基于不均衡数据的行星齿轮故障预测方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及一种机械设备故障预测领域,尤其涉及基于不均衡数据的行星齿轮故障预测方法。
背景技术
行星齿轮是旋转机械的关键部件之一,在工业生产中得到了广泛应用,它的运行状况不仅影响其自身的运转,而且还会对相关的机械设备产生直接的影响。如果行星齿轮出现故障,轻则会影响机械设备的正常运行,重则会造成重大的经济损失,甚至出现毁机事故和人员伤亡。然而,行星齿轮在产生故障初期,由于故障程度轻微,往往难以被人们察觉,因发现不及时,极易引起停机或设备损坏,由此引发一系列事故;因此,对行星齿轮的故障进行预测尤为重要,通过对行星齿轮的状态监测和故障预测,可以及时发现由行星齿轮故障引起的设备隐患,能够有效防止事故发生,并为企业节省成本。
机器学习作为一种主流的智能数据分析处理技术,因其强大的功能为解决此类问题提供了一种有效途径,尤其是其中的分类算法能有效利用数据集构建一个具有较强泛化能力的分类模型,从而提取数据中的有用信息,因此成为目前国内外学者们的研究重点。现有技术采用基于机器学习的行星齿轮故障预测方法有神经网络、决策树、K-近邻和支持向量机等。
Bangalore[1]等人提出了一种基于人工神经网络的状态检测方法,该方法利用了监控系统和数据采集系统的数据对齿轮可能磨损的早期迹象进行有效的预测,从而降低总体维护成本;薛璇怡[2]等人针对传统的机器学习方法在行星齿轮故障诊断方面存在识别率低、特征提取操作繁琐等问题,提出了基于一维深度卷积神经网络(1-DCNN)的故障诊断方法,将原始信号直接输入到网络中进行诊断,整个过程将特征提取与自动识别相结合,实现了完全的智能诊断;姚立纲[3]等人利用樽海鞘群优化变分模态分解(SSO-VMD)对信号进行分解与重构;然后,从多域提取故障特征,并采用改进监督型自组织增量学习神经网络界标点等度规映射(ISSL-Isomap)进行降维处理。最后,运用人工蜂群优化支持向量机(ABC-SVM)分类器进行诊断识别,该发明能够有效识别出各故障类型,具有很大的实用价值;王亚萍[4]等人利用自编码器降噪网络对收集到的原始数据进行降噪处理,然后对降噪后的数据进行降维处理以获取特征矩阵中各数据之间的无向图,最后将其输入半监督图卷积神经网络故障诊断模型中得到最终的诊断结果,该发明能够对行星齿轮故障进行准确诊断。
然而,上述的研究都未能考虑到数据样本不均衡的情况。在实际应用中,故障样本的收集工作十分困难,故障样本往往可遇不可求,通常收集到故障样本数要远远小于正常样本数,从而导致训练样本不均衡,此外,由于上述因素影响,所收集到的故障样本内部也会出现分布不均问题,面对这种故障样本与正常样本比例失衡、故障样本内部分布不均的情况,传统的故障诊断算法往往表现不佳,因此本发明针对上述问题,设计了一种基于不均衡数据的行星齿轮故障预测方法来解决这种类间类内不均衡数据状况的行星齿轮故障预测问题。
[1]Bangalore P,Tjernberg L B.An artificial neural network approachfor early fault detection of gearbox bearings[J].IEEE Transactions on SmartGrid,2015,6(2):980-987.
[2]薛璇怡,庞新宇.基于1-DCNN的行星齿轮箱故障诊断[J].机械传动,2020,44(11):127-133.
[3]姚立纲,王振亚,蔡永武,王博.一种行星齿轮箱故障诊断方法[P].福建省:CN111238807A,2020-06-05.
[4]王亚萍,曹若凡,王博,许迪,张盛.基于半监督图卷积的行星齿轮箱故障诊断方法[P].黑龙江省:CN115017955A,2022-09-06.
