声音控制的装置、系统和方法
文献发布时间:2023-06-19 12:11:54
交叉引用
本申请要求2019年1月6日提交的题为“声音控制的装置、系统和方法(APPARATUS,SYSTEM AND METHOD OF SOUND CONTROL)”的美国临时专利申请62/788,868号的权益和优先权,其全部公开内容通过引用的方式并入本文中。
技术领域
本文描述的实施例大体涉及声音控制。
背景技术
存在许多的多声音环境,例如火车、公共汽车、飞机等,在这些环境中若干用户可以产生和/或收听多个不同的声音。
在此类多声音环境中,用户可能被一个或多个其他用户的声音所干扰。
附图说明
为了说明的简单性和清晰性,图中所示的元件不一定按比例绘制。例如,为了呈现的清晰性,一些元件的尺寸可能相对于其他元件被放大。此外,附图标记可以在附图中重复,以指示对应或类似的元件。下文列出各图。
图1是根据一些示范性实施例的声音控制系统的示意性框图说明。
图2是根据一些示范性实施例的声音控制系统的组件的部署方案的示意图。
图3是根据一些示范性实施例的控制器的示意性框图说明。
图4A是根据一些示范性实施例的被部署以控制多个声音控制区中的声音的扩音器阵列的示意图。
图4B是根据一些示范性实施例的被部署以控制多个声音控制区中的声音的扩音器阵列的示意图。
图5是根据一些示范性实施例的声音控制系统的部署方案的示意图。
图6是根据一些示范性实施例的声音控制系统的组件的部署方案的示意图。
图7是根据一些示范性实施例的声音控制系统的组件的部署方案的示意图。
图8是根据一些示范性实施例的声音控制系统的组件的部署方案的示意图。
图9是根据一些示范性实施例的声音控制系统的组件的部署方案的示意图。
图10是根据一些示范性实施例的控制器的示意图。
图11是根据一些示范性实施例的频率选择器的示意图。
图12是根据一些示范性实施例的扬声器传递函数(STF)适配器的示意图。
图13是根据一些示范性实施例的声音控制模式产生器的示意图。
图14是根据一些示范性实施例的车辆的示意图。
图15是根据一些示范性实施例的包括主动噪声控制(ANC)机制的控制器的示意图。
图16是根据一些示范性实施例的声音控制方法的示意性流程图说明。
图17是根据一些示范性实施例的产品的示意图。
具体实施方式
在以下具体实施方式中,陈述众多具体细节以提供对一些实施例的透彻理解。然而,本领域普通技术人员将理解,可以在没有这些具体细节的情况下实践一些实施例。在其他情况下,没有详细描述众所周知的方法、程序、组件、单元和/或电路,以免混淆论述。
本文利用诸如“处理”、“运算”、“计算”、“确定”、“建立”、“分析”、“检查”等术语的论述可以指计算机、计算平台、计算系统或其他电子计算设备的操作和/或过程,这些操作和/或过程将表示为计算机寄存器和/或存储器内的物理(例如,电子)量的数据操纵和/或变换为类似地表示为计算机寄存器和/或存储器或其他信息存储介质内的物理量的其他数据,这些信息存储介质可以存储指令以执行操作和/或过程。
如本文所使用的术语“多个”包括例如“多个”或“两个或更多个”。例如,“多个项目”包括两个或更多个项目。
以下具体实施方式的一些部分是根据对计算机存储器内的数据位或二进制数字信号的操作的算法和符号表示来呈现的。这些算法描述和表示是数据处理领域的技术人员用于向该领域的其他技术人员传达其工作实质的技术。
此处,算法通常被认为是导致期望结果的动作或操作的自洽序列。这些包括物理量的物理操纵。通常,但不一定,这些量采取能够被存储、传递、组合、比较和以其他方式操纵的电信号或磁信号的形式。主要由于常用的原因,有时将这些信号称为位、值、元素、符号、字符、术语、数字等被证明是方便的。然而,应理解,所有这些和类似的术语都与适当的物理量相关联,并且仅仅是应用于这些量的方便的标签。
一些示范性实施例包括系统和方法,其可以被有效地实现用于例如在预定义区域和/或区内控制声音,例如,如下文描述。
一些示范性实施例可以包括被配置为控制至少一个个人声音区(也称为“个人声音气泡(PSB)”)内的声音的方法和/或系统,例如,如下文描述。
在一些示范性实施例中,声音控制系统(也称为“PSB系统”)可以被配置成产生声音控制模式,该模式例如可以基于至少一个音频输入,使得可以基于该音频输入创建至少一个个人声音区。
在一些示范性实施例中,声音控制系统可以被配置成例如基于用户在PSB要听到的音频来控制至少一个预定义位置、区域或区(例如,至少一个PSB)内的声音,例如,如下文描述。
在一些示范性实施例中,声音控制系统可以被配置成控制PSB中的一个或多个第一声音模式和一个或多个第二声音模式之间的声音对比度,例如,如下文描述。
在一些示范性实施例中,例如,声音控制系统可以被配置成控制将由用户在PSB中听到的音频的一个或多个第一声音模式与一个或多个第二声音模式之间的声音对比度,例如,如下文描述。
在一些示范性实施例中,例如,声音控制系统可以被配置成:例如基于要在PSB中听到的音频,选择性地增加和/或放大PSB内一种或多种类型的声学模式的声能和/或波幅;例如基于要提供给一个或多个其他PSB的音频,选择性地减少和/或消除PSB内一种或多种类型的声学模式的声能和/或波幅;和/或选择性地和/或选择性地维持和/或保存PSB内一种或多种其他类型声学模式的声能和/或波幅。
在一些示范性实施例中,声音控制系统可以被配置成基于任何其他附加或替代输入或准则来控制PSB内的声音,例如,如下文描述。
在一些示范性实施例中,例如,声音控制系统可以被配置成例如基于例如PSB外部的环境(例如,PSB周围的环境)和/或一个或多个其他PSB(例如,相邻PSB)中声音的一个或多个属性来控制PSB内的声音。
在一些示范性实施例中,例如,声音控制系统可以被配置成例如基于噪声和/或不想要的声音的一个或多个属性来控制PSB内的声音,以例如减少和/或消除PSB内的一个或多个声音模式,例如,如下文描述。
在一些示范性实施例中,例如,本文描述的声音控制系统和/或方法可以被配置成以任何其他方式来控制PSB内一个或多个声学模式的声能和/或波幅,以例如影响、改变和/或修改预定义区内一个或多个声学模式的声能和/或波幅。
在一些示范性实施例中,个人声音区可以包括三维区,例如,定义要在其中控制声音的体积。
在一个示例中,个人声音区可以包括球形体积,例如气泡状体积,或者具有任何其他形状或形式的任何其他体积,并且PSB系统可以被配置成控制球形体积内的声音。
在其他实施例中,个人声音区可以包括任何其他合适的体积,其可以例如基于个人声音区将被维持的位置的一个或多个属性来定义。
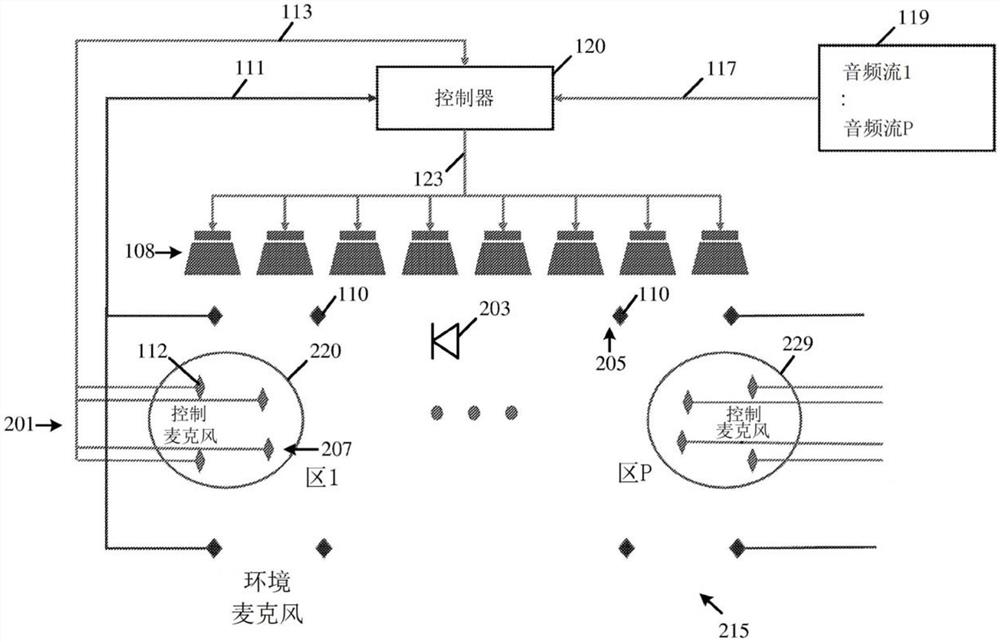
现在参考图1,其示意性地示出了根据一些示范性实施例的声音控制系统100(也称为“PSB系统”)。还参考图2,其示意性地示出了根据一些示范性实施例的PSB系统100的组件的部署方案200。
在一些示范性实施例中,系统100可以被配置成例如至少基于至少一个音频输入来控制至少一个个人声音区201内的声音,例如,至少包括个人声音区220,表示为“区1”。例如,PSB系统可以被配置成例如基于用户在PSB 220中要听到的至少一个音频输入来控制至少一个PSB 220内的音频,例如,如下文描述。
在一些示范性实施例中,个人声音区220可以包括三维区。例如,个人声音区220可以包括球形区。
在一个示例中,个人声音区220可以包括预定义的区和/或区域,其可以适用于单个人、动物、植物、设备(例如,智能家庭设备)或任何其他对象。
在一个示例中,个人声音区220可以包括三维区,例如,定义要在其中控制声音的体积。
在一些示范性实施例中,音频输入可以包括指定在个人声音区中听到的音频,例如,如下文描述。
在一些示范性实施例中,系统100可以被配置成控制多个个人声音区201(例如,包括两个或更多个个人声音区)内的声音,例如,如下文描述。
在一些示范性实施例中,多个声音区201可以包括P个个人声音区,例如包括个人声音区220和至少一个其他个人声音区229,表示为“区P”。
在一些示范性实施例中,多个个人声音区201可以被配置用于例如一个或多个(例如,几个)人、动物、植物、设备或任何其他对象,例如计算设备或个人助理设备,例如,如下文描述。
在一个示例中,一些环境,例如多声音环境(诸如车辆、火车、飞机、工作空间、家庭、公共场所等)可以包括由多个用户共享的空间,其中每一用户可能想要听到不同的声音,例如音频、音乐、声音等。根据该示例,可能需要允许多个用户享受个别的声音体验,例如,如下文描述。
在一些示范性实施例中,声音控制系统100可以被配置成在多个声音区201的个人声音区之间创建分隔,以例如在此类多声音环境中实现声音分隔,例如,如下文描述。
在一些示范性实施例中,声音控制系统100可以被配置成将环境215(例如,多声音环境)划分成几个虚拟的独立区,例如,以几个个人声音区的形式,例如使得可以将个人声音体验递送到例如每个个人声音区,例如,如下文描述。
在一些示范性实施例中,声音控制系统100可以被配置成使用部署在环境215中的声换能器108(例如,扩音器)的阵列,例如,以可以被配置成将环境划分成多个个人声音区201的方式,例如,如下文描述。
本文描述了关于利用多个扩音器的声音控制系统的一些示范性实施例。在其他实施例中,例如,除了一个或多个扩音器之外或代替一个或多个扩音器,声音控制系统可以包括一个或多个其他类型的声换能器。
在一些示范性实施例中,声音控制系统100可以被配置成实现高级信号处理方法,例如以将环境215划分成多个个人声音区201,例如,如下文描述。
在一些示范性实施例中,声音控制系统100可以实现和/或支持朝向个人声音区(例如,个人声音区220)的聚焦声音传输,同时减少、最小化或甚至消除其他地方的声音强度,例如,在多个个人声音区201的其他个人声音区中的声音强度,和/或在声音区220外部的环境215中的一个或多个其他位置的声音强度,例如,如下文描述。
在一些示范性实施例中,声音控制系统100可以实现和/或支持向多个个人声音区201提供独立的音频内容,例如,甚至在例如同质环境(诸如房间或汽车)的环境中。例如,该环境中的听众(例如,每一听众)可能能够享受他自己选择的音频,例如音乐、声音、新闻等,例如,如下文描述。
在一些示范性实施例中,声音控制系统100可以被配置成在各种环境中实现和/或支持各种环境,例如,如下文描述。
在一些示范性实施例中,声音控制系统100可以包括车辆系统,例如,如下文描述。
在一个示例中,声音控制系统100可以被实现为车辆的一个或多个车辆系统的一部分,例如,如下文描述。例如,声音控制系统100可以在车辆的内部实现。例如,车辆可以包括公共汽车、货车、汽车、卡车、飞机、船舶、火车、自主驾驶车辆等。
在其他实施例中,声音控制系统100可以结合任何其他设备、系统和/或环境来实现。
在一个示例中,声音控制系统100可以被配置成在运输环境中实现和/或被配置成支持运输环境,例如飞机、火车和/或汽车,以例如使用户(例如每一用户,例如驾驶员、乘客和/或旅行者)能够享受他或她自己选择的音频。
在一个示例中,声音控制系统100可以被配置成在家庭环境中实现和/或支持家庭环境,例如,实现和/或支持向一个或多个用户提供定制的多媒体(例如,电视、音频、视频和/或游戏)体验,同时适应用户的个人偏好。
在一个示例中,声音控制系统100可以被配置成在工作环境中实现和/或支持工作环境,例如,允许例如为共享同一工作空间的用户提供隐私和/或提高工作环境内的保密性。
在一个示例中,声音控制系统100可以被配置成在公共环境中实现和/或支持公共环境,例如,允许和/或支持音频信号向公共环境中的一个或多个相关区的音频转换。
在另一示例中,声音控制系统100可以被配置成在任何其他环境中实现和/或支持任何其他环境。
在一些示范性实施例中,声音控制系统100可以被配置成使用多个声换能器108(例如,扩音器)来将一个或多个输入音频信号117聚集到特定的个人声音区,例如,使得个人声音区(例如,每个个人声音区)可以体验相应的音频信号,例如,期望的一个或多个音频信号,例如,如下文描述。
在一些示范性实施例中,声音控制系统100可以实现高级信号处理方法,以例如增强(例如,最大化)例如相应的个人声音区中的信号117的一个或多个输入音频信号的声音强度,同时减少(例如,最小化或甚至消除)个人声音区220中的一个或多个不期望音频信号的声音强度,例如,如下文描述。
在一些示范性实施例中,声音控制系统100可以被配置成实现一个或多个信号处理技术,以例如单独地处理多个声音控制区201的声音,例如,增加(例如,最大化)多个个人声音区201的每一区的声音强度,例如,如下文描述。
