烧成曲线的自适应预测方法、设备及计算机存储介质
文献发布时间:2023-06-19 12:13:22
技术领域
本发明涉及数据预测领域,尤其涉及一种烧成曲线的自适应预测方法、设备及计算机存储介质。
背景技术
现代烧结物工业化生产是一个复杂的工艺过程,从原料加工到成品出库,包含多道工序。其中,连续加热设备烧成以及原料成分配为影响烧结物生产质量最重要的两个生产因素。
不同烧结物产品有不同的原料配比需求、不同的原料批次,以及生产过程中的原料配比的系统性误差和人工误差等原因,带来原料化学和物理性质的波动,因此造成烧结物生产质量的波动。
工业化生产使用连续加热设备实现连续性生产,烧结物的烧制在不同烧成阶段需要对应的温度设定,与之对应的各连续加热设备的设定温度、压力和气氛需要做调整,连续加热设备烧成曲线分为不同空间和时间数十个表面底面温度点、压力和气氛参数设定,操作复杂。
目前的连续加热设备烧成曲线依赖于技术车间的工艺单及连续加热设备人工经验,生产容易出现一些问题,如:
1)连续加热设备建议烧成温度、压力和气氛参数阈值过于宽泛,指导意义有限,依赖连续加热设备工人经验调整;
2)连续加热设备烧成曲线调整为生产质量波动导向的调整,当生产质量下降后,再调整烧成曲线,调整期间造成时间及经济成本重;
3)人工经验调经验较难传授和沉淀,难实现标准化操作。
发明内容
有鉴于此,本申请实施例提供一种烧成曲线的自适应预测方法、设备及计算机存储介质,解决依靠人工经验调整连续加热设备烧成曲线造成的生产质量及效率低下的问题。
本申请实施例提供了一种烧成曲线的自适应预测方法,所述方法包括:
基于烧成曲线自适应转化模型,将历史烧成曲线自适应转化为多项式嵌入参数;
利用历史原料成分数据以及所述多项式嵌入参数训练并生成多项式嵌入参数预测模型;
将实时原料成分数据输入所述多项式嵌入参数预测模型,则输出预测的多项式嵌入参数;
将所述预测的多项式嵌入参数输入所述烧成曲线自适应转化模型,则输出预测的烧成曲线。
在一实施例中,所述基于烧成曲线自适应转化模型,将历史烧成曲线自适应转化为多项式嵌入参数,包括
将所述历史烧成曲线输入所述烧成曲线自适应转化模型;
利用所述烧成曲线自适应转化模型,对所述历史烧成曲线进行自适应的曲线拆解;
对曲线拆解生成的多个曲线段进行自适应的多项式拟合,转化为所述历史烧成曲线对应的多项式嵌入参数。
在一实施例中,利用所述烧成曲线自适应转化模型,所述对所述历史烧成曲线进行自适应的曲线拆解,包括:
对所述历史烧成曲线执行多次不同次幂的多项式回归,生成对应的多项式回归次幂以及决定系数;其中,所述不同次幂为依次递增次幂;
基于自适应寻优法则,从多个多项式回归次幂中自适应选取第一多项式回归次幂;
基于所述第一多项式回归次幂以及对应的决定系数,进行多项式拟合;
基于预设方法,对所述多项式拟合生成的结果进行计算,获得拆分点;
基于所述拆分点,将所述历史烧成曲线拆解。
在一实施例中,所述基于自适应寻优法则,从多个多项式回归次幂中自适应选取第一多项式回归次幂,包括:
以X轴为所述多项式回归次幂,以Y轴为决定系数,将生成的多个多项式回归次幂以及决定系数绘制出第一关系曲线;
将所述第一关系曲线转化为第二关系曲线,获得所述第二关系曲线的极值点,则所述极值点对应的多项式回归次幂为所述第一多项式回归次幂。
在一实施例中,所述将所述第一关系曲线转化为第二关系曲线,获得所述第二关系曲线的极值点,则所述极值点对应的多项式回归次幂为所述第一多项式回归次幂,包括:
赋值所述第一关系曲线的最大决定系数与最小决定系数为等值,基于第一预设公式获得所述第一关系曲线转化为所述第二关系曲线所需翻转角度;
基于所述第一关系曲线对应的矩阵M以及所述所需翻转角度,通过第二预设公式获得所述第二关系曲线对应的矩阵M*;
获得所述矩阵M*中决定系数的最值,则所述最值对应的多项式回归次幂为所述第一多项式回归次幂。