发明内容
本发明的目的在于针对行星齿轮故障预测研究中存在的类间、类内子集群数量、密度、形状各不相同的现象以及重叠噪声点难以处理的问题提出一种行星齿轮故障预测方法。
本发明的目的可以通过采用如下技术方案达到:
基于不均衡数据的行星齿轮故障预测方法,该方法包括如下步骤:
S1:获取行星齿轮的原始振动信号并且采用形态平均滤波对其进行降噪处理;
S2:对降噪后的振动信号片段利用小波包获取训练样本振动信号的高维频谱特征数据集;
S3:通过TSNE方法对获取的高维频谱特征数据集进行降维处理,获得低维特征数据集;
S4:采用基于SVDD模型和DPC技术的不均衡分类算法对行星齿轮故障预测模型进行训练,利用训练后的行星齿轮故障预测模型对行星齿轮故障进行检测,得到最终的检测结果。
优选地,获取行星齿轮的原始震动信号并且采用形态平均滤波对其进行降噪处理,具体为:利用安装在行星齿轮箱上的传感器实时采集行星齿轮在运作状态下多种工况的振动信号,包括正常、断齿、裂纹、缺齿四种状态,并且采取形态平均滤波进行降噪。
优选地,对降噪后的振动信号片段利用小波包获取训练样本振动信号的高维频谱特征数据集,具体为:
将降噪后的振动信号xi,
其中,xi,
总能量E可以根据公式(2)获得:
信号的特征向量为各个子频带的能量占有百分比,则特征向量T可用公式(3)表示如下:
其中,
优选地,通过TSNE方法对获取的高维频谱特征数据集进行降维处理,获得低维特征数据集。具体为:
1.构建高维空间中的概率分布:
高维数据用X表示,x
其中,p
2.构建低维空间中的分布概率矩阵Q,其中第i个样本分布在样本j周围的概率表示为q
3.计算低维嵌入:
使用KL散度来度量低维空间分布概率矩阵Q和高维空间分布概率矩阵P之间的相似度C:
使用梯度下降来最小化KL散度,获得低维嵌入y
优选地,基于SVDD模型和DPC技术的不均衡分类算法构建的行星齿轮故障预测模型,具体为:
1.对所有少数类和多数类样本进行归一化处理,以消除其量纲在不同维度的影响;
2.确定少数类噪声样本:
(1)设置X
其中,d
其中,
(2)对X
3.构建SVDD模型消除重叠和噪声样本:
(1)利用公式(12)构建SVDD模型;
F(R,a,ξ
s.t.
其中,设置X
(2)引入拉格朗日乘子α
s.t.
其中,α
(3)选择满足条件d
4.DPC技术聚类少数类样本:
(1)对每一个在X
其中
(2)选择所有o
5.基于权重的SMOTE策略生成少数类合成样本:
(1)对每一个少数类样本x
I
其中,d
其中β为平衡距离和密度因子重要性的权衡参数,通常将其设置为0.8;
(2)根据公式(23)计算每一个少数类子簇的权重SD
其中,I
(3)根据公式(24)计算每个子簇对应的过采样大小OS
其中,s表示所有生成的少数类合成样本的数目。一般来说,s被设置为多数类样本和少数类样本数目的差值,这样可以用来均衡两类样本数目达到1∶1的比例。
(4)在每个少数类子簇中的选择一个候选样本x
其中x
(5)使用SMOTE策略生成少数类合成样本,从而获得最终的少数类样本X
优选地,将处理后的低维行星齿轮故障预测数据集作为输入,利用基于SVDD模型和DPC技术的算法作为行星齿轮故障预测模型进行故障预测。
本发明的有益技术效果是:
1.针对数据不均衡下的行星齿轮故障预测研究中存在的类间、类内以及重叠噪声点难以处理的问题,设计了相应的基于SVDD模型和DPC技术的不均衡分类算法构建了行星齿轮故障预测模型,能够在行星齿轮故障预测中有效且精确地识别故障样本;
2.本发明的行星齿轮故障预测方法,针对不均衡行星齿轮数据中存在的类间重叠噪声点难以处理的问题,构建改进的SVDD模型以消除重叠样本和多数类噪声样本;
