一种基于语法点进行检索的方法、装置及文心检索平台
文献发布时间:2023-06-19 18:46:07
技术领域
本发明涉及语言处理技术领域,特别是指一种基于语法点进行检索的方法、装置及文心检索平台。
背景技术
语料库作为一个收录各类型语言数据的综合性语言资源,在语言本体研究及语言应用领域(如语言教学、教材编写、词典编纂等方面)都发挥着非常重要的作用。随着语言数据积累的规模日益扩大与语料库技术发展的日益革新,国内外已建成了多种类型、多种规模的语料库以供不同研究目的的使用,也提供了多种语料库检索平台和工具,为语言学相关研究提供了更大规模的检索以及对语言系统性分析的可能性。
其中,语料库的建设是核心基础。语料库系统在为语言学研究提供翔实的语言证据的同时,其语料的加工方式与系统检索工具的功能性也限制着它在研究中的具体用途。“工欲善其事,必先利其器”。做好语料库建设工作,设计好语料库检索方式是开展基于语料库相关研究的前提。
相较而言,当前国内汉语语料库资源建设存在以下不足:检索方式普遍停留在句子的表层形式上,依靠关键字、词和词性匹配来进行检索约束,而较少地关注到句子深层的句法结构,面对涉及到句法成分、依存搭配等较为复杂的检索需求略显吃力;检索模式单一,检索功能的全面性与用户友好性难以兼顾。总的来说,目前汉语语料库的构建情况与日趋精细化、智能化、简洁化的检索需求不匹配,不利于基于语料库的语言研究的开展和相关研究工作的深入。
发明内容
本发明实施例提供了一种基于语法点进行检索的方法、装置及文心检索平台。所述技术方案如下:
一方面,提供了一种基于语法点进行检索的方法,该方法由电子终端实现,该方法包括:
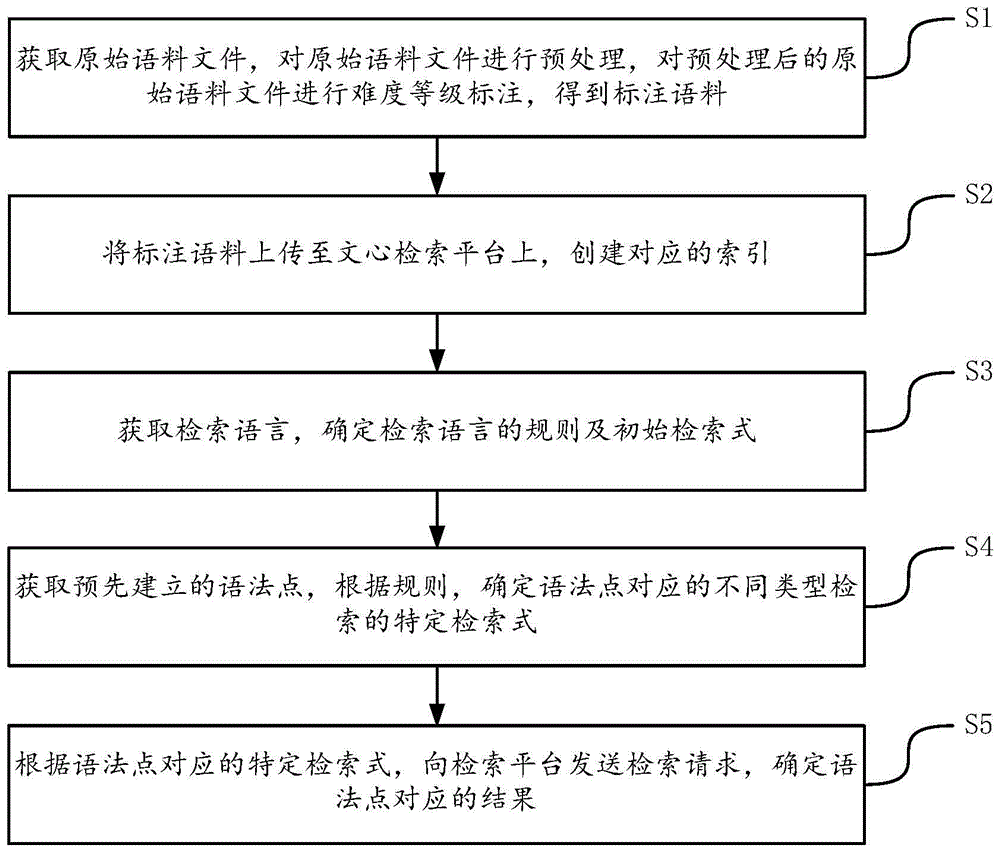
S1、获取原始语料文件,对所述原始语料文件进行预处理,对预处理后的原始语料文件进行难度等级标注,得到标注语料;
S2、将所述标注语料上传至文心检索平台上,创建对应的索引;
S3、获取检索语言,根据检索语言的规则确定所述检索语言对应的初始检索式;
S4、获取预先建立的语法点,根据所述规则,确定语法点对应的不同类型检索的特定检索式;
S5、根据所述语法点对应的特定检索式,向所述文心检索平台发送检索请求,确定语法点对应的结果。
可选地,所述对所述原始语料文件进行预处理,包括:
对原始语料文件进行分词、词性标注、命名实体识别以及依存句法分析操作。
可选地,所述初始检索式的构造模块包括:字符项、词性标签项、命名实体项、依存项、词语难度项以及复杂项六种构成形式。
可选地,所述不同类型检索包括普通类型检索以及模式检索。
可选地,所述普通检索包括基础检索、依存检索和捕获。
另一方面,提供了一种文心检索平台,其特征在于,所述文心检索平台包括VUE前端模块、Tornado后端模块、语料标注模块、Odinson后端模块;其中:
所述VUE前端模块,用于用户交互;
所述Tornado后端模块,用于接收前端用户请求,对请求做处理后,向所述Odinson后端模块发送检索请求,获取检索结果;
所述语料标注模块,用于对语料进行标注;
所述Odinson后端模块,用于提供检索服务,
所述Odinson后端模块包括构建索引子模块、检索字段设置子模块、parent query子模块以及检索服务子模块,其中:
所述构建索引子模块,用于运行检索后端服务;
所述检索字段设置子模块,设置的字段包括raw、word、tag、lemma、entity以及dependencies;