在一实施例中,所述对曲线拆解生成的多个曲线段进行自适应的多项式拟合,转化为所述历史烧成曲线对应的多项式嵌入参数,包括:
对每个所述曲线段分别执行多次不同次幂的多项式回归,生成每个所述曲线段的多项式回归次幂以及决定系数;
基于自适应寻优法则,从每个所述曲线段对应生成的多个多项式回归次幂中自适应选取第二多项式回归次幂;其中,所述一个曲线段对应一个第二多项式回归次幂;
基于每个所述曲线段的第二多项式回归次幂以及对应的决定系数,进行多项式拟合并转化为所述历史烧成曲线对应的多项式嵌入参数。
在一实施例中,所述将所述预测的多项式嵌入参数输入所述烧成曲线自适应转化模型,则输出预测的烧成曲线,包括:
基于所述预测的多项式嵌入参数以及第二多项式回归次幂,生成多个曲线段;
基于所述拆分点以及所述第一多项式回归次幂,将所述多个曲线段连接并生成所述预测的烧成曲线。
在一实施例中,所述方法,还包括:
基于所述预测的烧成曲线以及所述预测的烧成曲线包含的烧成曲线参数值,生成最佳烧成曲线建议。
为实现上述目的,还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有烧成曲线的自适应预测方法程序,所述烧成曲线的自适应预测方法程序被处理器执行时实现上述任一所述的烧成曲线的自适应预测方法的步骤。
为实现上述目的,还提供一种预测烧成曲线的设备,包括存储器,处理器及存储在所述存储器上并可在所述处理器上运行的烧成曲线的自适应预测方法程序,所述处理器执行所述烧成曲线的自适应预测方法程序时实现上述任一所述的烧成曲线的自适应预测方法的步骤。
本申请实施例中提供的一个或多个技术方案,至少具有如下技术效果或优点:
基于烧成曲线自适应转化模型,将历史烧成曲线转化为所述历史烧成曲线对应的多项式嵌入参数;通过烧成曲线自适应转化模型,将历史烧成曲线量化为多项式嵌入参数,保证多项式嵌入参数的正确性,从而提高多项式嵌入参数预测模型的预测结果。
利用历史原料成分数据以及所述多项式嵌入参数训练并生成多项式嵌入参数预测模型;通过大数量级的历史原料成分数据以及多项式嵌入参数训练生成多项式嵌入参数预测模型,保证多项式嵌入参数预测模型同时具有历史原料特征以及多项式曲线关系特征,能够更好的预测多项式嵌入参数,从而保证烧成曲线预测的正确性。
将实时原料成分数据输入所述多项式嵌入参数预测模型,输出预测的多项式嵌入参数;通过训练好的多项式嵌入参数预测模型,正确的将实时原料成分数据转化为预测的多项式嵌入参数,从而保证正确预测实时的工业化过程的烧成曲线。
将所述预测的多项式嵌入参数输入所述烧成曲线自适应转化模型,则输出预测的烧成曲线;保证预测的烧成曲线正确的输出,并可根据预测的结果进行实时的自适应调整,节省人工试错时间,提高生产质量及效率,达到降本增效的目的。
附图说明
图1为本申请烧成曲线的自适应预测方法的第一实施例的流程示意图;
图2为烧成曲线的自适应预测方法的流程示意图;
图3为本申请烧成曲线的自适应预测方法的第一实施例步骤S110的具体实施步骤;
图4为本申请烧成曲线的自适应预测方法步骤S112的具体实施步骤
图5为多项式嵌入参数生成过程的示意图;
图6为曲线拆解点选取结果的示意图;
图7为本申请烧成曲线的自适应预测方法步骤S112-2的具体实施步骤;
图8为关系曲线的示意图;
图9为本申请烧成曲线的自适应预测方法步骤S112-2-2的具体实施步骤
图10为本申请烧成曲线的自适应预测方法第一实施例中步骤S113的具体实施步骤;
图11为多个曲线段的多项式拟合结果示意图;
图12为本申请烧成曲线的自适应预测方法步骤S140的具体实施步骤;
图13为本申请烧成曲线的自适应预测方法的第二实施例的流程示意图;
