基于上下文的二进制算术编码和解码
文献发布时间:2023-06-19 09:52:39
技术领域
本实施例一般而言涉及用于视频编码或解码的方法和装置,并且更具体地涉及用于使用自适应量化的视频编码或解码的方法和装置。
背景技术
为了实现高压缩效率,图像和视频编解码方案通常采用预测和变换来充分利用视频内容中的空间和时间冗余性。一般而言,使用帧内或帧间预测来利用帧内或帧间相关性,然后对原始图像块与预测图像块之间的差异(常常表示为预测误差或预测残差)进行变换、量化和熵编解码。在编码期间,通常可能使用四叉树分割将原始图像块分割/拆分为子块。为了重建视频,通过与预测、变换、量化和熵编解码对应的逆处理来对压缩数据进行解码。
发明内容
给出的实施例中的一个或多个还提供了一种计算机可读存储介质,其上存储有根据上述任何方法的至少一部分用于对视频数据进行编码或解码的指令。一个或多个实施例还提供了一种计算机可读存储介质,其上存储有根据上述编码方法生成的比特流。一个或多个实施例还提供了一种用于发送或接收根据上述编码方法生成的比特流的方法和装置。一个或多个实施例还提供了一种计算机程序产品,该计算机程序产品包括用于执行上述任何方法的至少一部分的指令。
附图说明
图1描绘了给定输入编解码比特流的语法元素的CABAC(上下文自适应二进制算术编解码)解码处理;
图2描绘了比特流中语法元素的CABAC(上下文自适应二进制算术编解码)编码处理;
图3图示了如HEVC支持的8×8变换块中的不同扫描顺序;
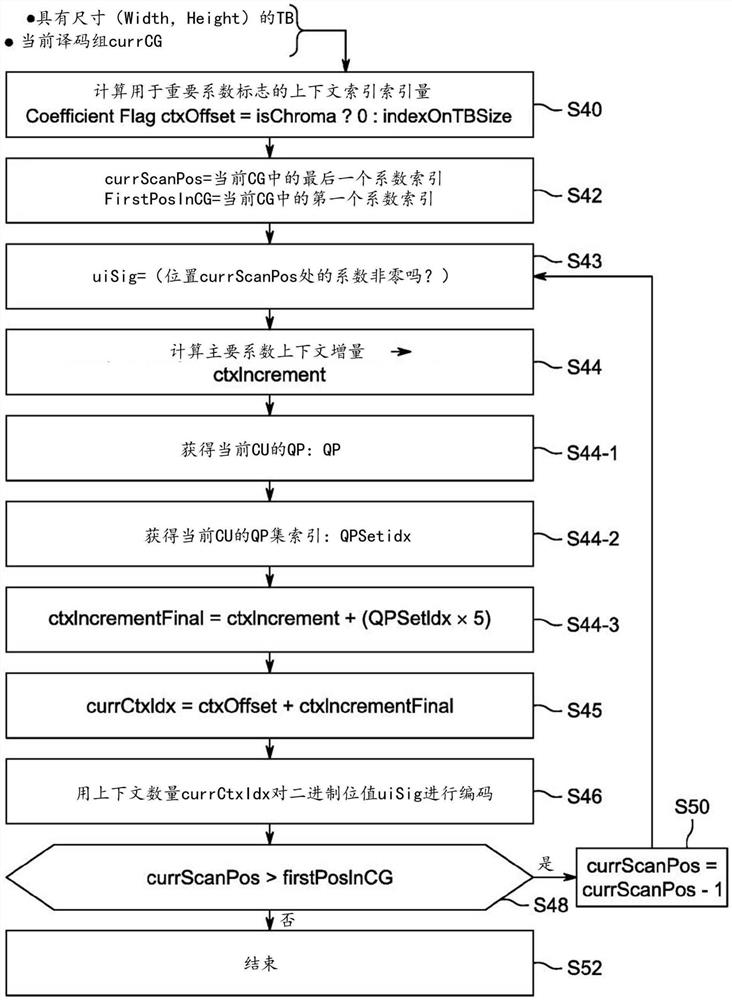
图4描绘了用于对重要性系数标志进行编解码的方法的流程图;
图5图示了用于对系数级别,特别是重要系数标志,进行编解码的基于模板的上下文模型选择的原理;
图6描绘了用于对编码单元的四叉树拆分标志进行编解码的上下文计算方法的流程图;
图7描绘了编解码树和编解码树中每个编解码单元的四叉树深度;
图8描绘了用于使用基于编解码单元的QP的上下文分离来对重要性系数标志进行编解码的方法的流程图;
图9和10描绘了根据各种实施例的用于对编解码单元的四叉树拆分标志进行编解码的上下文计算方法的流程图;
图11图示了根据实施例的视频编码器的框图;
图12图示了根据实施例的视频解码器的框图;以及
图13图示了其中实现各个方面和实施例的系统的示例的框图。
具体实施方式
自适应(或可变)量化被广泛用于以给定的比特速率(bitrate)优化解码的视频的视觉质量。作为示例,可以在同一条带内采用可变量化参数(QP)。通常,通过将更多的比特分配给感知敏感的图片区域来获得感知上优化编码。
在使用多个QP对一个图片进行编码的假设下,至少一个实施例提出提高视频编码系统的压缩效率。
在传统的标准视频压缩方案中,一些比特流语法元素的熵编码采用已知的上下文自适应二进制算术编码(Context Adaptive Binary Arithmetic Coding,CABAC)。
这包括表示每个语法元素(或符号)以便以一系列称为“二进制位(bin)”的二进制符号的形式进行编码。每个二进制位可以被算术编解码。二进制位等于1或0的概率是条件概率,这取决于所考虑的二进制位与之相关的一些上下文状态/信息。
这些条件概率定义所谓的上下文模型,该上下文模型表示与所考虑的二进制符号对应的随机变量的统计行为。当处理所考虑的二进制位时,可以根据编解码器的上下文状态来自适应地选择用于对所考虑的二进制位进行编码/解码的上下文。
因此,为了选择适于对所考虑的二进制位进行编码/解码的上下文,计算上下文索引,然后将其用于识别用于编码/解码的上下文。
通常,对于一些周围(顶部、左侧)已经编解码的块,上下文索引可以取决于所考虑的符号所取的值。
只要对“二进制位”进行编码,例如对于图片中连续的块,所关注的上下文模型(即,与上下文相关联的条件概率)就根据二进制位连续获取的值被更新。
上下文概率的更新分别在HEVC和JEM(联合勘探模型,“联合勘探测试模型7(JEM7)的算法描述(Algorithm description of Joint Exploration Test Model 7(JEM7))”,J.Chen,E.Alshina,GJ Sullivan,J.-R.Ohm,J.Boyce(编辑),JVET-G1001,2017年8月)中考虑了单个或两个滑动窗口。它旨在逐步使条件概率与所考虑的二进制位的统计行为相匹配,并尽可能准确。上下文模型更新处理还具有给定的惯性(intertia),即,概率以一定的速度逐步收敛到二进制位的精确统计模式。
但是,一些语法元素的统计行为从一个QP到另一个显著变化。通常这是用于发信令通知一些拆分模式的二进制位或一些变换系数/块重要性信息的情况。确实,这种信息就速率级别而言很大程度上取决于编解码器操作点。
实际上,在QP在同一个编解码的条带内取多个值的情况下,一些语法元素的统计行为会改变,并且它们的相关联的上下文可以根据由于多个QP值引起的这些统计模型改变而被更新。
上下文模型更新系统具有一定程度的惯性,需要所关注的“二进制位”的几个事件才能使模型朝着准确的建模收敛。因此,就一些编解码的/解码的语法元素的统计行为模型的准确性而言,CABAC编码效率会遭受同一编解码的条带中多个QP之间切换的困扰。
在单个编解码的条带内的多个QP改变的情况下,至少一个实施例使CABAC编码/解码系统更高效。
通常,给定一些过去的事件,上下文模型由二进制位为1或0的两个条件概率组成。每次对二进制位进行解码时,都根据多假设系统来更新所关注的上下文模型。
就朝着准确的建模收敛而言,上下文模型概率更新处理具有一定的速度。通过条带类型和条带级别量化参数(QP),调整这个速度以优化编码效率。
但是,上下文概率更新处理没有考虑在给定条带内QP可能随块而变化的可能性。此外,对于编解码的视频语法的给定二进制符号,一般将相同的上下文用于所有QP值。
因此,对于QP在同一编解码的条带内随块改变的情况,没有优化CABAC算术编码引擎和上下文管理。
至少一个实施例在多个QP在单个编解码的条带内随块改变的情况下使CABAC编码/解码系统更高效。
以下各节描述几个实施方式。首先,描述各种语法元素的编码/解码。然后,描述在残差编码/解码中使用的语法元素的熵编码/解码的第一实施例的各种实施方式。然后,描述在拆分信息的编码/解码中使用的语法元素的熵编码/解码的第二实施例的不同实施方式。描述用于在基于上下文的熵编码中更新概率的第三实施例的各种实施方式。最后,描述使用旁路编码的至少一个实施例。至少一个实施例针对一些语法元素使用多个可能的上下文模型,并且根据在条带的编码/解码期间发生的QP改变从一个上下文集合切换到另一个上下文集合。
