一种3D人体姿态估计方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及计算机视觉技术领域,尤其涉及一种3D人体姿态估计方法。
背景技术
3D(Three Dimensions,三维)人体姿态估计技术是计算机视觉和模式识别领域中的一个重要研究方向,它需要预测给定人体图像的3D人体关键点坐标。然而3D人体姿态估计存在诸多问题,3D人体姿态估计数据的获得通常具有局限性,大部分场景为室内,且动作范式有限,限制了3D人体姿态数据的多样性。近年来,随着深度学习的发展,3D人体姿态估计取得了长足的进步。
随着基于深度学习的2D人体姿态估计技术的发展,先进的3D人体姿态估计多采用双阶段的方法,即先从图像中获取2D人体姿态坐标序列,然后将2D人体姿态坐标序列提升到3D,从而获取完整的3D人体姿态坐标序列,但这类方法仍然存在几个问题:首先,2D图像到3D人体姿态本身就是一个存在多个可行解的问题,即一个2D人体姿态对应多个不同的3D人体姿态的2D投影,那么多个可行解之间是否存在某种关系、一个2D人体姿态对应几个可行解都会对最终结果有重要影响,会导致获得3D人体姿态坐标序列不精准的问题;还有,目前基于卷积神经网络的3D人体姿态估计方法主要利用膨胀时序卷积神经网络,这类方法感受野受到网络层数、卷积核大小、扩张系数等因素的影响,普遍存在时间窗口有限的问题。
发明内容
本发明公开了一种3D人体姿态估计方法,用以解决只使用单一可行解造成网络预测能力受限的问题,以及利用膨胀时序卷积神经网络使得时间窗口有限的问题。
为了解决上述技术问题,本发明的公开了如下技术方案:
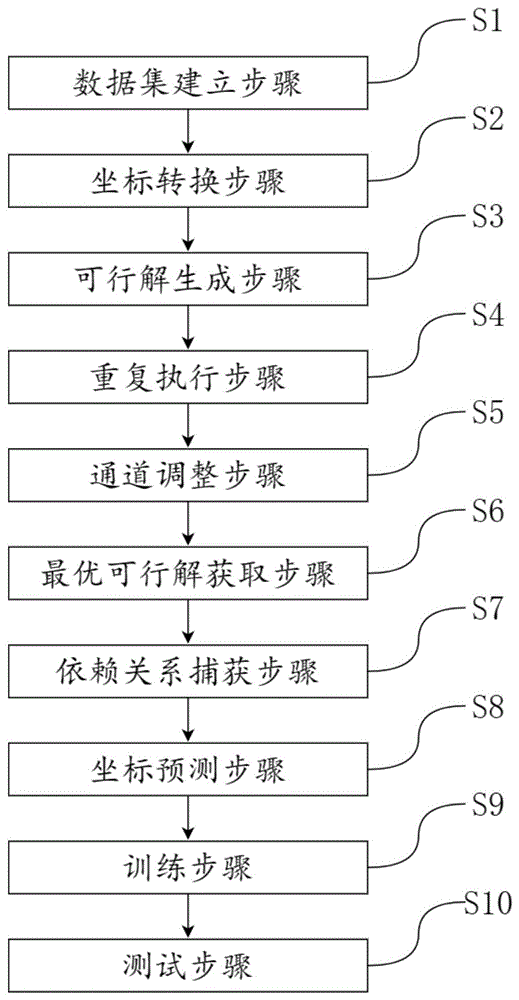
本发明提供了一种3D人体姿态估计方法,具体包括如下步骤:数据集建立步骤,坐标转换步骤,可行解生成步骤,重复执行步骤,通道调整步骤,最优可行解获取步骤,依赖关系捕获步骤以及坐标预测步骤。所述数据集建立步骤是指录入多组2D人体姿态坐标序列以及每组2D人体姿态坐标序列对应的3D人体姿态坐标序列。所述坐标转换步骤将输入的2D人体姿态坐标序列的横纵坐标连接,转换为Transformer编码器可读的2D人体姿态坐标序列,输出第一转换数据;所述可行解生成步骤是将所述第一转换数据输入坐标Transformer编码器生成一个可行解;所述重复执行步骤是指至少重复所述可行解生成步骤三次,获得至少三个可行解。所述通道调整步骤是对每个可行解执行一个一维卷积将每个可行解的通道进行调整,从而获得每个可行解的高维特征。最优可行解获取步骤是将所述多个可行解延通道维度拼接,利用多层感知机实现所述多个可行解之间的信息交换,并通过一个多对一的映射,获得一个最优可行解;高维特征编码生成步骤是将所述最优可行解输入时域Transformer编码器,获得包含输入序列全局依赖关系的高维特征编码;坐标预测步骤是将一个一维卷积作为回归首部调整所述特征通道数量,去预测3D人体姿态坐标,并输出预测的3D人体姿态坐标序列。
进一步地,所述可行解生成步骤具体包括如下步骤:坐标嵌入步骤,第一数据连接步骤,第二数据连接步骤以及可行解获取步骤。所述坐标嵌入步骤将所述第一转换数据嵌入一个可学习的坐标位置,并执行Dropout模块,坐标位置嵌入公式为
Z
其中,Z
其中,Q为查询,K为键,V为值,d为维度。MSA将Q、K、V分割为h份,h为MSA的头数,分别进行上述Attention运算;所述第二数据连接步骤是将所述第一输出特征作为输入,执行所述LayerNorm操作后,输入到一个多层感知机模块,所述多层感知机模块包括多个线性层,在每个线性层后都执行所述Dropout模块,输出第二输出特征,并通过跳跃连接将所述第一输出特征与所述第二输出特征相连接,在所述多层感知机模块中的计算公式为
MLP(x)=σ(W
其中,σ为GELU函数,W
