一种基于语音识别的构音障碍自动评估系统和方法
文献发布时间:2023-06-19 11:17:41
技术领域
本发明涉及构音障碍评估技术领域,尤其涉及一种基于语音识别的构音障碍自动评估系统和方法。
背景技术
构音障碍表现为说话含糊不清,不流利,发音不准,音量、韵律异常等。医生通常经过发音器官检查和言语评估来确认是否患有构音障碍以及病理程度。对学龄前儿童,上述表现可以通过语言训练来改善和治愈。因医生资源、时间有限以及互联网和移动设备的广泛使用,促使构音障碍的语言训练得以在移动设备应用程序(app)上进行。移动端语言训练效果的评估结果,能为使用者提供及时反馈,同时为训练程序设计者提供有利于个性化设计训练课程的重要信息。
目前有效的评估方法主要以听觉感知的主观方法为主,客观分析方法缺少关注,没有完备的构音障碍自动评估方案。已有的构音障碍识别方案是提取构音障碍语音的共振峰来计算声学参数,计算器官运动数据的舌唇偏移位移,再对声学参数和器官运动数据做相关性计算来识别构音障碍。还有用集成在OpenSMILE工具的语音分析eGeMAPS声学参数集,被用来分析其他语音相关的疾病,如失语症语音评估,但目前还没有用在构音障碍语音分析评估的案例。
在学术研究上,对于构音障碍语音的评估主要集中在元音及部分声学特征上。例如已有讨论共振峰集中比率(FCR3)、三角元音区域(TVSA)、嗓音起始时间(VOT)与构音障碍的相关性,其中共振峰集中比率和三角元音区域特征由元音固定发音来提取,嗓音起始时间则由含有目标辅音的短语中提取。由于固定发音和日常对话中的连续语音在发音质量和时长上有区别,在现有技术中描述的元音特征不适于语言训练课程中连续语音的部分。针对辅音,这种方法只关注了b、p、d、t、g和k六个辅音,同时对于嗓音起始时间这类特征的程序自动提取很难做到精确。另外,这些特征不足以充分反应构音障碍语音存在的问题,特别是辅音上存在置换现象导致的发音不准问题没被考虑。
综上,现有技术还缺乏有效的构音障碍自动评估手段,存在的主要问题是:听觉感知的主观评估方法缺少客观性、准确性和稳定性;没有实现障碍语音的自动评估;现有评估方法所使用的输入局限在有限的、孤立的字母发音,没有使用连续语音信息。
发明内容
本发明的目的在于克服上述现有技术的缺陷,提供一种基于语音识别的构音障碍自动评估系统和方法,旨在使用基于语音识别的言语特征提取方式,并结合深度学习的分类器进行构音障碍自动评估。
根据本发明的第一方面,提供了一种基于语音识别的构音障碍自动评估系统。该系统包括第一特征提取单元、第二特征提取单元、特征拼接单元、多层感知机、评估单元,所述特征拼接单元与所述第一特征提取单元、所述第二特征提取单元、所述多层感知机具有通信连接,所述评估单元与所述多层感知机具有通信连接,其中:所述第一特征提取单元用于提取传统的句子级别的声学特征;所述第二特征提取单元用于提取帧级别的音频标注和帧音素-概率对应关系,该帧音素-概率对应关系是一个帧所含音素及其后验概率组成的两元组的集合;所述特征拼接单元将所述第一特征提取的特征和所述第二特征提取单元提取的特征进行拼接处理,获得拼接特征;所述多层感知机用于基于拼接特征输出个体句子障碍程度类别和相应的预测概率;所述评估单元利用个体句子的预测概率信息得到总体评估结果。
在一个实施例中,所述第二特征提取单元被配置为对每个句子音频提取音素时长、音素替换率、近似发音质量、帧模糊率或帧音素数中的一项或多项。
在一个实施例中,所述多层感知机被配置为包括输入层、隐藏层和输出层,其中所述输出层设置为4个节点,分别对应“正常”、“轻微”、“中等”和“严重”四类构音障碍。
在一个实施例中,所述第二特征提取单元被配置为:
将标准文本标注和实际发音音频输入深度神经网络声学模型,通过强制对齐得到帧级别的关于118个发音的音频标注;
将实际发音音频输入深度神经网络声学模型,得到深度神经网络声学模型的输出层每个节点对应的音素及相应的高斯概率密度函数;
计算每一帧包含的音素及其后验概率,其中相同音素的高斯概率密度函数的输出相加得到音素后验概率,进而获得帧音素-概率对应关系。
