资料分析系统及资料分析方法
文献发布时间:2023-06-19 18:35:48
技术领域
本发明实施例是关于一种资料分析系统及资料分析方法,特别是关于一 种应用于将优化资料及资料视觉化的资料分析系统及资料分析方法。
背景技术
疾病分类是将罹患的疾病体或疾病群,依既定的准则加以分门别类的一 套分类系统。而国际疾病分类的目的在于让不同国家、不同地区、在不同时 间所搜集的罹病或死亡资料做有系统的记录、分析、解读与比较。
现行国际疾病统计分类(International Classification of Disease,ICD)是用来将疾病及其他健康问题的诊断从文字转译成英文字母与数字混合配置译 码或代码(alphanumeric code),以便于资料的存取与分析。前三码为核心分类 代码,是世界卫生组织(WHO)死因资料库的国际通报及国际间一般性比较 必要的分类项译码;后四码为细部的分类项目。自1989年WHO通过第10 版ICD(简称ICD-10),各国皆陆续上线使用。
然而,ICD-9至ICD-10疾病代码结构及特性改变,疾病诊断编码完全不 同,复杂度及精细程度大幅提升,故而数量上也从原本13000笔改版至68000 笔,医师及临床人员需要重新学习及适应,也对繁杂的临床工作更增添行政 上的不便。医师肩负临床、教学、行政及研究作业,但因应符合卫生或健保 申请给付规范,撰写病历占用医师大量时间,压缩照护病人时间。
因此如何使用自动优化医生撰写的病历资料,并将优化后的资料以较佳 的视觉化方式呈现,已成为本领域需解决的问题之一。
发明内容
本公开内容的一态样提供了一种资料分析系统,包含一电子装置以及一 服务器。电子装置用以显示一使用者界面,该使用者界面包含多个医疗信息 栏位,并通过一第一传输接口传送至少一部分的所述医疗信息栏位的内容。 服务器用以通过一第二传输接口接收该至少一部分的所述医疗信息栏位的 内容,通过一处理器依据该至少一部分的所述医疗信息栏位内容产生一优化 报告。其中,该处理器将该优化报告输入一应用模型,该应用模型输出对应 该优化报告的多个诊断码,该处理器依据优化报告中的多个词汇各自对应的 多个权重产生一热图(heatmap),该处理器通过该使用者界面显示该热图。
本公开内容的一态样提供了一种资料分析方法,包含:显示一使用者界 面,该使用者界面包含多个医疗信息栏位;传送至少一部分的所述医疗信息 栏位的内容;接收该至少一部分的所述医疗信息栏位的内容,通过一处理器 依据该至少一部分的所述医疗信息栏位的内容产生一优化报告;通过该处理 器将该优化报告输入一应用模型,该应用模型输出对应该优化报告的多个诊 断码;通过该处理器依据该优化报告中的多个词汇各自对应的多个权重产生 一热图(heatmap);以及通过该处理器通过该使用者界面显示该热图。
综上,资料分析系统及资料分析方法可以提供医师在撰写病历时能够有 缩写还原及错别字修正建议的辅助,以优化的病历报告,优化后的病历报告 输入一应用模型,使得应用模型能够将病历报告与诊断码间连结,输出精准 的推荐诊断码。诊断码的查找工作有了应用模型辅助后,医疗人员可以花更 多心思研究病历,包括病人做的检查、症状是否全反应在诊断上,是否有缺 失资料,且在不违反医疗原则下,如何依据对应候选诊断码各自对应的费用 资料,以提高健保给付,进一步提高了医疗的整体品质。
附图说明
图1是依照本发明实施例绘示一种资料分析系统的方框图。
图2是依照本发明实施例绘示一种资料分析方法的流程图。
图3是依照本发明实施例绘示一种使用者界面的示意图。
图4是依照本发明实施例绘示一种应用模型的示意图。
图5是依照本发明一实施例绘示一种热图的示意图。