所述parent query子模块,用于检索制定类别的语料;
所述检索服务子模块,用于为Tornado后端模块提供检索服务。
另一方面,提供了一种基于语法点进行检索的装置,该装置应用于基于语法点进行检索的方法,该装置包括:
标注模块,用于获取原始语料文件,对所述原始语料文件进行预处理,对预处理后的原始语料文件进行难度等级标注,得到标注语料;
创建模块,用于将所述标注语料上传至文心检索平台上,创建对应的索引;
确定模块,用于获取检索语言,根据检索语言的规则确定所述检索语言对应的初始检索式;
建立模块,用于获取预先建立的语法点,根据所述规则,确定语法点对应的不同类型检索的特定检索式;
检索模块,用于根据所述语法点对应的特定检索式,向所述文心检索平台发送检索请求,确定语法点对应的结果。
可选地,所述对所述原始语料文件进行预处理,包括:
对原始语料文件进行分词、词性标注、命名实体识别以及依存句法分析操作。
可选地,所述初始检索式的构造模块包括:字符项、词性标签项、命名实体项、依存项、词语难度项以及复杂项六种构成形式。
可选地,所述不同类型检索包括普通类型检索以及模式检索,普通检索包括基础检索、依存检索和捕获。
另一方面,提供了一种电子设备,所述电子设备包括处理器和存储器,所述存储器中存储有至少一条指令,所述至少一条指令由所述处理器加载并执行以实现上述基于语法点进行检索的方法。
另一方面,提供了一种计算机可读存储介质,所述存储介质中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现上述基于语法点进行检索的方法。
本发明实施例提供的技术方案带来的有益效果至少包括:
通过依存句法来进行检索,即使是面对比较复杂的语法点或是包含距离较远的句法成分的语法点,也能够得到比较准确的结果;在检索时可以对词汇难度等级进行限制,帮助教师在检索时能充分考虑学生的汉语水平,检索到适合不同学生的例句,提高检索的针对性;捕获功能方便教师查看句中的不定成分,也能帮助教师更容易地查看词汇间的搭配和聚类。这些功能在教师检索例句时都起到了很大的帮助,提高了教师备课质量与效率,也能帮助教材或试卷编写提供丰富的用例。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例提供的一种文心检索平台的架构示意图;
图2是本发明实施例提供的一种基于语法点进行检索的方法流程图;
图3是本发明实施例提供的一种基于语法点进行检索的装置框图;
图4是本发明实施例提供的一种电子终端的结构示意图。
具体实施方式
为使本发明要解决的技术问题、技术方案和优点更加清楚,下面将结合附图及具体实施例进行详细描述。
本发明实施例提供了一种文心检索平台,如图1所示,文心检索平台可以包括VUE前端模块、Tornado后端模块、语料标注模块以及Odinson后端模块。下面分别对每个模块进行介绍:
1、VUE前端模块
一种可行的实施方式中,VUE是一套用于构建用户界面的渐进式框架,是一个JS框架,本发明实施中使用VUE前端模块可以向用户提供交互界面,方便用户输入检索语言以及查看检索结果。
2、Tornado后端模块
一种可行的实施方式中,Tornado是一个开源的、使用Python编写的Web服务器兼Web应用框架,可以提供websocket服务、长连接服务、HTTP短链接服务、UDP服务等,非常适合开发长轮询、WebSocket和需要与每个用户建立持久连接的应用。本发明实施例中使用Tornado后端模块,用于接收前端用户请求,对请求做处理后,向Odinson后端模块发送检索请求,获取检索结果。
