一种海上多智能体作战任务规划方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及人工智能技术,尤其涉及一种海上多智能体作战任务规划方法。
背景技术
目前海上作战面对战场态势错综复杂、决策要素众多、作战任务多样、节点编组灵活、作战数据繁杂、节奏快、强度高等问题,致使决策时面对的数据海量爆发。多智能体系统利用分布式计算技术,可用于解决分布式决策问题。将强化学习技术应用到多智能体系统,能在更高维且动态的真实场景中通过交互和决策完成更复杂的任务。
发明内容
本发明要解决的技术问题在于针对现有技术中的缺陷,提供一种海上多智能体作战任务规划方法。
本发明解决其技术问题所采用的技术方案是:一种海上多智能体作战任务规划方法,包括以下步骤:
1)初始化;
初始化作战任务规划的经验回放池D,设定后验经验回放算法HER目标更新策略S;
目标更新策略S为回放该回合中,选取该回合中从当前状态开始k个随机状态作为新目标;
2)初始化作战战场所有智能体的环境和状态(包含经纬度)集合s;
3)经验存储;
智能体在t时刻的初始状态为o
4)利用经验训练Actor和Critic网络;
对每个智能体i=1,…,N,执行以下循环:
4.1)从D中随机抽取minibatch;
4.2)计算期望回报;
4.3)使用最小化损失函数更新Critic网络;
4.4)利用梯度下降法更新Actor网络;
4.5)更新每个智能体i的目标网络参数;
5)重复步骤2)至4),直至达到设定次数M或多智能体强化学习网络收敛,获得最终的目标网络,并根据目标网络获得海上多智能体作战任务规划策略。
按上述方案,所述步骤4.3)中Critic网络的输入是所有智能体的观测信息o=(o
其中,
其中,v
α
其中,线性转换矩阵W
按上述方案,所述步骤4.3)中,Critic网络采用的损失函数L
其中,
策略网络的表达式为:
其中,b(o,a
本发明产生的有益效果是:
本发明将后验经验回放(HER)思想引入MAAC算法应用于海上多智能体作战任务规划,引入注意力机制,在智能体数目增大时可扩展性更好,事后经验回放通过将既定目标更改为当前智能体达到的状态获得更密集的奖励函数,实现任务规划最终成功率的有效提高。
附图说明
下面将结合附图及实施例对本发明作进一步说明,附图中:
图1是本发明实施例的方法流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
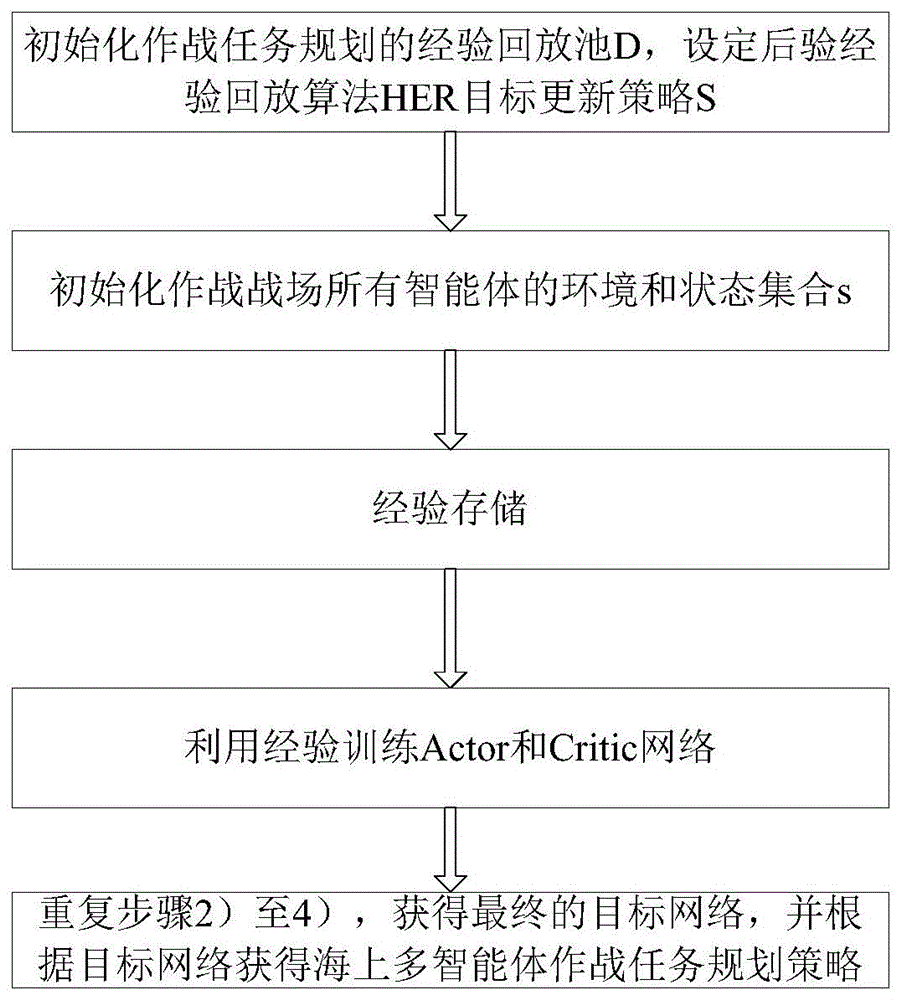
如图1所示,一种海上多智能体作战任务规划方法,包括以下步骤:
1)初始化;
初始化作战任务规划的经验回放池D,设定后验经验回放算法HER目标更新策略S;
HER算法在每一轮的训练序列中附加了初始目标g与智能体状态s对应,并且将该序列 目标更新策略S为回放该回合中,选取该回合中从当前状态开始k个随机状态作为新目标; HER在每一轮结束后依据选定的策略S取样新目标,对每个新目标g'重新计算奖励值r',并且将得到的序列 2)初始化作战战场所有智能体的环境和状态(包含经纬度)集合s; 3)经验存储; 智能体在t时刻的初始状态为o 4)利用经验训练Actor和Critic网络; 对每个智能体i=1,…,N,执行以下循环: 4.1)从D中随机抽取minibatch; 4.2)计算期望回报; 4.3)使用最小化损失函数更新Critic网络; 4.4)利用梯度下降法更新Actor网络; 4.5)更新每个智能体i的目标网络参数; 步骤4.3)中Critic网络的输入是所有智能体的观测信息o=(o 其中, 其中,v α 其中,线性转换矩阵W 步骤4.3)中,Critic网络采用的损失函数L 其中, 策略网络的表达式为: 其中,b(o,a 5)重复步骤2)至4),直至达到设定次数M或多智能体强化学习网络收敛,获得最终的目标网络,并根据目标网络获得海上多智能体作战任务规划策略。 应当理解的是,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,而所有这些改进和变换都应属于本发明所附权利要求的保护范围。