图6是依照本发明实施例绘示一种资料分析系统应用于门诊或急诊情境 的示意图。
图7是依照本发明实施例绘示一种资料分析系统应用于病人住院情境的 示意图。
其中,附图标记说明如下:
10:电子装置
11:传输接口
12:处理器
13:显示器
14:存储装置
20:服务器
15:传输接口
16:处理器
17:存储装置
18:应用模型
LK:通信连接
L1,L12:转换层
CL:分类层
200:资料分析方法
210~250,S1~S4,S1’~S5’:步骤
S:病人主诉栏位
O:诊察观察栏位
A:诊断评估栏位
P:处置治疗栏位
具体实施方式
以下说明是为完成发明的较佳实现方式,其目的在于描述本发明的基本 精神,但并不用以限定本发明。实际的发明内容必须参考之后的权利要求。
必须了解的是,使用于本说明书中的“包含”、“包括”等词,是用以 表示存在特定的技术特征、数值、方法步骤、作业处理、元件以及/或组件, 但并不排除可加上更多的技术特征、数值、方法步骤、作业处理、元件、组 件,或以上的任意组合。
于申请专利中使用如“第一”、“第二”、“第三”等词是用来修饰申 请专利中的元件,并非用来表示之间具有优先权顺序,先行关系,或者是一 个元件先于另一个元件,或者是执行方法步骤时的时间先后顺序,仅用来区 别具有相同名字的元件。
请参阅图1,图1是依照本发明实施例绘示一种资料分析系统100的方 框图。资料分析系统100包含一电子装置10及一服务器20。于一实施例中, 电子装置10中包含一传输接口11、一处理器12、一显示器13及一存储装 置14。于一实施例中,服务器20中包含一传输接口15、一处理器16及一 存储装置17。于一实施例中,电子装置10通过有线或无线方式与服务器20 建立通信连接LK。
于一实施例中,服务器20中的处理器16存取并执行存储装置17中存 储的程序,以实现一应用模型18。于一实施例中,应用模型18由软件或固 件实现。于一实施例中,应用模型18由硬件电路实现,举例而言,应用模 型18可通过主动元件(例如开关、晶体管)、被动元件(例如电阻、电容、电 感)所构成,其硬件电路耦接于处理器16。于一实施例中,处理器16用以存 取应用模型18的运算结果,于一例子中,处理器16将运算结果进行进一步 的运算后,可以再将进一步的运算结果存回存储装置17。
于一实施例中,存储装置14、存储装置17各自可被实作为只读存储器、 快闪存储器、软盘、硬盘、光盘、随身盘、磁带、可由网络存取的资料库或 熟悉此技艺者可轻易思及具有相同功能的存储媒体。
于一实施例中,处理器12、处理器16可由集成电路如微控制单元(microcontroller)、微处理器(microprocessor)、数字信号处理器(Digital Signal Processor,DSP)、现场可编程逻辑闸阵列(Field Programmable Gate Array, FPGA)、特殊应用集成电路(Application Specific Integrated Circuit,ASIC)或 一逻辑电路来实施。
于一实施例中,传输接口11、15可以是Wi-Fi装置、蓝牙装置、无线网 络接口卡或其他用以传输资料的装置。
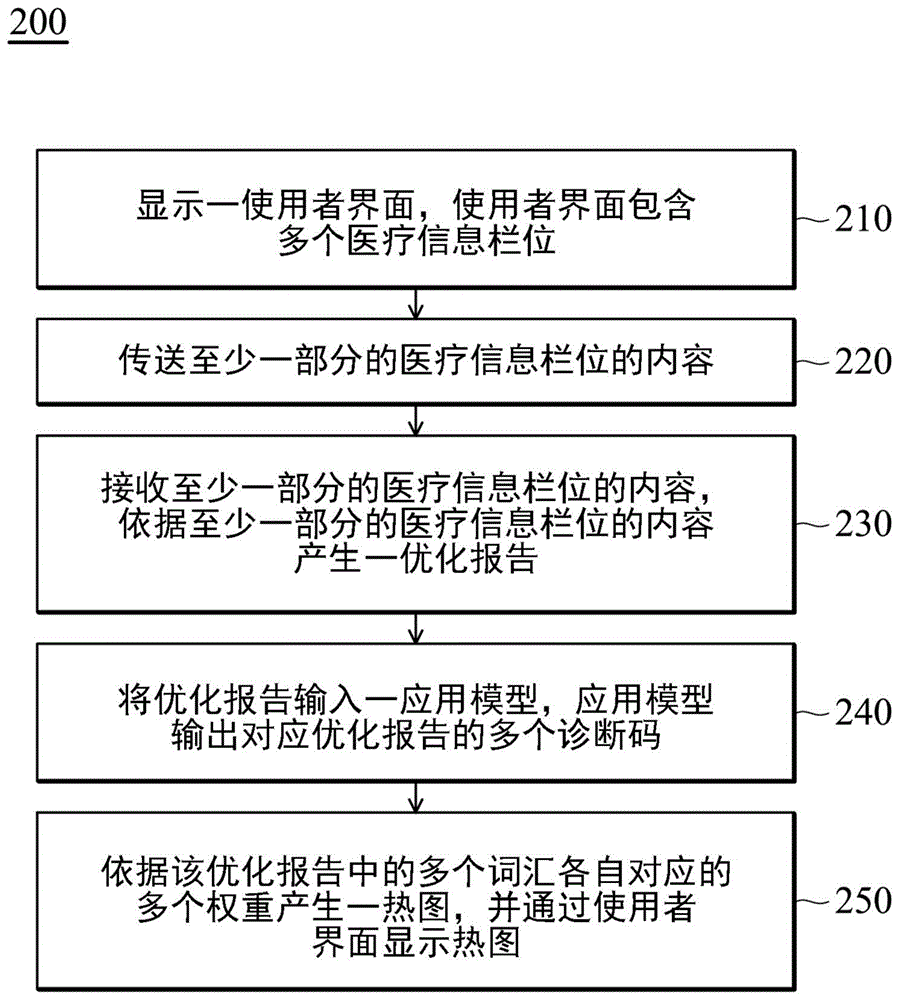
请参阅图2,图2是依照本发明实施例绘示一种资料分析方法200的流 程图。资料分析方法200可以由图1的元件实现。
于步骤210中,电子装置10用以显示一使用者界面,使用者界面包含 多个医疗信息栏位。