上下文自适应二进制算术编码(CABAC)和解码
图1描绘了给定输入编解码的比特流的语法元素的CABAC解码处理。
图1的处理的一个输入是编解码的比特流,例如符合HEVC规范、及其扩展或将来的视频编码标准。在解码处理的任何时候,解码器都知道接下来要解码哪个语法元素。这在标准化的比特流语法和解码处理中已完全指定。而且,它也知道如何对当前要解码的语法元素进行二进制化(即,表示为称为二进制位的二进制符号序列,每个二进制符号等于“1”或“0”)以及二进制位字符串的每个二进制位已经如何被编码。
因此,CABAC解码处理的第一阶段(图1的左侧)对一系列二进制位进行解码。对于每个二进制位,它知道它是否已根据旁路模式或常规模式进行了编码。旁路模式仅包括读取比特流中的比特并将获得的比特值指派给当前二进制位。这种模式的优点是简单明了,因此快速。图1的旁路解码引擎(10)以旁路模式执行解码。它通常用于具有统一统计分布的二进制位,即,等于“1”或“0”的概率相等。
相反,如果当前二进制位没有以旁路模式被编解码,那么意味着它已经以所谓的常规模式被编解码,即,通过基于上下文的算术编码。
在那种情况下,所考虑的二进制位的解码如下进行。首先,获得用于当前二进制位的解码的上下文。它由图1上所示的上下文建模器模块(12)给出。上下文的目标是在给定某个上下文先验信息X的情况下获得当前二进制位具有值“0”的条件概率。先验信息X通常是某个已经被解码的语法元素的值,在当前二进制位被解码时,该信息在编码器和解码器侧以同步的方式都可用。
通常,用于对二进制位进行解码的先验信息X在标准中以如下方式指定,即,该信息与要解码的当前二进制位在统计上相关。使用这个上下文信息的兴趣在于,它减少了对二进制位进行编码的速率成本。二进制位和X相互关联的事实使得给定X的情况下二进制位(bin)的条件熵(即,H(bin|X))降低。在信息理论中,以下关系是众所周知的:
H(bin|X) 这意味着知道X的bin的条件熵低于如果bin和X在统计上相关时bin的熵。因此,上下文信息X被用于获得bin为“0”或“1”的概率。给定这些条件概率,图1的常规解码引擎(14)执行二进制值bin的算术解码。然后,在知道当前上下文信息X的情况下,使用bin的值来更新与当前二进制位相关联的条件概率的值。这在图1上被称为上下文模型更新步骤。只要二进制位被解码(或编解码)就更新用于每个二进制位的上下文模型允许逐步细化用于每个二进制元素的上下文模型。因此,CABAC解码器逐步学习以常规模式编码的每个二进制位的统计行为。 当前二进制位的常规算术解码或旁路解码(取决于它被如何编解码)导致一系列解码的二进制位。 如图1的右侧所示,CABAC解码的第二阶段包括将这一系列二进制符号转换成更高级别的语法元素。语法元素可以采用标志的形式,在这种情况下,它直接取当前解码的二进制位的值。另一方面,如果根据所考虑的标准规范,当前语法元素的二进制化与几个二进制位的集合对应,那么转换模块发生,在图1上被称为“二进制码字到语法元素(BinaryCodeword to Syntax Element)”(16)。 这使得由编码器完成的二进制化步骤的互反(reciprocal)进行。因此,这里执行的逆转换包括基于这些语法元素相应的解码的二进制化版本来获得这些语法元素的值。 图2描绘了将语法元素转换成比特流的CABAC编码处理。这是图1的语法元素解码处理的互反处理。注意的是,上下文建模和上下文模型更新(12)在编码器侧和解码器侧是完全相同的操作。编码处理还包括二进制化器(20)、常规编码引擎(22)和旁路编码引擎(24)。二进制化器(20)包括获得语法元素的值的二进制化版本。 变换系数的熵编码中使用的上下文 首先,将变换块划分为量化系数的4×4子块,称为编解码组(CG)。熵编码/解码由几个扫描遍历组成,这些扫描遍历根据如图3上所示的几种可能的扫描模式当中选择的扫描模式来扫描TB(变换块)。 作为示例,包含在8×8TB中的编解码组(CG)在图3上示出。 HEVC中的变换系数编码涉及五个主要步骤:扫描、最后一个重要系数编码、有效图编码、系数级别编码以及符号数据编码。 对于帧间块,使用图3左侧的对角线扫描,而对于4×4和8×8帧内块,扫描顺序取决于对于那些块处于活动状态的帧内预测模式。 然后,对TB的扫描遍历包括根据三种扫描模式(对角线、水平、垂直)之一依次处理每个CG,并且每个CG内的16个系数也根据所考虑的扫描顺序被扫描。扫描遍历在TB中的最后一个重要系数开始,并处理所有系数,直到DC系数为止。 变换系数的熵编码最多包括五个扫描遍历,分别专用于以下列表中每个语法元素的编码: ●significant-coeff-flag:系数的重要性指示系数是零还是非零。 ●coeff-abs-level-greater1-flag:指示系数级别的绝对值是否大于1。 ●coeff-abs-level-greater2-flag:指示系数级别的绝对值是否大于2 ●coeff-sign-flag:重要系数的符号(0:正,1:负)。 ●coeff-abs-level-remaining:系数级别的绝对值的剩余值(如果该值大于之前遍历中编解码的值)。 一旦在解码器侧通过执行上面前四个扫描遍历的子集而知道了系数的绝对值,就在针对那个系数的剩余遍历中关于其绝对值不再对其它语法元素进行解码。类似地,仅对于解码器基于重要性遍历知道其不等于零的系数,才用信令通知coeff-sign-flag,因此对其进行解码。 编码器针对给定的CG执行所有扫描遍历,直到在转到下一个CG之前可以通过对应的解码处理重建那个CG中的所有量化系数为止。 扫描遍历是按扫描顺序在给定CG中所有量化系数上的循环。 整个TB解析处理由以下步骤组成: 1.解码最后一个重要坐标。这包括以下语法元素: last_sig_coeff_x_prefi、last_sig_coeff_y_prefix、 last_sig_coeff_x_suffix和last_sig_coeff_y_suffix 这为解码器提供了整个TB中最后一个非零系数的空间位置(x和y坐标)。 然后,对于从TB中包含最后一个重要系数的CG到TB中左上角CG的每个连续CG,以下步骤适用: 2.对CG重要性标志进行解码,其在HEVC规范中被称为 coded_sub_block_flag。 3.对所考虑的CG中的每个系数的重要系数标志进行解码。这与HEVC规范中的语法元素sig_coeff_flag对应。这指示CG中哪些系数非零。 接下来的解析阶段旨在发信令通知在所考虑的CG中被称为非零的系数的系数级别。这涉及以下语法元素。 4.coeff_aba_level_greater1_flag:这个标志指示当前系数的绝对值是否大于1。