在一个实施例中,所述第二特征提取单元被设置为对每个句子音频提取元音音素时长、辅音音素时长、总体音素时长、辅音替换率、元音替换率、总体替换率、辅音近似发音质量的均值、元音近似发音质量的均值、总体近似发音质量的均值、句子帧模糊率、辅音音素数、元音音素数、帧音素数中的一项或多项。
在一个实施例中,所述特征拼接单元被设置为将所述第一特征提取单元提取的特征和所述第二特征提取单元提取的特征进行最大-最小归一化作为所述多层感知机的输入。
根据本发明的第二方面,提供一种基于语音识别的构音障碍自动评估方法。该方法包括以下步骤:
提取传统的句子级别的声学特征;
提取帧级别的音频标注和帧音素-概率对应关系,该帧音素-概率对应关系是一个帧所含音素及其后验概率组成的两元组的集合;
将所述传统的句子级别的声学特征和基于所述帧音素-概率对应关系提取的特征进行拼接处理,获得拼接特征;
利用多层感知机基于所述拼接特征输出个体句子障碍程度类别和相应的预测概率;
利用个体句子的预测概率信息得到总体评估结果。
在一个实施例中,所述总体评估结果表示为:
其中,N表示被评估的语音句子数量,P
与现有技术相比,本发明的优点在于:基于语音识别技术进行客观分析来进行构音障碍评估,评估结果具有准确性和稳定性;基于连续语音中的发音音素提取特征,使得特征含有尽可能多的构音障碍语音相关的信息;所述提取的特征集包含传统声学特征与基于自动语音识别技术的特征,使得将构音障碍语音存在的问题更加完整地表征出来,提高了评估的准确率;自动评估过程为被评估者及时反馈其语言训练效果信息,节省了人力和时间资源。
附图说明
以下附图仅对本发明作示意性的说明和解释,并不用于限定本发明的范围,其中:
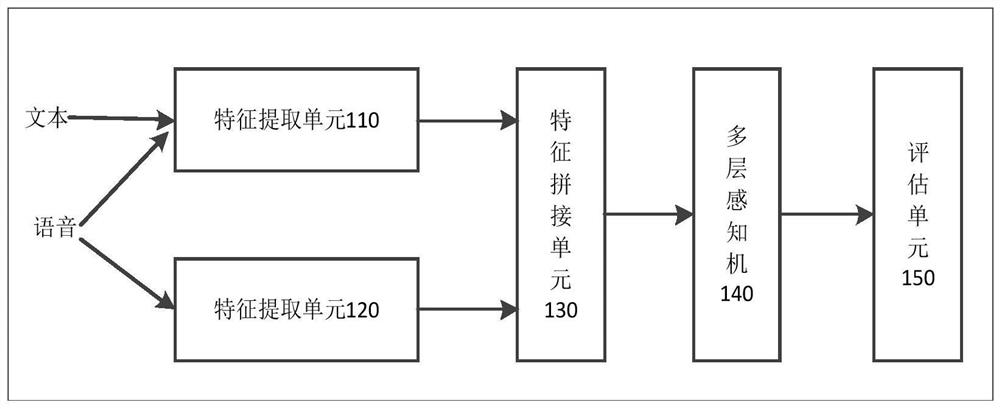
图1是根据本发明一个实施例的基于语音识别的构音障碍自动评估系统的示意图;
图2是根据本发明另一实施例的基于语音识别的构音障碍自动评估系统的示意图;
图3是根据本发明一个实施例的DNN声学模型框架的示意图。
具体实施方式
为了使本发明的目的、技术方案、设计方法及优点更加清楚明了,以下结合附图通过具体实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用于解释本发明,并不用于限定本发明。
在本文示出和讨论的所有例子中,任何具体值应被解释为仅仅是示例性的,而不是作为限制。因此,示例性实施例的其它例子可以具有不同的值。
对于相关领域普通技术人员已知的技术、方法和设备可能不作详细讨论,但在适当情况下,所述技术、方法和设备应当被视为说明书的一部分。
参见图1所示,本发明实施例提供的基于语音识别的构音障碍自动评估系统包括特征提取单元110、特征提取单元120、特征拼接单元130、多层感知机140和评估单元150,其中,特征提取单元110用于传统声学特征,特征提取单元120用于提取本文自定义的声学特征,特征拼接单元130用于将传统声学特征和自定义特征拼接之后输入至多层感知机140,多层感知机140用于输出对应的障碍程度类别和相应的预测概率,评估单元150用于利用个体句子的预测概率信息得到总体评估结果。图1所示各单元可采用软件模块、处理器或硬件逻辑电路实现。
结合图1所示,本发明实施例提供的基于语音识别的构音障碍自动评估系统整体上包括以下方面:特征提取部分,对构音障碍语音提取句子级别的特征描述,例如,首先使用自动语音识别技术(Automatic Speech Recognition,以下简称ASR)提取自定义的13维特征,然后用OpenSMILE工具提取88维的eGeMAPS参数,作为传统声学特征,接着将自定义的13维特征和88维的传统声学特征拼接在一起,形成101维的新特征,该特征是句子级别的特征;分类与评估部分,对句子级别的特征使用多层感知机分类,多层感知机输出每个句子的障碍程度类别和预测概率,进一步利用个体所有句子的预测概率信息来自动评估个体构音障碍程度。
