一种分布式信号数据分析系统
文献发布时间:2023-06-19 19:28:50
技术领域
本发明属于信号分析技术领域,涉及一种分布式信号数据分析系统。
背景技术
信号分析与处理技术正在不断发展,应用于很多场景,比如设备故障诊断和监测、分析设备干扰因素等。随着信息技术的不断发展和信息技术应用领域的不断扩展,使得信号分析领域进入到大数据时代,信号采集数据增长率已经远超高数据存储增率和信号分析速度增长率,逐渐暴露出很多问题。在大数据背景下,数据信号量持续增加,高速的信号分析面临极大的挑战。
Spark是专为大规模数据处理而设计的快速通用的分布式计算引擎。其包含SparkSQL、Spark Streaming、MLlib和Graphx等模块,可用于ETL分析、在线数据分析、流计算、机器学习和图计算等场景。
Arrow定义了一种在内存中表示Tabular Data的格式,同时定义了IPC格式,序列化内存中的数据,进行网络传输,让数据在不同的进程之间进行交换。
Python中有许多现成的信号数据分析模块,是信号分析领域中最有利的工具之一。现有的数据场景下,信号数据分析人员对于信号数据的分析使用编程语言大多是Python。但是由于信号数据量通常是庞大的,分析处理是在单机资源下运行,导致其常常面临的困难就是计算资源不足的问题,限制了信号分析在大数据场景下使用的便利性以及通用性。大多数机构都部署大量的集群资源,单机信号分析场景下,并未充分利用集群资源,造成资源闲置。
发明内容
本发明的目的是提供一种分布式信号数据分析系统,为了解决单机大数据信号分析时资源不足以及效率低下的问题,本发明借助Spark的分布式运行框架以及Arrow作为Spark与Python的数据通信格式,实现分块调用Python信号分析算法。
本发明所采用的技术方案是,一种分布式信号数据分析系统,包括:
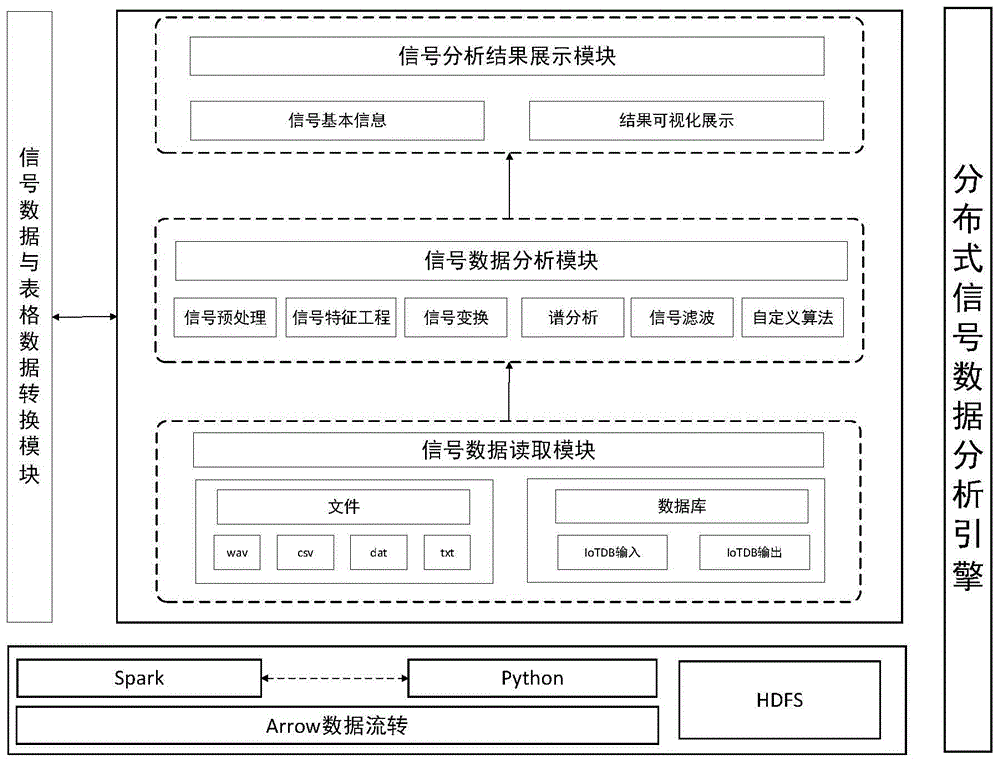
信号数据读取模块,信号数据读取模块包括有HDFS,HDFS搭载分布式计算引擎,信号数据读取模块基于HDFS从信号文件或数据库中的分布式提取数据,将数据分布式读取为信号数据,实现离线的信号数据的IO加速;
信号数据与表格数据转换模块,用于将信号数据借助Arrow通信转换为信号DataFrame;
信号数据分析模块,用于通过Arrow序列化和反序列化来实现Spark和Python间的数据通信,并基于动态内存加载的信号分析函数引用机制实现分块调用信号分析函数。
本发明的特点还在于:
步骤1中的数据的格式包括有wav、txt、dat和csv的信号文件以及IoTDB数据库。
HDFS通过分布式计算引擎中预设算法获取wav、txt、dat和csv格式的信号文件以及IoTDB数据库中的信号数据,构造信号DataFrame;
分布式计算引擎中通过重构Python端中的scipy和pandas方法,分别实现读取wav、txt、dat和csv信号文件的接口,将文件读取为Pandas.DataFrame格式进而转换为信号DataFrame;利用Spark读取IoTDB数据库中的信号数据,实现Python端数据结构转换的接口,进而转换为信号DataFrame。
信号数据分析模块在Spark端根据本地信号文件的信息,构造DataFrame结构,得到信号DataFrame,每行为一个信号。
信号通过分布式计算引擎接口将本地信号文件或数据库中的分布式提取数据并行上传到分布式计算引擎中,然后在各信号DataFrame分区中;
根据信号信息从信号中拉取信号文件到各计算节点,并在Python端实现对信号的读取,通过Arrow对数据进行回传,进而实现信号DataFrame的构造。
信号包含信号存储路径及信号名称信息。