进一步地,所述最优可行解获取步骤具体包括如下步骤:可行解拼接步骤,信息交换步骤以及通道数缩减步骤。所述可行解拼接步骤是将所述多个可行解延通道维度拼接形成新的可行解,使所述新的可行解的特征通道数量为所述第一可行解的多倍;所述信息交换步骤是将所述新的可行解执行LayerNorm操作之后,输入到一个多层感知机,所述多层感知机模块包括多个线性层,并执行两个所述Dropout模块,进行每个可行解之间的信息交换,输出第一输出数据,并通过跳跃连接连接所述新的可行解与所述第一输出数据,在所述多层感知机模块中的计算公式为
MLP(x)=σ(W
其中,σ为GELU函数,W
进一步地,所述依赖关系捕获步骤具体包括如下步骤:数据转换步骤,时间位置嵌入步骤,第三数据连接步骤,第四数据连接步骤以及特征编码获取步骤。所述数据转换步骤是将所述最优可行解的数据进行转换,生成第二转换数据;所述时间位置嵌入步骤是将所述第二转换数据嵌入一个可学习的时间位置,并执行Dropout模块,时间位置嵌入公式如下:
Z
其中,Z
其中,Q为查询,K为键,V为值,d为维度。MSA将Q、K、V分割为h份,h为MSA的头数,MSA为多头自注意机制,分别进行上述Attention运算;
第四数据连接步骤是将所述第三输出特征作为输入,执行LayerNorm操作后输入到所述多层感知机模块,所述多层感知机模块包括多个线性层,在每个线性层后都执行所述Dropout模块,输出第四输出特征,并通过跳跃连接将所述第四输出特征与所述第三输出特征连接,在所述多层感知机模块中的计算公式为:
MLP(x)=σ(W
其中,σ为GELU函数,W
进一步地,在所述坐标预测步骤之后,还包括训练步骤,所述权利要求1-6的3D人体姿态估计方法在Human3.6M数据集上进行训练,所述数据集包括多组数据集,部分数据集作为训练集,部分数据集作为测试集,共训练15个epoch,选择Adam作为优化器,初始学习率设为0.001,并且每个epoch后对学习率应用一个收缩因子0.95,同时采用平均每个关节的位置误差作为损失函数,公式如下:
其中,N表示关节点数量;
进一步地,在所述训练步骤之后,还包括测试步骤,利用上述训练好的3D人体姿态估计方法和其他先进方法对所述数据集的测试集进行测试,并将测试结果进行对比。
本发明还提供一种存储介质,用于存储可执行程序代码;一处理器读取所述可执行程序代码,以运行与所述可执行程序代码对应的计算机程序,以执行所述的3D人体姿态估计方法中的至少一步骤。
本发明的优点在于,提供一种3D人体姿态估计方法,通过一个多对一的映射将多个可行解的信息进行交换,生成一个最优可行解,使网络预测更加准确,利用时域Transformer编码器捕获输入序列的全局依赖关系,同时避免了传统的膨胀时序卷积方法时间窗受限的问题。
附图说明
下面结合附图和具体实施例,对本发明的技术方案进行详细的说明。
图1为本发明提供的3D人体姿态估计方法流程图;
图2为本发明提供的可行解生成步骤方法流程图;
图3为本发明坐标Transformer编码器的示意图;
图4为本发明提供的最优可行解获取步骤方法流程图;
图5为本发明提供的依赖关系捕获步骤方法流程图;
图6为本发明时域Transformer编码器的示意图;
图7为本发明提供的在半身遮挡的情况下测试跳跃场景的结果图;
图8为本发明提供的在半身遮挡的情况下测试奔跑场景的结果图
图9为本发明提供的方法与其他先进算法在同一个数据集上的可视化对比图
图10为本发明提供的方法与其他先进算法在同一个数据集上的测试结果对比图;
图11为本发明存储介质的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,本发明提供了一种3D人体姿态估计方法,具体包括如下步骤:步骤S1)数据集建立步骤,步骤S2)坐标转换步骤,步骤S3)可行解生成步骤,步骤S4)重复执行步骤,步骤S5)通道调整步骤,步骤S6)最优可行解获取步骤,步骤S7)依赖关系捕获步骤,步骤S8)坐标预测步骤,步骤S9)训练步骤,步骤S10)测试步骤。