如果不是,那么绝对值是否等于1。 5.coeff_aba_level_greater2_flag:这个标志指示当前系数的绝对值是否大于1。如果不是,那么绝对值是否等于2。 6.coeff_sign_flag:这个标志指示非零系数的符号coeff_abs_level_remaining对绝对值大于2的系数的绝对值进行编码。 重要标志的编码 图4描绘了重要系数编码处理。 该处理的输入是要编码的变换块(TB)和所考虑的TB中的当前编码组currCG。TB的尺寸由(width,height)定义。该处理的第一步(S40)旨在计算用于对重要系数标志进行编码的基本上下文索引的索引。更精确地说,ctxOffset是在S40处计算的。如图4上所示,它取决于TB尺寸,更精确地说,取决于TB面积。实际上,计算以下值: uiLog2BlkSize=(log2(width)+log2(height))>>1 如果当前TB是亮度块,那么根据这个值uiLog2BlkSize确定用于对重要系数标志进行编码的上下文。 indexOnTbSize=uiLog2BlkSize≤2?0:f(uiLog2BlkSize) 在实施例中,f()是定义的函数,例如以查找表的形式,并且(a
这意味着采用分离的CABAC上下文集合来对具有不同面积(即,不同的uiLog2BlkSize)的TB的重要系数标志进行编码。 这些不同的上下文集合由全局加索引的上下文集合中的上下文地址ctxOffset来表示,其对于重要系数标志的编码是有用的。 图4的编码处理的后续步骤包括在当前TB的当前编码组中的每个系数上从最后一个系数朝着最低频率系数的循环。 在步骤S42处初始化这个循环,该步骤S42在解析处理期间根据给定编解码组中的量化系数的HEVC扫描来计算所考虑的编解码组中的起始系数位置firstPosInCG和最后一个系数位置currScanPos。在S43处,将重要系数标志或重要性(也为sig_coeff_flag)确定为变量uiSig,如果currScanPos中的系数非零,那么uiSig为1,否则为0。 对于每个系数,在步骤S45处根据上下文偏移(ctxOffset)和上下文增量(ctxIncrement)来计算用于对其重要性进行编码的上下文索引currCtxIdx。它包括计算上下文增量(S44),如稍后参考图5所描述的。 一旦获得了当前系数的上下文索引currCtxIdx(由currScanPos定义),就在步骤S46中基于由currCtxIdx识别出的上下文对由变量uiSig表示的重要性二进制位进行熵编码(例如,CABAC编码)。在步骤S48中,该方法检查currScanPos是否大于firstPosInCG。如果步骤S48中的检查为真(true),那么该方法在步骤S50中将currScanPos递减1并返回到步骤S43。如果步骤S48中的检查为假(false),那么该方法在步骤S52中结束。 图4的上下文增量计算(S44)取决于被局部模板覆盖的邻域中先前编解码的系数的重要系数标志值的值。更具体而言,基于相邻系数的重要标志之和来确定上下文索引。模板在图5上用白色(X0至X4)描绘。为了以不同频率捕获变换系数的特点,将一个TB拆分为多达三个区域,并且不管TB尺寸如何,拆分方法都是固定的,如图5中所示。每个TB被拆分为三个标有不同灰色级别的区域,并示出指派给每个区域的上下文索引。例如,第一个区域(TB的左上部分)被指派有上下文索引12到17。 与给定变换系数X相关联的上下文增量ctxIncrement计算如下: -计算相邻系数的集合(x -系数X所属的对角线的索引被计算为其坐标之和: diag=posX(X)+poxY(X) -最后,用于当前系数X的上下文增量计算如下: ctxIncrement=(diag<2?6:0)+(diag<5?6:0)+num 亮度和色度分量以相似的方式进行处理,但具有分离的上下文模型集。 通过将上下文增量ctxIncrement添加到上下文偏移ctxOffset来计算(S45)用于系数的重要性的编码的上下文索引。一旦获得了当前系数的上下文索引currCtxIdx,就对其由变量uiSig表示的重要性二进制位进行算术编码。一旦循环已经处理了当前CG中具有最低频率的系数,处理就结束(S48,S50)。当所考虑的CG中具有最低频率的系数已经被处理时,处理结束(S52)。 拆分信息的编码 图6描绘了用于编解码单元(CU)四叉树拆分标志处理的编码的上下文计算。 用于在编解码树中对拆分信息进行编码/解码的语法元素如下: -四叉树拆分标志指示CU是否以四叉树方式被拆分。例如,用于四叉树拆分标志的编码的上下文是相对于已编解码的周围CU的四叉树深度、根据当前CU的四叉树深度的值来确定的。在5个可能的上下文中选择上下文来对四叉树CU拆分标志进行编码/解析。图6的算法描绘了上下文标识符对CU四叉树拆分标志进行编码的计算。如可以看出的,相对于已经编解码/解析的周围CU的四叉树深度,根据当前CU的四叉树深度来确定上下文。CU的四叉树深度表示将CTU逐步拆分为更小的编解码单元时四叉树部分的深度级别。在图7上,图示了被划分为编解码单元的示例性CTU。还给出了每个编解码单元的四叉树深度。这个四叉树深度取决于导致所考虑的CU的四叉树拆分的数量。二元或三元拆分不包括在四叉树深度的计算中。 图6的图上表示的数量定义如下: ○ctxIdx表示正被确定的上下文的索引。它由图6的算法计算,并且相关联的上下文用在CU四叉树拆分标志的编码中。 ○leftQTDepth表示位于当前CU的左上角的左侧的CU的四叉树深度。 ○topQTDepth表示位于当前CU的左上角的顶部的CU的四叉树深度。 ○bottomLeftQTDepth表示位于当前CU的左下角的左侧的CU的四叉树深度。 ○topRightQTDepth表示位于当前CU的右上角的顶部的CU的四叉树深度。 ○currQTDepth是当前CU的四叉树深度。 -二进制/三进制拆分标志指示未以四叉树方式拆分的CU是否以二进制或三进制方式拆分。如果不是,那么CU根本不拆分。该标志在下文中被称为BT拆分标志。为了对其进行编码或解析,使用3种可能的上下文当中的CABAC上下文。相对于左侧和顶部相邻CU或当前CU的组合深度,根据组合的四叉树和二叉树深度来计算上下文id。 -二进制/三进制拆分模式的朝向。这个朝向(水平或垂直)通过标志发信令通知。它基于上下文被编解码/解析。取决于块的形状,对应的上下文取值0、1或2。计算方法如下: btSplitOrientationContextIdx=(width==height)?0:(width>height?1:2) -三元拆分模式标志指示对于当前CU是否使用三元拆分模式。