一种方法级Java软件供应链的构建方法
文献发布时间:2024-04-18 20:01:30
技术领域
本发明涉及软件工程(程序分析)技术领域,尤其涉及一种方法级Java软件供应链的构建方法。
背景技术
随着开源模式的快速发展,开发者通过复用第三方软件包来构建新的软件项目。大量开源软件之间通过包引用、代码引用等形成了复杂的开源软件依赖网络,即开源软件供应链。构建软件供应链能帮助软件的开发者更快的开发和部署项目。同时,这种复杂的供应关系也给软件安全性带来了巨大挑战,一个开源软件库出现问题往往会波及许多相关的其他软件。因此,我们需要了解一个软件项目是否使用了第三方软件包、使用了哪些第三方软件包、以及如何使用这些第三方软件包,即对该软件的供应链进行分析和构建,从而在上游软件包出现漏洞、知识产权、废弃等等安全问题时能及时对下游项目进行维护,减少可能造成的损失。然而目前的软件供应链分析技术依赖于已存在的包管理器,通过分析包管理器的元数据进行供应链构建。这些包管理器(如Maven和NPM)将自动解析依赖性描述并连接到集中式代码存储库,以下载构建客户端程序所需的特定库版本。由于依赖关系的传递效应,开源软件之间的关系变得错综复杂,一个软件项目所引用的软件包,同时也会依赖其他的软件包,从而形成了所谓的“系统之系统”。复杂的和不断变化的依赖关系对于许多开发人员来说是一个负担,造成了“依赖地狱”现象的出现。著名网络安全公司奇安信发布的《2023中国软件供应链安全分析报告》中指出,根据其包级别的软件供应链分析工具的分析结果发现,平均每个开源项目使用了155个开源软件第三方软件库,且平均每个项目存在110个已知的开源软件漏洞。
然而2021年的一项实证研究指出,大量的软件依赖关系其实并不存在,即包级别的软件供应链网络中大约1/4的软件包是冗余依赖项。冗余依赖是指被开发者声明为应用程序的依赖项,但实际上该应用程序的构建或运行并不需要的软件包。冗余的依赖关系带来了许多问题,其中主要的三个包括:最终打包的二进制文件包含了更多的代码,增大了软件包占用的容量;引入更多的第三方软件库给软件的维护者增加不必要的维护成本;以及给在供应链网络基础上进行的组件可达性分析和漏洞分析造成了误报的可能。
在软件包级软件供应链方面,目前学术界和工业界已经有了较成熟的分析和构建工具,如Dependabot、BlackDuck、FOSSID,国内的SourceCheck、FOSSCheck等等。这些工具依托所构建的庞大商业数据库能进行较为全面的包级别依赖网络分析和构建,但在更进一步的方法级依赖网络方面还没有产品问世。
在方法级软件供应链方面,一些新的分析方法已经被发表出来。方法级软件供应链指在构建了包级别软件供应链的基础上,进一步解决一个软件项目通过项目间的API调用和项目内的函数调用、继承等方式传递了哪些参数,构建一个节点细化为函数的依赖网络,从而确立实际使用的第三方软件包。现有的研究一方面局限于软件包级软件供应链的分析和构建,在此基础上进行组件可达性分析和漏洞影响范围分析会产生大量误报,增加软件项目的维护成本;另一方面,现有关于Java程序之间依赖关系分析的研究工作没有考虑类的继承和接口调用等关系,使得分析结果不准确。总体上,现有的工作要么无法进行细粒度的依赖分析,且准确度较低;要么仅限于理论层面,还没有很完备的细粒度分析工具。
本发明针对软件开发和维护场景下,现有Java生态中软件包级软件供应链分析工具的结果存在误报,进而在供应链构建过程中引用了过多冗余依赖包的问题,提出了一种方法级Java软件供应链分析与构建方法,通过分析软件项目的方法调用关系、接口实现关系和类继承关系,并逐层构建软件项目直接使用的依赖包和间接使用的依赖包,最终实现一个完整的方法级软件供应链分析和构建工具。本发明着重解决软件供应链构建任务中的三个问题:(1)方法级依赖网络的定义和构建;(2)软件包依赖关系约束解析;(3)完整方法级软件供应链的构建。
发明内容
为此,本发明首先提出一种方法级Java软件供应链的构建方法,首先通过包管理器的中央仓库获取项目的元数据、源代码以及可执行代码;然后基于项目的元数据,提出一种基于开源项目数据的包级别依赖网络构建方法;接着在包级别依赖网络的基础上,基于开源软件及其依赖项API级别的调用关系,构建方法级依赖网络,形成细粒度软件供应链;