图14为本申请实施例中涉及的烧成曲线的自适应预测方法的硬件架构示意图。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明实施例的主要解决方案是:基于烧成曲线自适应转化模型,将历史烧成曲线自适应转化为历史烧成曲线对应的多项式嵌入参数;利用历史原料成分数据以及多项式嵌入参数训练并生成多项式嵌入参数预测模型;将实时原料成分数据输入多项式嵌入参数预测模型,输出预测的多项式嵌入参数;将预测的多项式嵌入参数输入烧成曲线自适应转化模型,输出预测的烧成曲线;本发明解决了依靠人工经验调整连续加热设备烧成曲线造成的生产质量及效率低下的问题,实现连续加热设备烧成曲线的自适应调整方法,节省人工试错时间,提高生产质量及效率,达到降本增效的目的。
对本发明实施例进行进一步详细说明之前,对本发明实施例中涉及的名词和术语进行说明,本发明实施例中涉及的名词和术语适用于如下的解释。
烧结物可以是粉末或压坯在低于主要组分熔点的温度下的热处理后生成的致密体;在本申请中烧结物包括但不限定于水泥、玻璃、陶瓷、钢铁、电路板等。
连续加热设备可以是烧结物生成过程使用的加热设备且加热过程是连续的;在本申请中连续加热设备包括但不限定于加热炉、高炉、转炉、窑炉,如水泥生成过程使用的回转窑;玻璃生成过程使用的浮法玻璃窑炉;陶瓷生成过程使用的辊道窑;电路板生成过程使用的回流焊炉等。
为了更好的理解上述技术方案,下面将结合说明书附图以及具体的实施方式对上述技术方案进行详细的说明。
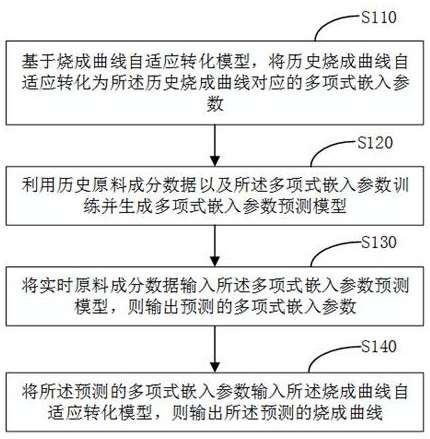
参照图1,图1为本申请烧成曲线的自适应预测方法的第一实施例,所述方法包括:
步骤S110:基于烧成曲线自适应转化模型,将历史烧成曲线自适应转化为所述历史烧成曲线对应的多项式嵌入参数。
具体地,烧成曲线自适应转化模型可以是一个数学模型,功能为输入历史烧成曲线,则输出历史烧成曲线对应的多项式嵌入参数。
其中,历史烧成曲线包含历史烧成曲线参数,所述历史烧成曲线参数可以是工业化生产过程中实际的参数数据,包含但不限于,连续加热设备烧成表面温度、底面温度、压力、气氛参数等。
步骤S120:利用历史原料成分数据以及所述多项式嵌入参数训练并生成多项式嵌入参数预测模型。
具体地,所述历史原料成分数据以及所述实时原料成分数据包含物理成分数据以及化学成分数据。物理成分数据包含但不限于颜色、状态熔点、沸点、硬度、导电性、导热性、延展性、溶解性、密度、流速、颗粒度的特性参数的全集和子集;化学成分数据包含化学成分比例以及化学成分特性,其中化学成分特性包括但不限于酸碱性、可燃性、氧化性、还原性、燃烧热、灰熔点、燃烧速率、燃尽温度等特性参数的全集和子集。
具体地,多项式嵌入参数预测模型可以是机器学习模型、深度学习模型等,使用的预测算法包括但不限于回归算法(线性回归、岭回归、LASSO回归(Least absoluteshrinkage and selection operator)、弹性网络回归、多元回归等)、树状回归算法(决策树、随机森林、GBDT(Gradient Boosting Decision Tree,梯度提升决策树)、XGBoost(eXtreme Gradient Boosting,极端梯度提升)等)、基于深度学习的回归算法等。
步骤S130:将实时原料成分数据输入所述多项式嵌入参数预测模型,输出预测的多项式嵌入参数。
具体地,实时原料成分数据是工业化生产过程中实时使用的原料成分数据。
具体地,利用大数量级历史原料成分数据以及多项式嵌入参数训练多项式嵌入参数预测模型,并将实时原料成分数据输入训练好的多项式嵌入参数预测模型,则会输出预测的多项式嵌入参数;其中,大数量级的历史原料成分数据以及历史烧成曲线以及历史烧成曲线参数可以是烧结物工业化生产过程中产生的历史数据。
步骤S140:将所述预测的多项式嵌入参数输入所述烧成曲线自适应转化模型,则输出预测的烧成曲线。
具体地,预测的烧成曲线对于实时的工业生产过程具有指导性,可以实时对连续加热设备烧成曲线进行自适应调整,避免人工经验调整连续加热设备烧成曲线造成的生产质量及效率低下的问题。