在一些示范性实施例中,声音控制系统100可以被配置成实现一个或多个信号处理技术,以例如联合地处理多个声音控制区201的两个或更多个声音控制区的声音,例如,增加(例如,最大化)多个个人声音区201的每一区的声音强度,例如,如下文描述。
在一些示范性实施例中,声音控制系统100可以被配置成例如以降低的(例如,最小的)对音频质量的影响向个人声音区提供音频,同时例如提供个人声音体验,而不干扰或最小程度地干扰不在个人声音区中的其他人,例如,如下文描述。
在一些示范性实施例中,声音控制系统100可以包括被配置成控制例如环境215内的声音的声音控制器102,例如,如下文描述。
在一个示例中,环境215可以包括车辆的内部、共享办公室和/或任何其他环境。
在一些示范性实施例中,声音控制器102可以包括输入125,该输入125被配置成接收要在例如多个个人声音区201中的一个或多个个人声音区中听到的一个或多个音频输入117,例如,如下文描述。例如,一个或多个音频输入117可以来自一个或多个音频源119。
在一个示例中,一个或多个音频输入117可以包括例如音乐、电话对话、人机交互声音、导航输入、车辆警报和/或任何其他声音和/或音频输入。
在一些示范性实施例中,输入125可以被配置成接收多个监测输入113,例如,如下文描述。
在一些示范性实施例中,多个监测输入113可以表示在多个预定义的监测感测位置207处的声学声音,这些位置可以被定义在多个个人声音区201的一个或多个个人声音区内,例如,如下文描述。
在一些示范性实施例中,声音控制器102可以包括控制器120,其被配置成基于一个或多个音频输入117和多个监测输入113来确定声音控制模式123,例如,如下文描述。
在一些示范性实施例中,声音控制模式123可以包括多个声音控制信号,其被配置成例如分别驱动多个声换能器108,使得可以在例如多个个人声音区201的一个或多个个人声音区中听到一个或多个音频输入117,例如,如下文描述。
在一些示范性实施例中,声音控制器102可以包括输出127,用于向多个声换能器108输出多个声音控制信号,例如,如下文描述。
在一些示范性实施例中,控制器120可以被配置成例如基于环境声学信息来确定声音控制模式123,例如,如下文描述。
在其他实施例中,控制器120可以被配置成例如即使不使用环境声学信息也能确定声音控制模式123。
在一些示范性实施例中,输入125可以被配置成接收表示在多个预定义环境位置205处的环境声学声音的环境声学信息111,这些位置可以相对于包括一个或多个个人声音区201的环境215来定义,例如,如下文描述。
在一个示例中,控制器120可以被配置成例如使用声学传感器来改进传输到个人声音区的音频流的质量,声学传感器可以被配置成“环境声学传感器”以“收听”环境声音和/或噪声。例如,实现环境声学传感器可以提供允许声音控制系统100例如实时控制个人声音区220中的听众例如在任何时间听到的频率的技术优势,例如,如下文描述。
在一些示范性实施例中,控制器120可以被配置成例如基于环境声学信息111来确定声音控制模式123,例如,如下文描述。
在一些示范性实施例中,环境声学信息111可以包括由声学传感器110在多个预定义环境位置205中的一个环境位置205处感测的声学声音的信息,例如,如下文描述。
在一些示范性实施例中,环境声学信息111可以包括例如一个或多个音频输入117的音频信号的信息、由预定义的音频源203产生的声学声音和/或与环境215的一个或多个位置中的声音相关的任何其他信息,例如,如下文描述。
例如,预定义的音频源203可以包括蜂窝式电话的扬声器、车辆安全系统的声音警报等。
在其他实施例中,环境声学信息111可以包括与环境215相关的任何其他附加或替代的声学信息。
在一些示范性实施例中,控制器120可以被配置成确定要包括在声音控制模式123中的多个选定频率,例如,如下文描述。
在一些示范性实施例中,控制器120可以被配置成例如基于环境声学信息111和一个或多个音频输入117从频谱中选择多个选定频率,例如,如下文描述。
在一些示范性实施例中,控制器120可以被配置成例如基于投影音频和投影环境声音来确定多个选定频率,例如,如下文描述。
在一些示范性实施例中,投影的音频可以例如基于通过从多个换能器108到个人声音区220的传递函数进行的将在个人声音区220听到的音频输入117的投影,例如,如下文描述。
在一些示范性实施例中,投影的环境声音可以基于例如通过从多个预定义环境位置205到个人声音区220的传递函数进行的环境声学声音的投影,例如,如下文描述。
在一些示范性实施例中,控制器120可以被配置成例如基于特定频率的投影音频和特定频率的投影环境声音来确定该特定频率是否将被包括在多个选定频率中,例如,如下文描述。
在一些示范性实施例中,控制器120可以被配置成例如当特定频率的投影音频与特定频率的投影环境声音之间的差异大于预定义阈值时,确定该特定频率将被包括在多个选定频率中,例如,如下文描述。该阈值可以例如基于要在个人声音区中听到的音频与影响个人声音区的环境声音之间的期望对比度来定义。
在一些示范性实施例中,控制器120可以被配置成例如基于对应于一个或多个个人声音区210的一个或多个权重向量集来确定多个声音控制信号,例如,如下文描述。
在一些示范性实施例中,对应于个人声音区220的权重向量集可以包括分别对应于多个声换能器108的多个权重向量,例如,如下文描述。
在一些示范性实施例中,该权重向量集中的权重向量可以基于例如多个声换能器108中的一个声换能器108和个人声音区220之间的声学传递函数,例如,如下文描述。
在一些示范性实施例中,控制器120可以被配置成例如通过将来自对应于个人声音区220的权重向量集的对应于特定声换能器108的权重向量应用于将在个人声音区220中听到的音频输入117、来确定特定声换能器108的声音控制信号,例如,如下文描述。
在一些示范性实施例中,控制器120可以被配置成例如基于第一多个声学传递函数和第二多个声学传递函数来确定对应于个人声音区220的权重向量集,例如,如下文描述。
在一些示范性实施例中,第一多个声学传递函数可以包括多个声换能器108和个人声音区220之间的声学传递函数,例如,如下文描述。
在一些示范性实施例中,第二多个声学传递函数可以包括多个声换能器108和个人声音区220外部的一个或多个监测位置之间的声学传递函数,例如,一个或多个其他个人声音区中的一个或多个监测位置和/或环境215中的一个或多个监测位置,例如,如下文描述。
在一些示范性实施例中,控制器120可以被配置成例如基于环境声学信息111来调整第一多个声学传递函数或第二多个声学传递函数中的一个或多个声学传递函数,该环境声学信息表示多个预定义环境位置205处的环境声学声音,预定义环境位置205可以相对于包括一个或多个个人声音区201的环境215来定义,例如,如下文描述。
在一些示范性实施例中,控制器120可以被配置成例如基于个人声音区220的位置变化来调整第一多个声学传递函数或第二多个声学传递函数中的一个或多个声学传递函数,例如,如下文描述。
在一个示例中,环境215可以包括车辆的内部,并且个人声音区220可以包括在旅行者(例如,驾驶员或乘客)头部附近的区域。例如,个人声音区220可以被定义为覆盖旅行者的至少一只耳朵附近或周围的区域。根据该示例,个人声音区220的位置变化可以包括例如旅行者的头靠和/或座椅的移动,例如可以移动驾驶员头部的向上、向下、向后和/或向前的移动。在一个示例中,控制器120可以被配置成例如从车辆的车辆系统接收座椅和/或头靠的位置的位置信息,并且控制器120可以被配置成基于位置信息来调整个人声音区的一个或多个声学传递函数。
在一些示范性实施例中,控制器120可以被配置成例如基于环境215的一个或多个环境参数的环境参数信息来调整第一多个声学传递函数或第二多个声学传递函数中的一个或多个声学传递函数,例如,如下文描述。
在一个示例中,环境215的环境参数信息可以包括例如环境215中的温度,例如车辆中的温度,当系统100在车辆中被实现时,可以从一个或多个车辆系统(例如空调车辆系统)接收该温度。根据该示例,控制器120可以被配置成例如从车辆的系统控制器接收该车辆中的环境的温度信息和/或任何其他信息,并且控制器120可以被配置成基于环境参数信息来调整个人声音区的一个或多个声学传递函数。
在一些示范性实施例中,控制器120可以被配置成例如基于与第一声能和第二声能之间的对比度相关的准则来确定对应于个人声音区220的权重向量集,例如,如下文描述。
在一些示范性实施例中,第一声能可以包括例如基于对应于个人声音区的权重向量集的个人声音区220处的声能,例如,如下文描述。
在一些示范性实施例中,第二声能可以包括例如基于对应于个人声音区220的权重向量集的在个人声音区220外部的一个或多个监测位置处的声能,例如在一个或多个其他个人声音区中的一个或多个位置和/或在环境215中的任何其他位置,例如,如下文描述。
在一些示范性实施例中,权重向量可以包括对应于相应多个声频的多个权重,例如,如下文描述。
在一个示例中,权重向量可以包括对应于来自频谱的多个选定频率中的一些或全部的多个权重,例如,如下文描述。
在一些示范性实施例中,控制器120可以被配置成例如基于至少第一和第二音频输入117来确定声音控制模式123,例如,如下文描述。
在一些示范性实施例中,第一音频输入可以用于第一个人声音区,例如个人声音区220,第二音频输入可以用于第二个人声音区,例如个人声音区229。
在一些示范性实施例中,控制器120可以被配置成例如基于表示在第一多个监测感测位置处的声学声音的第一多个监测输入和表示在第二多个监测感测位置处的声学声音的第二多个监测输入来确定声音控制模式123,该第一多个监测感测位置被定义在第一个人声音区220内,该第二多个监测感测位置被定义在第二个人声音区229内,例如,如下文描述。
在一些示范性实施例中,控制器120可以被配置成利用主动噪声消除(ANC)机制以例如动态地控制、减少或消除来自个人声音区201的环境215的噪声。
在一些示范性实施例中,控制器120可以被配置成基于ANC机制来确定声音控制模式,该ANC机制被配置成基于一个或多个音频输入和来自ANC麦克风的输入来减少个人声音区外部的剩余噪声,例如,如下文描述。
在一些示范性实施例中,控制器120可以被配置成控制至少一个个人声音区220内的声音,例如,如下文详细描述。
在一些示范性实施例中,控制器120可以被配置成基于可以被指定在个人声音区220听到的音频输入117来控制该个人声音区220内的声音,例如,如下文描述。
在一些示范性实施例中,控制器120可以被配置成例如从至少一个声源119接收音频输入117,例如,如下文描述。
在一些示范性实施例中,例如,声源119可以包括一个或多个数字音频源,例如,如下文描述。
在一个示例中,声源119可以包括被配置成提供音频输入117的任何音频源,例如音频信号、电话呼叫、导航指令、人类语音、机器声音、系统警报和/或任何其他语音、声音和/或噪声。
在一些示范性实施例中,控制器120可以被配置成以局部方式向个人声音区220提供声音,例如音频,例如使得声音的一个或多个频率可以被导向声音区220,同时控制(例如,减少或消除)个人声音区220外部的声音的一个或多个频率的效应,例如,如下文描述。
在一个示例中,控制器120可以被配置成例如基于音频输入117来控制和/或定位朝向个人声音区220的声音,例如,如下文描述。
例如,控制器120可以被配置成控制和/或定位个人声音区220中的声音,例如,在一个或多个可听频率中,例如,仅在与用户要听到的期望声音相关的可听频率中,例如,以最大化个人声音区220的声音性能,例如,如下文描述。
在一些示范性实施例中,控制器120可以被配置成例如经由输入125接收多个监测输入113,这些监测输入可以表示可以在个人声音区220内定义的多个预定义监测感测位置207处的声学声音。
在一些示范性实施例中,控制器120可以从位于一个或多个监测感测位置207的多个监测传感器112(例如,麦克风、加速度计、转速计等)和/或从被配置成估计一个或多个监测感测位置207处的声学音频的一个或多个虚拟传感器接收多个监测输入113,例如,如下文详细描述。
在一些示范性实施例中,控制器120可以被配置成例如经由输入125接收环境声学信息111,该环境声学信息可以表示在多个预定义环境位置205处的环境声学声音,该多个预定义环境位置可以相对于包括个人声音区220的环境215来定义,例如,如下文描述。