它基于上下文被编解码/解析。取决于拆分的朝向和块的形状,使用6种可能的上下文当中的上下文。 返回到图6,ctxId被初始化为零。在左侧CU(即,位于当前CU的左上角的左侧的CU)可用的情况下(S60),将leftQTDepth与currQTDepth进行比较(S62)。在leftQTDepth>currQTDepth的情况下,将ctxIdx设置为等于ctxId+1(S64),并且方法继续到S66。否则(即,左侧CU不可用或leftQTDepth≤currQTDepth),方法继续到S66。 在顶部CU(即,位于当前CU的左上角的顶部的CU)可用的情况下(S66),将topQTDepth与currQTDepth进行比较(S68)。在topQTDepth>currQTDepth的情况下,将ctxIdx设置为等于ctxId+1(S70),并且方法继续到S72。否则(即,顶部CU不可用或leftQTDepth≤currQTDepth),方法继续到S72。将minQTDepth设置为等于leftQTDepth、topQTDepth、bottomLeftQTDepth、topRightQTDepth之间的最小值(S72)。将maxQTDepth设置为等于leftQTDepth、topQTDepth、bottomLeftQTDepth、topRightQTDepth之间的最大值(S72)。在currQTDepth<minQTDepth的情况下,将ctxIdx设置为3(S74,S76),并且方法继续到S78。否则,方法继续到S78。在currQTDepth>maxQTDepth的情况下,将ctxIdx设置为4(S80),并且方法结束(S98)。否则,方法结束。 第一实施例:通过QP值分离上下文以对残差块的变换系数进行编码 根据第一实施例,根据QP值来分离用于对变换系数进行编码的上下文。 换句话说,关于变换系数,具有不同QP值的两个CU利用不同的上下文集合被编码和解码。 根据变体,仅当相应的QP值足够不同时,即,两个QP值之间的绝对差高于给定值时,才使用分离的上下文集合。 根据变体,使用有限数量的分离的上下文集合,以对用于对残差块进行编码和解码的上下文的总数进行限制。在这种情况下,每个QP范围定义一个上下文集合。CU的语法元素使用与CU的QP所属的QP范围相关联的上下文集合进行编码。在示例中,最多可以使用3个不同的基于QP的上下文集合。 在实践中,用于对给定系数重要标志进行编码的上下文的标识符的确定将类似于在标题为“重要标志的编码”一节中所描述的方法。区别在于上下文id也根据所考虑的CU的QP值进行区分。 例如,在现有技术中,如标题为“重要标志的编码”一节中所描述的那样来计算量ctxIncrement。在此,让我们假设基于QP值使用3个分离的上下文集合。 在那种情况下,用于对所考虑的重要性标志进行编码的最终上下文增量值通常变为: contextIncrementFinal=NctxIncrement×QPsetIdx+ctxIncrement(等式1) 其中: -NctxIncreement是ctxIncrement的可能值的数量(这里为5)。 -QPSetIdx是基于QP的上下文集合的索引。如果使用最多3个分离的上下文集合,那么QPSetIdx等于0、1或2。 根据实施例,提出的基于QP的上下文分离仅在lastSignificantX和lastSignificantY语法元素的编码和解析中采用。 本节中描述的第一实施例可以应用于以下语法元素中的每一个,这些语法元素采用基于上下文的二进制算术编码: -last_sig_coeff_x_prefix,last_sig_coeff_y_prefix -coded_sub_block_flag -coeff_abs_level_greater1_flag -coeff_abs_level_greater2_flag 在图8上图示了第一实施例。与图4的步骤完全相同的图8的步骤由相同的附图标志识别并且不再进一步公开。图8包括根据所提出的第一实施例的、旨在计算最终上下文索引增量ctxIncrementFinal的附加步骤,该最终上下文索引增量ctxIncrementFinal被用于获得实际用于对量化系数的重要标志进行编码的CABAC上下文。通过获得当前CU的QP(S44-1)、从当前CU的QP获得QP范围索引QPSetIdx(S44-2),然后根据等式(等式1)计算(S44-3)最终上下文索引增量,获得最终上下文索引增量。在S45处,将最终上下文索引增量ctxIncrementFinal添加到ctxOffset,以获得currCtxIdx。 第二实施例:通过QP值分离上下文以对CU拆分信息进行编码 根据第二实施例,利用基于所考虑的编解码单元的QP值选择的上下文来对指示CU分割的标志进行编解码/解析。这意味着具有不同QP值的两个CU为它们相关联的拆分标志的CABAC编码采用分离的上下文集合。 根据变体,仅当相应的QP值足够不同时,即,两个QP值之间的绝对差高于给定值时,才使用分离的上下文集合。 根据变体,使用有限数量的分离的上下文集合,以对用于对残差块进行编码和解码的上下文的总数进行限制。 图9图示了本节中介绍的实施例。与图6的步骤完全相同的图9的步骤(S60至S80)由相同的附图标志识别并且不再进一步描述。这个实施例特有的图9的处理的步骤是流程图的最后三个步骤,即,S92、S94和S96。 在S92处,获得当前CU的QP,称为当前QP。接下来,在S94处,计算当前QP所属的QP值的集合。实际上,考虑有限数量的QP值的集合。当基于QP分离上下文时,这导致CABAC上下文的数量的有限增加。QP索引集(记为QPSetIdx)的计算可以采用以下形式: QPSetIdx=floor(max(min((QP–30)/4+2,4),0)) 其中:如果a>=b,那么max(a,b)返回a,否则返回b;如果a<=b,那么min(a,b)返回a,否则返回b;并且floor(a)返回小于或等于x的最大整数。 注意的是,在这个特定实施方式中,使用了5个QP值集。通过使用以下经修改的公式,可以实现减少到3个QP范围集: QPSetIdx=floor(max(min((QP–30)/5+2,2),0)) 特别地,变换上下文标识符的步骤(S96)如下: ctxIdx=ctxIdx+(QPSetIdx×5) 它旨在分离上下文。在现有技术中,使用5个可能的上下文(从0至4索引的)来选择上下文以对CU四叉树拆分标志进行编码。现在根据上述上下文id变换,在使用三个QP范围来分离上下文的情况下,最终上下文id在3×5=15个可能值的整个集合中取其值。