一种角度余量自适应的人脸识别模型训练方法
文献发布时间:2023-06-19 11:44:10
技术领域
本发明涉及人脸识别的技术领域,尤其涉及一种角度余量自适应的人脸识别模型训练方法。
背景技术
目前,人脸识别已经成为十分重要的用于身份认证的生物识别技术,广泛应用于金融、商业、安防等多个领域。传统的人脸识别方法一般采用描述符算子对人脸图像就行特征提取,如局部二值模式(LBP)算子等。这类方法实现简单,但提取的特征的辨别力低,用于人脸识别准确率低。目前,主流的人脸识别模型均采用基于深度学习的方法。基于深度学习的人脸识别方法的核心是损失函数的设计,近年来,基于余弦距离优化并且引入角度余量思想的损失函数的提出和不断优化,促进了人脸识别的快速发展。如SphereFace,CosFace和ArcFace等一系列加入角度余量的损失函数,所监督训练出的人脸识别网络获得了很高的准确率。然而,这些算法引入的都是一个固定的角度余量值,这个值作为一个固定参数,在训练前人为设定。这种做法是存在一定问题的。
人脸识别数据集中普遍存在着长尾分布的问题,类别之间的分布极度不平衡,存在富裕类(Rich Class)和贫穷类(Poor Class)的区别。对样本数足够多且类内方差足够大的富裕类,数据集中的该类数据样本的分布可以近似表示这一类别的真实分布。但是对于样本数稀少且类内方差小的贫穷类,数据集中该类数据样本的分布只是该类别真实分布的一小部分,无法表示完整的真实分布。如果在训练中,富裕类和贫穷类的样本都使用相同的角度余量,那么贫穷类人脸样本对应的特征向量的分布会不如富裕类的紧凑,即贫穷类人脸特征向量的类内距离会更大,这是因为贫穷类真实的样本分布要比观测到的更大,但在训练中却没有注意到这一点,导致网络的泛化能力降低。
发明内容
发明目的:为了克服现有技术中存在的不足,本发明提供一种角度余量自适应的人脸识别模型训练方法,该发明能够对人脸识别数据集中不同的类别设定自适应的角度余量,解决类别之间的分布极度不平衡的问题。
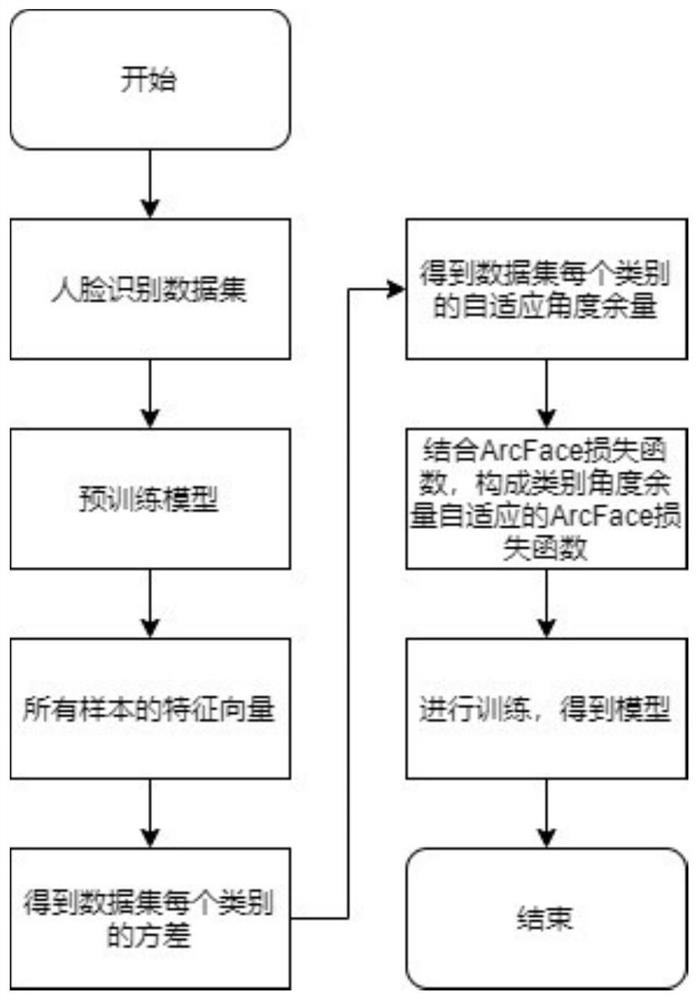
技术方案:为了实现上述发明目的,本发明提供了一种角度余量自适应的人脸识别模型训练方法,包括以下步骤,
步骤1,基于人脸识别数据集,采用损失函数进行预训练,得到预训练模型;
步骤2,将人脸识别数据集中的样本输入预训练模型,得到对应的特征向量;
步骤3,对人脸识别数据集中的每个类别,分别求出对应的类内方差;
步骤4,根据所得每个类别对应的类内方差,得到对应的角度余量大小;
步骤5,结合每个类别的角度余量和加法角度余量损失函数,构成类别角度余量自适应的加法角度余量损失函数;
步骤6,用类别角度余量自适应的加法角度余量损失函数监督人脸识别模型进行训练,以端到端的方式,采用随机梯度下降法进行训练,当类别角度余量自适应的加法角度余量损失函数下降收敛后,保存网络参数,得到最终的人脸识别模型并可用于人脸识别。
