络以提供第一模型系数。
处理单元36可以配置为基于第一模型处理第一音频输入信号以提供第一输出信号,并且其中传输听力装置信号的步骤包括将第一输出信号传输到听力装置。
图5是示例性听力装置的示意框图。听力装置4包括天线24和耦合到天线24的无线电收发器26,无线电收发器用于接收/发送无线通信,包括经由通信链路接收听力装置信号27。听力装置4包括一组麦克风,包括第一麦克风28,例如,用于基于第一麦克风输入信号28A提供第一输入信号。该组麦克风可以包括第二麦克风30。第一输入信号可以基于来自第二麦克风30A的第二麦克风输入信号。第一输入信号可以基于听力装置信号27。听力装置4包括:处理器32,用于处理第一输入信号并基于第一输入信号提供电输出信号32A;以及接收器32,用于将电输出信号32A转换为音频输出信号。处理器32配置为基于听力装置信号27来处理第一输入信号,例如,基于深度神经网络的第一模型系数和/或深度神经网络的第二模型系数,并且其中处理器配置为基于第一模型系数和/或第二模型系数处理第一输入信号以提供电输出信号。
图6是类似于方法100的操作包括听力装置和附件装置的听力系统的示例性方法的流程图。方法100B包括:在附件装置中获得表示来自一个或多个音频源的音频的音频输入信号的步骤102;通过附件装置的摄像头获取图像数据的步骤104;基于图像数据识别包括第一音频源的一个或多个音频源的步骤106;确定包括第一模型系数MC_1的第一模型M_1的步骤108,其中第一模型M_1基于第一音频源的图像数据ID和音频输入信号;以及向听力装置传输听力装置信号的步骤110,其中听力装置信号基于第一模型。
在方法100B中,识别一个或多个音频源的步骤106可选地包括基于图像数据确定第一音频源的第一位置的步骤106A、显示指示第一音频源的第一用户接口元素的步骤106B、以及检测选择第一用户接口元素的用户输入的步骤106C。方法100可以包括,根据检测选择第一用户接口元素的用户输入的步骤106C来确定图像数据的第一图像数据的步骤106D,第一图像数据与音频源相关联。
在方法100B中,确定包括第一模型系数的第一模型M_1的步骤108可选地包括基于图像数据和音频输入信号确定第一语音输入信号的步骤108D、以及基于第一语音输入信号确定第一模型的步骤108E。基于第一语音输入信号确定第一模型的步骤108E可选地包括基于第一语音输入信号训练第一模型。
向听力装置传输听力装置信号的步骤110可选地包括向听力装置传输第一模型系数的步骤110A。
在一种或多种示例性方法中,方法100B包括在听力装置中从一个或多个音频源获得表示音频的第一输入信号的步骤112;基于第一模型系数处理第一输入信号以提供电输出信号的步骤114;以及将电输出信号转换为音频输出信号的步骤116。因此,步骤112、114、116由听力装置,例如听力装置2来执行。
在方法100B中,基于第一模型系数处理第一输入信号的步骤114可选地包括将盲源分离BSS应用于第一输入信号的步骤114A,其中盲源分离基于第一模型系数MC_1。
在方法100B中,基于第一模型系数处理第一输入信号的步骤114可选地包括将深度神经网络DNN应用于第一输入信号的步骤114B,其中深度神经网络DNN基于第一模型系数MC_1。
还公开了根据以下项目中任一项的方法、附件装置、听力装置和听力系统。
项目:
1.一种操作包括听力装置和附件装置的听力系统的方法,该方法包括:
在附件装置中获取表示来自一个或多个音频源的音频的音频输入信号;
通过附件装置的摄像头获取图像数据;
基于图像数据识别包括第一音频源的一个或多个音频源;
确定包括第一模型系数的第一模型,其中第一模型基于第一音频源的图像数据和音频输入信号;以及
向听力装置传输听力装置信号,其中听力装置信号基于第一模型。
2.根据项目1所述的方法,其中,的步骤包括将第一模型系数传输到听力装置。
3.根据项目2所述的方法,该方法包括:在听力装置中,
从一个或多个音频源获取表示音频的第一输入信号;
基于第一模型系数处理第一输入信号以提供电输出信号;以及
将电输出信号转换为音频输出信号。
4.根据项目3所述的方法,其中,基于第一模型系数处理第一输入信号的步骤包括对第一输入信号应用盲源分离。
5.根据项目3至4中任一项所述的方法,其中,基于第一模型系数处理第一输入信号的步骤包括将深度神经网络应用于第一输入信号,其中深度神经网络基于第一模型系数。
6.根据项目1至5中任一项所述的方法,其中,识别一个或多个音频源的步骤包括基于图像数据确定第一音频源的第一位置、显示指示第一音频源的第一用户接口元素、以及检测选择第一用户接口元素的用户输入。
7.根据项目1至6中任一项所述的方法,其中,确定第一模型的步骤包括基于图像数据确定第一音频源的唇部运动,并且其中第一模型基于唇部运动。
8.根据项目1至7中任一项所述的方法,其中,第一模型是具有N层的深度神经网络,其中N大于3。
9.根据项目8所述的方法,其中,确定包括第一模型系数的第一模型的步骤包括基于图像数据训练深度神经网络以提供第一模型系数。
10.根据项目1至9中任一项所述的方法,该方法包括在附件装置中基于第一模型处理第一音频输入信号以提供第一输出信号,并且其中传输听力装置信号的步骤包括将第一输出信号传输到听力装置。