将依赖网络划分为包级别粒度、方法粒度、类粒度三个粒度的依赖网络,每个粒度的依赖网络均可视为一个由节点和边构成的有向图,其中节点代表相应粒度上的软件组成单元,有向边代表软件组成单元之间的联系;包级别依赖网络定义为根据包管理器提供的元数据构建出初步的依赖关系;进一步方法级依赖网络定义为:在包级别依赖网络的基础上,基于开源软件及其依赖项API级别的调用关系,构建出的包含类依赖、方法依赖的依赖关系。
所述基于开源项目数据的包级别依赖网络构建方法的构建方法具体为:给定一个目标软件包集合,首先为每个软件包的每个版本收集分布在中央仓库以及开源社区的元数据信息,保存到本地的一个单一存储库中;之后对于获取到的元数据,进行清洗并从中抽取出需要的节点信息;抽取出所述节点信息后,对软件包的直接依赖关系进行解析,基于semver实现一个依赖项约束解析器,处理各种依赖项约束条件;最后通过广度优先算法实现对目标软件包集合依赖网络的构建,存取到图数据库中。
所述元数据信息包括软件包名字、中央仓库地址、项目软件库托管地址、直接依赖项以及对直接依赖项的版本约束条件。
所述依赖项约束解析器的具体实现方式为:首先需要确定版本之间优先级比较规则,根据semver规范采用优先级比较规则实现,具体规则为:1.版本号的优先级按major、minor、patch、pre-release顺序比较;2.优先级由从左至右第一个不同的标识符确定,且major、minor、patch总是以数值方式比较;3.当major、minor、patch相同时,带pre-release标签的版本号优先级更低;4.只包含数字的标识符通过数值方式比较;5.包含字母的标识符逐个字符按ASCII顺序比较;6.只包含数字的标识符优先级低于非数字标识符;7.前缀标识符相同时有更多标识符部分的优先级更高;并根据包生态系统相关文档以及前文描述的semver优先级比较规则,将其翻译成相对应版本范围,归一化依赖约束与对应的版本范围映射规则。
所述对目标软件包集合依赖网络的构建方法为:输入为一个待分析的软件包队列,先对已访问软件包列表seenPkg、待提交指令数orderCnt、输出包级别依赖网络cgdn置空,之后遍历初始队列里的每一个软件包pkg,首先访问本地是否有pkg的元数据文件metadata,如果不存在需要访问对应编程语言中央仓库给出的API,并将其缓存到本地,接着根据获取到的元数据文件,获取当前软件包的基本信息并进行依赖项解析;取软件名称和版本信息作为唯一id,在ne04j数据库生成节点,上述基本信息作为节点属性,同时将当前软件包id加入到已访问的队列seenPkg中避免重复访问;遍历从元数据文件里获取解析出当前软件包的所有直接依赖项,对每一个依赖项dep,生成依赖边pkg→dep;为了获取软件包的传递依赖,先判断依赖项dep是否在已访问软件包列表seenPkg中,或者在之前的执行过程中是否已经在数据库中生成了dep的依赖网络,否则就将其加入待构建队列;当待分析队列为空时,说明每个软件包及其所有的直接、传递依赖都已经解析完成;在执行数据库插入操作时,将一定数量的节点生成或边生成操作指令放入一个事务中进行提交,检查当前的待提交指令数是否达到阈值BATCH_SIZE,如果是则提交当前所有指令;最后提交剩余的指令,完成输入队列中所有软件包级别依赖网络cdnkg的构建。
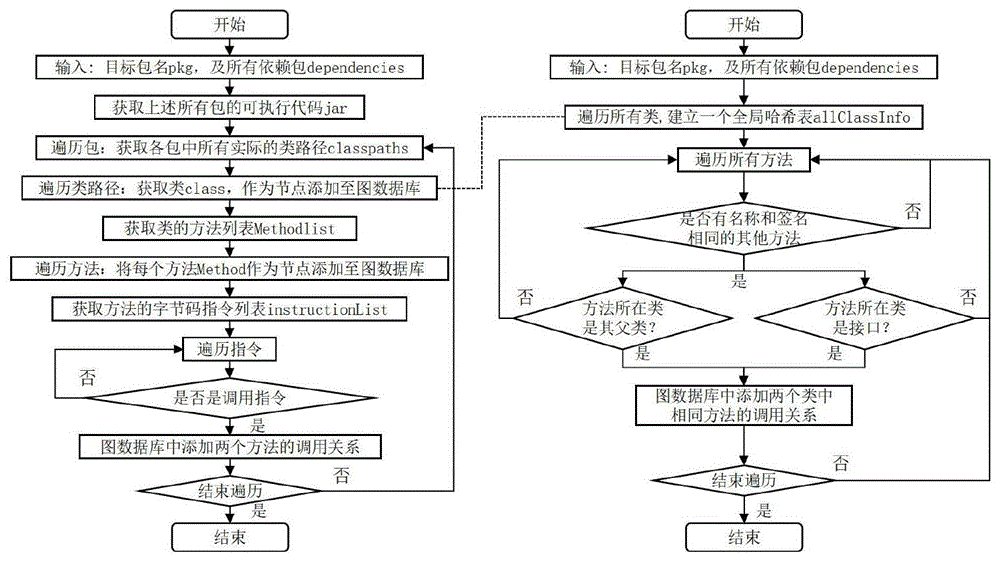
所述构建方法级依赖网络的具体方法为:基于程序静态分析技术、针对Maven托管的Java项目进行,分为三个阶段:第一阶段,给定一个待构建方法级依赖网络的Maven项目坐标集,使用自定义的下载模块从Maven中央仓库将每一个Maven坐标对应的元数据文件pom.xml与字节码文件JAR保存到本地存储库;第二阶段,对于项目集中每一个Maven项目,首先通过将其pom.xml文件输入依赖解析器,得到在当前时间节点t的该项目的软件包依赖网络SPDN0,这个依赖图包含了该项目的所有直接依赖项和传递依赖项,然后对依赖图中的每一个依赖项,首先查询本地存储库是否存在其字节码文件,如果有则直接取出,否则访问中央仓库将其保存到本地;接着将该Maven项目与其所有依赖项的字节码文件路径作为输入传递给静态代码分析器;静态代码分析器通过读取每个字节码文件,提取出其中的方法依赖关系,为每个字节码文件生成一个方法依赖关系图,此时图中的方法节点标识符并未统一,且一个方法依赖关系图中的某个外部节点可能映射到另一个方法依赖关系图中的一个内部节点上,因此需要重新对其中的节点进行统一标识和内外节点映射,得到了本发明前一节定义的方法粒度依赖网络MDN;第三阶段,使用多级粗化技术,以MDN作为输入,将具有相同名称空间的方法节点折叠到单个类节点中,生成类粒度依赖网络CDN,对CDN进行合并得到了初始Maven项目的一个新的软件包依赖网络SPDN,将不同粒度的依赖网络存在一个统一的图数据库中。