在一些示范性实施例中,控制器120可以从位于多个预定义环境位置205中的一个或多个处的多个声学传感器110(例如,麦克风、加速度计、转速计等)和/或从被配置成估计多个预定义环境位置205中的一个或多个处的声学声音的一个或多个虚拟传感器,接收声学声音的信息111,例如,如下文详细描述。
在一些示范性实施例中,控制器120可以被配置成例如基于要提供给声音控制区220的音频输入117、环境声学信息111和/或多个监测输入113来确定声音控制模式123,并且输出声音控制模式123来控制多个声换能器108,例如,如下文详细描述。
在一些示范性实施例中,多个声换能器108(例如,多个扬声器)可以包括例如扬声器阵列,例如,如下文描述。
在一些示范性实施例中,控制器120可以控制多个声换能器108,以例如基于声音控制模式123来产生音频输出模式122,该音频输出模式122被配置成控制个人声音区220内的音频,例如,如下文描述。
在一个示例中,多个声换能器108可以包括多个扬声器、扩音器或任何其他声换能器,其被配置成例如基于众多音频输入117将音频输出模式122聚集到例如一个或多个个人声音区201中,例如使得每个个人声音区220可以体验相应的音频输入,例如,如下文描述。
在一些示范性实施例中,多个声换能器108可以包括部署在环境215(例如,包括个人声音区220)中的扩音器阵列,例如,如下文描述。
在一些示范性实施例中,多个声换能器108可以包括例如一个或多个声换能器的阵列,例如至少一个合适的扬声器,以例如基于声音控制模式123产生音频输出模式122。
在一些示范性实施例中,多个声换能器108可以位于一个或多个位置,这些位置可以基于个人声音区220的一个或多个属性来确定,例如,区220的大小和/或形状、个人声音区220的预期位置和/或方向性、要在个人声音区220中听到的音频输入117的一个或多个属性、多个声换能器108的数量等。
在一个示例中,多个声换能器108可以包括扬声器阵列,该扬声器阵列包括预定义数量(表示为M)的扬声器或多通道声学源。
在一些示范性实施例中,多个声换能器108可以包括扬声器阵列,该阵列使用位于合适位置(例如,在个人声音区220外部)的合适的“紧凑声学源”来实现。在另一示例中,扬声器阵列可以使用分布在空间中的多个扬声器来实现,例如围绕个人声音区220。
在一些示范性实施例中,多个环境位置205可以分布在个人声音区220的外部。例如,多个环境位置205中的一个或多个可以分布在围绕个人声音区220的包络或壳体上或附近。
例如,如果个人声音区220由球形体积定义,则多个环境位置205中的一个或多个可以分布在球形体积的表面上和/或球形体积的外部。
在另一示例中,多个环境位置205中的一个或多个可以分布在个人声音区220上和/或外部的位置的任何组合中,例如围绕球形体积的一个或多个位置。
在一些示范性实施例中,监测感测位置207可以分布在个人声音区220内,例如,在个人声音区220的包络附近和/或在个人声音区220内的任何其他位置。
例如,如果区220由球形体积定义,则监测感测位置207可以分布在半径小于个人声音区220的半径的球形表面上。
在一些示范性实施例中,多个声学传感器110可以被配置和/或分布以感测在多个环境位置205中的一个或多个处的声学声音。
在一些示范性实施例中,多个声学传感器110可以被配置成收听环境和/或基于在环境215上感测到的声音来提供参考信号,例如环境声学信息111,例如,如下文描述。
在一些示范性实施例中,控制器120可以被配置成控制至少一个个人声音区内的“想要的”声音,例如,通过选择性地控制一个或多个频率(例如,仅在与想要的声音相关的可听见频率中)中的想要的声音来将声音输入117提供给个人声音区220,例如,如下文描述。
例如,在一个或多个频率中(例如,仅在与想要的声音相关的可听频率中)对想要的声音的选择性控制可以提供增加(例如,最大化)控制器120的控制器声音性能的技术优势。
在一些示范性实施例中,控制器120可以被配置成利用环境声学信息111,例如,以估计在多个环境位置205处的一个或多个可听频率中的声能,例如不想要的声能。例如,控制器120可以被配置成确定个人声音区220的声音控制模式123,同时利用估计的环境不想要的声能,该声能可以例如在监测位置205掩盖要在个人声音区220中听到的声音,例如音频输入117。
在一个示例中,控制器120可以被配置成利用环境声学信息111,例如,以估计至少一个个人声音区220内的可听频率,该可听频率与环境不想要的声能相关,该环境不想要的声能掩盖了想要在私人声音区220中被听到的声音。
在一些示范性实施例中,控制器120可以被配置成例如基于环境声学信息111来在频谱方面估计环境噪声及其对个人声音区220的贡献。
在一些示范性实施例中,控制器120可以被配置成例如基于相对于环境噪声源的相关“主要”音频来控制个人声音区220内的声音。例如,仅使用主要音频(例如,不是所有频谱)可以提供支持降低复杂性的技术解决方案,例如,降低计算复杂性、降低处理复杂性、降低处理延迟和/或降低系统100的功耗。
在一些示范性实施例中,控制器120可以被配置成实现和/或支持对传入音频流117执行频谱分析,例如,通过决定要解决哪些频率,使用相关主要频率中的约束来优化解决方案,和/或优化解决方案的复杂性。
在一个示例中,控制器120可以被配置成例如针对不同声音类型的音频输入(例如,语音、音乐、警报等)来实现频谱分析。
在另一示例中,控制器120可以被配置成例如针对多个声音气泡来实现频谱分析。
在一些示范性实施例中,多个监测传感器112可以被配置成感测在监测感测位置207中的一个或多个处的声学声音。
在一个示例中,多个监测传感器112可以被配置成感测和/或监测多个预定义的监测感测位置207处的声学声音的有效性。
在一些示范性实施例中,多个监测传感器112可以被配置成产生多个监测输入113,这些监测输入表示在个人声音区220内的多个预定义监测感测位置207处的声学声音,例如,如下文描述。
在一些示范性实施例中,多个监测传感器112可以被配置成产生监测信号(例如,多个监测输入113),和/或可以位于个人声音区220中。
在一个示例中,多个监测传感器112可以用于例如实时监测个人声音区220中的音频的有效性,以定义个人声音区220的尺寸和/或例如实时地连续优化个人声音区220中的音频性能。
在一些示范性实施例中,控制器120可以被配置成例如实时地调整和/或优化传递函数,例如从多个换能器108到一个或多个个人声音区220的传递函数,例如,以适应系统和/或环境的变化(例如,如果用户改变声学环境效应),例如,如下文描述。
在一些示范性实施例中,控制器120可以被配置成使用监测输入113和/或环境声学信息111,例如,以优化传递函数中的一个或多个,例如,如下文描述。
在一些示范性实施例中,控制器120可以例如基于虚拟感测方法来优化传递函数中的一个或多个,例如,如下文描述。
在一些示范性实施例中,控制器120可以例如基于一个或多个场景来调整和/或优化一个或多个传递函数,这可能导致声学环境效应和/或变化,例如,如下文描述。
例如,控制器120可以例如基于人的移动、物体的移动、温度变化和/或环境215中的任何其他环境和/或物理变化来调整优化一个或多个传递函数。
例如,控制器120可以例如基于个人声音区220的位置变化来调整和/或优化一个或多个传递函数。例如,个人声音区220可以移动和/或改变。在一个示例中,当系统100在车辆内实现时,可以基于驾驶员和/或驾驶员座椅的移动来移动驾驶员的个人声音区。
在一个示例中,多个监测传感器112和/或多个声学传感器110可以包括和/或可以由一个或多个电子源、声源、电子信号和/或传感器实现,例如麦克风、加速度计、光学传感器,例如激光传感器、激光雷达传感器、摄像机、雷达、数字音频信号和/或任何其他传感器。
在一些示范性实施例中,多个声学传感器110中的一个或多个和/或多个监测传感器112中的一个或多个可以使用一个或多个“虚拟传感器”(“虚拟麦克风”)来实现。对应于特定麦克风位置的虚拟麦克风可以通过能够评估声学模式的任何合适的算法和/或方法来实现,该声学模式将由位于特定麦克风位置的实际声学传感器来感测。
在一些示范性实施例中,控制器120可以被配置成例如通过估计和/或评估在虚拟麦克风的特定位置的声学音频模式来模拟和/或执行虚拟麦克风的功能性。
在一些示范性实施例中,系统100可以包括多个声学传感器110中的一个或多个的第一阵列,例如麦克风、加速度计、转速计等,其被配置成感测多个环境位置205中的一个或多个处的声学声音。例如,多个声学传感器110可以包括一个或多个传感器以感测个人声音区220外部的区中的声学声音。
在一些示范性实施例中,第一阵列的一个或多个传感器可以使用一个或多个“虚拟传感器”来实现。例如,第一阵列可以通过至少一个麦克风和至少一个虚拟麦克风的组合来实现。对应于多个环境位置205的特定麦克风位置的虚拟麦克风可以通过能够评估声学模式的任何合适的算法和/或方法来实现,例如,作为控制器120的一部分或系统100的任何其他元件,该声学模式将由位于特定麦克风位置的声学传感器来感测。例如,控制器120可以被配置成基于由第一阵列的至少一个麦克风感测的至少一个实际声学模式来评估虚拟麦克风的声学模式。
在一些示范性实施例中,系统100可以包括多个监测传感器112中的一个或多个的第二阵列,例如麦克风,其被配置成感测监测感测位置207中的一个或多个处的声学声音。例如,多个监测传感器112可以包括一个或多个传感器以感测个人声音区220内的区中的声学声音。
在一些示范性实施例中,第二阵列的一个或多个传感器可以使用一个或多个“虚拟传感器”来实现。例如,第二阵列可以包括至少一个麦克风和至少一个虚拟麦克风的组合。对应于监测感测位置207的特定麦克风位置的虚拟麦克风可以通过能够评估声学模式的任何合适的算法和/或方法来实现,例如,作为控制器120的一部分或系统100的任何其他元件,该声学模式将由位于特定麦克风位置的声学传感器来感测。例如,控制器120可以被配置成基于由第二阵列的至少一个麦克风感测的至少一个实际声学模式来评估虚拟麦克风的声学模式。
在一些示范性实施例中,环境位置205和/或监测感测位置207的数量、位置和/或分布,和/或一个或多个环境位置205和/或监测感测位置207处的一个或多个声学传感器的数量、位置和/或分布可以基于以下各项来确定:个人声音区220或个人声音区220的包络的大小、个人声音区220或个人声音区220的包络的形状、位于一个或多个环境位置205和/或监测感测位置207的声学传感器的一个或多个属性,例如传感器的采样速率等。
在一个示例中,一个或多个声学传感器(例如,麦克风、加速度计、转速计等)可以根据空间采样定理(例如,如下面由等式1所定义)部署在环境位置205和/或监测感测位置207。
例如,多个声学传感器110的数量、多个声学传感器110之间的距离、监测传感器112的数量和/或监测传感器112之间的距离可以根据空间采样定理来确定,例如,如下面由等式1所定义。
在一个示例中,多个声学传感器110和/或多个监测传感器112可以相互以某一距离(用d表示)分布,例如相等地分布。例如,距离d可以如下确定:
其中c表示声速,并且f
例如,如果感兴趣的最大频率是f
在其他实施例中,可以使用任何其他距离和/或部署方案。
在一些示范性实施例中,如图2中所示,部署方案200可以相对于圆形或球形个人声音区220进行配置。例如,多个环境位置205可以在个人声音区220周围和外部以球形或圆形方式分布,例如大体上均匀分布,和/或监测感测位置207可以在个人声音区220内以球形或圆形方式分布,例如大体上均匀分布。
然而在其他实施例中,系统100的组件可以根据任何其他部署方案来部署,包括环境位置205和/或监测感测位置207的任何合适的分布,例如相对于任何其他合适形式和/或形状的个人声音区来配置。
在一些示范性实施例中,例如,多个监测传感器112和/或声学传感器110可以例如使用虚拟感测技术来定位,例如,以将监测传感器112和/或声学传感器110定位在可行的位置,例如,在头靠中、在汽车中被占用的座椅上方等,同时例如为用户202启用个人声音区220,而不需要将麦克风定位在用户的人耳中和/或用户的头部周围。
在一个示例中,虚拟传感器,例如虚拟麦克风、信号(表示为
例如,可以定义虚拟感测传递函数(表示为{h
例如,虚拟感测传递函数{h
例如,虚拟麦克风信号可以例如如下确定:
在一些示范性实施例中,控制器120可以被配置成控制个人声音区220内的声音的声学对比度,例如,如下文描述。