换句话说,保留了现有技术的上下文id的计算,但是如此计算的上下文id被用于在由QPSetIdx值索引的上下文集合中选择上下文。QPSetIdx值是从当前CU的QP值,更精确地说是当前QP值所属的QP范围,得到的索引。作为示例,如果使用3个分离的上下文集合,那么QPSetIdx等于0、1或2。 本节中描述的第二实施例可以对以下语法元素应用。 -四叉树拆分标志 -二元/三元拆分标志 -二元/三元拆分朝向标志 -三元拆分模式标志 第三实施例:根据连续编解码单元的QP值来更新上下文概率 根据另一个实施例,仅在以下情况下才进行与给定上下文相关联的概率的更新:用于当前CU中的CABAC编码的上下文信息来自具有与当前CU的QP值、或接近当前CU的QP值的QP值相同的QP值的一个或几个相邻CU。接近当前QP通常意味着两个QP之间的绝对差低于给定值。如果不是这种情况,即,如果两个QP之间的距离太大,那么绕过上下文概率更新步骤。 在一个实施例中,如果当前CU中没有相邻的CU具有与当前CU相同的QP(或接近的QP),那么选择旁路模式来对当前CU的四叉树拆分标志进行编码和解析。 如果至少一个相邻CU具有与当前CU相同的QP(或接近的QP),那么仅考虑用与当前CU具有相同的QP(或接近的QP)的相邻CU来计算当前CU的四叉树标志的CABAC上下文。 实际上,在CABAC中,给定在考虑的二进制位被编码或解析时在编码器和解码器处都可用的一些上下文信息,上下文概率表示二进制符号(或二进制位)等于1(或0)的条件概率。 二进制位值对CABAC引擎中使用的上下文信息的统计依赖性甚至更重要,因为当前CU及其因果相邻CU是用相同的QP或用接近的QP编码的。 因此,在足够不同的QP值的情况下绕过上下文模型更新是有利的,因为它避免了降级CABAC上下文建模的准确性。 根据实施例,本节中描述的第三实施例与第一实施例和/或第二实施例结合使用。 根据另一个实施例,在不使用第一和第二实施例的情况下采用在本节中描述的第三实施例。 第四实施例:根据当前CU相对于相邻CU的QP值而采用基于上下文的编码 根据第四实施例,如果所考虑的二进制位和用于其编码/解析的上下文信息属于具有相同的QP值(或接近的QP值)的编码单元,那么使用二进制符号的基于上下文的编码(或者在变换系数中或者在拆分信息编码中使用)。 否则,以熵编解码器的已知旁路模式对所考虑的二进制符号进行编码,其包括在一比特上对二进制符号进行编码。这意味着在这种情况下,所考虑的二进制位未被算术编码。取而代之的是,将等于二进制符号(或等于其互补值)的比特直接写入编解码的比特流。 这个实施例由图10的图示出。与图6的模块完全相同的图10的模块(S60至S80)由相同的附图标志识别并且不再进一步描述。S60、S66和S72略有修改。在左侧CU可用(S60)并且具有与当前QP相同的QP(或与当前CU的QP接近的QP)的情况下,将leftQTDepth与currQTDepth进行比较(S62)。在顶部CU可用(S66)并且具有与当前QP相同的QP(或与当前CU的QP接近的QP)的情况下,将topQTDepth与currQTDepth进行比较(S68)。在S72中,minQTDepth和maxQTDepth的计算如下: minQTDepth =min(与当前CU具有相同(或接近)QP的周围CU的QT深度) maxQTDepth =max(与当前CU具有相同(或接近)QP的周围CU的QT深度) 在当前CU中没有相邻CU具有与当前CU相同的QP(或接近QP)的情况下,选择旁路模式来对当前CU的四叉树拆分标志进行编码和解析(S100)。 在与当前CU相邻的至少一个CU具有与当前CU相同的QP(或接近的QP)的情况下,仅考虑与当前CU具有相同的QP(或具有接近的QP)的相邻CU来计算当前CU的四叉树拆分标志的CABAC上下文(S102)。 最后,先前参考图8描述的先前在标题为“通过QP值分离上下文以对残差块的变换系数进行编码”的一节中先前引入的第一实施例也包括在图9的处理中(S92、S94和S96),以便在具有不同QP或属于不同QP值的集合的CU之间分离上下文。注意的是,这些上下文分离步骤是可选的,并且可以从图9的处理中丢弃。 本文档描述了包括工具、特征、实施例、模型、方法等在内的各种方面。这些方面中的许多是专门描述的,并且至少是为了示出各个特点,并且常常以听起来可能受到限制的方式来描述。但是,这是为了描述的清楚,并且不限制那些方面的应用或范围。实际上,所有不同方面都可以组合和互换以提供另外的方面。而且,这些方面也可以与先前申请中所述的方面进行组合和互换。 本文档中描述和设想的方面可以以许多不同的形式实现。下面的图11、12和13提供了一些实施例,但是可以设想其它实施例,并且对图11、12和13的讨论不限制实施方式的广度。这些方面中的至少一个方面一般而言涉及视频编码和解码,并且至少另一方面一般而言涉及传输所生成或编码的比特流。这些和其它方面可以被实现为方法、装置、其上存储有用于根据所描述的任何方法对视频数据进行编码或解码的指令的计算机可读存储介质,和/或其上存储有根据所描述的任何方法生成的比特流的计算机可读存储介质。 在本申请中,术语“重建的”和“解码的”可以互换使用,术语“像素”和“样点”可以互换使用,术语“图像”、“图片”和“帧”可以互换使用。通常但不是必需,术语“重建的”在编码器侧使用,而“解码的”在解码器侧使用。 本文描述了各种方法,并且每个方法包括用于实现所描述的方法的一个或多个步骤或动作。除非方法的正确操作要求步骤或动作的特定顺序,否则可以修改或组合特定步骤和/或动作的顺序和/或使用。 本文档中描述的各种方法和其它方面可以被用于修改如图11和12中所示的视频编码器100和解码器200的模块,例如熵编码和/或解码模块(145、230)。而且,本方面不限于VVC或HEVC,并且可以应用于例如其它标准和建议(无论是预先存在的还是将来开发的),以及任何此类标准和建议的扩展(包括VVC和HEVC)。除非另有指示或技术上被禁止,否则本文档中描述的各个方面可以单独使用或组合使用。 在本文档中使用了各种数值,例如,不同的基于QP的上下文集合的数量。特定值是出于示例目的,并且所描述的方面不限于这些特定值。 图11图示了编码器100。这种编码器100的变化是预期的,但是为了清楚起见,下面描述编码器100,而没有描述所有预期的变化。在被编码之前,视频序列可以通过预编码(pre-encoding)处理(101),例如,对输入的彩色图片应用颜色变换(例如,从RGB 4:4:4到YCbCr 4:2:0的转换),或者执行输入的图片分量的重新映射,以便获得对压缩更有弹性的信号分布(例如,使用颜色分量之一的直方图均衡化)。