具体地,可以参照图2,图2为烧成曲线的自适应预测方法的流程示意图。
上述实施例中,存在的有益效果为:基于烧成曲线自适应转化模型,将历史烧成曲线自适应转化为所述历史烧成曲线对应的多项式嵌入参数;通过烧成曲线自适应转化模型,将历史烧成曲线量化为多项式嵌入参数,保证多项式嵌入参数的正确性,从而提高多项式嵌入参数预测模型的预测结果。
利用历史原料成分数据以及所述多项式嵌入参数训练并生成多项式嵌入参数预测模型;通过大数量级的历史原料成分数据以及多项式嵌入参数训练生成多项式嵌入参数预测模型,保证多项式嵌入参数预测模型同时具有历史原料特征以及多项式曲线关系特征,能够更好的预测多项式嵌入参数,从而保证烧成曲线预测的正确性。
将实时原料成分数据输入所述多项式嵌入参数预测模型,输出预测的多项式嵌入参数;通过训练好的多项式嵌入参数预测模型,正确的将实时原料成分数据转化为预测的多项式嵌入参数,从而保证正确预测实时的工业化过程的烧成曲线。
将所述预测的多项式嵌入参数输入所述烧成曲线自适应转化模型,则输出预测的烧成曲线;保证预测的烧成曲线正确的输出,并可根据预测的结果进行实时的自适应调整,节省人工试错时间,提高生产质量及效率,达到降本增效的目的。
参照图3,图3为本申请烧成曲线的自适应预测方法的第一实施例步骤S110的具体实施步骤,所述基于烧成曲线自适应转化模型,将历史烧成曲线自适应转化为多项式嵌入参数,包括
步骤S111:将所述历史烧成曲线输入所述烧成曲线自适应转化模型。
具体地,将所述历史烧成曲线作为所述烧成曲线自适应转化模型的输入数据进行输入,即将所述历史烧成曲线包含的特征信息输入所述烧成曲线自适应转化模型。
步骤S112:对所述历史烧成曲线进行自适应的曲线拆解。
具体地,在本实施例中可以自动自适应地选取合适的防止过拟合的拆分点对历史烧成曲线进行拆解。
步骤S113:对曲线拆解生成的多个曲线段进行自适应的多项式拟合,转化为所述历史烧成曲线对应的多项式嵌入参数。
具体地,多项式拟合是用一个多项式展开去拟合包含数个分析格点的一小块分析区域中的所有观测点,得到观测数据的客观分析场。展开系数用最小二乘拟合确定。
上述实施例,存在的有益效果为:考虑到了连续性历史烧成曲线参数的关联关系,并有效防止模型过拟合。
参照图4,图4为本申请烧成曲线的自适应预测方法步骤S112的具体实施步骤,所述利用所述烧成曲线自适应转化模型,对所述历史烧成曲线进行自适应的曲线拆解,包括:
步骤S112-1:对所述历史烧成曲线执行多次不同次幂的多项式回归,生成对应的多项式回归次幂以及决定系数。
具体地,执行多次不同次幂的多项式回归时,可以执行一次幂到十三次幂的多项式回归或者十三次幂到一次幂的多项式回归,但并不限定于一次幂到十三次幂,根据曲线情况进行调整;利用公式1进行多项式回归:
决定系数,亦称测定系数、可决系数、可决指数。与复相关系数类似的,表示一个随机变量与多个随机变量关系的数字特征,用来反映回归模式说明因变量变化可靠程度的一个统计指标,一般用符号“R
步骤S112-2:基于自适应寻优法则,从多个多项式回归次幂中自适应选取第一多项式回归次幂。
具体地,自适应寻优法则可以是膝部法则,也可以是肘部法则,根据烧成曲线的性质进行选择。
需要另外说明的是,膝部法则(knee method)与肘部法则(elbow method)是相对的,肘部法则是将降函数曲线进行翻转,翻转时将翻转前曲线中的最大值与最小值赋值为等值且同为最大值,找到该曲线的最小值为肘部点;而膝部法则是将升函数曲线进行翻转,翻转时将翻转前曲线中的最大值与最小值赋值为等值且同为最小值,找到该曲线的最大值为膝部点。
步骤S112-3:基于所述第一多项式回归次幂以及对应的决定系数,进行多项式拟合。
具体地,在进行多项式拟合的过程中,以第一多项式回归次幂进行拟合,在保证数据正确的同时,防止过拟合的现象出现。