进一步的,在本发明中:所述步骤1还包括,
步骤1.1,对预训练网络模型的参数进行初始化;
步骤1.2,以简单的人脸识别损失函数为监督,采用随机梯度下降法进行训练;
步骤1.3,当损失函数下降收敛后,保存网络参数,得到预训练模型。
进一步的,在本发明中:所述步骤2还包括,
步骤2.1,将数据集中的样本x
步骤2.2,将特征向量f(x
进一步的,在本发明中:所述步骤3还包括,
步骤3.1,对数据集中的每个类别C
其中,n
步骤3.2,计算类内方差
进一步的,在本发明中:所述步骤4还包括,
步骤4.1,确定角度余量值的上界M
步骤4.2,统计得到所有类别中最大的方差Var
步骤4.3,通过线性映射,将每个类别C
进一步的,在本发明中:所述步骤5还包括,
步骤5.1,将加法角度余量损失函数表达式中的固定角度余量参数修改为类别自适应的角度余量参数;
步骤5.2,将步骤4中得到的每个类别的角度余量值作为参数值,构成类别角度余量自适应的加法角度余量损失函数L
其中,y
进一步的,在本发明中:所述步骤6还包括,
步骤6.1,对人脸识别网络模型的参数进行初始化;
步骤6.2,以类别角度余量自适应的加法角度余量损失函数作为监督,采用随机梯度下降法进行训练。
步骤6.3,当损失函数下降收敛后,保存网络参数,得到最终的人脸识别模型。
有益效果:本发明与现有技术相比,其有益效果是:
(1)本发明针对人脸识别数据集中存在的长尾分布问题,在角度余量损失函数的基础上,引入了类别自适应角度余量,使得角度余量不再是固定的超参数,而是与类别属性有关的参数,使得训练出的模型具有更高的准确率和泛化能力从而在一定程度上解决了类别分布不均衡的问题;
(2)本方明提供的训练方法,首先通过预训练模型得到人脸样本对应的特征向量,计算出数据集中每个类别的特征向量方差,方差大的类别赋予更小的角度余量,方差小的类别赋予更大的角度余量,从而实现类别自适应,训练得到的人脸识别模型在准确率和泛化能力上都有所提高。
附图说明
图1为本发明所述角度余量自适应的人脸识别模型训练方法的整体流程示意图;
图2为本发明方差和角度余量映射关系示意图;
图3为本发明人脸识别模型的准确率测试结果对比示意图。
具体实施方式
下面结合附图对本发明的技术方案做进一步的详细说明:
本发明可以用许多不同的形式实现,而不应当认为限于这里所述的实施例。相反,提供这些实施例以便使本公开透彻且完整,并且将向本领域技术人员充分表达本发明的范围。
如图1所示,为本发明所述一种角度余量自适应的人脸识别模型训练方法的整体流程示意图,该方法包括以下步骤,
步骤1,基于人脸识别数据集,采用损失函数进行预训练,得到预训练模型;其中,人脸识别数据集可以采用UMDFaces数据集和MegaFace数据集。
具体的,步骤1还包括,
步骤1.1,对预训练网络模型的参数进行初始化;
步骤1.2,以简单人脸识别损失函数为监督,采用随机梯度下降法进行训练;其中,简单人脸识别损失函数可以选择NormFace损失函数。