3、语料标注模块
一种可行的实施方式中,语料标注模块采用Stanford CoreNLP标注工具对语料进行标注,Stanford CoreNLP标注工具可对语料进行分词,分句,词性标注,依存句法标注。标注后的语料以JSON数据格式组织,注明语料中的raw、word、tag、lemma、entity以及dependencies等字段。
4、Odinson后端模块,用于提供检索服务,
一种可行的实施方式中,Odinson后端模块是由Scala语言搭建的检索引擎,其优点在于除了基本的全文检索功能外,可提供对依存图的图检索。
Odinson后端模块包括构建索引子模块、检索字段设置子模块、parent query子模块以及检索服务子模块,其中:
构建索引子模块,用于使用标注好的语料构建可供检索引擎检索的倒排索引;
检索字段设置子模块,设置的字段包括raw、word、tag、lemma、entity以及dependencies;
parent query子模块,用于检索制定类别的语料;
检索服务子模块,用于为Tornado后端模块提供检索服务。
使用该文心检索平台时,前期需要使用语料标注模块对待检索语料进行标注,Odinson后端模块使用标注好的语料构建倒排索引,以待检索;用户在终端使用该文心检索平台时,用户在终端上输入由检索语言构成的检索表达式,VUE前端模块接收用户的输入,将用户检索语句发送向Tornado后端,当用户检索请求为普通检索时,将检索语句直接发送向Odinson后端,当用户检索请求为高级检索时,Tornado后端将对检索语句进行依存分析,提取出用户想要检索的依存路径后构造用于Odinson检索的检索表达式,然后将检索表达式发送向Odinson后端请求检索,Odinson后端对检索表达式进行检索后,将检索结果返回给Tornado后端,Tornado后端对检索结果做进一步处理,将检索结果处理为VUE方便显示的数据格式后,将结果返回给VUE前端,展示给用户。
本发明实施例提供了一种基于语法点进行检索的方法,该方法可以由电子终端实现,该电子终端可以是终端或服务器。如图2所示的基于语法点进行检索的方法流程图,该方法的处理流程可以包括如下的步骤:
S1、获取原始语料文件,对原始语料文件进行预处理,对预处理后的原始语料文件进行难度等级标注,得到标注语料。
其中,原始语料文件可以是纯文本格式的文件,预处理操作可以包括但不限于对原始语料文件进行分词、词性标注、命名实体识别、依存句法分析等操作。
一种可行的实施方式中,原始语料文件的类型可以包括两大类:新闻报刊语料和二语教材语料,具体语料规模如下表1中所示。
表1
原始语料完成断句后,可以使用自然语言处理工具对句子进行预处理。分词及词性标注可以采用宾州中文树库CTB的词性标注体系(Xue et al.,2005),命名实体识别可以使用Stanford NER(Finkel et al.,2005),句法标注可以采用斯坦福大学的依存句法标注规范(De Marnee et al.,2010)。
完成预处理后,对预处理后的原始语料文件进行难度等级标注,难度等级标注可以采用人工标注,也可以采用现有的标注模型进行标注,本发明实施例对此不作限定。
S2、将标注语料上传至检索平台上,创建对应的索引。
一种可行的实施方式中,本发明实施例中的检索平台是预先构建的文心检索平台,该平台的构建理念可以如下:
(1)服务于语言教学与研究。一方面,可为教师提供相应的例句参考,可以解决以往选择例句困难的问题;另一方面,可为汉语学习者提供延展学习的例句,学习者可以通过“捕获”功能学习汉语词汇最常出现的语境、语用、搭配等知识。
(2)充分利用依存句法信息。用户不仅可以对字和词进行检索,还可以约束它们的词性、命名实体类型与依存关系。
(3)强大的检索功能与简洁的检索语言。文心语料库检索系统定义一种用户友好且功能强大的语料库检索语句,旨在提供高度准确的检索结果,同时保持检索语言的简洁。
该文心检索平台可以具体包括如下检索方式:
(1)普通检索,通过文心语料库检索式实现检索,支持正则表达式。包括基础检索、依存句法检索及捕获。
(2)模式检索,模式检索不需要用户知道底层语法表示的细节,而是通过提供一个加有简单标记的示例句子来进行查询。
需要说明的是,创建检索的方式可以采用现有技术中常用的创建方式,本发明实施例对此不做赘述。
S3、获取检索语言,确定检索语言的规则及初始检索式。
一种可行的实施方式中,检索语言可以是用户输入的检索式,用户在输入过程中,输入的数据可能包括待检索的词语、操作符、量词等单元,这些单元共同构成检索语言。
其中,初始检索式的构造模块包括:字符项、词性标签项、命名实体项、依存项、词语难度项以及复杂项六种构成形式,这六项可以作为检索的附加条件,由用户按照需求选择一项或多项,结合需要检索的文字,共同构成初始检索式。
具体地,初始检索式的构成形式分为基本项与复杂项两种,基本构成单元包括字符串、词性标签、依存标签、词语难度标签、命名实体名称、操作符以及量词。具体检索语言的规则,即检索式的构成形式及示例在表2中列出。
表2
为帮助理解规则,或者说上述检索式中符号的含义和用法,表3结合检索示例对所有符号的具体含义进行了说明。
表3
需要说明的是,根据上述步骤构建初始检索式的过程,可以将规则输入到电子设备中,用户在电子设备中输入想要检索的文字、以及检索的条件,由电子设备自动生成初始检索式;也可以由用户掌握规则,然后按照规则以及想要检索的文字、检索的条件构建初始检索式,将构建好的初始检索式输入到电子设备中。
S4、获取预先建立的语法点,根据规则,确定语法点对应的不同类型检索的特定检索式。
其中,不同类型检索包括普通类型检索以及模式检索,普通检索包括基础检索、依存检索和捕获。普通检索,检索式使用正则表达式以及逻辑操作符、依存关系操作符等构成;模式检索,检索式即为例句以及带有符号标记的锚点与需要捕获的内容。
一种可行的实施方式中,语法点是归纳总结《国际中文教育中文水平等级标准》(2021)《语法等级大纲》写成的汉语国际教育领域中的汉语教学语法点。对《语法等级大纲》进行重构,获得既可以反映语法大纲体系、又便于自动抽取的语法点,通常来讲,可以构建出500多个通用的语法点。根据规则逐一撰写汉语语法点的特定检索式。特定检索式类型及具体实例在表4中列出:
表4
S5、根据语法点对应的特定检索式,向检索平台发送检索请求,确定语法点对应的结果。
一种可行的实施方式中,读入预先构建好的语法点检索式,通过云服务的方式调用已存检索式,逐一向检索平台发送对应语法点检索式的检索请求,检索平台检索并返回所有包含对应语法点的匹配结果。
优选地,上述匹配结果以原始语料文件(纯文本格式)中的一个自然句为单位输出显示。查询结果中,被检索项会被加粗显示。模式检索中,锚点词将被加粗显示。此外,检索结果页面右上角位置有“结果下载”按钮,用户可指定下载的检索结果条数(默认为50条)与文件名,点击“结果下载”按钮,可将查询结果以本文文件(*.txt)格式保存至本地电脑。每句之后注明该句所在篇章名、日期等信息。