所述本地存储库为本地的镜像存储库,存储Maven组件的构建文件pom.xml和已编译的二进制代码包JAR,一个Maven组件可由一个三元组唯一标识:
GroupId:ArtifactId:Version
其中GroupId指定了Maven项目所属的组织或者公司,为了保证唯一性一般使用反转的域名格式,GroupId、用于对依赖进行分类和组织,ArtifactId指定了、项目或者库的名称,Version为具体的发行版本号,给定一个Maven坐标 所述依赖网络的有向图的定义方法具体为:将依赖网络定义成一个由带标记和属性的顶点集和有向边集组成的有向图: FGDN=(N,E) 其中顶点集N: N=SP∪C∪IF∪M 其中顶点集SP,C,IF,M: SP={sp C={c IF={if M={m sp E=E 分为两类,一类是同等粒度实体节点之间的关系: E 其中: 分别代表Maven软件包之间、类之间、类与接口、接口之间、方法之间的关系集合; 另一类为不同层次间实体节点的关系: E 其中: 分别表示Maven软件包、类与接口、方法不同层次之间的关系集合。 所述第二阶段中提取方法依赖关系的具体方法为,基于pom.xml文件对一个Maven项目进行依赖解析,具体实现时,首先需要构建包级别依赖网络;此外,Maven使用scope字段来限制依赖关系的传递以及确定依赖项何时包含在类路径中。 本发明所要实现的技术效果在于: (1)本发明提出了一种方法级Java软件供应链的构建方法,首先给出了方法级软件依赖网络的定义和设计方法,并在此基础上,提出并实现了方法级软件供应链的构建方法。 (2)在方法级依赖网络的定义方面,在包级别依赖网络的基础上,提出了类级别依赖网络和方法级别依赖网络的定义、模式和构造。 (3)在方法级软件供应链构建方面,提出了方法级软件供应链构建方法,对Java软件及其依赖项构造API级别的调用依赖关系,并进行分层抽象以刻画更准确的依赖关系。 (4)此外,在包级别依赖网络的基础上,提出了基于semver的软件包依赖关系约束解析方法,对方法级软件供应链的节点进行了更标准的表示和存储。 附图说明 图1软件包与依赖项的方法粒度依赖示意图; 图2软件包与依赖项的类粒度依赖示意图; 图3总体方案架构图; 图4包级别依赖网络构建方法流程; 图5包级别依赖网络的构建算法流程; 图6方法级依赖网络构建流程; 图7方法级依赖网络节点关系图; 图8方法级依赖网络的构建流程; 具体实施方式 以下是本发明的优选实施例并结合附图,对本发明的技术方案作进一步的描述,但本发明并不限于此实施例。 本发明提出了一种方法级Java软件供应链的构建方法。 首先本发明申请定义术语如下: 包管理器:一种用于自动化下载、安装、升级、卸载和配置软件包,以及解决软件包之间的依赖关系的软件工具。 包生态系统:用于打包、分发和管理软件组件的工具和技术的集合。这个生态系统包括了从软件包管理器和构建工具到容器化平台和云基础设施的各种组件。 中央仓库:一个集中存储和管理软件包的在线存储库,通常由软件包管理系统使用。中央仓库存储了各种软件包及其元数据,这些软件包可以被开发人员通过软件包管理器进行访问和下载。例如,Maven中央仓库Java编程语言的一个非常著名的中央仓库,而与Nodejs编程语言对应的有npm中央仓库。 软件包:一个使用某种编程语言实现的提供具体功能的计算机程序。一个软件包通常存在着许多称之为发行版的版本号,为了简化描述,将在某个时间点的软件包指代为这个包在此时间点的可获取的最新发行版。 发行版:可以通过包管理器访问和安装的包的特定版本。它通常以归档文件的形式出现,其中包含构建、配置和删除所需的内容并包含一个清单,其中包含重要的元数据,如其所有者、名称、描述、时间戳,以及对其正常运行所需的对其他包的直接依赖关系列表。 依赖项:一个软件包为了实现正常功能所需要的其他软件包集合。在软件开发中,通常会使用第三方库、框架、工具等软件组件,这些组件都有可能被其他组件依赖。开发者一般对依赖项会指定约束条件来限制使用的目标版本号。 直接依赖项:一个软件包在其元数据文件里明确声明了它需要依赖的其他软件包集合。直接依赖项通常由开发者出于使用意图而进行显示声明。 传递依赖项:从直接依赖项及其依赖项所构成的传递闭包获得的依赖项集合,传递依赖项的获取通常需要借助包管理器进行解析。 