在一些示范性实施例中,控制器120可以被配置成创建个人声音区220与个人声音区220周围之间的声学对比度,例如,如下文描述。
在一个示例中,声学对比度可以在个人声音区220的音频输入(例如,音频输入117)和其他个人声音区的一个或多个其他音频输入之间,和/或在多个音频输入的子集到多个音频输入的互补子集之间。
在一些示范性实施例中,控制器120可以被配置成利用环境声学信息111来例如增加(例如,最大化)个人声音区220与个人声音区220周围之间的声学对比度,例如减小(例如,最小化)在环境215中(例如,在个人声音区220中)和/或在一个或多个其他个人声音区对音频质量的效应。
在一个示例中,环境声学信息111可以充当控制器120的参考信号。根据该示例,控制器120可以使用环境先验声学知识,例如,在音频输出模式122中修改一个或多个相关频率,这些频率可以被指定为由用户在个人声音区220听到。
在一些示范性实施例中,控制器120可以被配置成接收环境声学信息111和/或多个监测输入113,并且例如基于该个人声音区220的声学对比度向多个声换能器108输出声音控制信号122,例如,如下文描述。
在一个示例中,环境声学信息111和/或多个监测输入113可以由控制器120延迟可配置的延迟时间,例如,以允许足够的时间用于声音控制信号123的传输和处理。例如,延迟时间可以例如基于控制器120的一个或多个输入的性质。
在一些示范性实施例中,控制器120可以被配置成实现和/或支持优化方法,例如,以基于环境声学信息111来改进音频输出模式122的质量,例如,传输到个人声音区220的音频流,该环境声学信息可以表示环境噪声和/或可以能够例如实时地控制个人声音区220中的音频。
在一个示例中,控制器120可以被配置成利用环境声学信息111来考虑一个或多个频率,例如,仅听众在特定时间听到的频率,和/或任何其他频率。
在一些示范性实施例中,控制器120可以被配置成实现优化方法,以例如对音频质量提供减小的(例如,最小的)影响,同时例如提供个人声音体验,而不干扰不位于PSB 220中的其他用户。
在一些示范性实施例中,控制器可以被配置成利用环境声学信息111和/或多个监测输入113,例如,以改进个人声音区220处的音频,例如,对位于个人声音区220外部的其他区的干扰减小(例如,最小),这些其他区例如可以由多个监测传感器112定义。
在一些示范性实施例中,控制器120可以被配置成例如基于环境声学信息111来修改发送到音频换能器108的声音控制模式123,以例如在环境215处实现对周围声音具有减小的(例如,最小的)效应的本地声音气泡,例如PSB 220。
在一些示范性实施例中,控制器120可以被配置成支持优化方法,例如,以实现例如在个人声音区220的个人声音体验,甚至不会干扰不在个人声音区220中的其他人。
在一些示范性实施例中,控制器120可以被配置成单独地或联合地控制多个个人声音区的多个音频输入,例如,通过对多个个人声音区的每一区对一个个人声音区(例如,个人声音区220)执行一个或多个上述操作,例如,如下文描述。
在一个示例中,声音控制模式123的多个声音控制信号中的表示为“音频信号”的声音控制信号,例如用于声换能器108的声音控制信号,可以例如基于指定在个人声音区220中听到的音频输入117、来自声学传感器110的输入、来自监测传感器112的输入和/或基于个人声音区220中不需要的其他音频信号来确定。
例如,可以基于一个或多个音频输入117、环境声学信息111和/或多个监测输入113来确定声音控制信号,例如,如下:
Sound control signal’=f(environment mics(n),monitoring mics(n),Audiosignal
(5)
在一些示范性实施例中,PSB系统(例如,系统100)可以结合一个或多个其他系统,例如,以改进个人声音区220的音频质量。
在一些示范性实施例中,PSB系统100可以结合和/或可以实现主动噪声控制/消除(ANC)系统,该主动噪声控制/消除系统可以被配置成例如减少或消除例如在个人声音区220的不期望的噪声,例如,如下文描述。
在一个示例中,控制器120可以被配置成利用本文描述的个人声音控制技术与ANC技术的组合,例如,以基于音频输入117和一个或多个不想要的噪声信号的ANC的组合来控制PSB 220中的声音,例如,如下文描述。根据该示例,PSB系统的性能可以例如通过使用ANC来减少PSB中残留的不期望的声音而被改善,例如,源自其他PSB和/或其他噪声源的声音。例如,PSB 220的音频流可以用作ANC系统的输入,例如,作为参考输入,例如,以减少这些音频流例如在不需要这些流的区中的效应,例如,如下文描述。
在一个示例中,控制器120可以被配置成确定用于Q声音区210的声音控制模式123,例如包括个人声音区220和229。
在一些示范性实施例中,预定义数量的监测传感器(表示为Lq)被放置在声音区q内。
在一些示范性实施例中,监测传感器的总和可以包括所有个人声音区Q中的监测传感器Lq的总和,例如,
在一些示范性实施例中,对应于特定频率(表示为w)下的区q中麦克风感测位置的声压的向量(表示为Pq)可以例如如下定义:
在一些示范性实施例中,区q处声压的向量Pq可以基于权重向量集(表示为g
p
(7)
在一些示范性实施例中,权重向量集g
在一个示例中,权重向量集g
在一些示范性实施例中,控制器120可以被配置成最大化将听到音频输入的个人声音区b(“亮区”,例如,个人声音区220)与另一区d(“暗区”,例如,多个个人声音区201中的一个或多个其他个人声音区)之间的声能对比度。
在一个示例中,多个个人声音区Q中的个人声音区q可以被定义为亮区b,并且多个个人声音区Q中的剩余Q-1个声音区可以被定义为暗区d。
在另一示例中,暗区d可以包括环境215中的一个或多个其他区或区域,例如,内部区或外部区201。
在一些示范性实施例中,亮区处的能量(表示为E
在一些示范性实施例中,暗区处的能量(表示为E
在一些示范性实施例中,控制器120可以被配置成例如基于与第一声能E
在一些示范性实施例中,该准则可以包括例如基于在个人声音区q中听到音频输入的音量(表示为B
min
E
||g
(11)
其中,第一准则可以要求暗区中的声能Ed最小,第二准则可以要求亮区(例如,个人声音区220)中的声能E
在一些示范性实施例中,可以基于准则集(11)来定义目标函数,表示为L(g),例如,如下:
在一些示范性实施例中,控制器120可以被配置成例如通过确定最小化目标函数L(g)的最大特征向量来确定权重向量集g
在一些示范性实施例中,权重向量集g
在一些示范性实施例中,控制器120可以被配置成例如通过将来自对应于个人声音区q的权重向量集g
其中
在一些示范性实施例中,控制器120可以被配置成例如在将信号传输到扬声器m之前,将信号
现在参考图3,其示意性地示出根据一些示范性实施例的PSB控制器320。
在一个示例中,控制器120(图1)可以执行PSB控制器320(图3)的一个或多个操作、一个或多个功能性和/或角色。
在一些示范性实施例中,如图3中所示,PSB控制器320可以被实现为多输入多输出(MIMO)PSB控制器,以从多个环境传感器310接收多个环境输入311。
在一些示范性实施例中,如图3中所示,PSB控制器320可以从多个监测传感器312接收多个监测输入313。
在一些示范性实施例中,如图3中所示,PSB控制器320可以向多个声换能器308输出声音控制模式322。
参考图4A和图4B,其示意性示出根据一些示范性实施例的被部署以控制多个声音控制区中的声音的扩音器阵列400。
在一些示范性实施例中,扩音器阵列400可以被配置成将两个音频输入聚集到例如两个相应的个人声音区,例如,如下文描述。
例如,如图4A中所示,扩音器阵列400可以包括多个扩音器,这些扩音器可以被配置成向第一个人声音区404发送第一声音传输402,以及向第二个人声音区408发送第二声音传输406,例如,如上文所述。
例如,如图4B中所示,阵列400的多个扩音器可以被配置成向第一声音区414(例如,个人声音区)发送第一声音传输412;以及发送第二声音传输416用于例如第一声音区414周围环境中的第二声音区418,例如,如上文所述。
在其他实施例中,可以实现第一声音区和第二声音区的任何其他配置,和/或可以实现任何其他数量的多个声音区。
参考图5,其示意性地示出根据一些示范性实施例的PSB系统的部署方案500。
在一些示范性实施例中,PSB系统100(图1)可以在例如汽车和飞机等环境中实现,例如,其可以被配置用于两个人坐在两个座椅上,例如,如下文描述。
在一个示例中,部署方案500可以为两个座椅(例如,汽车的两个前排座椅)和/或任何其他数量的座位(例如,一排)和/或任何其他座椅来布置实现PSB系统。
在一些示范性实施例中,如图5中所示,PSB系统可以被配置成在第一用户的头部周围创建至少一个第一PSB 502,例如在第一用户的两个耳朵周围创建两个PSB,和/或在第二用户的头部周围创建至少一个第二PSB 508,例如在第二用户的两个耳朵周围创建两个PSB。
在一个示例中,控制器120(图1)可以被配置成控制扩音器阵列400(图4)以创建PSB 504和/或508。
在一些示范性实施例中,声音控制系统,例如PSB系统100(图1),可以被配置成实现和/或支持一个或多个PSB的各种部署方案,例如,如下文描述。
参考图6,其示意性地示出根据一些示范性实施例的PSB系统600的部署方案。例如,噪声控制系统100(图1)可以执行PSB系统600的一个或多个操作、一个或多个功能性和/或角色。
在一些示范性实施例中,PSB系统600可以被配置成为表示为“信号1”的音频信号创建PSB 602,例如,如下文描述。
在一些示范性实施例中,PSB系统600可以例如通过在PSB 602和一个或多个其他区域之间为音频信号1创建声学对比度来创建PSB 602,例如,如下文描述。
在一些示范性实施例中,PSB系统600可以被配置成在PSB 602内部的音频信号1的第一振幅(例如,高振幅)和PSB 602外部的音频信号1的第二振幅(例如,低振幅)之间创建高对比度。
参考图7,其示意性地示出根据一些示范性实施例的PSB系统700的部署方案。例如,噪声控制系统100(图1)可以执行PSB系统700的一个或多个操作、一个或多个功能性和/或角色。
在一些示范性实施例中,PSB系统700可以被配置成为表示为“信号1、2、3、4、……”的相应多个音频信号创建多个PSB,例如,如下文描述。
在一个示例中,PSB系统700可以使用多个PSB系统来实现。例如,PSB系统700可以包括多个PSB系统,以处理(例如,单独地和/或独立地)用于多个PSB的多个音频信号。
在另一示例中,PSB系统700可以被实现为联合实现和/或控制多个PSB中的两个或更多个PSB。
在一些示范性实施例中,PSB系统700可以被配置成例如通过在多个音频信号之间创建声学对比度来创建多个PSB,如下文描述。
在一些示范性实施例中,PSB系统700可以被配置成针对音频信号,例如针对多个音频信号中的每一信号,在对应于音频信号的相应PSB内部的音频信号的第一幅度(例如,高幅度)和相应PSB外部的音频信号的第二幅度(例如,低幅度)之间创建高对比度。
在一个示例中,PSB系统700可以被配置成例如通过重复PSB系统600(图6)的操作来为每一信号创建高对比度,例如为多个音频信号的每一信号。
例如,PSB系统700可以:例如通过在PSB 712内部的音频信号1的第一振幅(例如,高振幅)和PSB 712外部的信号1的第二振幅(例如,低振幅)之间创建高对比度,来为表示为“信号1”的第一音频信号创建表示为“PSB A”的第一PSB 712;例如通过在PSB 714内部的信号2的高振幅和PSB 714外部的音频信号2的低振幅之间创建高对比度,来为表示为“信号2”的第二音频信号创建表示为“PSB B”的第二PSB 714;例如通过在PSB 716内部的信号3的高振幅和PSB 716外部的音频信号3的低振幅之间创建高对比度,来为表示为“信号3”的第三音频信号创建表示为“PSB C”的第三PSB 716;和/或例如通过在PSB 718内部的信号4的高振幅和PSB 718外部的信号4的低振幅之间创建高对比度,来为表示为“信号4”的第四音频信号创建表示为“PSB D”的第四PSB 718。
参考图8,其示意性地示出根据一些示范性实施例的PSB系统800的部署方案。例如,噪声控制系统100(图1)可以执行PSB系统800的一个或多个操作、一个或多个功能性和/或角色。