信号分析函数引用机制为,通过Arrow序列化和反序列化来让分布式计算引擎和HDFS的数据进行通信,并加载信号分析函数对所得的信号DataFrame进行分析。
Spark获取到信号数据之后,构建单个信号分析算法脚本,单个信号分析算法脚本为Python脚本的字符串形式,通过Spark的DataFrame数据分区执行单个信号分析算法脚本。
每个信号DataFrame分区分别启动各自的Python进程,结合动态内存加载机制,将自定义信号分析算法加载为Python标准模块。
信号分析函数包括信号预处理、信号特征工程、信号变换、谱分析以及信号滤波五大算法模块以及自定义算法调用模块。
本发明的有益效果是:
1、本分明为了解决单机大数据信号分析时资源不足以及效率低下的问题,本发明借助Spark的分布式运行框架以及Arrow作为Spark与Python的数据通信格式,实现分块调用Python信号分析算法。
2、本发明在信号文件读取过程中,通过对不同格式信号文件的接口实现,可实现分布式文件读取,由于可利用集群资源,相对于单机下的信号文件读取效率更高。
附图说明
图1是本发明整体模块示意图。
图2是本发明整体的技术架构图。
图3是本发明中数据流转示意图。
图4是本发明中信号文件读取过程示意图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进。这些都属于本发明的保护范围。
为了解决单机大数据信号分析时资源不足以及效率低下的问题,本发明借助Spark的分布式运行框架以及Arrow作为Spark与Python的数据通信格式,实现分块调用Python信号分析算法,本发明一种分布式数据分析引擎,如图1所示,包括:
信号数据读取模块,信号数据读取模块包括有HDFS,所述HDFS搭载分布式计算引擎,信号数据读取模块基于HDFS从信号文件或数据库中的分布式提取数据,将数据分布式读取为信号数据,实现离线的信号数据的IO加速;
信号数据与表格数据转换模块,用于将所述信号数据借助Arrow通信转换为信号DataFrame;
信号数据分析模块,用于通过Arrow序列化和反序列化来实现Spark和Python间的数据通信,并基于动态内存加载的信号分析函数引用机制实现分块调用所述信号分析函数;
信号分析结果展示模块,信号分析结果展示模块用于将信号数据分析模块得出的结果进行图像化展示。
如图2和图3所示,为本发明整体的技术架构图和数据流转图。基于通过Arrow组件建立起与Python端数据传输的桥梁。Spark端与Python端的数据转换是基于Arrow,主要是将Spark端的数据转化为Python可用的数据,Arrow主要是加速两者数据的转换,也就是提高存储效率。
首先,获取信号数据。通过Spark分布式调用Python脚本获取wav、txt、dat和csv格式的信号文件以及IoTDB数据库中的信号数据,构造信号DataFrame。其数据格式为:“name”为文件名,类型为String;“start_time”为信号产生的时间日期,类型为String;“sample_rate”为信号的采样率,类型为Float;“signal_data”为信号数据,类型为Array[Double];“signal_length”为信号长度,类型为Int;“is_Complex”为实复数标志,类型为String。
为了加速IO过程,在读取时采用基于HDFS的方式实现,具体见图4。在Spark端根据本地信号文件的信息,构造DataFrame结构,每行为一个信号,信号包含信号存储路径及信号名称信息,同时通过HDFS接口将本地文件并行上传到HDFS中;然后在各DataFrame分区中,根据信号信息从HDFS中拉取信号文件到各计算节点,并在Python端实现对信号的读取,通过Arrow对数据进行回传,进而实现信号DataFrame的构造。