步骤S112-4:基于预设方法,对所述多项式拟合生成的结果进行计算,获得拆分点。
具体地,预设方法可以是二次微分的方法,利用公式2进行计算:
需要另外说明的是,所述拆分点可以是二次微分所求拐点。其中拐点,又称反曲点,在数学上指改变曲线向上或向下方向的点,直观地说拐点是使切线穿越曲线的点(即连续曲线的凹弧与凸弧的分界点)。
在此并不限定于二次微分的方法,同样也可以是其他的方法获得拆分点。
步骤S112-5:基于所述拆分点,将所述历史烧成曲线拆解。
具体地,将历史烧成曲线在多个拆分点处进行拆解,以生成多段的烧成曲线段。
具体地,参照图5,图5为多项式嵌入参数生成过程的示意图,在本实施例中对应图5的左侧部分,需要说明的是,图5中使用膝部法则进行举例,同时也可以为肘部法则,在此不作限定;也可以参照图6,图6为曲线拆解点选取结果的示意图。
在上述实施例中,存在的有益效果为:拆解烧成曲线过程中,自适应的正确选择第一多项式回归次幂,防止过拟合的现象发生的基础上保证后续准确的以第一多项式回归次幂进行合成预测的烧成曲线,以保证烧成曲线的正确预测。
参照图7,图7为本申请烧成曲线的自适应预测方法步骤S112-2的具体实施步骤,所述基于自适应寻优法则,从多个多项式回归次幂中自适应选取第一多项式回归次幂,包括:
步骤S112-2-1:以X轴为所述多项式回归次幂,以Y轴为决定系数,将生成的多个多项式回归次幂以及决定系数绘制出第一关系曲线。
具体地,在本实施例中以膝部法则为例对自适应寻优法则进行阐述,使用膝部法则的目的是自动自适应地选取合适地多项式回归次幂,选取较低的次幂及较高的决定系数。具体参照图8上图为绘制出的第一关系曲线,多项式回归次幂从1至13。
需要另外说明的是,如果是使用肘部法则,则目的是自动自适应地选取合适地多项式回归次幂,选择较高的次幂及较低的决定系数。
步骤S112-2-2:将所述第一关系曲线转化为第二关系曲线,获得所述第二关系曲线的极值点,则所述极值点对应的多项式回归次幂为所述第一多项式回归次幂。
具体地,参照图8下图为转换后的第二关系曲线,从图8下图很清晰的可以看到极值点对应的多项式回归次幂为4。
上述实施例中,存在的有益效果为:自适应的正确选择第一多项式回归次幂,以防止过拟合线现象的出现。
参照图9,图9为本申请烧成曲线的自适应预测方法步骤S112-2-2的具体实施步骤,所述将所述第一关系曲线转化为第二关系曲线,获得所述第二关系曲线的极值点,则所述极值点对应的多项式回归次幂为所述第一多项式回归次幂,包括:
步骤S112-2-2-1:赋值所述第一关系曲线的最大决定系数与最小决定系数为等值,基于第一预设公式获得所述第一关系曲线转化为所述第二关系曲线所需翻转角度。
具体地,若使用膝部法则,则赋值最大决定系数与最小决定系数为等值,且同为最大值;若使用肘部法则,则赋值最大决定系数与最小决定系数为等值,且为最小值。
具体地,第一关系曲线对应的矩阵M:
其中n为多项式回归不同次幂;
第一预设公式可以为:
其中θ为翻转角度;n为多项式回归不同次幂;
步骤S112-2-2-2:基于所述第一关系曲线对应的矩阵M以及所述所需翻转角度,通过第二预设公式获得所述第二关系曲线对应的矩阵M*。
具体地,第二预设公式可以为:
其中,θ为翻转角度;M为第一关系曲线对应的矩阵;M*为第二关系曲线对应的矩阵。
步骤S112-2-2-3:获得所述矩阵M*中决定系数的最值,则所述最值对应的多项式回归次幂为所述第一多项式回归次幂。
其中,决定系数的最值可以是最大值,也可以是最小值;最大值对应的膝部法则,最小值对应的是肘部法则。
上述实施例中,存在的有益效果为:给出了确定第一多项式回归次幂的具体步骤,保证第一多项式回归次幂的正确性,从而保证预测的烧成曲线的正确性。