间接依赖项:传递依赖项中的没有在本软件包元数据里声明的依赖项称之为间接依赖项。 依赖者:由反向依赖关系指示的依赖项,对于一个包A和它的依赖项B,称A为B的依赖者。类似地,定义直接依赖者、传递依赖者、间接依赖者。 软件包级别依赖网络(SPDN):包生态系统中的一个有向图结构,其中节点代表可由包管理器获得的软件包,边代表了软件包之间的直接依赖关系。 方法级依赖网络的定义: 在针对Java生态进行方法级依赖网络构建之前,首先对其进行细致的粒度划分。在面向对象软件系统中,类的方法定义了其创建出来的对象的行为,能够操作对象内部状态的改变,类与类通常通过方法调用的方式进行交互。这些不同结构的软件组成单元通过相互之间的多种联系组合在一起,共同实现复杂的软件任务。本发明将依赖网络划分为包级别粒度、方法粒度、类粒度三个粒度的依赖网络,每个粒度的依赖网络均可视为一个由节点和边构成的有向图,其中节点代表了相应粒度上的软件组成单元,有向边代表了软件组成单元之间的联系。包级别依赖网络已经比较成熟,即软件包之间的引用关系所构成的网络。本发明下面对后两种粒度的依赖网络进行具体的定义。 方法粒度依赖网络:方法依赖代表了软件系统中最低层次上的依赖关系,最常见的一种方法间依赖关系通常为方法调用,方法调用可以发生在本软件包内部的方法之间,也可以发生在本软件包内部方法与其依赖项方法之间;此外在面向对象语言Java中子类可以默认继承父类中非private类型的方法,如果子类不进行重写,对子类中该方法的调用实际上是调用父类中的同名方法,因此在本发明中定义该子类方法对父类的同名方法存在依赖关系;类似地,接口方法以及类中的抽象方法只是一个声明,其方法的实现在具体的某个类中完成,而软件代码中通常存在对接口方法以及抽象方法的调用,因此本发明同样定义接口方法和类中的抽象方法对其具体的实现方法存在依赖关系。 下面给出一个软件包的方法粒度依赖网络的形式化定义: MDN 对于顶点集: M=M 其中M 对于边集: 代表了软件包内部方法节点之间的依赖关系、对依赖项中方法的调用关系以及依赖项内部方法节点之间的依赖关系。例如,图1为软件包A@1.0.0的与其依赖项中方法粒度依赖的示意图。A@1.0.0内部共有A:M1~A:M5共五个方法,有两个直接依赖项B@1.2.1和C@2.0.0,三个间接依赖项D@3.0.0、E@3.0.1、和F@3.2.1。除了A@1.0.0内部方法之间的依赖关系,A:M3调用了B:M1,A:M4调用了C:M1,而C:M3调用了D:M1,C:M5调用了F:M1,且这些被调用的直接或间接依赖项的方法,在其内部也存在着依赖的路径。根据前文的定义,图中绿色节点构成了M 类粒度依赖网络:通常类粒度依赖关系存在以下两种情况:一个类中的方法调用了另一个类(自身或者依赖项的)中的方法;一个类是另一个类的子类,继承了它的属性与方法。此外,在Java语言中,接口与类的源代码通常保存在“.java”结尾的文件中,而字节码都保存在“.class”结尾的文件中,两者十分相似,因此在本发明中同样把接口当成类粒度依赖网络中的节点,则类粒度依赖关系还包括接口对接口的继承以及类对接口的实现两种情况。 下面给出软件包的类粒度依赖网络的形式化定义: CDN 对于顶点集: C=C 其中C 对于边集: 代表了软件包内部类与类、接口之间的依赖关系,对依赖项中类和接口的调用关系以及依赖项内部方法类、接口之间的依赖关系。图2为软件包A@1.0.0的与其依赖项中类粒度依赖的示意图。软件包A@1.0.0中有三个类:A@1.0.0:C1,A@1.0.0:C2,A@1.0.0:C3,其中A@1.0.0:C2是A@1.0.0:C1的子类,且没有重写A@1.0.0:C1中的方法;A@1.0.0:C2中的方法调用了A@1.0.0:C3中的方法,两者存在依赖关系;A@1.0.0:C3中方法一方面调用了依赖项接口B@1.2.0:I1中的方法,且该方法被类B@1.2.0:C2实现,另一方面调用了依赖项类C@2.1.0:C1中的方法,且该方法调用了自身类C@2.1.0:C2中的方法。根据前文的定义,图中绿色圆角矩形节点构成了C 总体方案架构 本发明总体方案架构如图3所示,首先通过包管理器的中央仓库获取项目的元数据、源代码以及可执行代码;然后基于项目的元数据,提出一种基于开源项目数据的包级别依赖网络构建方法;接着在包级别依赖网络的基础上,对开源软件及其依赖项构造API级别的调用依赖关系,从而构建方法级的软件供应链。 包级别依赖网络构建方法设计 在构建方法级依赖网络的之前,需要先根据包管理器提供的元数据构建出初步的依赖关系,即包级别依赖网络。