请参阅图3,图3是依照本发明实施例绘示一种使用者界面的示意图。 于一实施例中,电子装置10可以是手机、平板、笔电、桌电,电子装置10 一般放置于医院内,电子装置10中可以搭载或通信连结医院信息系统 (Hospital Information System,HIS),医院信息系统是指利用现代电脑软技术 与网络通信技术,用以实现对医院的人流、物流、财流进行综合管理,使用 者界面可以是医院信息系统中的其中一页面,使用者界面用以让医护人员输入病历相关信息。
于一实施例中,电子装置10的显示器13上显示的使用者界面中包含多 个医疗信息栏位,所述医疗信息栏位例如为包含一病人主诉(subjective)栏位 S、一诊察观察(objective)栏位O、一诊断评估(assessment)栏位A及一处置治 疗(Plan)栏位P,各栏位分别包含病人主诉内容、诊察观察内容、诊断评估内 容、处置治疗内容。于另一实施例中,电子装置10的显示器13上显示病人 的病历资料,病人主诉内容、诊察观察内容、诊断评估内容、处置治疗内容 组合或分散地呈现于病人的病历资料中,本发明实施例不限制各栏位及其栏 位对应的内容呈现的形式。
其中,病人主诉栏位S的内容为病人自觉症状。病人自觉症状包含病人 主诉、症状、发病时间、现在病史、过去病史及个人史,例如记载病人所述: 从昨天下午开始右下腹痛,晚上开始发烧到摄氏38.5度,过去没有发生过这 种情况,也没有慢性疾病。
其中,诊察观察栏位O的内容为医生检查发现,包含诊察发现及各种检 查报告,例如记载医生观察到:病人有肚脐附近的疼痛、呕吐、右下腹部按 压痛、白血球增多等现象。
其中,诊断评估栏位A的内容为诊断评估,即诊断(Diagnosis)或臆断(Impression)。例如记载:病人可能罹患阑尾炎。
其中,处置治疗栏位P的内容为治疗计划,包含各种处置或处方,例如 切除阑尾。此外,多个医疗信息栏位进一步分为关联于门诊模型的医疗信息 栏位及关联于住院模型的医疗信息栏位,其中,住院模型的医疗信息栏位内 容包含病人半年内的其余文字报告(会诊、病理、手术、检查),门诊模型的 医疗信息栏位包含病人主诉栏位S、诊察观察栏位O、诊断评估栏位A及处 置治疗栏位P至少其中之一。电子装置10填写或代入当前病人相关的医疗 信息栏位的内容。
于步骤220中,电子装置10传送至少一部分的医疗信息栏位的内容。
于一实施例中,电子装置10通过传输界面11传送的医疗信息栏位内容 包含一病人主诉栏位内容(例如病人主诉栏位S的内容)、一诊察观察栏位内 容(例如诊察观察位O的内容)及一诊断评估栏位内容(例如诊断评估栏位A 的内容)。
于步骤230中,服务器20的传输界面15接收至少一部分的医疗信息栏 位的内容,通过一处理器16依据至少一部分的医疗信息栏位的内容产生一 优化报告。
于一实施例中,服务器20通过传输界面15接收的医疗信息栏位内容包 含病人主诉栏位内容、诊察观察栏位内容及诊断评估栏位内容。
于一实施例中,服务器20通过处理器16依据至少一部分的多个医疗信 息栏位内容进行一内容优化,以产生优化报告。
于一实施例中,服务器20的处理器16将病人主诉栏位内容、诊察观察 栏位内容及诊断评估栏位内容进行内容优化。
于一实施例中,内容优化包含通过一缩写还原应用程序界面(ApplicationProgramming Interface,API),将至少一部分的多个医疗信息栏位内容中的缩 写改成全名;其中,至少一部分的多个医疗信息栏位内容通过一错字修正建 议应用程序界面,将错字自动改成正确文字或接收校正错字的一校正文字, 以产生优化报告。
于一实施例中,内容优化包含将该病人主诉栏位内容、诊察观察栏位内 容及诊断评估栏位内容各自通过一缩写还原应用程序界面,将病人主诉栏位 内容、诊察观察栏位内容及诊断评估栏位内容中的缩写改成全名。