更具体地,参见图2所示的自动评估框架,其中ASR系统的训练过程如下:对于正常儿童语音数据,提取每一个训练样本的声学特征,它包含12维静态PLP(感知线性预测)特征和1维静态Pitch特征,以及其对应的一阶二阶差分,共39维;然后使用最大似然概率的方法训练得到G MM-HMM基线模型,含有3652个三音素绑定状态;接着使用GMM-HM M基线模型进行强制对齐得到每一帧的三音素绑定状态作为后续网络训练的监督标签;最后使用该监督标签,并结合BP(Back Propagation)算法训练得到深度神经网络(Deep Neural Network,下文简称DNN)模型。在评估阶段,有构音障碍的儿童首先需要认真倾听给定的句子,然后再重复朗读句子3次。句子长度为4-7个字,并覆盖所有118个音素,见表1。每个句子含有其标准发音和标准文本标注,以及构音障碍儿童的实际发音音频。
表1:汉语中用于语音识别的118个音素
最后,利用ASR系统完成以下步骤,来获取用于声学特征提取的信息:
步骤(1),将标准文本标注和实际发音音频输入DNN声学模型,通过强制对齐(force alignment)得到帧级别的关于118个发音的音频标注;
步骤(2),将实际发音音频输入DNN声学模型,并从DNN声学模型的输出层得到每一帧的初步识别信息,该信息包含最后一层每个节点对应的音素及相应的高斯概率密度函数的输出,参见图3(Ot表示特征向量);
步骤(3),利用步骤(2)中的信息,计算每一帧包含的音素及其后验概率,如图3步骤(3)所示,即相同音素的高斯概率密度函数的输出相加得到音素后验概率。帧音素-概率表定义为一个帧所含音素及其后验概率组成的两元组的集合。
需要注意的是,图3中输入的基本单位是一帧,输出层高斯概率密度函数的输出和为1。相应地,步骤(3)得到的多个音素是包含在一个帧内的,即所有音素的后验概率值相加和为1。
在本发明实施例中,基于ASR系统提取以下5类特征:
1)、音素时长
用步骤(1)得到每个句子帧级别的音频标注,使用此标注统计该句子中出现的各音素的帧数量。统计方法是:
音素的帧数量等于该音素连续出现的帧个数,如/a/这个音素连续出现7帧,则其帧数量为7。若一个句子有两处(及以上)出现同一个音素,则取两处帧数量的均值作为该音素的帧数量。
音素时长等于帧时长(25毫秒)乘以音素的帧数量。
根据音素种类的不同(元音,辅音),计算该句子中各类音素时长的均值作为特征值。该类特征有三维,即元音音素时长,辅音音素时长,总体音素时长。
2)、音素替换率
主要音素定义为对应帧中概率值最大的音素,根据步骤(3)得到的帧音素-概率表,计算得到每个句子的帧级别主要音素序列。
用步骤(1)得到的音频标注与上述主要音素序列作对比(静音音素除外),若两音素一致则视为“匹配,”若不一致且主要音素序列中的音素不是静音音素,则视为“替换”。该过程是以帧为单位。
音素替换率等于“替换”的帧个数与“替换”和“匹配”帧个数之和的比值,即:
其中,R表示替换率;N
根据上式分别对辅音,元音,所有音素计算替换率,构成由辅音替换率,元音替换率,总体替换率组成的三维音素替换率特征
3)、近似发音质量(approximate Goodness of Pronunciation,aGOP)近似发音质量是表征发音好坏的量,其计算需要知道真实发音(实际发出来的音)的标注信息,但在实际中因构音障碍语音本身的特点,无论是人工标注还是自动识别无法提供准确的真实发音信息。因此本文定义近似发音质量aGOP来表示发音质量。计算方法是用步骤(3)得到的帧音素-概率表中主要音素(概率值最大的音素)的概率值来表示:
aGOP=max
其中,O
按照句子中不同音素的aGOP,按其类型(元音、辅音)相加取均值得到该类型aGOP均值向量。
该特征有三维,即辅音aGOP的均值,元音aGOP的均值,总体aGOP的均值。
4)、帧模糊率(Blurred Frame Ratio,BFR)
根据帧音素-概率表,对每一帧取概率最大的三个音素。若其满足如下条件则称为“模糊帧”:次大概率值大于等于0.2或第三大概率值大于等于0.1。反之称为“非模糊帧”,不考虑静音音素帧。帧模糊率的计算公式如下:
其中N
该特征有一维,即句子帧模糊率。
5)、帧音素数
帧音素数定义为:步骤(3)得到的帧音素-概率表包含音素的个数。