步骤1.3,当损失函数下降收敛后,保存网络参数,得到预训练模型。
步骤2,将人脸识别数据集中的样本输入预训练模型,得到对应的特征向量;
具体的,步骤2还包括,
步骤2.1,将数据集中的样本x
步骤2.2,将特征向量f(x
步骤3,对人脸识别数据集中的每个类别,分别求出对应的类内方差;其中,人脸识别数据集中每个人代表一个类别。
具体的,步骤3还包括,
步骤3.1,对数据集中的每个类别C
其中,n
步骤3.2,计算类内方差
步骤4,根据所得每个类别对应的类内方差,得到对应的角度余量大小;参照图2的示意,为类内方差和角度余量映射关系示意图,其中横坐标为类内方差,纵坐标为角度余量值,可以看出二者为线性负相关关系,映射函数为斜率为负一次函数。
具体的,步骤4还包括,
步骤4.1,确定角度余量值的上界M
步骤4.2,统计得到所有类别中最大的方差Var
步骤4.3,通过线性映射,将每个类别C
步骤5,结合每个类别的角度余量和加法角度余量损失函数,构成类别角度余量自适应的加法角度余量损失函数;
具体的,步骤5还包括,
步骤5.1,将加法角度余量损失函数表达式中的固定角度余量参数修改为类别自适应的角度余量参数;
步骤5.2,将步骤4中得到的每个类别的角度余量值作为参数值,构成类别角度余量自适应的加法角度余量损失函数L
其中,y
步骤6,用类别角度余量自适应的加法角度余量损失函数监督人脸识别模型进行训练,以端到端的方式,采用随机梯度下降法进行训练,当类别角度余量自适应的加法角度余量损失函数下降收敛后,保存网络参数,得到最终的人脸识别模型并可用于人脸识别。
具体的,步骤6还包括,
步骤6.1,对人脸识别网络模型的参数进行初始化;
步骤6.2,以类别角度余量自适应的加法角度余量损失函数作为监督,采用随机梯度下降法进行训练。
步骤6.3,当损失函数下降收敛后,保存网络参数,得到最终的人脸识别模型。
进一步的,为了验证本发明所提出方法的有益效果,参照图3的示意,分别使用传统的加法角度余量损失函数监督网络进行训练和本发明提出的类别角度余量自适应的加法角度余量损失函数监督进行训练,并采用训练后的网络进行人脸识别测试,对比两种训练方法下得到的网络在不同测试集上识别的准确率,采用的测试集包括LFW测试集、AgeDB-30测试集和CALFW测试集,可以看出,在本发明提出的训练方法下,网络识别准确率在各测试集上均高于传统训练方法下网络识别的准确率,验证了本发明的有益效果。
应说明的是,以上所述实施例仅表达了本发明的部分实施方式,其描述并不能理解为对本发明专利范围的限制。应当指出的是,对于本技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干改进,这些均应落入本发明的保护范围。
- 一种角度余量自适应的人脸识别模型训练方法
- 基于多角度的人脸识别模型训练及测试系统及方法