3.本发明的行星齿轮故障预测方法,针对不均衡行星齿轮数据中存在的类间分布不均衡,类内子集群数量、密度、形状各不相同的现象,利用改进的DPC算法准确聚类少数类数据集并且构建了一种有效的自适应确定子集群上采样大小的模型,以解决由各种因素造成的类内不均衡问题,为基于聚类的采样算法应用于多种不均衡数据领域奠定基础;
4.本发明的行星齿轮故障预测方法,提出了基于SVDD模型和DPC技术的不均衡分类算法用于解决数据不均衡下的行星齿轮故障预测问题,该方法能够在行星齿轮故障预测中有效且精确地识别故障样本,进而提高传统分类算法的故障预测性能,并为后续类似行星齿轮故障诊断这种样本不均衡研究问题提供理论和技术支持。
附图说明
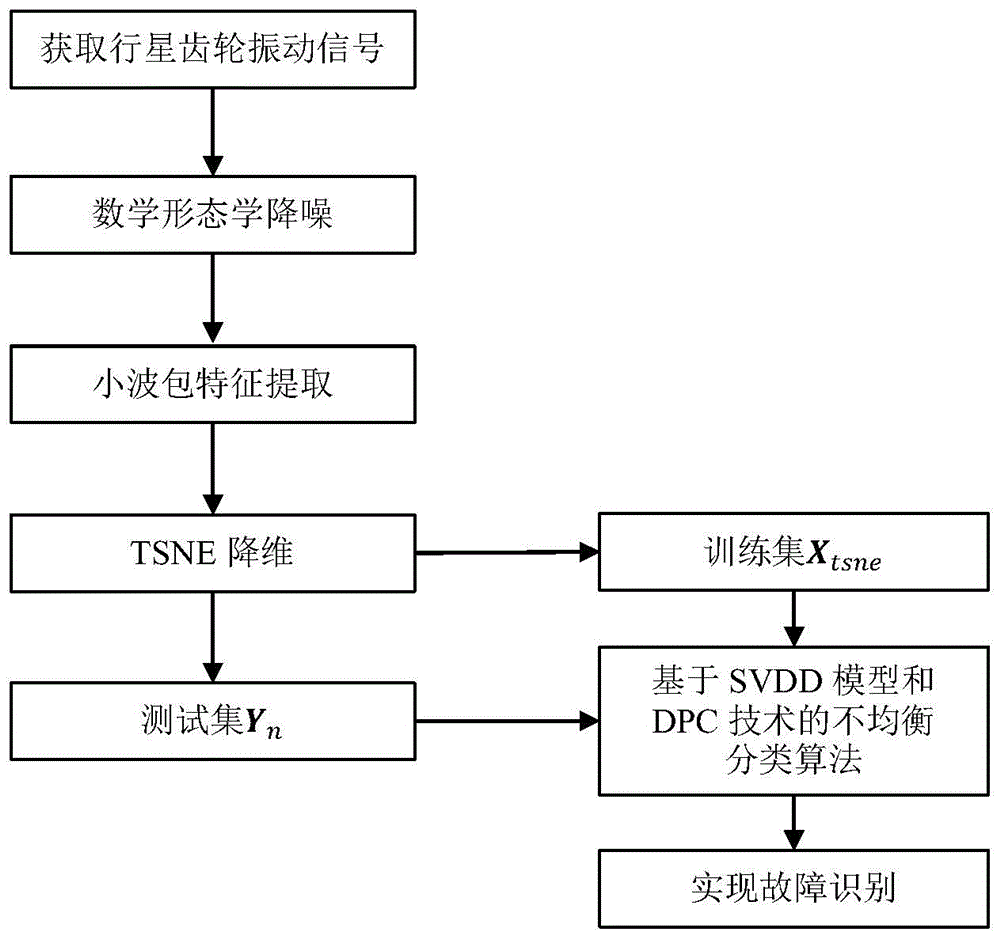
图1是本发明检测方法的流程图;
图2是本发明采用的基于SVDD模型和DPC技术的不均衡分类算法流程图;
图3是实施例中本发明算法和k-means SMOTE对选取样本识别结果,其中(a)为本发明算法识别结果,(b)为k-means SMOTE的识别结果;
图4是不同算法的故障检测性能比较。
具体实施方式
下面将对本发明技术方案的实施例进行详细的描述。以下实施例仅用于更加清楚的说明本发明的技术方案,因此只作为实例,而不能以此来限制本发明的保护范围。
本发明针对不均衡行星齿轮数据中存在的类间分布不均衡,类内子集群数量、密度、形状各不相同的现象,基于SVDD模型利用改进的DPC算法准确聚类少数类数据集并且构建了一种有效的自适应确定子集群上采样大小的模型,以解决由各种因素造成的类内不均衡问题,为基于聚类的采样算法应用于多种不均衡数据领域奠定基础;
本发明将基于SVDD模型和DPC技术的不均衡分类算法用于解决数据不均衡下的行星齿轮故障预测问题,该方法能够在行星齿轮故障预测中有效且精确地识别故障样本,进而提高传统分类算法的故障预测性能,并为后续类似行星齿轮故障诊断这种样本不均衡研究问题提供理论和技术支持。
如附图1所示,本发明实施提供的基于不均衡数据的行星齿轮故障预测方法包括如下步骤:
步骤1:获取行星齿轮的原始振动信号并且采用形态平均滤波对其进行降噪处理,具体包括:
利用安装在行星齿轮箱上的传感器实时采集行星齿轮在运作状态下多种工况的振动信号,包括正常、断齿、裂纹、缺齿四种状态。并且采取形态平均滤波进行降噪,降噪后的波形图。
步骤2:对降噪后的振动信号片段利用小波包获取训练样本振动信号的高维频谱特征数据集,具体包括:
将降噪后的振动信号x
其中,x
总能量E可以根据公式(28)获得:
信号的特征向量为各个子频带的能量占有百分比,则特征向量T可用公式(3)表示如下:
其中,
步骤3:通过TSNE方法对获取的高维频谱特征数据集进行降维处理,获得低维特征数据集,具体包括:
1.构建高维空间中的概率分布:
高维数据用X表示,x
/>
其中,p
2.构建低维空间中的分布概率矩阵Q,其中第i个样本分布在样本j周围的概率表示为q
3.计算低维嵌入:
使用KL散度来度量低维空间概率分布Q和高维空间概率分布P之间的相似度:
使用梯度下降来最小化KL散度,获得低维嵌入y
步骤4:采用基于SVDD模型和DPC技术的不均衡分类算法构建的行星齿轮故障预测模型进行训练,(算法流程如附图2所示)利用训练后的行星齿轮故障预测模型对行星齿轮故障进行检测,得到最终的检测结果,具体包括:
1.对所有少数类和多数类样本进行归一化处理,以消除其量纲在不同维度的影响;
2.确定少数类噪声样本:
(1)设置X
其中,d
其中,
(2)对X
3.构建SVDD模型消除重叠和噪声样本:
(1)利用公式(38)构建SVDD模型;
F(R,a,ξ
s.t.
其中,设置X