辅音音素数即为帧音素-概率表中辅音音素的个数,元音音素数则为帧音素-概率表中元音音素的个数。
该特征有三维,辅音音素数,元音音素数,帧音素数。
综上,在本发明实施例中,提取的自定义特征是,每个句子音频提取音5大类(共13维)特征,即素时长、音素替换率、近似发音质量、帧模糊率和帧音素数。
对于传统声学特征提取,利用OpenSMILE工具。集成在OpenSMILE工具的eGeMAPS参数集广泛用于音频的声学分析,它包含88维统计特征参数。在本发明实施例中,按照该参数集用OpenSMILE工具,对构音障碍语音提取句子级别的特征。
对于分类和评估部分,首先对训练数据集里的儿童语语音音障碍程度进行量化。例如,对现有儿童语音按医学评估判断其障碍程度,分为“正常”、“轻微”、“中等”,“严重”四类。
然后,对每一个句子做特征拼接,即基于ASR的13维特征和88维声学特征拼接维为101维。对101维句子特征数值进行最大-最小归一化作为多层感知机的输入。多层感知机包含三层,输入层(如101个节点),隐藏层(如52个节点),输出层(如4个节点)。多层感知机的输出包括当前句子障碍程度类别和相应的预测概率。预测概率是个4维向量,各维度对应4个构音障碍程度类别,其数值在0到1之间,并且4个概率值之和为1。
接下来,利用个体句子的预测概率信息得到总体评估结果。例如,对被评估个体的所有句子的预测概率(4维向量)按维度分别相加取平均值。
其中,N表示被评估儿童语音句子数量,P
本发明实施例的自动评估对构音障碍语音给出预先量化定义的障碍程度等级的一种。这种分类评估与主观评估相比能提供更客观、稳定的结果。并且,本发明的ASR的特征提取根据正常儿童语音训练的声学模型与构音障碍病理语音的不匹配程度,整个特征提取和分类评估过程只需用到用于语言训练的范文和被评估者的语音音频,不需要人工标注信息,从而上述技术方案可以做到自动评估。
综上所述,本发明基于语音识别技术,从构音障碍患者连续语音中提取构音障碍语音的言语特征,这些特征包含构音障碍语音的声学和语言学信息,并且特征提取过程利用构音障碍患者语音所含有的全部元音和辅音,以充分反映构音障碍患者语音的病理特点。根据所提取的特征,用分类器分类和综合判别方法来给出自动评估结果。构音障碍语音特征提取时,覆盖到构音障碍语音含有的全部音素,同时从短句子,即连续语音中提取特征。并且经验证,本发明能够提供客观、可靠、稳定的评估结果,并且能够实现构音障碍语音的自动评估,节省了人力和时间资源。
需要说明的是,虽然上文按照特定顺序描述了各个步骤,但是并不意味着必须按照上述特定顺序来执行各个步骤,实际上,这些步骤中的一些可以并发执行,甚至改变顺序,只要能够实现所需要的功能即可。
本发明可以是系统、方法和/或计算机程序产品。计算机程序产品可以包括计算机可读存储介质,其上载有用于使处理器实现本发明的各个方面的计算机可读程序指令。
计算机可读存储介质可以是保持和存储由指令执行设备使用的指令的有形设备。计算机可读存储介质例如可以包括但不限于电存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或者上述的任意合适的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:便携式计算机盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦式可编程只读存储器(EPROM或闪存)、静态随机存取存储器(SRAM)、便携式压缩盘只读存储器(CD-ROM)、数字多功能盘(DVD)、记忆棒、软盘、机械编码设备、例如其上存储有指令的打孔卡或凹槽内凸起结构、以及上述的任意合适的组合。
以上已经描述了本发明的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术改进,或者使本技术领域的其它普通技术人员能理解本文披露的各实施例。
- 一种基于语音识别的构音障碍自动评估系统和方法
- 一种基于Zynq FPGA的自动化可靠性评估系统及评估方法