于一实施例中,病人主诉栏位内容、诊察观察栏位内容及诊断评估栏位 内容各自通过一错字修正建议应用程序界面,将错字自动改成正确文字或接 收校正错字的一校正文字,以产生该优化报告。
例如,服务器20传送包含病人主诉栏位内容、诊察观察栏位内容及诊 断评估栏位内容的文本给电子装置10,此文本中针对不确定的字词(例如错 字、缩写还原)提供一些候选字词,供医生选择,待医生确认文本的内容完整 无误后,电子装置10再将文本回传服务器20,此时的文本为优化报告。
由于每位医师针对病历会有自己不同的撰写风格,医师时常在病历当中 以疾病缩写的方式记录,然而,每个科别或每位医师的缩写习惯不同、歧异 性很大,同时,医师面对繁忙的临床工作,能够编写医嘱的时间有限,往往 会在病历的文字内容中发现一些错别字,如果希望根据医师写的医嘱内容, 通过应用模型18输出对应的第十版国际疾病统计分类(International Classification of Disease,ICD),后称ICD-10代码,进而降低医院疾病分类 师的工作负担,文字病历的内容品质是相当重要的。
因此通过步骤230,协助医师在撰写病历时能够有缩写还原及错别字修 正建议辅助,方能让医师在有限的时间内产出高品质内容的优化后的病历报 告(即优化报告),避免被退件重新修改撰写,同时高品质的病历使应用模型 18的准确率亦能有所提升。于一实施例中,服务器20传送优化后的病人主 诉栏位内容、诊察观察栏位内容及诊断评估栏位内容的文本给电子装置10, 电子装置10于显示器13显示优化后的病历报告(即优化报告),或是将各栏 位中的内容更新为优化后的内容。
于步骤240中,服务器20通过处理器16将优化报告输入一应用模型18, 应用模型18输出对应优化报告的多个诊断码。
于一实施例中,应用模型输出对应该优化报告的所述诊断码符合第十版 国际疾病统计分类(ICD-10)的一疾病分类编码规则;其中,该疾病分类编码 规则针对多个疾病诊断及多个预测编制大于60000个对应所述诊断的诊断码 及所述预测的诊断码。
于一实施例中,应用模型18是以一基于变换器的双向编码器表示技术 的卷积神经网络(Bidirectional Encoder Representations from Transformers-ConvolutionalNeural Networks,BERT-CNN)实现,后称 BERT-CNN。然而,此为一例,应用模型18可以由其他能够产生字汇向量 或权重的卷积神经网络实现。
请参阅图3中的诊断码表单CM,当服务器20通过处理器16将优化报 告输入应用模型18(例如BERT-CNN),应用模型18输出对应优化报告的多 个诊断码。这些诊断码代表依据优化报告,应用模型18输出与优化报告相 关的诊断结果。于一实施例中,服务器20传送这些诊断码至电子装置10, 并显示对应这些诊断码的诊断码表单CM于显示器13。
由于诊断结果的叙述(如英文/中文名称栏位)较为冗长,熟练ICD-10诊 断码的医生可以快速通过诊断码勾选病人符合的一或多个诊断结果。另一方 面,尚未熟练ICD-10诊断码的医生仍可以通过英文/中文名称栏位勾选病人 符合的一或多个诊断结果。
请参阅图4,图4是依照本发明实施例绘示一种应用模型的示意图。图 4是依照本发明实施例绘示一种应用模型18的示意图。图4中的应用模型 18采用BERT-CNN的架构,BERT-CNN为近年来在自然语言处理(Natural Language Processing,NLP)领域较为当代先进(State-Of-The-Art,SOTA) 的两阶段迁移式学习,分别为:预训练(Pre-training)与微调(Fine-Tuning)。