在不均衡数据集中,少数类样本通常出现在特殊情况中,并且极其难获取,为了确保除了少量噪声点和重叠样本以外的绝大多数样本都能被所构建的模型正确分类,因此引入惩罚因子,将相对较大的惩罚常数分配给所有少数类样本,同时分配给相对较小的惩罚常数C
(2)引入拉格朗日乘子α
s.t.
其中,α
(3)选择满足条件d
4.DPC技术聚类少数类样本:
(1)对每一个在X
其中
(2)选择所有o
5.利用基于权重的SMOTE策略生成少数类合成样本:
(1)对每一个少数类样本x
I
其中β为平衡距离和密度因子重要性的权衡参数,通常将其设置为0.8;
其中,d
(2)根据公式(49)计算每一个少数类子簇的权重SD
其中,I
因此在本发明中,我们利用相距超球体的距离来识别那些难以学习的少数类边界样本,距离超球体较近的少数类实例越难分类,因此分配较大的权重,这样可以保证边界稀疏的少数类样本具有更大的可能性被过采样。
(3)根据公式(50)计算每个子簇对应的过采样大小OS
其中,s表示所有生成的少数类合成样本的数目。一般来说,s被设置为多数类样本和少数类样本数目的差值,这样可以用来均衡两类样本数目达到1∶1的比例。
(4)在每个少数类子簇中的选择一个候选样本x
其中x
(5)将处理后的低维行星齿轮故障预测数据集作为输入,利用基于SVDD模型和DPC技术的不均衡分类算法构建的行星齿轮故障预测模型进行故障预测。
本发明提供的基于SVDD模型和DPC技术的不均衡分类算法故障预测的有效性评价指标取决于表1所示的混合矩阵,其中列为预测类,行为真实类,在混合矩阵中TP(TruePositive)是正确分类的正类样本(少数故障类样本)的数量;TN(True Negative)是正确分类的负类样本(多数正常类样本)的数量;FP(False Positive)是错分为正类样本的负类样本数量;FN(False Negative)是错分为负类样本的正类样本数量。
表1混合矩阵
如果只考虑少数类(Positive)样本分类效果时,正确率和查准率是两个至关重要的指标,正确率,也称为正类准确率度,定义为真正正类(TP)与所有正类样本之比;查准率定义为真正正类(TP)与所有预测正类之比。原则上,F-Measure表示正确率和查准率之间的调和平均值,两个指标的调和平均值往往更接近两者中较小者。如果正确率和查准率都较小,则F-Measure的值会很小;如果正确率和查准率其中一方较小,F-Measure的值也会很小。因此,在正确率和查准率均衡的情况下才能确保高的F-Measure值。
当同时考虑少数类和多数类两类样本的分类效果时,需要定义一种负类样本正确率:真正负类(TN)与所有负类样本数量之比。性能指标G-Mean可作为这两类间的平衡性能,其本质定义为少数类正确率和多数类正确率的几何平均正确率。如果G-Mean值较大,则少数类和多数类样本正确率的值同时都大。
五个性能评价指标定义如下:
正类样本的正确率(Sensitivity):
Sensitivity=TP/(TP+FN)
正类样本的准确率(Precision):
Precision=TP/(TP+FP)
正类样本的F-Measure指标:
/>
负类样本的正确率(Specificity):
Specificity=TN/(TN+FP)
几何平均正确率(G-Mean):
曲线下面积(AUC)是另一种广泛应用于不均衡数据分类问题的分类器性能评价指标,它是ROC的图下面积,将真阳性率(Sensitivity)与假阳性率(1-Specificity)作图便可得到,并且该评价指标对于二分类问题不敏感。因此,本发明可采用综合评价指标F-Measure、几何平均正确率G-Mean与AUC和其他相关算法进行对比分析来验证其有效性。