其构建算法的整体流程如图4所示。给定一个目标软件包集合,本发明的构建方法为每个软件包的每个版本收集元数据信息,包括软件包名字、中央仓库地址、项目软件库托管地址、直接依赖项以及对直接依赖项的版本约束条件,这些元数据的信息主要来自于软件包中央仓库以及开源社区。然后将分布在中央仓库以及开源社区的元数据信息保存到本地的一个单一存储库中,以便后续进一步的分析与构建。对于获取到的元数据,首先从中抽取出需要的节点信息。对于不同包管理器的中央仓库,其提供的元数据格式不一,且各字段格式混乱未进行标准化,需要对其进行清洗。抽取出各节点信息后,需要对软件包的直接依赖关系进行解析,在推理传递依赖时,错误的依赖版本解析可能会导致偏差。值得注意的是,不同包管理器元数据文件中对依赖项的版本声明并不总是一个固定版本号,而是非常灵活的范围约束。已有研究证明,许多软件包生态系统对语义版本规范semver的遵循程度在逐渐增加。因此,在进行依赖解析时,本发明基于semver实现了一个依赖项约束解析器,能够处理各种依赖项约束条件。最后,通过广度优先算法(BFS)实现对目标软件包集合依赖网络的构建,存取到图数据库中。 下面对涉及到的依赖解析算法和网络构建算法进行具体介绍: 依赖约束解析 不同的软件包生态系统倾向于使用不同的语法符号来指定依赖关系约束,这种依赖关系约束的多样性使得解析正确的版本变得十分复杂,目前没有已有的工作能够将依赖约束的各种主要类型进行很好的处理。因此,本发明基于语义版本规范semver以及包生态系统提供的文档实现了一个依赖项约束求解器,以便尽可能多地处理依赖约束。 semver是由GitHub的联合创始人Tom Preston-Werner建立,由于它常被许多软件包管理系统和其他开源甚至商业软件项目所使用,它可以被认为是一个事实上的标准。一个有效的semver版本语法格式的形式化定义如表1所示。概括来说,一个典型的semver版本表达式为: Version=Major.Minor.Patch 例如版本号1.2.0。其中,当对软件包进行了不兼容的API修改时,递增主版本号Major;当对软件包做了向后兼容的功能新增时,递增次版本号Minor;当对软件包做了向后兼容的bug修复时,递增修订号Patch。此外,可以在上述版本号后面加上先行版本标签pre-release和版本编译信息标签build-metadata。为了对依赖项约束进行解析,首先需要确定版本之间优先级比较规则,根据semver规范,本发明采用的优先级比较规则如表2所示,其中规则4-7针对major、minor、patch相同的两个带pre-release标签的版本号,通过比较从左至右按“.”分割的标识符差异确定。 表1 semver版本语法格式 表2 semver版本优先级比较规则 不同的包生态系统对依赖项约束的表达形式不尽相同,因此需要先对依赖项约束进行归一化。依赖项约束通常由一些符号和版本号构成,符号与版本号不规范的情况分别如表3与表4所示。对于归一化之后的依赖项约束,本发明根据包生态系统相关文档以及前文描述的semver优先级比较规则,将其翻译成相对应版本范围,归一化之后的依赖约束与对应的版本范围映射规则如表5所示。 表3约束中符号不规范的归一化 表4约束中版本号不规范的归一化 在解析依赖项的版本时,本发明首先提取出元数据中对该依赖项的约束,然后根据上述映射规则将其转换为一个版本范围;访问本地的元数据库或者中央仓库取得该依赖项在当前时间节点的列表;根据依赖约束映射出来的版本范围以及该依赖项当前的版本列表,求解出一个最高的版本号作为解析结果。 表5归一化依赖约束与版本范围映射规则表 /> 网络构建算法 本发明基于广度优先策略实现了一个包级别依赖网络的构建算法,算法大致流程如图5所示: 具体算法如表6所示,输入为一个待分析的软件包队列,算法1-3行先对已访问软件包列表seenPkg、待提交指令数orderCnt、输出包级别依赖网络cgdn置空。5-8行遍历初始队列里的每一个软件包pkg,首先访问本地是否有pkg的元数据文件metadata,如果不存在需要访问对应编程语言中央仓库给出的API,并将其缓存到本地。接着,算法第9行根据获取到的元数据文件,获取当前软件包的基本信息并进行依赖项解析。元数据信息包括名称、版本、源码仓库地址、直接依赖项等;对于依赖项约束的解析,按照4.4.1中方法进行实现。