参照图10,图10为本申请烧成曲线的自适应预测方法第一实施例中步骤S113的具体实施步骤,所述对曲线拆解生成的多个曲线段进行自适应的多项式拟合,转化为所述历史烧成曲线对应的多项式嵌入参数,包括:
步骤S113-1:对每个所述曲线段分别执行多次不同次幂的多项式回归,生成每个所述曲线段的多项式回归次幂以及决定系数;
具体地,该步骤中每个曲线段的多项式回归次幂以及决定系数的生成过程与上述步骤步骤S112-1中相同,即已经进行了阐述,在此不再赘述;
步骤S113-2:基于自适应寻优法则,从每个所述曲线段对应生成的多个多项式回归次幂中自适应选取第二多项式回归次幂;其中,所述一个曲线段对应一个第二多项式回归次幂。
具体地,自适应寻优法则已在上述步骤中阐述,在此不再赘述。
步骤S113-3:基于每个所述曲线段的第二多项式回归次幂以及对应的决定系数,进行多项式拟合并转化为所述历史烧成曲线对应的多项式嵌入参数。
具体地,可以将连续加热设备烧成表面温度、底面温度、压力、气氛参数等历史烧成曲线参数转化为历史烧成曲线对应的多项式嵌入参数。
具体地,参照图5,图5为多项式嵌入参数生成过程的示意图,在本实施例中对应图5的右侧部分,也可以参照图11,图11为多个曲线段的多项式拟合结果示意图。
上述实施例中,存在的有益效果为:本实施例为多项式嵌入参数预测模型提供正确的训练数据,保证多项式嵌入参数预测模型训练的正确性,从而保证预测的多项式嵌入参数的正确性。
参照图12,图12为本申请烧成曲线的自适应预测方法步骤S140的具体实施步骤,所述将所述预测的多项式嵌入参数输入所述烧成曲线自适应转化模型,则输出预测的烧成曲线,包括:
步骤S141:基于所述预测的多项式嵌入参数以及第二多项式回归次幂,生成多个曲线段。
具体地,根据预测出的多项式嵌入参数以及已知的第二多项式回归次幂,反向生成多个曲线段。
步骤S142:基于所述拆分点以及所述第一多项式回归次幂,将所述多个曲线段连接并生成所述预测的烧成曲线。
具体地,根据已知的拆分点以及已知的第一多项式回归次幂,将生成的多个曲线段进行拼接,最终生成预测的烧成曲线。
上述实施例中,存在的有益效果为:烧成曲线的预测方法从数理捕捉了原料物理以及化学性质参数与烧成曲线参数的高维空间对应关系,更好的对烧成曲线进行预测。
参照图13,图13为本申请烧成曲线的自适应预测方法的第二实施例,所述方法,还包括:
步骤S210:基于烧成曲线自适应转化模型,将历史烧成曲线自适应转化为所述历史烧成曲线对应的多项式嵌入参数;
步骤S220:利用历史原料成分数据以及所述多项式嵌入参数训练并生成多项式嵌入参数预测模型。
步骤S230:将实时原料成分数据输入所述多项式嵌入参数预测模型,则输出预测的多项式嵌入参数。
步骤S240:将所述预测的多项式嵌入参数输入所述烧成曲线自适应转化模型,则输出预测的烧成曲线。
具体地,在其中一个实施例中,在输出预测的烧成曲线包含的烧成曲线参数值的同时推导出影响烧成曲线的原料特征重要度排序;根据原料特征的重要程度排序,基于优先级对原料进行自适应的调整,也可以更好的生成烧成曲线建议。
步骤S250:基于所述预测的烧成曲线以及所述预测的烧成曲线包含的烧成曲线参数值,生成最佳烧成曲线建议。
具体地,烧成曲线建议可以是工程师易懂的且对工业化过程中提高生产效率与质量的具有指导性的调整方法;可以是对某个烧成曲线参数进行调整。
其中,预测的烧成曲线包含预测的烧成曲线参数,所述预测的烧成曲线参数可以是预测的工业化生产过程中的参数数据,包含但不限于,连续加热设备烧成表面温度、底面温度、压力、气氛参数等。
与第一实施例相比,第二实施例中包含了步骤S250,其他步骤在第一实施例中已经进行了阐述,在此不再赘述。
上述实施例中,存在的有益效果为:通过生成的最佳烧成曲线建议,进一步实现了连续加热设备烧成曲线的自适应调整方法,节省人工试错时间,提高生产质量及效率,达到降本增效的目的。