在一些示范性实施例中,PSB系统800可以被配置成为表示为“信号1”的音频信号创建PSB。
在一些示范性实施例中,PSB系统800可以为音频信号7创建PSB,例如,通过在音频信号1和多个其他(不想要的)音频信号(表示为“信号2、3、4、……”)之间创建声学对比度,例如,如下文描述。
在一些示范性实施例中,PSB系统800可以被配置成例如通过在PSB 802内部创建信号1的第一振幅(例如,高振幅)、并在PSB 802内部创建多个其他音频信号的第二振幅(例如,低振幅),来为音频信号7创建高对比度。
参考图9,其示意性地示出根据一些示范性实施例的PSB系统900的部署方案。例如,声音控制系统100(图1)可以执行PSB系统900的一个或多个操作、一个或多个功能性和/或角色。
在一些示范性实施例中,PSB系统900可以被配置成为相应多个输入音频信号创建多个PSB,例如,如下文描述。
在一个示例中,PSB系统900可以使用多个PSB系统来实现。例如,PSB系统900可以包括多个PSB系统,以处理(例如,单独地和/或独立地)用于多个PSB的多个音频信号。
在另一示例中,PSB系统900可以被实现为联合实现和/或控制多个PSB中的两个或更多个PSB。
在一些示范性实施例中,PSB系统900可以被配置成在多个PSB的音频信号之间创建声学对比度,例如,如下文描述。
在一些示范性实施例中,PSB系统900可以被配置成例如通过在PSB内部创建PSB的专用音频信号的第一振幅(例如,高振幅)并在PSB内部创建PSB内部的多个音频信号的剩余音频信号的第二振幅(例如,低振幅),来为PSB的音频信号创建高对比度,例如,多个PSB中的每一PSB。
例如,PSB系统900可以:例如通过在PSB 912内部的在音频信号7的第一振幅(例如,高振幅)和信号2、3和/或4的第二振幅(例如,低振幅)之间创建高对比度,来为表示为“信号1”的第一音频信号创建表示为“PSB A”的第一PSB 912;例如通过在PSB914内部在信号2的高振幅和信号1、3和/或4的低振幅之间创建高对比度,来为表示为“信号2”的第二音频信号创建表示为“PSB B”的第二PSB 914;例如通过在PSB 916内部在信号3的高振幅和信号1、2和/或4的低振幅之间创建高对比度,来为表示为“信号3”的第三音频信号创建表示为“PSB C”的第三PSB 916;和/或例如通过在信号4的高振幅和信号1、2和/或3的低振幅之间创建高对比度,来为表示为“信号4”的第四音频信号创建表示为“PSB D”的第四PSB 918。
在一个示例中,PSB系统900可以被配置成例如通过重复PSB系统800(图8)的操作来为每一PSB创建高对比度,例如为多个PSB中的每一PSB。
参考图10,其示意性地示出根据一些示范性实施例的控制器1020。例如,控制器120(图1)可以包括、执行控制器1020的角色、执行控制器1020的功能性、执行控制器1020的角色和/或执行控制器1020的一个或多个操作。
在一些示范性实施例中,如图10中所示,控制器1020可以包括例如被实现为频率列表模块的频率选择器1050,以输出多个选定频率1052,例如,如下文描述。
在一些示范性实施例中,如图10中所示,控制器1020可以包括例如被实现为自适应扬声器传递函数(STF)模块的STF适配器1040,以输出多个声学传递函数1042,例如,如下文描述。
在一些示范性实施例中,如图10中所示,控制器1020可以包括例如被实现为输出模块的声音控制模式产生器1030,以处理多个权重向量集1023以及产生包括多个声音控制信号1032的声音控制模式给多个声换能器1008,例如,如下文描述。
在一些示范性实施例中,如图10中所示,多个声音控制信号1032可以基于权重向量1023和音频输入1017,例如,在例如通过对音频输入1017应用快速傅立叶变换(FFT)119而将音频输入转换到频域之后。
在一些示范性实施例中,如图10中所示,控制器1020可以基于多个选定频率1052和声学传递函数1042来确定权重向量1023,例如,如下文描述。
在一些示范性实施例中,如块1012和1014所指示,控制器1020可以迭代遍历多个选定频率1052上的频率W,例如,如下文描述。
在一些示范性实施例中,如块1016所指示,控制器1020可以例如基于来自STF适配器1040的多个声学传递函数来确定表示为Hd(W)的第一传递函数(例如,暗区传递函数)和/或表示为Hb(W)的第二传递函数(例如,亮区传递函数)。
在一个示例中,亮区传递函数可以包括多个声换能器1008和个人声音区q之间的声学传递函数,并且暗声传递函数可以包括多个声换能器1008和个人声音区q外部的一个或多个监测位置之间的声学传递函数,例如,如上文所述。
在一些示范性实施例中,如块1018所指示,控制器1020可以例如基于等式13来确定对应于个人声音区q的权重向量集,例如,如上文所述。
参考图11,其示意性地示出根据一些示范性实施例的频率选择器1150。例如,控制器120(图1)可以被配置成执行频率选择器1150的一个或多个操作或功能性。
在一些示范性实施例中,如图11中所示,频率选择器1150可以被配置成确定要包括在声音控制模式(例如,声音控制模式1032(图10)中的多个选定频率1112,例如多个选定频率1052(图10)。
在一些示范性实施例中,如图11中所示,频率选择器1150可以例如基于环境声学信息1111和音频输入1117来从频谱选择多个选定频率1112。
在一些示范性实施例中,如图11中所示,频率选择器1150可以基于投影音频1119和投影环境声音1113来确定多个选定频率,例如,如上文所述。
在一些示范性实施例中,如图11中所示,投影音频1119可以基于音频输入1117通过从多个换能器1008(图10)到个人声音区q的传递函数进行的投影1131,例如,如上文所述。
在一些示范性实施例中,如图11中所示,投影环境声音1113可以基于环境声学声音1111通过从多个预定义环境位置(例如,多个环境位置205(图1))到个人声音区q的传递函数进行的投影1133,例如,如上文所述。
在一些示范性实施例中,如图11中所示,频率选择器1150可以例如使用FFT 1115在频域中产生投影环境声音1113。
在一些示范性实施例中,如图11中所示,频率选择器1150可以例如使用FFT 1118在频域中产生投影音频1119。
在一些示范性实施例中,如块1124所指示,频率选择器1150可以例如基于特定频率的投影音频1119与特定频率的投影环境声音1113之间的差异是否大于预定义阈值,来确定该特定频率Wk是否将被包括在多个选定频率1112中。
在一些示范性实施例中,如块1126所指示,频率选择器1150可以例如基于当特定频率的投影音频1119与特定频率的投影环境声音1113之间的差异大于预定义阈值时,将该特定频率Wk添加到多个选定频率1112。
参考图12,其示意性地示出根据一些示范性实施例的STF适配器1240。例如,控制器120(图1)可以被配置成执行频率选择器STF适配器1240的一个或多个操作或功能性。
在一些示范性实施例中,如图12中所示,STF适配器1240可以被配置成处理由监测麦克风1210例如在监测感测位置所感测的声学声音1213,该监测感测位置可以被定义在个人声音区q内,例如,如上文所述。
在一些示范性实施例中,如图12中所示,STF适配器1240可以被配置成例如基于来自多个声换能器1008(图10)的音频输入1217,动态地调整多个声换能器1008(图10)和个人声音区q内的监测感测位置之间的声学传递函数1214。
在一些示范性实施例中,如图12中所示,STF适配器1240可以被配置成例如基于监测麦克风1210在监测感测位置所感测的声学声音1213与将确定的声学传递函数1214应用到音频输入1217的结果之间的比较,调适该声学传递函数1214,例如,如上文所述。
参考图13,其示意性地示出根据一些示范性实施例的声音控制模式产生器1330。例如,控制器120(图1)可以被配置成执行声音控制模式产生器1330的一个或多个操作或功能性。
在一些示范性实施例中,如图13中所示,声音控制模式产生器1330可以例如在FFT操作1319之后处理音频输入1317,并且可以产生多个声音控制信号1325的声音控制模式,该声音控制模式被提供来驱动相应的多个声换能器1308,例如,如下文描述。
例如,如图13中所示,声音控制模式产生器1330可以产生M个声音控制信号1325,以驱动相应多个M个声换能器1308,例如,换能器108(图1)。
在一些示范性实施例中,如块1321和1323所指示,声音控制模式产生器1330可以通过迭代遍历多个选定频率1052(图10)上的频率W而产生多个声音控制信号1325,例如,如下文描述。
在一些示范性实施例中,如图13中所示,声音控制模式产生器1330可以基于对应于用于个人声音区q的声换能器1308的多个权重向量1327,来产生多个声音控制信号1325,例如,如上文所述。
在一些示范性实施例中,用于个人区q的声换能器1308的权重向量1327可以基于例如声换能器1308与个人声音区q之间的声学传递函数,例如,如上文所述。
在一些示范性实施例中,如图13中所示,声音控制模式产生器1330可以通过将多个权重向量1327乘以特定频率w下的音频输入1317,来产生多个声音控制信号1325,例如,根据等式14,例如,如上文所述。
在一些示范性实施例中,如图13中所示,声音控制模式产生器1330可以对多个声音控制信号1325执行IFFT操作1329,例如,以将声音控制信号1325从频域转换到时域。
在一些示范性实施例中,如图13中所示,声音控制模式产生器1330可以例如向多个声换能器1308提供多个声音控制信号1325。
参考图14,其示意性地示出根据一些示范性实施例的车辆1400。
在一个示例中,车辆1440可以包括系统100(图1)的单独或多个元件和/或组件,例如,用于控制车辆1400内的一个或多个个人声音区内的声音。
在一些示范性实施例中,如图14中所示,车辆1400可以包括多个扬声器1408、多个监测麦克风1412和多个环境麦克风1410。
在一些示范性实施例中,车辆1400可以包括控制器120(图1),该控制器120被配置成控制多个扬声器1408以为车辆1400的驾驶员提供第一个人声音区1420,例如,在驾驶员座椅的头靠位置。
在一些示范性实施例中,控制器120(图1)可以被配置成控制多个扬声器1408以例如为乘客提供第二个人声音区1420,例如在驾驶员座椅附近的前排座椅,例如在乘客座椅的头靠位置。
在一些示范性实施例中,如图14中所示,多个监测麦克风1412可以位于第一个人声音区1420和第二个人声音区1430内。
在一些示范性实施例中,如图14中所示,多个环境麦克风1410可以位于个人声音区1420和1430外部的环境中。
在其他实施例中,车辆1400可以包括任何其他数量的多个扬声器1408、多个监测麦克风1412和/或多个环境麦克风1410、多个扬声器1408、多个监测麦克风1412和/或多个环境麦克风1410的任何其他布置、位置和/或定位、和/或任何其他附加或替代组件。
参考图15,其示意性地示出根据一些示范性实施例的包括ANC机制的控制器1520。例如,控制器120(图1)可以包括执行控制器1520的角色、执行控制器1520的功能性、执行控制器1520的角色和/或执行控制器1520的一个或多个操作。
在一些示范性实施例中,如图15中所示,控制器1520可以包括ANC控制器1560,其被配置成减少来自一个或多个个人声音区外部的残余噪声,例如,如下文描述。
在一些示范性实施例中,如图15中所示,控制器1520可以例如通过将ANC控制器1560的输出1566与声音控制模式产生器1430(例如,声音控制模式产生器1330(图13))的输出进行组合,来确定要提供给多个声换能器1508的声音控制模式1523。
在一些示范性实施例中,如图5中所示,ANC控制器1560可以例如基于一个或多个音频输入1517以及基于一个或多个ANC声学传感器输入1562来产生输出1566。
在一些示范性实施例中,来自个人声音区的ANC声学传感器输入1562可以来自个人声音区外部的一个或多个感测位置。例如,一个或多个ANC声学传感器输入1562可以来自个人声音区周围的一个或多个位置,例如在个人声音区的周边和/或附近。在另一示例中,一个或多个ANC声学传感器输入1562可以来自一个或多个其他个人声音区和/或环境中的任何其他位置。