10-12行取软件名称和版本信息作为唯一id,在neo4j数据库生成节点,上述基本信息作为节点属性,同时将当前软件包id加入到已访问的队列seenPkg中避免重复访问;13-15行遍历从元数据文件里获取解析出当前软件包的所有直接依赖项,对每一个依赖项dep,生成依赖边pkg→dep。为了获取软件包的传递依赖,16-18行先判断依赖项dep是否在已访问软件包列表seenPkg中,或者在之前的执行过程中是否已经在数据库中生成了dep的依赖网络,否则就将其加入待构建队列,这样可以避免重复构建同一个软件包的依赖网络以减少算法的执行时间。当待分析队列为空时,说明每个软件包及其所有的直接、传递依赖都已经解析完成。在执行数据库插入操作时,为了提高速度,将一定数量的节点生成或边生成操作指令放入一个事务中进行提交,20-23行检查当前的待提交指令数是否达到阈值BATCH_SIZE,如果是则提交当前所有指令,经试验BATCH_SIZE设为1000-2000效果较好。在算法的最后提交剩余的指令,完成输入队列中所有软件包级别依赖网络cdnkg的构建。 表6包级别依赖网络构建算法 方法级依赖网络构建方法设计 方法级依赖网络的构建不同于包级别依赖网络,包级别依赖网络从软件发行版层面上捕获依赖关系,然而真实的软件重用发生在代码层面,因此方法级依赖网络的构建需要深入到软件包内部代码进行分析。因此,本发明的构建方法基于程序静态分析技术进行。 总体流程如图6所示。本发明的方法级依赖网络构建针对Maven托管的Java项目进行,主要分为三个阶段。第一个阶段,给定一个待构建方法级依赖网络的Maven项目坐标集,使用自定义的下载模块从Maven中央仓库将每一个Maven坐标对应的元数据文件pom.xml与字节码文件JAR保存到本地存储库;第二阶段,对于项目集中每一个Maven项目,首先通过将其pom.xml文件输入依赖解析器,得到在当前时间节点t的该项目的软件包依赖网络SPDN0,这个依赖图包含了该项目的所有直接依赖项和传递依赖项,然后对依赖图中的每一个依赖项,首先查询本地存储库是否存在其字节码文件,如果有则直接取出,否则访问中央仓库将其保存到本地;接着将该Maven项目与其所有依赖项的字节码文件路径作为输入传递给静态代码分析器。静态代码分析器通过读取每个字节码文件,提取出其中的方法依赖关系,为每个字节码文件生成一个方法依赖关系图,此时图中的方法节点标识符并未统一,且一个方法依赖关系图中的某个外部节点可能映射到另一个方法依赖关系图中的一个内部节点上,因此需要重新对其中的节点进行统一标识和内外节点映射,得到了本发明前一节定义的方法粒度依赖网络MDN;最后,使用多级粗化技术,以MDN作为输入,将具有相同名称空间的方法节点折叠到单个类节点中,生成类粒度依赖网络CDN,对CDN进行合并得到了初始Maven项目的一个新的软件包依赖网络SPDN,这些不同粒度的依赖网络将存在一个统一的图数据库中。值得注意的是,前文中依赖解析器求解得到的SPDN0与这个新的软件包依赖网络SPDN不同,前者是基于软件元数据求解,后者是从代码层面自底向上分析得到的。下面对构建过程进行具体介绍。 本地存储库构建 Maven Central是一个公共的、免费的、稳定的、可靠的软件仓库,通常是Maven构建工具默认的存储库。为了减少由于网络原因产生的时间成本,方便后续阶段的分析,本发明构建了一个本地的镜像存储库来存储Maven组件的构建文件pom.xml和已编译的二进制代码包JAR。通常一个Maven组件可由一个三元组唯一标识: GroupId:ArtifactId:Version 其中GroupId指定了Maven项目所属的组织或者公司,为了保证唯一性一般使用反转的域名格式(例如:com.example)。GroupId主要用于对依赖进行分类和组织,可以理解为依赖的命名空间。ArtifactId指定了项目或者库的名称,可以理解为依赖的ID。它一般是由开发人员自己定义的,但是需要保证在同一个GroupId下唯一,一般与项目或库的名称相关联。Version为具体的发行版本号。给定一个Maven坐标 网络定义与模式 本发明将对目标Maven项目构建出的MDN、CDN、PDN、SPDN存储到一个统一的图数据库中,形成一个方法级依赖网络(FGDN)。类似地,将FGDN定义成一个由带标记和属性的顶点集和有向边集组成的有向图: FGDN=(N,E) 其中顶点集N: N=SP∪C∪IF∪M 其中顶点集SP,C,IF,M: SP={sp C={c IF={if M={m sp E=E 主要分为两类,一类是同等粒度实体节点之间的关系: E 其中: 分别代表了Maven软件包之间、类之间、类与接口、接口之间、方法之间的关系集合。