元数据可以与预处理相关联,并附加到比特流。 在编码器100中,如下所述,由编码器元件对图片进行编码。以例如CU为单位对要编码的图片进行分割(102)和处理。使用例如或者帧内或者帧间模式对每个单元进行编码。当单元以帧内模式编码时,其执行帧内预测(160)。在帧间模式下,执行运动估计(175)和补偿(170)。编码器决定(105)使用帧内模式或帧间模式中的哪一个对单元进行编码,并且通过例如预测模式标志来指示帧内/帧间决定。例如通过从原始图像块减去(110)预测的块来计算预测残差。 然后对预测残差进行变换(125)和量化(130)。对量化的变换系数以及运动向量和其它语法元素进行熵编解码(145)以输出比特流。编码器可以跳过变换并将量化直接应用于未变换的残差信号。编码器可以绕过变换和量化两者,即,残差被直接编解码而无需应用变换或量化处理。 编码器对编码的块进行解码,以便为进一步的预测提供参考。对量化的变换系数进行去量化(140)和逆变换(150)以解码预测残差。通过组合(155)解码的预测残差和预测的块,重建图像块。环路滤波器(165)被应用于重建的图片以执行例如去方块/SAO(样本自适应偏移)滤波以减少编码伪像。经滤波的图像被存储在参考图片缓冲器(180)中。 图12图示了视频解码器200的框图。在解码器200中,如下所述,由解码器元件对比特流进行解码。视频解码器200一般执行与编码遍历(pass)对应的解码遍历,如图11中所述。编码器100一般还执行视频解码,作为对视频数据进行编码的一部分。 特别地,解码器的输入包括视频比特流,其可以由视频编码器100生成。首先对比特流进行熵解码(230),以获得变换系数、运动向量和其它编解码的信息。 图片分割信息指示图片如何被分割。因此,解码器可以根据解码后的图片分割信息来划分(235)图片。对变换系数进行去量化(240)和逆变换(250)以解码预测残差。组合(255)解码的预测残差和预测块,重建图像块。可以从帧内预测(260)或运动补偿的预测(即,帧间预测)(275)获得(270)预测块。环路滤波器(265)被应用于重建的图像。经滤波的图像被存储在参考图片缓冲器(280)中。 解码的图片还可以经历解码后处理(285),例如,执行在预编码处理(101)中执行的重新映射处理的逆的逆颜色变换(例如,从YCbCr 4:2:0到RGB 4:4:4的转换)或逆重新映射。解码后处理可以使用在预编码处理中导出并在比特流中用信令通知的元数据。 图13图示了其中实现各个方面和实施例的系统的示例的框图。系统1000可以被实施为包括以下描述的各种组件的设备,并且被配置为执行本文档中描述的一个或多个方面。此类设备的示例包括但不限于各种电子设备,诸如个人计算机、膝上型计算机、智能电话、平板计算机、数字多媒体机顶盒、数字电视接收器、个人视频记录系统、连网的家用电器,以及服务器。系统1000的元件可以单独或组合地实施在单个集成电路、多个IC和/或分立组件中。例如,在至少一个实施例中,系统1000的处理和编码器/解码器元件分布在多个IC和/或分立组件上。在各种实施例中,系统1000经由例如通信总线或通过专用输入和/或输出端口通信耦合到其它类似系统或其它电子设备。在各种实施例中,系统1000被配置为实现本文档中描述的一个或多个方面。 系统1000包括至少一个处理器1010,该至少一个处理器1010被配置为执行其中加载在其中的指令,以实现例如本文档中描述的各个方面。处理器1010可以包括嵌入式存储器、输入输出接口和本领域已知的各种其它电路系统。系统1000包括至少一个存储器1020(例如,易失性存储器设备,和/或非易失性存储器设备)。系统1000包括存储设备1040,其可以包括非易失性存储器和/或易失性存储器,包括但不限于EEPROM、ROM、PROM、RAM、DRAM、SRAM、闪存、磁盘驱动器和/或光盘驱动器。作为非限制性示例,存储设备1040可以包括内部存储设备、附接的存储设备和/或网络可访问的存储设备。 系统1000包括编码器/解码器模块1030,该编码器/解码器模块1030被配置为例如处理数据以提供编码的视频或解码的视频,并且编码器/解码器模块1030可以包括其自己的处理器和存储器。编码器/解码器模块1030表示可以被包括在设备中以执行编码和/或解码功能的(一个或多个)模块。如已知的,设备可以包括编码和解码模块之一或两者。此外,编码器/解码器模块1030可以被实现为系统1000的单独元件,或者可以作为硬件和软件的组合结合在处理器1010内,如本领域技术人员已知的。 可以将要加载到处理器1010或编码器/解码器1030上以执行本文档中描述的各个方面的程序代码存储在存储设备1040中,随后加载到存储器1020上以供处理器1010执行。根据各种实施例,在执行本文档中描述的处理期间,处理器1010、存储器1020、存储设备1040和编码器/解码器模块1030中的一个或多个可以存储各种项目中的一项或多项。这样存储的项目可以包括但不限于输入视频、解码的视频或解码的视频的一部分、比特流、矩阵、变量以及对等式、公式、运算和运算逻辑的中间或最终结果。 在几个实施例中,处理器1010和/或编码器/解码器模块1030内部的存储器被用于存储指令并为编码或解码期间所需的处理提供工作存储器。但是,在其它实施例中,处理设备外部的存储器(例如,处理设备可以是或者处理器1010或者编码器/解码器模块1030)被用于这些功能中的一个或多个。外部存储器可以是存储器1020和/或存储设备1040,例如,动态易失性存储器和/或非易失性闪存。在几个实施例中,外部非易失性闪存被用于存储电视的操作系统。在至少一个实施例中,快速外部动态易失性存储器(诸如RAM)被用作用于视频编码和解码操作的工作存储器,诸如用于MPEG-2、HEVC或VVC(通用视频编解码)。 如方框1130中所示,可以通过各种输入设备来提供对系统1000的元件的输入。此类输入设备包括但不限于(i)接收例如由广播公司通过空中传输的RF信号的RF部分、(ii)复合输入端子、(iii)USB输入端子,和/或(iv)HDMI输入端子。 在各种实施例中,方框1130的输入设备具有相关联的相应输入处理元件,如本领域中已知的。例如,RF部分可以必要地与以下元素相关联:(i)选择期望的频率(也称为选择信号,或将信号频带限制在一个频带内),(ii)下转换所选择的信号,(iii)再次频带限制到更窄的频带以选择(例如)在一些实施例中可以被称为信道的信号频带,(iv)解调下转换和限制频带的信号,(v)执行纠错,以及(vi)解复用以选择期望的数据分组流。