步骤S1)数据集建立步骤,录入多组2D人体姿态坐标序列以及每组2D人体姿态坐标序列对应的真实3D人体姿态坐标序列。
步骤S2)坐标转换步骤,将输入的2D人体姿态坐标序列的横纵坐标连接,转换为Transformer编码器可读的2D人体姿态坐标序列,输出第一转换数据,例如将原来的格式(batchsize,frames,in_joints,2)转换为(batchsize,in_joints*2,frames)。
如图2和图3所示,步骤S3)可行解生成步骤,将所述第一转换数据输入坐标Transformer编码器生成多个可行解,具体包括如下步骤:步骤S31)坐标嵌入步骤,步骤S32)第一数据连接步骤,步骤S33)第二数据连接步骤以及步骤S34)可行解获取步骤。
步骤S31)坐标嵌入步骤,将所述第一转换数据嵌入一个可学习的坐标位置以保留每个关节点的空间位置,并执行Dropout模块以抑制过拟合,坐标位置嵌入公式为
Z
其中,Z
步骤S32)第一数据连接步骤,将所述Z
其中,Q为查询,K为键,V为值,d为维度。MSA将Q、K、V分割为h份,h为MSA的头数,分别进行上述Attention运算。
步骤S33)第二数据连接步骤,将所述第一输出特征作为输入,执行所述LayerNorm操作后,输入到一个多层感知机模块,所述多层感知机模块包括包含两个隐藏单元数量为54的线性层、一个GELU函数,在每个线性层后都执行所述Dropout模块,输出第二输出特征,并通过跳跃连接将所述第一输出特征与所述第二输出特征相连接,在所述多层感知机模块中的计算公式为
MLP(x)=σ(W
其中,σ为GELU函数,W
S34)可行解获取步骤,通过跳跃连接将所述第一转换数据与所述第二输出特征相连接,作为一个样本,对所述样本的不同特征进行所述
步骤S4)重复执行步骤,重复所述可行解获取步骤三次,获得三个可行解。
步骤S5)通道调整步骤,对每个可行解执行一个一维卷积将每个可行解的通道调整到512,获得每个可行解的高维特征,然后使用BatchNorm操作加速网络训练和收敛,使用ReLU函数增加网络各层之间的非线性关系,使用Dropout模块抑制过拟合。
如图4所示,步骤S6)最优可行解获取步骤,将所述多个可行解延通道维度拼接,利用多层感知机实现所述多个可行解之间的信息交换,并通过一个多对一的映射,获得一个最优可行解,具体包括如下步骤:步骤S61)可行解拼接步骤,步骤S62)信息交换步骤以及步骤S63)通道数缩减步骤。
步骤S61)可行解拼接步骤,将所述多个可行解延通道维度拼接形成新的可行解,使所述新的可行解的特征通道数量为每个可行解的3倍。
步骤S62)信息交换步骤,将所述新的可行解执行LayerNorm操作之后,输入到一个多层感知机,所述多层感知机模块包括两个隐藏单元数量为54的线性层、一个GELU函数和两个Dropout模块,进行三个可行解之间的信息交换,输出第一输出数据,并通过跳跃连接连接所述新的可行解与所述第一输出数据,在所述多层感知机模块中的计算公式为
MLP(x)=σ(W
其中,σ为GELU函数,W
S63)通道数缩减步骤,将所述第一输出数据执行BatchNorm操作后,利用所述一维卷积对所述输出数据完成多对一的映射,将所述第一输出数据的特征通道数量调整为当前特征通道数量的1/3,输出最优可行解。
如图5和图6所示,步骤S7)依赖关系捕获步骤,将所述最优可行解输入时域Transformer编码器,获得包含输入序列全局依赖关系的高维特征编码,具体包括如下步骤:步骤S71)数据转换步骤,步骤S72)时间位置嵌入步骤,步骤S73)第三数据连接步骤,步骤S74)第四数据连接步骤以及步骤S75)特征编码获取步骤。