另一类为不同层次间实体节点的关系: E 其中: 分别表示了Maven软件包、类与接口、方法不同层次之间的关系集合。 图7展示了FGDN中每种类型节点和关系的详细模式。具体如下 (1)Software Package:该实体节点有六个属性,其中Id作为主键唯一地标识一个带版本的软件包节点,Name为Maven软件包名字,Version为版本号,Description对软件包的进行简要地描述,Time为此版本软件包的发布时间,Link为该软件包的项目主页地址; (2)Class和Interface:类粒度中存在两种实体节点Class实体和Interface实体,这两者较为相像但不完全相同,Id作为主键唯一标识一个类或者接口,Name为类名或者接口名,其中类还有IsAbstract属性来表示一个类是否是抽象类; (3)Method:该节点有四个属性,Id作为主键唯一标识一个方法,Name为方法名称,isStatic和isAbstract属性分别表示一个方法是否是静态方法和抽象方法。 (4)同等粒度的实体间关系:同等粒度的实体间联系中,Software Package实体节点间为“Software Package--Depend→Software Package”,且为多对多联系,即一个Maven软件包节点可以依赖多个其他Maven软件包,也可以被其他多个Maven软件包依赖。Class实体节点之间存在两种关系,一种为“Class-Extend→Class”,为一对多联系,即Maven项目中一个类可以被多个其他类继承,但是仅能从一个类继承,另一种为调用关系“Class--ClassCall→Class”,为多对多联系,即一个类可能调用多个其他类(通过方法调用产生),且一个类也可能被多个其他类调用。Interface实体节点间仅有一种关系“Interface--Extend→Interface”,且为多对多关系,即一个接口可以继承多个接口,也可以被多个接口继承。 (5)不同粒度的实体间关系:Class实体节点与Interface实体节点间存在“Class--Implement→Interface”关系,为多对多关系,一个类可以实现多个接口,一个接口也可以被多个类实现。对于不同层次间实体节点的关系,均为一对多的拥有关系,例如Software Package和Class实体节点间为“Software Package--HasClass→Class”关系,一个软件包内可以存在多个类,一个类只能定义在一个软件包内。 依赖项解析 在第二阶段中,基于pom.xml文件对一个Maven项目进行依赖解析。具体实现时,首先需要构建包级别依赖网络。这个过程基于4.4节中的方法实现。事实上,Maven项目中对依赖项的约束通常为一个固定版本号,因此对于版本约束的解析较为直接。对于同一个Maven软件包的多个版本出现在依赖解析过程中的情况,遵照Maven的“就近原则”选择最接近根项目的那个版本。此外,Maven使用scope字段来限制依赖关系的传递以及确定依赖项何时包含在类路径中,由于在项目的正常使用中不涉及scope为test的依赖项,在解析过程中对此类依赖项进行了排除。 方法级依赖网络的构建 在第二阶段中,对Maven项目进行字节码分析以提取出其中的方法依赖关系。算法大致流程如图8所示 表7描述了整个构建算法流程。算法的输入为目标Maven项目及其所有依赖项的JAR包,输出为目标Maven项目内的方法依赖关系集合,整个算法流程分为三个步骤。 表7Maven项目方法依赖关系构建算法 /> /> 第一步,由于可能存在Uber JAR的情况,需要从Maven项目JAR包中提取出所有属于其自身的类文件路径。所谓Uber JAR也被称作Fat JAR,它是指将依赖项同程序本身字节码嵌入到一个JAR包中。对于依赖项中存在的类文件,对其解析的结果不能归入目标Maven项目方法依赖关系集合中。因此,首先获取了目标Maven项目JAR中的所有类路径集合ClassPaths,然后遍历每一个依赖项JAR,取出对应的依赖项类路径集合depclassPaths,将depClassPaths与classPaths中的类路径进行对比,如果出现了完全一致的情况,则将其从ClassPaths中剔除,对所有依赖项类路径进行对比剔除之后,得到了目标Maven项目自身的类路径集合ClassPaths。 第二步,扫描每一个类路径对应的.class文件,从中提取出所有的方法调用关系。