各种实施例的RF部分包括执行这些功能的一个或多个元件,例如,频率选择器、信号选择器、频带限制器、信道选择器、滤波器、下转换器、解调器、纠错器和解复用器。RF部分可以包括执行这些功能中的各种功能的调谐器,包括例如将接收到的信号下转换为更低频率(例如,中频或近基带频率)或基带。在一个机顶盒实施例中,RF部分及其相关联的输入处理元件接收在有线(例如,电缆)介质上传输的RF信号,并通过滤波、下转换和再次滤波到期望的频带来执行频率选择。各种实施例重新布置上述(和其它)元件的顺序、移除这些元件中的一些,和/或添加执行相似或不同功能的其它元件。添加元件可以包括在现有元件之间插入元件,例如,插入放大器和模数转换器。在各种实施例中,RF部分包括天线。 此外,USB和/或HDMI端子可以包括相应的接口处理器,用于跨USB和/或HDMI连接将系统1000连接到其它电子设备。应该理解的是,输入处理的各个方面(例如,里德-所罗门(Reed-Solomon)纠错)可以根据需要例如在单独的输入处理IC内或在处理器1010内实现。类似地,USB或HDMI接口处理的各方面可以根据需要在单独的接口IC内或在处理器1010内实现。解调、纠错和解复用的流被提供给各种处理元件,包括例如处理器1010,以及与存储器和存储元件结合操作的编码器/解码器1030,以根据需要处理数据流以在输出设备上呈现。 可以在集成的壳体内提供系统1000的各种元件。在集成的壳体内,可以使用合适的连接布置1140(例如,本领域已知的内部总线,包括I2C总线、布线和印刷电路板)互连各种元件并在它们之间传输数据。 系统1000包括通信接口1050,其使得能够经由通信信道1060与其它设备通信。通信接口1050可以包括但不限于被配置为通过通信信道1060传输和接收数据的收发器。通信接口1050可以包括但不限于调制解调器或网卡,并且通信信道1060可以例如在有线和/或无线介质内实现。 在各种实施例中,使用诸如IEEE 802.11之类的Wi-Fi网络将数据流式传输到系统1000。这些实施例的Wi-Fi信号在适于Wi-Fi通信的通信信道1060和通信接口1050上被接收。这些实施例的通信信道1060通常连接到接入点或路由器,该接入点或路由器提供对包括互联网的外部网络的访问,以允许流式传输应用和其它空中通信。其它实施例使用机顶盒向系统1000提供流式传输的数据,该机顶盒通过输入块1130的HDMI连接来递送数据。还有其它实施例使用输入块1130的RF连接将流式传输的数据提供给系统1000。 系统1000可以向包括显示器1100、扬声器1110和其它外围设备1120的各种输出设备提供输出信号。在实施例的各种示例中,其它外围设备1120包括独立DVR、盘播放器、立体声系统、照明系统以及基于系统1000的输出提供功能的其它设备中的一个或多个。在各种实施例中,控制信号在有或没有用户干预的情况下使用诸如AV.Link、CEC或启用设备到设备控制的其它通信协议的信令在系统1000与显示器1100、扬声器1110或其它外围设备1120之间传送。输出设备可以经由通过相应接口1070、1080和1090的专用连接通信耦合到系统1000。可替代地,输出设备可以经由通信接口1050使用通信信道1060连接到系统1000。在电子设备(例如,电视)中,显示器1100和扬声器1110可以与系统1000的其它组件集成在单个单元中。在各种实施例中,显示接口1070包括显示驱动器,例如,定时控制器(T Con)芯片。 例如,如果输入1130的RF部分是单独的机顶盒的一部分,那么显示器1100和扬声器1110可以可替代地与其它组件中的一个或多个分开。在显示器1100和扬声器1110是外部组件的各种实施例中,可以经由包括例如HDMI端口、USB端口或COMP输出的专用输出连接来提供输出信号。 实施例可以通过由处理器1010实现的计算机软件或者通过硬件或者通过硬件和软件的组合来实现。作为非限制性示例,实施例可以由一个或多个集成电路实现。存储器1020可以是适于技术环境的任何类型,并且可以使用任何适当的数据存储技术来实现,作为非限制性示例,诸如光学存储器设备、磁存储器设备、基于半导体的存储器设备、固定存储器和可移动存储器。处理器1010可以是适于技术环境的任何类型,并且作为非限制性示例,可以涵盖微处理器、通用计算机、专用计算机和基于多核体系架构的处理器中的一个或多个。 各种实施方式涉及解码。如本申请中所使用的,“解码”可以涵盖例如对接收到的编码的序列执行以便产生适于显示的最终输出的处理的全部或部分。在各种实施例中,此类处理包括通常由解码器执行的处理中的一个或多个,例如,熵解码、逆量化、逆变换和差分解码。在各种实施例中,此类处理还,或者可替代地,包括由本申请中描述的各种实施方式的解码器执行的处理,例如,响应于与块相关联的量化参数而对块进行熵编码。 作为另外的示例,在一个实施例中,“解码”仅仅是指熵解码,在另一个实施例中,“解码”仅仅是指差分解码,在另一个实施例中,“解码”是指熵解码和差分解码的组合。基于特定描述的上下文,短语“解码处理”是旨在专门指操作的子集还是广义地指更广泛的解码处理将是显而易见的,并且相信本领域技术人员会很好地理解。 各种实施方式涉及编码。以与上面关于“解码”的讨论类似的方式,如在本申请中使用的,“编码”可以涵盖例如对输入视频序列执行以便产生编码的比特流的处理的全部或部分。在各种实施例中,此类处理包括通常由编码器执行的处理中的一个或多个,例如,分割、差分编码、变换、量化和熵编码。在各种实施例中,此类处理还,或者可替代地,包括由本申请中描述的各种实施方式的编码器执行的处理,例如,响应于与块相关联的量化参数而对块进行熵编码。 作为另外的示例,在一个实施例中,“编码”仅仅是指熵编码,在另一个实施例中,“编码”仅仅是指差分编码,在另一个实施例中,“编码”是指差分编码和熵编码的组合。基于特定描述的上下文,短语“编码处理”是旨在专门指操作的子集还是广义地指更广泛的编码处理将是显而易见的,并且相信本领域技术人员会很好地理解。 注意的是,如本文所使用的语法元素,例如,响应于与块相关联的量化参数而对块进行熵编码,是描述性术语。照此,它们不排除使用其它语法元素名称。 当将图作为流程图呈现时,应当理解的是,它还提供了对应装置的框图。类似地,当将图呈现为框图时,应当理解的是,它还提供了对应方法/处理的流程图。 在编码处理期间,常常给出计算复杂性的约束,通常考虑速率与失真之间的平衡或折衷。通常将率失真优化公式化为最小化率失真函数,该函数是速率和失真的加权和。有多种解决率失真优化问题的方法。例如,这些方法可以基于对包括所有考虑的模式或编码参数值在内的所有编码选项的广泛测试,并对其编码成本以及编码和解码之后重建的信号的相关失真进行完整评估。