步骤S71)数据转换步骤,将所述最优可行解的数据格式进行转换,生成第二转换数据,例如将数据格式由(batchsize,dim,frames)转换为(batchsize,frames,dim)。
步骤S72)时间位置嵌入步骤,将所述第二转换数据嵌入一个可学习的时间位置以保留每一帧的时间位置,并执行Dropout模块,时间位置嵌入公式如下:
Z
其中,Z
步骤S73)第三数据连接步骤,将所述Z
其中,Q为查询,K为键,V为值,d为维度。MSA将Q、K、V分割为h份,h为MSA的头数,MSA为多头自注意机制,分别进行上述Attention运算;
步骤S74)第四数据连接步骤,将所述第三输出特征作为输入,执行LayerNorm操作后输入到所述多层感知机模块,包含两个隐藏单元数量为1024的线性层、一个GELU函数,并且在每个线性层后执行一个Dropout模块,输出第四输出特征,并通过跳跃连接将所述第四输出特征与所述第三输出特征连接,在所述多层感知机模块中的计算公式为:
MLP(x)=σ(W
其中,σ为GELU函数,W
S75)特征编码获取步骤,通过跳跃连接将所述第四输出特征与所述最优可行解相连接,然后执行所述LayerNorm操作,获得包含输入序列全局依赖关系的高维特征编码。
步骤S8)坐标预测步骤,将一个一维卷积作为回归首部调整所述特征通道数量,去预测3D人体姿态坐标,并输出预测3D人体姿态坐标序列。
步骤S9)训练步骤,将步骤S2),步骤S3),步骤S4),步骤S5),步骤S6),步骤S7),步骤S8)在Human3.6M公开数据集上进行训练,所述数据集包括7组有3D标签的数据集[1]D1、D2、D3、D4、D5、D6、D7,使用D1、D2、D3、D4、D5作为训练集,D6、D7作为测试集,共训练15个epoch,选择Adam作为优化器,初始学习率设为0.001,并且每个epoch后对学习率应用一个收缩因子0.95,同时采用平均每个关节的位置误差作为损失函数,公式如下:
其中,N表示关节点数量;
如图9和图10所示,步骤S10)测试步骤,使用其他先进算法在Human3.6M数据集上进行训练,训练过程中训练集、测试集划分以及优化器等因素均与本发明的方法保持一致,输入序列的长度均为243帧。同时选择了具有代表性的简单招手动作和复杂跳跃动作两个场景,如图9所示,通过可视化的方式对比了VideoPose、PoseFormer、MHFormer等先进算法和本发明的优劣,其中VideoPose算法虽然检测到人物,但是人物动作出现明显失真;PoseFormer、MHFormer方法虽然可以展现人体大概动作,但是在手腕、膝盖等细节均不如本发明;本发明不仅可以检测到复杂场景下的人物,并且能够准确还原手腕、手肘、膝盖等细节的弯曲、旋转。如图10所示,各种方法在损失函数上的表现也同样体现出本发明提供的方法所预测的位置误差更小。
如图7和图8所示,为了进一步考察本发明方法在半身遮挡情况下的表现情况,所述测试步骤中除了原本的动作以外,还添加了包括但不限于跳跃、奔跑等测试场景。
如图11所示,本实施例还提供一种存储介质11,一存储器111用于存储可执行程序代码;一处理器112读取所述可执行程序代码,以运行与所述可执行程序代码对应的计算机程序,以执行所述的3D人体姿态估计方法中的至少一步骤。
本发明的优点在于,提供一种3D人体姿态估计方法,通过一个多对一的映射将多个可行解的信息进行交换,生成一个最优可行解,使网络预测更加准确,利用时域Transformer编码器捕获输入序列的全局依赖关系,同时避免了传统的膨胀时序卷积方法时间窗受限的问题。
以上对本发明实施例所提供的一种3D人体姿态估计方法进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的技术方案及其核心思想;本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例的技术方案的范围。