在预训练阶段,预先使用大量医疗生技相关的文本资料(如病人主诉栏位 内容、诊察观察栏位内容及诊断评估栏位内容、医疗生技相关的论文、报纸、 期刊),以非监督式学习的方式训练一个语言模型(即应用模型18)。
在微调阶段则是针对诊断码的分类任务,以有类别标签的资料训练、对 应用模型18进行监督式学习来微调参数,进而对新的资料做预测,其中的 类别标签就是ICD-10代码。通过这样的训练方式,能让应用模型18理解病 历中上下文的内容关系,学习医师撰写的病人病况描述与病人历史记录,训 练出一个具备医学知识的应用模型18,准确建立病历与诊断码间的连结,精 准推荐诊断码。
其中,自我注意力(Self Attention)为临床(Clinical)BERT-CNN训练应用模 型18执行的重要机制,以“This patient has heart disease”为例,进行 Self-Attention时有下列步骤:(1)在分类任务中,以处理器16或手动将预测 用标签“[CLS]”符号插入到每个句子的开头(如图4的转换层L1、L12的第一 栏所表示)。自我注意力机制的目的是理解文字意义,并预测对应的类别(例 如,类别为ICD-10诊断码),此机制固定会在文字的最前端以处理器16或手 动加入标签“[CLS]”作为后续预测的依据。
(2)将每个词汇转换为词嵌入(Word Embedding):此步骤会将所有词汇转 换成相同维度的向量(每种模型架构会有不同的维度,Clinical BERT为768 维度),每个词汇的向量皆不相同,应用模型18预先定义好这些词汇的向量 值。
(3)根据上下文来更新每个词汇的词嵌入:每一个词汇在应用模型18中 需要经过12次的转换(于此例中,以12个转换层(transformer layer)L1~L12 为例),每层接受一组词向量(Word Embedding)作为输入,并产生相同数目的 词向量作为输出。每次转换后会得到不同的词向量,应用模型18会参考上 下文的内容决定转换后的向量数值,且根据上下文语意的不同,参考的比重 也各不相同,而应用模型18将会在学习的过程中,自动调整这些权重。于 一实施例中,所有文字经过12次转换后,使用预测用标签“[CLS]”进行预测 最后一层转换后的输出,只有第一个向量(对应到“[CLS]”符号)会输入到分类 器中,将“[CLS]”的向量以线性回归(Linear Regression)分类方法预测ICD-10 诊断码。在自我注意力的预测机制中,应用模型18会根据上下文的内容调 整参考的权重,由于是通过“[CLS]”标签的向量进行预测,通过观察“[CLS]” 所参考的权重值可以了解「模型进行预测时,主要参考哪些词汇」。
以图4为例,最终的“[CLS]”会得到6个权重,这些权重是“[CLS]” 标签分别参考“[CLS]”,“This”,“patient”,“has”,“heart”,“disease” 的权重。如下表一所示:
表一
通过将这些权重值进行视觉化,权重越重则绘制更深的颜色,反之则不 上色,即可针对模型预测时所关注的重点进行特征萃取,并得到热图(heatmap) 视觉化结果,此将于步骤250详述。
换言之,如表一与图4所示,BERT-CNN依据优化报告的内容的上下文 决定多个词向量,处理器16依据BERT-CNN各层中被事先定义的多个字词 特征进行特征萃取,以萃取出所述词汇,所述词向量经过BERT-CNN的一 分类层CL后,分类层CL对应每个词向量输出各自对应的所述权重。
于一实施例中,服务器20的处理器16将病人主诉栏位内容、诊察观察 栏位内容及诊断评估栏位内容输入BERT-CNN后,可得到关于所述内容的 多个诊断码(例如ICD-10诊断码),处理器16依据所述权重由大到小排序对 应所述权重的所述诊断码,以产生一诊断码列表,并选取前面一定数量的诊 断码(例如前十个)供医生参考。