也可以使用更快的方法来节省编码复杂性,特别是基于预测或预测残差信号而不是重建的信号来计算近似失真。也可以使用这两种方法的混合,诸如通过仅对一些可能的编码选项使用近似失真,而对其它编码选项使用完全失真。其它方法仅评估可能的编码选项的子集。更一般地,许多方法采用多种技术中的任何一种来执行优化,但是优化不一定是对编码成本和相关失真两者的完整评估。 本文描述的实施方式和方面可以例如以方法或处理、装置、软件程序、数据流或信号来实现。即使仅在单一形式的实施方式的上下文中进行讨论(例如,仅作为方法讨论),所讨论的特征的实施方式也可以以其它形式(例如,装置或程序)来实现。装置可以例如以适当的硬件、软件和固件来实现。方法可以在例如处理器中实现,处理器一般是指处理设备,包括例如计算机、微处理器、集成电路或可编程逻辑设备。处理器还包括通信设备,诸如例如计算机、移动电话、便携式/个人数字助理(“PDA”)和有助于最终用户之间信息通信的其它设备。 对“一个实施例”或“实施例”或“一个实施方式”或“实施方式”以及它们的其它变体的引用是指结合该实施例描述的特定特征、结构、特性等包括在至少一个实施例中。因此,短语“在一个实施例中”或“在实施例中”或“在一个实施方式中”或“在实施方式中”以及任何其它变体在本文档中各处的出现不一定全部指相同的实施例。 此外,本文档可以提到“确定”各种信息。确定信息可以包括例如以下一项或多项:估计信息、计算信息、预测信息或从存储器中检索信息。 另外,本文档可以提到“访问”各种信息。访问信息可以包括例如以下一项或多项:接收信息、(例如,从存储器中)检索信息、存储信息、移动信息、复制信息、计算信息、确定信息、预测信息或估计信息。 此外,本文档可以提到“接收”各种信息。与“访问”一样,接收是广义的术语。接收信息可以包括以下一个或多个:例如,访问信息或检索信息(例如,从存储器)。另外,以一种或另一种方式,在诸如例如以下操作期间:存储信息、处理信息、发送信息、移动信息、复制信息、擦除信息、计算信息、确定信息、预测信息或估计信息,通常涉及“接收”。 应该认识到的是,例如在“A/B”、“A和/或B”和“A和B中的至少一个”的情况下使用以下“/”、“和/或”和“…中的至少一个”中的任何一个旨在涵盖仅选择第一个列出的选项(A),或者仅选择第二个列出的选项(B),或者选择两个选项(A和B)。作为另外的示例,在“A、B和/或C”和“A、B和C中的至少一个”的情况下,这种措词旨在涵盖仅选择第一个列出的选项(A),或仅选择第二个列出的选项(B),或仅选择第三个列出的选项(C),或仅选择第一个和第二个列出的选项(A和B),或仅选择第一个和第三个列出选项(A和C),或仅选择第二个和第三个列出的选项(B和C),或者选择所有三个选项(A和B和C)。如对于本领域和相关领域的普通技术人员显而易见的那样,这可以针对所列的多个项目扩展。 而且,如本文所使用的,词“信号”尤其是指向对应的解码器指示某些东西。例如,在某些实施例中,编码器用信令通知多个参数中的特定参数,以用于基于量化的熵编码。以这种方式,在实施例中,在编码器侧和解码器侧都使用相同的参数。因此,例如,编码器可以向解码器传输(明确信令通知)特定参数,使得解码器可以使用相同的特定参数。相反,如果解码器已经具有特定参数以及其它参数,那么可以使用信令而无需传输(隐式信令通知)以简单地允许解码器知道并选择特定参数。通过避免传输任何实际功能,在各种实施例中实现了位节省。应该认识到的是,可以以多种方式来完成信令通知。例如,在各种实施例中,一个或多个语法元素、标志等被用于将信息用信令通知给对应的解码器。虽然前面涉及词“信令通知”的动词形式,但词“信令通知”在本文中也可以用作名词信令通知。 如对于本领域普通技术人员将显而易见的,实施方式可以产生各种信号,这些信号被格式化为携带例如可以被存储或传输的信息。信息可以包括例如用于执行方法的指令或由所描述的实施方式之一产生的数据。例如,信号可以被格式化为携带所描述的实施例的比特流。可以将这种信号格式化为例如电磁波(例如,使用频谱的射频部分)或基带信号。格式化可以包括例如对数据流进行编码并且用编码的数据流来调制载波。信号携带的信息可以是例如模拟或数字信息。如已知的,信号可以通过各种不同的有线或无线链路传输。信号可以存储在处理器可读介质上。 我们已经描述了多个实施例。这些实施例至少提供以下跨各种不同的权利要求类别和类型的广义发明和权利要求,包括所有组合: ·一种方法,包括:响应于与块(例如,CU、TB、图片块)相关联的量化参数,对与所述块相关联的语法元素进行熵编码。 ·一种方法,包括:对与块相关联的语法元素进行基于上下文的熵编码,用于对块(例如,CU)进行熵编码的上下文是响应于与所述块相关联的量化参数来确定的。 ·在与块相关联的量化参数接近其相邻块之一(例如,左侧或顶部邻居)的至少一个量化参数的情况下,更新熵编码的概率,否则不更新。 ·在与块相关联的量化参数接近其相邻块(例如,左侧或顶部邻居)的所有量化参数的情况下,更新熵编码的概率,否则不更新。 ·如果两个量化参数的值相等,那么它们接近。 ·如果两个量化参数值之间的绝对差高于给定值,那么它们接近。 ·使用有限数量的分离的上下文集合。 ·在块的量化参数与其相邻块的量化参数不接近的情况下,以旁路模式对块进行编解码,否则使用上下文对块进行编解码。 ·熵编码是上下文自适应熵编码。 ·与块相关联的语法元素属于包括以下的语法元素集合:块的系数的重要性标志、指示块的系数级别的绝对值是否大于一或二的标志、用于对块中的最后一个重要系数(最后一个非零系数)的位置进行编码的元素、拆分标志(例如,二叉树拆分标志、三叉树拆分标志等)。 ·包括所描述的语法元素中的一个或多个或其变体的比特流或信号。 ·创建和/或发送和/或接收和/或解码包括所描述的语法元素中的一个或多个或其变体的比特流或信号。 ·执行根据所描述的任何实施例的基于量化参数的熵编码的TV、机顶盒、移动电话、平板电脑或其它电子设备。 ·执行根据所描述的任何实施例的基于量化参数的熵编码并显示(例如,使用监视器、屏幕或其它类型的显示器)结果图片的TV、机顶盒、移动电话、平板电脑或其它电子设备。 ·调谐(例如,使用调谐器)频道以接收包括编码的图像的信号并执行根据所描述的任何实施例的基于量化参数的熵编码的TV、机顶盒、移动电话、平板电脑或其它电子设备。 ·通过无线接收(例如,使用天线)包括编码的图像的信号并执行根据所描述的任何实施例的基于量化参数的熵编码的TV、机顶盒、移动电话、平板电脑或其它电子设备。 贯穿本公开,还支持并设想各种其它广义的以及特化的发明和权利要求。
- 基于上下文的二进制算术编码和解码
- 上下文自适应二进制算术编码的解码单元及解码方法