在一些示范性实施例中,控制器1520可以被配置成将ANC控制器1560的输出1566的一个或多个输出(例如,所有输出)和声音控制模式1523的多个声音控制信号中的一个或多个(例如,所有)求和。
在一个示例中,车辆(例如,车辆1440(图14))中左座椅的左座椅头靠扬声器可以用于左座椅PSB,以及用于ANC,例如,以减少传输到车辆中右座椅的右座椅头靠扬声器的音频,例如,以实现右座椅的PSB,和/或反之亦然,例如,相对于左座椅PSB。
在一些示范性实施例中,将主动噪声控制技术与PSB技术合并在一起可以提高PSB性能,例如,通过使用ANC控制器1560来减少个人声音气泡中残留的不希望的声音,这些声音可能源自例如其他个人声音气泡。
在一些示范性实施例中,音频流1517的音频流可以被发送到ANC控制器1560,例如作为对ANC控制器1560的参考,可以在不需要这些流的区中被减少。
参考图16,其示意性地示出根据一些示范性实施例的声音控制的方法。例如,图16的方法的一个或多个操作可以由声音控制系统(例如,声音控制系统100(图1))的一个或多个元件、声音控制器(例如,声音控制器102(图1))和/或控制器(例如,控制器120(图1)和/或声音控制系统的任何其他组件来执行。
如块1602所指示,方法可以包括接收要在一个或多个个人声音区中听到的一个或多个音频输入和多个监测输入,其中多个监测输入表示在一个或多个个人声音区内定义的多个预定义监测感测位置处的声学声音。例如,控制器120(图1)可以接收要在一个或多个个人声音区中听到的一个或多个音频输入117(图1),以及表示在多个预定义的监测感测位置207(图2)处的声学声音的多个监测输入113,这些位置207可以被定义在一个或多个个人声音区内,例如,如上文所述。
如块1604所指示,方法可以包括基于一个或多个音频输入和多个监测输入来确定声音控制模式,该声音控制模式包括被配置成驱动相应多个声换能器的多个声音控制信号,使得将在一个或多个个人声音区中听到一个或多个音频输入。例如,控制器120(图1)可以基于一个或多个音频输入117(图1)和多个监测输入113(图1)来确定声音控制模式123(图1),该声音控制模式123(图1)包括被配置成驱动相应多个声换能器108(图1)的多个声音控制信号,使得将在一个或多个个人声音区中听到一个或多个音频输入117(图1),例如,如上文所述。
如块1608所指示,方法可以包括向多个声换能器输出多个声音控制信号。例如,控制器120(图1)可以向多个声换能器108(图1)输出多个声音控制信号,例如,如上文所述。
参考图17,其示意性地示出根据一些示范性实施例的制造产品1700。产品1700可以包括一个或多个有形计算机可读非暂时性存储介质1702,其可以包括例如由逻辑1704实现的计算机可执行指令,这些指令在由至少一个计算机处理器执行时,可操作以使至少一个计算机处理器能够在声音控制系统100(图1)和/或控制器120(图1)处实现一个或多个操作,和/或根据图1-16执行、触发和/或实现根据一个或多个图1-16的一个或多个操作、通信和/或功能性,和/或本文描述的一个或多个操作。短语“非暂时性机器可读介质”旨在包括所有计算机可读介质,唯一的例外是暂时性传播信号。
在一些示范性实施例中,产品1700和/或机器可读存储介质1702可以包括能够存储数据的一个或多个类型的计算机可读存储介质,包括易失性存储器、非易失性存储器、可移除或不可移除存储器、可擦除或不可擦除存储器、可写或可重写存储器等。例如,机器可读存储介质1702可以包括:RAM、DRAM、双倍数据速率DRAM(DDR-DRAM)、SDRAM、静态RAM(SRAM)、ROM、可编程ROM(PROM)、可擦除可编程ROM(EPROM)、电可擦除可编程ROM(EEPROM)、紧密光盘ROM(CD-ROM)、可刻录光盘(CD-R)、可重写光盘(CD-RW)、快闪存储器(例如,NOR或NAND快闪存储器)、内容可寻址存储器(CAM)、聚合物存储器、相变存储器、铁电存储器、氧化硅-氮化物-氧化硅(SONOS)存储器、磁盘、固态驱动器(SSD)、软盘、硬盘驱动器、光盘、磁盘、卡、磁卡、光卡、磁带、盒式录音带等。计算机可读存储介质可以包括涉及通过通信链路(例如,调制解调器、无线电或网络连接)将计算机程序从远程计算机下载或传送到请求计算机的任何合适的介质,该计算机程序由体现在载波或其他传播介质中的数据信号承载。
在一些示范性实施例中,逻辑1704可以包括指令、数据和/或代码,如果由机器执行,这些指令、数据和/或代码可以使机器执行如本文描述的方法、过程和/或操作。机器可以包括例如任何合适的处理平台、计算平台、计算设备、处理设备、计算系统、处理系统、计算机、处理器等,并且可以使用硬件、软件、固件等的任何合适组合来实现。
在一些示范性实施例中,逻辑1704可以包括或可以被实现为软件、软件模块、应用程序、程序、子例程、指令、指令集、计算代码、字、值、符号等。指令可以包括任何合适类型的代码,诸如源代码、编译代码、解释代码、可执行代码、静态代码、动态代码等。这些指令可以根据预定义的计算机语言、方式或语法来实现,用于指示处理器执行特定功能。这些指令可以使用任何合适的高级、低级、面向对象、可视化、编译和/或解释的编程语言来实现,诸如C、C++、Python、Java、BASIC、Matlab、Pascal、Visual BASIC、汇编语言、机器代码等。
示例
以下示例属于进一步的实施例。
示例1包括一种装置,包含:输入,其用以接收要在一个或多个个人声音区中听到的一个或多个音频输入和多个监测输入,其中多个监测输入表示在多个预定义监测感测位置的声学声音,该多个预定义监测感测位置被定义在一个或多个个人声音区内;控制器,其被配置成基于一个或多个音频输入和多个监测输入来确定声音控制模式,该声音控制模式包含被配置成驱动相应多个声换能器的多个声音控制信号,使得将在一个或多个个人声音区中听到一个或多个音频输入;以及输出,其用以向多个声换能器输出多个声音控制信号。
示例2包括示例1的主题,且任选地,其中该输入被配置成接收表示在多个预定义环境位置处的环境声学声音的环境声学信息,该多个预定义环境位置是相对于包括一个或多个个人声音区的环境而定义的,该控制器被配置成基于环境声音信息来确定声音控制模式。
示例3包括示例2的主题,且任选地,其中环境声学信息包含由声学传感器在多个预定义环境位置中的环境位置处感测的声学声音的信息。
示例4包括示例2或3的主题,且任选地,其中环境声学信息包含音频信号或预定义音频源所产生的声学声音中的至少一个的信息。
示例5包括示例2-4中的任一个的主题,且任选地,其中控制器被配置成确定要被包括在声音控制模式中的多个选定频率,该控制器被配置成基于环境声学信息和一个或多个音频输入来从频谱中选择多个选定频率。
示例6包括示例5的主题,且任选地,其中控制器被配置成基于投影音频和投影环境声音来确定多个选定频率,该投影音频是基于将在个人声音区听到的音频输入通过从多个换能器到个人声音区的传递函数进行的投影,该投影环境声音是基于环境声学声音通过从多个预定义环境位置到个人声音区的传递函数进行的投影。
示例7包括示例6的主题,且任选地,其中控制器被配置成基于特定频率的投影音频和特定频率的投影环境声音来确定该特定频率是否将被包括在多个选定频率中。
示例8包括示例7的主题,且任选地,其中控制器被配置成当特定频率的投影音频与特定频率的投影环境声音之间的差异大于预定义阈值时确定该特定频率将被包括在多个选定频率中。
示例9包括示例1-8中的任一个的主题,且任选地,其中控制器被配置成基于分别对应于一个或多个个人声音区的一个或多个权重向量集来确定多个声音控制信号,对应于个人声音区的权重向量集包含分别对应于多个声换能器的多个权重向量,权重向量集中的权重向量是基于多个声换能器中的声换能器与个人声音区之间的声学传递函数。
示例10包括示例9的主题,且任选地,其中控制器被配置成通过将来自对应于个人声音区的权重向量集的对应于特定声换能器的权重向量应用于将在个人声音区中听到的音频输入来确定特定声换能器的声音控制信号。
示例11包括示例9或10的主题,且任选地,其中控制器被配置成基于第一多个声学传递函数和第二多个声学传递函数来确定对应于个人声音区的权重向量集,第一多个声学传递函数包含多个声换能器与个人声音区之间的声学传递函数,第二多个声学传递函数包含多个声换能器与个人声音区外部的一个或多个监测位置之间的声学传递函数。
示例12包括示例11的主题,且任选地,其中控制器被配置成基于环境声学信息来调整第一或第二多个声学传递函数中的一个或多个声学传递函数,该环境声学信息表示多个预定义环境位置处的环境声学声音,该多个预定义环境位置是相对于包括一个或多个个人声音区的环境来定义的。
示例13包括示例11或12的主题,且任选地,其中控制器被配置成基于个人声音区的位置变化来调整第一或第二多个声学传递函数中的一个或多个声学传递函数。
示例14包括示例11-13中的任一个的主题,且任选地,其中控制器被配置成基于包括一个或多个个人声音区的环境的一个或多个环境参数的环境参数信息来调整第一或第二多个声学传递函数中的一个或多个声学传递函数。
示例15包括示例9-14中的任一个的主题,且任选地,其中控制器被配置成基于与第一声能和第二声能之间的对比度相关的准则来确定对应于个人声音区的权重向量集,其中第一声能包含基于对应于个人声音区的权重向量集的在个人声音区的声能,其中第二声能包含基于对应于个人声音区的权重向量集的在个人声音区外部的一个或多个监测位置的声能。
示例16包括示例15的主题,且任选地,其中该准则包含基于在个人声音区中要听到音频输入的音量来限制第一能量,并且最小化第二能量。
示例17包括示例9-16中的任一个的主题,且任选地,其中权重向量包含对应于相应多个声频的多个权重。
示例18包括示例1-17中的任一个的主题,且任选地,其中控制器被配置成至少基于第一和第二音频输入来确定声音控制模式,第一音频输入用于第一个人声音区,第二音频输入用于第二个人声音区,其中控制器被配置成基于表示在第一多个监测感测位置处的声学声音的第一多个监测输入和表示在第二多个监测感测位置处的声学声音的第二多个监测输入来确定声音控制模式,该第一多个监测感测位置被定义在第一个人声音区内,该第二多个监测感测位置被定义在第二个人声音区内。
示例19包括示例1-18中的任一个的主题,且任选地,其中控制器被配置成基于主动噪声消除(ANC)机制来确定声音控制模式,该ANC机制被配置成基于一个或多个音频输入和基于一个或多个ANC声学传感器输入来减少来自一个或多个个人声音区外部的残余噪声。
示例20包括一种声音控制的系统,该系统包含:多个监测声学传感器,其用以感测多个预定义监测感测位置处的声学声音,这些预定义监测感测位置被定义在一个或多个个人声音区内;多个声换能器;以及控制器,其用以接收要在一个或多个个人声音区中听到的一个或多个音频输入和来自多个监测声学传感器的多个监测输入,其中多个监测输入表示在多个预定义监测感测位置的声学声音,其中控制器被配置成基于一个或多个音频输入和多个监测输入来确定声音控制模式,该声音控制模式包含被配置成分别驱动多个声换能器的多个声音控制信号,使得将在一个或多个个人声音区中听到一个或多个音频输入。
示例21包括示例20的主题,且任选地,其中该控制器被配置成接收表示在多个预定义环境位置处的环境声学声音的环境声学信息,该多个预定义环境位置是相对于包括一个或多个个人声音区的环境而定义的,该控制器被配置成基于环境声音信息来确定声音控制模式。
示例22包括示例21的主题,且任选地,其中环境声学信息包含由声学传感器在多个预定义环境位置中的环境位置处感测的声学声音的信息。
示例23包括示例21或22的主题,且任选地,其中环境声学信息包含音频信号或预定义音频源所产生的声学声音中的至少一个的信息。
示例24包括示例21-23中的任一个的主题,且任选地,其中控制器被配置成确定要被包括在声音控制模式中的多个选定频率,该控制器被配置成基于环境声学信息和一个或多个音频输入来从频谱选择多个选定频率。
示例25包括示例24的主题,且任选地,其中控制器被配置成基于投影音频和投影环境声音来确定多个选定频率,该投影音频是基于将在个人声音区听到的音频输入通过从多个换能器到个人声音区的传递函数进行的投影,该投影环境声音是基于环境声学声音通过从多个预定义环境位置到个人声音区的传递函数进行的投影。
示例26包括示例25的主题,且任选地,其中控制器被配置成基于特定频率的投影音频和特定频率的投影环境声音来确定该特定频率是否将被包括在多个选定频率中。