需要说明的是,在使用文心检索平台进行检索时,用户可以选择需要检索的语料类型,然后按照预先构建好的语法点,自动在语料中抽取语法点对应的检索结果;如果用户想要检索的内容不在预先构建好的语法点的范围内,也可以自行构建检索式,然后在文心检索平台上进行检索,本发明对此不作限定。
本发明实施例中,通过依存句法来进行检索,即使是面对比较复杂的语法点或是包含距离较远的句法成分的语法点,也能够得到比较准确的结果;在检索时可以对词汇难度等级进行限制,帮助教师在检索时能充分考虑学生的汉语水平,检索到适合不同学生的例句,提高检索的针对性;捕获功能方便教师查看句中的不定成分,也能帮助教师更容易地查看词汇间的搭配和聚类。这些功能在教师检索例句时都起到了很大的帮助,提高了教师备课质量与效率,也能帮助教材或试卷编写提供丰富的用例。
图3是根据一示例性实施例示出的一种基于语法点进行检索的装置框图。参照图3,该装置包括:
标注模块310,用于获取原始语料文件,对所述原始语料文件进行预处理,对预处理后的原始语料文件进行难度等级标注,得到标注语料;
创建模块320,用于将所述标注语料上传至文心检索平台上,创建对应的索引;
确定模块330,用于获取检索语言,根据检索语言的规则确定所述检索语言对应的初始检索式;
建立模块340,用于获取预先建立的语法点,根据所述规则,确定语法点对应的不同类型检索的特定检索式;
检索模块350,用于根据所述语法点对应的特定检索式,向所述文心检索平台发送检索请求,确定语法点对应的结果。
可选地,所述标注模块310,用于:
对原始语料文件进行分词、词性标注、命名实体识别以及依存句法分析操作。
可选地,所述初始检索式的构造模块包括:字符项、词性标签项、命名实体项、依存项、词语难度项以及复杂项六种构成形式。
可选地,所述不同类型检索包括普通类型检索以及模式检索,普通检索包括基础检索、依存检索和捕获。
本发明实施例中,通过依存句法来进行检索,即使是面对比较复杂的语法点或是包含距离较远的句法成分的语法点,也能够得到比较准确的结果;在检索时可以对词汇难度等级进行限制,帮助教师在检索时能充分考虑学生的汉语水平,检索到适合不同学生的例句,提高检索的针对性;捕获功能方便教师查看句中的不定成分,也能帮助教师更容易地查看词汇间的搭配和聚类。这些功能在教师检索例句时都起到了很大的帮助,提高了教师备课质量与效率,也能帮助教材或试卷编写提供丰富的用例。
图4是本发明实施例提供的一种电子终端400的结构示意图,该电子终端400可因配置或性能不同而产生比较大的差异,可以包括一个或一个以上处理器(centralprocessing units,CPU)401和一个或一个以上的存储器402,其中,所述存储器402中存储有至少一条指令,所述至少一条指令由所述处理器401加载并执行以实现上述基于语法点进行检索的方法的步骤。
在示例性实施例中,还提供了一种计算机可读存储介质,例如包括指令的存储器,上述指令可由终端中的处理器执行以完成上述基于语法点进行检索的方法。例如,所述计算机可读存储介质可以是ROM、随机存取存储器(RAM)、CD-ROM、磁带、软盘和光数据存储设备等。
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。