11.一种听力系统的附件装置,该听力系统包括听力装置和该附件装置,该附件装置包括处理单元、存储器、摄像头和接口,其中处理单元配置为:
从一个或多个音频源获取表示音频的音频输入信号;
通过摄像头获取图像数据;
基于图像数据识别包括第一音频源的一个或多个音频源;
确定包括第一模型系数的第一模型,其中第一模型基于第一音频源的图像数据和音频输入信号;以及
向听力装置传输听力装置信号,其中听力装置信号基于第一模型。
12.根据项目11所述的附件装置,其中,向听力装置传输听力装置信号的步骤包括将第一模型系数传输到听力装置。
13.根据项目11至12中任一项所述的附件装置,其中,识别一个或多个音频源的步骤包括基于图像数据确定第一音频源的第一位置、显示指示第一音频源的第一用户接口元素、以及检测选择第一用户接口元素的用户输入。
14.根据项目11至13中任一项所述的附件装置,其中,确定第一模型的步骤包括基于图像数据确定第一音频源的唇部运动,并且其中第一模型基于唇部运动。
15.根据项目11至14中任一项所述的附件装置,其中,第一模型是具有N层的深度神经网络,其中N大于3。
16.根据项目15所述的附件装置,其中,确定包括第一模型系数的第一模型的步骤包括基于图像数据训练深度神经网络以提供第一模型系数。
17.根据项目11至16中任一项所述的附件装置,其中,处理单元配置为基于第一模型处理第一音频输入信号以提供第一输出信号,并且其中传输听力装置信号的步骤包括将第一输出信号传输至听力装置。
18.一种听力装置,包括:
天线,用于将来自附件装置的听力装置信号转换为天线输出信号;
耦合到天线的无线电收发器,用于将天线输出信号转换为收发器输入信号;
一组麦克风,包括用于提供第一输入信号的第一麦克风;
处理器,用于处理第一输入信号并基于第一输入信号提供电输出信号;以及
接收器,用于将电输出信号转换为音频输出信号,其中听力装置信号包括深度神经网络的第一模型系数,并且其中处理器配置为基于第一模型系数来处理第一输入信号以提供电输出信号。
19.一种听力系统,包括根据项目11至17中任一项所述的附件装置和根据项目18所述的听力装置。
20.根据项目1至9中任一项所述的方法,其中,确定包括第一模型系数的第一模型的步骤包括基于图像数据和音频输入信号确定第一语音输入信号、以及基于第一语音输入信号确定第一模型。
21.根据项目20所述的方法,其中,基于第一语音输入信号确定第一模型的步骤包括基于第一语音输入信号训练第一模型。
术语“第一”、“第二”、“第三”和“第四”、“第一的”、“第二的”、“第三的”等的使用并不意味着任何特定的顺序,而是用于识别各个元件。此外,术语“第一”、“第二”、“第三”和“第四”、“第一的”、“第二的”、“第三的”等的使用并不表示任何顺序或重要性,而是使用术语“第一”、“第二”、“第三”和“第四”、“第一的”、“第二的”、“第三的”等来区分一个元件和另一元件。请注意,此处和其他地方使用的“第一”、“第二”、“第三”和“第四”、“第一的”、“第二的”、“第三的”等词语仅用于标记目的,并不旨在表示任何特定的空间或时间排序。
此外,标记第一元件并不意味着存在第二元件,反之亦然。
可以理解,图1-图5包括用实线示出的一些模块或操作和用虚线示出的一些模块或操作。包含在实线中的模块或操作是包含在最宽泛的示例实施例中的模块或操作。包括在虚线中的模块或操作是示例性实施例,其可以被包括在实线示例性实施例的模块或操作中,或者是其一部分,或者是除实线示例性实施例的模块或操作之外可以采用的进一步模块或操作。应该理解,这些操作不需要按顺序执行。
此外,应当理解,并非所有操作都需要执行。可以以任何顺序以及任何组合来执行示例性操作。
需要注意的是,词语“包括”不一定排除所列出的元件或步骤之外的其他元件或步骤的存在。
需要注意的是,元件前面的词语“一个”或“一种”不排除存在多个这种元件。还应当注意的是,任何附图标记不限制权利要求的范围,示例性实施例可以至少部分地通过硬件和软件来实现,并且几个“装置”、“单元”或“设备”可以由相同的硬件项目表示。
此处描述的各种示例性方法、装置和系统是在方法步骤过程的一般背景下描述的,其一方面可以由包含在计算机可读介质中的计算机程序产品实现,包括由联网环境中的计算机执行的计算机可执行指令(例如程序代码)。计算机可读介质可以包括可移动和不可移动存储设备,包括但不限于只读存储器(ROM)、随机存取存储器(RAM)、压缩盘(CD)、数字多功能盘(DVD)等。通常,程序模块可以包括执行特定任务或实现特定抽象数据类型的例程、程序、对象、组件、数据结构等。计算机可执行指令、关联的数据结构和程序模块表示用于执行本文公开的方法的步骤的程序代码的示例。此类可执行指令或相关联的数据结构的特定序列表示用于实现此类步骤或过程中描述的功能的相应动作的示例。
尽管已经示出并描述了特征,但是应当理解,它们并不旨在限制要求保护的发明,并且对于本领域技术人员显而易见的是,在不脱离本发明的精神和范围的情况下还可进行各种变形和修改。因此,说明书和附图应被认为是说明性而非限制性的。要求保护的发明旨在涵盖所有替代、修改和等同形式。
- 听力装置中的声源分离及相关方法
- 包括低延时声源分离单元的听力装置