示例27包括示例26的主题,且任选地,其中控制器被配置成当特定频率的投影音频与特定频率的投影环境声音之间的差异大于预定义阈值时确定该特定频率将被包括在多个选定频率中。
示例28包括示例20-27中的任一个的主题,且任选地,其中控制器被配置成基于分别对应于一个或多个个人声音区的一个或多个权重向量集来确定多个声音控制信号,对应于个人声音区的权重向量集包含分别对应于多个声换能器的多个权重向量,权重向量集中的权重向量是基于多个声换能器中的声换能器与个人声音区之间的声学传递函数。
示例29包括示例28的主题,且任选地,其中控制器被配置成通过将来自对应于个人声音区的权重向量集的对应于特定声换能器的权重向量应用于将在个人声音区中听到的音频输入来确定特定声换能器的声音控制信号。
示例30包括示例28或29的主题,且任选地,其中控制器被配置成基于第一多个声学传递函数和第二多个声学传递函数来确定对应于个人声音区的权重向量集,第一多个声学传递函数包含多个声换能器与个人声音区之间的声学传递函数,第二多个声学传递函数包含多个声换能器与个人声音区外部的一个或多个监测位置之间的声学传递函数。
示例31包括示例30的主题,且任选地,其中控制器被配置成基于环境声学信息来调整第一或第二多个声学传递函数中的一个或多个声学传递函数,该环境声学信息表示多个预定义环境位置处的环境声学声音,该多个预定义环境位置是相对于包括一个或多个个人声音区的环境来定义的。
示例32包括示例30或31的主题,且任选地,其中控制器被配置成基于个人声音区的位置变化来调整第一或第二多个声学传递函数中的一个或多个声学传递函数。
示例33包括示例30-32中的任一个的主题,且任选地,其中控制器被配置成基于包括一个或多个个人声音区的环境的一个或多个环境参数的环境参数信息来调整第一或第二多个声学传递函数中的一个或多个声学传递函数。
示例34包括示例28-33中的任一个的主题,且任选地,其中控制器被配置成基于与第一声能和第二声能之间的对比度相关的准则来确定对应于个人声音区的权重向量集,其中第一声能包含基于对应于个人声音区的权重向量集的在个人声音区的声能,其中第二声能包含基于对应于个人声音区的权重向量集的在个人声音区外部的一个或多个监测位置的声能。
示例35包括示例34的主题,且任选地,其中该准则包含基于在个人声音区中要听到音频输入的音量来限制第一能量,并且最小化第二能量。
示例36包括示例28-35中的任一个的主题,且任选地,其中权重向量包含对应于相应多个声频的多个权重。
示例37包括示例20-36中的任一个的主题,且任选地,其中控制器被配置成至少基于第一和第二音频输入来确定声音控制模式,第一音频输入用于第一个人声音区,第二音频输入用于第二个人声音区,其中控制器被配置成基于表示在第一多个监测感测位置处的声学声音的第一多个监测输入和表示在第二多个监测感测位置处的声学声音的第二多个监测输入来确定声音控制模式,该第一多个监测感测位置被定义在第一个人声音区内,该第二多个监测感测位置被定义在第二个人声音区内。
示例38包括示例20-37中的任一个的主题,且任选地,其中控制器被配置成基于主动噪声消除(ANC)机制来确定声音控制模式,该ANC机制被配置成基于一个或多个音频输入和基于一个或多个ANC声学传感器输入来减少来自一个或多个个人声音区外部的残余噪声。
示例39包括一种车辆,包含:一个或多个座椅;以及声音控制系统,其被配置成控制相对于一个或多个座椅定义的一个或多个个人声音区内的声音,该声音控制系统包含多个监测声学传感器以感测在多个预定义监测感测位置的声学声音,该多个预定义监测感测位置被定义在一个或多个个人声音区内;多个声换能器;以及控制器,其用以接收要在一个或多个个人声音区中听到的一个或多个音频输入和来自多个监测声学传感器的多个监测输入,其中多个监测输入表示在多个预定义监测感测位置的声学声音,其中该控制器被配置成基于一个或多个音频输入和多个监测输入来确定声音控制模式,该声音控制模式包含被配置成分别驱动多个声换能器的多个声音控制信号,使得将在一个或多个个人声音区中听到一个或多个音频输入。
示例40包括示例39的主题,且任选地,其中该控制器被配置成接收表示在多个预定义环境位置处的环境声学声音的环境声学信息,该多个预定义环境位置是相对于包括一个或多个个人声音区的环境而定义的,该控制器被配置成基于环境声音信息来确定声音控制模式。
示例41包括示例40的主题,且任选地,其中环境声学信息包含由声学传感器在多个预定义环境位置中的环境位置处感测的声学声音的信息。
示例42包括示例40或41的主题,且任选地,其中环境声学信息包含音频信号或预定义音频源所产生的声学声音中的至少一个的信息。
示例43包括示例40-42中的任一个的主题,且任选地,其中控制器被配置成确定要被包括在声音控制模式中的多个选定频率,该控制器被配置成基于环境声学信息和一个或多个音频输入来从频谱选择多个选定频率。
示例44包括示例43的主题,且任选地,其中控制器被配置成基于投影音频和投影环境声音来确定多个选定频率,该投影音频是基于将在个人声音区听到的音频输入通过从多个换能器到个人声音区的传递函数进行的投影,该投影环境声音是基于环境声学声音通过从多个预定义环境位置到个人声音区的传递函数进行的投影。
示例45包括示例44的主题,且任选地,其中控制器被配置成基于特定频率的投影音频和特定频率的投影环境声音来确定该特定频率是否将被包括在多个选定频率中。
示例46包括示例45的主题,且任选地,其中控制器被配置成当特定频率的投影音频与特定频率的投影环境声音之间的差异大于预定义阈值时确定该特定频率将被包括在多个选定频率中。
示例47包括示例39-46中的任一个的主题,且任选地,其中控制器被配置成基于分别对应于一个或多个个人声音区的一个或多个权重向量集来确定多个声音控制信号,对应于个人声音区的权重向量集包含分别对应于多个声换能器的多个权重向量,权重向量集中的权重向量是基于多个声换能器中的声换能器与个人声音区之间的声学传递函数。
示例48包括示例47的主题,且任选地,其中控制器被配置成通过将来自对应于个人声音区的权重向量集的对应于特定声换能器的权重向量应用于将在个人声音区中听到的音频输入来确定特定声换能器的声音控制信号。
示例49包括示例47或48的主题,且任选地,其中控制器被配置成基于第一多个声学传递函数和第二多个声学传递函数来确定对应于个人声音区的权重向量集,第一多个声学传递函数包含多个声换能器与个人声音区之间的声学传递函数,第二多个声学传递函数包含多个声换能器与个人声音区外部的一个或多个监测位置之间的声学传递函数。
示例50包括示例49的主题,且任选地,其中控制器被配置成基于环境声学信息来调整第一或第二多个声学传递函数中的一个或多个声学传递函数,该环境声学信息表示多个预定义环境位置处的环境声学声音,该多个预定义环境位置是相对于包括一个或多个个人声音区的环境来定义的。
示例51包括示例49或50的主题,且任选地,其中控制器被配置成基于个人声音区的位置变化来调整第一或第二多个声学传递函数中的一个或多个声学传递函数。
示例52包括示例49-51中的任一个的主题,且任选地,其中控制器被配置成基于包括一个或多个个人声音区的环境的一个或多个环境参数的环境参数信息来调整第一或第二多个声学传递函数中的一个或多个声学传递函数。
示例53包括示例47-52中的任一个的主题,且任选地,其中控制器被配置成基于与第一声能和第二声能之间的对比度相关的准则来确定对应于个人声音区的权重向量集,其中第一声能包含基于对应于个人声音区的权重向量集的在个人声音区的声能,其中第二声能包含基于对应于个人声音区的权重向量集的在个人声音区外部的一个或多个监测位置的声能。
示例54包括示例53的主题,且任选地,其中该准则包含基于在个人声音区中要听到音频输入的音量来限制第一能量,并且最小化第二能量。
示例55包括示例47-54中的任一个的主题,且任选地,其中权重向量包含对应于相应多个声频的多个权重。
示例56包括示例39-55中的任一个的主题,且任选地,其中控制器被配置成至少基于第一和第二音频输入来确定声音控制模式,第一音频输入用于第一个人声音区,第二音频输入用于第二个人声音区,其中控制器被配置成基于表示在第一多个监测感测位置处的声学声音的第一多个监测输入和表示在第二多个监测感测位置处的声学声音的第二多个监测输入来确定声音控制模式,该第一多个监测感测位置被定义在第一个人声音区内,该第二多个监测感测位置被定义在第二个人声音区内。
示例57包括示例39-56中的任一个的主题,且任选地,其中控制器被配置成基于主动噪声消除(ANC)机制来确定声音控制模式,该ANC机制被配置成基于一个或多个音频输入和基于一个或多个ANC声学传感器输入来减少来自一个或多个个人声音区外部的残余噪声。
示例58包括一种声音控制方法,该方法包含:处理要在一个或多个个人声音区中听到的一个或多个音频输入和多个监测输入,其中多个监测输入表示在多个预定义监测感测位置的声学声音,该多个预定义监测感测位置被定义在一个或多个个人声音区内;基于一个或多个音频输入和多个监测输入来确定声音控制模式,该声音控制模式包含被配置成驱动相应多个声换能器的多个声音控制信号,使得将在一个或多个个人声音区中听到一个或多个音频输入;以及向多个声换能器输出多个声音控制信号。
示例59包括示例58的主题,且任选地,包含接收表示在多个预定义环境位置处的环境声学声音的环境声学信息,该多个预定义环境位置是相对于包括一个或多个个人声音区的环境而定义的,以及基于环境声音信息来确定声音控制模式。
示例60包括示例59的主题,且任选地,其中环境声学信息包含由声学传感器在多个预定义环境位置中的环境位置处感测的声学声音的信息。
示例61包括示例59或60的主题,且任选地,其中环境声学信息包含音频信号或预定义音频源所产生的声学声音中的至少一个的信息。
示例62包括示例59-61中的任一个的主题,且任选地,包含确定要被包括在声音控制模式中的多个选定频率,以及基于环境声学信息和一个或多个音频输入来从频谱选择多个选定频率。
示例63包括示例62的主题,且任选地,包含基于投影音频和投影环境声音来确定多个选定频率,该投影音频是基于将在个人声音区听到的音频输入通过从多个换能器到个人声音区的传递函数进行的投影,该投影环境声音是基于环境声学声音通过从多个预定义环境位置到个人声音区的传递函数进行的投影。
示例64包括示例63的主题,且任选地,包含基于特定频率的投影音频和特定频率的投影环境声音来确定该特定频率是否将被包括在多个选定频率中。
示例65包括示例64的主题,且任选地,包含当特定频率的投影音频与特定频率的投影环境声音之间的差异大于预定义阈值时确定该特定频率将被包括在多个选定频率中。
示例66包括示例58-65中的任一个的主题,且任选地,包含基于分别对应于一个或多个个人声音区的一个或多个权重向量集来确定多个声音控制信号,对应于个人声音区的权重向量集包含分别对应于多个声换能器的多个权重向量,权重向量集中的权重向量是基于多个声换能器中的声换能器与个人声音区之间的声学传递函数。
示例67包括示例66的主题,且任选地,包含通过将来自对应于个人声音区的权重向量集的对应于特定声换能器的权重向量应用于将在个人声音区中听到的音频输入来确定特定声换能器的声音控制信号。
示例68包括示例66或67的主题,且任选地,包含基于第一多个声学传递函数和第二多个声学传递函数来确定对应于个人声音区的权重向量集,第一多个声学传递函数包含多个声换能器与个人声音区之间的声学传递函数,第二多个声学传递函数包含多个声换能器与个人声音区外部的一个或多个监测位置之间的声学传递函数。
示例69包括示例68的主题,且任选地,包含基于环境声学信息来调整第一或第二多个声学传递函数中的一个或多个声学传递函数,该环境声学信息表示多个预定义环境位置处的环境声学声音,该多个预定义环境位置是相对于包括一个或多个个人声音区的环境来定义的。
示例70包括示例68或69的主题,且任选地,包含基于个人声音区的位置变化来调整第一或第二多个声学传递函数中的一个或多个声学传递函数。
示例71包括示例68-70中的任一个的主题,且任选地,包含基于包括一个或多个个人声音区的环境的一个或多个环境参数的环境参数信息来调整第一或第二多个声学传递函数中的一个或多个声学传递函数。
示例72包括示例66-71中的任一个的主题,且任选地,包含基于与第一声能和第二声能之间的对比度相关的准则来确定对应于个人声音区的权重向量集,其中第一声能包含基于对应于个人声音区的权重向量集的在个人声音区的声能,其中第二声能包含基于对应于个人声音区的权重向量集的在个人声音区外部的一个或多个监测位置的声能。