本申请还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有烧成曲线的自适应预测方法程序,所述烧成曲线的自适应预测方法程序被处理器执行时实现上述任一所述的烧成曲线的自适应预测方法的步骤。
本申请还提供一种预测烧成曲线的设备,包括存储器,处理器及存储在所述存储器上并可在所述处理器上运行的烧成曲线的自适应预测方法程序,所述处理器执行所述烧成曲线的自适应预测方法程序时实现上述任一所述的烧成曲线的自适应预测方法的步骤。
本申请涉及一种预测烧成曲线的设备010包括如图14所示:至少一个处理器012、存储器011。
处理器012可能是一种集成电路芯片,具有信号的处理能力。在实现过程中,上述方法的各步骤可以通过处理器012中的硬件的集成逻辑电路或者软件形式的指令完成。上述的处理器012可以是通用处理器、数字信号处理器(DSP)、专用集成电路(ASIC)、现场可编程门阵列(FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。可以实现或者执行本发明实施例中的公开的各方法、步骤及逻辑框图。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。软件模块可以位于随机存储器,闪存、只读存储器,可编程只读存储器或者电可擦写可编程存储器、寄存器等本领域成熟的存储介质中。该存储介质位于存储器011,处理器012读取存储器011中的信息,结合其硬件完成上述方法的步骤。
可以理解,本发明实施例中的存储器011可以是易失性存储器或非易失性存储器,或可包括易失性和非易失性存储器两者。其中,非易失性存储器可以是只读存储器(ReadOnly Memory,ROM)、可编程只读存储器(Programmable ROM,PROM)、可擦除可编程只读存储器(Erasable PROM,EPROM)、电可擦除可编程只读存储器(Electrically EPROM,EEPROM)或闪存。易失性存储器可以是随机存取存储器(Random Access Memory,RAM),其用作外部高速缓存。通过示例性但不是限制性说明,许多形式的 RAM可用,例如静态随机存取存储器(Static RAM,SRAM)、动态随机存取存储器(Dynamic RAM,DRAM)、同步动态随机存取存储器(Synchronous DRAM,SDRAM)、双倍数据速率同步动态随机存取存储器(Double DataRateSDRAM,DDRSDRAM)、增强型同步动态随机存取存储器(Enhanced SDRAM,ESDRAM)、同步连接动态随机存取存储器 (Synch link DRAM,SLDRAM) 和直接内存总线随机存取存储器(Direct Rambus RAM,DRRAM)。本发明实施例描述的系统和方法的存储器011旨在包括但不限于这些和任意其它适合类型的存储器。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
应当注意的是,在权利要求中,不应将位于括号之间的任何参考符号构造成对权利要求的限制。单词“包含”不排除存在未列在权利要求中的部件或步骤。位于部件之前的单词“一”或“一个”不排除存在多个这样的部件。本发明可以借助于包括有若干不同部件的硬件以及借助于适当编程的计算机来实现。在列举了若干装置的单元权利要求中,这些装置中的若干个可以是通过同一个硬件项来具体体现。单词第一、第二、以及第三等的使用不表示任何顺序。可将这些单词解释为名称。
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发
明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 烧成曲线的自适应预测方法、设备及计算机存储介质
- 自适应曲线学习方法、装置、计算机设备及存储介质