于步骤250中,通过处理器16依据该优化报告中的多个词汇各自对应 的多个权重产生一热图(heatmap),并通过处理器16通过使用者界面显示热 图。
请参阅图5,图5是依照本发明一实施例绘示一种热图的示意图。如图 5所示,处理器16在优化报告中以不同颜色标注所述权重各自对应的所述词 汇,以产生热图。例如,将权重较大的词汇用较深的颜色标注,将权重较小 的词汇用较浅的颜色标注。于一实施例中,权重的标注色彩的深度至浅度是 依据权重由大至小作对应。
借此,阅读者(例如医生)在不阅读所有文章(例如病人主诉栏位S、诊察 观察栏位O、诊断评估栏位A及处置治疗栏位P)的前提下,通过视觉化标注 词汇色彩的方式,能够快速聚焦在大批文章(病历相关文章)中的主要内容。
于一实施例中,处理器16更用以依据所述权重产生一文字云(word cloud),文字云是由各种字词组合成、如云一般的图形。文字云的存在目的 在于能让阅读者在不阅读所有文章的前提下,快速聚焦在大批文章中的主要 内容(例如权重最大的词汇,在文字云中的字体最大也最明显)。
由上述步骤可知,通过广泛收集医院过去的门诊、急诊及住院诊断结果 资料,其内容包含各病患ICD-10诊断码与门诊、急诊主客观描述或是住院 过程中的病摘和病程记录等文字医嘱内容,以及病患的检查、手术、会诊及 病理文字报告,将所述资料输入应用模型18,由应用模型18进行ICD-10 诊断码的分类推荐。
由于医师在门急诊看诊时输入的病人主诉栏位的内容、诊察观察栏位的 内容、诊断评估栏位的内容及一处置治疗栏位的内容与住院针对住院病人所 撰写的入院病摘(Admission Note)、病程记录(Progress Note)以及出院病摘 (Discharge Summary)其文字结构与内容差异性较大,因此在应用模型18训练 时根据使用情境的资料来源的不同分别训练建模,以确保诊断码分类的推荐 品质。
以下请参阅图6~图7,图6是依照本发明实施例绘示一种资料分析系统 应用于门诊或急诊情境的示意图。图7是依照本发明实施例绘示一种资料分 析系统应用于病人住院情境的示意图。
于一实施例中,在门诊或急诊的情境中(如图6所示),病人进入诊间(步 骤S1),处理器12将医师即时输入的病人主诉栏位S的内容(例如病人说喉 咙痛,一直吐)、诊察观察栏位O的内容(例如医生观察到病人发烧且血压异 常)、诊断评估栏位A的内容(例如医生判断食物中毒及/或肠胃炎)及处置治 疗栏位P的内容(例如开药及/或住院观察)与此病人半年内的其余文字报告 (会诊、病理、手术、检查)合并,以产生一合并资料,并将合并资料进行缩 写还原及错别字修正建议辅助,以产生优化报告(步骤S2),再由传输界面11 传送优化报告到服务器20,处理器16将优化报告输入到应用模型18,应用 模型18输出数个ICD-10诊断码的诊断码建议清单(步骤S3),其中,处理器 16依据所述权重由大到小排序对应所述权重的所述诊断码,以产生一诊断码 列表,例如,根据提供前10个最有可能的ICD-10诊断码供医师或疾分师来 做参考。通过文字资料视觉化方法(例如依权重标注字汇色彩、文字云)呈现 隐藏在文字内容中,应用模型18所认为的重要特征(步骤S4)。