分布式计算引擎中通过重构Python端中的scipy和pandas方法,分别实现读取wav、txt、dat和csv信号文件的接口,将文件读取为Pandas.DataFrame格式进而转换为信号DataFrame;利用Spark读取IoTDB数据库中的信号数据,实现Python端数据结构转换的接口,进而转换为信号DataFrame。
其次,信号数据分析过程。具体信号分析函数在Python端实现并提供调用接口,包括:信号预处理(信号分割函数、信号重采样)、信号特征工程(信号特征提取、变点检测、信号相似度)、信号变换(模糊函数、希尔伯特变换、傅里叶变换、逆傅里叶变换、变分模态分解、小波变换、S变换、经验模态分解、希尔伯特黄变换、Wigner-Ville分布)、谱分析(相位谱、阶比包络分析、功率谱、互功率谱、全息谱、幅频谱)以及信号滤波(维纳滤波、自适应滤波、巴特沃斯滤波)五大算法模块以及自定义算法调用模块。
结合图2所示,Spark端获取到信号数据之后,构建单个信号分析算法脚本,其为Python脚本的字符串形式,通过Spark的DataFrame数据分区执行Python分析脚本,每个分区分别启动各自的Python进程,结合动态内存加载机制,将自定义信号分析算法加载为Python标准模块,以提供Python分析脚本进行调用。其中动态内存加载机制如图3,由于自定义分析算法间可进行相互调用,故采用先编译后加载的方式实现,进而调用集群中的各个节点资源进行分析,最后汇总所有节点结果,返回信号分析结果。
如图3所示,为Spark端调用Python信号分析算法数据流图。Spark的DataFrame信号结构数据,每个分区中包含一个或多个信号数据。信号分析脚本通过IO流进行传输、分区数据通过Arrow进行序列化,传输到Python端生成Pandas的DataFrame。同时启动Python进程,通过动态内存加载机制加载自定义算法,进而实现信号分析脚本的执行,分析结果中数据部分通过Arrow传回Spark端并反序列化为RDD的Row格式,列名、模型表格信息等则通过IO流进行回传。Spark端接收到RDD数据后,根据定义的Schema生成DataFrame,为最终结果。
最后,信号分析结果展示以及信号数据与表格数据格式的转换。为了信号分析的结果更直观的展示,构建信号数据以及分析结果图像化洞察组件。数据之间格式的转换可将信号数据与常规的表格数据格式相互转换,转换方式与信号分析模块采用相同的策略。为后续采用机器学习算法对信号数据进行分析,提供了接口。
上述方案的设计避免了单机计算信号数据,整个过程充分调用了Spark集群资源,能够避免单机计算海量信号数据时面临的资源不足的问题,同时提高对海量信号数据分析的执行效率。
实施例1
本实施例利用该引擎通过对某工厂设备信号数据文件的分析,分析该设备是否存在故障,具体按实施过程如下:
需要说明的是,该设备中存在25个信号采集点,文件格式为wav,分析某个时间段内的数据。搭建的集群环境,其中包含5台DataNode和1台NameNode。
第一步,通过分析引擎中信号数据读取模块读取25个信号文件,获取信号DataFrame;
第二步,通过分析引擎中信号数据分析模块对获取的数据进行分析,分别采用信号特征提取获取信号数据特征,采用傅里叶变换以及变点检测算法对信号异常点进行收集;
第三步,通过分析引擎中信号分析结果展示模块,对以上的结果进行可视化展示;
第四步,通过分析引擎中信号数据与表格数据转换模块将以上分析得到的数据转换为表格数据,进而利用机器学习分类算法,对数据进行分析,结合图像分析,最终的到该设备是否存在故障的结论。
整个过程为标准的设备故障检测流程,对比传统的单机下的分析,在该集群资源的配置下,整个过程可提升5倍的时间,同时避免资源不足的缺陷。