示例73包括示例72的主题,且任选地,其中该准则包含基于在个人声音区中要听到音频输入的音量来限制第一能量,并且最小化第二能量。
示例74包括示例66-73中的任一个的主题,且任选地,其中权重向量包含对应于相应多个声频的多个权重。
示例75包括示例58-74中的任一个的主题,且任选地,包含至少基于第一和第二音频输入来确定声音控制模式,第一音频输入用于第一个人声音区,第二音频输入用于第二个人声音区,以及基于表示在第一多个监测感测位置处的声学声音的第一多个监测输入和表示在第二多个监测感测位置处的声学声音的第二多个监测输入来确定声音控制模式,该第一多个监测感测位置被定义在第一个人声音区内,该第二多个监测感测位置被定义在第二个人声音区内。
示例76包括示例58-75中的任一个的主题,且任选地,包含基于主动噪声消除(ANC)机制来确定声音控制模式,该ANC机制被配置成基于一个或多个音频输入和基于一个或多个ANC声学传感器输入来减少来自一个或多个个人声音区外部的残余噪声。
示例77包括一种包含一个或多个有形计算机可读非暂时性存储介质的产品,该一个或多个有形计算机可读非暂时性存储介质包含计算机可执行指令,该指令在由至少一个处理器执行时可操作以使至少一个处理器能够致使声音控制系统:处理要在一个或多个个人声音区中听到的一个或多个音频输入和多个监测输入,其中多个监测输入表示在多个预定义监测感测位置的声学声音,该多个预定义监测感测位置被定义在一个或多个个人声音区内;基于一个或多个音频输入和多个监测输入来确定声音控制模式,该声音控制模式包含被配置成驱动相应多个声换能器的多个声音控制信号,使得将在一个或多个个人声音区中听到一个或多个音频输入;以及向多个声换能器输出多个声音控制信号。
示例78包括示例77的主题,且任选地,其中该指令在被执行时致使声音控制系统接收表示在多个预定义环境位置处的环境声学声音的环境声学信息,该多个预定义环境位置是相对于包括一个或多个个人声音区的环境而定义的,以及基于环境声音信息来确定声音控制模式。
示例79包括示例78的主题,且任选地,其中环境声学信息包含由声学传感器在多个预定义环境位置中的环境位置处感测的声学声音的信息。
示例80包括示例78或79的主题,且任选地,其中环境声学信息包含音频信号或预定义音频源所产生的声学声音中的至少一个的信息。
示例81包括示例78-80中的任一个的主题,且任选地,其中该指令在被执行时致使声音控制系统确定要被包括在声音控制模式中的多个选定频率,以及基于环境声学信息和一个或多个音频输入来从频谱选择多个选定频率。
示例82包括示例81的主题,且任选地,其中该指令在被执行时致使声音控制系统基于投影音频和投影环境声音来确定多个选定频率,该投影音频是基于将在个人声音区听到的音频输入通过从多个换能器到个人声音区的传递函数进行的投影,该投影环境声音是基于环境声学声音通过从多个预定义环境位置到个人声音区的传递函数进行的投影。
示例83包括示例82的主题,且任选地,其中该指令在被执行时致使声音控制系统基于特定频率的投影音频和特定频率的投影环境声音来确定该特定频率是否将被包括在多个选定频率中。
示例84包括示例83的主题,且任选地,其中该指令在被执行时致使声音控制系统当特定频率的投影音频与特定频率的投影环境声音之间的差异大于预定义阈值时确定该特定频率将被包括在多个选定频率中。
示例85包括示例77-84中的任一个的主题,且任选地,其中该指令在被执行时致使声音控制系统基于分别对应于一个或多个个人声音区的一个或多个权重向量集来确定多个声音控制信号,对应于个人声音区的权重向量集包含分别对应于多个声换能器的多个权重向量,权重向量集中的权重向量是基于多个声换能器中的声换能器与个人声音区之间的声学传递函数。
示例86包括示例85的主题,且任选地,其中该指令在被执行时致使声音控制系统通过将来自对应于个人声音区的权重向量集的对应于特定声换能器的权重向量应用于将在个人声音区中听到的音频输入来确定特定声换能器的声音控制信号。
示例87包括示例85或86的主题,且任选地,其中该指令在被执行时致使声音控制系统基于第一多个声学传递函数和第二多个声学传递函数来确定对应于个人声音区的权重向量集,第一多个声学传递函数包含多个声换能器与个人声音区之间的声学传递函数,第二多个声学传递函数包含多个声换能器与个人声音区外部的一个或多个监测位置之间的声学传递函数。
示例88包括示例87的主题,且任选地,其中该指令在被执行时致使声音控制系统基于环境声学信息来调整第一或第二多个声学传递函数中的一个或多个声学传递函数,该环境声学信息表示多个预定义环境位置处的环境声学声音,该多个预定义环境位置是相对于包括一个或多个个人声音区的环境来定义的。
示例89包括示例87或88的主题,且任选地,其中该指令在被执行时致使声音控制系统基于个人声音区的位置变化来调整第一或第二多个声学传递函数中的一个或多个声学传递函数。
示例90包括示例87-89中的任一个的主题,且任选地,其中该指令在被执行时致使声音控制系统基于包括一个或多个个人声音区的环境的一个或多个环境参数的环境参数信息来调整第一或第二多个声学传递函数中的一个或多个声学传递函数。
示例91包括示例85-90中的任一个的主题,且任选地,其中该指令在被执行时致使声音控制系统基于与第一声能和第二声能之间的对比度相关的准则来确定对应于个人声音区的权重向量集,其中第一声能包含基于对应于个人声音区的权重向量集的在个人声音区的声能,其中第二声能包含基于对应于个人声音区的权重向量集的在个人声音区外部的一个或多个监测位置的声能。
示例92包括示例91的主题,且任选地,其中该准则包含基于在个人声音区中要听到音频输入的音量来限制第一能量,并且最小化第二能量。
示例93包括示例85-92中的任一个的主题,且任选地,其中权重向量包含对应于相应多个声频的多个权重。
示例94包括示例77-93中的任一个的主题,且任选地,其中该指令在被执行时致使声音控制系统至少基于第一和第二音频输入来确定声音控制模式,第一音频输入用于第一个人声音区,第二音频输入用于第二个人声音区,以及基于表示在第一多个监测感测位置处的声学声音的第一多个监测输入和表示在第二多个监测感测位置处的声学声音的第二多个监测输入来确定声音控制模式,该第一多个监测感测位置被定义在第一个人声音区内,该第二多个监测感测位置被定义在第二个人声音区内。
示例95包括示例77-94中的任一个的主题,且任选地,其中该指令在被执行时致使声音控制系统基于主动噪声消除(ANC)机制来确定声音控制模式,该ANC机制被配置成基于一个或多个音频输入和基于一个或多个ANC声学传感器输入来减少来自一个或多个个人声音区外部的残余噪声。
示例96包括一种声音控制装置,该装置包含:用于处理要在一个或多个个人声音区中听到的一个或多个音频输入和多个监测输入的部件,其中多个监测输入表示在多个预定义监测感测位置的声学声音,该多个预定义监测感测位置被定义在一个或多个个人声音区内;用于基于一个或多个音频输入和多个监测输入来确定声音控制模式的部件,该声音控制模式包含被配置成驱动相应多个声换能器的多个声音控制信号,使得将在一个或多个个人声音区中听到一个或多个音频输入;以及用于向多个声换能器输出多个声音控制信号的部件。
示例97包括示例96的主题,且任选地,包含用于接收表示在多个预定义环境位置处的环境声学声音的环境声学信息以及基于该环境声音信息来确定声音控制模式的部件,该多个预定义环境位置是相对于包括一个或多个个人声音区的环境而定义的。
示例98包括示例97的主题,且任选地,其中环境声学信息包含由声学传感器在多个预定义环境位置中的环境位置处感测的声学声音的信息。
示例99包括示例97或98的主题,且任选地,其中环境声学信息包含音频信号或预定义音频源所产生的声学声音中的至少一个的信息。
示例100包括示例97-99中的任一个的主题,且任选地,包含用于确定要被包括在声音控制模式中的多个选定频率以及基于环境声学信息和一个或多个音频输入来从频谱选择多个选定频率的部件。
示例101包括示例100的主题,且任选地,包含用于基于投影音频和投影环境声音来确定多个选定频率的部件,该投影音频是基于将在个人声音区听到的音频输入通过从多个换能器到个人声音区的传递函数进行的投影,该投影环境声音是基于环境声学声音通过从多个预定义环境位置到个人声音区的传递函数进行的投影。
示例102包括示例101的主题,且任选地,包含用于基于特定频率的投影音频和特定频率的投影环境声音来确定该特定频率是否将被包括在多个选定频率中的部件。
示例103包括示例102的主题,且任选地,包含用于当特定频率的投影音频与特定频率的投影环境声音之间的差异大于预定义阈值时确定该特定频率将被包括在多个选定频率中的部件。
示例104包括示例96-103中的任一个的主题,且任选地,包含用于基于分别对应于一个或多个个人声音区的一个或多个权重向量集来确定多个声音控制信号的部件,对应于个人声音区的权重向量集包含分别对应于多个声换能器的多个权重向量,权重向量集中的权重向量是基于多个声换能器中的声换能器与个人声音区之间的声学传递函数。
示例105包括示例104的主题,且任选地,包含用于通过将来自对应于个人声音区的权重向量集的对应于特定声换能器的权重向量应用于将在个人声音区中听到的音频输入来确定特定声换能器的声音控制信号的部件。
示例106包括示例104或105的主题,且任选地,包含用于基于第一多个声学传递函数和第二多个声学传递函数来确定对应于个人声音区的权重向量集的部件,第一多个声学传递函数包含多个声换能器与个人声音区之间的声学传递函数,第二多个声学传递函数包含多个声换能器与个人声音区外部的一个或多个监测位置之间的声学传递函数。
示例107包括示例106的主题,且任选地,包含用于基于环境声学信息来调整第一或第二多个声学传递函数中的一个或多个声学传递函数的部件,该环境声学信息表示多个预定义环境位置处的环境声学声音,该多个预定义环境位置是相对于包括一个或多个个人声音区的环境来定义的。
示例108包括示例106或107的主题,且任选地,包含用于基于个人声音区的位置变化来调整第一或第二多个声学传递函数中的一个或多个声学传递函数的部件。
示例109包括示例106-108中的任一个的主题,且任选地,包含用于基于包括一个或多个个人声音区的环境的一个或多个环境参数的环境参数信息来调整第一或第二多个声学传递函数中的一个或多个声学传递函数的部件。
示例110包括示例104-109中的任一个的主题,且任选地,包含用于基于与第一声能和第二声能之间的对比度相关的准则来确定对应于个人声音区的权重向量集的部件,其中第一声能包含基于对应于个人声音区的权重向量集的在个人声音区的声能,其中第二声能包含基于对应于个人声音区的权重向量集的在个人声音区外部的一个或多个监测位置的声能。
示例111包括示例110的主题,且任选地,其中该准则包含基于在个人声音区中要听到音频输入的音量来限制第一能量,并且最小化第二能量。
示例112包括示例104-111中的任一个的主题,且任选地,其中权重向量包含对应于相应多个声频的多个权重。
示例113包括示例96-112中的任一个的主题,且任选地,包含用于至少基于第一和第二音频输入来确定声音控制模式的部件,第一音频输入用于第一个人声音区,第二音频输入用于第二个人声音区,以及用于基于表示在第一多个监测感测位置处的声学声音的第一多个监测输入和表示在第二多个监测感测位置处的声学声音的第二多个监测输入来确定声音控制模式的部件,该第一多个监测感测位置被定义在第一个人声音区内,该第二多个监测感测位置被定义在第二个人声音区内。
示例114包括示例96-113中的任一个的主题,且任选地,包含用于基于主动噪声消除(ANC)机制来确定声音控制模式的部件,该ANC机制被配置成基于一个或多个音频输入和基于一个或多个ANC声学传感器输入来减少来自一个或多个个人声音区外部的残余噪声。
本文参考一个或多个实施例描述的功能、操作、组件和/或特征可以与本文参考一个或多个其他实施例描述的一个或多个其他功能、操作、组件和/或特征组合,或者可以与它们组合使用,或反之亦然。
虽然本文已经说明和描述了某些特征,但是本领域技术人员可以想到许多修改、替换、改变和等同物。因此,应当理解,随附权利要求旨在覆盖落入本公开的真实精神内的所有此类修改和改变。
- 设备控制装置、声音识别装置、代理装置、车载设备控制装置、导航装置、音响装置、设备控制方法、声音识别方法、代理处理方法、车载设备控制方法、导航方法、音响装置控制方法和程序
- 声音控制装置、声音控制方法、声音控制程序以及移动终端装置