于一实施例中,在病人已住院的情境中(如图7所示),病人住院(步骤S1’) 后,医院信息系统准备病人此次住院历程病历信息及病人住院病摘与病程记 录,合并病人半年内的其余文字报告(会诊、病理、手术、检查)结果为一历 史病历,处理器12将医师输入的住院记录及历史病历合并,以产生一合并 资料,并将合并资料进行缩写还原及错别字修正建议辅助,以产生优化报告 (步骤S2’),再由传输界面11传送优化报告到服务器20,处理器16将优化 报告输入到应用模型18,应用模型18输出数个ICD-10诊断码的诊断码建议 清单(步骤S3’),其中,处理器16依据所述权重由大到小排序对应所述权重 的所述诊断码,以产生一诊断码列表,例如,提供前10个最有可能的ICD-10 诊断码供医师或疾分师来做参考。通过文字资料视觉化方法(例如依权重标注 字汇色彩、文字云)呈现隐藏在文字内容中,应用模型18所认为的重要特征 (步骤S4’)。另一方面,在步骤S3’完成后,当诊断码被选择后(例如,医生选 择诊断码),处理器16输出诊断码对应的收费资料,及并发症与处置码,以提示信息供医师选择(步骤S5’)。
于一实施例中,医生以勾选诊断码表单CM其中多个选项的方式(被选择 的选项视为候选诊断码),借此以下指令给处理器16,使处理器16选择诊断 码列表CM中的多个候选诊断码,接收对应所述候选诊断码各自对应的一处 置资料,所述处置资料各自记录于一处置治疗栏位P。
于一实施例中,所述处置资料来自服务器20的存储装置17或电子装置 的存储装置14中所存储的历史记录,每个诊断码(例如肠胃炎的诊断码)对应 至少一个处置资料(例如开药、住院观察、打点滴)。
于一实施例中,处理器16选择诊断码列表中的多个候候选诊断码,依 据一历史记录产生对应所述候选诊断码各自对应的一费用资料,所述费用资 料各自记录于对应所述候选诊断码的一费用栏位。
于一实施例中,回应于处理器16接收对应所述候选诊断码各自对应的 处置资料后,处理器16依据对应处置资料或历史记录,产生对应所述候选 诊断码各自对应的费用资料,所述费用资料各自记录于费用栏位。
于一实施例中,采用资料分析系统及资料分析方法进行资料分析,时间 范围从2016年1月至2020年2月,门诊与急诊共有3,112,158笔看诊资料, ICD-10诊断码涵盖了12,732种不同类别;而住院共有83,441笔住院资料, ICD-10诊断码涵盖了3,772种不同类别的诊断码。为了避免过度拟合以及提 升模型泛化能力,以时间切分资料,将2016年至2019年资料作为训练集, 2020年1月至2月资料作为测试集来验证应用模型18准确率,门诊与急诊模型使用测试集验证的主诊断的前十笔预测诊断码的精准度为91.45%;住院 模型使用测试集验证主诊断的前十笔诊断码的精准度为89.35%。其中精准度 的计算方式为测试集的主诊断与模型所预测的十个诊断码耦合率(测试集主 诊断在十个预测诊断码的样本数/测试集总样本数)。
此外,上述应用模型18使用大量已标注的资料进行微调训练,所以应 用模型18目前能够预测的诊断码类别数可以正向表列为样本资料所涵盖的 范围。通过未来持续的提供搜集到的资料,资料量的增加能够持续的给予应 用模型18进行学习校正,能够预测的诊断码类别范围也会随之增加,应用 模型18的表现也会持续不断的精进,进而提升预测的准确率。
综上,资料分析系统及资料分析方法可以协助医师在撰写病历时能够有 缩写还原及错别字修正建议的辅助,以优化的病历报告,优化后的病历报告 输入一应用模型,使得应用模型能够将病历报告与诊断码间连结,输出精准 的推荐诊断码。诊断码的查找工作有了应用模型辅助后,医疗人员可以花更 多心思研究病历,包括病人做的检查、症状是否全反应在诊断上,是否有缺 失资料,且在不违反医疗原则下,如何依据对应候选诊断码各自对应的费用 资料,以提高健保给付,进一步提高了医疗的整体品质。
虽然本发明已以实施方式公开如上,然其并非用以限定本发明,任何熟 习此技艺者,在不脱离本发明的精神和范围内,当可作各种的更动与润饰, 因此本发明的保护范围当视后附的权利要求所界定者为准。