为了验证本发明实施提供的基于不均衡数据的行星齿轮故障预测方法的预测性能,进行了如下实验:
(1)基于SVDD模型和DPC技术的不均衡分类算法故障预测性能验证与分析:
实施例1:
从TSNE降维后提取的低维特征中分别随机选取1000个正常样本、15个断齿、15个裂纹以及15个缺齿故障样本带入到目前较先进的k-means SMOTE故障检测方法进行故障检测:对于k-means SMOTE,聚类数量设为3,安全子集不均衡比的阈值设置为1,SMOTE的k值设置为3。
实施例2:
从TSNE降维后提取的低维特征中分别随机选取1000个正常样本、15个断齿、15个裂纹以及15个缺齿故障样本带入到本发明运用的基于SVDD模型和DPC技术的不均衡分类算法进行故障检测:对于基于SVDD模型和DPC技术的不均衡分类算法,用于寻找多数类k近邻的k值设为3,并设置用于生成人工样本的每个少数类子集少数类近邻数目NN为3,比例因子θ设置为100,启发式过滤最大迭代次数maxIters为50。
对比结果如附图3所示,从实验结果可以看出,k-means SMOTE算法所得到的故障识别结果存在分类不清晰、类间重叠等现象,无法准确识别出行星齿轮故障类型,这是由于K均值聚类只能处理类间不均衡问题,无法兼顾故障样本内部失衡问题,且在SMOTE过程中不可避免地会产生重叠噪声点,最终达不到理想的故障预测结果。与k-means SMOTE相比,本发明运用的基于SVDD模型和DPC技术的不均衡分类算法在考虑正常样本与故障样本两类间不均衡与故障样本内部不均衡问题的同时,还通过迭代过滤的方式将重叠噪声点移至安全区域,能有效将三种故障样本与正常样本分开,并且准确识别出不同故障类型,这说明了本发明所设计的基于SVDD模型和DPC技术的不均衡分类算法对正常样本与故障样本类内类间不均衡并存问题下行星齿轮故障预测的有效性。
(2)与其他算法故障检测性能对比
将本发明算法同目前先进的不均衡数据分类故障预测方法在收集的正常和故障样本上获得的故障识别实验结果进行比较:
实验环境为:64位操作系统,4.00GB RAM,3.4G处理器,CPU:Intel i7,仿真软件为Matlab2017b。
算法:(1)Random Over-sampling、(2)SMOTE、(3)Borderline SMOTE(BSMOTE)、(4)Safe-level SMOTE(SSMOTE)、(5)ADASYN、(6)MWMOTE、(7)Cluster-SMOTE、(8)A-SUWO、(9)k-means SMOTE。
其中,RandomO、SMOTE、BSMOTE、SSMOTE和ADASYN属于启发式采样技术,MWMOTE,Cluster-SMOTE,A-SUWO和KM-SMOTE属于基于聚类的方法,对于SMOTE-like的变体,将少数类最近邻(NN)设置为5;同样地,BSMOTE,SSMOTE和ADASYN中用于识别样本不同类型的最近邻(k)的数目也为5,对于MWMOTE,k1=5,k2=3,k3=|S
通过附图4可以直观看出,本发明运用的基于SVDD模型和DPC技术的不均衡分类算法相对于其它9种分类算法在G-Means、F-Measure、AUC三个指标上性能均达到最佳,该实验结果可以进一步验证本文构建的基于SVDD模型和DPC技术的不均衡分类算法在解决行星齿轮这种正常样本与故障样本类间不均衡、故障样本类内不均衡故障预测问题上相对于其它不均衡算法性能明显有所提升,因此,可以证明本发明提出的这种基于不均衡数据的行星齿轮故障预测方法是有效的。
以上所述,仅为本发明较优的具体的实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,都应涵盖在本发明的保护范围之内。