首先使用classParser加载字节码文件,获得一个JavaClass对象,接着使用getMethods和ConstantPoolGen获取该JavaClass的方法列表mthdlist、常量池信息cpg,然后遍历方法列表中的每一个方法,使用MethodGen为之生成一个方法对象,根据这个方法对象可以获取它的字节码指令列表instructionList,该列表描述了方法的具体执行流程。最后,遍历字节码指令列表中的每条指令,判断其是否属于一条方法调用指令INVOKE,具体来说包括Java虚拟机内部指定了分派逻辑的四种调用指令类型:INVOKESTATIC、INVOKESPECIAL、INVOKEVIRTUAL、INVOKEINTERFACE,其中被前两种指令调用的方法,都可以在编译阶段确定唯一的调用版本。如果判断为方法调用指令,根据指令中的符号引用信息以及常量池信息cpg,为该指令生成一条方法调用关系并添加到该Maven项目的方法关系集合FR中。 第三步,由于面向对象的一些特性,一些方法的调用是在运行时确定具体的调用版本,例如1NVOKEINTERFACE类型的指令是指对接口方法的调用,而接口内部方法是没有实现体的,Java虚拟机会在运行时寻找一个实现了该接口的对象,调用它的实现版本,因此这里认为接口方法对其实现方法存在依赖关系。为了尽可能捕捉这类依赖关系,在第三步中进行补充。首先在第二步中保存了所有的类名到类信息的映射关系,将其存在一个全局的哈希表allClassInfo中。在第三步中,访问每一个字节码文件对应的类信息,获取其父类名和所实现的接口名列表,再从全局哈希表allClassInfo中查找出父类信息和所有的接口信息。接着,遍历当前类的每一个方法m,检查其是否为以下三种情况之一: /> 对于情况一,如果当前方法不是重写的,且在父类中存在一个方法名称和方法签名完全一致且为非私有且非抽象方法,则认为该方法是直接继承父类的,即对当前类该方法的调用实际上会调用到父类中的实现版本;对于情况二,如果父类中存在一个方法名称和方法签名完全一致的抽象方法,当前方法是非抽象的,则认为该方法是对父类抽象方法的实现,对父类抽象方法的调用会使用子类中的实现版本;对于情况三,如果当前方法为非抽象方法,且在其声明实现的某个接口中存在相同方法名称和方法签名的接口方法,则认为该方法是对接口方法的实现,即调用该接口方法会调用到该类中的实现版本。将这三种情况生成对应的方法依赖关系,作为补充添加到该Maven项目的方法关系集合FR中,算法最后返回FR。 节点名称统一标识与归一 为了得到的统一的方法依赖网络(MDN),需要重写FR中的每一个方法标识符,使得其在全局唯一。在依赖树中不同的包可能存在相同名称的方法,此外在整个方法级依赖网络知识图谱中,可能存在同一个Maven项目的不同版本,其内部的方法可能存在大量同名,如果不对方法进行标识符统一,那么图谱将与真实的依赖关系不一致。使用以下的格式对FR中的每一个方法进行唯一标识: GroupId:ArtifactId:Version@Pkg:Class:Mthd(Args) 其中GroupId:ArtifactId:Version为该方法所在Maven项目的坐标,Pkg和Class为该方法所在的代码包名和类名,这两者构成一个类文件的完全限定名,可以标识出方法的命名空间。Mthd为方法的名称,Args为方法的所有参数。对于标识符的后半部分Pkg:Class:Mthd(Args),在进行字节码分析时每一个class都能够获取到该部分内容。为了将方法映射到对应的Maven坐标上,在扫描目标Maven项目及其所有依赖项的JAR包时,将其中的所有类路径与相应的Maven坐标存进一个全局哈希表时,重写标识符时根据类路径取出对应的Maven坐标进行拼接。然后,对目标项目及其依赖项FR中方法进行标识符重写之后,可以很方便地将标识符相同的节点进行合并,即一个方法依赖关系图中的某个外部节点映射到另一个方法依赖关系图中的一个内部节点上,合并之后便得到了目标Maven项目的方法依赖网络(MDN)。 网络粗化 粗化是一种图简化形式,它可以定义为图节点的聚合过程,以识别下一个粗化图的节点。为了构建最后的方法级软件供应链,首先将MDN作为输入将具有相同名称空间的方法节点折叠到单个类节点中,生成类粒度依赖网络CDN;类似地,输入CDN将具有相同命名空间的类节点合并得到了初始Maven项目的一个新的软件包依赖网络SPDN,将所有粒度的依赖网络按照前文定义的模式存入到一个统一的图数据库中,形成了最终的方法级软件供应链。